Pandas_数据结构详解
1.创建DataFrame对象
-
概述
-
DataFrame是一个表格型的==结构化==数据结构,它含有一组或多组有序的列(Series),每列可以是不同的值类型(数值、字符串、布尔值等)。
-
DataFrame是Pandas中的最基本的数据结构对象,简称df;可以认为df就是一个二维数据表,这个表有行有列有索引
-
DataFrame是Pandas中最基本的数据结构,Series的许多属性和方法在DataFrame中也一样适用.
-
-
创建方式
-
字典方式创建
import pandas as pd dict_data = {'id': [1, 2, 3],'name': ['张三', '李四', '王五'],'age': [18, 20, 22] } # 使用默认自增索引 # 字典中的key值是df对象的列名,value值是对应列的数据值 df1 = pd.DataFrame(data=dict_data) print(df1) print(type(df1)) # 通过index参数指定索引, columns参数指定列的位置 df2 = pd.DataFrame(data=dict_data, index=['A', 'B', 'C'], columns=['id', 'age', 'name']) print(df2) -
列表+元组方式创建
list_data = [(1, '张三', 18),(2, '李四', 20),(3, '王五', 22)] df3 = pd.DataFrame(data=list_data,index=['A', 'B', 'C'], # 手动指定索引columns=['id', 'name', 'age']) # 手动指定列名 print(df3) # 输出结果如下id name age A 1 张三 18 B 2 李四 20 C 3 王五 22
-
2.Series的常用属性
-
常见属性
属性 说明 loc 使用索引值取子集 iloc 使用索引位置取子集 dtype或dtypes Series内容的类型 T Series的转置矩阵 shape 数据的维数 size Series中元素的数量 values Series的值 index Series的索引值 -
代码演示
# 加载数据 import pandas as pd # 读取csv文件, 设置 id列为: 索引列 data = pd.read_csv('data/nobel_prizes.csv', index_col='id') data.head() # 默认值只展示前5行数据 -
loc属性
first_row = data.loc[941] print(first_row) # 获取第一行数据, 但是是以列的方式展示的 print(type(first_row)) # <class 'pandas.core.series.Series'>

