深度学习02-pytorch-08-自动微分模块



其实自动微分模块,就是求相当于机器学习中的线性回归损失函数的导数。就是求梯度。
反向传播的目的: 更新参数, 所以会使用到自动微分模块。
神经网络传输的数据都是 float32 类型。
案例1:
代码功能概述:
该代码展示了如何在 PyTorch 中使用 自动微分(Autograd) 计算损失函数相对于权重 w 和偏置 b 的梯度。这是机器学习模型训练中非常重要的步骤,因为这些梯度将用于更新模型的参数,从而最小化损失函数
import torch# 1. 当x为标量时,梯度的计算
def test01():x = torch.tensor(5) # 输入变量x为标量5# 目标值y = torch.tensor(0.) # 目标输出y设置为0# 设置要更新的权重 和 偏置的初始值w = torch.tensor(1., requires_grad=True, dtype=torch.float32) # 权重w初始化为1,并启用梯度计算b = torch.tensor(3., requires_grad=True, dtype=torch.float32) # 偏置b初始化为3,并启用梯度计算# 设置网络的输出值z = x * w + b # 计算线性模型的输出 z = x*w + b (等同于线性回归的公式)# 设置损失函数,并进行损失的计算loss = torch.nn.MSELoss() # 使用均方误差(MSE)作为损失函数loss1 = loss(z, y) # 计算损失,z 是模型的预测值,y 是目标值# 自动微分,计算损失函数相对于w和b的梯度loss1.backward() # 反向传播计算梯度# backward 函数计算的梯度值会存储在张量的grad 变量中print("w的梯度", w.grad) # 打印出损失函数对 w 的梯度print("b的梯度", b.grad) # 打印出损失函数对 b 的梯度test01() w的梯度 tensor(80.)
b的梯度 tensor(16.)
代码讲解:
1. 输入与目标值:
• x = torch.tensor(5):输入为 x = 5,表示输入的特征值。
• y = torch.tensor(0.):目标输出 y 设置为 0,这是我们希望模型最终预测得到的值。
2. 参数的初始化:
• w = torch.tensor(1., requires_grad=True):初始化权重 w 为 1,requires_grad=True 启用对 w 的梯度计算。
• b = torch.tensor(3., requires_grad=True):初始化偏置 b 为 3,同样启用对 b 的梯度计算。
requires_grad=True 的作用是让 PyTorch 知道我们想对这些参数进行梯度计算。
3. 模型计算:
• z = x * w + b:计算模型的输出,类似于线性回归的公式。z 是模型的预测输出。
4. 损失函数:
• loss = torch.nn.MSELoss():选择均方误差(MSE)作为损失函数,用于衡量预测值 z 与目标值 y 之间的误差。
• loss1 = loss(z, y):计算损失值,z 是模型预测输出,y 是目标值。
MSE 的公式为:
在这个例子中,由于我们只使用了一个数据点,损失计算为:
5. 反向传播:
• loss1.backward():通过调用 backward(),PyTorch 会自动计算损失函数对 w 和 b 的梯度。这个过程称为反向传播(Backpropagation)。梯度的计算基于链式法则,PyTorch 会自动追踪所有的计算操作,计算各个参数对损失的导数。
6. 梯度输出:
• w.grad:存储了损失函数对 w 的梯度。
• b.grad:存储了损失函数对 b 的梯度。
案例2:
import torchdef test02():# 输入张量 2x5,表示 2 个样本,每个样本有 5 个特征x = torch.ones(2, 5) # 输入数据,全部初始化为 1# 目标输出张量 2x3,表示我们希望模型预测的输出有 3 个类别y = torch.zeros(2, 3) # 目标输出,初始化为 0# 设置可更新的权重和偏置的初始值# 权重 w 的形状是 5x3,表示输入特征为 5,输出类别为 3w = torch.randn(5, 3, requires_grad=True) # 随机初始化权重,启用梯度计算# 偏置 b 的形状是 3,表示每个输出类别有一个偏置b = torch.randn(3, requires_grad=True) # 随机初始化偏置,启用梯度计算# 计算网络的输出,z = x * w + b# x 的形状是 2x5,w 的形状是 5x3,矩阵乘法后的结果 z 的形状是 2x3z = torch.matmul(x, w) + b # 矩阵乘法和偏置加法# 设置损失函数,并计算损失# 这里使用均方误差(MSE),z 是预测值,y 是目标值loss_fn = torch.nn.MSELoss() # 损失函数为均方误差loss = loss_fn(z, y) # 计算损失,输出一个标量值# 自动微分,计算损失函数相对于 w 和 b 的梯度loss.backward() # 反向传播,计算梯度# 打印权重和偏置的梯度,梯度值存储在 grad 属性中print("w 的梯度:\n", w.grad) # 打印权重 w 的梯度print("b 的梯度:\n", b.grad) # 打印偏置 b 的梯度# 调用函数进行计算
test02()

