pretrain Llama3
-
导入模块:导入了一些必要的模块,包括数学计算、时间处理、文件操作、深度学习框架(如
torch)、以及自定义的LLama Transformer模型相关内容。 -
I/O配置:定义了模型输出路径、评估与日志记录的间隔步数、批次大小、最大序列长度、词汇表大小等。
-
模型配置:设置了模型的隐藏层维度、层数、注意力头的数量、分组数量、Dropout概率等超参数。
-
AdamW优化器配置:配置了优化器的学习率、权重衰减系数、β1和β2参数、梯度累积步数等,使用梯度累积来模拟更大的批次训练。
-
学习率调度:通过线性预热和余弦衰减方式动态调整学习率,保证训练过程中的学习率变化更加平滑。
-
设备与精度设置:判断设备类型(CPU或GPU),并配置混合精度(FP16)训练相关的上下文。
-
数据加载:定义了批次迭代器
iter_batches,每次从训练集和验证集中加载数据,并准备进行模型的前向和反向传播。 -
模型初始化:通过自定义的Transformer类初始化模型,并使用GradScaler处理混合精度训练时的梯度缩放。
-
损失评估函数
estimate_loss:定义了一个评估函数,在训练过程中定期评估训练和验证集上的损失,并根据损失决定是否保存模型检查点。 -
学习率获取函数
get_lr:实现了学习率的预热和衰减策略,根据当前的迭代步数动态调整学习率。 -
训练循环:
- 按照配置的批次大小从数据加载器中获取数据。
- 进行前向传播,计算损失。
- 进行梯度累积和反向传播。
- 使用梯度裁剪和优化器更新模型参数。
- 根据配置的间隔进行日志记录和损失评估,并保存模型检查点。
- 在迭代次数达到预设的最大值时终止训练。
-
日志记录:在训练过程中,程序会定期输出当前的训练步数、损失值、学习率、运行时间以及模型的浮点运算利用率(MFU,模型浮点计算的利用率,表示模型计算效率)。
-
检查点保存:当验证损失下降时,程序会保存模型的检查点,包括模型的状态、优化器的状态和当前的迭代信息,以便在需要时可以恢复训练。
import math
import os
import time
from contextlib import nullcontext
from datetime import datetime
from functools import partialimport torch
from LLama_content.llama_model import Transformer, ModelArgs
from LLama_content.llama_model import Task# -----------------------------------------------------------------------------
# I/O 配置,用于定义输出目录和训练时的日志记录与评估设置
out_dir = "output" # 模型输出保存路径
eval_interval = 2000 # 评估间隔步数
log_interval = 1 # 日志记录间隔步数
eval_iters = 100 # 每次评估时迭代的步数
eval_only = False # 如果为True,脚本在第一次评估后立即退出
always_save_checkpoint = False # 如果为True,在每次评估后总是保存检查点
init_from = "scratch" # 可以选择从头开始训练('scratch')或从已有的检查点恢复('resume')# 数据配置
batch_size = 128 # 每个微批次的样本数量,如果使用梯度累积,实际批次大小将更大
max_seq_len = 256 # 最大序列长度
vocab_size = 4096 # 自定义词汇表大小# 模型配置
dim = 288 # 模型的隐藏层维度
n_layers = 8 # Transformer的层数
n_heads = 8 # 注意力头的数量
n_group = 4 # 模型分组
multiple_of = 32 # 在某些层的维度必须是该数的倍数
dropout = 0.0 # Dropout概率# AdamW优化器配置
gradient_accumulation_steps = 4 # 梯度累积步数,用于模拟更大的批次
learning_rate = 5e-4 # 最大学习率
max_iters = 100000 # 总的训练迭代次数
weight_decay = 1e-1 # 权重衰减系数
beta1 = 0.9 # AdamW优化器的β1参数
beta2 = 0.95 # AdamW优化器的β2参数
grad_clip = 1.0 # 梯度裁剪阈值,0表示不裁剪# 学习率衰减配置
decay_lr = True # 是否启用学习率衰减
warmup_iters = 1000 # 学习率预热的步数# 系统设置
device = "cuda:0" # 设备选择:'cpu','cuda','cuda:0'等
dtype = "bfloat16" # 数据类型:'float32','bfloat16','float16'# -----------------------------------------------------------------------------
# 获取配置参数的键值对,便于后续的日志记录
config_keys = [kfor k, v in globals().items()if not k.startswith("_") and isinstance(v, (int, float, bool, str))
]
config = {k: globals()[k] for k in config_keys} # 保存配置到字典中,便于日志记录
# -----------------------------------------------------------------------------# 固定一些超参数的默认值
lr_decay_iters = max_iters # 学习率衰减步数,设置为等于最大迭代步数
