神经网络面试题目
1. 批规范化(Batch Normalization)的好处都有啥?、
A. 让每一层的输入的范围都大致固定
B. 它将权重的归一化平均值和标准差
C. 它是一种非常有效的反向传播(BP)方法
D. 这些均不是
正确答案是:A
解析:
batch normalization 就是对数据做批规范化,使得数据满足均值为0,方差为1的高斯分布。其主要作用是缓解DNN训练中的梯度消失/爆炸现象,加快模型的训练速度。 但是注意是对数据做批规范化,不是对权重。
BN的优点:
- 极大提升了训练速度,收敛过程大大加快;
- 增加了分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout或正则化也能达到相当的效果;
- 简化了调参过程,对于初始化参数权重不太敏感,允许使用较大的学习率
2. 如果我们用了一个过大的学习速率会发生什么?
A. 神经网络会收敛
B. 不好说
C. 都不对
D. 神经网络不会收敛
正确答案是:D
解析:过大,说明不适合,梯度下降时,梯度会来回震荡,神经网络不会收敛。
3. 下图所示的网络用于训练识别字符H和T,如下所示

D. 可能是A或B,取决于神经网络的权重设置
正确答案是:D
解析:不知道神经网络的权重和偏差是什么,则无法判定它将会给出什么样的输出。
4. 增加卷积核的大小对于改进卷积神经网络的效果是必要的吗?
A. 没听说过
B. 是
C. 否
D. 不知道
正确答案是:C
解析:C,增加核函数的大小不一定会提高性能。这个问题在很大程度上取决于数据集。
5. 对于一个分类任务,如果开始时神经网络的权重不是随机赋值的,而是都设成0,下面哪个叙述是正确的?
A 其他选项都不对
B 没啥问题,神经网络会正常开始训练
C 神经网络可以训练,但是所有的神经元最后都会变成识别同样的东西
D 神经网络不会开始训练,因为没有梯度改变
正确答案是:C
解析:
令所有权重都初始化为0这个一个听起来还蛮合理的想法也许是一个我们假设中最好的一个假设了, 但结果是错误的,因为如果神经网络计算出来的输出值都一个样,那么反向传播算法计算出来的梯度值一样,并且参数更新值也一样(w=w−α∗dw)。更一般地说,如果权重初始化为同一个值,网络即使是对称的, 最终所有的神经元最后都会变成识别同样的东西。
6. 下图显示,当开始训练时,误差一直很高,这是因为神经网络在往全局最小值前进之前一直被卡在局部最小值里。为了避免这种情况,我们可以采取下面哪种策略?

A 改变学习速率,比如一开始的几个训练周期不断更改学习速率
B 一开始将学习速率减小10倍,然后用动量项(momentum)
C 增加参数数目,这样神经网络就不会卡在局部最优处
D 其他都不对
正确答案是:A
解析:选项A可以将陷于局部最小值的神经网络提取出来。
7. 对于一个图像识别问题(在一张照片里找出一只猫),下面哪种神经网络可以更好地解决这个问题?
A 循环神经网络
B 感知机
C 多层感知机
D 卷积神经网络
正确答案是:D
解析:卷积神经网络将更好地适用于图像相关问题,因为考虑到图像附近位置变化的固有性质。
8. 假设在训练中我们突然遇到了一个问题,在几次循环之后,误差瞬间降低, 你认为数据有问题,于是你画出了数据并且发现也许是数据的偏度过大造成了这个问题。你打算怎么做来处理这个问题?