自动微分 (Autograd) 的工作原理:
• PyTorch 中的 Autograd 是自动微分引擎,它会记录所有张量的计算历史,并根据这些计算图自动执行反向传播,计算参数的梯度。
• 在向前计算过程中,PyTorch 构建了一个动态计算图(计算图是有向无环图 DAG)。当你调用 .backward(),计算图会根据链式法则从损失开始计算每个变量的梯度。
• 计算的梯度会存储在对应张量的 .grad 属性中,然后可以使用这些梯度来更新模型的参数。
总结:
• w.grad 和 b.grad 的值告诉我们,若我们改变 w 或 b,损失函数会如何变化。
• 梯度的计算对于优化模型非常重要,因为我们会使用这些梯度来更新权重和偏置,使得损失函数最小化。
PyTorch 中的 自动微分模块 是通过 autograd 实现的,这是 PyTorch 中的核心功能之一,它可以帮助用户在神经网络的训练过程中自动计算梯度。autograd 模块使得实现反向传播和梯度计算变得非常简单和高效。
核心概念
-
Tensor: PyTorch 的张量 (
Tensor) 是自动微分系统的基本单位。如果将Tensor的requires_grad属性设置为True,则 PyTorch 会开始跟踪所有与该张量相关的操作,并在反向传播时自动计算该张量的梯度。 -
Computational Graph (计算图): PyTorch 会构建一个动态图,记录张量的所有操作。这个图是有向无环图(DAG),图中的每个节点代表一个变量,边代表该变量上发生的操作。当你调用
.backward()时,PyTorch 会根据计算图自动计算每个张量的梯度。 -
梯度 (Gradient): 如果一个张量参与了计算并且
requires_grad=True,在反向传播时可以通过.grad属性获取其梯度值。 -
反向传播: 通过
tensor.backward()来执行反向传播计算张量的梯度,默认情况下会对标量进行求导。
使用案例
-
创建一个张量并启用梯度跟踪:
import torch # 创建一个张量,并启用梯度跟踪 x = torch.tensor([[2.0, 3.0]], requires_grad=True) -
执行一些操作:
y = x * 3 z = y.sum() print(z) -
反向传播:
z.backward() # 对 z 求导 print(x.grad) # 查看 x 的梯度输出:
tensor([[3., 3.]])在这个例子中,
z = x * 3,z.backward()计算了z对x的梯度,结果为3。
PyTorch 自动微分的几个重要点:
-
requires_grad=True: 如果需要对某个张量求导,必须将其
requires_grad属性设置为True,否则在反向传播时 PyTorch 不会计算该张量的梯度。 -
grad_fn: 每个跟踪计算的张量都有一个
grad_fn属性,代表该张量的创建方式和跟踪的操作。例如,如果你对一个张量做了加法操作,它的grad_fn就会显示AddBackward0。print(y.grad_fn) # <MulBackward0 object at 0x...> -
.backward():
backward()方法会根据计算图反向传播,自动计算梯度。 -
梯度累加: 每次调用
backward()时,梯度会被累加到.grad中,因此在多次反向传播之前,最好手动将.grad清零,使用x.grad.zero_()。
autograd 的典型使用场景
-
神经网络训练:通过
autograd,我们可以在每次迭代时计算损失函数的梯度,然后使用这些梯度更新网络的参数。 -
自定义梯度计算:可以通过创建复杂的操作来自动推导梯度。
Example: 简单的线性回归
import torch
# 生成数据
x = torch.randn(10, 1, requires_grad=True)
y = 3 * x + 2
# 定义损失函数
loss = (x - y).pow(2).mean()
# 反向传播
loss.backward()
# 查看 x 的梯度
print(x.grad)在这个例子中,loss.backward() 会自动计算 x 对 loss 的梯度。
总结
-
PyTorch 的自动微分机制通过
autograd实现,用户只需要将张量的requires_grad设置为True,在执行反向传播时,PyTorch 会自动计算张量的梯度。 -
通过自动构建计算图,
autograd能够跟踪张量上的所有操作,动态计算梯度,极大地方便了深度学习模型的训练。
相关文章:
深度学习02-pytorch-08-自动微分模块
其实自动微分模块,就是求相当于机器学习中的线性回归损失函数的导数。就是求梯度。 反向传播的目的: 更新参数, 所以会使用到自动微分模块。 神经网络传输的数据都是 float32 类型。 案例1: 代码功能概述: 该…...

