基于BiGRU+Attention实现风力涡轮机发电量多变量时序预测(PyTorch版)

前言
系列专栏:【深度学习:算法项目实战】✨︎
涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对抗网络、门控循环单元、长短期记忆、自然语言处理、深度强化学习、大型语言模型和迁移学习。
随着全球能源结构的不断转型和可持续发展战略的深入实施,风能作为一种清洁、可再生的能源,其在全球能源供应中的地位日益凸显。风力涡轮机作为风能利用的主要设备,其发电量的准确预测对于电力系统的稳定运行、优化调度以及风电的并网消纳具有重要意义。然而,由于风能的间歇性和不稳定性,风力涡轮机的发电量预测成为了一个极具挑战性的任务。
近年来,深度学习技术在时间序列预测领域展现出了强大的潜力,特别是循环神经网络(RNN)及其变体,如长短期记忆网络(LSTM)和门控循环单元(GRU),在处理序列数据方面表现出色。双向门控循环单元(BiGRU)作为GRU的一种扩展,通过同时考虑序列数据中的过去和未来信息,进一步提高了模型捕捉长期依赖关系的能力。此外,注意力机制(Attention)的引入,使得模型能够动态地调整不同时间步长输入特征的权重,从而更加关注对预测结果影响较大的关键信息。
基于上述背景,本文提出了基于BiGRU+Attention的风力涡轮机发电量时序预测模型,旨在通过结合BiGRU和Attention机制的优势,提高风力涡轮机发电量预测的准确性和效率。该模型不仅能够捕捉风力发电量数据中的时序依赖关系,还能通过注意力机制关注对预测结果更为重要的输入特征,从而在复杂多变的风电环境中实现高精度的预测。
本文首先介绍了研究背景与意义,概述了BiGRU和Attention机制的基本原理及其在风力涡轮机发电量预测中的应用潜力。随后,详细描述了模型的构建与训练过程,包括数据收集与预处理、特征提取、时间序列建模、预测输出以及模型训练与性能评估等关键步骤。通过实际案例分析和实验结果展示,验证了该模型在风力涡轮机发电量预测中的有效性和优越性。
基于BiGRU+Attention实现风力涡轮机发电量时序预测
- 1. 数据集介绍
- 2. 数据预处理
- 3. 数据可视化
- 3.1 数据相关性
- 4. 特征工程
- 4.1 特征缩放(归一化)
- 4.2 构建时间序列数据
- 4.3 数据集划分
- 4.4 数据集张量
- 5. 构建时序模型(TSF)
- 5.1 构建BiGRU_Attention模型
- 5.2 定义模型、损失函数与优化器
- 5.3 模型概要
- 6. 模型训练与可视化
- 6.1 定义训练与评估函数
- 6.2 绘制训练与验证损失曲线
- 7. 模型评估与可视化
- 7.1 构建预测函数
- 7.2 验证集预测
- 7.3 回归拟合图
- 7.4 评估指标
1. 数据集介绍
在风力涡轮机中,Scada 系统测量并保存风速、风向、发电量等数据,时间间隔为 10 分钟。该文件取自土耳其一台正在发电的风力涡轮机的 scada 系统。原数据英文及解释如下:
- Date/Time (for 10 minutes intervals)
- LV ActivePower (kW): The power generated by the turbine for that moment
- Wind Speed (m/s): The wind speed at the hub height of the turbine (the wind speed that turbine use for electricity generation)
- Theoretical_Power_Curve (KWh): The theoretical power values that the turbine generates with that wind speed which is given by the turbine manufacturer
- Wind Direction (°): The wind direction at the hub height of the turbine (wind turbines turn to this direction automaticly)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsfrom sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, \mean_absolute_percentage_error, \mean_squared_error, root_mean_squared_error, \r2_scoreimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import TensorDataset, DataLoader, Dataset
from torchinfo import summarynp.random.seed(0)
data = pd.read_csv("T1.csv")
data.head(10).style.background_gradient(cmap='bone')

