机器学习——Bagging
Bagging:
方法:集成n个base learner模型,每个模型都对原始数据集进行有放回的随机采样获得随机数据集,然后并行训练。
回归问题:n个base模型进行预测,将得到的预测值取平均得到最终结果。
分类问题:n个base模型进行预测,投票选择出n个分类结果中出现次数最对的结果作为最终分类结果
代表模型:随机森林是Bagging的一个代表。它基于自助采样法从原始数据集中抽取多个样本子集,
并在每个子集上训练一个决策树,最后通过投票或平均的方式得到最终的预测结果。
随机森林在鸢尾花数据集的分类实现,代码可直接运行,数据集在文章顶部免费下载
# 导入所需的库
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.preprocessing import StandardScaler
import seaborn as sns# 加载鸢尾花数据集
data = pd.read_excel('../data/鸢尾花分类数据集/Iris花分类.xlsx')
X = data.iloc[:, :4].values # 选取前4列作为特征
y = data.iloc[:, 4:].values.ravel() # 选取最后1列作为标签# 特征缩放(标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 将数据集划分为训练集和测试集
# 通常我们使用80%的数据作为训练集,20%的数据作为测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=66)# 创建随机森林分类器实例
# n_estimators表示森林中树的数量,可以调整以获得更好的性能
randomForest = RandomForestClassifier(n_estimators=100, random_state=42)# 使用训练数据来拟合(训练)随机森林模型
randomForest.fit(X_train, y_train)# 使用训练好的模型对测试集进行预测
y_pred = randomForest.predict(X_test)# 计算预测结果的准确度
accuracy = accuracy_score(y_test, y_pred)# 打印出准确度
print("随机森林分类精度为: {:.4f}%".format(accuracy * 100))# 获取特征重要性
feature_importances = randomForest.feature_importances_
# 获取特征名称
feature_names = data.columns[:4].tolist()
# 打印特征重要性
print("特征重要性:")
for feature, importance in zip(feature_names, feature_importances):print(f"{feature}: {importance:.4f}")
# 可视化特征重要性
# 创建一个DataFrame来存储特征重要程度
importances_df = pd.DataFrame({'Feature': feature_names, 'Importance': feature_importances})# 按重要程度降序排序
importances_df = importances_df.sort_values(by='Importance', ascending=False)# 绘制条形图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10, 5))
plt.bar(importances_df['Feature'], importances_df['Importance'])
plt.title('Feature Importances')
plt.ylabel('Importance')
plt.xlabel('Feature')
plt.show()# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)# 绘制混淆矩阵图
plt.figure(figsize=(7, 5))
sns.heatmap(cm, annot=True, fmt=".0f", linewidths=.5, square=True, cmap='Blues')
plt.ylabel('实际标签', fontproperties='SimHei', size=14)
plt.xlabel('预测标签', fontproperties='SimHei', size=14)
plt.title('随机森林分类器混淆矩阵', fontproperties='SimHei', size=15)
plt.show()
结果为:



相关文章:
机器学习——Bagging
Bagging: 方法:集成n个base learner模型,每个模型都对原始数据集进行有放回的随机采样获得随机数据集,然后并行训练。 回归问题:n个base模型进行预测,将得到的预测值取平均得到最终结果。 分类问题…...

日志体系结构与框架:历史、实现与如何在 Spring Cloud 中使用日志体系
文章目录 1. 引言2. 日志体系结构3. 日志框架的发展历程日志框架特点对比 4. 日志记录器的使用与管理使用 SLF4J 和 Logback 的日志记录示例 5. Spring Cloud 中的日志使用5.1 日志框架集成5.2 分布式追踪:Spring Cloud Sleuth 和 Zipkin添加 Sleuth 和 Zipkin 依赖…...

图文深入理解SQL语句的执行过程
List item 本文将深入介绍SQL语句的执行过程。 一.在RDBMS(关系型DB)中,看似很简单的一条已写入DB内存的SQL语句执行过程却非常复杂,也就是说,你执行了一条诸如select count(*) where id 001 from table_name的非常简…...

ubuntu安装StarQuant
安装boost 下面展示一些 内联代码片。 sudo apt install libboost-all-dev -y安装libmongoc-1.0 链接: link // An highlighted block sudo apt install libmongoc-1.0-0 sudo apt install libbson-1.0 sudo apt install cmake libssl-dev libsasl2-dev编译源码 $ git clone…...
)
学习篇 | Jupyter 使用(notebook hub)
1. JupyterHub 1.1 快速尝试 jupyterhub -f/path/jupyter_config.py --no-ssl1.2 长期后台运行 bash -c "nohup jupyterhub -f/path/jupyter_config.py --no-ssl" > ~/jupyterhub.log 2>&1 &1.3 帮助 jupyterhub --help2. Jupyter Notebook 2.1 快…...
-虚拟内存swap交换分区扩展)
【裸机装机系列】8.kali(ubuntu)-虚拟内存swap交换分区扩展
推荐阅读: 1.kali(ubuntu)-为什么弃用ubuntu,而选择基于debian的kali操作系统 linux swap交换分区,相当于win系统虚拟内存的概念。当linux系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前…...