-
iloc属性
first_row = data.iloc[0] # 使用索引位置获取自己 print(first_row) # 获取第一行数据, 但是是以列的方式展示的 print(type(first_row)) # <class 'pandas.core.series.Series'> -
dtype 或者 dtypes
print(first_row.dtype) # 打印Series的元素类型, object表示字符串 print(first_row['year'].dtype) # 打印Series的year列的元素类型, int64 # 打印Series的year列的元素类型, 该列值为字符串, 字符串没有dtype属性, 所以报错. print(first_row['firstname'].dtype) -
shape 和 size属性
print(first_row.shape) # 维度 # 结果为: (7,) 因为有7列元素 print(first_row.size) # 元素个数: 7 -
values 属性
print(first_row.values) # 获取Series的元素值 -
index属性
print(first_row.index) # 获取Series的索引 print(first_row.keys()) # Series对象的keys()方法, 效果同上.
3.Series的常用方法
-
常见方法
方法 说明 append 连接两个或多个Series corr 计算与另一个Series的相关系数 cov 计算与另一个Series的协方差 describe 计算常见统计量 drop_duplicates 返回去重之后的Series equals 判断两个Series是否相同 get_values 获取Series的值,作用与values属性相同 hist 绘制直方图 isin Series中是否包含某些值 min 返回最小值 max 返回最大值 mean 返回算术平均值 median 返回中位数 mode 返回众数 quantile 返回指定位置的分位数 replace 用指定值代替Series中的值 sample 返回Series的随机采样值 sort_values 对值进行排序 to_frame 把Series转换为DataFrame unique 去重返回数组 value_counts 统计不同值数量 keys 获取索引值 head 查看前5个值 tail 查看后5个值 -
代码演示
import pandas as pd # 创建s对象 s1 = pd.Series(data=[1, 2, 3, 4, 2, 3], index=['A', 'B', 'C', 'D', 'E', 'F']) # 查看s对象值数量 print(len(s1)) # 查看s对象前5个值, n默认等于5 print(s1.head()) print(s1.head(n=2)) # 查看s对象后5个值, n默认等于5 print(s1.tail()) print(s1.tail(n=2)) # 获取s对象的索引 print(s1.keys()) # s对象转换成python列表 print(s1.tolist()) print(s1.to_list()) # s对象转换成df对象 print(s1.to_frame()) # s对象中数据的基础统计信息 print(s1.describe()) # s对象最大值、最小值、平均值、求和值... print(s1.max()) print(s1.min()) print(s1.mean()) print(s1.sum()) # s对象数据值去重, 返回s对象 print(s1.drop_duplicates()) # s对象数据值去重, 返回数组 print(s1.unique()) # s对象数据值排序, 默认升序 print(s1.sort_values(ascending=True)) # s对象索引值排序, 默认升序 print(s1.sort_index(ascending=False)) # s对象不同值的数量, 类似于分组计数操作 print(s1.value_counts()) -
小案例: 电影数据
# 加载电影数据 movie = pd.read_csv('data/movie.csv') movie.head() # 获取 导演名(列) director = movie.director_name # 导演名 director = movie['director_name'] # 导演名, 效果同上 director # 获取 主演在脸书的点赞数(列) actor_1_fb_likes = movie.actor_1_facebook_likes # 主演在脸书的点赞数 actor_1_fb_likes.head() # 统计相关 director.value_counts() # 不同导演的 电影数 director.count() # 统计非空值(即: 有导演名的电影, 共有多少), 4814 director.shape # 总数(包括null值), (4916,) # 查看详情 actor_1_fb_likes.describe() # 显示主演在脸书点击量的详细信息: 总数,平均值,方差等... director.describe() # 因为是字符串, 只显示部分统计信息
4.Series的布尔索引
从
scientists.csv数据集中,列出大于Age列的平均值的具体值,具体步骤如下:
-
加载并观察数据集
import pandas as pd df = pd.read_csv('data/scientists.csv') print(df) # print(df.head()) # 输出结果如下Name Born Died Age Occupation 0 Rosaline Franklin 1920-07-25 1958-04-16 37 Chemist 1 William Gosset 1876-06-13 1937-10-16 61 Statistician 2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse 3 Marie Curie 1867-11-07 1934-07-04 66 Chemist 4 Rachel Carson 1907-05-27 1964-04-14 56 Biologist 5 John Snow 1813-03-15 1858-06-16 45 Physician 6 Alan Turing 1912-06-23 1954-06-07 41 Computer Scientist 7 Johann Gauss 1777-04-30 1855-02-23 77 Mathematicia # 演示下, 如何通过布尔值获取元素. bool_values = [False, True, True, False, False, False, True, False] df[bool_values] # 输出结果如下Name Born Died Age Occupation 1 William Gosset 1876-06-13 1937-10-16 61 Statistician 2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse 6 Alan Turing 1912-06-23 1954-06-07 41 Computer Scientist -
计算
Age列的平均值# 获取一列数据 df[列名] ages = df['Age'] print(ages) print(type(ages)) print(ages.mean()) # 输出结果如下 0 37 1 61 2 90 3 66 4 56 5 45 6 41 7 77 Name: Age, dtype: int64 <class 'pandas.core.series.Series'> 59.125 -
输出大于
Age列的平均值的具体值print(ages[ages > ages.mean()]) # 输出结果如下 1 61 2 90 3 66 7 77 Name: Age, dtype: int64 -
总结
# 上述格式, 可以用一行代码搞定, 具体如下 df[ages > avg_age] # 筛选(活的)年龄 大于 平均年龄的科学家信息 df[df['Age'] > df.Age.mean()] # 合并版写法.
5.Series的运算
Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算;
两个Series之间计算时,索引值相同的元素之间会进行计算;索引值不同的元素的计算结果会用NaN值(缺失值)填充。
-
Series和数值型变量计算
