位图与布隆过滤器
引例
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
思路1:排序+二分查找
思路2:哈希或红黑树
因为40亿个整数要占用16GB
102410241024Byte 约等于10亿Byte=1GB
40亿*4Byte = 16GB
16G太大放不进内存,就算我们用归并排序对文件排序,也无法对文件使用二分查找,如果一段一段的放进内存里面查找的话,还不如在读取的时候就直接把他那个数挨个查找,放在内存,所以用哈希桶和红黑存储就更加不可能了,毕竟红黑树和哈希桶存储还有导致其他的内存开销。
位图
位图就是用数据中的一个位来标识,然后用哈希的直接定址法存储那一个标识bit位来表示某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。
逻辑结构图:
 问:如何确定我要存储的x值应该存储到哪一个位置?
问:如何确定我要存储的x值应该存储到哪一个位置?
x/8=x存储在那一个char里面
x%8= x存储在char的那一个位里面
问:如何在第一个char中的第5个字节置为1?
对0x01左移动5位(设为y),然后再对第一个char(设为x),x|=y,因为0|或任何数都是该数本身,而1|任何数都是1
注意,这里的为什么是左移而不是右移,要清楚左右移不是指移动的方向,而是指右移一向低地址移动,左移-向高地址移动
问:如何在第一个char中的第5个字节置为0?
对0x01左移动5位(设为y),在对y取反就会得到 1110 1111, x&=y,因为1&任何数都是该数本身,而0&任何数都是0
位图的作用
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
代码实现:
#pragma once
#include <vector>
using namespace std;template<size_t N>
class bitset
{
public:bitset(){_bits.resize(N / 8 + 1, 0);}//置1void set(size_t x){size_t i = x / 8;size_t j = x % 8;_bits[i] |= (0x01 << j);//为什么是左移动}//置零void reset(size_t x){size_t i = x / 8;size_t j = x % 8;_bits[i] &= ~(0x01 << j);}// 查值bool test(size_t x){size_t i = x / 8;size_t j = x % 8;return _bits[i] & (0x01 << j);}private:vector<char> _bits;
};
int main()
{bitset<-1> bitset;return 0;
}
注意这里这个bitset使用了一个非类型的模版参数来传入一个N用来表述,用于在开空间的时候要开多少多大?
非类型模板参数
模板参数分类类型形参与非类型形参。
类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
引例的解决方案
把40亿存到位图中,再用位图的test去查那个无符号整数到底有没有在位图里面
位图的题目:
1. 给定100亿个整数,设计算法找到只出现一次的整数?
解答:用两个位图来标识出现的状态, 00表示一次都没有出现,01表示出现一次,如果在01状态之后再出现的话就是多次出现
2. 1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
解答:同样用两个位图来标识出现的状态00一次都没有出现 01出现一次 10出现两次 11出现两次以上。
代码实现
#pragma once
#include "bitset.h"template<size_t N>
class TwoBitset
{
public:// 给定100亿个整数,设计算法找到只出现一次的整数?bool Test_OneTime(size_t x) const{if (bit1.test(x) && !bit2.test(x)){return true;}return false;}// 1个文件有100亿个int,1G内存,// 设计算法找到出现次数不超过2次的所有整数bool Test_NoMoreThanTwoTime(size_t x) const{if (bit1.test(x) && bit2.test(x)){return false;}return true;}void set(size_t x){if (!bit1.test(x) && !bit2.test(x)){bit1.set(x);}else if (bit1.test(x) && !bit2.test(x)){bit1.reset(x);bit2.set(x);}else if (!bit1.test(x) && bit2.test(x)){bit1.set(x);}}
private:bitset<N> bit1;bitset<N> bit2;
};
3. 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
解答:用两个位图来存储两个文件,然后再对两个位图进行 &预算,得出的第三个位图就是交集
代码实现
//给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
void intersection()
{int a1[] = { 100,21,21,32,121,123,123,31,32,12,41,213,231,413312,312,213,122 };int a2[] = { -1,-1,100,21,21,21,32,32,121,123,123,31,32,1,12,4321,24,12,412, };bitset<-1> bit1;bitset<-1> bit2;for (auto val : a1){bit1.set(val);}for (auto val : a2){bit2.set(val);}for (size_t i = 0; i < -1; i++){if (bit1.test(i) && bit2.test(i)){cout << i << endl;}}
}
位图的缺点
只能映射整形,其他类型如:浮点数、string等等不能存储映射
布隆过滤器
布隆过滤器是由布隆在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你“某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
布隆过滤器就是用位图+多个哈希函数映射来确定字符串在不在的一个key模型,但是布隆过滤器确定一个字符串不在是准确的,在是不准确的,如下图:
我们存放不同名字的时候,会映射三个位置,如果我搜寻这字符串的时候少于三个位置就是不在的,为什么呢?因为我们是映射是通过三个函数去映射三个位置,如果只有二个位置,那么就证明我并没有存进来,这那个位置只不过是存放其他值的时候刚好冲突到该字符串映射的位置而已,而为什么说在是不准的呢?是因为这三个映射位置也有可能是其他值冲突导致碰巧映射到而已。