min_lr = 0.0 # 最小学习率,建议为学习率的十分之一
vocab_source = 'custom' # 词汇表来源
master_process = True # 用于区分主进程
seed_offset = 0 # 随机种子偏移量
ddp_world_size = 1 # 分布式数据并行的世界大小
tokens_per_iter = batch_size * max_seq_len # 每次迭代处理的token数# 设置随机种子,确保可重复性
torch.manual_seed(1337 + seed_offset)
torch.backends.cuda.matmul.allow_tf32 = True # 允许在matmul上使用tf32
torch.backends.cudnn.allow_tf32 = True # 允许在cudnn上使用tf32
device_type = "cuda" if "cuda" in device else "cpu" # 用于自动选择设备类型
ptdtype = torch.float16 # 设置训练时使用的数据类型# 混合精度训练相关
ctx = (nullcontext()if device_type == "cpu"else torch.amp.autocast(device_type=device_type, dtype=ptdtype)
)# task-specific setup
iter_batches = partial(Task.iter_batches,batch_size=batch_size,max_seq_len=max_seq_len,vocab_size=vocab_size,vocab_source=vocab_source,device=device,num_workers=0,
)iter_num = 0
best_val_loss = 1e9# model init
model_args = dict(dim=dim,n_layers=n_layers,n_heads=n_heads,n_group=n_group,vocab_size=vocab_size,multiple_of=multiple_of,max_seq_len=max_seq_len,dropout=dropout,
) # 模型参数初始化# ===========================================================
# 模型初始化
gptconf = ModelArgs(**model_args)
model = Transformer(gptconf)model.to(device)# initialize a GradScaler. If enabled=False scaler is a no-op
scaler = torch.cuda.amp.GradScaler(enabled=(dtype == "float16"))# optimizer
optimizer = model.configure_optimizers(weight_decay, learning_rate, (beta1, beta2), device_type)# 定义eval流程
@torch.no_grad()
def estimate_loss():out = {}model.eval()for split in ["train", "val"]:batch_iter = iter_batches(split=split)losses = torch.zeros(eval_iters) # keep on CPUfor k in range(eval_iters):X, Y = next(batch_iter)with ctx:logits = model(X, Y)loss = raw_model.last_losslosses[k] = loss.item()out[split] = losses.mean()model.train()return out# 定义学习率
def get_lr(it):# 1) linear warmup for warmup_iters stepsif it < warmup_iters:return learning_rate * it / warmup_iters# 2) if it > lr_decay_iters, return min learning rateif it > lr_decay_iters:return min_lr# 3) in between, use cosine decay down to min learning ratedecay_ratio = (it - warmup_iters) / (lr_decay_iters - warmup_iters)assert 0 <= decay_ratio <= 1coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio)) # coeff ranges 0..1return min_lr + coeff * (learning_rate - min_lr)# training loop
train_batch_iter = iter_batches(split="train")
X, Y = next(train_batch_iter) # fetch the very first batch
t0 = time.time()
local_iter_num = 0 # number of iterations in the lifetime of this process
raw_model = model # unwrap DDP container if needed
running_mfu = -1.0