2. 数据预处理
现在,我们使用 pandas.to_datetime 函数,将日期解析为时间数据类型
print(type(data['LV ActivePower (kW)'].iloc[0]),type(data['Date/Time'].iloc[0]))# Let's convert the data type of timestamp column to datatime format
data['Date/Time'] = pd.to_datetime(data['Date/Time'],format='%d %m %Y %H:%M')
print(type(data['LV ActivePower (kW)'].iloc[0]),type(data['Date/Time'].iloc[0]))cond_1 = data['Date/Time'] >= '2018-01-01 00:00:00'
cond_2 = data['Date/Time'] <= '2018-01-07 23:59:59'
data = data[cond_1 & cond_2]
print(data.shape)
<class 'numpy.float64'> <class 'str'>
<class 'numpy.float64'> <class 'pandas._libs.tslibs.timestamps.Timestamp'>
(987, 5)
3. 数据可视化
3.1 数据相关性
使用 data.corr() 计算相关系数矩阵
correlation = data.corr()
print(correlation['LV ActivePower (kW)'].sort_values(ascending=False))
LV ActivePower (kW) 1.000000
Theoretical_Power_Curve (KWh) 0.996930
Wind Speed (m/s) 0.965048
Wind Direction (°) 0.217183
Date/Time -0.028100
Name: LV ActivePower (kW), dtype: float64
plt.figure(figsize=(10, 8)) # 设置图片大小
sns.heatmap(correlation, annot=True, cmap=sns.cubehelix_palette(dark=.20, light=.95, as_cmap=True), linewidths=0.5)
plt.show()