A 对数据作归一化
B 对数据取对数变化
C 都不对
D 对数据作主成分分析(PCA)和归一化
正确答案是:D
解析:首先您将相关的数据去掉,然后将其置零。具体来说,误差瞬间降低, 一般原因是多个数据样本有强相关性且突然被拟合命中, 或者含有较大方差数据样本突然被拟合命中. 所以对数据作主成分分析(PCA)和归一化能够改善这个问题。
9. 在下图中,我们可以观察到误差出现了许多小的"涨落"。 这种情况我们应该担心吗?
![![[images/Pasted image 20240922161657.png]]](https://i-blog.csdnimg.cn/direct/1efa2df45d9641d7b8aa52540b0ae780.png)
A 需要,这也许意味着神经网络的学习速率存在问题
B 不需要,只要在训练集和交叉验证集上有累积的下降就可以了
C 不知道
D 不好说
正确答案是:B
解析:选项B是正确的,为了减少这些“起伏”,可以尝试增加批尺寸(batch size)。具体来说,在曲线整体趋势为下降时, 为了减少这些“起伏”,可以尝试增加批尺寸(batch size)以缩小batch综合梯度方向摆动范围. 当整体曲线趋势为平缓时出现可观的“起伏”, 可以尝试降低学习率以进一步收敛. “起伏”不可观时应该提前终止训练以免过拟合
10. 对于神经网络的说法, 下面正确的是 :
增加神经网络层数, 可能会增加测试数据集的分类错误率
减少神经网络层数, 总是能减小测试数据集的分类错误率
增加神经网络层数, 总是能减小训练数据集的分类错误率
A 1
B 1 和 3
C 1 和 2
D 2
正确答案是:A
解析:深度神经网络的成功, 已经证明, 增加神经网络层数, 可以增加模型泛化能力, 即, 训练数据集和测试数据集都表现得更好. 但更多的层数, 也不一定能保证有更好的表现. 所以, 不能绝对地说层数多的好坏, 只能选A
11. 考虑某个具体问题时,你可能只有少量数据来解决这个问题。不过幸运的是你有一个类似问题已经预先训练好的神经网络。可以用下面哪种方法来利用这个预先训练好的网络?
A 把除了最后一层外所有的层都冻结,重新训练最后一层
B 对新数据重新训练整个模型
C 只对最后几层进行调参(fine tune)
D 对每一层模型进行评估,选择其中的少数来用
正确答案是:C
解析:如果有个预先训练好的神经网络, 就相当于网络各参数有个很靠谱的先验代替随机初始化.
- 若新的少量数据来自于先前训练数据(或者先前训练数据量很好地描述了数据分布, 而新数据采样自完全相同的分布), 则冻结前面所有层而重新训练最后一层即可; -> 迁移学习
- 但一般情况下, 新数据分布跟先前训练集分布有所偏差, 所以先验网络不足以完全拟合新数据时, 可以冻结大部分前层网络, 只对最后几层进行训练调参(这也称之为fine tune)。 -> fine tuning
12. 深度学习是当前很热门的机器学习算法,在深度学习中,涉及到大量的矩阵相乘,现在需要计算三个稠密矩阵A,B,C的乘积ABC,假设三个矩阵的尺寸分别为m∗n,n∗p,p∗q,且m < n < p < q,以下计算顺序效率最高的是()
A. (AB)C
B. AC(B)
C. A(BC)
D. 所以效率都相同
正确答案是:A
解析:
首先,根据简单的矩阵知识,因为 A * B , A 的列数必须和 B 的行数相等。因此,可以排除 B 选项
然后,再看 A 、 C 选项。在 A 选项中,m∗n 的矩阵 A 和n∗p的矩阵 B 的乘积,得到 m∗p的矩阵 A * B ,而 A∗B的每个元素需要 n 次乘法和 n-1 次加法,忽略加法,共需要 m∗n∗p次乘法运算。
同样情况分析 A * B 之后再乘以 C 时的情况,共需要 m∗p∗q次乘法运算
因此, A 选项 (AB)C 需要的乘法次数是 m∗n∗p+m∗p∗q 。
同理分析, C 选项 A (BC) 需要的乘法次数是 n∗p∗q+m∗n∗q。
13. 下列哪个神经网络结构会发生权重共享?
A 卷积神经网络
B 循环神经网络
C 全连接神经网络
D 选项A和B
正确答案是:D
解析:CNN卷积核卷积计算时可以重复用。 RNN序列的每个时间步的参数都是共享的。
14.不属于深度学习开发框架的是?
A、CNTK
B、Keras
C、BAFA
D、MXNet
答案:C
15.不属于深度学习算法的是?
A自编码器
B卷积神经网络
C循环神经网络
D支持向量机
答案:D
16.训练误差会降低模型的准确率,产生欠拟合,此时如何提升模型拟合度?
A、增加数据量
B、特征工程
C、减少正则化参数
D、增加特征
答案:AB
17.关于超参数描述错误的是?
A、超参数是算法开始学习之前设置值的参数
B、大多数机器学习算法都有超参数
C、超参数是不能修改的
D、超参数的值不是通过算法本身学习出来的
答案:C
18. 不属于自动超参数优化算法的是?
A、网格搜索
B、随机梯度下降
C、随机搜索
D、基于模型的超参数优化
答案:C
19.关于循环神经网络(RNN)描述正确的是?
A、可以用于处理序列数据
B、不能处理可变长序列数据
C、不同于卷积神经网络,RNN的参数不能共享。
D、隐藏层上面的unit彼此没有关联
答案:A
20. 训练CNN时,可以对输入进行旋转、平移、缩放等预处理提高模型泛化能力。这么说是对,还是不对?
(对)
解释:
输入进行旋转、平移、缩放等预处理相当于做了数据增强,提升泛化能力
21. 深度学习与机器学习算法之间的区别在于,后者过程中无需进行特征提取工作,也就是说,我们建议在进行深度学习过程之前要首先完成特征提取的工作。这种说法是:
(错)
解释:
机器学习和深度学习都需要特征提取工作
深度学习是直接从数据中自动学习到特征,无需提前人工进行特征提取