# 加法 print(ages + 10) # 乘法 print(ages * 2) # 输出结果如下 0 47 1 71 2 100 3 76 4 66 5 55 6 51 7 87 Name: Age, dtype: int64 0 74 1 122 2 180 3 132 4 112 5 90 6 82 7 154 Name: Age, dtype: int64 -
两个Series之间计算时,索引值相同的元素之间会进行计算;索引值不同的元素的计算结果会用NaN值(缺失值)填充
print(ages + ages) print('=' * 20) print(pd.Series([1, 100])) print('=' * 20) print(ages + pd.Series([1, 100])) # 输出结果如下 0 74 1 122 2 180 3 132 4 112 5 90 6 82 7 154 Name: Age, dtype: int64 ==================== 0 1 1 100 dtype: int64 ==================== 0 38.0 1 161.0 2 NaN 3 NaN 4 NaN 5 NaN 6 NaN 7 NaN dtype: float64
6.DataFrame常用属性和方法
-
基础演示
import pandas as pd # 加载数据集, 得到df对象 df = pd.read_csv('data/scientists.csv') print('=============== 常用属性 ===============') # 查看维度, 返回元组类型 -> (行数, 列数), 元素个数代表维度数 print(df.shape) # 查看数据值个数, 行数*列数, NaN值也算 print(df.size) # 查看数据值, 返回numpy的ndarray类型 print(df.values) # 查看维度数 print(df.ndim) # 返回列名和列数据类型 print(df.dtypes) # 查看索引值, 返回索引值对象 print(df.index) # 查看列名, 返回列名对象 print(df.columns) print('=============== 常用方法 ===============') # 查看前5行数据 print(df.head()) # 查看后5行数据 print(df.tail()) # 查看df的基本信息 df.info() # 查看df对象中所有数值列的描述统计信息 print(df.describe()) # 查看df对象中所有非数值列的描述统计信息 # exclude:不包含指定类型列 print(df.describe(exclude=['int', 'float'])) # 查看df对象中所有列的描述统计信息 # include:包含指定类型列, all代表所有类型 print(df.describe(include='all')) # 查看df的行数 print(len(df)) # 查看df各列的最小值 print(df.min()) # 查看df各列的非空值个数 print(df.count()) # 查看df数值列的平均值 print(df.mean()) -
DataFrame的布尔索引
# 小案例, 同上, 主演脸书点赞量 > 主演脸书平均点赞量的 movie[movie['actor_1_facebook_likes'] > movie['actor_1_facebook_likes'].mean()] # df也支持索引操作 movie.head()[[True, True, False, True, False]] -
DataFrame的计算
scientists * 2 # 每个元素, 分别和数值运算 scientists + scientists # 根据索引进行对应运算 scientists + scientists[:4] # 根据索引进行对应运算, 索引不匹配, 返回NAN
7. DataFrame-索引操作
Pandas中99%关于DF和Series调整的API, 都会默认在副本上进行修改, 调用修改的方法后, 会把这个副本返回
这类API都有一个共同的参数: inplace, 默认值是False
如果把inplace的值改为True, 就会直接修改原来的数据, 此时这个方法就没有返回值了
-
通过 set_index()函数 设置行索引名字
# 读取文件, 不指定索引, Pandas会自动加上从0开始的索引 movie = pd.read_csv('data/movie.csv') movie.head() # 设置 电影名 为索引列. movie1 = movie.set_index('movie_title') movie1.head() # 如果加上 inplace=True, 则会修改原始的df对象 movie.set_index('movie_title', inplace=True) movie.head() # 原始的数据并没有发生改变. -
加载数据的时候, 直接指定索引列
-
通过reset_index()函数, 可以重置索引
# 加上inplace, 就是直接修改 源数据. movie.reset_index(inplace=True) movie.head()
8.DataFrame-修改行列索引
-
方式1: rename()函数, 可以对原有的行索引名 和 列名进行修改
movie = pd.read_csv('data/movie.csv', index_col='movie_title') movie.index[:5] # 前5个行索引名 movie.columns[:5] # 前5个列名 # 手动修改下 行索引名 和 列名 idx_rename = {'Avatar': '阿凡达', "Pirates of the Caribbean: At World's End": '加勒比海盗'} col_rename = {'color': '颜色', 'director_name': '导演名'} # 通过rename()函数, 对原有的行索引名 和 列名进行修改 movie.rename(index=idx_rename, columns=col_rename).head() -
方式2:把 index 和 columns属性提取出来, 修改之后, 再赋值回去
index类型不能直接修改,需要先将其转成列表, 修改列表元素, 再整体替换movie = pd.read_csv('data/movie.csv', index_col='movie_title') # 提取出 行索引名 和 列名, 并转成列表. index_list = movie.index.tolist() columns_list = movie.columns.tolist() # 修改列表元素值 index_list[0] = '阿凡达' index_list[1] = '加勒比海盗' columns_list[0] = '颜色' columns_list[1] = '导演名' # 重新把修改后的值, 设置成 行索引 和 列名 movie.index = index_list movie.columns = columns_list # 查看数据 movie.head(5)
9.添加-删除-插入列
-
添加列
movie = pd.read_csv('data/movie.csv') # 通过 df[列名] = 值 的方式, 可以给df对象新增一列, 默认: 在df对象的最后添加一列. movie['has_seen'] = 0 # 新增一列, 表示: 是否看过(该电影) # 新增一列, 表示: 导演和演员 脸书总点赞数 movie['actor_director_facebook_likes'] = (movie['actor_1_facebook_likes'] +movie['actor_2_facebook_likes'] +movie['actor_3_facebook_likes'] +movie['director_facebook_likes'] ) movie.head() # 查看内容 -
删除列 或者 行
# movie.drop('has_seen') # 报错, 需要指定方式, 按行删, 还是按列删. # movie.drop('has_seen', axis='columns') # 按列删 # movie.drop('has_seen', axis=1) # 按列删, 这里的1表示: 列 movie.head().drop([0, 1]) # 按行索引删, 即: 删除索引为0和1的行 -
插入列
有点特殊, 没有inplace参数, 默认就是在原始df对象上做插入的.
# insert() 表示插入列. 参数解释: loc:插入位置(从索引0开始计数), column=列名, value=值 # 总利润 = 总收入 - 总预算 movie.insert(loc=1, column='profit', value=movie['gross'] - movie['budget']) movie.head()