使用Python实现深度学习模型:智能宠物监控与管理
在现代家庭中,宠物已经成为许多家庭的重要成员。为了更好地照顾宠物,智能宠物监控与管理系统应运而生。本文将详细介绍如何使用Python实现一个智能宠物监控与管理系统,并结合深度学习模型来提升其功能。 一、准备工作 在开始之前,我们需要准备以下工具和材料: Python环境…...
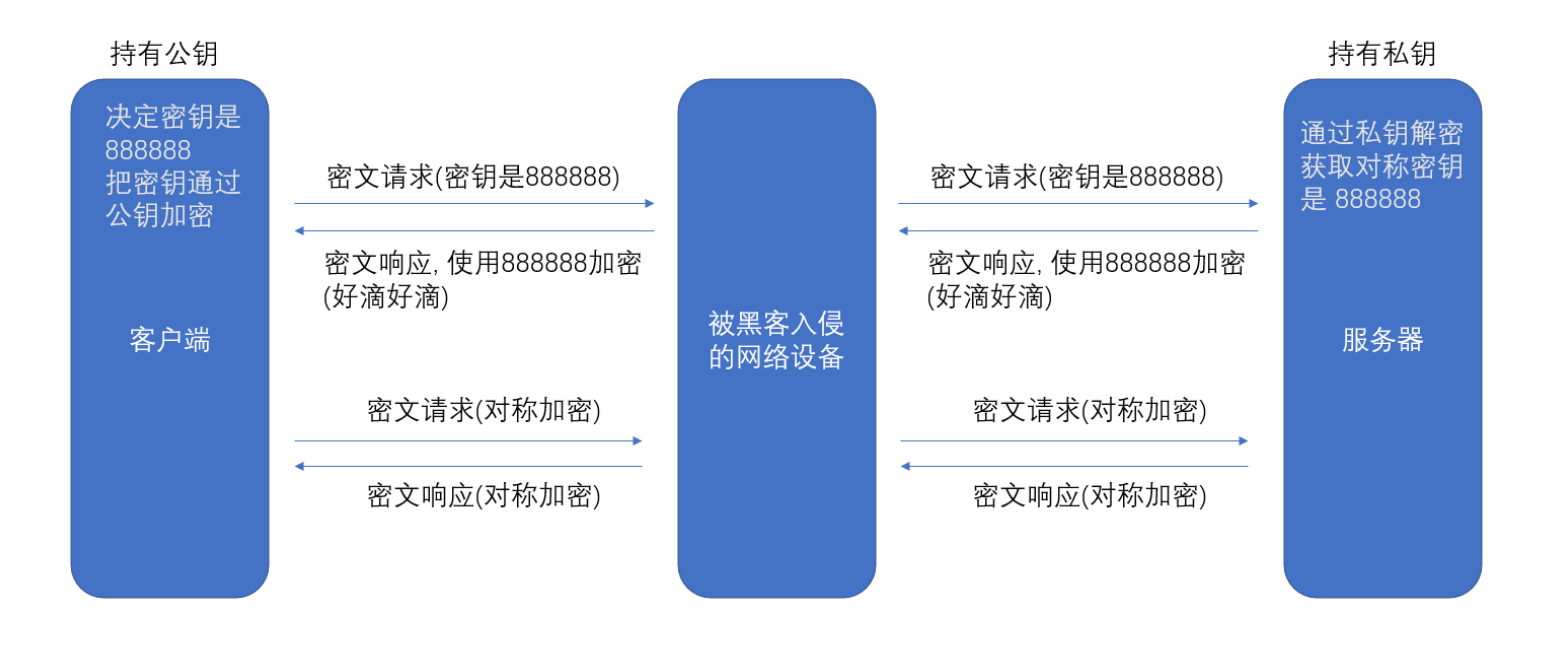
【HTTPS】对称加密和非对称加密
HTTPS 是什么 HTTPS 是在 HTTP 的基础上,引入了一个加密层(SSL)。HTTP 是明文传输的(不安全) 当下所见到的大部分网站都是 HTTPS 的,这都是拜“运营商劫持”所赐 运营商劫持 下载⼀个“天天动听“&…...