White是没有映射存放的,但是碰巧他的映射位置被其他字符串冲突了
布隆过滤器实现代码
struct BKDRHash
{size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash += ch;hash *= 31;}return hash;}
};struct APHash
{size_t operator()(const string& s){size_t hash = 0;for (long i = 0; i < s.size(); i++){size_t ch = s[i];if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}}return hash;}
};struct DJBHash
{size_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash += (hash << 5) + ch;}return hash;}
};// N最多会插入key数据的个数
template<size_t N,
class K = string,
class Hash1 = BKDRHash,
class Hash2 = APHash,
class Hash3 = DJBHash>
class BloomFilter
{
public:void set(const K& key){size_t len = N*_X;size_t hash1 = Hash1()(key) % len;_bs.set(hash1);size_t hash2 = Hash2()(key) % len;_bs.set(hash2);size_t hash3 = Hash3()(key) % len;_bs.set(hash3);//cout << hash1 << " " << hash2 << " " << hash3 << " " << endl << endl;}bool test(const K& key){size_t len = N*_X;size_t hash1 = Hash1()(key) % len;if (!_bs.test(hash1)){return false;}size_t hash2 = Hash2()(key) % len;if (!_bs.test(hash2)){return false;}size_t hash3 = Hash3()(key) % len;if (!_bs.test(hash3)){return false;}// 在 不准确的,存在误判// 不在 准确的return true;}
private:static const size_t _X = 6;bitset<N*_X> _bs;
};
布隆过滤器的场景
能容忍误判的场景。比如:注册时,快速判断昵称是否使用过,假设现在要实现注册表单去判断有没有人用过昵称,就可以用到布隆过滤器,因为布隆过滤器对于不在这个结果是准确的。所以可以把昵称存放在布隆过滤器中快速过滤
哈希切分
题目1:给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
首先,估算一下文件大小,100亿个query大概需要占用多少空间? 假设单个query,平均50byte,100亿个query是5000亿byte大概估算占用500G
用哈希函数把文件映射成小文件

为什么哈希切分只需要找A、B中对应i号的文件即可?
因为在哈希切分的时候,query字符串经过哈希函数的切分,会把冲突的字符串放在同一个桶里,只需要桶对桶之间进行交集计算即可
问题:因为不是平均切分,可能会出现冲突多,每个Ai,Bi小文件过大。…假设两个都是4-5G
所以要分类处理,
直接使用一个unordered set/set,依次读取文件query,插入set中
1、如果读取整个小文件query,都可以成功插入set,那么说明单个文件有大量重复的query
2、如果读取整个小文件query,插入过程中抛异常,则是单个文件有大量不同的query,换其他哈希函数,再次分割,再求交集。说明:set插入key,如果已经有了,返回false;如果没有内存,会抛bad alloc异常,剩下的都会成功。
相关文章:
位图与布隆过滤器
引例 给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。 思路1:排序二分查找 思路2:哈希或红黑树 因为40亿个整数要占用16GB 102410241024Byte 约等于10亿Byte1GB 40亿*4Byte 16G…...

【题解】—— LeetCode一周小结38
🌟欢迎来到 我的博客 —— 探索技术的无限可能! 🌟博客的简介(文章目录) 【题解】—— 每日一道题目栏 上接:【题解】—— LeetCode一周小结37 16.公交站间的距离 题目链接:1184. 公交站间的距…...
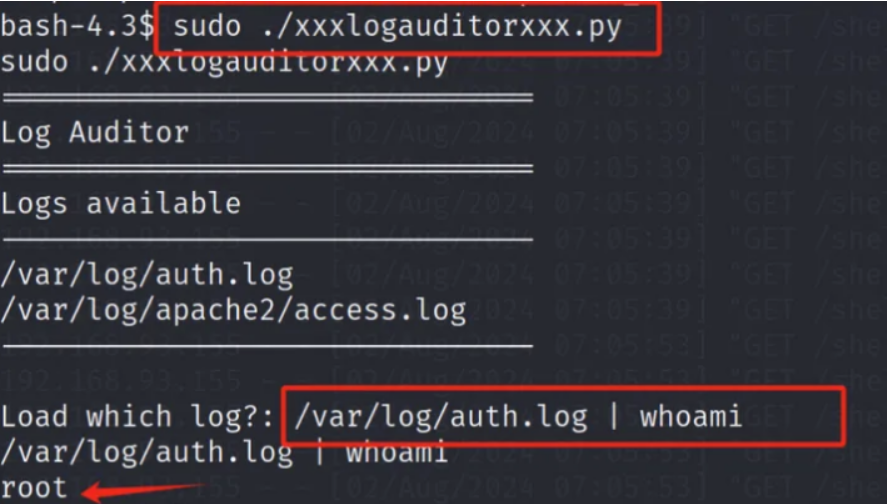
EvilScience靶机详解
主机发现 arp-scan -l 得到靶机ip 192.168.229.152 端口扫描 nmap -sV -A -T4 192.168.1.20 这段代码使用 nmap 命令来扫描目标主机 192.168.1.20,并执行以下操作:-sV:探测开放的端口,以确定服务/版本信息。-A:启…...

