MySQL索引知识个人笔记总结(持续整理)
本篇笔记是个人整理的索引知识总结,刚开始有点乱,后续会一直边学边整理边总结
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。就好比索引就是数据的目录
B+tree索引,Hash索引,Full-text索引,R-tree(空间索引)
创建的主键索引和二级索引默认使用的是B+Tree索引。B+tree是一种多叉树,叶子结点才存放数据,非叶子结点只存放索引,(有根节点和其他不是叶子结点的结点),而且每个结点里的数据是按主键顺序存放的。
每一层 父结点的索引值 都会出现在下层子结点的索引值中
因此在叶子结点中,包括了所有的索引值信息
并且每个叶子结点都有两个指针,分别指向下一个叶子结点和上一个叶子结点,形成双向链表
物理存储: 聚集索引,二级索引

有了主键索引为什么还要有二级索引?
二级索引里面,他存储的是主键值,所以先去二级索引里面查找这个主键值,然后再通过这个主键值,去一级索引查找他的实际数据,因为一级索引(主键索引)里面存储的是主键数据
主键索引的B+tree叶子结点 存放的是实际数据,所有完整的用户存放在主键索引的B+tree的叶子结点里
二级索引的B+tree的叶子结点 存放的是主键值,而不是实际数据
回表是什么?

字段特性:主键,唯一,普通,前缀索引
主键索引:就是建立在主键字段上的索引,通常在创建表的时候一起创建 一张表最多只有一个主键索引
唯一索引:建立在union字段上的索引,一张表可以有多个唯一索引 (每个唯一索引可以用于不同的列或列的组合,确保这些列或列组的值唯一) 索引列的值必须唯一(这意味着在索引列中不能存在两个完全相同的值),但是允许有空值
普通索引:建立在普通字段上的索引 不要求字段为主键 也不要求字段为unique
前缀索引:使用它的目的是 减少索引占用的存储空间 提升查询效率
字段个数分类:单列索引,联合索引
单列就是建立在单列上的索引 比如主键
联合就是建立在多列
联合索引:通过将多个字段组合成一个索引
联合索引 他的非叶子结点用两个字段的值作为B+tree的key值,当在联合索引查询数据的时候,先按product_no字段比较
这里不懂什么意思了
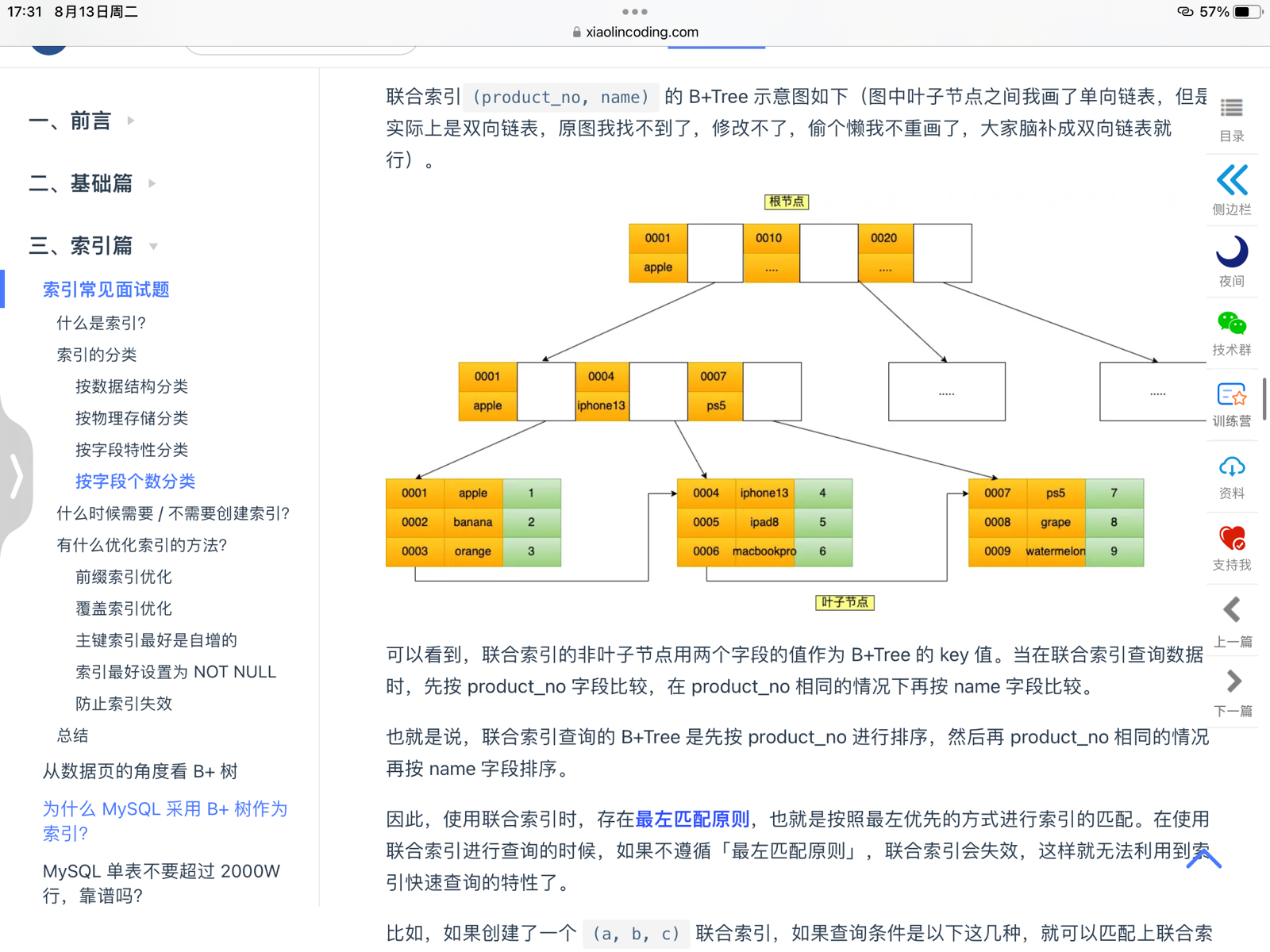
联合索引范围查询
他里面有一些特殊情况,不是查询过程中使用了联合索引查询查询,就代表联合索引中的所有字段 都用到了联合索引进行索引查询(就是不能以偏盖全!!)
联合索引存在最左匹配原则,最左匹配原则就是按照最左优先的方式进行索引的匹配。
使用联合索引的时候 不遵循这个原则,那就会失效,就不能利用索引快速查询了

