代码随想录Day 52|题目:101.孤岛的面积、102.沉没孤岛、103.水流问题、104.建造最大岛屿
提示:DDU,供自己复习使用。欢迎大家前来讨论~
文章目录
- 图论part03
- 题目一:101.孤岛的总面积
- 解题思路
- DFS
- **BFS**
- 题目二:102. 沉没孤岛
- 解题思路
- 题目三:103. 水流问题
- 解题思路
- 优化
- 题目四:104.建造最大岛屿
- 解题思路
- 优化思路
- 总结
图论part03
题目一:101.孤岛的总面积
101. 孤岛的总面积 (kamacoder.com)
解题思路
本题使用dfs,bfs,并查集都是可以的。
本题要求找到不靠边的陆地面积,那么我们只要从周边找到陆地然后 通过 dfs或者bfs 将周边靠陆地且相邻的陆地都变成海洋,然后再去重新遍历地图 统计此时还剩下的陆地就可以了。
如图,在遍历地图周围四个边,靠地图四边的陆地,都为绿色,
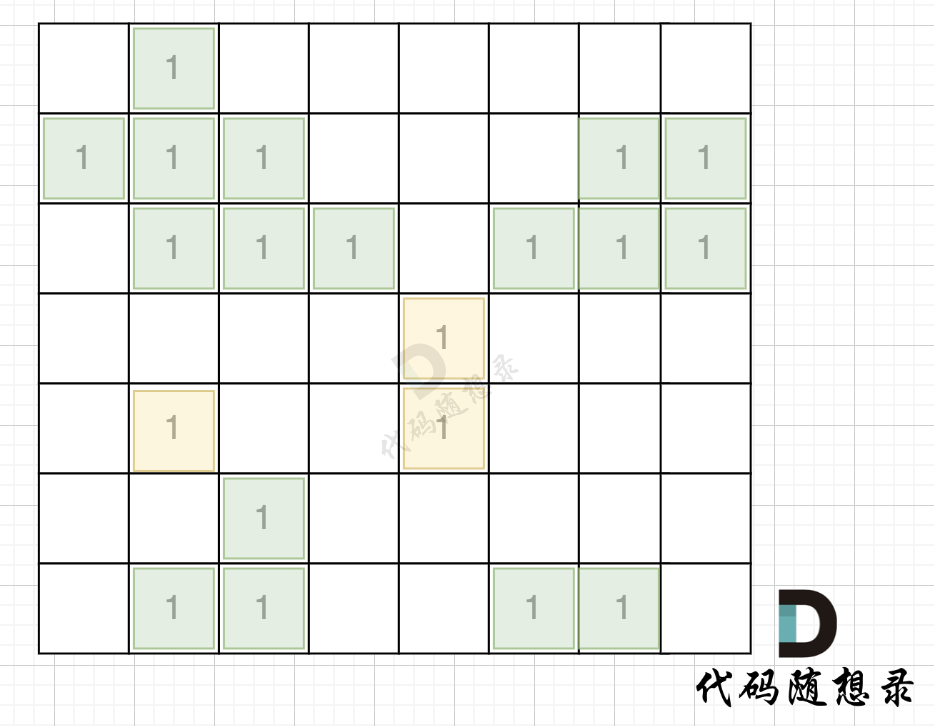
在遇到地图周边陆地的时候,将1都变为0,此时地图为这样:
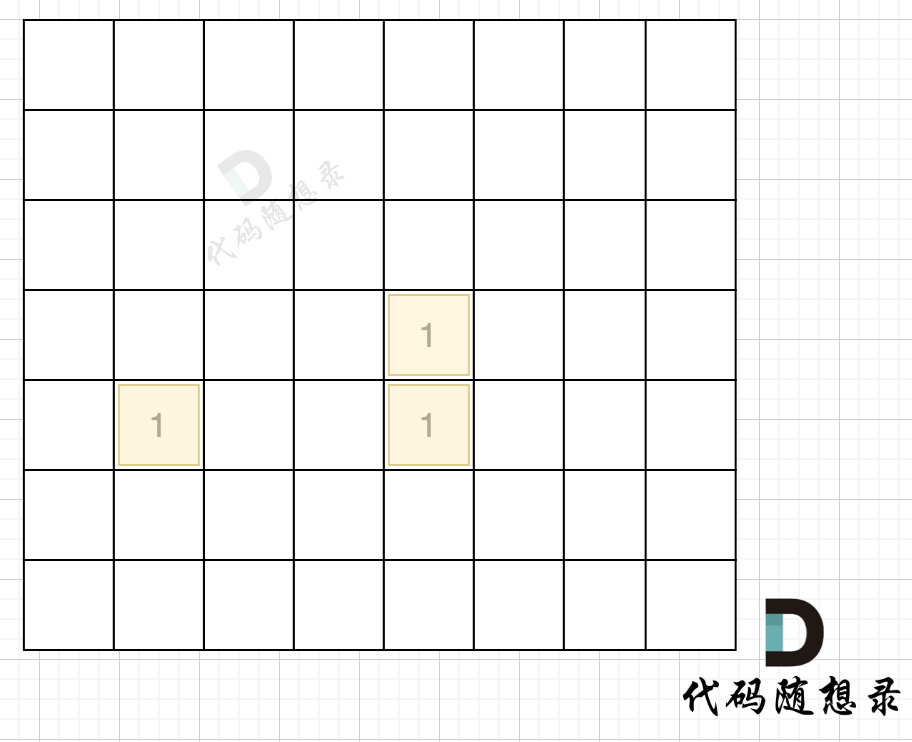
然后我们再去遍历这个地图,遇到有陆地的地方,去采用深搜或者广搜,边统计所有陆地。
DFS
采用深度优先搜索的代码如下:
#include <iostream>
#include <vector>
using namespace std;
int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1}; // 保存四个方向
int count; // 统计符合题目要求的陆地空格数量
void dfs(vector<vector<int>>& grid, int x, int y) {grid[x][y] = 0;count++;for (int i = 0; i < 4; i++) { // 向四个方向遍历int nextx = x + dir[i][0];int nexty = y + dir[i][1];// 超过边界if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue;// 不符合条件,不继续遍历if (grid[nextx][nexty] == 0) continue;dfs (grid, nextx, nexty);}return;
}int main() {int n, m;cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}// 从左侧边,和右侧边 向中间遍历for (int i = 0; i < n; i++) {if (grid[i][0] == 1) dfs(grid, i, 0);if (grid[i][m - 1] == 1) dfs(grid, i, m - 1);}// 从上边和下边 向中间遍历for (int j = 0; j < m; j++) {if (grid[0][j] == 1) dfs(grid, 0, j);if (grid[n - 1][j] == 1) dfs(grid, n - 1, j);}count = 0;for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (grid[i][j] == 1) dfs(grid, i, j);}}cout << count << endl;
}
BFS
采用广度优先搜索的代码如下:
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
int count = 0;
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void bfs(vector<vector<int>>& grid, int x, int y) {queue<pair<int, int>> que;que.push({x, y});grid[x][y] = 0; // 只要加入队列,立刻标记count++;while(!que.empty()) {pair<int ,int> cur = que.front(); que.pop();int curx = cur.first;int cury = cur.second;for (int i = 0; i < 4; i++) {int nextx = curx + dir[i][0];int nexty = cury + dir[i][1];if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过if (grid[nextx][nexty] == 1) {que.push({nextx, nexty});count++;grid[nextx][nexty] = 0; // 只要加入队列立刻标记}}}