MySQL中的LIMIT与ORDER BY关键字详解
前言 众所周知,LIMIT和ORDER BY在数据库中,是两个非常关键并且经常一起使用的SQL语句部分,它们在数据处理和分页展示方面发挥着重要作用。 今天就结合工作中遇到的实际问题,回顾一下这块的知识点。同时希望这篇文章可以帮助到正…...
)
Java 编码系列:集合框架(List、Set、Map 及其常用实现类)
引言 在 Java 开发中,集合框架是不可或缺的一部分,它提供了存储和操作一组对象的工具。Java 集合框架主要包括 List、Set 和 Map 接口及其常用的实现类。正确理解和使用这些集合类不仅可以提高代码的可读性和性能,还能避免一些常见的错误。本…...

Go进阶概览 -【7.2 泛型的使用与实现分析】
7.2 泛型的使用与实现分析 泛型是Go 1.18引入的概念,在引入这个概念前经过了好几年的考量最终才将这这个特性加进去。 泛型在多种语言中都是存在的,比如C、Java等语言中都有泛型的概念。 本节我们将针对泛型的使用、实现原理进行整体的讲解。 本节代…...

罗德岛战记游戏源码(客户端+服务端+数据库+全套源码)游戏大小9.41G
罗德岛战记游戏源码(客户端服务端数据库全套源码)游戏大小9.41G 下载地址: 通过网盘分享的文件:【源码】罗德岛战记游戏源码(客户端服务端数据库全套源码)游戏大小9.41G 链接: https://pan.baidu.com/s/1y0…...

AI+教育|拥抱AI智能科技,让课堂更生动高效
AI在教育领域的应用正逐渐成为现实,提供互动性强的学习体验,正在改变传统教育模式。AI不仅改变了传统的教学模式,还为教育提供了更多的可能性和解决方案。从个性化学习体验到自动化管理任务,AI正在全方位提升教育质量和效率。随着…...

WebServer
一、服务器代码 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <unistd.h> #define PORT 80 #define BUFFER_SIZE 1024 void ha…...

java项目之基于spring boot的多维分类的知识管理系统的设计与实现源码
项目简介 基于spring boot的多维分类的知识管理系统的设计与实现实现了以下功能: 基于spring boot的多维分类的知识管理系统的设计与实现的主要使用者管理员可以管理用户信息,知识分类,知识信息等,用户可以查看和下载管理员发布…...

go的结构体、方法、接口
结构体: 结构体:不同类型数据集合 结构体成员是由一系列的成员变量构成,这些成员变量也被称为“字段” 先声明一下我们的结构体: type Person struct {name stringage intsex string } 定义结构体法1: var p1 P…...

力扣第一题——删除有序数组中的重复项
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次,返回删除后数组的新长度。不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1)额外空间的条件下完成。 示例 1&#x…...

Tuxera NTFS for Mac 2023绿色版
在数字化时代,数据的存储和传输变得至关重要。Mac用户经常需要在Windows NTFS格式的移动硬盘上进行读写操作,然而,由于MacOS系统默认不支持NTFS的写操作,这就需要我们寻找一款高效的读写软件。Tuxera NTFS for Mac 2023便是其中…...

LeetCode[中等] 155. 最小栈
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 实现 MinStack 类: MinStack() 初始化堆栈对象。void push(int val) 将元素val推入堆栈。void pop() 删除堆栈顶部的元素。int top() 获取堆栈顶部的元素。int get…...

Python青少年简明教程目录
Python青少年简明教程目录 学习编程语言时,会遇到“开头难”和“深入难”的问题,这是许多编程学习者都会经历的普遍现象。 学习Python对于青少年来说是一个很好的编程起点,相对容易上手入门,但语言特性复杂,应用较广&…...

Revit学习记录-版本2018【持续补充】
将墙面拆分并使用不同材料 【修改】>【几何图形】>【拆分面】(SF), 然后再使用【修改】>【几何图形】>【填色】(PT)进行填充 楼板漏在墙外 绘制楼板时最好选择墙体绘制,如果标高上不显示墙体,可以先选…...

