2024年中国研究生数学建模竞赛A/C/D/E题全析全解

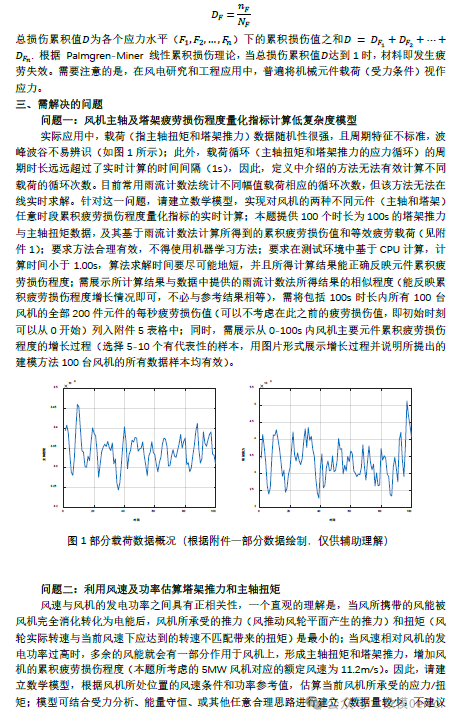


问题一:
针对问题一,可以采用以下低复杂度模型,来计算风机主轴及塔架的疲劳损伤累积程度。
建模思路:
-
累积疲劳损伤计算: 根据Palmgren-Miner线性累积损伤理论,元件的疲劳损伤可以累积。因此,对于每一秒的应力循环,可以根据应力幅值S和元件的S-N曲线计算累积疲劳损伤值。
-
假设在应力幅值F下,材料的最大应力循环次数为,当前应力循环次数为。
-
则该应力幅值下的累积损伤值为。
-
总的累积疲劳损伤值为所有应力水平下损伤值的总和。
-
-
简化雨流计数法:
-
使用简化的雨流计数法来计算每一秒中的应力循环幅值和次数,并估算每秒的疲劳损伤增长。
-
由于经典雨流计数法较为复杂且计算耗时,可以设计一种近似计数法,通过检测应力数据的局部极值来估算应力循环次数,从而降低复杂度。
-
-
基于数据的实时累积疲劳损伤计算:
-
对于提供的每秒的100台风机的数据,直接计算每个时刻的损伤增长,并从0时刻开始进行累积。
-
每一秒的累积疲劳损伤 可以通过上一秒的累积损伤 加上当前时刻的损伤增长量来计算:
-
其中 是简化雨流计数法得到的损伤增长。
-
计算优化:
-
使用CPU进行实时计算时,需优化计算流程,尽可能减少浮点运算,并使用有效的数据结构来存储和访问历史损伤数据。
-
将每秒的计算时间控制在1秒以内。
-
具体实现:
-
针对100台风机的主轴和塔架元件,逐秒计算各自的疲劳损伤,并以累积方式记录。
-
最后将计算结果与基于雨流计数法的参考累积疲劳损伤值进行对比,展示增长趋势是否一致。
结果展示:
-
通过计算100s内100台风机的所有元件的累积疲劳损伤值,可以选择5-10个有代表性的样本,展示其累积疲劳损伤的增长曲线,并说明这些样本能够正确反映累积疲劳损伤的增长情况。
这样,可以满足问题要求中的低复杂度、合理性和实时性。
问题二:利用风速及功率估算塔架推力和主轴扭矩
建模思路
1. 风能与发电功率的关系:
风机的发电功率与风速之间的关系可以通过功率曲线来描述。功率曲线呈现非线性趋势,一般来说,当风速低于额定风速时,发电功率与风速的三次方成正比;当风速达到或超过额定风速时,发电功率达到最大值,不再增加。
功率公式为:
其中:
• 为空气密度(通常取1.225 kg/m³),
• 为风轮扫掠面积,
•为功率系数,通常取值在0.4至0.5之间,
为轮毂处风速。
2. 塔架推力估算:
根据风能转换理论,塔架推力与风速和发电功率之间有一定的关系。推力通常是风轮受力的分量,按如下公式估算:
其中:
为推力系数,与风机的运行状态有关。
3. 主轴扭矩估算:
主轴扭矩可通过功率和风轮转速的关系计算:
其中:
•为风机的角速度,
•为风机当前发电功率。
当风机在额定风速下运行时,转速是稳定的,功率与扭矩的比值可以通过查表或根据风机规格计算。
4. 结合风速与功率的模型:
当风速低于额定风速时,风机功率与风速的三次方成正比,主轴扭矩和塔架推力也会相应变化。
•当风速达到或超过额定风速时,风机的功率保持不变,而主轴扭矩和塔架推力随着风速增大而增加。
具体实现步骤
1. 数据准备:
使用附件2中的风速和发电功率参考值,通过上述公式分别估算每一台风机在每一时刻的塔架推力和主轴扭矩。
2. 计算过程:
•对每台风机的风速和功率进行逐时刻计算,得到塔架推力和主轴扭矩。
•对于塔架推力,使用风速平方关系进行计算。
对于主轴扭矩,根据风机功率和转速的比值计算。
3. 对比计算结果:
将计算得到的塔架推力和主轴扭矩与数据中提供的参考值进行对比,通过计算误差的平方和来评估模型的准确性:
其中为所有时间点的总数。
4. 结果展示:
将100台风机的塔架推力和主轴扭矩计算结果列入附件6的表格中,展示估算值与参考值的对比情况。同时,计算所有时刻的估算值与参考值之间的误差平方和,以展示模型的准确性。
总结
通过该模型,可以利用风速和发电功率参考值来估算风机的塔架推力和主轴扭矩,并与参考数据进行对比。通过误差平方和展示计算结果的准确性,计算结果可以用于进一步分析风机累积疲劳损伤等问题。
问题三:有功调度优化问题构建与实时求解
优化问题概述
目标是对风电场中100台风机的有功功率进行优化分配,确保发电量满足电网调度指令的同时,尽可能降低风机的累积疲劳损伤。
优化目标
目标函数 1:降低主轴累积疲劳损伤:
.....................................
问题四:考虑通信延迟和测量噪声的有功功率优化与求解
问题背景与挑战
实际风电场中,通信延迟和传感器噪声不可避免,导致功率优化调度过程中的数据误差。为了提高系统鲁棒性,优化模型必须能够应对这些随机干扰。
改进优化模型
在问题三的基础上,优化模型需加入以下两方面的改进:
1. 测量噪声处理:通过卡尔曼滤波或移动平均滤波平滑传感器数据,减少噪声干扰。
2. 通信延迟处理:采用历史数据进行线性外推,在通信延迟时预测当前风速和功率值。
优化目标与约束目标函数为:.............................