}int main() {int n, m;cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}// 从左侧边,和右侧边 向中间遍历for (int i = 0; i < n; i++) {if (grid[i][0] == 1) bfs(grid, i, 0);if (grid[i][m - 1] == 1) bfs(grid, i, m - 1);}// 从上边和下边 向中间遍历for (int j = 0; j < m; j++) {if (grid[0][j] == 1) bfs(grid, 0, j);if (grid[n - 1][j] == 1) bfs(grid, n - 1, j);}count = 0;for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (grid[i][j] == 1) bfs(grid, i, j);}}cout << count << endl;
}
题目二:102. 沉没孤岛
102. 沉没孤岛 (kamacoder.com)
解题思路
- 标记边缘陆地:从地图的边缘开始,将所有边缘的陆地(1)标记为特殊值(2)。
- 转换中间陆地:遍历整个地图,将未标记的陆地(1)转换为水域(0)。
- 恢复边缘标记:将特殊标记(2)恢复为陆地(1)。
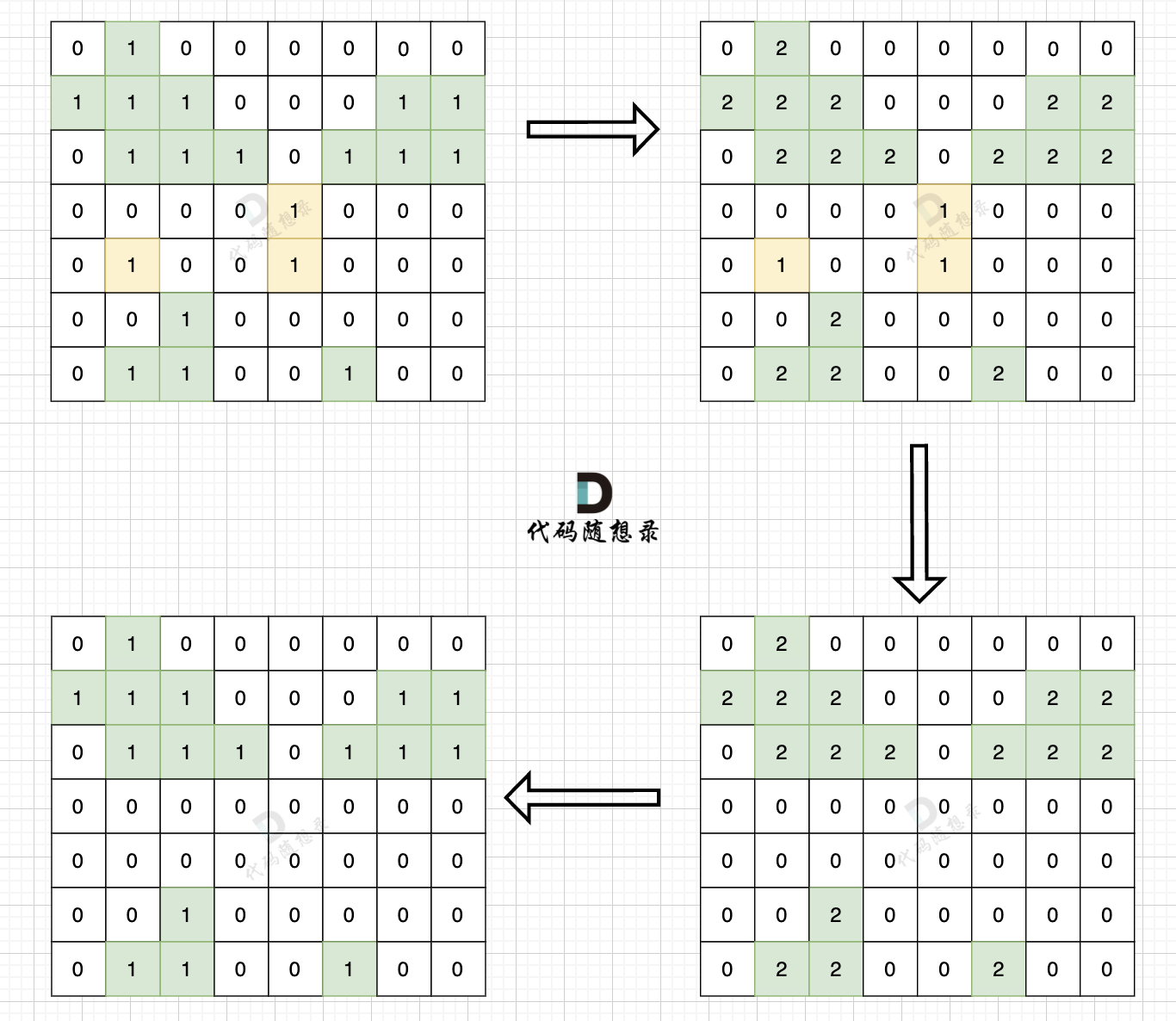
整体C++代码如下,以下使用dfs实现,其实遍历方式dfs,bfs都是可以的。
#include <iostream>
#include <vector>
using namespace std;
int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1}; // 保存四个方向
void dfs(vector<vector<int>>& grid, int x, int y) {grid[x][y] = 2;for (int i = 0; i < 4; i++) { // 向四个方向遍历int nextx = x + dir[i][0];int nexty = y + dir[i][1];// 超过边界if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue;// 不符合条件,不继续遍历if (grid[nextx][nexty] == 0 || grid[nextx][nexty] == 2) continue;dfs (grid, nextx, nexty);}return;
}int main() {int n, m;cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}// 步骤一:// 从左侧边,和右侧边 向中间遍历for (int i = 0; i < n; i++) {if (grid[i][0] == 1) dfs(grid, i, 0);if (grid[i][m - 1] == 1) dfs(grid, i, m - 1);}// 从上边和下边 向中间遍历for (int j = 0; j < m; j++) {if (grid[0][j] == 1) dfs(grid, 0, j);if (grid[n - 1][j] == 1) dfs(grid, n - 1, j);}// 步骤二、步骤三for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (grid[i][j] == 1) grid[i][j] = 0;if (grid[i][j] == 2) grid[i][j] = 1;}}for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cout << grid[i][j] << " ";}cout << endl;}
}
题目三:103. 水流问题
103. 水流问题 (kamacoder.com)
解题思路
想象你有一块高低不平的地形,这块地形是一个由很多小格子组成的矩形,每个小格子都有一个高度值。现在下了一场雨,雨水会从高处流向低处,但是雨水只能流向四个方向:上、下、左、右,而且只能流向比它低或者一样高的地方。
现在,我们要找出那些雨水可以流到地形边缘的格子。地形的边缘分为两组:第一组是地形的左边界和上边界,第二组是右边界和下边界。