深度学习01-概述
深度学习是机器学习的一个子集。机器学习是实现人工智能的一种途径,而深度学习则是通过多层神经网络模拟人类大脑的方式进行学习和知识提取。 深度学习的关键特点: 1. 自动提取特征:与传统的机器学习方法不同,深度学习不需要手动…...

leetcode232. 用栈实现队列
leetcode232. 用栈实现队列 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): 实现 MyQueue 类: void push(int x) 将元素 x 推到队列的末尾 int pop() 从队列的开头移除并返回元…...

智慧火灾应急救援航拍检测数据集(无人机视角)
智慧火灾应急救援。 无人机,直升机等航拍视角下火灾应急救援检测数据集,数据分别标注了火,人,车辆这三个要素内容,29810张高清航拍影像,共31GB,适合森林防火,应急救援等方向的学术研…...

eureka.client.service-url.defaultZone的坑
错误的配置 eureka: client: service-url: default-zone: http://192.168.100.10:8080/eureka正确的配置 eureka: client: service-url: defaultZone: http://192.168.100.10:8080/eureka根据错误日志堆栈打断电调试 出现两个key,也就是defaultZone不支持snake-c…...

深耕 Harness 工程,解锁 AI Agent 开发之路
2026三掌柜赠书活动第三十一期 Harness工程:从上下文管理到Agent系统构建 目录 前言 详解Harness工程核心价值与独特优势 关于《Harness工程:从上下文管理到Agent系统构建》 编辑推荐 内容简介 作者简介 图书目录 《Harness工程:从上…...

Selenium动作链原理与Go实战:模拟人类交互的底层机制
1. 为什么“动作链”不是锦上添花,而是Selenium自动化绕不开的生死线你写过driver.FindElement(By.Id("submit")).Click(),也用过SendKeys("hello"),甚至加了Thread.Sleep(2000)等页面加载——但当你要拖拽一个滑块完成验…...

大模型的“文字障眼法“:FlipAttack 文本反转越狱技术全解析
一、先打个比方:你听说过"倒着说话"绕过安检吗? 想象一下,有个调皮的小孩想带进游乐园一个违禁品。安检人员耳朵很尖,一听到"炸弹""刀具"这些词就会拦人。于是小孩想了个办法——把话说反。 “我要…...

CANN/pypto isfinite函数文档
pypto.isfinite 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品…...

Jooby数据库集成实战:Hikari、JDBI、Ebean最佳实践
Jooby数据库集成实战:Hikari、JDBI、Ebean最佳实践 【免费下载链接】jooby The modular web framework for Java and Kotlin 项目地址: https://gitcode.com/gh_mirrors/jo/jooby Jooby是一个模块化的Java和Kotlin Web框架,提供了简洁高效的数据库…...
:Handle进阶——批量巡检、自动审计与高危操作SOP)
《Sysinternals实战指南》进程和诊断工具学习笔记(8.25):Handle进阶——批量巡检、自动审计与高危操作SOP
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

11.三层网络VXLAN
先把之前基于flat模式创建的虚机,全部删除 控制节点配置:1.修改配置文件/etc/neutron/neutron.conf 将[DEFAULT]区域 core_plugin ml2 service_plugins 修改为 core_plugin ml2 service_plugins router allow_overlapping_ips True2.修改/etc/neutro…...

【K8s】解惑:K8s 与 Docker 的关系
目录 引言:一个绕不开的问题 一句话说清K8s与Docker的关系 澄清三个误解 从命令的角度,直观对比 引言:一个绕不开的问题 在学习云原生技术的路上,几乎每个人都会遇到这样一个困惑: “有了 Kubernetes(…...

Unity游戏资源提取实战指南:AssetStudio高阶用法与避坑手册
1. 这不是“又一个AssetStudio教程”,而是我拆了27款Unity手游后总结的资源提取生存手册AssetStudio、Unity游戏资源提取、Unity AssetBundle、Unity3D反编译——这几个词,过去三年里我每天至少在技术群、论坛、工单系统里看到50次。但绝大多数人点开Ass…...

2026免费在线去水印软件推荐:优缺点对比与测评
在2026年,处理带有水印的图片、视频和文档已经成为许多人日常工作中的常见需求。无论是内容创作者、自媒体运营者,还是普通用户,偶尔都需要从素材中移除水印。本文将全面介绍当前免费在线去水印软件的最新情况,帮助你了解各工具的…...