异步请求的方法以及原理
异步请求是指在发送请求后,不会阻塞程序的执行,而是继续执行后续的代码,等待请求返回后再执行相应的回调函数。常见的异步请求方法包括使用XMLHttpRequest对象(XHR)和fetch API。 异步请求的方法 1. XMLHttpRequest (X…...

SpringCloud入门(六)Nacos注册中心(下)
一、Nacos环境隔离 Nacos提供了namespace来实现环境隔离功能。 nacos中可以有多个namespace。namespace下可以有group、service等。不同namespace之间相互隔离,例如不同namespace的服务互相不可见。 使用Nacos Namespace 环境隔离 步骤: 1.在Nacos控制…...

【RDMA】mlxlink检查和调试连接状态及相关问题--驱动工具
简介 mlxlink工具用于检查和调试连接状态及相关问题。该工具可以用于不同的链路和电缆(包括被动、电动、收发器和背板)。 属于mft工具套件的一个工具,固件工具 Firmware Tools (MFT):https://blog.csdn.net/bandaoyu/article/details/14242…...

QT For Android开发-打开PPT文件
一、前言 需求: Qt开发Android程序过程中,点击按钮就打开一个PPT文件。 Qt在Windows上要打开PPT文件或者其他文件很容易。可以使用QDesktopServices打开文件,非常方便。QDesktopServices提供了静态接口调用系统级别的功能。 这里用的QDesk…...
SpringBoot教程(三十) | SpringBoot集成Shiro权限框架
SpringBoot教程(三十) | SpringBoot集成Shiro权限框架 一、 什么是Shiro二、Shiro 组件核心组件其他组件 三、流程说明shiro的运行流程 四、SpringBoot 集成 Shiro (shiro-spring-boot-web-starter方式)1. 添加 Shiro 相关 maven2…...

[ffmpeg] 视频格式转换
本文主要梳理 ffmpeg 中的视频格式转换。由于上屏的数据是 rgba,编码使用的是 yuv数据,所以经常会使用到视频格式的转换。 除了使用 ffmpeg进行转换,还可以通过 libyuv 和 directX 写 shader 进行转换。 之前看到文章说 libyuv 之前是 ffmpeg…...
 git-repo https证书认证问题)
git-repo系列教程(3) git-repo https证书认证问题
文章目录 问题描述解决步骤1.下载证书2.测试证书是否正常3.设置环境变量 总结 问题描述 在使用git repo 同步仓库时,发现不能同步,出现如下提示错误: % Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left …...

中序遍历二叉树全过程图解
文章目录 中序遍历图解总结拓展:回归与回溯 中序遍历图解 首先看下中序遍历的代码,其接受一个根结点root作为参数,判断根节点是否为nil,不为nil则先递归遍历左子树。 func traversal(root *TreeNode,res *[]int) {if root nil …...
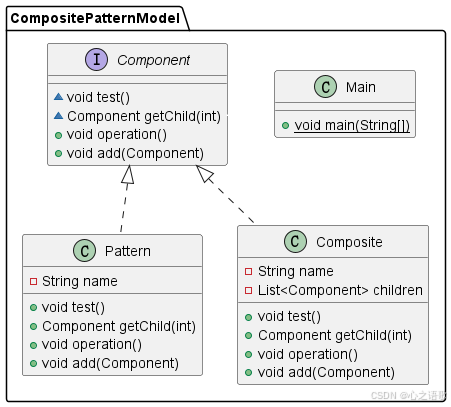
设计模式 组合模式(Composite Pattern)
组合模式简绍 组合模式(Composite Pattern)是一种结构型设计模式,它允许你将对象组合成树形结构来表示“部分-整体”的层次结构。组合模式使得客户端可以用一致的方式处理单个对象和组合对象。这样,可以在不知道对象具体类型的条…...