while True:# 或许当前step的学习率lr = get_lr(iter_num) if decay_lr else learning_ratefor param_group in optimizer.param_groups:param_group["lr"] = lr# evaluate the loss on train/val sets and write checkpointsif iter_num % eval_interval == 0 and master_process:losses = estimate_loss()print(f"step {iter_num}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")if losses["val"] < best_val_loss or always_save_checkpoint:best_val_loss = losses["val"]if iter_num > 0:checkpoint = {"model": raw_model.state_dict(),"optimizer": optimizer.state_dict(),"model_args": model_args,"iter_num": iter_num,"best_val_loss": best_val_loss,"config": config,}print(f"saving checkpoint to {out_dir}")torch.save(checkpoint, os.path.join(out_dir, "ckpt.pt"))if iter_num == 0 and eval_only:break# 前向更新过程,使用了梯度累积(检查点)for micro_step in range(gradient_accumulation_steps):with ctx: # 混合精度相关logits = model(X, Y)loss = raw_model.last_lossloss = loss / gradient_accumulation_stepsX, Y = next(train_batch_iter)# 反向传播scaler.scale(loss).backward()# 梯度阶段if grad_clip != 0.0:scaler.unscale_(optimizer)torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip)# step the optimizer and scaler if training in fp16scaler.step(optimizer)scaler.update()# flush the gradients as soon as we can, no need for this memory anymoreoptimizer.zero_grad(set_to_none=True)# timing and loggingt1 = time.time()dt = t1 - t0t0 = t1if iter_num % log_interval == 0 and master_process:# get loss as float, scale up due to the divide above. note: this is a CPU-GPU sync pointlossf = loss.item() * gradient_accumulation_stepsif local_iter_num >= 5: # let the training loop settle a bitmfu = raw_model.estimate_mfu(batch_size * gradient_accumulation_steps, dt)running_mfu = mfu if running_mfu == -1.0 else 0.9 * running_mfu + 0.1 * mfuprint(f"{iter_num} | loss {lossf:.4f} | lr {lr:e} | {dt*1000:.2f}ms | mfu {running_mfu*100:.2f}%" # mfu表示模型浮点运算利用率)iter_num += 1local_iter_num += 1# termination conditionsif iter_num > max_iters:break0 | loss 8.3757 | lr 0.000000e+00 | 36663.83ms | mfu -100.00%
1 | loss 8.3732 | lr 5.000000e-07 | 1476.33ms | mfu -100.00%
2 | loss 8.3785 | lr 1.000000e-06 | 1700.56ms | mfu -100.00%
3 | loss 8.3699 | lr 1.500000e-06 | 1702.70ms | mfu -100.00%
4 | loss 8.3650 | lr 2.000000e-06 | 1697.50ms | mfu -100.00%
5 | loss 8.3470 | lr 2.500000e-06 | 1703.32ms | mfu 1.38%
6 | loss 8.3465 | lr 3.000000e-06 | 1704.92ms | mfu 1.38%
7 | loss 8.3269 | lr 3.500000e-06 | 1701.99ms | mfu 1.38%
8 | loss 8.3189 | lr 4.000000e-06 | 1700.86ms | mfu 1.38%
9 | loss 8.2904 | lr 4.500000e-06 | 1700.20ms | mfu 1.38%
10 | loss 8.2730 | lr 5.000000e-06 | 1702.60ms | mfu 1.38%
11 | loss 8.2581 | lr 5.500000e-06 | 1700.75ms | mfu 1.38%
