神经网络通俗理解学习笔记(3)注意力神经网络
Tansformer
- 什么是注意力机制
- 注意力的计算
- 键值对注意力和多头注意力
- 自注意力机制
- 注意力池化及代码实现
- Transformer模型
- Transformer代码实现
- BERT 模型
- GPT 系列模型
- GPT-1模型思想
- GPT-2模型思想
- GPT-3 模型思想
- T5模型
- ViT模型
- Swin Transformer模型
- GPT模型代码实现
什么是注意力机制
注意力机制的发展史
Attention Mechanism
Mnih V, Heess N, Graves A. Recurrent models of visual attention, 2014.
Vaswani A, et al. Attention is alyouneed, 2017. (Tansformer首篇文章)
生物学中的注意力
从众多信息中选择出对当前任务目标更关键的信息
深度学习中的注意力机制
让神经网络能够更加关注图像中的重要特征,而不是整张图像
编解码器架构
大多数注意力机制都附着在Encoder-Decoder框架下
注意力机制是一种思想,本身并不依赖于任何框架


编码器的信息被压缩到编码器和解码器之间固定长度的向量
会导致很多信息的损失
存在信息瓶颈的问题
解决办法:
NLP中的注意力机制
上下文向量c应可访问输入序列所有部分,而不仅是最后一个
每一时刻产生不同的语言编码向量,表示不同的关注区域

注意力机制的类型
隐式注意力:非常深的神经网络已经学会了一种形式的隐式注意
显式注意力:根据先前输入的记忆“权衡”其对输入的敏感度
注意力机制的类型
软注意力:函数在其域内平滑变化,因此是可微的
硬注意力:用随机抽样模型代替了确定性方法,不可微的

编解码器架构中的注意力机制
注意力权重的计算:


建立编码器到解码器之间非线性的映射关系
把yi-1看作是一个查询向量,看和编码器中哪个隐状态hj最相关
注意力的可视化
对齐alignment
权重是动态计算的
允许一对多的关系

注意力的计算
编码器-解码器中的注意力
神经网络的输出
注意力就是衡量两种隐状态间对齐”程度的分数
输入是解码器先前的状态
以及各个时刻编码器的隐藏状态

输出就是一个权重
表示编码器和解码器2种状态间的关联关系。并且捕捉对齐关系
如何计算注意力
注意力就是衡量编码器隐状态与前一时刻解码器输出对齐的分数

第二种最常用,将注意力参数转化为小型的全连接网络
注意力相当于一组可以训练的权重
可以用标准的反向传播算法进行调整
解码器决定原来要输入注意句子中哪一部分
通过让解码器有注意力机制,减轻编码器必须将输入的序列语句中所有信息编码成固定长度向量的这种负担。
通过这种方法信息可以分布在整个序列中
解码器可以相应的选择检索这些信息

注意视角,是解码器来注意编码器中当中的隐状态序列,从他这里去关注重要信息

全局注意力和局部注意力
Global Attention:在整个输入序列上计算注意力分数
Local Attention:只考虑输入单元/标记的一个子集

注意力权重 是剧烈变化,不像全连接权重缓慢变化
而且注意力 的输入是隐状态,全连接输入的是前一层的神经元
自注意力机制
·Self-Attention:序列自身的注意力


把序列转化成一个新序列在输入
可以看作是对输入序列的一种预处理
注意力机制的优点
- 解决了编码器到解码器之间信息传递的瓶颈问题
- 建立编码器状态和解码器间直接联系,消除了梯度消失问题(RNN 级联 造成)
- 提供了更好的可解释性

注意力权重关系图
注意力与transformer
transformer:编码器到解码器两个序列之间的一个转换器
注意力机制某种程度上就是transformer
注意力机制是transformer模型的核心部分
主要处理信息序列的处理问题
通过学习不同位置之间的关系来决定对哪些位置进行重点的关注从而输出更加准确的结果
注意力机制的应用
通用的NLP模型,文本生成、聊天机器人、文本分类等任务
图像分类模型中也可以使用注意力机制,VisionTransformer
键值对注意力和多头注意力
经典注意力机制计算:

直接使用编码器隐状态计算注意力的局限:
注意力分数仅基于隐藏状态在序列中的相对位置而不是他们的内容,限制了模型关注相关信息的能力
故引入键值对

query可以看作是解码器上一回的输出
key value 由input 线性变化得来
value不参与计算 实现相似性和内容的分离
键值对注意力分数的计算:

dk是向量的维度
QK相当于求了相似性
Q、K、V本质都是输入向量的线性变换
W都是训练得到的

当key和value相等 就回到了前面的经典注意力机制
key value分离带来更多灵活性
多头注意力机制
Multi-Head Attention:多个查询向量


每个Q关注X不同的角度 不同部分
使模型学习到更加丰富的内容
捕获X更多信息
并行还能提高训练效率
自注意力机制
Self-Attention:
The animal didn’t cross the street it was too tired.because
it到底知道animal还是street呢

自注意
可以让模型聚焦在输入的重要部分,忽略不相关信息
能处理变长的信息 图像文本等
而且可以在不改变模型结构情况下,加强模型的表示能力
还能减少模型的复杂度,因为只对关键信息进行处理
获取输入向量的OKV值
三个权重矩阵训练得到
Query:查询
Key:键
Value:值

qkv分别由词嵌入向量与权重相乘得到
自注意力分数
查询向量q和各个单词的键向量求点积运算

Softmax归一化
除以key向量维度的平方根
使得梯度更加稳定

softmax求出来的注意力分布
表示每个词对各个位置的关注程度
注意力加权求和
保留想关注的词
淹没不相干的词
加权和为自注意力输出

汪意力矩阵计算
一次性计算出所有位置的的Attention输出向量

QK 相乘是求相似度
softmax是为获取自注意力分布
K和V分离是为了使模型更灵活捕获更多信息
V保存了输入的内容
Z表示序列自身内部不同元素间的注意力关系
自注意力机制的理解
计算输入序列每个元素与其余元素之间的相关性得分

注意力池化及代码实现



颜色越浅表示权重越大
注意力池化
Q与K的计算构成注意力池化
注意力池化对输入进行选择并生成最终输出
对信息筛选的本身其实就是池化
对输入进行选择并生成输出这一过程就是池化

非参数注意力池化
非参数就是不用训练
,
- 平均注意力池化

-
通用注意力池化公式

-
Nadaraya-Watson核回归公式









参数注意力池化
令查询O和键K之间的距离乘以可学习参数w

Transformer模型
RNN 和LSTM 都存在梯度爆炸的问题
transformer通过自注意力机制的建模避免了这一问题
模型结构
六个编码器串联
六个解码器串联
编解码器互联

编码器把输入变成一些向量
解码器则利用这些向量来输出序列
两者通过注意力机制交互,使得解码器能够根据输入序列生成输出序列
可以理解为 彼此通过多次非线性变化在不同空间提取更多特征
编码器的结构相同,但不共享权重

嵌入算法转化为向量
超参数:512

每个词都独立
词与词间的关系通过自注意力机制来表达
前向反馈没有相互之间的计算,因此前向反馈层可以并行运算

多头自注意力层

一个输入X会生成不同的Q、K、V
得到不同的Z
然后再拼接他们
扩展模型关注不同位置的能力
为注意力层提供了多个表示子空间
有点类似CNN中的不同卷积核
用于捕捉输入空间不同维度特征
不同颜色代表不同头
颜色深浅代表自注意力权重
以it为例,编码时关注重点
- The animal
- tired

一个头关注animal
一个头关注tired
位置嵌入
为了让模型了解单词的顺序,我们添加了位置编码向量
embedding 单词嵌入向量可以通过预训练的word2vector 或者 glove 获取 或者训练得到
位置编码 使用正余弦函数定义

transformer并不是RNN结构而是使用全局信息,无法利用单词顺序信息,所以要引入位置嵌入向量保存位置信息
残差结构
更容易学习复杂特征
避免梯度消失和爆炸
训练更稳定,收敛快

每一步解码都要编码器的输出来生成输出序列中下一个单词的表示
通过连接编码器和解码器,模型可以有效利用编码器对输入序列的理解,从而输出更有效输出序列
也可以避免信息丢失问题,从而提高模型整体性能