很明显,LV ActivePower (kW) 与 Theoretical_Power_Curve (KWh)、Wind Speed (m/s) 存在强相关性
4. 特征工程
4.1 特征缩放(归一化)
StandardScaler()函数将数据的特征值转换为符合正态分布的形式,它将数据缩放到均值为0,标准差为1的区间。在机器学习中,StandardScaler()函数常用于不同尺度特征数据的标准化,以提高模型的泛化能力。
# 使用选定的特征来训练模型
features = data.drop('Date/Time', axis=1)
target = data['LV ActivePower (kW)'].values.reshape(-1, 1)
# 创建 StandardScaler实例,对特征进行拟合和变换,生成NumPy数组
scaler = StandardScaler()
features_scaled = scaler.fit_transform(features)
target_scaled = scaler.fit_transform(target)
print(features_scaled.shape, target_scaled.shape)
4.2 构建时间序列数据
我们创建一个时间序列数据,时间步 time_steps 假设设置为10
time_steps = 10
X_list = []
y_list = []for i in range(len(features_scaled) - time_steps):X_list.append(features_scaled[i:i+time_steps])y_list.append(target_scaled[i+time_steps])X = np.array(X_list) # [samples, time_steps, num_features]
y = np.array(y_list) # [target]
samples, time_steps, num_features = X.shape
4.3 数据集划分
train_test_split 函数将数组或矩阵随机分成训练子集和测试子集。
X_train, X_valid,\y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=45,shuffle=False)
print(X_train.shape, X_valid.shape, y_train.shape, y_valid.shape)
以上代码中 random_state=45 设置了随机种子,以确保每次运行代码时分割结果的一致性。shuffle=False 表示在分割数据时不进行随机打乱。如果设置为True(默认值),则会在分割之前对数据进行随机打乱,这样可以增加数据的随机性,但时间序列数据具有连续性,所以设置为False。
4.4 数据集张量
# 将 NumPy数组转换为 tensor张量
X_train_tensor = torch.from_numpy(X_train).type(torch.Tensor)
X_valid_tensor = torch.from_numpy(X_valid).type(torch.Tensor)
y_train_tensor = torch.from_numpy(y_train).type(torch.Tensor).view(-1, 1)
y_valid_tensor = torch.from_numpy(y_valid).type(torch.Tensor).view(-1, 1)print(X_train_tensor.shape, X_valid_tensor.shape, y_train_tensor.shape, y_valid_tensor.shape)
以上代码通过 train_test_split 划分得到的训练集和验证集中的特征数据 X_train、X_valid 以及标签数据 y_train、y_valid 从 numpy 数组转换为 PyTorch 的张量(tensor)类型。.type(torch.Tensor) 确保张量的数据类型为标准的 torch.Tensor 类型,.view(-1, 1) 对张量进行维度调整
class DataHandler(Dataset):def __init__(self, X_train_tensor, y_train_tensor, X_valid_tensor, y_valid_tensor):self.X_train_tensor = X_train_tensorself.y_train_tensor = y_train_tensorself.X_valid_tensor = X_valid_tensorself.y_valid_tensor = y_valid_tensordef __len__(self):return len(self.X_train_tensor)def __getitem__(self, idx):sample = self.X_train_tensor[idx]labels = self.y_train_tensor[idx]return sample, labelsdef train_loader(self):train_dataset = TensorDataset(self.X_train_tensor, self.y_train_tensor)return DataLoader(train_dataset, batch_size=32, shuffle=True)def valid_loader(self):valid_dataset = TensorDataset(self.X_valid_tensor, self.y_valid_tensor)return DataLoader(valid_dataset, batch_size=32, shuffle=False)
在上述代码中,定义了一个名为 DataHandler 的类,它继承自 torch.utils.data.Dataset
__init__ 方法用于接收数据和标签。__len__ 方法返回数据集的长度。__getitem__ 方法根据给定的索引 idx 返回相应的数据样本和标签。
data_handler = DataHandler(X_train_tensor, y_train_tensor, X_valid_tensor, y_valid_tensor)
train_loader = data_handler.train_loader()
valid_loader = data_handler.valid_loader()
5. 构建时序模型(TSF)
5.1 构建BiGRU_Attention模型
class BiGRU_Attention(nn.Module):def __init__(self, input_dim, hidden_dim, num_layers, output_dim, num_heads):super(BiGRU_Attention, self).__init__()self.hidden_dim = hidden_dimself.num_layers = num_layersself.bigru = nn.GRU(input_dim, hidden_dim, num_layers=num_layers, batch_first=True, bidirectional=True)self.attention = nn.MultiheadAttention(embed_dim=hidden_dim*2, num_heads=num_heads, batch_first=True)self.dropout = nn.Dropout(p=0.5)self.fc = nn.Linear(hidden_dim*2, output_dim)def forward(self, x):# x: [batch_size, seq_len, input_dim]# h0: [num_layers * num_directions, batch_size, hidden_dim]h0 = torch.zeros(self.num_layers*2, x.size(0), self.hidden_dim).to(x.device)out, _ = self.bigru(x, h0)drop_gruout = self.dropout(out)# 注意力层attn_output, _ = self.attention(drop_gruout, drop_gruout, drop_gruout)drop_output = self.dropout(attn_output[:, -1, :])# 全连接层out = self.fc(drop_output)return out
5.2 定义模型、损失函数与优化器
model = BiGRU_Attention(input_dim = num_features,hidden_dim = 8,num_layers = 2, output_dim = 1, num_heads = 16)
criterion_mse = nn.MSELoss() # 定义均方误差损失函数
criterion_mae = nn.L1Loss() # 定义平均绝对误差损失
optimizer = torch.optim.Adam(model.parameters(), lr=1e-04) # 定义优化器
nn.L1Loss() 是 PyTorch 中的一个损失函数,用于计算模型预测值和真实值之间的平均绝对误差(Mean Absolute Error, MAE)
5.3 模型概要
