【Elasticsearch系列十九】评分机制详解
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。
- 推荐:kwan 的首页,持续学习,不断总结,共同进步,活到老学到老
- 导航
- 檀越剑指大厂系列:全面总结 java 核心技术,jvm,并发编程 redis,kafka,Spring,微服务等
- 常用开发工具系列:常用的开发工具,IDEA,Mac,Alfred,Git,typora 等
- 数据库系列:详细总结了常用数据库 mysql 技术点,以及工作中遇到的 mysql 问题等
- 新空间代码工作室:提供各种软件服务,承接各种毕业设计,毕业论文等
- 懒人运维系列:总结好用的命令,解放双手不香吗?能用一个命令完成绝不用两个操作
- 数据结构与算法系列:总结数据结构和算法,不同类型针对性训练,提升编程思维,剑指大厂
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨

博客目录
- 1.评分机制 TF\IDF
- 2.score 是如何被计算出来的
- 3.分析如何被匹配上
- 4.Doc value
- 5.query phase
- 6.replica shard 提升吞吐量
- 7.fetch phbase 工作流程
- 8.搜索参数小总结
- 9.bucket 和 metric
1.评分机制 TF\IDF
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的统计方法,用以评估一个词在一个文档集中一个特定文档的重要程度。这个评分机制考虑了一个词语在特定文档中的出现频率(Term Frequency,TF)和在整个文档集中的逆文档频率(Inverse Document Frequency,IDF)。
TF(Term Frequency)词频(Term Frequency,TF)表示一个词在一个特定文档中出现的频率。这通常是该词在文档中出现次数与文档的总词数之比。
IDF(Inverse Document Frequency)逆文档频率(Inverse Document Frequency,IDF)是一个词在文档集中的重要性的度量。如果一个词很常见,出现在很多文档中(例如“和”,“是”等),那么它可能不会携带有用的信息。IDF 度量就是为了降低这些常见词在文档相似性度量中的权重。
2.score 是如何被计算出来的

GET /book/_search?explain=true
{"query": {"match": {"description": "java程序员"}}
}
返回
{"took": 5,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 2.137549,"hits": [{"_shard": "[book][0]","_node": "MDA45-r6SUGJ0ZyqyhTINA","_index": "book","_type": "_doc","_id": "3","_score": 2.137549,"_source": {"name": "spring开发基础","description": "spring 在java领域非常流行,java程序员都在用。","studymodel": "201001","price": 88.6,"timestamp": "2019-08-24 19:11:35","pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg","tags": ["spring", "java"]},"_explanation": {"value": 2.137549,"description": "sum of:","details": [{"value": 0.7936629,"description": "weight(description:java in 0) [PerFieldSimilarity], result of:","details": [{"value": 0.7936629,"description": "score(freq=2.0), product of:","details": [{"value": 2.2,"description": "boost","details": []},{"value": 0.47000363,"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details": [{"value": 2,"description": "n, number of documents containing term","details": []},{"value": 3,"description": "N, total number of documents with field","details": []}]},{"value": 0.7675597,"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details": [{"value": 2.0,"description": "freq, occurrences of term within document","details": []},{"value": 1.2,"description": "k1, term saturation parameter","details": []},{"value": 0.75,"description": "b, length normalization parameter","details": []},{"value": 12.0,"description": "dl, length of field","details": []},{"value": 35.333332,"description": "avgdl, average length of field","details": []}]}]}]},{"value": 1.3438859,"description": "weight(description:程序员 in 0) [PerFieldSimilarity], result of:","details": [{"value": 1.3438859,"description": "score(freq=1.0), product of:","details": [{"value": 2.2,"description": "boost","details": []},{"value": 0.98082924,"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details": [{"value": 1,"description": "n, number of documents containing term","details": []},{"value": 3,"description": "N, total number of documents with field","details": []}]},{"value": 0.6227967,"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details": [{"value": 1.0,"description": "freq, occurrences of term within document","details": []},{"value": 1.2,"description": "k1, term saturation parameter","details": []},{"value": 0.75,"description": "b, length normalization parameter","details": []},{"value": 12.0,"description": "dl, length of field","details": []},{"value": 35.333332,"description": "avgdl, average length of field","details": []}]}]}]}]}},{"_shard": "[book][0]","_node": "MDA45-r6SUGJ0ZyqyhTINA","_index": "book","_type": "_doc","_id": "2","_score": 0.57961315,"_source": {"name": "java编程思想","description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。","studymodel": "201001","price": 68.6,"timestamp": "2019-08-25 19:11:35","pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg","tags": ["java", "dev"]},"_explanation": {"value": 0.57961315,"description": "sum of:","details": [{"value": 0.57961315,"description": "weight(description:java in 0) [PerFieldSimilarity], result of:","details": [{"value": 0.57961315,"description": "score(freq=1.0), product of:","details": [{"value": 2.2,"description": "boost","details": []},{"value": 0.47000363,"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details": [{"value": 2,"description": "n, number of documents containing term","details": []},{"value": 3,"description": "N, total number of documents with field","details": []}]},{"value": 0.56055,"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details": [{"value": 1.0,"description": "freq, occurrences of term within document","details": []},{"value": 1.2,"description": "k1, term saturation parameter","details": []},{"value": 0.75,"description": "b, length normalization parameter","details": []},{"value": 19.0,"description": "dl, length of field","details": []},{"value": 35.333332,"description": "avgdl, average length of field","details": []}]}]}]}]}}]}
}
3.分析如何被匹配上
分析一个 document 是如何被匹配上的
- 最终得分
- IDF 得分
GET /book/_explain/3
{"query": {"match": {"description": "java程序员"}}
}