编解码器协同工作


线性层和softmax层
线性层:转化为logits向量
每个单元格对应一个单词分数
softmax层:转化为概率
选择具有最高概率的单词作输出

优缺点
与RNN相比更易并行化训练;本身无单词顺序,要加入位置嵌入
重点是自注意力结构OKV矩阵;多头注意力含多个自注意力模块

Transformer代码实现




















在这里插入图片描述








数据太烂了,并不是说transformer不行
可以借鉴代码
BERT 模型
BERT是什么
Bidirectional Encoder Representations from Transformers
Transformer编码器堆叠;预训练+精调两步结构

模型结构
主要特点在于其双向性,利用双向语言表示来训练模型
三种transformer的变体

BERT 箭头是双向
GPT只是单向
传统transformer模型只考虑左边语境对当前词语的影响
BERT同时考虑了左右2侧的语境
使其能在语义和语法方便更好理解文本
模型结构
主要特点在于其双向性,利用双向语言表示来训练模型
ELMo箭头也是双向,但与BERT目标函数不同

BERT特色:
Embedding词嵌入
将文本中的词语(或字符)转化为向量表示
通过预训练好的词向量矩阵来实现,用来捕捉词语间语义关系

预训练: Masked语言模型
通过随机掩盖一些词语学习语义关系,更好地理解上下文信息

预训练:下一句预测
面向问答和自然语言推理任务
使模型理解两个句子间关系
语料选文档级别的
预训练可达97-98%准确率

精调Fine-Tuning
通常只会更新BERT模型的最后一层
对于句子级别分类任务中,增加softmax层


精调Fine-Tuning
MNLI 评估文本推理任务能力
QQP 和 QNLI 测试问答任务效果
STS-B 测试语义相似度判定效果
MRPC测试抄袭检测中的效果
RTE 评估文本蕴含任务的能力
SWAG 评估推理生成任务能力

SST-2 测试情感分析任务效果
COLA 测试模型在语言规则接受性判定任务中的效果
SQUAD 测试模型在问答任务中的效果
CONLL-2003 NER 测试模型在命名实体识别任务中的效果
优点
效果显著
能力强
通用性强
缺点·
计算复杂度高
训练数据量大
解释性差
GPT 系列模型

GPT-1模型思想
传统监督学习的缺点:高质量标注数据获取难,模型泛化难
将无监督的预训练与有监督的下游任务精调相结合
高质量数据少,那就用transformer 的decoder来生成 进行预训练
所以是生成式预训练模型

BERT用的是transformer的encoder
GPT用的是decoder
GPT更适合文本生成领域
GPT-1模型架构
12个Transformer中的Decoder模块经修改后组成

GPT-1无监督预训练

GPT-1有监督精调

GPT-1数据集
BookCorpus数据集:7000本没有发布的书籍

GPT-1 性能
- 在监督学习12个任务中9个SOTA
- 比LSTM模型稳定,泛化能力强
- 简单的领域专家,而非通用语言学家
- 无监督生成式预训练替代监督式学习
GPT-2模型思想
实现多任务在同一模型上学习,扩增数据集和模型参数

GPT-2模型思想
任何有监督任务都是语言模型的一个子集
当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学司的任务

GPT-2 数据集
WebText:Reddit上高赞文章
800万篇,40G
移除wikipedia文章
GPT-2 模型参数
字典大小 为50257
滑动窗口大小为 1024
batchsize大小为 512
残差层初始化值用 1/N 缩放

GPT-2 性能
8个语言模型中7个SOTA
Children’s Book Test”数据集命名实体识别任务超SOTA7%
LAMBADA"数据集将困惑度从99.8降到8.6
阅读理解数据中超过4基线模型中3个
GPT-3 模型思想
海量参数1750亿,45TB训练数据,大力出奇迹!