看这个例子,第一个例子是可以匹配上联合索引的,第二个例子匹配不上联合索引。
因为第一个,是先按a排序,a相同再按b排序,b相同再按c排序。
第二个直接跳过a,直接跳过那,就没有最左优先,就不符合最左匹配原则,那联合索引就会失效。
b和c是全局无序,局部相对有序的,(意思就是b,c这个在局部是有序的,但他前面的a没有,那就全局无序)
看图,看第二个字段,a,b,o,I,I,m,p,g,w他没有按26个字母顺序排序的,他是无序的。在a的基础上建立索引,

a是全局有序的(1,2,2,3,4,5,6,7,8) b是全局无序的(12,7,8,2,3,8,10,5,2)直接执行where b = 2无法利用联合索引
利用索引的前提:索引里的key是有序的
无序你怎么查,乱查,要是数据那么多,直接扔进去查效率会很低
联合索引范围查询
就上面说的那个特殊情况,不是查询过程中使用了联合索引查询查询,就代表联合索引中的所有字段 都用到了联合索引进行索引查询(就是不能以偏盖全!!)也可能存在部分字段用到联合索引的B+tree,部分字段没有用到
这特殊情况 发生在范围查询。
就联合索引的最左匹配原则会一直向右匹配,(就是从最左依次向右),,直到遇到 范围查询 ,就会停止匹配。
就是说:范围查询的字段,可以用到联合索引(比如a>1),但是在范围查询字段的后面的字段就无法用到联合索引(比如b=2)
联合索引(二级索引??)先按照a字段的值排序的,符合a
这个又是什么玩意?
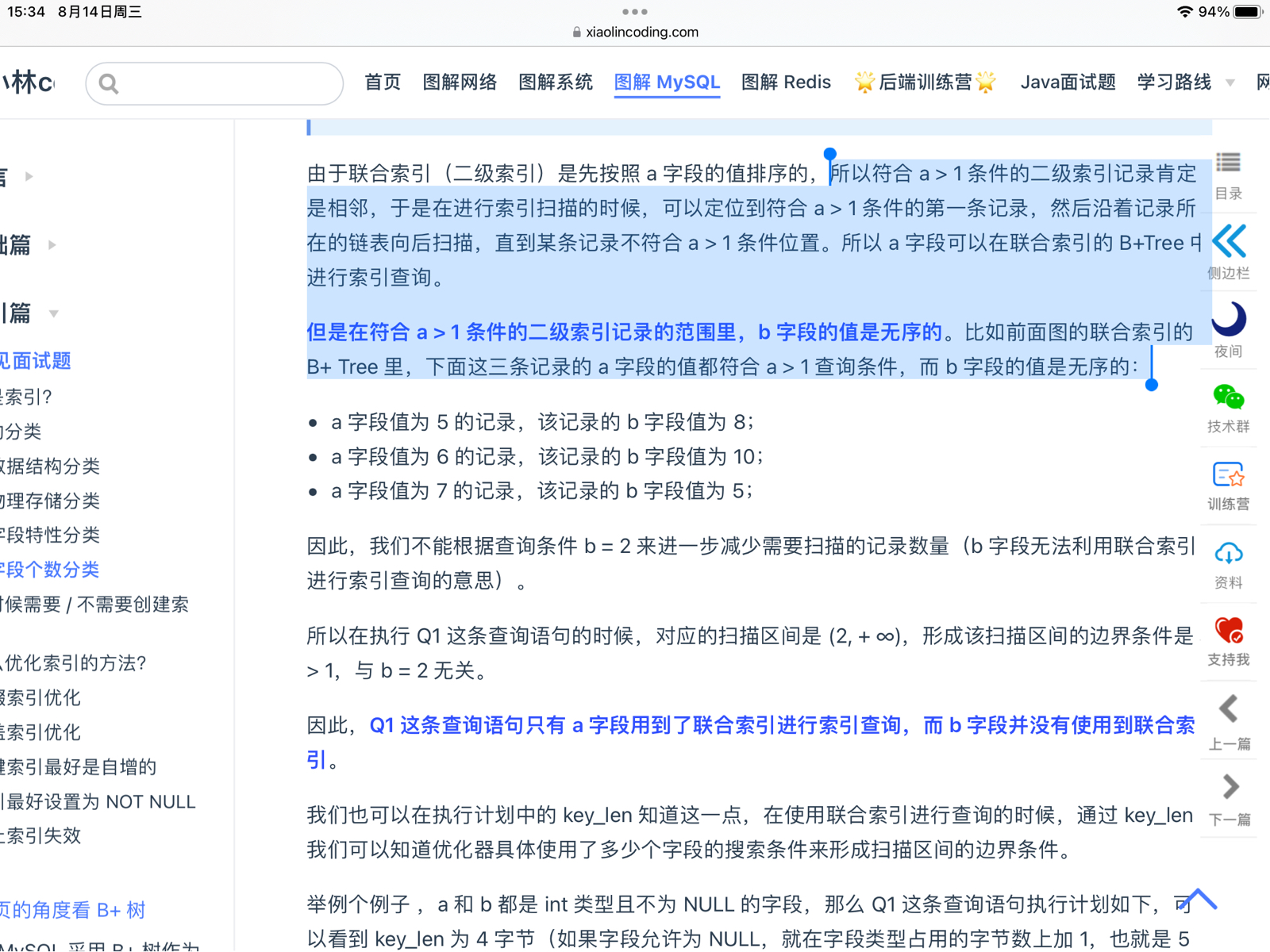
额Q1这条语句,他a>1这个字段用到了联合索引,b=2没有用到。
在a>1条件的二级索引记录的范围里,b字段的值是无序的
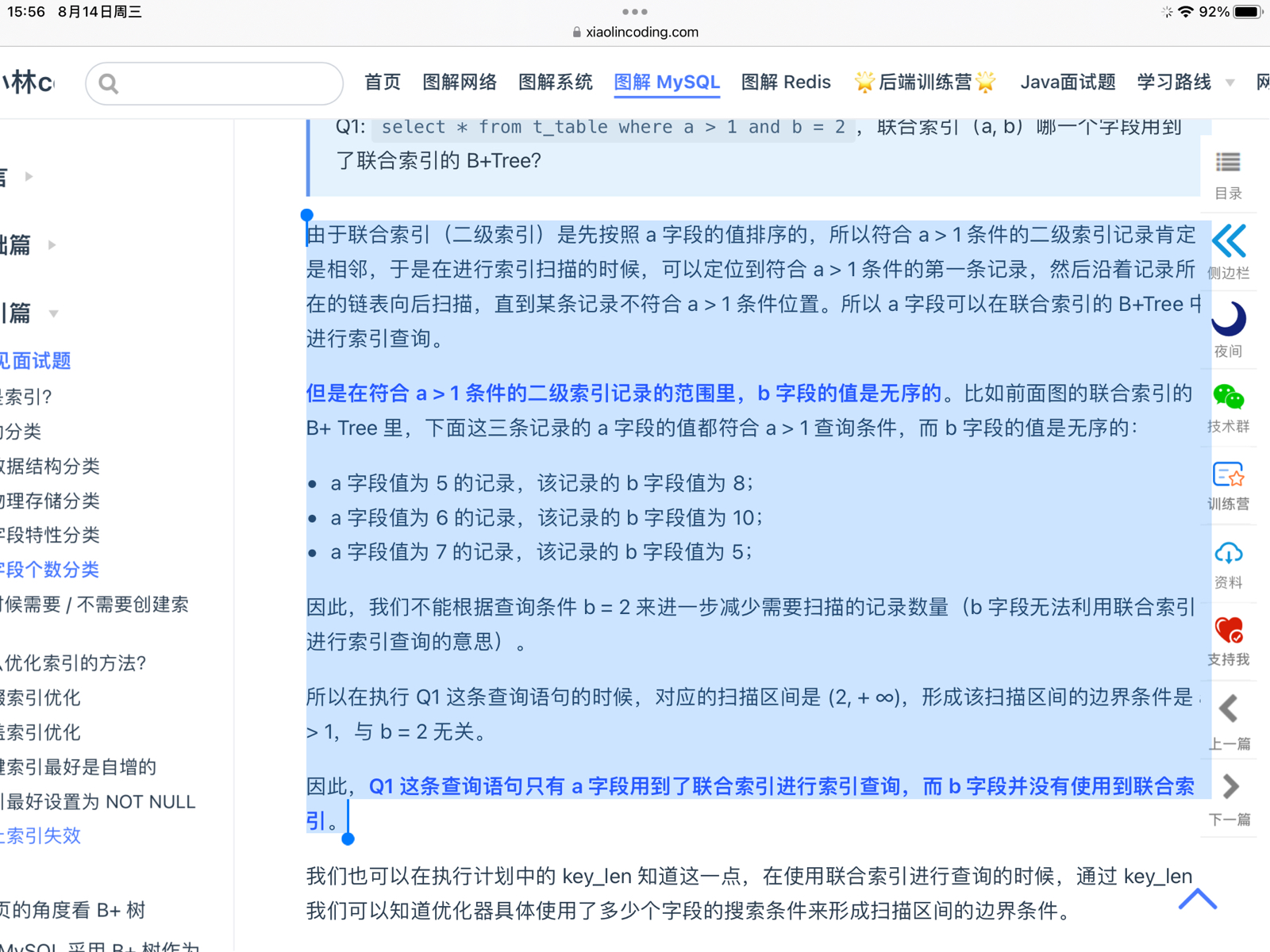
这段话说明了:为什么在这个查询中,b 字段的条件无法利用联合索引来加速查询?我的理解:
联合索引会按照索引列的顺序对数据进行排序。
比如有一个表中有两个字段a和b,你对这两个字段建立了联合索引(a, b),那么数据库会首先根据a字段的值进行排序
如果a字段的值相同,再根据b字段的值进行排序。
索引扫描与查询条件:
假设你查询a > 1的记录,数据库可以快速找到第一个满足a > 1的记录,并从该位置开始顺序扫描其他记录。
由于数据在a字段上是排序的,数据库可以高效地定位到第一个符合条件的记录。
b字段的无序性:
在a > 1的查询范围内,b字段的值是无序的。即使你在查询中增加条件b = 2,也无法进一步缩小扫描的范围。
这是因为虽然a字段在索引中是有序的,但在a > 1的范围内,b字段的值并不是按照b字段的顺序排列的。 就是说这个b=2与这个a>1无瓜。。。
因此,在这种情况下,b字段的索引无法被有效利用,数据库仍然需要扫描所有a > 1范围内的记录,检查每条记录的b值是否等于2。
数据库首先根据a > 1的条件,找到满足该条件的记录,也就是上面的三条记录:
a = 5, b = 8
a = 6, b = 10
a = 7, b = 5
但是,b字段的值在这些记录中是无序的(8、10、5)这个一看既不是连续的也不是什么升序降序。因此,尽管我们加了b = 2的条件,但是 但是 b字段在满足a>1的这些记录中是无序的,上面说过
即使 你加了这个什么b=2的条件,数据库还是要逐条扫描 这些记录来检查b字段的值
具体来说,数据库会这样执行查询:
首先定位到第一个满足 a > 1 的记录(a = 5, b = 8)。
然后继续顺序扫描接下来的记录(a = 6, b = 10 和 a = 7, b = 5)。
每扫描到一条记录,数据库都会检查 b 字段的值是否等于 2。
因为b字段的值是无序的,数据库无法跳过任何记录,所以必须扫描所有满足a>1的记录。
因为b字段的值是无序的,数据库无法跳过任何记录???为什么?
因为在联合索引中,数据首先根据第一个字段(如 a 字段)排序,而第二个字段(如 b 字段)只在前一个字段相同的情况下才有序。(这个上面有一直在说)
当你在联合索引 (a, b) 上执行查询时,如果你的查询条件是 a > 1 AND b = 2,数据库会首先利用 a 字段来定位满足 a > 1 的记录。然而,由于联合索引首先是根据 a 字段排序的,所以在 a > 1 的范围内,b 字段的值并没有按照特定顺序排列。这意味着数据库无法预先知道哪些记录的 b 字段等于 2,因此它无法直接跳到这些记录。
就是说b=2他不在范围查询a>1的这个范围内,所以就无法直接跳到这些记录
具体原因如下:
索引的有序性:
联合索引 (a, b) 按照 a 字段的顺序排列记录。如果 a 字段的值不同,b 字段的顺序是无关紧要的,因此在不同的 a 值下,b 字段的值不会有序排列。(a都不相同了那b更无所谓了)
全扫描的必要性:
当数据库在满足 a > 1 的记录中查找 b = 2 时,因为 b 字段在这些记录中是无序的,数据库无法通过索引直接跳过不符合条件的记录。它必须逐条扫描每一条满足 a > 1 的记录,检查 b 字段是否等于 2。
缺少有序条件:
如果 b 字段的值在 a > 1 的范围内是有序的,数据库就可以利用二分查找等高效算法直接跳过不符合 b = 2 条件的记录。但是由于无序性,数据库只能通过顺序扫描来找到匹配的记录。
举个例子
假设联合索引 (a, b) 中有如下记录:
a b
5 8
6 10
7 5
8 2
9 3
当你查询 a > 5 AND b = 2 时,数据库会先定位到 a = 6 开始的记录。因为 b 字段在这些记录中是无序的,数据库必须检查 a = 6、a = 7、a = 8 的所有记录,直到找到 b = 2 的记录(在 a = 8 时)。就是在a>5之后找,找到与b=2对应的那个a
如果 b 字段在 a > 5 范围内是有序的,数据库就可以直接跳到 b = 2 的记录,而不必扫描之前的所有记录。但因为无序性,数据库没有办法这样做,只能逐条检查。
执行计划中的key_len:
通过key_len我们可以知道优化器具体使用了多少个字段的搜索条件来形成扫描区间的边界条件
如果 key_len显示使用了两个字段(如 a 和 b),这意味着查询条件中的这两个字段都被用来形成索引扫描的边界条件,进一步缩小扫描范围,提高查询效率。