12 | loss 8.2332 | lr 6.000000e-06 | 1703.53ms | mfu 1.38%
13 | loss 8.2065 | lr 6.500000e-06 | 1718.47ms | mfu 1.38%
14 | loss 8.1800 | lr 7.000000e-06 | 1707.27ms | mfu 1.38%
15 | loss 8.1510 | lr 7.500000e-06 | 1716.64ms | mfu 1.38%
16 | loss 8.1214 | lr 8.000000e-06 | 1721.91ms | mfu 1.38%
17 | loss 8.0870 | lr 8.500000e-06 | 1721.15ms | mfu 1.38%
18 | loss 8.0530 | lr 9.000000e-06 | 1721.06ms | mfu 1.38%
19 | loss 8.0241 | lr 9.500000e-06 | 1733.10ms | mfu 1.37%
20 | loss 7.9939 | lr 1.000000e-05 | 1729.06ms | mfu 1.37%
21 | loss 7.9736 | lr 1.050000e-05 | 1727.64ms | mfu 1.37%
22 | loss 7.9490 | lr 1.100000e-05 | 1734.65ms | mfu 1.37%
23 | loss 7.9211 | lr 1.150000e-05 | 1731.17ms | mfu 1.37%
24 | loss 7.8911 | lr 1.200000e-05 | 1731.48ms | mfu 1.37%
25 | loss 7.8686 | lr 1.250000e-05 | 1736.57ms | mfu 1.37%
26 | loss 7.8458 | lr 1.300000e-05 | 1726.87ms | mfu 1.37%
27 | loss 7.8293 | lr 1.350000e-05 | 1724.82ms | mfu 1.37%
28 | loss 7.8036 | lr 1.400000e-05 | 1720.08ms | mfu 1.37%
29 | loss 7.8019 | lr 1.450000e-05 | 1732.76ms | mfu 1.36%
30 | loss 7.7791 | lr 1.500000e-05 | 1730.16ms | mfu 1.36%
31 | loss 7.7619 | lr 1.550000e-05 | 1724.99ms | mfu 1.36%
32 | loss 7.7674 | lr 1.600000e-05 | 1741.93ms | mfu 1.36%
33 | loss 7.7393 | lr 1.650000e-05 | 1741.69ms | mfu 1.36%
34 | loss 7.7329 | lr 1.700000e-05 | 1739.45ms | mfu 1.36%
35 | loss 7.7254 | lr 1.750000e-05 | 1742.96ms | mfu 1.36%
36 | loss 7.7207 | lr 1.800000e-05 | 1744.78ms | mfu 1.36%
37 | loss 7.7090 | lr 1.850000e-05 | 1745.76ms | mfu 1.36%
38 | loss 7.7068 | lr 1.900000e-05 | 1755.41ms | mfu 1.36%
39 | loss 7.6913 | lr 1.950000e-05 | 1751.07ms | mfu 1.35%
40 | loss 7.6824 | lr 2.000000e-05 | 1760.08ms | mfu 1.35%
41 | loss 7.6860 | lr 2.050000e-05 | 1764.52ms | mfu 1.35%
42 | loss 7.6879 | lr 2.100000e-05 | 1759.85ms | mfu 1.35%
43 | loss 7.6856 | lr 2.150000e-05 | 1773.77ms | mfu 1.35%
44 | loss 7.6762 | lr 2.200000e-05 | 1778.94ms | mfu 1.34%
45 | loss 7.6797 | lr 2.250000e-05 | 1781.31ms | mfu 1.34%
46 | loss 7.6697 | lr 2.300000e-05 | 1772.70ms | mfu 1.34%
47 | loss 7.6638 | lr 2.350000e-05 | 1775.44ms | mfu 1.34%
48 | loss 7.6535 | lr 2.400000e-05 | 1778.56ms | mfu 1.34%
49 | loss 7.6516 | lr 2.450000e-05 | 1780.90ms | mfu 1.34%
50 | loss 7.6531 | lr 2.500000e-05 | 1776.91ms | mfu 1.33%
51 | loss 7.6512 | lr 2.550000e-05 | 1769.89ms | mfu 1.33%
52 | loss 7.6373 | lr 2.600000e-05 | 1775.77ms | mfu 1.33%
53 | loss 7.6428 | lr 2.650000e-05 | 1784.00ms | mfu 1.33%
54 | loss 7.6320 | lr 2.700000e-05 | 1780.11ms | mfu 1.33%
55 | loss 7.6242 | lr 2.750000e-05 | 1784.60ms | mfu 1.33%
56 | loss 7.6152 | lr 2.800000e-05 | 1788.55ms | mfu 1.33%