2024华为杯A题参考论文代码![]() https://download.csdn.net/download/qq_52590045/89779433
https://download.csdn.net/download/qq_52590045/89779433






总领这个题,是属于数据挖掘和数据优化类型的题目,对于数据的要求非常高,数据的精确度和有效性能够直接决定磁心损耗的评价的准确度,所以在进行问题的建模时,首先需要对数据进行数据预处理。
数据预处理的步骤为:数据清洗、数据归一化等等。
数据清洗是数据处理中的重要环节,由于数据源头不一,直接导致数据质量参差不齐,因此必须要做好数据清洗。
去重:移除重复的样本,确保数据多样性
去噪:过滤掉无意义的数据,如广告,拼写错误,噪声图像等
统一格式:确保所有数据采用一致的编码格式(如UTF-8),并且统一时间,日前等标准格式;
数据修复:修正数据中的错误,如拼写,补全等。
数据归一化的方法:
数据归一化是数据预处理中的一个重要步骤,它对于提高机器学习模型的性能、加速训练过程以及改善数据分布特性具有重要意义。以下是关于数据归一化的意义和方法的详细解答:
数据归一化的意义
消除尺度差异:不同特征可能具有不同的尺度和范围,这可能导致某些特征在模型训练中起主导作用,而其他特征的影响被忽略。归一化可以消除特征之间的尺度差异,确保每个特征对模型的贡献相对平等。
-
加速模型收敛:在训练深度神经网络等模型时,数据的归一化可以加速模型的收敛。这是因为在归一化后,模型的参数更新更加稳定,训练过程更容易找到损失函数的最优解。
-
提高模型精度:对于某些算法,如K近邻算法(KNN)和神经网络,特征的尺度对模型的性能有显著影响。归一化可以帮助这些算法更准确地捕捉特征之间的关系,从而提高模型的精度。
-
防止数值问题:在某些计算过程中,如使用梯度下降算法时,如果特征的尺度差异很大,可能会导致数值不稳定或梯度消失/爆炸的问题。归一化有助于避免这类数值问题。
-
提高模型稳定性:归一化可以提高算法的稳定性,使得算法对于不同的数据集或数据子集具有更一致的性能。
数据归一化的方法
数据归一化有多种方法,以下是几种常用的方法:
Min-Max归一化(最小-最大规范化)----常用
方法描述:也称为线性归一化,通过将数据缩放到[0, 1]区间内,实现数据的归一化。
-
公式:
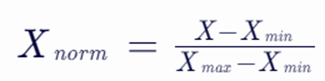
其中,X 是原始数据,Xmin 和 Xmax 分别是数据集中的最小值和最大值,Xnorm 是归一化后的数据。
-
优点:简单直观,易于实现。
-
缺点:对极端值非常敏感,如果数据集中存在离群值,可能会影响归一化效果。
-
Z-Score归一化(标准化)---(本文推荐应用)
-
方法描述:将数据转换为均值为0,标准差为1的正态分布(也称为标准正态分布或高斯分布)。
-
公式:
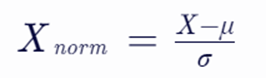
其中,X 是原始数据,μ 是原始数据的均值,σ 是原始数据的标准差,Xnorm 是标准化后的数据。
优点:不受离群值影响,适用于数据分布接近正态分布的情况。
缺点:对于非正态分布的数据,可能不是最佳选择。
小数定标规范化
方法描述:通过移动特征数据的小数位数,将其转换到特定区间内,如[-1, 1]。
公式:根据特征值绝对值的最大值决定移动的小数位数。
优点:适用于不同量级的数据,可以通过调整小数位数来适应不同的区间需求。
缺点:需要手动确定小数位数,且对于极端值可能不太敏感。
非线性归一化方法
方法描述:包括对数变换、平方根变换、指数变换等,通过非线性函数将数据映射到新的区间内。
优点:能够改善数据的分布特性,特别是对于偏态分布的数据。
缺点:需要根据数据的具体分布选择合适的非线性函数。
在选择归一化方法时,需要根据数据的特性和后续算法的需求进行综合考虑。例如,在分类、聚类算法中,如果需要使用距离来度量相似性,或者使用PCA技术进行降维时,Z-Score归一化表现可能更好。而在不涉及距离度量、协方差计算、数据不符合正态分布的情况下,可以使用Min-Max归一化或其他归一化方法。
数据预处理完后,就根据问题对下列问题的分析
问题一:励磁波形分类
思路:
1. 数据准备:读取附件一中的磁通密度数据。
2. 特征提取:分析磁通密度的分布特征及不同波形的形状特征,提取出反映磁通密度分布及波形的形状特征变量。
3. 分类模型建立:利用提取的特征变量建立分类模型,识别出励磁的三种波形(正弦波、三角波和梯形波)。
4. 模型验证:使用附件二中的样本数据验证分类模型的合理性及有效性。
5. 结果填入表格:将分类结果填入附件四(Excel表格)中第2列,并统计出三种波形的各自数量。
数学建模过程:
- 特征提取:可以通过计算磁通密度的时间导数和加速度等特征来描述波形的形状。
- 分类算法:可以使用支持向量机(SVM)、随机森林(Random Forest)或K近邻(KNN)等分类算法。
问题二:斯坦麦茨方程(Steinmetz-equation)修正
思路:
1. 数据分析:分析斯坦麦茨方程在不同温度变化下的磁芯损耗预测效果。
2. 模型修正:构造一种可适用于不同温度变化的磁芯损耗修正方程。
3. 效果比较:比较修正方程与斯坦麦茨方程的预测效果。
数学建模过程:
- 修正方程:在原斯坦麦茨方程基础上,增加温度因素,构造修正方程。
- 效果评估:使用均方误差(MSE)或平均绝对误差(MAE)等指标评估两个模型的预测效果。
..........................................................................................