相关文章:
Pandas_数据结构详解
1.创建DataFrame对象 概述 DataFrame是一个表格型的结构化数据结构,它含有一组或多组有序的列(Series),每列可以是不同的值类型(数值、字符串、布尔值等)。 DataFrame是Pandas中的最基本的数据结构对象&am…...

Leetcode 3287. Find the Maximum Sequence Value of Array
Leetcode 3287. Find the Maximum Sequence Value of Array 1. 解题思路2. 代码实现 题目链接:3287. Find the Maximum Sequence Value of Array 1. 解题思路 这一题我的思路比较暴力,就是求出每一个位置前后所有可能的长度为k的子序列的所有的或结果…...

python 山峦图
效果: 代码: import matplotlib.pyplot as plt import numpy as npdef mountain_plot(data_dict, colorsNone):if colors is None:colors get_colors_from_map(len(data_dict), "Spectral")x list(data_dict.keys())# Y轴位置y_positions …...

Open3D:3D数据处理与可视化的强大工具
创作不易,您的打赏、关注、点赞、收藏和转发是我坚持下去的动力! Open3D算法框架简介 Open3D是一个开源的3D数据处理库,旨在为3D数据提供高效、易用的计算和可视化工具。它支持多种3D数据格式,例如点云、网格、RGB-D图像等&…...

YOLOv8改进系列,YOLOv8的Neck替换成AFPN(CVPR 2023)
摘要 多尺度特征在物体检测任务中对编码具有尺度变化的物体非常重要。多尺度特征提取的常见策略是采用经典的自上而下和自下而上的特征金字塔网络。然而,这些方法存在特征信息丢失或退化的问题,影响了非相邻层次的融合效果。一种渐进式特征金字塔网络(AFPN),以支持非相邻…...

BitLocker硬盘加密的详细教程分享
硬盘加密是将数据转换为一种只有授权用户才能读取的形式。通过使用加密算法,硬盘上的数据在存储时被加密,只有输入正确的密钥或密码才能解密和访问这些数据。 硬盘加密的重要性 数据是现代社会的重要资产,保护这些数据免受非法访问和窃取至关…...

YOLOv8的GPU环境搭建方法
首先说明这个环境搭建教程是基于电脑已经安装好CUDA和CUDNN的情况下,去搭建能够正确运行YOLOv8代码的Pytorch的GPU版本。具体安装方法可见:最适合新手入门的CUDA、CUDNN、Pytorch安装教程_cuda安装-CSDN博客 第一步:需要在cmd中创建虚拟环境c…...

JZ2440下载后设置NAND启动文件系统
(一)下载 (二)设置根文件系统NAND FLASH启动 set bootargs noinitrd root/dev/mtdblock3 init/linuxrc consolettySAC0...

AI绘画与摄影新纪元:ChatGPT+Midjourney+文心一格 共绘梦幻世界
文章目录 一、AI艺术的新时代二、ChatGPT:创意的引擎与灵感的火花三、Midjourney:图像生成的魔法与技术的奇迹四、文心一格:艺术的升华与情感的共鸣五、融合创新:AI绘画与摄影实战的无限可能六、应用场景与实践案例AI艺术的美好未…...

金手指设计
"MCP6294"。是一个轨到轨, 带宽为 10MHz 的 低功耗放大器. 对LM358测量 10MHz 范围内的频率特性,在 8MHz 左右,输出相移超过了 180。MCP6294的频率特性,则显示在 10MHz 运放相移之后 100左右。 对比两个运放的频率特性ÿ…...