# batch_size, seq_len(time_steps), input_size(in_channels)
summary(model, (32, time_steps, num_features))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
BiGRU_Attention [32, 1] --
├─GRU: 1-1 [32, 10, 16] 1,920
├─Dropout: 1-2 [32, 10, 16] --
├─MultiheadAttention: 1-3 [32, 10, 16] 1,088
├─Dropout: 1-4 [32, 16] --
├─Linear: 1-5 [32, 1] 17
==========================================================================================
Total params: 3,025
Trainable params: 3,025
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 0.61
==========================================================================================
Input size (MB): 0.01
Forward/backward pass size (MB): 0.04
Params size (MB): 0.01
Estimated Total Size (MB): 0.05
==========================================================================================
6. 模型训练与可视化
6.1 定义训练与评估函数
def train(model, iterator, optimizer):epoch_loss_mse = 0epoch_loss_mae = 0model.train() # 确保模型处于训练模式for batch in iterator:optimizer.zero_grad() # 清空梯度inputs, targets = batch # 获取输入和目标值outputs = model(inputs) # 前向传播loss_mse = criterion_mse(outputs, targets) # 计算损失loss_mae = criterion_mae(outputs, targets)combined_loss = loss_mse + loss_mae # 可以根据需要调整两者的权重combined_loss.backward()optimizer.step()epoch_loss_mse += loss_mse.item() # 累计损失epoch_loss_mae += loss_mae.item()average_loss_mse = epoch_loss_mse / len(iterator) # 计算平均损失average_loss_mae = epoch_loss_mae / len(iterator)return average_loss_mse, average_loss_mae
上述代码定义了一个名为 train 的函数,用于训练给定的模型。它接收模型、数据迭代器、优化器作为参数,并返回训练过程中的平均损失。
def evaluate(model, iterator):epoch_loss_mse = 0epoch_loss_mae = 0model.eval() # 将模型设置为评估模式,例如关闭 Dropout 等with torch.no_grad(): # 不需要计算梯度for batch in iterator:inputs, targets = batchoutputs = model(inputs) # 前向传播loss_mse = criterion_mse(outputs, targets) # 计算损失loss_mae = criterion_mae(outputs, targets)epoch_loss_mse += loss_mse.item() # 累计损失epoch_loss_mae += loss_mae.item()return epoch_loss_mse / len(iterator), epoch_loss_mae / len(iterator)
上述代码定义了一个名为 evaluate 的函数,用于评估给定模型在给定数据迭代器上的性能。它接收模型、数据迭代器作为参数,并返回评估过程中的平均损失。这个函数通常在模型训练的过程中定期被调用,以监控模型在验证集或测试集上的性能。通过评估模型的性能,可以了解模型的泛化能力和训练的进展情况。
epoch = 500
train_mselosses = []
valid_mselosses = []
train_maelosses = []
valid_maelosses = []for epoch in range(epoch):train_loss_mse, train_loss_mae = train(model, train_loader, optimizer)valid_loss_mse, valid_loss_mae = evaluate(model, valid_loader)train_mselosses.append(train_loss_mse)valid_mselosses.append(valid_loss_mse)train_maelosses.append(train_loss_mae)valid_maelosses.append(valid_loss_mae)print(f'Epoch: {epoch+1:02}, Train MSELoss: {train_loss_mse:.5f}, Train MAELoss: {train_loss_mae:.3f}, Val. MSELoss: {valid_loss_mse:.5f}, Val. MAELoss: {valid_loss_mae:.3f}')
Epoch: 01, Train MSELoss: 0.86945, Train MAELoss: 0.852, Val. MSELoss: 1.08921, Val. MAELoss: 0.997
Epoch: 02, Train MSELoss: 0.82845, Train MAELoss: 0.827, Val. MSELoss: 1.07914, Val. MAELoss: 0.992
Epoch: 03, Train MSELoss: 0.77970, Train MAELoss: 0.800, Val. MSELoss: 1.06364, Val. MAELoss: 0.984
Epoch: 04, Train MSELoss: 0.72964, Train MAELoss: 0.770, Val. MSELoss: 1.03752, Val. MAELoss: 0.971
Epoch: 05, Train MSELoss: 0.67883, Train MAELoss: 0.740, Val. MSELoss: 1.00662, Val. MAELoss: 0.954
******
Epoch: 496, Train MSELoss: 0.08508, Train MAELoss: 0.223, Val. MSELoss: 0.05806, Val. MAELoss: 0.203
Epoch: 497, Train MSELoss: 0.08262, Train MAELoss: 0.218, Val. MSELoss: 0.05554, Val. MAELoss: 0.195
Epoch: 498, Train MSELoss: 0.08714, Train MAELoss: 0.220, Val. MSELoss: 0.04519, Val. MAELoss: 0.168
Epoch: 499, Train MSELoss: 0.09767, Train MAELoss: 0.239, Val. MSELoss: 0.05352, Val. MAELoss: 0.191
Epoch: 500, Train MSELoss: 0.08566, Train MAELoss: 0.220, Val. MSELoss: 0.05005, Val. MAELoss: 0.183
6.2 绘制训练与验证损失曲线
# 绘制 MSE损失图
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_mselosses, label='Train MSELoss')
plt.plot(valid_mselosses, label='Validation MSELoss')
plt.xlabel('Epoch')
plt.ylabel('MSELoss')
plt.title('Train and Validation MSELoss')
plt.legend()
plt.grid(True)# 绘制 MAE损失图
plt.subplot(1, 2, 2)
plt.plot(train_maelosses, label='Train MAELoss')
plt.plot(valid_maelosses, label='Validation MAELoss')
plt.xlabel('Epoch')
plt.ylabel('MAELoss')
plt.title('Train and Validation MAELoss')
plt.legend()
plt.grid(True)plt.show()