57 | loss 7.6133 | lr 2.850000e-05 | 1778.49ms | mfu 1.33%
58 | loss 7.6066 | lr 2.900000e-05 | 1779.38ms | mfu 1.33%
59 | loss 7.6035 | lr 2.950000e-05 | 1783.05ms | mfu 1.33%
60 | loss 7.5961 | lr 3.000000e-05 | 1786.11ms | mfu 1.33%
61 | loss 7.5854 | lr 3.050000e-05 | 1779.18ms | mfu 1.32%
62 | loss 7.5616 | lr 3.100000e-05 | 1781.52ms | mfu 1.32%
63 | loss 7.5642 | lr 3.150000e-05 | 1780.07ms | mfu 1.32%
64 | loss 7.5492 | lr 3.200000e-05 | 1783.43ms | mfu 1.32%
65 | loss 7.5362 | lr 3.250000e-05 | 1779.71ms | mfu 1.32%
66 | loss 7.5173 | lr 3.300000e-05 | 1783.60ms | mfu 1.32%
67 | loss 7.4988 | lr 3.350000e-05 | 1786.05ms | mfu 1.32%
68 | loss 7.4706 | lr 3.400000e-05 | 1780.08ms | mfu 1.32%
69 | loss 7.4393 | lr 3.450000e-05 | 1785.92ms | mfu 1.32%
70 | loss 7.4272 | lr 3.500000e-05 | 1781.09ms | mfu 1.32%
71 | loss 7.3885 | lr 3.550000e-05 | 1784.05ms | mfu 1.32%
72 | loss 7.3811 | lr 3.600000e-05 | 1784.42ms | mfu 1.32%
73 | loss 7.3529 | lr 3.650000e-05 | 1789.80ms | mfu 1.32%
74 | loss 7.3472 | lr 3.700000e-05 | 1779.04ms | mfu 1.32%
75 | loss 7.3249 | lr 3.750000e-05 | 1786.06ms | mfu 1.32%
76 | loss 7.3031 | lr 3.800000e-05 | 1779.51ms | mfu 1.32%
77 | loss 7.2921 | lr 3.850000e-05 | 1783.96ms | mfu 1.32%
78 | loss 7.2693 | lr 3.900000e-05 | 1775.51ms | mfu 1.32%
79 | loss 7.2408 | lr 3.950000e-05 | 1779.59ms | mfu 1.32%
80 | loss 7.2256 | lr 4.000000e-05 | 1783.40ms | mfu 1.32%
81 | loss 7.2261 | lr 4.050000e-05 | 1780.04ms | mfu 1.32%
82 | loss 7.1853 | lr 4.100000e-05 | 1781.24ms | mfu 1.32%
83 | loss 7.1707 | lr 4.150000e-05 | 1775.67ms | mfu 1.32%
84 | loss 7.1402 | lr 4.200000e-05 | 1783.91ms | mfu 1.32%
85 | loss 7.1046 | lr 4.250000e-05 | 1780.41ms | mfu 1.32%
86 | loss 7.1195 | lr 4.300000e-05 | 1780.56ms | mfu 1.32%
87 | loss 7.0987 | lr 4.350000e-05 | 1779.48ms | mfu 1.32%
88 | loss 7.0582 | lr 4.400000e-05 | 1780.50ms | mfu 1.32%
89 | loss 7.0510 | lr 4.450000e-05 | 1781.78ms | mfu 1.32%
90 | loss 7.0386 | lr 4.500000e-05 | 1778.67ms | mfu 1.32%
91 | loss 7.0191 | lr 4.550000e-05 | 1783.66ms | mfu 1.32%
92 | loss 7.0163 | lr 4.600000e-05 | 1781.06ms | mfu 1.32%
93 | loss 6.9911 | lr 4.650000e-05 | 1782.13ms | mfu 1.32%
94 | loss 6.9513 | lr 4.700000e-05 | 1782.88ms | mfu 1.32%
95 | loss 6.9741 | lr 4.750000e-05 | 1773.50ms | mfu 1.32%
96 | loss 6.9196 | lr 4.800000e-05 | 1781.74ms | mfu 1.32%
97 | loss 6.9085 | lr 4.850000e-05 | 1787.56ms | mfu 1.32%
98 | loss 6.9231 | lr 4.900000e-05 | 1776.59ms | mfu 1.32%
99 | loss 6.8738 | lr 4.950000e-05 | 1779.54ms | mfu 1.32%
100 | loss 6.8620 | lr 5.000000e-05 | 1782.77ms | mfu 1.32%
相关文章:

pretrain Llama3
导入模块:导入了一些必要的模块,包括数学计算、时间处理、文件操作、深度学习框架(如torch)、以及自定义的LLama Transformer模型相关内容。 I/O配置:定义了模型输出路径、评估与日志记录的间隔步数、批次大小、最大序…...

[附源码]SpringBoot+VUE+Java实现人脸识别系统
今天带来一款优秀的项目:java人脸识别系统源码 。 系统采用的流行的前后端分离结构,内含功能包括 “人脸数数据录入”,“人脸管理”,“摄像头识别” 如果您有任何问题,也请联系小编,小编是经验丰富的程序员…...

数据库_解决SQL Server数据库log日志过大,清理日志文件方法
SQL Server数据库日志文件过大的原因主要有几个方面: 事务日志记录了所有对数据库进行修改的操作,如插入、更新和删除,这些操作会不断增加日志文件的大小。 长时间运行且未正确结束的事务会持续占用事务日志中的空间,导致日志文…...

引领长期投资新篇章:价值增长与财务安全的双重保障
随着全球金融市场的不断演变,长期投资策略因其稳健性和对价值增长的显著推动作用而日益受到投资者的重视。在这一背景下,Zeal Digital Shares(ZDS)项目以其创新的数字股票产品,为全球投资者提供了一个全新的长期投资平…...