2024华为杯C题代码![]() https://download.csdn.net/download/qq_52590045/897753262024华为杯C题参考论文
https://download.csdn.net/download/qq_52590045/897753262024华为杯C题参考论文![]() https://download.csdn.net/download/qq_52590045/89774923
https://download.csdn.net/download/qq_52590045/89774923




问题一解答:降水量与土地利用/土地覆被类型的时空演化特征描述
1. 降水量的描述性统计方法
降水量是一个连续变化的变量,可以通过以下几种描述性统计方法进行时空演化特征的总结:
-
平均降水量:统计中国范围内1990至2020年各年份的平均降水量,用于展示降水的时间趋势。
-
年际变化率:计算每年降水量相对于上一年的变化率,展示降水量的波动情况。
-
降水量的空间分布:使用中国区域的降水量分布图,展示各个地理区域的降水量差异。
通过这些统计指标,我们可以得出结论:中国的降水量在1990至2020年间呈现出显著的年际波动,尤其在特定年份(如厄尔尼诺和拉尼娜现象年份),降水量变化更为明显。在空间上,降水量呈现东南沿海地区高,西北内陆地区低的显著分布特征。
代码:
import numpy as npimport matplotlib.pyplot as plt# 假设降水量数据为1990至2020年的逐年平均降水量years = np.arange(1990, 2021)average_precipitation = np.random.uniform(500, 1200, len(years)) # 生成随机数据作为示例# 计算年际变化率annual_change_rate = np.diff(average_precipitation) / average_precipitation[:-1]# 绘制降水量和年际变化率图表plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)plt.plot(years, average_precipitation, marker='o')plt.title("1990-2020年平均降水量")plt.xlabel("年份")plt.ylabel("平均降水量(mm)")........................
2. 土地利用/土地覆被类型的描述性统计方法
土地利用和土地覆被是离散分布的变量,可以通过以下统计方法描述其变化:
-
土地覆被类型的比例:统计每年各类土地覆被类型的比例(如耕地、林地、草地等),展示土地利用的演变趋势。
-
变化速率:计算各类土地利用类型的变化速率,展示土地利用/覆被的突变现象。
-
空间分布图:通过土地利用的空间分布图,展示不同区域土地利用类型的空间变化。
这些方法可以揭示出土地利用类型在1990至2020年间的变化。例如,耕地面积可能随着城市化的进展而减少,林地面积则可能通过植树造林项目有所增加。空间上,南方的森林覆盖率较高,而北方则可能以耕地和草地为主。
# 假设1990至2020年不同覆被类型的数据为随机生成的示例数据land_cover_types = ['耕地', '林地', '草地', '湿地', '灌木丛']years = np.arange(1990, 2021)land_cover_proportions = np.random.dirichlet(np.ones(len(land_cover_types)), len(years)) # 示例数据# 绘制土地覆被类型比例随时间的变化图plt.figure(figsize=(10, 6))for i, land_type in enumerate(land_cover_types):plt.plot(years, land_cover_proportions[:, i], label=land_type)plt.title("1990-2020年土地覆被类型比例变化")plt.xlabel("年份")..................
3. 总结
通过对降水量和土地利用/土地覆被类型的描述性统计方法,我们可以总结出两者在1990至2020年间中国范围内的时空演化特征。降水量表现出较为明显的年际波动,土地利用则随着人类活动的变化而呈现显著的突变,尤其是城市化进程加剧对耕地、森林等覆被类型的影响。
问题2:地形-气候相互作用在极端天气形成过程中的作用
1.问题分析
暴雨等极端天气事件的形成与地形和气候条件密切相关,特别是降水量的分布往往受以下几个主要因素影响:
•气候因素:温度、湿度、风速、气压等因素影响大气的含水量与降水强度。
•地形因素:高山、平原等地形对气流运动有显著的影响,尤其是地形抬升效应(Orographic Lift),当气流遇到高山时,湿气上升冷凝,产生降水。
因此,模型需考虑到气候与地形的相互作用,来解释暴雨的生成机制。
2.模型框架
模型的核心思想是描述地形和气候变量的关系,模拟气流在地形作用下的降水过程。我们将通过以下几个方面建立模型:
•气候输入:气温、湿度、风速等变量。
•地形因素:地形高度、坡度、地形梯度。
•降水输出:在不同地形条件下的降水强度。
我们使用地形抬升模型(Orographic Lift Model)作为基础,结合气候参数来解释极端天气的形成。
3. 数学模型构建
3.1地形抬升模型
当湿润气流遇到高山等地形障碍时,由于地形抬升,空气中水汽冷凝,导致降水增加。这个过程可以通过以下公式来描述:
![]()
其中:
• 表示某个地理位置处的降水量。
•为平地降水量的初始值。
• 为该点的地形高度(海拔)。
• 为气流与地形抬升的衰减系数。
• 是气候条件的影响函数,依赖于温度、湿度、风速和气压梯度。
3.2 气候因子的作用
气候因子对降水量的影响可以通过线性或非线性函数进行建模。我们假设气温、湿度和风速分别对降水量有以下影响:
![]()
....................................
4.模型求解
4.1 数据输入
•气候数据:我们可以从附件中的气候数据集(如气温、湿度、风速)获取历史气象数据,分别计算1990至2020年间不同区域的气候变化特征。
•地形数据:利用附件中的中国数字高程数据(DEM),获得中国各区域的地形高度。
•降水数据:使用中国降水数据集,获取逐日降水数据,并通过上述模型进行拟合。
4.2 数据预处理与模型拟合
首先将气候和地形数据进行空间配准,以确保气候数据与地形数据能够正确匹配。然后,根据历史气象与降水数据,拟合出模型中的参数(如、、等),并进行模型校准。
5. 模型结果分析
通过该模型,我们可以模拟气流在不同地形下的抬升过程以及气候因素对降水的影响:
•地形抬升效应:在高海拔地区,由于地形抬升效应,气流遇到障碍被迫上升,导致湿气冷凝,增加降水。低海拔区域则降水量相对较少。
气候因素影响:气温越高、湿度越大,暴雨等极端天气的发生概率越.....