4.Doc value
搜索的时候,要依靠倒排索引;排序的时候,需要依靠正排索引,看到每个 document 的每个 field,然后进行排序,所谓的正排索引,其实就是 doc values
在建立索引的时候,一方面会建立倒排索引,以供搜索用;一方面会建立正排索引,也就是 doc values,以供排序,聚合,过滤等操作使用
doc values 是被保存在磁盘上的,此时如果内存足够,os 会自动将其缓存在内存中,性能还是会很高;如果内存不足够,os 会将其写入磁盘上
倒排索引
doc1: hello world you and me
doc2: hi, world, how are you
| term | doc1 | doc2 |
|---|---|---|
| hello | * | |
| world | * | * |
| you | * | * |
| and | * | |
| me | * | |
| hi | * | |
| how | * | |
| are | * |
搜索时:
hello you --> hello, you
hello --> doc1
you --> doc1,doc2
doc1: hello world you and me
doc2: hi, world, how are you
sort by 出现问题
正排索引
doc1: { “name”: “jack”, “age”: 27 }
doc2: { “name”: “tom”, “age”: 30 }
| document | name | age |
|---|---|---|
| doc1 | jack | 27 |
| doc2 | tom | 30 |
5.query phase
-
搜索请求发送到某一个 coordinate node,构构建一个 priority queue,长度以 paging 操作 from 和 size 为准,默认为 10
-
coordinate node 将请求转发到所有 shard,每个 shard 本地搜索,并构建一个本地的 priority queue
-
各个 shard 将自己的 priority queue 返回给 coordinate node,并构建一个全局的 priority queue
6.replica shard 提升吞吐量
replica shard 如何提升搜索吞吐量
一次请求要打到所有 shard 的一个 replica/primary 上去,如果每个 shard 都有多个 replica,那么同时并发过来的搜索请求可以同时打到其他的 replica 上去
7.fetch phbase 工作流程
-
coordinate node 构建完 priority queue 之后,就发送 mget 请求去所有 shard 上获取对应的 document
-
各个 shard 将 document 返回给 coordinate node
-
coordinate node 将合并后的 document 结果返回给 client 客户端
一般搜索,如果不加 from 和 size,就默认搜索前 10 条,按照_score 排序
8.搜索参数小总结
preference:
决定了哪些 shard 会被用来执行搜索操作
_primary, _primary_first, _local, _only_node:xyz, _prefer_node:xyz, _shards:2,3
bouncing results 问题,两个 document 排序,field 值相同;不同的 shard 上,可能排序不同;每次请求轮询打到不同的 replica shard 上;每次页面上看到的搜索结果的排序都不一样。这就是 bouncing result,也就是跳跃的结果。
搜索的时候,是轮询将搜索请求发送到每一个 replica shard(primary shard),但是在不同的 shard 上,可能 document 的排序不同
解决方案就是将 preference 设置为一个字符串,比如说 user_id,让每个 user 每次搜索的时候,都使用同一个 replica shard 去执行,就不会看到 bouncing results 了
timeout:
主要就是限定在一定时间内,将部分获取到的数据直接返回,避免查询耗时过长
routing:
document 文档路由,_id 路由,routing=user_id,这样的话可以让同一个 user 对应的数据到一个 shard 上去
search_type:
default:query_then_fetch
dfs_query_then_fetch,可以提升 revelance sort 精准度
9.bucket 和 metric
bucket:一个数据分组
city name
北京 张三
北京 李四
天津 王五
天津 赵六
天津 王麻子
划分出来两个 bucket,一个是北京 bucket,一个是天津 bucket
北京 bucket:包含了 2 个人,张三,李四
上海 bucket:包含了 3 个人,王五,赵六,王麻子
metric:对一个数据分组执行的统计
metric,就是对一个 bucket 执行的某种聚合分析的操作,比如说求平均值,求最大值,求最小值
select count(*) from book group by studymodel
bucket:group by studymodel --> 那些 studymodel 相同的数据,就会被划分到一个 bucket 中metric:count(*),对每个 user_id bucket 中所有的数据,计算一个数量。还有 avg(),sum(),max(),min()
觉得有用的话点个赞
👍🏻呗。
❤️❤️❤️本人水平有限,如有纰漏,欢迎各位大佬评论批评指正!😄😄😄💘💘💘如果觉得这篇文对你有帮助的话,也请给个点赞、收藏下吧,非常感谢!👍 👍 👍
🔥🔥🔥Stay Hungry Stay Foolish 道阻且长,行则将至,让我们一起加油吧!🌙🌙🌙
相关文章:

【Elasticsearch系列十九】评分机制详解
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

神经网络通俗理解学习笔记(3)注意力神经网络
Tansformer 什么是注意力机制注意力的计算键值对注意力和多头注意力自注意力机制注意力池化及代码实现Transformer模型Transformer代码实现BERT 模型GPT 系列模型GPT-1模型思想GPT-2模型思想GPT-3 模型思想 T5模型ViT模型Swin Transformer模型GPT模型代码实现 什么是注意力机制…...

【C#】 EventWaitHandle的用法
EventWaitHandle 是 C# 中用于线程间同步的一个类,它提供了对共享资源的访问控制,以及线程间的同步机制。EventWaitHandle 类位于 System.Threading 命名空间下,主要用于实现互斥访问、信号量控制等场景。 创建 EventWaitHandle 创建一个 E…...

设计模式之结构型模式例题
答案:A 知识点 创建型 结构型 行为型模式 工厂方法模式 抽象工厂模式 原型模式 单例模式 构建器模式 适配器模式 桥接模式 组合模式 装饰模式 外观模式 享元模式 代理模式 模板方法模式 职责链模式 命令模式 迭代器模式 中介者模式 解释器模式 备忘录模式 观…...

camtasia2024绿色免费安装包win+mac下载含2024最新激活密钥
Hey, hey, hey!亲爱的各位小伙伴,今天我要给大家带来的是Camtasia2024中文版本,这款软件简直是视频制作爱好者的福音啊! camtasia2024绿色免费安装包winmac下载,点击链接即可保存。 先说说这个版本新加的功能吧&#…...

如何导入一个Vue并成功运行
注意1:要确保自己已经成功创建了一个Vue项目,创建项目教程在如何创建Vue项目 注意2:以下操作均在VS Code,教程在VS Code安装教程 一、Vue项目导入VS Code 1.点击文件,然后点击将文件添加到工作区 2. 选择自己的vue项…...

封装svg图片
前言 项目中有大量svg图片,为了方便引入,所以对svg进行了处理 一、svg是什么? svg是可缩放矢量图形,是一种图片格式 二、使用步骤 1.创建icons文件夹 将icons文件夹放进src中,并创建一个svg文件夹和index.js&…...

tomcat的Catalinalog和localhostlog乱码
找到tomcat安装目录的loging文件 乱码这两个由UTF-8改为GBK...