对话模式
对模型进行引导,教会它应当输出什么内容

元学习 Meta-Learning
通过学习任务间共性和差异,发现规律,并将其应用到新任务

情景学习 In-context Learning
从上下文信息中学习语言含义和语法规则,来提高模型性能

根据提示情境,有针对性回答
Prompt学习方法
用户:你觉得tiktok是个好应用吗?
GPT: Do you think tiktok is a good app?
GPT:tiktok是什么呀?
GPT:我不能做出有偏袒的评价
零样本、单样本、少量样本
Zero-shot Learning
One-shot Learning
Few-shot Learning
GPT3中使用了这三种学习方式

GPT-3 数据集
根据数据集的不同的质量赋予了不同的权值

GPT-3 模型参数
96层的多头transformer,头个数为 96
词向量的长度是 12,888

GPT-3 性能
在很多复杂的NLP任务中取得了非常震惊的效果
transformer架构,模型结构并没有创新性的设计
典型不足:
- 不会判断命题有效与否
- 难保证生成文章不含敏感内容
- 不能保证长文章的连贯性,存在不停重复问题

1代主要是无监督生成式预训练
2代主要是多任务学习
3代主要是情境学习
模型结构上变化不大,主要差别在模型参数量和训练数据爆炸式增长
T5模型
transformer的重要变体
google19年出品的预训练模型
基本思想
T5:Transfer Text-to-Text Transformer

基本思想
将所有 NLP任务都转化成 Text-to-Text(文本到文本)任务
词表示发展史

历史贡献
70多项实验
34页论文
大规模实证评估
重要的迁移学习基准
模型结构
预训练策略:编解码器结构、语言模型、基于前缀的语言模型

三种不同的注意力机制掩码操作:

预训练策略
关键步骤的探索流程分四个方面比较

自监督的预训练方法:


预训练数据集
C4 dataset: Colossal Clean Crawled Corpus,750G训练数据

删去重复的
模型版本
参数量越大模型的效果也会越好


ViT模型
transformer在视觉领域的应用
Transformer的好处
- 更容易将序列数据并行化(RNN是将一个单词作为输入,每次一个,transformer可以将句子中所有单词作为输入)
- 注意力机制捕获上下文信息(可以访问过去信息,RNN只能一定程度上访问,长期信息容易丢失)
- 位置嵌入可存储单词的位置信息
模型结构:
图片切分预处理
patch+position嵌入
Transformer编码器
MLP头及分类

数据预处理

Patch和位置嵌入
用全连接层对维度进行缩放Patch Embedding:)

transformer编码器
Layer Norm
QKV分离
残差跳线连接

MLP头
把之前额外添加的分类专属向量单独提取出来
分类头其实就是一个全连接层


性能对比
在浅层和深层表示之间具有更多相似性
能从浅层获得全局表示,也能从浅层的局部表示学习信息
跳线连接比ResNet中的影响更大,且显著影响表示的性能和相似性
比 ResNet 保留了更多的空间信息
能够学习大规模数据里的高质量中间表示
CNN 只关注感受野内的信息,而不关注全局信息
可以视为一个简化版的自注意力模型


Swin Transformer模型
shift+windows
CNN和transformer结合
要解决的问题
图像目标尺度变化大时,不同场景下Transfomer结构性能不稳定
图像分辨率高、像素点多,全局自注意力机制的运算量大
使用移动窗口,将注意力限制在局部范围内,但是保持跨窗口的连接

极大减少计算量
模型结构
层次化设计:包含四个阶段,每个都会缩小特征图分辨率
W-MSA:Window Multi-head Self Attention
SW-MSA: Shifted Window Multi-head Self Attention

输入预处理
Patch Partition:把图片切成x4的patch,i通过嵌入操作向量化
单个patch特征维度为4x4x3=48维

四个阶段
每阶段由线性嵌入/合并层和多个swin transformer单元组成
图像本身大小没有改变,但注意力计算的区域在变
Swin Transformer 块
W-MSA窗口多头自注意力
SW-MSA移位窗口多头自注意力
局部窗口会损失很多信息,然后使用移动窗口来补偿

类似左图窗口边界信息丢失,然后通过右图捕获这些信息
窗口注意力
将注意力的计算限制在每个窗口内,减少了计算量
在计算注意力时加入相对位置编码

移动窗口多头自注意力机制
将窗口在水平和垂直方向上移动一定步长生成新窗口
把领域的因素考虑了进来,扩大了注意力机制的感受野
窗口数量多怎么解决?
特征图循环移位计算
对特征图向左上方向循环移位,并给注意力设置mask
能在保持原有的窗口个数下,使得最后的计算结果等价