22. 假设我们有一个使用ReLU激活函数(ReLU activation function)的神经网络,假如我们把ReLU激活替换为线性激活,那么这个神经网络能够模拟出同或函数(XNOR function)吗?
A、可以
B、不好说
C、不一定
D、不能
( D )
解释:
加入激活函数,模型具有了模拟非线性函数的作用,如果被替换成了线性,那么模型就不能进行其他非线性函数的模拟。
23. 梯度下降算法的正确步骤是什么
a.计算预测值和真实值之间的误差
b.重复迭代,直至得到网络权重的最佳值
c.把输入传入网络,得到输出值
d.用随机值初始化权重和偏差
e.对每一个产生误差的神经元,调整相应的(权重)值以减小误差
A、abcde
B、edcba
C、cbaed
D、dcaeb
( D )
24. 下列哪一项属于特征学习算法(representation learning algorithm)
A、K近邻算法
B、随机森林
C、神经网络
D、都不属于
( C )
解释:
特征学习能够替代手动特征工程,而只有神经网络是自动学习特征
25. caffe中基本的计算单元为
A、blob
B、layer
C、net
D、solver
( B )
解释:
Blob是Caffe的基本存储单元
Layer是Caffe的基本计算单元
26. 阅读以下文字:假设我们拥有一个已完成训练的、用来解决车辆检测问题的深度神经网络模型,训练所用的数据集由汽车和卡车的照片构成,而训练目标是检测出每种车辆的名称(车辆共有10种类型)。现在想要使用这个模型来解决另外一个问题,问题数据集中仅包含一种车(福特野马)而目标变为定位车辆在照片中的位置
A、除去神经网络中的最后一层,冻结所有层然后重新训练
B、对神经网络中的最后几层进行微调,同时将最后一层(分类层)更改为回归层
C、使用新的数据集重新训练模型
D、所有答案均不对
( B )
解释:
一个是分类任务,一个是检测任务
27. 考虑以下问题:假设我们有一个5层的神经网络,这个神经网络在使用一个4GB显存显卡时需要花费3个小时来完成训练。而在测试过程中,单个数据需要花费2秒的时间。 如果我们现在把架构变换一下,当评分是0.2和0.3时,分别在第2层和第4层添加Dropout,那么新架构的测试所用时间会变为多少?
A、少于2s
B、大于2s
C、仍是2s
D、说不准
( C )
解释:
在架构中添加Dropout这一改动仅会影响训练过程,而并不影响测试过程。
Dropout是在训练过程中以一定的概率使神经元失活,即输出为0,以提高模型的泛化能力,减少过拟合。Dropout 在训练时采用,是为了减少神经元对部分上层神经元的依赖,类似将多个不同网络结构的模型集成起来,减少过拟合的风险。而在测试时,应该用整个训练好的模型,因此不需要dropout。
Batch Normalization(BN),就是在深度神经网络训练过程中使得每一层神经网络的输入保持相近的分布。
对于BN,在训练时,是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差。而在测试时,比如进行一个样本的预测,就并没有batch的概念,因此,这个时候用的均值和方差是全量训练数据的均值和方差,这个可以通过移动平均法求得。
28. 下列的哪种方法可以用来降低深度学习模型的过拟合问题?
①增加更多的数据
②使用数据扩增技术(data augmentation)
③使用归纳性更好的架构
④ 正规化数据
⑤ 降低架构的复杂度
A、1 4 5
B、1 2 3
C、1 3 4 5
D、所有项目都有用
( D )
解释:
防止过拟合的几种方法:
- 引入正则化
- Dropout
- 提前终止训练
- 增加样本量
29. 如果我们用了一个过大的学习速率会发生什么?
A、神经网络会收敛
B、不好说
C、都不对
D、神经网络不会收敛
( D )
解释:
学习率过小,收敛太慢,学习率过大,震荡不收敛
如果使用自适应优化器,训练到后期学习率是会变小的
30. ResNet-50 有多少个卷积层?
A、48
B、49
C、50
D、51
( B )
31. 如果增加多层感知机(Multilayer Perceptron)的隐藏层 层数,分类误差便会减小。这种陈述正确还是错误?
A、正确
B、错误
( B )
解释:
过拟合可能会导致错误增加
32. 假设你有5个大小为7x7、边界值为0的卷积核,同时卷积神经网络第一层的深度为1。此时如果你向这一层传入一个维度为224x224x3的数据,那么神经网络下一层所接收到的数据维度是多少?
A、218x218x5
B、217x217x8
C、217x217x3
D、220x220x5
( A )
解释:
(W−F+2P)/S + 1
其中W为输入,F为卷积核,P为pading值,S为步长
(224 - 7 + 2 * 0)/ 1 + 1 为218,取218
33. 在CNN网络中,图A经过核为3x3,步长为2的卷积层,ReLU激活函数层,BN层,以及一个步长为2,核为2 * 2的池化层后,再经过一个3 * 3 的的卷积层,步长为1,此时的感受野是
A、10
B、11
C、12
D、13
( D )
解释:
感受野:现在的一个像素对应原来的多少个像素
倒推上一层感受野Ln-1 =( Ln -1)* Sn-1+ Kn-1 ,S 和 K分别是stride(步长)和kernel size(卷积核大小)
卷积层3x3,步长1: 1(1-1)+3=3 * 3;
池化层 2x2,步长2:2(3-1)+2=6 * 6
卷积层3x3,步长2:2(6-1)+3=13 * 13
34. 在训练神经网络时,损失函数(loss)在最初的几个epochs时没有下降,可能的原因是?