7. 模型评估与可视化
7.1 构建预测函数
定义预测函数prediction 方便调用
# 定义 prediction函数
def prediction(model, iterator): all_targets = []all_predictions = []model.eval()with torch.no_grad():for batch in iterator:inputs, targets = batchpredictions = model(inputs)all_targets.extend(targets.numpy())all_predictions.extend(predictions.numpy())return all_targets, all_predictions
7.2 验证集预测
# 模型预测
targets, predictions = prediction(model, valid_loader)
denormalized_targets = scaler.inverse_transform(targets)
denormalized_predictions = scaler.inverse_transform(predictions)
targets 是经过标准化处理后的目标值数组,predictions 是经过标准化处理后的预测值数组。scaler 是StandardScaler() 标准化类的实例,inverse_transform 方法会将标准化后的数组还原为原始数据的尺度,即对预测值进行反标准化操作。
# Visualize the data
plt.figure(figsize=(12,6))
plt.style.use('_mpl-gallery')
plt.title('Comparison of validation set prediction results')
plt.plot(denormalized_targets, color='blue',label='Actual Value')
plt.plot(denormalized_predictions, color='orange', label='Valid Value')
plt.legend()
plt.show()

7.3 回归拟合图
plt.figure(figsize=(5, 5), dpi=100)
sns.regplot(x=denormalized_targets, y=denormalized_predictions, scatter=True, marker="x", color='blue',line_kws={'color': 'red'})
plt.show()

7.4 评估指标
这里我们将通过调用 sklearn.metrics 模块中的 mean_absolute_error mean_absolute_percentage_error mean_squared_error root_mean_squared_error r2_score 函数来评估模型性能
mae = mean_absolute_error(targets, predictions)
print(f"MAE: {mae:.4f}")mape = mean_absolute_percentage_error(targets, predictions)
print(f"MAPE: {mape * 100:.4f}%")mse = mean_squared_error(targets, predictions)
print(f"MSE: {mse:.4f}")rmse = root_mean_squared_error(targets, predictions)
print(f"RMSE: {rmse:.4f}")r2 = r2_score(targets, predictions)
print(f"R²: {r2:.4f}")
MAE: 0.1893
MAPE: 58.1806%
MSE: 0.0519
RMSE: 0.2278
R²: 0.9173
相关文章:
基于BiGRU+Attention实现风力涡轮机发电量多变量时序预测(PyTorch版)
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对…...

深入探究 Flask 的应用和请求上下文
目标 读完本文后,您应该能够解释: 什么是上下文哪些数据同时存储在应用程序和请求上下文中在 Flask 中处理请求时,处理应用程序和请求上下文所需的步骤如何使用应用程序和请求上下文的代理如何在视图函数中使用current_app和代理request什么…...
)
C++学习笔记(30)
二十三、随机数 在实际开发中,经常用到随机数,例如:纸牌的游戏洗牌和发牌、生成测试数据等。 函数原型: void srand(unsigned int seed); // 初始化随机数生成器(播种子)。 int rand(); // 获一个取随机数。…...