对这里举的这个例子的理解:
首先前提是a和b都是int类型的非null的字段。
联合索引:idx_ab 是一个联合索引,包含了两个字段 a 和 b。
key_len:这是一个表示数据库查询计划中索引长度的参数。对于 int类型的字段,通常占用 4 个字节。如果字段允许为 NULL,则需要增加 1 个字节用于存储 NULL 的信息,所以可能占用 5 个字节。
这里查询显示key_len为4字节:意味着在这个查询中,数据库仅使用了联合索引的a字段
(a是int,占用4字节的空间,b也使用索引,那么总的就是8个字节,但是这里key_len只是4字节!!!按照最左前缀匹配原则,所以只使用了a字段)
来到Q2语句,Q2语句和Q1语句唯一的区别就是:大于和大于等于的区别
在之前a>1 的时候,b=2是无序的,但是现在a>=1,这里面包含了a=1,对于符合a=1 夜间的二级索引记录的范国里,b字段的值是「有序」的(因为对于联合索引,是先按照 a字段的值排序,然后在a字段的值相同的情况下,再按照b字段的值进行排序)(联想到这个最左匹配原则去思考问题)
Q2这条语句a>=1和b=2都用到了联合索引
这里是一些分析:
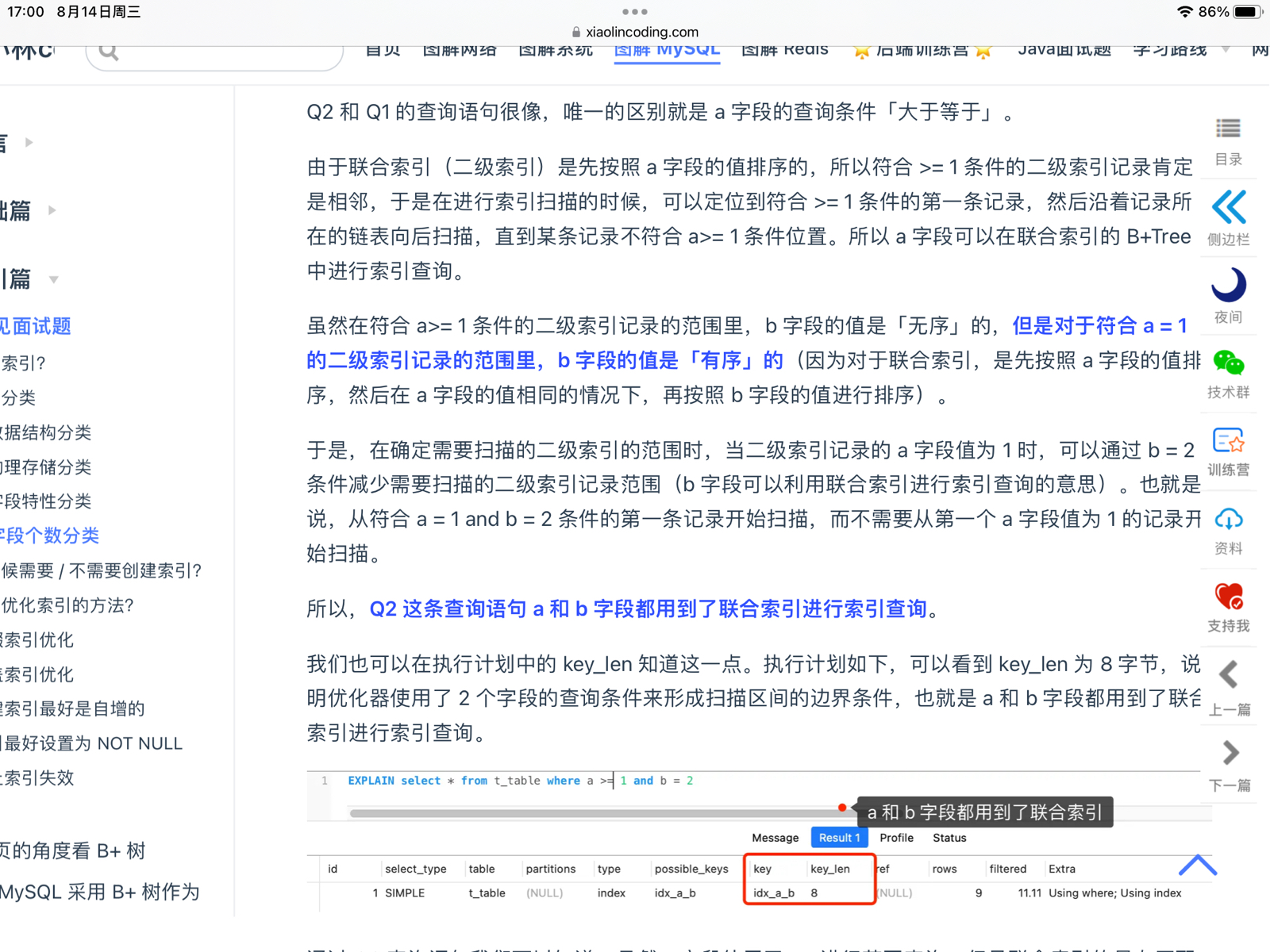
a字段的索引利用:
定位首条记录:当你使用 a >= 1的条件时,数据库可以利用 a 字段在联合索引中的排序顺序,直接跳到符合条件的第一条记录,然后沿着索引链表逐条扫描,直到遇到不满足 a >= 1 的记录为止。
b字段的索引利用:
有序性:对于 a 值相同的记录,b字段是有序的。这意味着当你在 a = 1 的范围内查询 b = 2 时,数据库可以通过索引快速定位到满足 a = 1 AND b = 2 的第一条记录,而不必扫描所有 a = 1 的记录。这就是为什么 b 字段的条件在这种情况下也能利用联合索引进行优化。
对于a值相同的记录,b字段是有序的理解:
拿这张表来看,联合索引(a,b):
(1, 1)
(1, 2)
(1, 3)
(2, 1)
(2, 2)
(3, 1)
对于a=1的记录,b字段的值是按照去1,2,3的顺序排列的,诠释了对于a值相同的记录,b字段是有序的,确实效率高了很多诶
为什么是这样的呢?
因为 联合索引在创建时会按照多个字段的顺序进行排序和存储
当你创建一个联合索引 (a, b)时,数据库会先按照第一个字段 a对数据进行排序。
在 a 值相同的情况下,数据库会再根据第二个字段 b 进行排序。因此,对于 a 值相同的所有记录,b字段的值是按照升序或降序排列的。
这里同样使用上面的例子,只不过这里key_len为8个字节,也就是a和b字段都用到了联合索引进行索引查询
Q3这条语句,Q4这条语句,昨晚看了之后 发现其实只要是范围查询,和这个范围里面有和b值相等的,那两者都用到了联合索引
总结:
联合索引的最左匹配原则,在遇到范围查询(什么>,<的时候),就会停止匹配,(mlgb的意思就是,范围查询的字段可以用到联合索引),但是!!!在范围查询的后面的字段无法用到联合索引
注意,对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配
索引下推:
可以在联合索引遍历过程中,
对联合索引中包含的字段先做判断,
直接过滤掉不满足条件对记录,减少回表次数
回表是什么?
指数据库查询中,使用二级索引的时候,数据库需要通过索引找到匹配的记录,然后再去主表中找到完整的数据行。(大概就是先去二级索引找主键值,然后在去主键索引中找实际数据)
回表的流程如下:
1 通过索引查询:数据库使用二级索引 查找到满足条件的记录
2 回表查找:如果查询的字段 不在索引里,数据库就需要通过索引中的行标识符,比如主键 ,去查找对应的完整数据行
3 返回结果
索引区分度
区分度又是什么???
简单了解一下 ,区分度 就是 衡量一个索引列(或多列组合)在数据库表中能够区分不同数据行的能力
越靠前的字段,被用于索引过滤的概率越高。
实际开发中建立联合索引时,要把区分度大的字段排在前面,他越有可能被更多的SQL使用q
联合索引进行排序的例子:
给定的 SQL 语句是:
SELECT * FROM orders WHERE status = 1 ORDER BY create_time ASC;
初步分析
status 列用于筛选数据。
create_time 列用于对结果集进行排序。
假设 orders 表的数据量较大,如果没有索引或者只给 status 列单独建立索引,数据库在执行这条查询时会有以下问题:
筛选效率:虽然 status 上的索引可以加速筛选,但筛选出来的数据依然需要排序。
排序开销:MySQL 可能会使用 filesort(文件排序)来对结果进行排序,这个过程可能比较耗费资源,尤其是在数据量大的情况下。
如何优化
最佳做法是为 status 和 create_time 列创建一个联合索引。避免mysql数据库发生文件排序
1 减少 filesort:
联合索引可以利用索引的有序性,使得在 status = 1 的前提下,数据已经按照 create_time 排序,从而避免了额外的排序操作。
这样,查询在提取数据时,数据已经按照 create_time 有序,不需要再进行额外的排序(即不会出现 Using filesort)。
2 覆盖索引的潜力:
如果在查询中你只选择了一些字段(如 SELECT status, create_time FROM orders WHERE status = 1 ORDER BY create_time ASC),联合索引不仅能加速查询,还可以作为覆盖索引,避免回表操作,进一步提升效率。
实施步骤
你可以通过以下 SQL 语句创建联合索引:
CREATE INDEX idx_status_create_time ON orders(status, create_time);
这条命令会在 status 和 create_time 列上创建一个联合索引。
查询执行计划
使用联合索引后,你可以通过 EXPLAIN 来查看查询计划,确保 Extra 列没有出现 Using filesort,并且索引已经被正确使用。
EXPLAIN SELECT * FROM orders WHERE status = 1 ORDER BY create_time ASC;
如果优化成功,你会看到索引 idx_status_create_time 被使用,且没有文件排序,查询效率将显著提升。
什么时候需要/不需要创建索引?
万事有利必有弊
什么时候适用索引??
字段有唯一性限制的,比如商品编码