import numpy as npimport matplotlib.pyplot as plt# 假设已加载的气象与地形数据temperature = np.random.uniform(15, 30, 100) # 气温数据 (°C)humidity = np.random.uniform(50, 100, 100) # 湿度数据 (%)wind_speed = np.random.uniform(0, 10, 100) # 风速数据 (m/s)pressure_gradient = np.random.uniform(1000, 1020, 100) # 气压梯度 (hPa)elevation = np.random.uniform(0, 3000, 100) # 地形海拔 (m)# 参数设置P0 = 10 # 初始降水量 (mm)alpha = 0.001 # 地形抬升衰减系数beta1, beta2, beta3, beta4 = 0.5, 0.3, 0.2, 0.1 # 气象因子权重.................
问题三解答:暴雨成灾的临界条件与未来脆弱地区的预测
1. 问题分析
暴雨等极端天气事件的形成与多种自然条件及人类活动相关,主要涉及以下三个关键因素:
·降雨:降雨量及其时空变异性对暴雨灾害的形成具有最直接的影响,尤其是持续强降雨会造成洪涝灾害。
·地形:地形因素决定了水流的聚集和扩散,山区、平原等不同地形在暴雨灾害中的影响不同。例如,山区的地形抬升效应可能导致局部强降水,而平原地区则可能因排水不畅造成洪涝。
·土地利用:土地利用的变化(如城市化、农业用地的扩展、森林覆盖率下降)会影响水土保持和洪水的管理能力,从而改变暴雨成灾的风险。
2. 从暴雨到灾害的临界条件确定
为了确定暴雨成灾的临界条件,需要考虑上述三个因素的相互作用。暴雨成灾的主要临界条件包括:
·强降雨量的持续时间与强度:暴雨成灾的一个主要临界条件是降雨量超过某一阈值。例如,如果某地区日降雨量超过100 mm,且持续数日,则可能引发严重的洪涝灾害。
·地形因素对水流汇集的影响:地形决定了暴雨后水流的汇集和排水速度。例如,山区的陡峭坡度会加速水流汇集,容易导致泥石流或山洪暴发;而平原地区排水能力较差,容易造成洪涝。
·土地利用对排水能力的影响:城市化地区由于不透水表面增多(如道路和建筑),排水能力大大降低,导致暴雨后的积水难以排走,容易形成城市内涝;而森林覆盖较少的地区,土壤对水的渗透能力下降,容易加剧水土流失和洪水灾害。
基于以上分析,暴雨成灾的临界条件可概括为:
1.降雨强度:日降雨量大于100 mm。
2.地形条件:坡度大于15度的山区容易引发泥石流和山洪,平原地区排水不畅导致洪涝。
3.土地利用:城市化程度高且排水系统不足的地区、森林覆盖率低的农业区风险更高。
3. 2025~2035年脆弱地区预测
结合问题1中降雨量和土地利用/土地覆被变化的时空演化特征,以及问题2中建立的地形-气候模型,我们可以预测2025~2035年中国境内最脆弱的地区。这一预测将基于以下几个关键点:
·降雨变化趋势:根据1990~2020年降雨量的历史变化趋势,预测未来十年中国哪些地区可能经历更频繁或更强烈的暴雨事件。
·土地利用变化:根据过去几十年土地利用的变化趋势,预测未来哪些地区的土地利用变化会导致排水能力下降或水土保持能力降低,如城市化进程加剧的地区、森林覆盖率继续减少的地区。
·地形影响:基于中国数字高程模型(DEM),结合地形特征预测暴雨后可能发生山洪、泥石流或洪涝的高风险区域。
4. 模型构建与脆弱性预测方法
为了实现预测,我们可以构建一个综合模型,将降雨量、地形和土地利用三个因素结合起来进行分析。模型的基本框架如下:
1.降雨预测模型:基于1990-2020年降雨量的时空演化趋势,使用时间序列预测模型(如ARIMA或LSTM)预测未来2025-2035年的降雨变化。
2.土地利用变化模型:根据1990~2020年土地利用类型的变化趋势,预测未来土地利用的进一步变化,特别是城市化进程、农业用地扩展等的影响。
3.地形影响模型:基于中国的数字高程数据,结合暴雨时的水流汇集与排水模式,评估不同地区的洪涝和泥石流风险。
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegression# 假设已加载的历史降雨量和土地利用数据years = np.arange(1990, 2021)rainfall_data = np.random.uniform(500, 1200, len(years)) # 历史降雨量urbanization_data = np.random.uniform(20, 60, len(years)) # 城市化率# 使用线性回归预测未来降雨量和城市化率model_rainfall = LinearRegression()model_urbanization = LinearRegression()future_years = np.arange(2025, 2036)rainfall_prediction = model_rainfall.fit(years.reshape(-1, 1), rainfall_data).predict(future_years.reshape(-1, 1))urbanization_prediction = model_urbanization.fit(years.reshape(-1, 1), urbanization_data).predict(future_years.reshape(-1, 1))# 可视化预测结果plt.figure(figsize=(10, 5))..........
问题四解答:土地利用变化的特征与结构的数学模型
1. 问题分析
中国的土地利用和覆被情况受自然地理和人文地理的双重影响,在中国宏观尺度上,地形、降水、人口分布与土地利用有着明显的关联:
·自然地理特征:地形“三级阶梯”和“800mm等降水量线”是中国自然地理的主要特征。这些自然地理条件影响了不同地区的土地利用类型,如农业、林地、草地等。
·人文地理特征:以“胡焕庸线”为分界线,中国东部人口密集,城市化程度高,土地利用以居住、商业、工业为主;而西部地区人口稀少,更多是林地、草地等自然覆被。
本题要求利用前三问中描述的降雨、地形、人口分布等因素,结合土地利用的变化趋势,建立一个数学模型对土地利用进行简化和综合描述。
2. 模型构建
我们将从自然地理和人文地理两个角度,利用地理大数据对土地利用进行建模,分析其变化特征与结构。土地利用模型主要从以下几个方面构建:
·自然地理因素的影响:基于“三级阶梯”地形和“800mm等降水量线”。
·人文地理因素的影响:基于“胡焕庸线”对人口和社会经济活动的影响。
·土地利用的时空演化:基于土地利用/覆被数据的变化趋势。
2.1 自然地理因素的建模
·三级阶梯地形模型:中国的地形可以大致分为三个阶梯,第一级阶梯是青藏高原,第二级阶梯包括西北和华北的山地与高原,第三级阶梯是东部沿海平原。不同阶梯对应着不同的土地利用类型,例如:
o第一级阶梯:高海拔地区,主要为林地、草地和未开发的荒地。
o第二级阶梯:丘陵、山地为主,适合发展农业、牧业以及林地。
o第三级阶梯:人口密集的平原地区,主要为农业用地、城市和工业用地。
·800mm等降水量线:降水量影响植被类型和农业生产,800mm等降水量线在中国自然地理中有着重要的划分意义。800mm线以南区域降水充足,适合水稻等湿润作物的种植;800mm线以北区域则适合旱地作物种植,如小麦。
................
3.2 模型公式
土地利用的变化可以表示为多个因素的综合影响函数:

import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegression# 假设已加载的历史地形、降水量、人口密度和土地利用数据years = np.arange(1990, 2021)land_use_data = np.random.uniform(30, 70, len(years)) # 土地利用变化数据population_density = np.random.uniform(50, 150, len(years)) # 人口密度变化数据# 使用线性回归预测未来的土地利用变化model_land_use = LinearRegression()future_years = np.arange(2025, 2036)land_use_prediction = model_land_use.fit(years.reshape(-1, 1), land_use_data).predict(future_years.reshape(-1, 1)).................



2024华为杯D题参考论文![]() https://download.csdn.net/download/qq_52590045/89774927
https://download.csdn.net/download/qq_52590045/89774927





2024华为杯E题代码![]() https://download.csdn.net/download/qq_52590045/897753302024华为杯E题参考论文
https://download.csdn.net/download/qq_52590045/897753302024华为杯E题参考论文![]() https://download.csdn.net/download/qq_52590045/89774929↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
https://download.csdn.net/download/qq_52590045/89774929↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
相关文章:
2024年中国研究生数学建模竞赛A/C/D/E题全析全解
问题一: 针对问题一,可以采用以下低复杂度模型,来计算风机主轴及塔架的疲劳损伤累积程度。 建模思路: 累积疲劳损伤计算: 根据Palmgren-Miner线性累积损伤理论,元件的疲劳损伤可以累积。因此,…...