任务就是找出所有那些雨水可以流到这两组边界的格子,并输出这些格子的坐标。
(就是找出那些雨水可以流到地形边缘的格子,并告诉你这些格子在哪里。)
- 输入:你会得到一个矩形矩阵,矩阵的大小由两个数字 N 和 M 决定,N 表示行数,M 表示列数。矩阵中的每个数字代表一个小格子的高度。
- 输出:你需要找出所有那些雨水可以流到地形的左边界或上边界(第一组边界)的格子,以及所有雨水可以流到地形的右边界或下边界(第二组边界)的格子。然后,你需要输出这些格子的坐标。
一个比较直白的想法,其实就是 遍历每个点,然后看这个点 能不能同时到达第一组边界和第二组边界。
至于遍历方式,可以用dfs,也可以用bfs,以下用dfs来举例。
#include <iostream>
#include <vector>
using namespace std;
int n, m;
int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1};// 从 x,y 出发 把可以走的地方都标记上
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y) {if (visited[x][y]) return;visited[x][y] = true;for (int i = 0; i < 4; i++) {int nextx = x + dir[i][0];int nexty = y + dir[i][1];if (nextx < 0 || nextx >= n || nexty < 0 || nexty >= m) continue;if (grid[x][y] < grid[nextx][nexty]) continue; // 高度不合适dfs (grid, visited, nextx, nexty);}return;
}
bool isResult(vector<vector<int>>& grid, int x, int y) {vector<vector<bool>> visited(n, vector<bool>(m, false));// 深搜,将x,y出发 能到的节点都标记上。dfs(grid, visited, x, y);bool isFirst = false;bool isSecond = false;// 以下就是判断x,y出发,是否到达第一组边界和第二组边界// 第一边界的上边for (int j = 0; j < m; j++) {if (visited[0][j]) {isFirst = true;break;}}// 第一边界的左边for (int i = 0; i < n; i++) {if (visited[i][0]) {isFirst = true;break;}}// 第二边界右边for (int j = 0; j < m; j++) {if (visited[n - 1][j]) {isSecond = true;break;}}// 第二边界下边for (int i = 0; i < n; i++) {if (visited[i][m - 1]) {isSecond = true;break;}}if (isFirst && isSecond) return true;return false;
}int main() {cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}// 遍历每一个点,看是否能同时到达第一组边界和第二组边界for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (isResult(grid, i, j)) {cout << i << " " << j << endl;}}}
}
直接对每个单元格进行深度优先搜索(DFS)会导致非常高的时间复杂度,尤其是在矩阵较大的情况下。这种直接的DFS方法在最坏情况下的时间复杂度是 O ( m 2 × n 2 ) O(m^2×n^2) O(m2×n2),这对于大型矩阵来说是不可行的。
优化
那么我们可以 反过来想,从第一组边界上的节点 逆流而上,将遍历过的节点都标记上。
同样从第二组边界的边上节点 逆流而上,将遍历过的节点也标记上。
然后两方都标记过的节点就是既可以流太平洋也可以流大西洋的节点。
从第一组边界边上节点出发,如图:
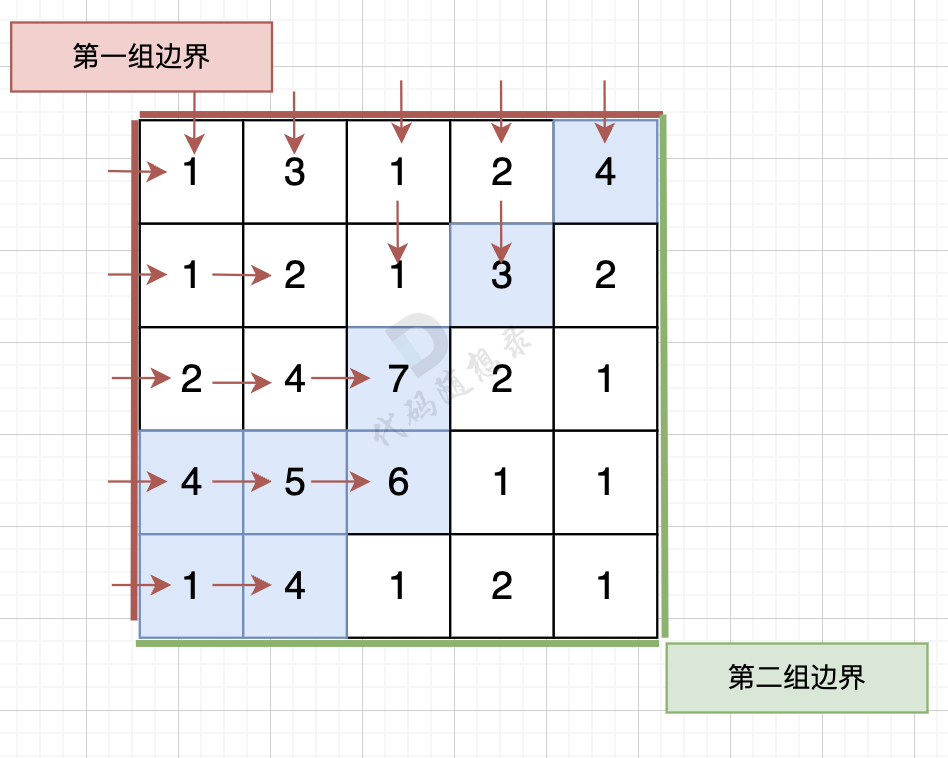
从第二组边界上节点出发,如图:
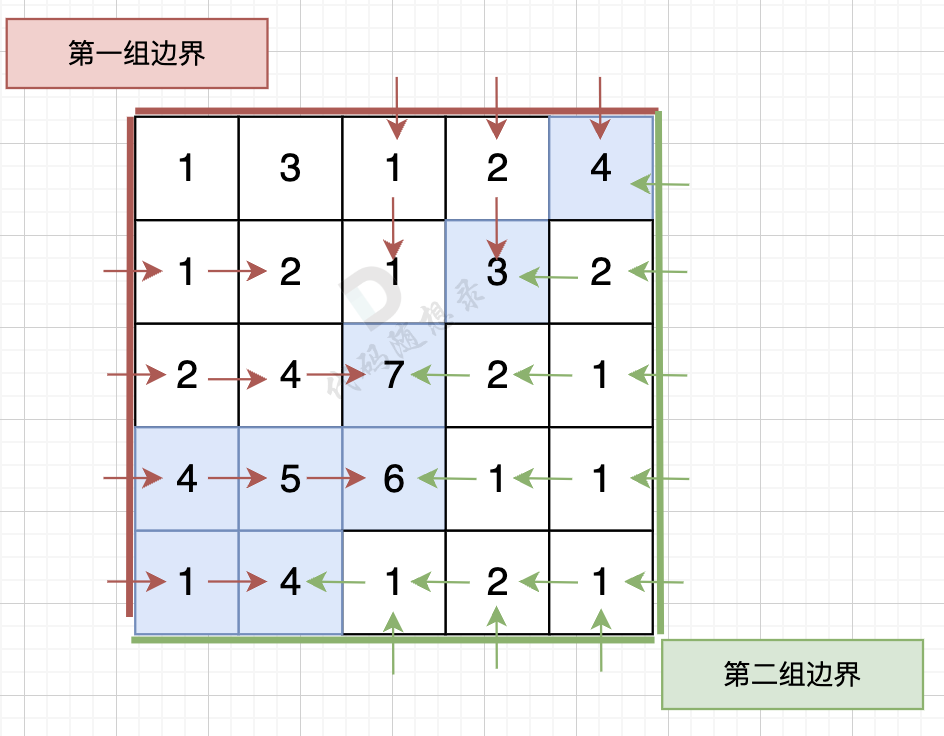