行人持刀检测数据集 voc yolo
行人持刀检测数据集 9000张 持刀检测 带标注 voc yolo 行人持刀检测数据集 数据集描述 该数据集旨在用于行人持刀行为的检测任务,涵盖了多种场景下的行人图像,特别是那些携带刀具的行人。数据集包含大量的图像及其对应的标注信息,可用于训练…...

基于51单片机的汽车倒车防撞报警器系统
目录 一、主要功能 二、硬件资源 三、程序编程 四、实现现象 一、主要功能 本课题基于微控制器控制器, 设计一款汽车倒车防撞报警器系统。 要求: 要求:1.配有距离, 用于把车和障碍物之间的距离信号送入控制器。 2.配有报警系…...

NLP 文本匹配任务核心梳理
定义 本质上是做了意图的识别 判断两个内容的含义(包括相似、矛盾、支持度等)侠义 给定一组文本,判断语义是否相似Yi 分值形式给出相似度 广义 给定一组文本,计算某种自定义的关联度Text Entailment 判断文本是否能支持或反驳这个…...

FastAPI 的隐藏宝石:自动生成 TypeScript 客户端
在现代 Web 开发中,前后端分离已成为标准做法。这种架构允许前端和后端独立开发和扩展,但同时也带来了如何高效交互的问题。FastAPI,作为一个新兴的 Python Web 框架,提供了一个优雅的解决方案:自动生成客户端代码。本…...
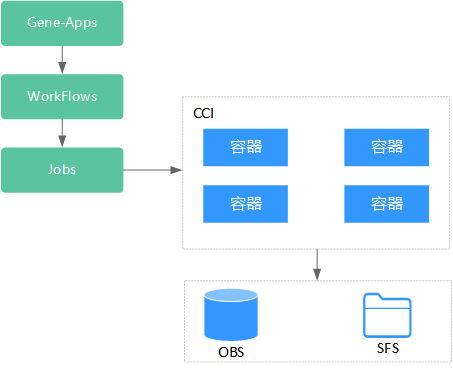
了解云容器实例云容器实例(Cloud Container Instance)
1.什么是云容器实例? 云容器实例(Cloud Container Instance, CCI)服务提供 Serverless Container(无服务器容器)引擎,让您无需创建和管理服务器集群即可直接运行容器。 Serverless是一种架构理念…...

OpenStack Yoga版安装笔记(十三)neutron安装
1、官方文档 OpenStack Installation Guidehttps://docs.openstack.org/install-guide/ 本次安装是在Ubuntu 22.04上进行,基本按照OpenStack Installation Guide顺序执行,主要内容包括: 环境安装 (已完成)OpenStack…...

[系列]参数估计与贝叶斯推断
系列 点估计极大似然估计贝叶斯估计(统计学)——最小均方估计和最大后验概率估计贝叶斯估计(模式识别)线性最小均方估计最小二乘估计极大似然估计&贝叶斯估计极大似然估计&最大后验概率估计线性最小均方估计&最小二乘…...

【Pyside】pycharm2024配置conda虚拟环境
知识拓展 Pycharm 是一个由 JetBrains 开发的集成开发环境(IDE),它主要用于 Python 编程语言的开发。Pycharm 提供了代码编辑、调试、版本控制、测试等多种功能,以提高 Python 开发者的效率。 Pycharm 与 Python 的关系 Pycharm 是…...

【RabbitMQ 项目】服务端:数据管理模块之消息队列管理
文章目录 一.编写思路二.代码实践 一.编写思路 定义消息队列 名字是否持久化 定义队列持久化类(持久化到 sqlite3) 构造函数(只能成功,不能失败) 如果数据库(文件)不存在则创建打开数据库打开 msg_queue_table 数据库表 插入队列移除队列将数据库中的队列恢复到内存…...

SDKMAN!软件开发工具包管理器
认识一下SDKMAN!(The Software Development Kit Manager)是您在Unix系统上轻松管理多个软件开发工具包的可靠伴侣。想象一下,有不同版本的SDK,需要一种无感知的方式在它们之间切换。SDKMAN拥有易于使用的命令行界面(CLI)和API。其…...