算法练习题24——leetcode3296移山所需的最小秒数(二分模拟)
【题目描述】 【代码示例(java)】 class Solution {// 计算让工人们将山的高度降到0所需的最少时间public long minNumberOfSeconds(int mountainHeight, int[] workerTimes) {long left 0; // 最少时间初始为0long right 0; // 最大时间初始化为0// …...

excel 单元格一直显示年月日
excel 单元格一直显示年月日,在单元格上右键选择单元格格式,选择日期时单元格会显示成日期格式...

【线程】线程的控制
本文重点:理解线程控制的接口 前言 内核中是没有很明确线程的概念的,只有轻量级进程的概念,不会提供直接给我们线程的系统调用,而会给我们提供轻量级进程的系统调用。我们用户是需要线程的接口的,在应用层࿰…...

掌握 Spring:从新手到高手的常见问题汇总
一提起Spring,总感觉有太多知识,无法详尽,有些基础理解就先不说了,相信大家都已经用过Spring了 下面简单针对常见Spring面试题做些回答 核心特性 IOC容器spring事件资源管理国际化校验数据绑定类型转换spirng表达式面向切面编程……...

机器学习——Bagging
Bagging: 方法:集成n个base learner模型,每个模型都对原始数据集进行有放回的随机采样获得随机数据集,然后并行训练。 回归问题:n个base模型进行预测,将得到的预测值取平均得到最终结果。 分类问题…...

日志体系结构与框架:历史、实现与如何在 Spring Cloud 中使用日志体系
文章目录 1. 引言2. 日志体系结构3. 日志框架的发展历程日志框架特点对比 4. 日志记录器的使用与管理使用 SLF4J 和 Logback 的日志记录示例 5. Spring Cloud 中的日志使用5.1 日志框架集成5.2 分布式追踪:Spring Cloud Sleuth 和 Zipkin添加 Sleuth 和 Zipkin 依赖…...

图文深入理解SQL语句的执行过程
List item 本文将深入介绍SQL语句的执行过程。 一.在RDBMS(关系型DB)中,看似很简单的一条已写入DB内存的SQL语句执行过程却非常复杂,也就是说,你执行了一条诸如select count(*) where id 001 from table_name的非常简…...

ubuntu安装StarQuant
安装boost 下面展示一些 内联代码片。 sudo apt install libboost-all-dev -y安装libmongoc-1.0 链接: link // An highlighted block sudo apt install libmongoc-1.0-0 sudo apt install libbson-1.0 sudo apt install cmake libssl-dev libsasl2-dev编译源码 $ git clone…...
)
学习篇 | Jupyter 使用(notebook hub)
1. JupyterHub 1.1 快速尝试 jupyterhub -f/path/jupyter_config.py --no-ssl1.2 长期后台运行 bash -c "nohup jupyterhub -f/path/jupyter_config.py --no-ssl" > ~/jupyterhub.log 2>&1 &1.3 帮助 jupyterhub --help2. Jupyter Notebook 2.1 快…...
-虚拟内存swap交换分区扩展)
【裸机装机系列】8.kali(ubuntu)-虚拟内存swap交换分区扩展
推荐阅读: 1.kali(ubuntu)-为什么弃用ubuntu,而选择基于debian的kali操作系统 linux swap交换分区,相当于win系统虚拟内存的概念。当linux系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前…...

异步请求的方法以及原理
异步请求是指在发送请求后,不会阻塞程序的执行,而是继续执行后续的代码,等待请求返回后再执行相应的回调函数。常见的异步请求方法包括使用XMLHttpRequest对象(XHR)和fetch API。 异步请求的方法 1. XMLHttpRequest (X…...

SpringCloud入门(六)Nacos注册中心(下)
一、Nacos环境隔离 Nacos提供了namespace来实现环境隔离功能。 nacos中可以有多个namespace。namespace下可以有group、service等。不同namespace之间相互隔离,例如不同namespace的服务互相不可见。 使用Nacos Namespace 环境隔离 步骤: 1.在Nacos控制…...