A、学习率(learning rate)太低
B、正则参数太高
C、陷入局部最小值
D、以上都有可能
(D)
35.下图是一个利用sigmoid函数作为激活函数的含四个隐藏层的神经网络训练的梯度下降图。这个神经网络遇到了梯度消失的问题。下面哪个叙述是正确的?
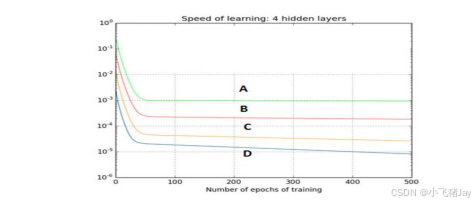
A、第一隐藏层对应D,第二隐藏层对应C,第三隐藏层对应B,第四隐藏层对应A
B、第一隐藏层对应A,第二隐藏层对应C,第三隐藏层对应B,第四隐藏层对应D
C、第一隐藏层对应A,第二隐藏层对应B,第三隐藏层对应C,第四隐藏层对应D
D、第一隐藏层对应B,第二隐藏层对应D,第三隐藏层对应C,第四隐藏层对应A
(A)
解释:
由于梯度反向传播,在梯度消失情况下越接近输入层,其梯度越小;在梯度爆炸的情况下越接近输入层,其梯度越大。
损失函数曲线越平,就说明梯度消失越厉害,在前向传播中,越接近输出层,梯度越接近0,所以最先消失的一定是离输出层最近的。
由于反向传播算法进入起始层,学习能力降低,这就是梯度消失。换言之,梯度消失是梯度在前向传播中逐渐减为0, 按照图标题所说, 四条曲线是4个隐藏层的学习曲线, 那么第一层梯度最高(损失函数曲线下降明显), 最后一层梯度几乎为零(损失函数曲线变成平直线). 所以D是第一层, A是最后一层。
36. 当在卷积神经网络中加入池化层(pooling layer)时,变换的不变性会被保留,是吗?
A、不知道
B、看情况
C、是
D、否
( C )
解释:
池化算法比如取最大值/取平均值等, 都是输入数据旋转后结果不变, 所以多层叠加后也有这种不变性。
37. 在一个神经网络中,知道每一个神经元的权重和偏差是最重要的一步。如果知道了神经元准确的权重和偏差,便可以近似任何函数,但怎么获知每个神经的权重和偏移呢?
A、搜索每个可能的权重和偏差组合,直到得到最佳值
B、赋予一个初始值,然后检查跟最佳值的差值,不断迭代调整权重
C、随机赋值,听天由命
D、以上都不正确的
( B )
解释:
深度学习是根据梯度下降优化参数的
38. 深度学习中的激活函数需要具有哪些属性
A、计算简单
B、非线性
C、具有饱和区
D、几乎处处可微
( A B D )
解释:
- 非线性:即导数不是常数
- 几乎处处可微(即仅在有限个点处不可微):保证了在优化中梯度的可计算性
- 计算简单:激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。
- 非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。
- 单调性(monotonic):即导数符号不变。个人理解,单调性使得在激活函数处的梯度方向不会经常改变,从而让训练更容易收敛。
- 输出范围有限:有限的输出范围使得网络对于一些比较大的输入也会比较稳定,但这导致了前面提到的梯度消失问题,而且强行让每一层的输出限制到固定范围会限制其表达能力。
- 接近恒等变换(identity):即约等于x。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加,从而使网络更为稳定,同时梯度也能够更容易地回传。
- 参数少:大部分激活函数都是没有参数的。
39. 准确率(查准率)、召回率(查全率)、F值
正确率、召回率和F值是目标的重要评价指标。
- 正确率 = 正确识别的个体总数 / 识别出的个体总数
- 召回率 = 正确识别的个体总数 / 测试集中存在的个体总数
- F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率)
相关文章:
神经网络面试题目
1. 批规范化(Batch Normalization)的好处都有啥?、 A. 让每一层的输入的范围都大致固定 B. 它将权重的归一化平均值和标准差 C. 它是一种非常有效的反向传播(BP)方法 D. 这些均不是 正确答案是:A 解析: batch normalization 就…...