Rust GUI框架 tauri V2 项目创建
文章目录 Tauri 2.0创建应用文档移动应用开发 Android 前置要求移动应用开发 iOS 前置要求参考资料 Tauri 2.0 Tauri 是一个构建适用于所有主流桌面和移动平台的轻快二进制文件的框架。开发者们可以集成任何用于创建用户界面的可以被编译成 HTML、JavaScript 和 CSS 的前端框架…...
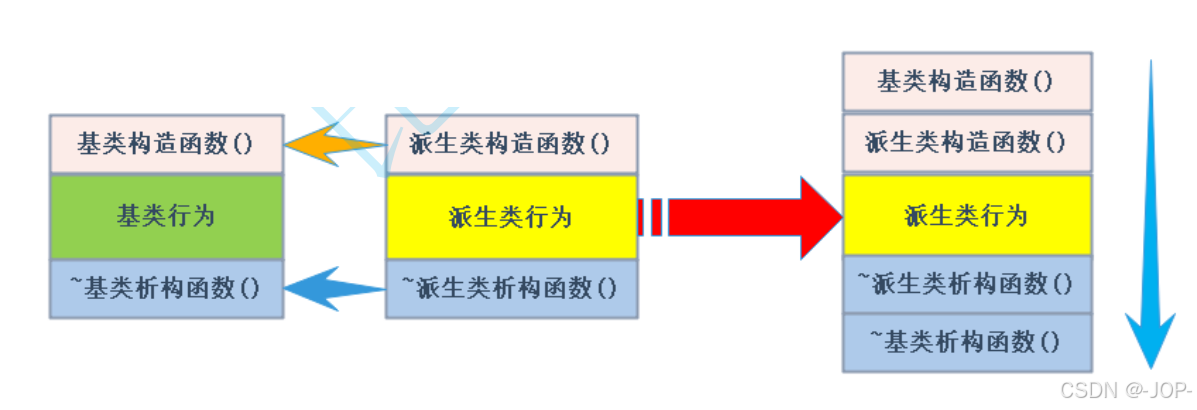
C++继承(上)
1.继承的概念 继承是一个类继承另外一个类,称继承的类为子类/派生类,被继承的类称为父类/基类。 比如下面两个类,Student和Person,Student称为子类,Person称为父类。 #include<iostream> using namespace std…...

在 Vim 中打开文件并快速查询某个字符
在 Vim 中打开文件并快速查询某个字符,可以按照以下步骤操作: 打开 Vim 并加载文件: vim your_file.txt将 your_file.txt 替换为你要查询的文件名。 进入普通模式(如果你还在插入模式或其他模式下): Es…...

oracle 条件取反
在Oracle数据库中,条件取反主要通过逻辑运算符NOT来实现。NOT是一个单目运算符,用于对指定的条件表达式取反。当条件表达式为真(True)时,NOT运算符的结果就是假(False);反之…...

力扣最热一百题——缺失的第一个正数
目录 题目链接:41. 缺失的第一个正数 - 力扣(LeetCode) 题目描述 示例 提示: 解法一:标记数组法 1. 将非正数和超出范围的数替换 2. 使用数组下标标记存在的数字 3. 找到第一个未标记的位置 4. 为什么时间复杂…...

零基础入门AI:一键本地运行各种开源大语言模型 - Ollama
什么是 Ollama? Ollama 是一个可以在本地部署和管理开源大语言模型的框架,由于它极大的简化了开源大语言模型的安装和配置细节,一经推出就广受好评,目前已在github上获得了46k star。 不管是著名的羊驼系列,还是最新…...

3.接口测试的基础/接口关联(Jmeter工具/场景一:我一个人负责所有的接口,项目规模不大)
一、Jmeter接口测试实战 1.场景一:我一个人负责所有的接口:项目规模不大 http:80 https:443 接口文档一般是开发给的,如果没有那就需要抓包。 请求默认值: 2.请求: 请求方式:get,post 请求路径 请求参数 查询字符串参数…...

【matlab】将程序打包为exe文件(matlab r2023a为例)
文章目录 一、安装运行时环境1.1 安装1.2 简介 二、打包三、打包文件为什么很大 一、安装运行时环境 使用 Application Compiler 来将程序打包为exe,相当于你使用C编译器把C语言编译成可执行程序。 在matlab菜单栏–App下面可以看到Application Compiler。 或者在…...