【图虫创意-注册安全分析报告-无验证方式导致安全隐患】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 1. 暴力破解密码,造成用户信息泄露 2. 短信盗刷的安全问题,影响业务及导致用户投诉 3. 带来经济损失,尤其是后付费客户,风险巨大,造…...
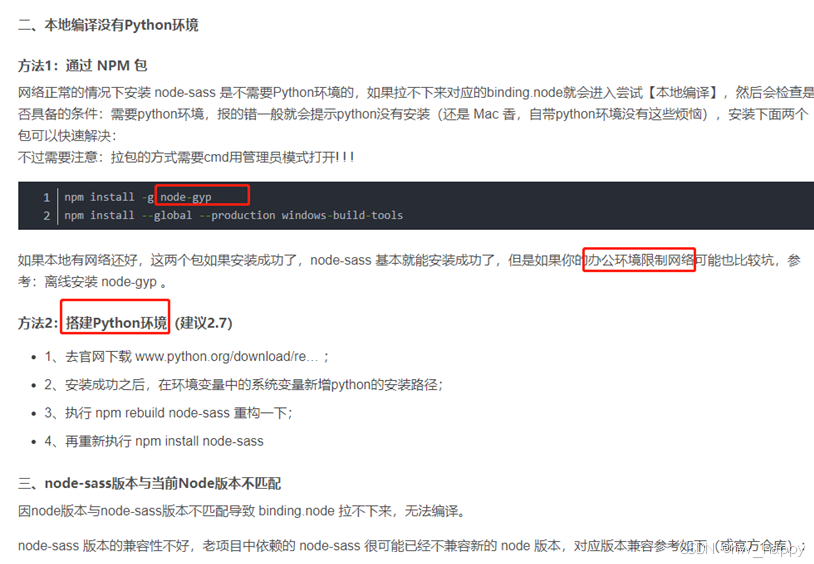
解决 npm ERR! node-sass 和 gyp ERR! node-gyp 报错问题
前言 在对一个项目进行npm i的时候 一直报错 npm ERR! code 1 npm ERR! path D:....\node-sass npm ERR! command failed 显示没有办法安装这个node-sass包 包兼容性 我电脑中默认使用的16的node版本,查找本地项目中这个包的版本和官方对于这个包的兼容ÿ…...

Golang | Leetcode Golang题解之第421题数组中两个数的最大异或值
题目: 题解: const highBit 30type trie struct {left, right *trie }func (t *trie) add(num int) {cur : tfor i : highBit; i > 0; i-- {bit : num >> i & 1if bit 0 {if cur.left nil {cur.left &trie{}}cur cur.left} else …...
:谈谈你对CAS的理解)
每天一道面试题(15):谈谈你对CAS的理解
CAS(Compare And Swap)机制在并发编程中是一个非常重要的概念,主要用于实现原子性操作,避免使用传统的锁机制,从而提高性能。 CAS 的基本原理 CAS 的核心思想是通过比较当前值与预期值来决定是否执行修改。其流程如下…...

如何将MySQL卸载干净(win11)
相信点进来的你肯定是遇到了这个问题,那就是在安装MySQL的时候操作错误,最后结果不是自己想要的。卸载重新安装又发现安装不了。其实最主要的原因就是没有将MySQL卸载干净,那么如何把MySQL卸载干净?下面本篇文章就来给大家一步步介…...

【Linux】简易日志系统
目录 一、概念 二、可变参数 三、日志系统 一、概念 一个正在运行的程序或系统就像一个哑巴,一旦开始运行我们很难知晓其内部的运行状态。 但有时在程序运行过程中,我们想知道其内部不同时刻的运行结果如何,这时一个日志系统可以有效的帮…...
yum 集中式安装 LNMP
目录 安装 nginx 安装 mysql 安装 php 配置lnmp 配置 nginx 支持 PHP 解析 安装 nginx 修改yum源 将原本的yum源备份 vim /etc/yum.repos.d/nginx.repo [nginx-stable] namenginx stable repo baseurlhttp://nginx.org/packages/centos/7/$basearch/ gpgcheck0 enable…...

淘宝扭蛋机小程序,扭蛋机文化下的新体验
在数字化时代中,扭蛋机逐渐从传统的线下机器转移到了线上互联网中,市场得到了创新发展。扭蛋机小程序具有便捷、多样化、个性化的特点,迎合了当下消费者的线上消费习惯,又能够让扭蛋机玩家体验到新鲜有趣的扭蛋。 扭蛋机是一种热…...

Go搭建TcpSocket服务器
1.net包的强大功能 不可否认,go在网络服务开发有强大的优势。net库是一个功能强大的网络编程库,它提供了构建TCP、UDP和HTTP服务器和客户端所需的所有基础工具。 例如,搭建tcp服务器,只需要几行代码。 func main() {listener, …...

hadoop3跑第一个例子wordcount
1、创建目录 hdfs dfs -mkdir -p /user/input2、创建测试文件,并上传文件到hdfs echo 1 > 1.txt hdfs dfs -put 1.txt /user/input3、进入hadoop-3目录,并创建测试文件 cd /app/hadoop-3创建目录 mkdir wcinput cd wcinput 保存wc.input nano wc.i…...