C语言题目之单身狗2
文章目录 一、题目二、思路三、代码实现 提示:以下是本篇文章正文内容,下面案例可供参考 一、题目 二、思路 第一步 在c语言题目之打印单身狗我们已经讲解了在一组数据中出现一个单身狗的情况,而本道题是出现两个单身狗的情况。根据一个数…...
)
Vue2学习笔记(03关于VueComponent)
1.school组件本质是一个名为Vuecomponent的构造函数,且不是程序员定义的,是Vue.extend生成的。 2.我们只需要写<school/>或<school></school>,Vue解析时会帮我们创建school组件的实例对象,即Vue帮我们执行的:new Vuecompo…...

微服务架构中常用技术框架
认证授权 Spring Security OAuth 2.0 JWT Keycloak Istio Apache Shiro 日志监控 ELK Prometheus Grafana Fluentd CI/CD Jenkins GitLab CI CircleCI ArgoCD 服务通信 gRPC REST API Apache Thrift Apache Avro Apache Dubbo OpenFegin 断路器 Hystr…...
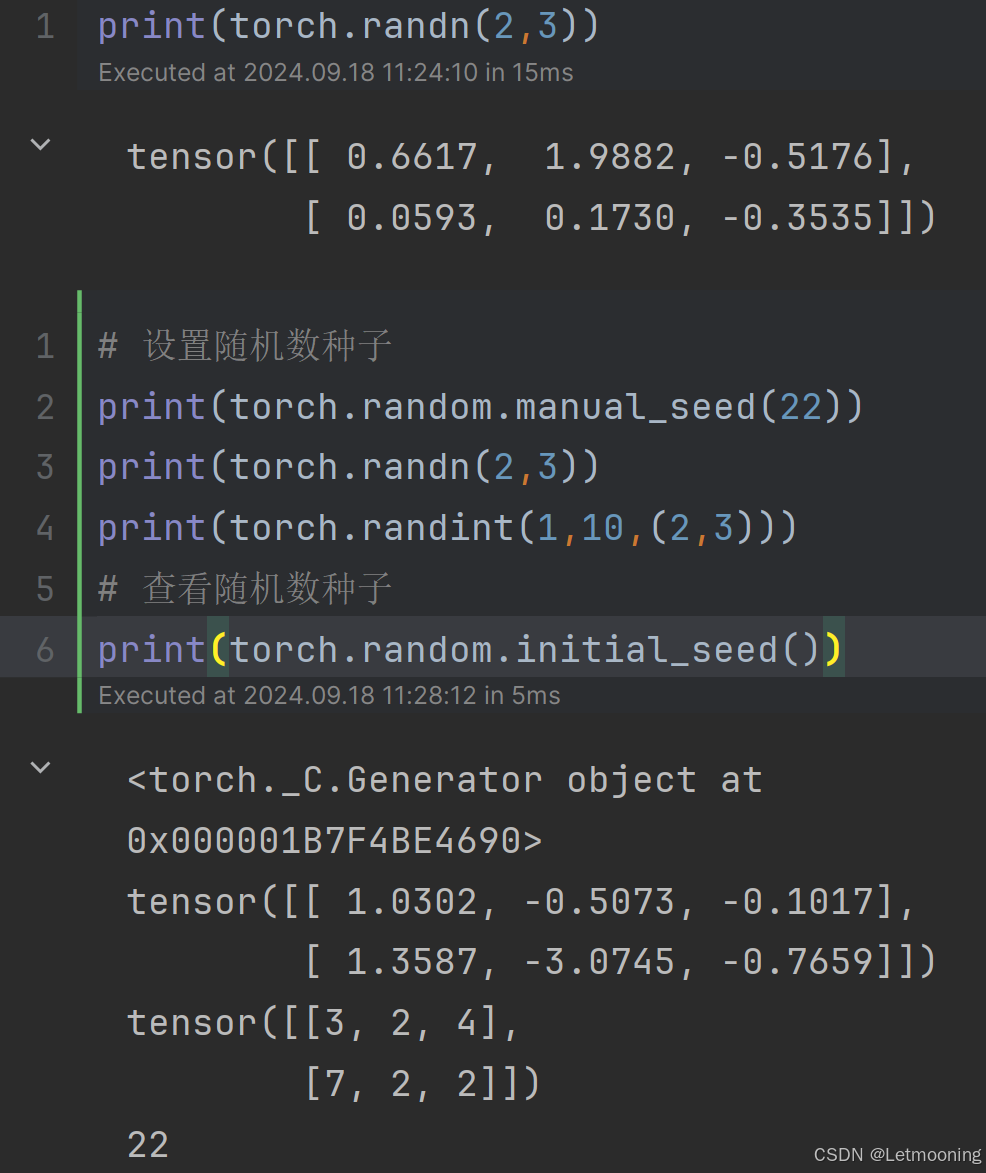
[深度学习]Pytorch框架
1 深度学习简介 应用领域:语音交互、文本处理、计算机视觉、深度学习、人机交互、知识图谱、分析处理、问题求解2 发展历史 1956年人工智能元年2016年国内开始关注深度学习2017年出现Transformer框架2018年Bert和GPT出现2022年,chatGPT出现,进入AIGC发展阶段3 PyTorch框架简…...