掩码MSA操作

只进行同编号的KV相乘
总体上借鉴了CNN的思想
比较典型的transformer变体
GPT模型代码实现
训练一个聊天机器人


口语化多人聊天对话数据


\t 替换成sep标记 用于分割段落或句子
聊天机器人通常是给定上文输出下文


构建数据集


填充数据,保证批内数据长度一致


GPT模型 就是transformer的decoder















相关文章:
神经网络通俗理解学习笔记(3)注意力神经网络
Tansformer 什么是注意力机制注意力的计算键值对注意力和多头注意力自注意力机制注意力池化及代码实现Transformer模型Transformer代码实现BERT 模型GPT 系列模型GPT-1模型思想GPT-2模型思想GPT-3 模型思想 T5模型ViT模型Swin Transformer模型GPT模型代码实现 什么是注意力机制…...

【C#】 EventWaitHandle的用法
EventWaitHandle 是 C# 中用于线程间同步的一个类,它提供了对共享资源的访问控制,以及线程间的同步机制。EventWaitHandle 类位于 System.Threading 命名空间下,主要用于实现互斥访问、信号量控制等场景。 创建 EventWaitHandle 创建一个 E…...

设计模式之结构型模式例题
答案:A 知识点 创建型 结构型 行为型模式 工厂方法模式 抽象工厂模式 原型模式 单例模式 构建器模式 适配器模式 桥接模式 组合模式 装饰模式 外观模式 享元模式 代理模式 模板方法模式 职责链模式 命令模式 迭代器模式 中介者模式 解释器模式 备忘录模式 观…...

camtasia2024绿色免费安装包win+mac下载含2024最新激活密钥
Hey, hey, hey!亲爱的各位小伙伴,今天我要给大家带来的是Camtasia2024中文版本,这款软件简直是视频制作爱好者的福音啊! camtasia2024绿色免费安装包winmac下载,点击链接即可保存。 先说说这个版本新加的功能吧&#…...

如何导入一个Vue并成功运行
注意1:要确保自己已经成功创建了一个Vue项目,创建项目教程在如何创建Vue项目 注意2:以下操作均在VS Code,教程在VS Code安装教程 一、Vue项目导入VS Code 1.点击文件,然后点击将文件添加到工作区 2. 选择自己的vue项…...

封装svg图片
前言 项目中有大量svg图片,为了方便引入,所以对svg进行了处理 一、svg是什么? svg是可缩放矢量图形,是一种图片格式 二、使用步骤 1.创建icons文件夹 将icons文件夹放进src中,并创建一个svg文件夹和index.js&…...

tomcat的Catalinalog和localhostlog乱码
找到tomcat安装目录的loging文件 乱码这两个由UTF-8改为GBK...

行人持刀检测数据集 voc yolo
行人持刀检测数据集 9000张 持刀检测 带标注 voc yolo 行人持刀检测数据集 数据集描述 该数据集旨在用于行人持刀行为的检测任务,涵盖了多种场景下的行人图像,特别是那些携带刀具的行人。数据集包含大量的图像及其对应的标注信息,可用于训练…...

基于51单片机的汽车倒车防撞报警器系统
目录 一、主要功能 二、硬件资源 三、程序编程 四、实现现象 一、主要功能 本课题基于微控制器控制器, 设计一款汽车倒车防撞报警器系统。 要求: 要求:1.配有距离, 用于把车和障碍物之间的距离信号送入控制器。 2.配有报警系…...

NLP 文本匹配任务核心梳理
定义 本质上是做了意图的识别 判断两个内容的含义(包括相似、矛盾、支持度等)侠义 给定一组文本,判断语义是否相似Yi 分值形式给出相似度 广义 给定一组文本,计算某种自定义的关联度Text Entailment 判断文本是否能支持或反驳这个…...