Maven笔记(二):进阶使用
Maven笔记(二)-进阶使用 一、Maven分模块开发 分模块开发对项目的扩展性强,同时方便其他项目引入相同的功能。 将原始模块按照功能拆分成若干个子模块,方便模块间的相互调用,接口共享(类似Jar包一样之间引用、复用)…...
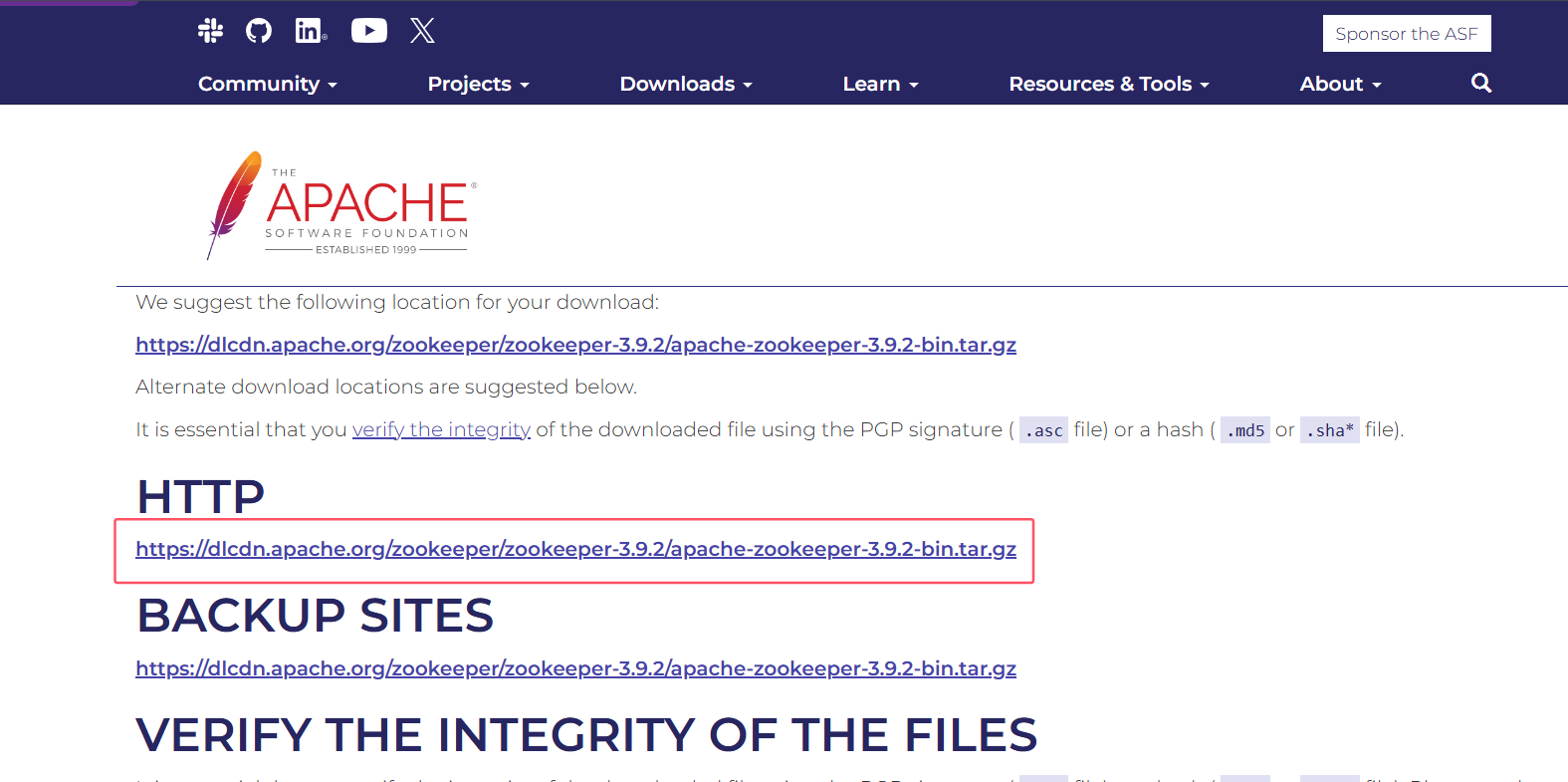
Apache ZooKeeper 及 Curator 使用总结
1. 下载 官网地址:Apache ZooKeeper 点击下载按钮 选择对应的版本进行下载 2. 使用 1、解压 tar -zxf apache-zookeeper-3.9.2-bin.tar.gz2、复制配置文件,有一个示例配置文件 conf/zoo_sample.cfg,此文件不能生效,需要名称为…...
及其应用)
深入探索:MATLAB中的硬件支持包(HSP)及其应用
在MATLAB环境中,硬件支持包(HSP)扮演着至关重要的角色,尤其是在与硬件交互和嵌入式系统开发方面。HSP提供了一套工具和库,使得MATLAB能够与特定的硬件平台进行有效通信,实现代码的生成和优化。本文将详细介…...

5.内容创作的未来:ChatGPT如何辅助写作(5/10)
引言 在信息爆炸的时代,内容创作已成为连接品牌与受众、传递信息与知识、以及塑造文化与观念的重要手段。随着数字媒体的兴起,内容创作的需求日益增长,对创作者的写作速度和质量提出了更高的要求。人工智能(AI)技术的…...