华为HarmonyOS灵活高效的消息推送服务(Push Kit) - 5 发送通知消息
场景介绍 通知消息通过Push Kit通道直接下发,可在终端设备的通知中心、锁屏、横幅等展示,用户点击后拉起应用。您可以通过设置通知消息样式来吸引用户。 开通权益 Push Kit根据消息内容,将通知消息分类为服务与通讯、资讯营销两大类别&…...
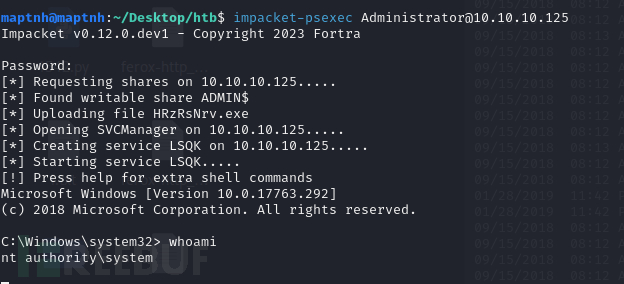
[Meachines] [Medium] Querier XLSM宏+MSSQL NTLM哈希窃取(xp_dirtree)+GPP凭据泄露
信息收集 IP AddressOpening Ports10.10.10.125TCP:135, 139, 445, 1433, 5985, 47001, 49664, 49665, 49666, 49667, 49668, 49669, 49670, 49671 $ nmap -p- 10.10.10.125 --min-rate 1000 -sC -sV -Pn PORT STATE SERVICE VERSION 135/tcp open msrp…...

新版ssh客户端无法连接旧版服务器sshd的方法
新安装完的windows 版本,连Linux服务器直接报错 C:\Users\wang>ssh root192.168.110.50 Unable to negotiate with 192.168.110.50 port 22: no matching key exchange method found. Their offer: diffie-hellman-group14-sha1,diffie-hellman-group1-sha1,kex…...
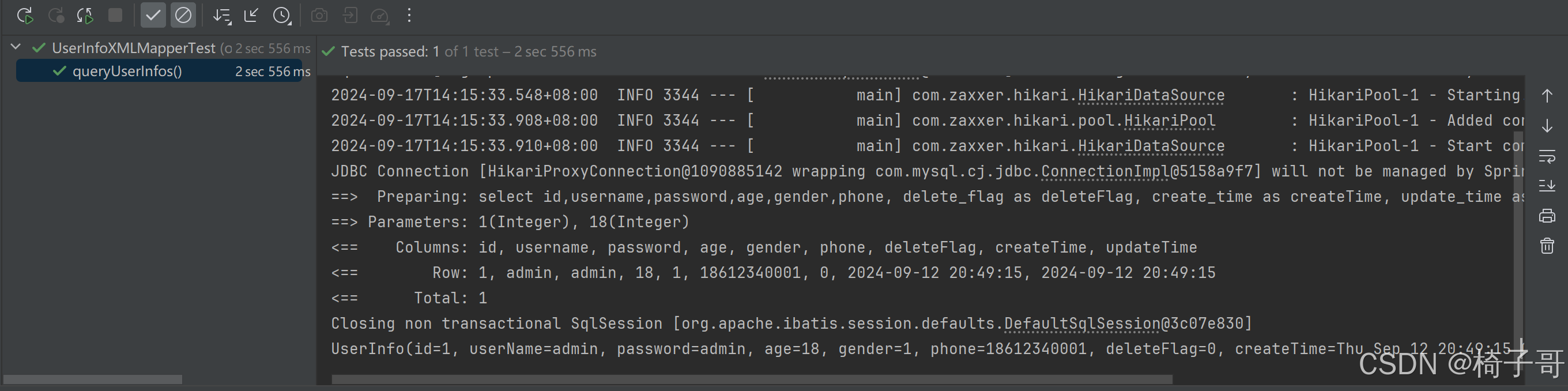
MyBatis操作数据库-XML实现
目录 1.MyBatis的简单介绍 2.MyBatis操作数据库的步骤 2.1 添加依赖 2.2 配置文件 2.3 写持久层代码 2.4 方法测试 3.MyBatis操作数据库(增删查改) 3.1 CRUD标签 3.2 参数传递 3.3 Insert-新增 3.4 Delete-删除 3.5 Update-修改 3.6 Select-查询(映射问题) 1.MyB…...
华为HarmonyOS地图服务 5 - 利用UI控件和手势进行地图交互
场景介绍 本章节将向您介绍如何使用地图的手势。 Map Kit提供了多种手势供用户与地图之间进行交互,如缩放、滚动、旋转和倾斜。这些手势默认开启,如果想要关闭某些手势,可以通过MapComponentController类提供的接口来控制手势的开关。 接口…...
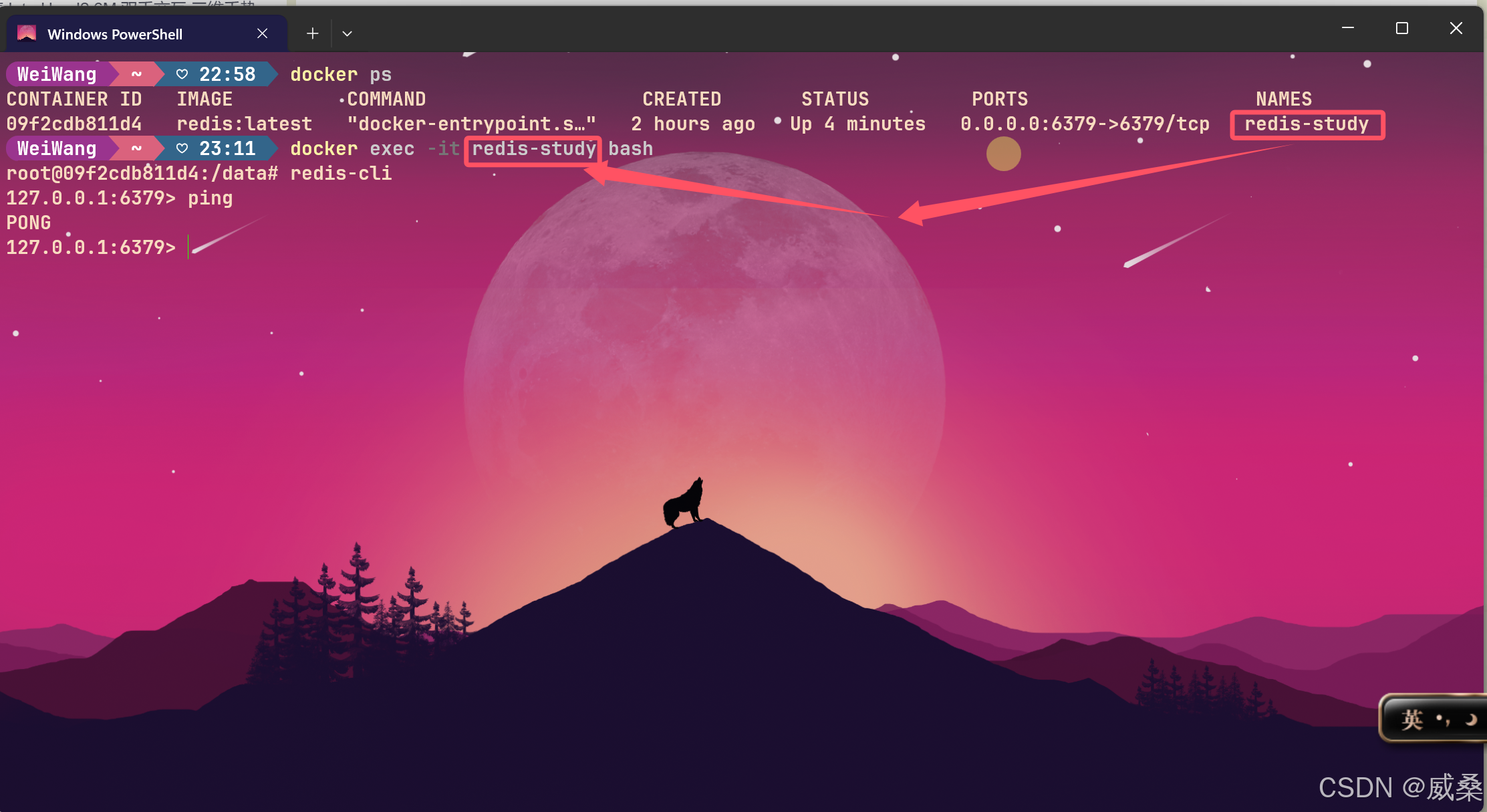
解决DockerDesktop启动redis后采用PowerShell终端操作
如图: 在启动redis容器后,会计入以下界面 : 在进入执行界面后如图: 是否会觉得界面过于单调,于是想到使用PowerShell来操作。 步骤如下: 这样就能使用PowerShell愉快地敲命令了(颜值是第一生…...