从底层原理上解释clickhouse查询为什么快
ClickHouse 是一个开源的列式数据库管理系统,以其极高的查询性能著称。为了理解 ClickHouse 查询为什么快,我们需要从以下几个方面进行深入探讨,包括其架构设计、存储引擎、索引结构、并行化策略以及内存管理等底层原理。 1. 列式存储&#…...

FEAD:fNIRS-EEG情感数据库(视频刺激)
摘要 本文提出了一种可用于训练情绪识别模型的fNIRS-EEG情感数据库——FEAD。研究共记录了37名被试的脑电活动和脑血流动力学反应,以及被试对24种情绪视听刺激的分类和维度评分。探讨了神经生理信号与主观评分之间的关系,并在前额叶皮层区域发现了显著的…...

标准库标头 <bit>(C++20)学习
<bit>头文件是数值库的一部分。定义用于访问、操作和处理各个位和位序列的函数。例如,有函数可以旋转位、查找连续集或已清除位的数量、查看某个数是否为 2 的整数幂、查找表示数字的最小位数等。 类型 endian (C20) 指示标量类型的端序 (枚举) 函数 bit_ca…...

redis群集三种模式:主从复制、哨兵、集群
redis群集有三种模式 redis群集有三种模式,分别是主从同步/复制、哨兵模式、Cluster,下面会讲解一下三种模式的工作方式,以及如何搭建cluster群集 ●主从复制:主从复制是高可用Redis的基础,哨兵和集群都是在主从复制…...

【MATLAB源码-第225期】基于matlab的计算器GUI设计仿真,能够实现基础运算,三角函数以及幂运算
操作环境: MATLAB 2022a 1、算法描述 界面布局 计算器界面的主要元素分为几大部分:显示屏、功能按钮、数字按钮和操作符按钮。 显示屏 显示屏(Edit Text):位于界面顶部中央,用于显示用户输入的表达式和…...

基于yolov8的红外小目标无人机飞鸟检测系统python源码+onnx模型+评估指标曲线+精美GUI界面
【算法介绍】 基于YOLOv8的红外小目标无人机与飞鸟检测系统是一项集成了前沿技术的创新解决方案。该系统利用YOLOv8深度学习模型的强大目标检测能力,结合红外成像技术,实现了对小型无人机和飞鸟等低空飞行目标的快速、准确检测。 YOLOv8作为YOLO系列的…...

网络封装分用
目录 1,交换机 2,IP 3,接口号 4,协议 分层协议的好处: 5,OSI七层网络模型. 6,TCP/IP五层网络模型(主流): [站在发送方视角] [接收方视角] 1,交换机 交换机和IP没有关系,相当于是对路由器接口的扩充,这时相当于主机都与路由器相连处于局域网中,把越来越多的路由器连接起…...

【Finetune】(一)、transformers之BitFit微调
文章目录 0、参数微调简介1、常见的微调方法2、代码实战2.1、导包2.2、加载数据集2.3、数据集处理2.4、创建模型2.5、BitFit微调*2.6、配置模型参数2.7、创建训练器2.8、模型训练2.9、模型推理 0、参数微调简介 参数微调方法是仅对模型的一小部分的参数(这一小部分可…...

ubuntu24系统普通用户免密切换到root用户
普通用户登录系统后需要切换到root用户,这边需要密码,现在不想让用户知道密码是多少。 sudo: 1 incorrect password attempt $ su - Password: root-security-cm5:~#开始配置普通用户免密切换到root用户,编辑配置文件 /etc/sudoers 最后增加…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...
)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测)
ParaView时间戳设置全攻略:从基础标注到自定义格式(5.8.0实测) 在科学可视化领域,时间戳不仅是数据演变的见证者,更是研究成果呈现的专业语言。ParaView作为开源可视化工具链的标杆,其时间标注功能在学术论…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

真可用!美团数字人模型开源,MV、电商等统统拿下
美团开源的数字人视频生成框架 LongCat-Video-Avatar 刚刚更新到 1.5 版本。是真能用。这版更新把音频编码器换了,推理步数砍到8步,在770人、13240条主观评分的大规模评测里,雷达图面积全面领先。音频编码器换血,8步出图LongCat-V…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...