按照这样的逻辑,就可以写出如下遍历代码:(详细注释)
#include <iostream>
#include <vector>
using namespace std;
int n, m;
int dir[4][2] = {-1, 0, 0, -1, 1, 0, 0, 1};
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y) {if (visited[x][y]) return;visited[x][y] = true;for (int i = 0; i < 4; i++) {int nextx = x + dir[i][0];int nexty = y + dir[i][1];if (nextx < 0 || nextx >= n || nexty < 0 || nexty >= m) continue;if (grid[x][y] > grid[nextx][nexty]) continue; // 注意:这里是从低向高遍历dfs (grid, visited, nextx, nexty);}return;
}int main() {cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}// 标记从第一组边界上的节点出发,可以遍历的节点vector<vector<bool>> firstBorder(n, vector<bool>(m, false));// 标记从第一组边界上的节点出发,可以遍历的节点vector<vector<bool>> secondBorder(n, vector<bool>(m, false));// 从最上和最下行的节点出发,向高处遍历for (int i = 0; i < n; i++) {dfs (grid, firstBorder, i, 0); // 遍历最左列,接触第一组边界dfs (grid, secondBorder, i, m - 1); // 遍历最右列,接触第二组边界}// 从最左和最右列的节点出发,向高处遍历for (int j = 0; j < m; j++) {dfs (grid, firstBorder, 0, j); // 遍历最上行,接触第一组边界dfs (grid, secondBorder, n - 1, j); // 遍历最下行,接触第二组边界}for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {// 如果这个节点,从第一组边界和第二组边界出发都遍历过,就是结果if (firstBorder[i][j] && secondBorder[i][j]) cout << i << " " << j << endl;;}}}
本题整体的时间复杂度其实是: 2 ∗ n ∗ m + n ∗ m 2 * n * m + n * m 2∗n∗m+n∗m ,所以最终时间复杂度为 O( n ∗ m n * m n∗m) 。
空间复杂度为:O(n * m) 。开了几个 n * m 的数组。
题目四:104.建造最大岛屿
104. 建造最大岛屿 (kamacoder.com)
解题思路
- 暴力想法:尝试将地图上的每个水域(0)变成陆地(1),然后计算这种情况下的最大岛屿面积。
- 计算最大面积:通过深度优先搜索(DFS)或广度优先搜索(BFS)遍历地图,标记岛屿,计算面积。这一步的时间复杂度大约是 O( n 2 n^2 n2),因为需要遍历地图上的每个单元格。
- 整体时间复杂度:由于地图上有 n2 个单元格,每个单元格改变状态后都需要重新计算最大岛屿面积,所以整体时间复杂度是 O( n 4 n^4 n4)。
优化思路
-
记录岛屿面积:首先,遍历地图一次,使用深度优先搜索(DFS)找出所有的岛屿,并记录每个岛屿的面积。这一步可以给每个岛屿一个唯一的编号,并使用一个字典(或map)来存储岛屿编号和对应的面积。
-
计算最大面积:然后,再次遍历地图中的水域(0),对于每个水域单元格,计算它变成陆地(1)后,与它相邻的岛屿面积总和。这样,对于每个水域单元格,你都可以得到一个“潜在的最大面积”,即如果这个水域变成陆地,与它相邻的所有岛屿合并后的总面积。
通过这两步,你可以找到将任意一个水域单元格变成陆地后,能够得到的最大岛屿面积。这种方法避免了重复计算,提高了效率。
拿如下地图的岛屿情况来举例: (1为陆地)
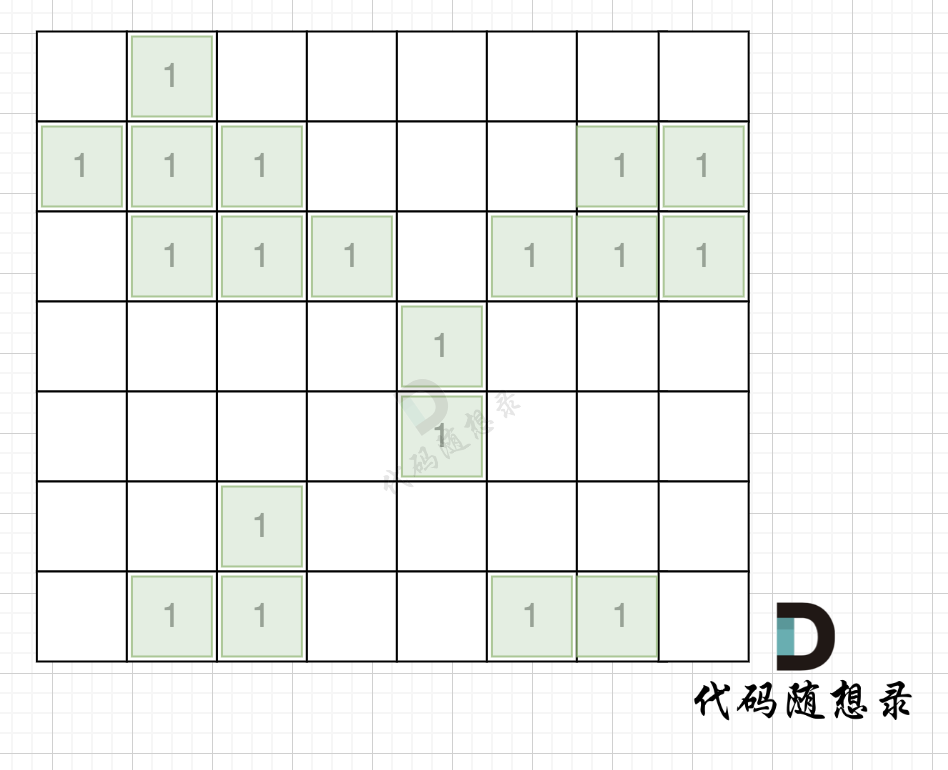
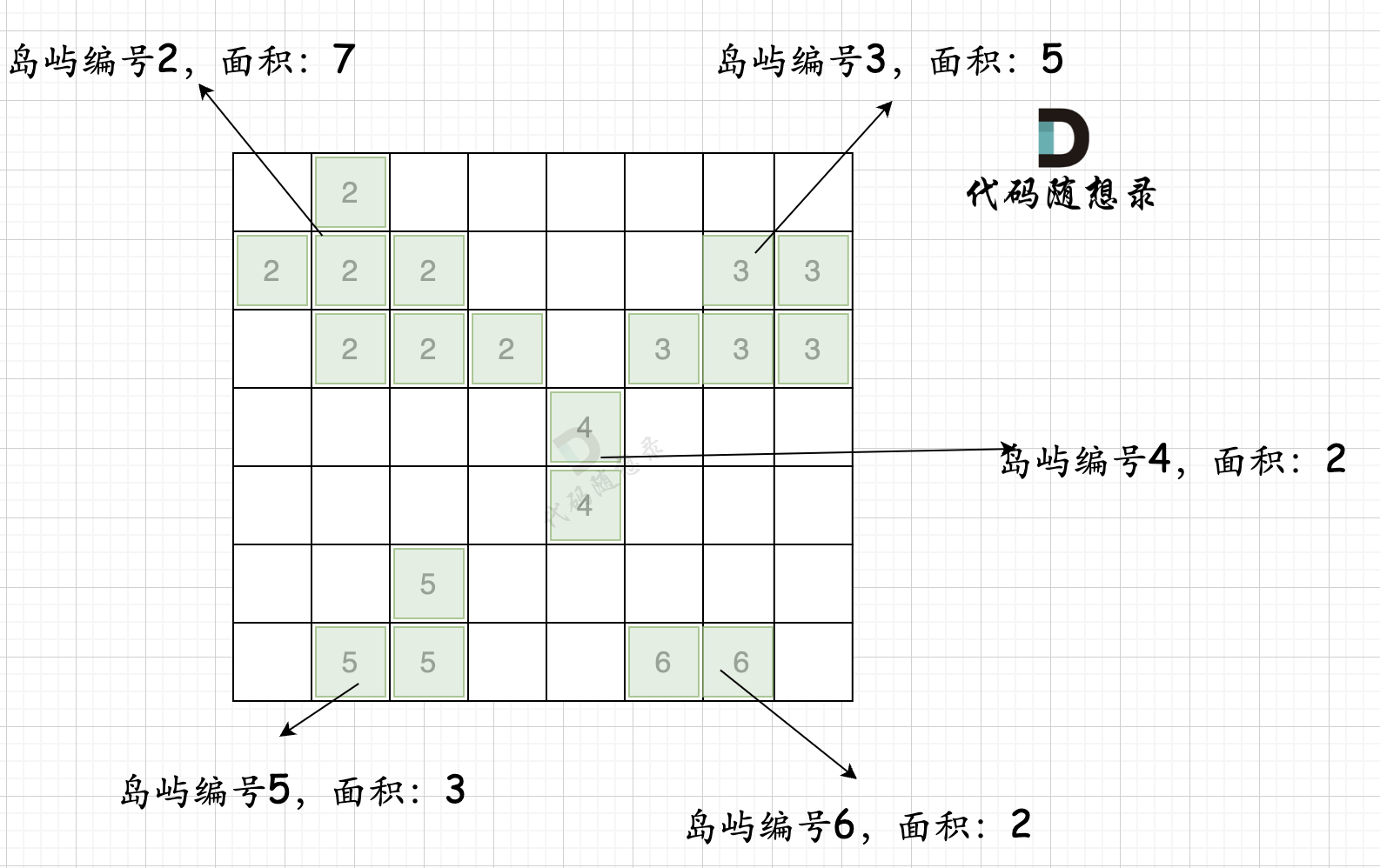
第一步,则遍历题目,并将岛屿到编号和面积上的统计,过程如图所示:
本过程代码如下:
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y, int mark) {if (visited[x][y] || grid[x][y] == 0) return; // 终止条件:访问过的节点 或者 遇到海水visited[x][y] = true; // 标记访问过grid[x][y] = mark; // 给陆地标记新标签count++;for (int i = 0; i < 4; i++) {int nextx = x + dir[i][0];int nexty = y + dir[i][1];if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过dfs(grid, visited, nextx, nexty, mark);}
}int largestIsland(vector<vector<int>>& grid) {int n = grid.size(), m = grid[0].size();vector<vector<bool>> visited = vector<vector<bool>>(n, vector<bool>(m, false)); // 标记访问过的点unordered_map<int ,int> gridNum;int mark = 2; // 记录每个岛屿的编号bool isAllGrid = true; // 标记是否整个地图都是陆地for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (grid[i][j] == 0) isAllGrid = false;if (!visited[i][j] && grid[i][j] == 1) {count = 0;dfs(grid, visited, i, j, mark); // 将与其链接的陆地都标记上 truegridNum[mark] = count; // 记录每一个岛屿的面积mark++; // 记录下一个岛屿编号}}}
}
这个过程时间复杂度 n * n 。可能有录友想:分明是两个for循环下面套这一个dfs,时间复杂度怎么回事 n * n呢?
其实大家可以仔细看一下代码,n * n这个方格地图中,每个节点我们就遍历一次,并不会重复遍历。
第二步过程如图所示:
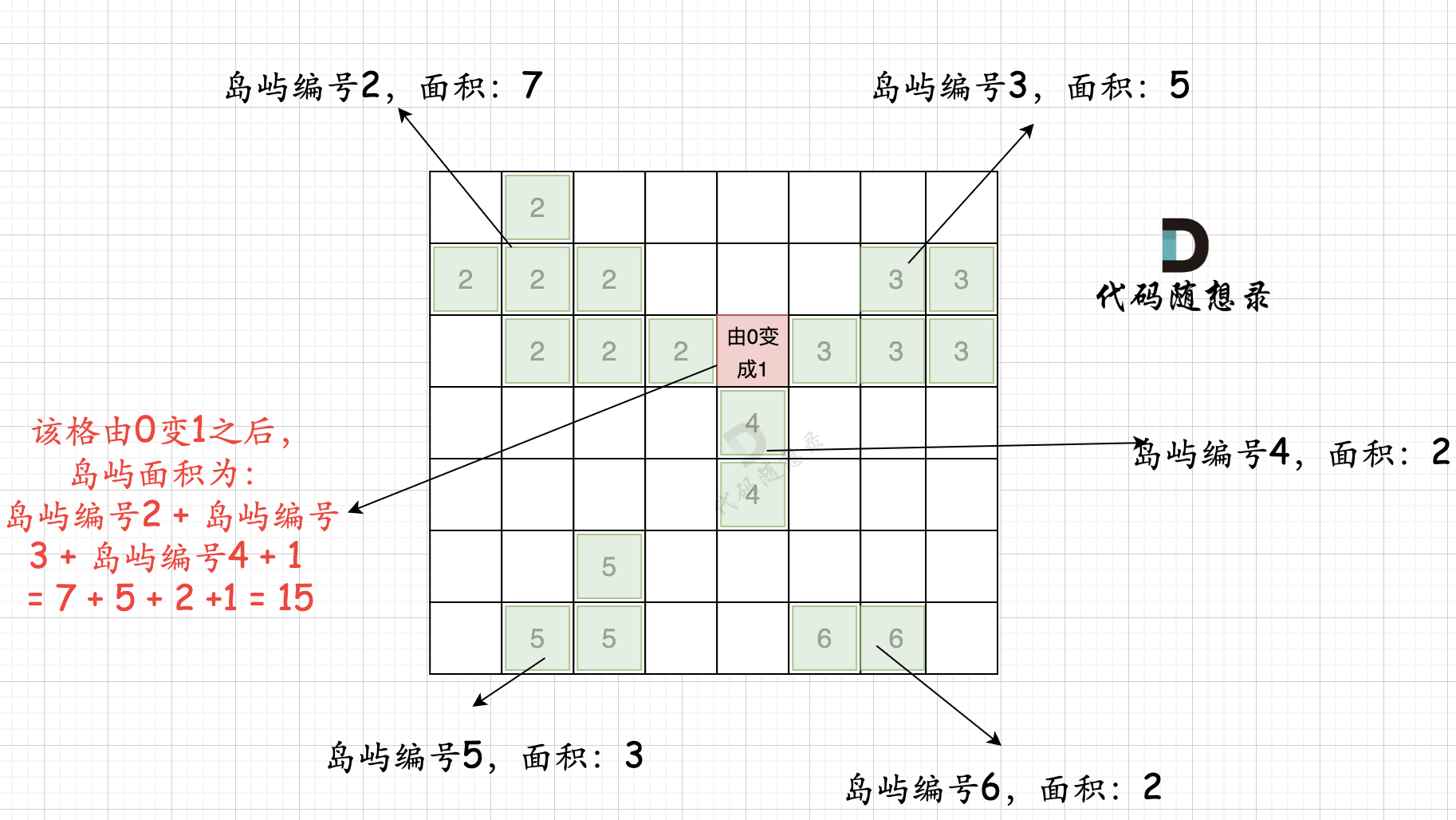
也就是遍历每一个0的方格,并统计其相邻岛屿面积,最后取一个最大值。
这个过程的时间复杂度也为 n * n。
所以整个解法的时间复杂度,为 n * n + n * n 也就是 n 2 n^2 n2。
当然这里还有一个优化的点,就是 可以不用 visited数组,因为有mark来标记,所以遍历过的grid[i][j]是不等于1的。
代码如下:
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void dfs(vector<vector<int>>& grid, int x, int y, int mark) {if (grid[x][y] != 1 || grid[x][y] == 0) return; // 终止条件:访问过的节点 或者 遇到海水grid[x][y] = mark; // 给陆地标记新标签count++;for (int i = 0; i < 4; i++) {int nextx = x + dir[i][0];int nexty = y + dir[i][1];if (nextx < 0 || nextx >= n || nexty < 0 || nexty >= m) continue; // 越界了,直接跳过dfs(grid, nextx, nexty, mark);}
}int main() {cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}unordered_map<int ,int> gridNum;int mark = 2; // 记录每个岛屿的编号bool isAllGrid = true; // 标记是否整个地图都是陆地for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (grid[i][j] == 0) isAllGrid = false;if (grid[i][j] == 1) {count = 0;dfs(grid, i, j, mark); // 将与其链接的陆地都标记上 truegridNum[mark] = count; // 记录每一个岛屿的面积mark++; // 记录下一个岛屿编号}}}