Day26_0.1基础学习MATLAB学习小技巧总结(26)——数据插值
利用空闲时间把碎片化的MATLAB知识重新系统的学习一遍,为了在这个过程中加深印象,也为了能够有所足迹,我会把自己的学习总结发在专栏中,以便学习交流。 参考书目: 1、《MATLAB基础教程 (第三版) (薛山)》 2、《MATL…...

SQL进阶技巧:火车票相邻座位预定一起可能情况查询算法 ?
目录 0 场景描述 1 数据准备 2 问题分析 2.1 分析函数法 2.2 自关联求解 3 小结...

神经网络构建原理(以MINIST为例)
神经网络构建原理(以MINIST为例) 在 MNIST 手写数字识别任务中,构建神经网络并训练模型来进行分类是经典的深度学习应用。MNIST 数据集包含 28x28 像素的手写数字图像(0-9),任务是构建一个神经网络,能够根据输入的图像…...

【ArcGIS微课1000例】0123:数据库中要素类批量转为shapefile
除了ArcGIS之外的其他GIS平台,想要打开ArcGIS数据库,可能无法直接打开,为了便于使用shp,建议直接将数据库中要素类批量转为shapefile。 文章目录 一、连接至数据库二、要素批量转shp一、连接至数据库 打开ArcMap,或者打开ArcCatalog,找到数据库连接,如下图: 数据库为个…...

【Elasticsearch系列十九】评分机制详解
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

终极罗技PUBG压枪宏配置指南:从新手到高手的完整教程
终极罗技PUBG压枪宏配置指南:从新手到高手的完整教程 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 你是否在《绝地求生》中经历过这…...

MCA Selector终极指南:Minecraft世界区块管理的核心技术解析与实战应用
MCA Selector终极指南:Minecraft世界区块管理的核心技术解析与实战应用 【免费下载链接】mcaselector A tool to select chunks from Minecraft worlds for deletion or export. 项目地址: https://gitcode.com/gh_mirrors/mc/mcaselector MCA Selector是一款…...

NotebookLM与Google Drive整合性能瓶颈实测报告:单次索引超10万页PDF时,延迟突增217%的根源与绕行方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM与Google Drive整合性能瓶颈实测报告:单次索引超10万页PDF时,延迟突增217%的根源与绕行方案 延迟突增的核心成因 实测表明,当 NotebookLM 通过 Google Dr…...
首次公开)
为什么顶尖SRE团队已停用Ctrl+F搜索Stack Overflow?Perplexity智能查询协议(P-SOQ v2.1)首次公开
更多请点击: https://intelliparadigm.com 第一章:为什么顶尖SRE团队已停用CtrlF搜索Stack Overflow?Perplexity智能查询协议(P-SOQ v2.1)首次公开 搜索范式的根本性迁移 传统 SRE 工作流中,工程师依赖关…...

Atheon OpenClaw插件:构建Discord Webhook自动化通知系统的核心指南
1. 项目概述与核心价值最近在折腾一个叫 Atheon OpenClaw Plugin 的开源项目,这名字听起来有点酷,是吧?简单来说,这是一个为 Discord 机器人框架 Atheon 设计的插件,核心功能是实现一个“开放之爪”——也就是一个灵活…...

C++ 入门核心语法|从 Hello World 到基础特性一次性吃透
文章目录前言一、C 第一个程序:Hello World二、命名空间 namespace1. 为什么需要命名空间?2. 命名空间定义规则3. 三种使用方式三、C 输入 & 输出1. 核心对象2. 最大优势四、缺省参数(默认参数)1. 定义2. 使用方式3. 声明与定…...

LocalChat:零门槛本地部署开源大语言模型,实现隐私安全的离线AI对话
1. 项目概述与核心价值如果你和我一样,对ChatGPT这类大语言模型的能力感到兴奋,但又对数据隐私、服务依赖和网络延迟心存顾虑,那么LocalChat这个项目可能就是为你量身打造的。简单来说,LocalChat是一个让你能在自己电脑上…...

刘教链|百万美刀的比特币:VanEck的预言与微策略的进化困境
BTC在8万刀附近磨了一周。就在市场踟蹰不前的时候,VanEck抛出一个大胆的预测[1]。一、VanEck的百万预言5月9日,VanEck的投资主管Matthew Sigel说了一番话。他认为比特币会在下一届美国总统任期结束前达到100万美刀[1],算下来大概是2031年前后…...

基于MCP的AI智能体:自动化与优化亚马逊DSP广告实战指南
1. 项目概述:用AI智能体管理亚马逊DSP广告如果你正在寻找一种更高效、更智能的方式来管理亚马逊需求方平台(Amazon DSP)的广告活动,那么这个项目可能就是为你准备的。作为一个在程序化广告领域摸爬滚打了十多年的从业者࿰…...
)
Hack The Box注册失败?别慌,可能是你的‘上网姿势’不对(附最新可用方案)
Hack The Box注册问题排查与解决方案全指南 注册Hack The Box时遇到各种报错提示是许多技术爱好者共同的困扰。作为全球知名的网络安全实战平台,其注册流程确实存在一些技术门槛需要跨越。本文将系统性地分析注册失败的深层原因,并提供多种经过验证的解决…...