FastAPI 的隐藏宝石:自动生成 TypeScript 客户端
在现代 Web 开发中,前后端分离已成为标准做法。这种架构允许前端和后端独立开发和扩展,但同时也带来了如何高效交互的问题。FastAPI,作为一个新兴的 Python Web 框架,提供了一个优雅的解决方案:自动生成客户端代码。本…...
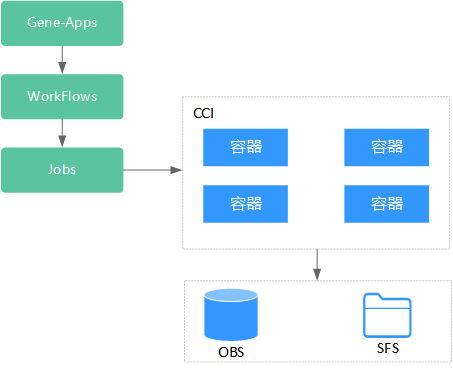
了解云容器实例云容器实例(Cloud Container Instance)
1.什么是云容器实例? 云容器实例(Cloud Container Instance, CCI)服务提供 Serverless Container(无服务器容器)引擎,让您无需创建和管理服务器集群即可直接运行容器。 Serverless是一种架构理念…...

OpenStack Yoga版安装笔记(十三)neutron安装
1、官方文档 OpenStack Installation Guidehttps://docs.openstack.org/install-guide/ 本次安装是在Ubuntu 22.04上进行,基本按照OpenStack Installation Guide顺序执行,主要内容包括: 环境安装 (已完成)OpenStack…...

[系列]参数估计与贝叶斯推断
系列 点估计极大似然估计贝叶斯估计(统计学)——最小均方估计和最大后验概率估计贝叶斯估计(模式识别)线性最小均方估计最小二乘估计极大似然估计&贝叶斯估计极大似然估计&最大后验概率估计线性最小均方估计&最小二乘…...

【Pyside】pycharm2024配置conda虚拟环境
知识拓展 Pycharm 是一个由 JetBrains 开发的集成开发环境(IDE),它主要用于 Python 编程语言的开发。Pycharm 提供了代码编辑、调试、版本控制、测试等多种功能,以提高 Python 开发者的效率。 Pycharm 与 Python 的关系 Pycharm 是…...

【RabbitMQ 项目】服务端:数据管理模块之消息队列管理
文章目录 一.编写思路二.代码实践 一.编写思路 定义消息队列 名字是否持久化 定义队列持久化类(持久化到 sqlite3) 构造函数(只能成功,不能失败) 如果数据库(文件)不存在则创建打开数据库打开 msg_queue_table 数据库表 插入队列移除队列将数据库中的队列恢复到内存…...

SDKMAN!软件开发工具包管理器
认识一下SDKMAN!(The Software Development Kit Manager)是您在Unix系统上轻松管理多个软件开发工具包的可靠伴侣。想象一下,有不同版本的SDK,需要一种无感知的方式在它们之间切换。SDKMAN拥有易于使用的命令行界面(CLI)和API。其…...

《使用 LangChain 进行大模型应用开发》学习笔记(四)
前言 本文是 Harrison Chase (LangChain 创建者)和吴恩达(Andrew Ng)的视频课程《LangChain for LLM Application Development》(使用 LangChain 进行大模型应用开发)的学习笔记。由于原课程为全英文视频课…...

gbase8s数据库常见的索引扫描方式
1 顺序扫描(Sequential scan):数据库服务器按照物理顺序读取表中的所有记录。 常发生在表上无索引或者数据量很少或者一些无法使用索引的sql语句中 2 索引扫描(Index scan):数据库服务器读取索引页&#…...
边缘智能-大模型架构初探
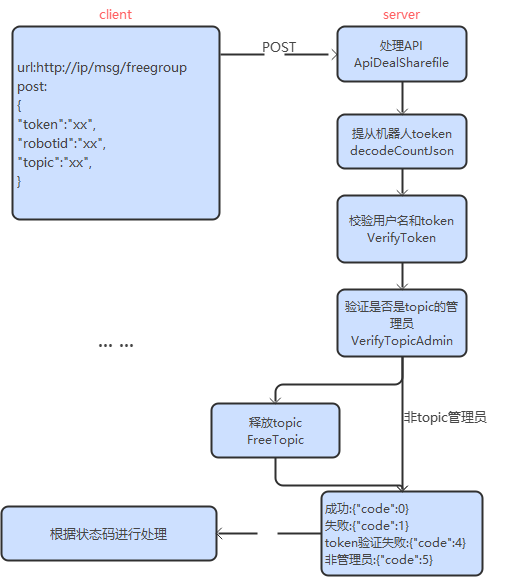
R2Cloud接口 机器人注册 请求和应答 注册是一个简单的 HTTP 接口,根据机器人/用户信息注册,创建一个新机器人。 请求 URL URLhttp://ip/robot/regTypePOSTHTTP Version1.1Content-Typeapplication/json 请求参数 Param含义Rule是否必须缺省roboti…...