经常用于 where查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。
经常用于group by 和 order by的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。
什么时候不需要创建索引??
where 条件,group by,order by里用不到的字段,索引的价值是快速定位,起不到定位的字段通常不需要创建索引,因为索引会占用空间
重复数据过多的字段不需要创建索引,比如在一个表中的性别字段,只有男和女,全是重复的男和女,建立索引干嘛??你一艘女,只要性别是女的都全出来了,这样只会增加数据库的开销
表数据太少的时候,不需要创建索引
经常更新的字段不用创建索引,因为经常更新,他很不稳定的,你建立了索引你也搜不到他,由于要维护B+tree的有序性,那么就需要频繁的重建索引,不添加索引反而能保持数据库的高效性
有什么优化索引的方法?
前缀索引优化
意思就是使用某个字段中 字符串的前几个字符建立索引,完整索引需要存储字段的每一个只,这在长字段(比如邮件地址,URL等)情况下会占用大量空间。通过前缀索引,只存储字段的前一部分(比如前10哥字符),这样会减少索引的占用空间。
例如,一个 VARCHAR(255) 的字段完整索引可能占用 255 字节,而如果你只索引前 10 个字符,则只占用 10 字节。这种方式可以减少索引文件的大小,使数据库管理更为高效。
前缀索引的适用场景:
1 长字符串字段(比如URL,电子邮件地址等)
2 非精确匹配 (比如查找某个字符串开头的匹配项)
前缀索引的局限性:
1 order by无法使用前缀索引
什么意思呢,就是在sql查询中,如果使用了这个order by子句对某个字段进行排序,而这个字段 他的索引是前缀索引,数据库是无法直接利用这个索引完成排序操作的
比如:有一个电子邮件字段email,并为其10个字符创建了前缀索引。查询的时候你想对email排序:
select * from users order by email;
这里索引不包含完整的email字段值,所以就无法使用前缀索引
2 无法把前缀索引用作覆盖索引
覆盖索引就是:当查询所需的所有数据都可以从索引中获取,那数据库就不用再去读取表中的数据了啊。。。都已经可以在索引中获取数据了,,查毛的表啊,多次一举。
但是,前缀索引只包含字段的前一部分(前缀),如果查询需要访问字段的完整值或其他字段,那数据库就不能仅仅依靠前缀索引来完成查询了。必须要回到表里去查询来获取完整的数据
再来一次,回表到底是啥意思???
查询的完整数据不在索引里,所以必须“回”到数据表中找
比如:你有一个包含用户信息的表users:有id,name和email字段。然后执行:
SELECT id, name FROM users WHERE email = 'example@example.com';
1 索引查找
数据库首先会利用 email 字段的索引,快速找到 email = 'example@example.com' 的那条记录。
索引中通常只包含被索引字段的值(这里是 email)和一部分其他信息(如行指针或主键)。
2 回表
但是,查询还需要返回 id 和 name 字段,而这些字段的数据不在 email 索引里。
因此,数据库需要根据索引提供的指针或主键,回到 users 表中找到这一行完整的数据,获取 id 和 name 的值。
而二叉树的每个父节点的儿子节点个数只能是2个,意味着其搜索复杂度为o(1ogN),这已经比 B+Tree 高出不少,因此二又树检索到目标数据所经历的磁盘 /0 次数要更多
覆盖索引优化
覆盖索引就是一种通过索引就可以获取查询所需要的所有字段数据的方法,从而避免回表操作,提高查询效率。
假设你有一个商品表 products,表中有以下字段:
product_id(商品ID)
name(商品名称)
price(价格)
description(描述)
其他字段
如果执行以下查询:
select name,price from products where product_id = 123;
为了避免回表,用索引覆盖:就是以这三个字段创建一个联合索引
create index idx_product_info on products (product_id,name,price);
查询过程:
当你运行 SELECT name, price FROM products WHERE product_id = 123; 时,数据库可以直接在索引 idx_product_info 中找到 product_id、name 和 price,因为这些字段已经被包含在了索引中。
因为查询需要的所有字段(name 和 price)都在索引里,数据库无需再去数据表中查找,也就是避免了回表。
减少I/O操作:
回表意味着数据库需要再做一次磁盘读取操作来获取完整的数据行,而覆盖索引避免了这种情况。索引可显著减少I/O操作,加快查询速度
主键索引最好是自增的
比如,第一条数据的主键是1,第二条是2,依次类推。
innooDB聚簇索引的结构:
主键 默认是 聚簇索引(二级索引),这意味着数据行的物理存储顺序与主键索引的顺序一致,数据被存放在 B+ 树的叶子节点上
为什么这么做呢,有什么好处?
1 数据写入效率高
每插入一条新记录,都是追加操作,不需要重新移动数据(就是追加到后面的操作而不是随便找个地方插进去)这样写入就大大减少了磁盘I/O操作
2 避免页分裂
如果使用非自增主键,因为每次插入主键的索引值都是随机的,每次 插入新数据的时候,他就随机乱插,然后不得不移动其他数据,甚至需要从一个页面复制数据到另外一个页面,这就是页分裂。
页分裂还有可能造成大量的内存碎片,导致索引结构不紧凑,从而影响效率。
使用非自增主键(如随机生成的字符串或 UUID)会导致以下问题:
插入效率低:因为新数据需要插入到索引的中间位置,这会导致大量的数据移动。
频繁的页分裂:随机插入的数据容易导致页面被分裂,进一步增加了磁盘 I/O 和内存碎片。
索引不再紧凑:频繁的插入和页分裂会使索引结构散乱,查询效率下降。
唉也就是上面一段所说的那个意思
主键字段的长度不要太大哦,因为 主键字段的长度越小,意味着二级索引的叶子结点越小,占用的空间越小
索引最好设置为not null
为什么呢?
1 索引列存在null ,null使索引选择和优化更复杂
2 null占用额外的存储空间,因为他没啥意义,没意义的东西能扔则扔
防止索引失效
这里说一下索引失效的情况