Chainlit集成LlamaIndex并使用通义千问模型实现AI知识库检索网页对话应用增强版
前言 之前使用Chainlit集成LlamaIndex并使用通义千问大语言模型的API接口,实现一个基于文档文档的网页对话应用。 可以点击我的上一篇文章《Chainlit集成LlamaIndex并使用通义千问模型实现AI知识库检索网页对话应用》 查看。 本次针对上一次的代码功能进一步的完善…...

详解c++菱形继承和多态---下
菱形继承 #include<iostream>using namespace std; class Animal { public:int m_Age; }; class Sheep : public Animal {}; class Tuo : public Animal {}; class SheepTuo : public Sheep, public Tuo {}; void test() {SheepTuo st;st.Sheep::m_Age 18;st.Tuo::m_Age…...

python学习笔记目录
基于windows下docker安装HDDM-CSDN博客 在python中安装HDDM-CSDN博客(这个办法没安装成功)...

非结构化数据中台架构设计最佳实践
在数据驱动的时代背景下,非结构化数据已成为企业决策和运营的重要支撑。非结构化数据中台作为企业数据管理和分析的核心平台,其架构设计对于数据的高效利用和业务的快速发展至关重要。本文将探讨非结构化数据中台架构设计的最佳实践,旨在为企…...

鹏鼎控股社招校招入职SHL综合能力测评:高分攻略及真题题库解析答疑
鹏鼎控股(深圳)股份有限公司,成立于1999年4月29日,是一家专注于印制电路板(PCB)的设计、研发、制造与销售的高新技术企业。公司总部位于中国广东省深圳市,并在全球多个地区设有生产基地和服务中…...
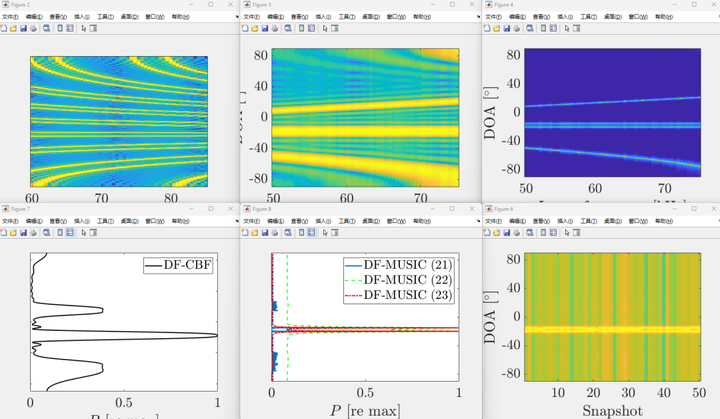
【测向定位】差频MUSIC算法DOA估计【附MATLAB代码】
微信公众号:EW Frontier QQ交流群:554073254 摘要 利用多频处理方法,在不产生空间混叠的情况下,估计出高频区域平面波的波达方向。该方法利用了差频(DF),即两个高频之间的差。这使得能够在可…...

智能车镜头组入门(四)元素识别
元素识别是摄像头部分中难度最大的一部分,也是我花时间最长的一部分,前前后后画了很长时间,最后还是勉勉强强完成了。 基础的元素识别主要有两个:十字,圆环,和斑马线。十字要求直行,圆环需要进…...

Java键盘输入语句
编程输入语句 1.介绍:在编程中,需要接受用户输入的数据,就可以使用键盘输入语句来获取。 2.步骤: 1)导入该类的所在包,java.util.* 2)创建该类对象(声明变量) 3)调用里面的功能 3…...

【读书笔记-《30天自制操作系统》-22】Day23
本篇内容比较简单,集中于显示问题。首先编写了应用程序使用的api_malloc,然后实现了在窗口中画点与画线的API与应用程序。有了窗口显示,还要实现关闭窗口的功能,于是在键盘输入API的基础上实现了按下按键关闭窗口。最后发现用上文…...
)
C++学习笔记(33)
三十五、栈 示例: #include <iostream> using namespace std; typedef int ElemType; // 自定义链栈的数据元素为整数。 struct SNode // 链栈的结点。 { ElemType data; // 存放结点的数据元素。 struct SNode* next; // 指向下一个结点的指针。 }; // 初始化…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

独立开发者如何利用Taotoken的TokenPlan在项目初期有效控制AI实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的TokenPlan在项目初期有效控制AI实验成本 对于独立开发者或学生而言,在构建AI应用原型时&…...

Unity中文语言包安装失败?手动部署全流程详解
1. 为什么Unity编辑器中文语言包总在安装时“卡住”或报错? Unity编辑器自带多语言支持,但中文语言包的安装过程却常年被开发者吐槽——点开Preferences → Localization → Install Language Pack,选中Chinese (Simplified),点击…...