不过为了让各个变量各司其事,代码清晰一些,完整代码还是使用visited数组来标记。
最后,整体代码如下:
#include <iostream>
#include <vector>
#include <unordered_set>
#include <unordered_map>
using namespace std;
int n, m;
int count;int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y, int mark) {if (visited[x][y] || grid[x][y] == 0) return; // 终止条件:访问过的节点 或者 遇到海水visited[x][y] = true; // 标记访问过grid[x][y] = mark; // 给陆地标记新标签count++;for (int i = 0; i < 4; i++) {int nextx = x + dir[i][0];int nexty = y + dir[i][1];if (nextx < 0 || nextx >= n || nexty < 0 || nexty >= m) continue; // 越界了,直接跳过dfs(grid, visited, nextx, nexty, mark);}
}int main() {cin >> n >> m;vector<vector<int>> grid(n, vector<int>(m, 0));for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {cin >> grid[i][j];}}vector<vector<bool>> visited(n, vector<bool>(m, false)); // 标记访问过的点unordered_map<int ,int> gridNum;int mark = 2; // 记录每个岛屿的编号bool isAllGrid = true; // 标记是否整个地图都是陆地for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {if (grid[i][j] == 0) isAllGrid = false;if (!visited[i][j] && grid[i][j] == 1) {count = 0;dfs(grid, visited, i, j, mark); // 将与其链接的陆地都标记上 truegridNum[mark] = count; // 记录每一个岛屿的面积mark++; // 记录下一个岛屿编号}}}if (isAllGrid) {cout << n * m << endl; // 如果都是陆地,返回全面积return 0; // 结束程序}// 以下逻辑是根据添加陆地的位置,计算周边岛屿面积之和int result = 0; // 记录最后结果unordered_set<int> visitedGrid; // 标记访问过的岛屿for (int i = 0; i < n; i++) {for (int j = 0; j < m; j++) {count = 1; // 记录连接之后的岛屿数量visitedGrid.clear(); // 每次使用时,清空if (grid[i][j] == 0) {for (int k = 0; k < 4; k++) {int neari = i + dir[k][1]; // 计算相邻坐标int nearj = j + dir[k][0];if (neari < 0 || neari >= n || nearj < 0 || nearj >= m) continue;if (visitedGrid.count(grid[neari][nearj])) continue; // 添加过的岛屿不要重复添加// 把相邻四面的岛屿数量加起来count += gridNum[grid[neari][nearj]];visitedGrid.insert(grid[neari][nearj]); // 标记该岛屿已经添加过}}result = max(result, count);}}cout << result << endl;}
总结
坚持!!!
相关文章:
代码随想录Day 52|题目:101.孤岛的面积、102.沉没孤岛、103.水流问题、104.建造最大岛屿
提示:DDU,供自己复习使用。欢迎大家前来讨论~ 文章目录 图论part03题目一:101.孤岛的总面积解题思路DFS**BFS** 题目二:102. 沉没孤岛解题思路 题目三:103. 水流问题解题思路优化 题目四:104.建造最大岛屿…...