索引存储结构长什么样
MySQL 默认的存储引擎是 InnoDB,B+tree 作为索引 的 结构
这里涉及到为什么MySQL喜欢B+树?
怎样的索引的数据结构是好的?
要设计一个适合 MySQL 索引的数据结构,至少满足以下要求:
能在尽可能少的磁盘的 I/O 操作中完成查询工作;
要能高效地查询某一个记录,也要能高效地执行范围查找;
什么是二分查找?
其他复杂的解释不要看了ok?大概就是 每次都把查询的范围减半,然后看你 要的数据在哪一边,然后就省去了查询另一边的时间。时间复杂度就降了啊,干什么事情不就是一个原则,图省事
二分查找树
二叉查找树:他的特点就是,一个节点的左子树的所有节点 都小于这个节点 ,右子树的所有节点都大于这个节点 看图
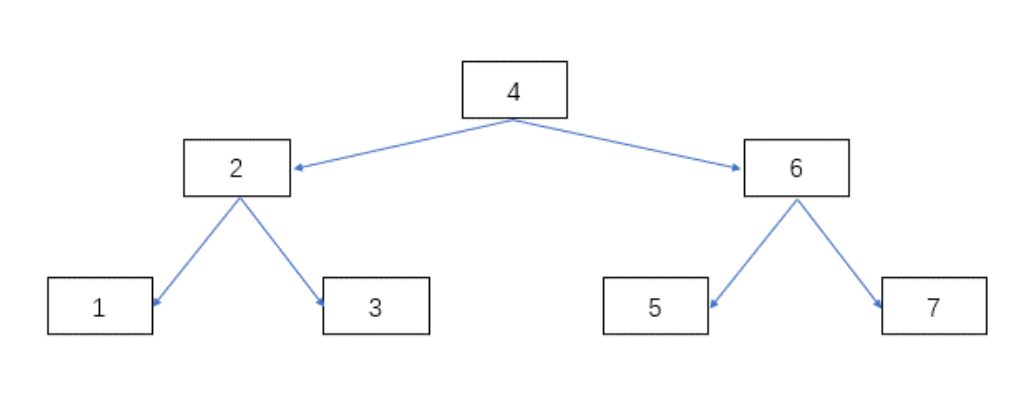
这他喵原理就跟二分查找一样
有一个极端情况;
要是你每一次都是插入二叉树中最大的元素,那你是不是要把它放到右子树一个连着一个的,那是不是就成了链条去了
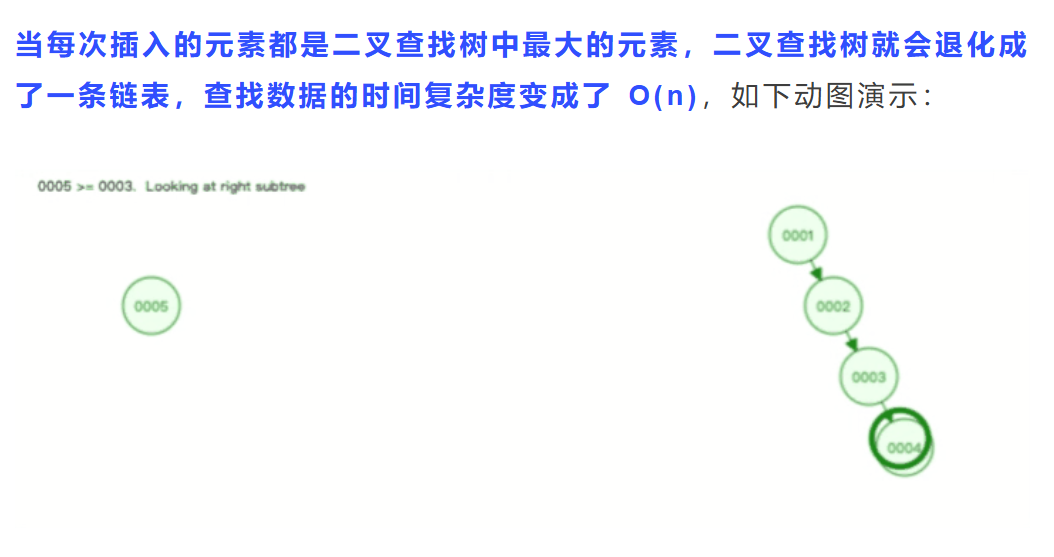
由于树是存储在磁盘中的,访问每个节点,都对应一次磁盘 I/O 操作(假设一个节点的大小「小于」操作系统的最小读写单位块的大小),也就是说树的高度就等于每次查询数据时磁盘 IO 操作的次数,所以树的高度越高,就会影响查询性能。
这段话就解释了为什么选B+tree作为索引而不是 二叉树(三个比较之一)
二叉查找树由于存在退化成链表的可能性,会使得查询操作的时间复杂度从 O(logn)降低为 O(n)。
而且会随着插入的元素越多,树的高度也变高,意味着需要磁盘 IO 操作的次数就越多,这样导致查询性能严重下降,再加上不能范围查询,所以不适合作为数据库的索引结构。
什么是自平衡二叉树
接上面,二叉树会变成链表的问题,现在则有平衡二叉树:主要是在二叉查找树的基础上增加了一些条件约束:每个节点的左子树和右子树的高度差不能超过 1。
不管平衡二叉查找树还是红黑树,都会随着插入的元素增多,而导致树的高度变高,这就意味着磁盘 I/O 操作次数多,会影响整体数据查询的效率
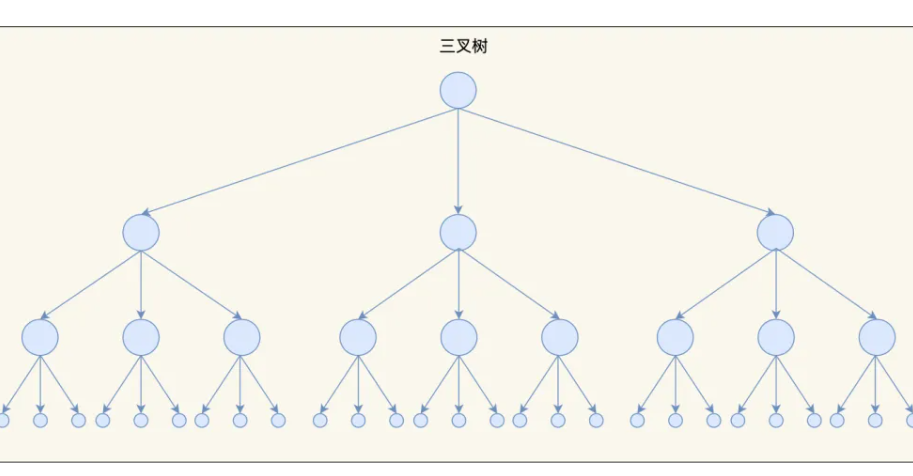
树的节点 越多的时候,并且树的分叉树M越大的时候,M叉树的高度会远小于二叉树的高度。
就你看这张图就行
B+树又他喵的是什么?
先分清楚:
叶子节点:在树中没有任何子节点的节点,在最底层;非叶子节点是在树中至少有一个子节点的节点
和B树差异的点:
1 叶子节点:存放实际数据(索引+记录);非叶子节点:只存放索引,没有记录
2 非叶子节点中有多少个子节点,就有多少个索引(每一个非叶子节点都有一个索引)
3 索引都会在叶子节点出现,叶子节点之间构成一个有序链表
4 非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小