在vue中嵌入vitepress,基于markdown文件生成静态网页从而嵌入社团周报系统的一些想法和思路
什么是vitepress vitepress是一种将markdown文件渲染成静态网页的技术 其使用仅需几行命令即可 //在根目录安装vitepress npm add -D vitepress //初始化vitepress,添加相关配置文件,选择主题,描述,框架等 npx vitepress init //…...
神经网络面试题目
1. 批规范化(Batch Normalization)的好处都有啥?、 A. 让每一层的输入的范围都大致固定 B. 它将权重的归一化平均值和标准差 C. 它是一种非常有效的反向传播(BP)方法 D. 这些均不是 正确答案是:A 解析: batch normalization 就…...

C语言题目之单身狗2
文章目录 一、题目二、思路三、代码实现 提示:以下是本篇文章正文内容,下面案例可供参考 一、题目 二、思路 第一步 在c语言题目之打印单身狗我们已经讲解了在一组数据中出现一个单身狗的情况,而本道题是出现两个单身狗的情况。根据一个数…...
)
Vue2学习笔记(03关于VueComponent)
1.school组件本质是一个名为Vuecomponent的构造函数,且不是程序员定义的,是Vue.extend生成的。 2.我们只需要写<school/>或<school></school>,Vue解析时会帮我们创建school组件的实例对象,即Vue帮我们执行的:new Vuecompo…...

微服务架构中常用技术框架
认证授权 Spring Security OAuth 2.0 JWT Keycloak Istio Apache Shiro 日志监控 ELK Prometheus Grafana Fluentd CI/CD Jenkins GitLab CI CircleCI ArgoCD 服务通信 gRPC REST API Apache Thrift Apache Avro Apache Dubbo OpenFegin 断路器 Hystr…...

剪映专业版教程:制作直接选择排序算法原理演示视频
前言 今天教大家用剪映制作直接选择排序算法的原理演示视频。直接选择排序的原理是:在同一个数组中,先挑一个最小的,跟第一位交换;待排序下标往后移到第二位,从这里开始往后找一个最小的,跟第二位交换&…...

BS-RoFormer:音频分离技术的革命性突破,从混合音乐中提取纯净音轨的终极指南
BS-RoFormer:音频分离技术的革命性突破,从混合音乐中提取纯净音轨的终极指南 【免费下载链接】BS-RoFormer Implementation of Band Split Roformer, SOTA Attention network for music source separation out of ByteDance AI Labs 项目地址: https:/…...

Nodejs后端服务如何集成Taotoken提供稳定的AI功能接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 后端服务如何集成 Taotoken 提供稳定的 AI 功能接口 在构建现代后端服务时,集成大模型能力已成为提升应用智能…...

企业微信SCRM与客户管理系统推荐:2026年这12家值得关注
2026年,一个企业要选客户管理系统,第一个要回答的问题是:你的客户在哪里?如果答案是"微信",那企业微信SCRM就是最直接的路径——而在这个领域,微盛企微管家作为企业微信最大ISV,服务了…...

Python盲水印终极指南:3个简单步骤保护你的数字版权
Python盲水印终极指南:3个简单步骤保护你的数字版权 【免费下载链接】BlindWatermark 使用盲水印保护创作者的知识产权using invisible watermark to protect creators intellectual property 项目地址: https://gitcode.com/gh_mirrors/bl/BlindWatermark 在…...

如何用QKeyMapper在5分钟内搞定Windows设备按键映射:终极免费解决方案
如何用QKeyMapper在5分钟内搞定Windows设备按键映射:终极免费解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到…...

DdddOcr:5分钟掌握Python验证码识别,彻底告别手动输入![特殊字符]
DdddOcr:5分钟掌握Python验证码识别,彻底告别手动输入!🚀 【免费下载链接】ddddocr 带带弟弟 通用验证码识别OCR pypi版 项目地址: https://gitcode.com/gh_mirrors/dd/ddddocr 还在为繁琐的验证码输入而烦恼吗?…...

Adobe-GenP 3.0终极指南:三步免费解锁Adobe全家桶的完整教程
Adobe-GenP 3.0终极指南:三步免费解锁Adobe全家桶的完整教程 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 想要免费使用Adobe Creative Cloud专业软件…...

终极OpenHTMLtoPDF教程:5分钟构建专业PDF生成器
终极OpenHTMLtoPDF教程:5分钟构建专业PDF生成器 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF/UA)!…...

Miniconda虚拟环境配置踩坑实录:从‘CondaHTTPError’到完美隔离环境
Miniconda虚拟环境配置踩坑实录:从‘CondaHTTPError’到完美隔离环境 第一次在终端输入conda create -n myenv python3.8时,满心期待能快速搭建起一个干净的Python工作环境。然而几秒钟后,屏幕上突然跳出的红色报错信息让整个流程戛然而止&a…...