灾备技术演进之路 | 虚拟化无代理备份只能挂载验证和容灾吗?只能无代理恢复吗?且看科力锐升级方案
灾备技术演进之路系列 虚拟化备份技术演进 摆脱束缚,加速前行 无代理备份仅能挂载/恢复验证吗? ——科力锐极简验证演练无代理备份来了 无代理备份无法应对平台级故障吗? ——科力锐应急接管无代理备份来了 无代理备份仅能同平台挂载吗&a…...

PowerShell install 一键部署Oracle23ai
Oracle23ai前言 Oracle Database 23ai Free 让您可以充分体验 Oracle Database 的能力,世界各地的企业都依赖它来处理关键任务工作负载。 Oracle Database Free 的资源限制为 2 个 CPU(前台进程)、2 GB 的 RAM 和 12 GB 的磁盘用户数据。该软件包不仅易于使用,还可轻松下载…...
)
【Kubernetes】常见面试题汇总(二十五)
目录 73.我们所有人都知道,从单片到微服务的转变解决了开发方面的问题,但却增加了部署方面的问题。公司如何解决部署方面的问题? 74.考虑一家拼车公司希望通过同时扩展其平台来增加服务器数量,公司如何有效地实现这种资源分配? …...

【踩坑】装了显卡,如何让显示器从主板和显卡HDMI都输出
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 背景介绍 装了显卡后,开机默认是从显卡的HDMI输出,但这很不方便。如何让视频仍然从主板输出?或者说让显卡HDMI和主板…...

spring boot启动报错:so that it conforms to the canonical names requirements
springboot 2.x的版本中对配置文件中的命名规范有了强制性的要求,如下图所示中的dataSource属性属于驼峰格式,但是在springboot 2.x中不允许使用驼峰形式。 根据错误提示可知将其使用 - 来分割即可 错误信息的含义:“Canonical names should…...

unix中如何查询和修改进程的资源限制
一、前言 一个进程在运行时,会用到各种资源,比如cpu的使用时间、内存空间、文件等等。那么,一个进程能够占用多少资源呢?cpu使用的时间有多长?进程空间有多大?能够创建多少个文件?这个就是本文…...

【LeetCode每日一题】——401.二进制手表
文章目录 一【题目类别】二【题目难度】三【题目编号】四【题目描述】五【题目示例】六【题目提示】七【解题思路】八【时间频度】九【代码实现】十【提交结果】 一【题目类别】 回溯 二【题目难度】 简单 三【题目编号】 401.二进制手表 四【题目描述】 二进制手表顶部…...

ROM和RAM的区别
ROM(Read-Only Memory,只读存储器)和RAM(Random Access Memory,随机存取存储器)是计算机系统中两种不同类型的存储技术,它们在功能、用途和特性上有显著的区别: 1. 存储数据的持久性…...

tomcat的配置
tomcat8最佳配置 <Executor name"tomcatThreadPool" namePrefix"catalina-exec-"maxThreads"500" minSpareThreads"100" prestartminSpareThreads"true"/><Connector executor"tomcatThreadPool" port&…...

SQL使用IN进行分组统计时如何将不存在的字段显示为0
这两天被扔过来一个脏活儿:做一个试点运行系统的运营指标统计。 活儿之所以称为“脏”,是因为要统计8家单位共12个项目的指标。而每个项目有3个用户类指标,以及分17个功能模块,每个功能模块又分5个维度的指标。也就是单个项目是1…...

MoCo对比损失
MoCo(Momentum Contrast,动量对比学习)是一种自监督学习方法,由Facebook AI Research提出,主要用于无监督学习视觉表示。在MoCo中,对比损失(Contrastive Loss)扮演着至关重要的角色&…...

01_WebRtc_一对一视频通话
文章目录 通话网页的设计客户端实现Web的API 服务端实现 2024-9-20 很久没有写博客啦,回顾总结这段时间的成果, 写下博客放松下(开始偷懒啦)主要内容:实现网页(html)打开摄像头并显示到页面需要…...

【小程序 - 大智慧】深入微信小程序的渲染周期
目录 前言应用生命周期页面的生命周期组件的生命周期渲染顺序页面路由运行机制更新机制同步更新异步更新 前言 跟 Vue、React 框架一样,微信小程序框架也存在生命周期,实质也是一堆会在特定时期执行的函数。 小程序中,生命周期主要分成了三…...

《深入了解 Linux 操作系统》
在计算机领域中,Linux 作为一种强大而重要的操作系统,有着广泛的应用场景,尤其在服务器端占据着举足轻重的地位。 一、Linux 简介 Linux 是一种操作系统,主要应用于服务器端。不同的厂商或个人会对 Linux 的内核进行封装ÿ…...