对数据结构分类中的问题剖析:
为什么 MySQL InnoDB 选择 B+tree 作为索引的数据结构?
B+Tree 相比于 B 树、二叉树或 Hash 索引结构的优势在哪儿?
B+Tree vs B Tree
B+树只在叶子结点存储数据,B树非叶子结点也要存储数据,所以 B+树的单个结点的数据量更小,在相同磁盘I/O次数下,就能查询更多的结点
B+tree他的叶子结点采用的是双向链表连接,双向链表就很容易的进行范围的顺序查找
B+Tree vs 二叉树
二叉树他只有两叉,而两叉的话,他的层次就会很高,而每一次去读取一个结点,就要进行一次磁盘I/O操作,磁盘的I/O操作呢,比较耗时。而B+tree呢他是一棵多叉树,他的高度依然保持在3-4层左右,也就是说一次数据查询操作只需要做3-4次的磁盘I/O操作就能查询到目标数据。此外,二叉树在极端情况下可能退化为链表,从而导致性能下降。
在B+树中,所有实际数据都存储在叶子节点中,非叶子节点只存储索引信息。因此,非叶子节点占用的空间较小,可以存储更多的索引信息,这样在内存中可以加载更多的索引,减少磁盘I/O操作,提高查找效率。
由于非叶子节点只存储索引而不存储实际数据,因此它们占用的空间较少,允许在内存中存储更多的索引。这样可以减少磁盘I/O操作,提高查询速度,同时更高效地利用内存空间。
B+Tree vs Hash
Hash在做等值查询的时候效率贼快,但他不适合做范围查询,他更适合做等值的查询。
说一说InnoDB的底层索引原理
按物理存储分类
主键索引 ,二级索引
主键索引 的B+tree的叶子结点 存放的是实际数据
二级索引 的B+tree的叶子结点 存放的是主键值
相关文章:
MySQL索引知识个人笔记总结(持续整理)
本篇笔记是个人整理的索引知识总结,刚开始有点乱,后续会一直边学边整理边总结 索引(index)是帮助MySQL高效获取数据的数据结构(有序)。就好比索引就是数据的目录 索引结构 Btree索引,Hash索引,Full-text索引,R-tree(空…...