go webapi上传文件
一、导入依赖 import "net/http" 我这里用到了Guid所以安装依赖 go get github.com/google/uuid 二、main.go package mainimport ("fmt""github.com/jmoiron/sqlx""github.com/tealeg/xlsx""log""path/filepath&q…...

【小沐学GIS】基于Openstreetmap创建Sionna RT场景(Python)
文章目录 1、简介1.1 blender 2、下载和安装2.1 Python2.2 jupyter 3、运行结语 1、简介 1.1 blender https://www.blender.org/ Blender 是一款免费开源的3D创作套件。 使用 Blender,您可以创建3D可视化效果,例如静态图像、3D动画、VFX(…...

网安面试题1
深信服厂商面 自我介绍 我看到你介绍里面有提到独立设计网络拓扑图,你知道内网有哪些攻击途径吗 护网红队有什么成果 sql注入有哪些类型 sql注入的防御方式 讲一个你工作中遇到的应急响应 怎么判断内网的攻击是不是真实攻击 Windows中了勒索病毒你应该怎么办 linux被…...

你了解system V的ipc底层如何设计的吗?消息队列互相通信的原理是什么呢?是否经常将信号量和信号混淆呢?——问题详解
前言:本节主要讲解消息队列, 信号量的相关知识。 ——博主主要是以能够理解为目的进行讲解, 所以对于接口的使用或者底层原理很少涉及。 主要的讲解思路就是先讨论消息队列的原理, 提一下接口。 然后讲解ipc的设计——这个设计一些…...