批评他人也需要技术
俗话说“人无完人,尺有所短,寸有所长”,每个人都有可能犯错误。我们犯错误,并不能说明我们一无是处;一个人做了一件好事,也不能说他做的每件事都是好的。 营造良好的氛围。一说到批评,我们许多…...
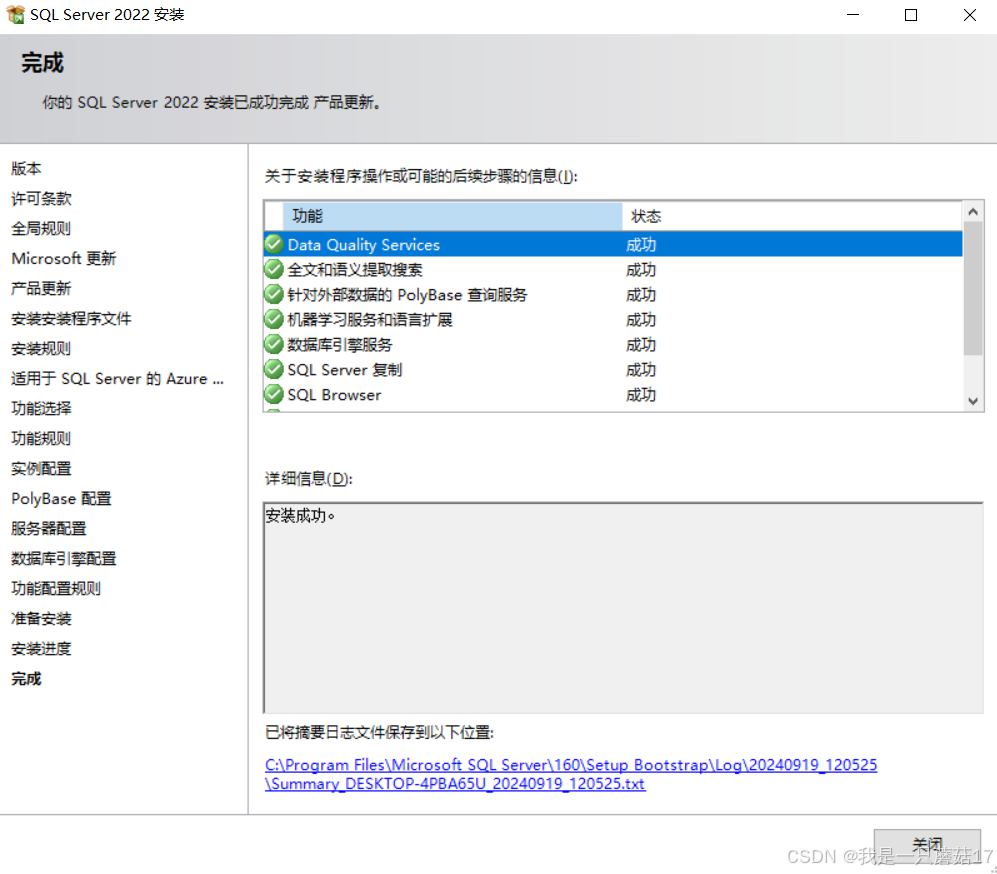
安装SQL Server遇到的问题
出现了一和二的问题,最后还是通过三完全卸载sqlserver安装成功了 一.安装过程中依次报错 1.MOF编译器无法连接WMI服务器。原因可能是语义错误(例如,与现有WMI知识库不兼容)或实际错误(例如WMI服务器启动失败)。 2.PerfLib 2.0计数器removal失败…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

CANN-昇腾NPU-RAG推理-检索增强生成怎么部署
RAG(Retrieval-Augmented Generation)是 LLM 知识库的组合:先检索相关文档,再让 LLM 基于文档回答。昇腾NPU 上部署 RAG 需要两个组件:Embedding 模型(做向量检索)和 LLM(做生成&am…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

AI算力要上天?别笑,太空数据中心真能干翻地球电费!
前言你有没有算过,训练一个大模型,相当于烧掉多少吨煤?如今AI狂飙突进,算力需求指数级增长,可地球上的电——不够用了!更别说建个数据中心还得跟地方政府“斗智斗勇”,抢地皮、配储能、扛审批&a…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...

如何快速解锁中兴光猫权限:zteOnu工具完整使用指南
如何快速解锁中兴光猫权限:zteOnu工具完整使用指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 中兴光猫作为家庭网络的核心设备,其强大的硬件性能常常被默认…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...