ReKep——李飞飞团队提出的让机器人具备空间智能:基于视觉语言模型GPT-4o和关系关键点约束
前言 由于工厂、车厂的任务需求场景非常明确,加之自今年年初以来,我司在机器人这个方向的持续大力度投入(包括南京、长沙两地机器人开发团队的先后组建),使得近期我司七月接到了不少来自车厂/工厂的订单,比如其中的三个例子&…...

[Java并发编程] synchronized(含与ReentrantLock的区别)
文章目录 1. synchronized与ReentrantLock的区别2. synchronized的作用3. synchronized的使用3.1 修饰实例方法,作用于当前实例,进入同步代码前需要先获取实例的锁3.2 修饰静态方法,作用于类的Class对象,进入修饰的静态方法前需要…...

spring-boot-maven-plugin插件打包和java -jar命令执行原理
文章目录 1. Maven生命周期2. jar包结构2.1 不可执jar包结构2.2 可执行jar包结构 3. spring-boot-maven-plugin插件打包4. 执行jar原理 1. Maven生命周期 Maven的生命周期有三种: clean:清除项目构建数据,较为简单,不深入探讨&a…...

Python办公自动化教程(001):PDF内容提取
1、Pdfplumber介绍 pdfplumber的github地址: https://github.com/jsvine/pdfplumber/【介绍】:pdfplumber 是一个用于处理 PDF 文件的 Python 第三方库,它提供了一种方便的方式来提取 PDF 文件中的文本、表格和其他信息。【功能】ÿ…...
HarmonyOS鸿蒙开发实战(5.0)自定义全局弹窗实践
鸿蒙HarmonyOS开发实战往期文章必看: HarmonyOS NEXT应用开发性能实践总结 最新版!“非常详细的” 鸿蒙HarmonyOS Next应用开发学习路线!(从零基础入门到精通) 非常详细的” 鸿蒙HarmonyOS Next应用开发学习路线&am…...

【AI学习】了解OpenAI o1背后的self-play RL:开启新的智能道路
在ChatGPT刚刚出来的时候,沐神关于ChatGPT有一段视频,只有几分钟,却是讲得极其透彻的一段。大概意思就是,过去的AI智能水平,比如五年前,大概相当于人类5秒钟思考的程度,包括自动驾驶,…...