react + antDesign封装图片预览组件(支持多张图片)
需求场景:最近在开发后台系统时经常遇到图片预览问题,如果一个一个的引用antDesign的图片预览组件就有点繁琐了,于是在antDesign图片预览组件的基础上二次封装了一下,避免重复无用代码的出现 效果 公共预览组件代码 import React…...
比较)
逻辑回归 和 支持向量机(SVM)比较
为了更好地理解为什么在二分类问题中使用 SVM,逻辑回归的区别,我们需要深入了解这两种算法的区别、优势、劣势,以及它们适用于不同场景的原因。 逻辑回归和 SVM 的比较 1. 模型的核心思想 • 逻辑回归: • 基于概率的模型&…...

GS-SLAM论文阅读笔记--TAMBRIDGE
前言 本文提出了一个自己的分类方法,传统的视觉SLAM通常使用以帧为中心的跟踪方法,但是3DGS作为一种高效的地图表达方法好像更侧重于地图的创建。这两种方法都有各自的优缺点,但是如果能取长补短,互相结合,那么就会是…...

[Redis面试高频] - zset的底层数据结构
文章目录 [Redis面试高频] - zset的底层数据结构一、引言二、zset 的底层数据结构1、zset 的编码方式1.1、ziplist 编码1.2、skiplist 编码 1.3、ziplist 编码适用条件1.4、skiplist 编码适用条件2、zset 的操作命令 三、zset 的性能考量1、内存效率2、搜索效率 四、总结 [Redi…...

搜维尔科技:OptiTrack将捕捉到的人类动作数据映射到人形机器人的各个关节上进行遥操作
OptiTrack将捕捉到的人类动作数据映射到人形机器人的各个关节上进行遥操作 搜维尔科技:OptiTrack将捕捉到的人类动作数据映射到人形机器人的各个关节上进行遥操作...