Android Perfetto 系列 6:为什么是 120Hz?高刷新率的优势与挑战
Android Perfetto 系列 6:为什么是 120Hz?高刷新率的优势与挑战本文是 Android Perfetto 系列的第六篇,主要介绍 Android 设备上 120Hz 刷新率的相关知识。如今,120Hz 已成为 Android 旗舰手机的标配,本文将讨论高刷新…...

Livox_ros_driver vs driver2:消息类型详解与ROS生态兼容性避坑指南
Livox_ros_driver与driver2深度对比:消息架构解析与ROS生态适配实战 当Livox发布HAP等新一代激光雷达时,技术团队常面临驱动版本选择的困境。livox_ros_driver与livox_ros_driver2看似只是版本迭代,实则反映了ROS生态中传感器接口标准化的深层…...

Django REST framework的应用场景
目录一、鉴权开发框架介绍二、Django REST framework是什么三、如何实现认证、权限与限流功能四、Django REST framework的应用场景一、鉴权开发框架介绍 鉴权开发框架是一种用于实现身份验证和授权的软件开发工具。它可以帮助开发者快速构建安全、可靠的身份验证和授权系统&a…...

【LAMMPS实战】从文献到模拟:精准定位与获取ReaxFF反应力场参数文件
1. 初识ReaxFF反应力场:为什么我们需要它? 第一次接触分子动力学模拟时,我完全被各种力场搞晕了。直到遇到需要模拟化学反应的情况,才发现普通的力场根本不够用。这时候ReaxFF反应力场就像救命稻草一样出现了。简单来说࿰…...

气候降尺度全流程实战:从 CMIP6 数据到极端气候预估,科研人一站式通关
做水文气象、气候学、地理遥感、生态环境等领域的科研人,是不是都逃不过这些噩梦:尺度鸿沟难跨越:GCM 粗网格(>100km)和流域 / 城市精细尺度(<10km)不匹配,动力降尺度成本太高…...

OpenClaw怎么集成?OpenClaw移动云小白6分钟搭建及使用指南【最新!】
OpenClaw怎么集成?OpenClaw移动云小白6分钟搭建及使用指南【最新!】。OpenClaw怎么部署?本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程&#…...

别再用ls了!从Linux文件系统卡顿,看透MinIO多级目录的性能陷阱与正确用法
从Linux文件系统卡顿到MinIO性能陷阱:高效查询的工程哲学 当你在Linux终端输入ls命令后,系统突然卡死——这种经历对许多开发者来说并不陌生。但很少有人意识到,同样的性能陷阱正潜伏在MinIO这类对象存储系统的日常使用中。本文将揭示文件系…...

3步释放20GB空间:给Android用户的系统减负指南
3步释放20GB空间:给Android用户的系统减负指南 【免费下载链接】universal-android-debloater Cross-platform GUI written in Rust using ADB to debloat non-rooted android devices. Improve your privacy, the security and battery life of your device. 项目…...

3秒获取全网歌词:163MusicLyrics让多平台歌词提取效率提升10倍
3秒获取全网歌词:163MusicLyrics让多平台歌词提取效率提升10倍 【免费下载链接】163MusicLyrics Windows 云音乐歌词获取【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 在数字音乐时代,歌词已成为音乐体验…...
到底怎么落地)
别再只盯着ODD了!从特斯拉FSD和华为ADS的实战,聊聊ODC(设计运行条件)到底怎么落地
从特斯拉FSD到华为ADS:ODC实战落地的工程密码 当特斯拉车主在暴雨天启动FSD时,系统会先检查挡风玻璃上的雨滴传感器数据;而华为ADS用户试图在未系安全带状态下激活系统,仪表盘会立即弹出红色警告——这些看似简单的交互背后&…...