Java项目实战II基于Java+Spring Boot+MySQL的车辆管理系统(开发文档+源码+数据库)
目录 一、前言 二、技术介绍 三、系统实现 四、论文参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。获取源码联系方式请查看文末 一、前言 "随着…...

IPsec-VPN中文解释
网络括谱图 IPSec-VPN 配置思路 1 配置IP地址 FWA:IP地址的配置 [FW1000-A]interface GigabitEthernet 1/0/0 [FW1000-A-GigabitEthernet1/0/0]ip address 10.1.1.1 24 //配置IP地址 [FW1000-A]interface GigabitEthernet 1/0/2 [FW1000-A-GigabitEthernet1/0/2]ip a…...
Ubuntu 22.04 源码下载、编译
Kernel/BuildYourOwnKernel - Ubuntu Wikihttps://wiki.ubuntu.com/Kernel/BuildYourOwnKernel 一、查询当前系统内核版本 rootubuntu22:~# uname -r 5.15.0-118-generic 二、查询本地软件包数据库中的内核源码信息 rootubuntu22:~# apt search linux-source Sorting... Do…...

【深度学习实战—11】:基于Pytorch实现谷歌QuickDraw数据集的下载、解析、格式转换、DDP分布式训练、测试
✨博客主页:王乐予🎈 ✨年轻人要:Living for the moment(活在当下)!💪 🏆推荐专栏:【图像处理】【千锤百炼Python】【深度学习】【排序算法】 目录 😺〇、仓库…...

基于SpringBoot+WebSocket实现地图上绘制车辆实时运动轨迹图
实现基于北斗卫星的车辆定位和轨迹图的Maven工程(使用模拟数据),我们将使用以下技术: Spring Boot:作为后端框架,用来提供数据接口。Thymeleaf:作为前端模板引擎,呈现网页。Leaflet…...

嵌入式入门小工程
此代码基于s3c2440 1.点灯 //led.c void init_led(void) {unsigned int t;t GPBCON;t & ~((3 << 10) | (3 << 12) | (3 << 14) | (3 << 16));t | (1 << 10) | (1 << 12) | (1 << 14) | (1 << 16);GPBCON t; }void le…...

hackmyvm靶场--zon
环境 攻击机kali 靶机 未知 主机探测 因为在同一个局域网内使用ARP协议探测存活主机 靶机为192.168.56.128 端口探测 常见的80和22端口 那么一定是寻找web漏洞拿shell了 后台扫描 后台扫描常用dirsearch和gobuster,有时候小字典可能不太行,可以尝试换个大点…...

atcoder abc372 启发式合并, dp
A delete 代码: #include <bits.stdc.h>using namespace std;int main() {string s;cin >> s;for(auto t: s) if(t ! .) cout << t; } B 3 ^ A 思路:三进制转换,可以参考二进制,先把当前可以加入的最大的3的…...

CentOS Stream 9部署MariaDB
1、更新系统软件包 sudo dnf update 2、安装MariaDB软件包(替代mysql) sudo dnf install mariadb-server 3、安装MariaDB服务 sudo systemctl enable --now mariadb 4、检查MariaDB服务状态 sudo systemctl status mariadb 5、配置MariaDB安全性 sudo my…...

【Leetcode:997. 找到小镇的法官 + 入度出度】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...

大数据Flink(一百二十三):五分钟上手Flink MySQL连接器
文章目录 五分钟上手Flink MySQL连接器 一、创建数据库表 二、创建session集群 三、源表查询 四、窗口计算 五、结果数据写回数据库 五分钟上手Flink MySQL连接器 MySQL Connector可以将本地或远程的MySQL数据库连接到Flink中&#x…...

SYN Flood攻击原理,SYN Cookie算法
SYN Flood是一种非常危险而常见的Dos攻击方式。到目前为止,能够有效防范SYN Flood攻击的手段并不多,SYN Cookie就是其中最著名的一种。 1. SYN Flood攻击原理 SYN Flood攻击是一种典型的拒绝服务(Denial of Service)攻击。所谓的拒绝服务攻击就是通过进…...
期末速成笔记1)
计组(蒋)期末速成笔记1
蒋本珊计组期末不挂科复习笔记 第1章 概论 第2章 数据的机器层次表示 第3章 指令系统 第4章 数值的机器运算 第5章 存储系统和结构 第6章 中央处理器 第7章 总线 第1章 概论 蒋本珊计组期末不挂科复习笔记知道你快考试了,莫慌! 第1章 概论1.1 冯诺依曼计…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

孤舟笔记 互联网常用框架篇三 Dubbo是如何动态感知服务下线的?注册中心和服务端双保险
文章目录先说结论机制一:注册中心通知机制二:心跳检测机制三:连接事件感知机制四:定时拉取四种机制的协作回答技巧与点评加分回答面试官点评个人网站微服务环境下,服务实例随时可能上下线——重启、扩容、宕机……调用…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

前馈补偿技术:用数字预失真驯服放大器非线性失真
1. 项目概述:用前馈补偿驯服放大器失真在音频发烧友和硬件工程师的圈子里,追求“高保真”几乎是一种信仰。我们总希望从扬声器里传出的声音,是录音现场或音乐制作人意图的完美复刻,纤毫毕现,不带一丝杂质。然而&#x…...
)
Unity开发者速查手册:Sora 2模型权重量化适配指南(INT8精度损失<0.3%,已验证于RTX 4090/Apple M3 Ultra)
更多请点击: https://codechina.net 第一章:Sora 2与Unity整合概述 Sora 2 是 OpenAI 推出的下一代视频生成模型,具备高保真时序建模与物理感知能力;而 Unity 作为主流实时3D开发引擎,广泛用于游戏、仿真与数字孪生场…...

Unity动态植被系统:实时天气与自然现象耦合方案
1. 这不是“贴图堆砌”,而是一套可交互的自然系统你有没有试过在Unity里拖进几棵树、铺点草地,结果运行起来——风一吹,所有树叶像被钉在空中一样纹丝不动;下雨时,雨滴垂直砸进地面,连个水花都没有…...

基于特征工程的电力系统虚假数据注入攻击检测方案
1. 项目概述与核心挑战在电力系统这个庞大而精密的“交响乐团”中,自动发电控制(AGC)系统扮演着指挥家的角色。它的核心任务是根据电网频率和联络线功率的微小波动,实时调整各发电机的出力,确保整个电网的频率稳定在50…...

初创团队如何借助Taotoken以低成本快速验证AI产品创意
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何借助Taotoken以低成本快速验证AI产品创意 对于资源有限的初创团队而言,验证一个AI产品创意的核心挑战往往…...

从自然语言到可视化洞察:ChartGPT如何用AI重构数据图表生成范式
从自然语言到可视化洞察:ChartGPT如何用AI重构数据图表生成范式 【免费下载链接】chart-gpt AI tool to build charts based on text input 项目地址: https://gitcode.com/gh_mirrors/ch/chart-gpt 在数据驱动的决策时代,业务人员与技术团队之间…...