python爬虫初体验(一)
文章目录 1. 什么是爬虫?2. 为什么选择 Python?3. 爬虫小案例3.1 安装python3.2 安装依赖3.3 requests请求设置3.4 完整代码 4. 总结 1. 什么是爬虫? 爬虫(Web Scraping)是一种从网站自动提取数据的技术。简单来说&am…...

ER 图 Entity-Relationship (ER) diagram 101 电子商城 数据库设计
起因, 目的: 客户需求, 就是要设计一个数据库。 过程, 关于工具: UI 设计,我最喜欢的工具其实是 Canva, 但是 Canva 没有合适的模板。我用的是 draw.io, 使用感受是,很垃圾。 各种快捷键不适应,箭头就是点不住&…...

JavaSE--IO流总览06:字符转换输入(输出)流: InputStreamReader ,OutputStreamWrite
IO流体系(学到哪扩展到哪): 学习字符转换流的目的是为了什么? InputStreamReader---解决不同编码时字符流读取文本内容乱码的问题 OutPutStreamWrite---可以控制写出去的字符使用什么字符集编码 为什么会有乱码呢?因为读取的文件内容编码与…...

浙版传媒思迈特软件大数据分析管理平台建设项目正式启动
近日,思迈特软件与出版发行及电商书城领域的领军企业——浙江出版传媒股份有限公司,正式启动大近日,思迈特软件与出版发行及电商书城领域的领军企业——浙江出版传媒股份有限公司,正式启动大数据分析管理平台建设项目。浙版传媒相…...

漏洞——CVE简介
1、什么是CVE CVE (Common Vulnerabilities and Exposures)(常见漏洞与暴露)是一个标准化的命名系统,用于识别和描述公开披露的网络安全漏洞。CVE 的目的是为漏洞提供唯一的标识符,使安全专家、软件供应商和用户能够统一参考和讨…...

IT行业中的技术趋势与未来展望
IT行业中的技术趋势与未来展望 IT行业作为全球经济发展的重要引擎,正在以惊人的速度推动着科技进步与创新。随着技术的不断演进,一些新的趋势正悄然改变着我们的工作方式和生活方式。本文将探讨当前IT行业中的主要技术趋势以及未来展望,帮助…...

解决 webpack 配置 sass-loader后报错,无法正常build
1. 问题描述 总是打包build报错,本质上css样式语法也没写错在使用 sass-resources-loader 的项目中,开发者常常遇到构建错误或意外的样式行为,这是因为 sass-resources-loader 的作用和使用场景并不总是被正确理解。sass-resources-loader 主…...

CentOS中使用DockerCompose方式部署带postgis的postgresql(附kartoza/docker-postgis镜像下载)
场景 CentOS中使用Docker部署带postgis的postgresql: CentOS中使用Docker部署带postgis的postgresql_centos postgis插件在容器中如何安装-CSDN博客 上面使用Docker搜索和拉取kartoza/postgis时并没有任何限制。 当下如果不能科学上网时,大部分镜像源…...

初识elasticsearch
初识elasticsearch 1.什么是elasticsearch 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能;elasticsearch 是结合kibana、Logstash、Beats,也就是elastic stach(ELK)。被广泛应用在日志数据分析、实时监控等领域。 elastic…...

react hooks--React.memo
基本语法 React.memo 高阶组件的使用场景说明: React 组件更新机制:只要父组件状态更新,子组件就会无条件的一起更新。 子组件 props 变化时更新过程:组件代码执行 -> JSX Diff(配合虚拟 DOM)-> 渲…...

App端测——稳定性测试
稳定性测试项:Crash、ANR、OOM、内存泄漏 crash:应用崩溃,从提测后开始关注,monkey持续上报跟踪 ANR:系统无响应,使用低端机内存小的机型测试,及monkey中关注ANR问题。关于ANR详细:…...

[数据结构与算法·C++] 笔记 1.4 算法复杂性分析
1.4 算法复杂性分析 算法的渐进分析 数据规模 n 逐步增大时, f(n)的增长趋势当 n 增大到一定值以后,计算公式中影响最大的就是 n 的幂次最高的项其他的常数项和低幂次项都可以忽略 大O表示法 函数f,g定义域为自然数,值域非负实数集定义: …...

Hive parquet表通过csv文件导入数据
1. background 已建好了 hive parquet 格式的表, 需要从服务器的csv导入数据至该hive表 2. step 提前上传csv至服务器 /path/temp.csv 创建 textfile 格式的中转表(这里使用内部表,方便删除) ,源表名dw_procurement.dwd_tc_comm_plant ,这里中转表加上了csv后缀 CREATE TA…...

C++ 构造函数最佳实践
文章目录 1. 构造函数应该做什么1.1 初始化成员变量1.2 分配资源1.3 遵循 RAII 原则1.4 处理异常情况 2. 构造函数不应该做什么2.1 避免做大量的工作2.2 不要在构造函数中调用虚函数2.3 避免在构造函数中执行复杂的初始化逻辑2.4 避免调用可能抛出异常的代码 3. 构造函数的其他…...

C++——关联式容器(4):set和map
在接触了诸如二叉搜索树、AVL树、红黑树的树形结构之后,我们对树的结构有了大致的了解,现在引入真正的关联式容器。 首先,先明确了关联式容器的概念。我们之前所接触到的如vector、list等容器,我们知道他们实际上都是线性的数据结…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...
)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)
Unity事件系统实战:用事件驱动重构你的金币拾取逻辑(告别硬编码)在游戏开发中,我们经常会遇到这样的场景:玩家拾取金币后,需要更新UI、播放音效、解锁成就、保存数据……如果把这些逻辑全部写在金币拾取的代…...

如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗
如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗 【免费下载链接】react-native-bottom-sheet-behavior react-native wrapper for android BottomSheetBehavior 项目地址: https://gitcode.com/gh_mirrors/re/react-native-bottom…...

Unity项目DrawCall降不下来?试试用Mesh Baker合并贴图集,保姆级图文教程
Unity性能优化实战:用Mesh Baker合并贴图集降低DrawCall全流程解析当你的Unity项目帧率开始卡顿,Profiler里DrawCall数字居高不下时,合并贴图集往往是解决问题的关键一步。本文将以一个实际项目为例,带你从零开始使用Mesh Baker的…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...