CentOS Linux教程(6)--CentOS目录
文章目录 1. 根目录2. cd目录切换命令3. CentOS目录介绍4. pwd命令介绍5. ls命令介绍5.1 ls5.2 ls -a5.3 ls -l 1. 根目录 Windows电脑的根目录是计算机(我的电脑),然后C盘、D盘。 Linux系统的根目录是/,我们可以使用cd /进入根目录,然后使…...

观察者模式全攻略:从设计原理到 SpringBoot 实践案例
观察者模式 观察者模式(Observer Pattern)是一种行为型设计模式,它定义了一种一对多的依赖关系,使得当一个对象的状态发生改变时,所有依赖于它的对象都能得到通知并自动更新。 核心思想: 观察者模式将**观…...

【MyBatis】Java 数据持久层框架:认识 MyBatis
Java 数据持久层框架:认识 MyBatis 1.CRUD 注解2.映射注解3.高级注解3.1 高级注解3.2 MyBatis 3 注解的用法举例 MyBatis 和 JPA 一样,也是一款优秀的 持久层框架,它支持定制化 SQL、存储过程,以及高级映射。它可以使用简单的 XML…...
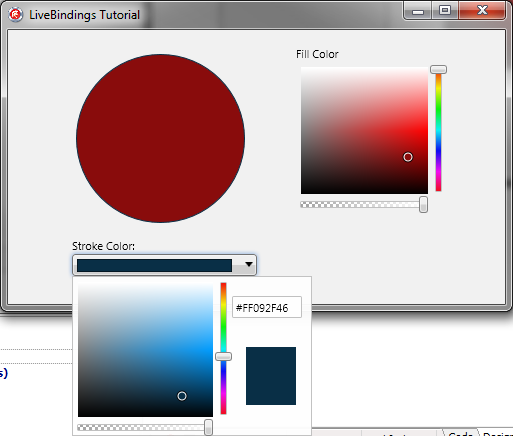
【Delphi】通过 LiveBindings Designer 链接控件示例
本教程展示了如何使用 LiveBindings Designer 可视化地创建控件之间的 LiveBindings,以便创建只需很少或无需源代码的应用程序。 在本教程中,您将创建一个高清多设备应用程序,该应用程序使用 LiveBindings 绑定多个对象,以更改圆…...

告别环境报错:用Docker 10分钟在本地/服务器部署YOLOv8完整开发环境
告别环境报错:用Docker 10分钟在本地/服务器部署YOLOv8完整开发环境 在计算机视觉领域,YOLOv8作为当前最先进的目标检测模型之一,其强大的性能和易用性吸引了大量开发者和研究者。然而,传统的手动搭建开发环境过程往往令人望而生畏…...

长期使用Taotoken Token Plan套餐的成本节省实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐的成本节省实际感受 1. 从按量付费到套餐订阅的转变 我们团队在接入大模型API进行日常开发与内容…...

如何用Akagi打造实时麻将AI辅助系统:从新手到高手的完整指南
如何用Akagi打造实时麻将AI辅助系统:从新手到高手的完整指南 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City,…...

ETS2LA自动驾驶插件:为《欧洲卡车模拟2》带来智能车道保持与模块化AI驾驶体验
ETS2LA自动驾驶插件:为《欧洲卡车模拟2》带来智能车道保持与模块化AI驾驶体验 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-A…...

7天职场内耗清零打卡计划
7天职场内耗清零打卡计划(极简好坚持)每天 3 件小事,不累不费脑,7 天稳住心态第一天:断胡思乱想别人随口一句话,当场听完就翻篇,绝不反复琢磨上班只盯自己手头事,不偷看别人忙不忙、…...

【更新 v 2.7.5 版本】桌面版 Open Claw 本地一键部署指南
✨ 核心亮点 零代码门槛|全程可视化|无需手动配环境|内置所有依赖|28 万 Tokens 额度 🔗 下载地址 https://xiake.yun/api/download/package/16?promoCodeIV8E496E2F7A 📝 前言 开源圈热门的「数字员…...

Win11Debloat:Windows 11系统优化终极指南,免费提升电脑性能50%
Win11Debloat:Windows 11系统优化终极指南,免费提升电脑性能50% 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes…...

3分钟搞定M3U8视频下载:N_m3u8DL-CLI-SimpleG完整指南
3分钟搞定M3U8视频下载:N_m3u8DL-CLI-SimpleG完整指南 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 还在为无法下载在线视频而烦恼吗?想保存喜欢的教学视…...

图片去水印软件哪个好用?2026免费工具对比测评|电脑手机全覆盖
去水印已经成为日常生活中的高频需求。无论是保存心仪的社交媒体内容、优化电商产品图片,还是整理个人素材库,一张带着平台水印的图片往往无法直接使用。但面对市面上琳琅满目的去水印方案,很多人都有同样的疑问:到底哪款软件最实…...

Hotkey Detective:3分钟找出Windows热键冲突元凶,重获键盘控制权
Hotkey Detective:3分钟找出Windows热键冲突元凶,重获键盘控制权 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-de…...