《使用 LangChain 进行大模型应用开发》学习笔记(四)
前言 本文是 Harrison Chase (LangChain 创建者)和吴恩达(Andrew Ng)的视频课程《LangChain for LLM Application Development》(使用 LangChain 进行大模型应用开发)的学习笔记。由于原课程为全英文视频课…...

gbase8s数据库常见的索引扫描方式
1 顺序扫描(Sequential scan):数据库服务器按照物理顺序读取表中的所有记录。 常发生在表上无索引或者数据量很少或者一些无法使用索引的sql语句中 2 索引扫描(Index scan):数据库服务器读取索引页&#…...

Cursor AI技能库一键部署指南:提升开发效率的标准化配置方案
1. 项目概述:当AI助手Cursor遇上Everything技能库如果你和我一样,日常开发重度依赖Cursor这款AI驱动的IDE,那你肯定也遇到过这样的场景:想让它帮你写个单元测试,得先花几分钟描述TDD流程;想让它重构一段代码…...

如何快速提取B站视频素材:新手必备的DownKyi音画分离指南
如何快速提取B站视频素材:新手必备的DownKyi音画分离指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&am…...

零命令行部署飞书AI机器人:桌面应用实现开箱即用
1. 项目概述:一个为普通人设计的飞书AI机器人桌面应用 如果你在飞书里用过官方提供的“AI助手”,可能会觉得它功能不错,但总有些限制——不能自由选择模型,无法深度定制,更别提把它无缝集成到你的工作流里了。于是&am…...
)
Linux安装配置小龙虾【openclaw】(飞牛NAS OS)
OneAPI & NewAPI 完全指南:从零开始搭建你的AI模型聚合网关 在AI大模型百花齐放的今天,我们常常需要同时使用多个模型提供商的服务——OpenAI的GPT-4、Anthropic的Claude、Google的Gemini、国内的文心一言、通义千问等等。每个提供商都有自己的API接…...

Armv8-A原子操作指令解析与应用优化
1. A64原子操作指令概述在Armv8-A架构中,A64指令集提供了一组强大的原子操作指令,这些指令在多核处理器环境下对实现线程安全的并发操作至关重要。原子操作的核心特性是保证特定内存操作的不可分割性——即这些操作要么完全执行,要么完全不执…...
:ChatGPT与Gemini,你选错一个就多花237万年运维成本)
仅剩72小时可获取的2026终极对比手册(含Prompt工程调优参数表、国产信创环境适配补丁包、等保2.0三级适配验证清单):ChatGPT与Gemini,你选错一个就多花237万年运维成本
更多请点击: https://intelliparadigm.com 第一章:ChatGPT与Gemini 2026年全面对比的基准定义与评估范式 为确保跨模型评估的科学性与可复现性,2026年主流AI基准已统一采用**多维动态评估范式(MDEP)**,该范…...

10分钟搞定:XUnity.AutoTranslator游戏翻译插件终极使用指南
10分钟搞定:XUnity.AutoTranslator游戏翻译插件终极使用指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏看不懂而烦恼吗?XUnity.AutoTranslator正是你需要的游戏…...

拒绝“见光死”:为什么真正的全域店群RPA必须内置原生指纹浏览器内核?
大家好,我是林焱,一名专注电商底层业务逻辑与企业级 RPA 自动化架构定制的独立开发者。 在 CSDN 的技术交流群里,我经常会遇到一些开发者抛出这样的疑问:“林大,我用 Python 写了一套并发脚本,去管理公司旗…...

Redis++完全指南:C++开发者的终极Redis客户端解决方案
Redis完全指南:C开发者的终极Redis客户端解决方案 【免费下载链接】redis-plus-plus Redis client written in C 项目地址: https://gitcode.com/gh_mirrors/re/redis-plus-plus Redis是一款专为C开发者打造的高性能Redis客户端,它提供了简洁易用…...

Model2Vec最佳实践:10个技巧让你的嵌入模型又快又好
Model2Vec最佳实践:10个技巧让你的嵌入模型又快又好 【免费下载链接】model2vec Fast State-of-the-Art Static Embeddings 项目地址: https://gitcode.com/gh_mirrors/mo/model2vec Model2Vec是一个革命性的静态嵌入模型技术,它能将任何句子转换…...