【RDMA】mlxlink检查和调试连接状态及相关问题--驱动工具
简介 mlxlink工具用于检查和调试连接状态及相关问题。该工具可以用于不同的链路和电缆(包括被动、电动、收发器和背板)。 属于mft工具套件的一个工具,固件工具 Firmware Tools (MFT):https://blog.csdn.net/bandaoyu/article/details/14242…...

QT For Android开发-打开PPT文件
一、前言 需求: Qt开发Android程序过程中,点击按钮就打开一个PPT文件。 Qt在Windows上要打开PPT文件或者其他文件很容易。可以使用QDesktopServices打开文件,非常方便。QDesktopServices提供了静态接口调用系统级别的功能。 这里用的QDesk…...
SpringBoot教程(三十) | SpringBoot集成Shiro权限框架
SpringBoot教程(三十) | SpringBoot集成Shiro权限框架 一、 什么是Shiro二、Shiro 组件核心组件其他组件 三、流程说明shiro的运行流程 四、SpringBoot 集成 Shiro (shiro-spring-boot-web-starter方式)1. 添加 Shiro 相关 maven2…...

[ffmpeg] 视频格式转换
本文主要梳理 ffmpeg 中的视频格式转换。由于上屏的数据是 rgba,编码使用的是 yuv数据,所以经常会使用到视频格式的转换。 除了使用 ffmpeg进行转换,还可以通过 libyuv 和 directX 写 shader 进行转换。 之前看到文章说 libyuv 之前是 ffmpeg…...
 git-repo https证书认证问题)
git-repo系列教程(3) git-repo https证书认证问题
文章目录 问题描述解决步骤1.下载证书2.测试证书是否正常3.设置环境变量 总结 问题描述 在使用git repo 同步仓库时,发现不能同步,出现如下提示错误: % Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left …...

如何用Akagi打造实时麻将AI辅助系统:从新手到高手的完整指南
如何用Akagi打造实时麻将AI辅助系统:从新手到高手的完整指南 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majsoul, Tenhou, Riichi City,…...
:Tool Calling 工具调用机制总览)
AI Agent 项目学习笔记(八):Tool Calling 工具调用机制总览
1. 本期目标 前几期主要分析了 ai_agent 项目的对话主链路、Advisor、多轮记忆和 RAG 检索增强。到目前为止,智能体已经具备了这些能力: 能够和用户多轮对话 能够记住当前会话上下文 能够参考本地知识库回答 能够通过 RAG 检索增强回答质量但是这些能力…...

如何让老旧Windows系统重新获得安全更新:Legacy Update完整解决方案
如何让老旧Windows系统重新获得安全更新:Legacy Update完整解决方案 【免费下载链接】LegacyUpdate Get back online, activate, and install updates on your legacy Windows PC 项目地址: https://gitcode.com/gh_mirrors/le/LegacyUpdate 还在为Windows X…...

告别造影剂过敏风险:用Python和PyTorch复现CTA-GAN,从平扫CT生成血管增强图像
告别造影剂过敏风险:用Python和PyTorch复现CTA-GAN,从平扫CT生成血管增强图像 医学影像技术正经历一场由深度学习驱动的革命。对于需要血管造影检查的患者而言,传统CT血管造影(CTA)必须注射含碘造影剂,这不…...

专科英语A级和B级考试历年真题试卷及答案PDF电子版
高等学校英语应用能力考试(PRETCO)A 级、B 级历年真题试卷及答案 PDF 电子版,专为高职高专、大专在校生备考整理。内容涵盖2022年、2023年、2024年、2025年 6 月、12 月全套真题,含听力原文、答案解析、写作范文,题型覆…...

如何用QKeyMapper在5分钟内搞定Windows设备按键映射:终极免费解决方案
如何用QKeyMapper在5分钟内搞定Windows设备按键映射:终极免费解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到…...

Cortex-Debug架构深度解析:从GDB MI协议到VSCode调试体验的完整实现
Cortex-Debug架构深度解析:从GDB MI协议到VSCode调试体验的完整实现 【免费下载链接】cortex-debug Visual Studio Code extension for enhancing debug capabilities for Cortex-M Microcontrollers 项目地址: https://gitcode.com/gh_mirrors/co/cortex-debug …...

为什么说Ohook重新定义了Office激活的技术边界?
为什么说Ohook重新定义了Office激活的技术边界? 【免费下载链接】ohook An universal Office "activation" hook with main focus of enabling full functionality of subscription editions 项目地址: https://gitcode.com/gh_mirrors/oh/ohook 当…...

计算机专业生打 CTF 全指南:从新手小白到赛事拿分,附实战避坑手册_ctf比赛自己带电脑吗
作为计算机专业毕业的过来人,我始终觉得:CTF 比赛是大学生把课本知识落地成硬技能的最佳载体。 刚上大二时,我还是个只会敲基础代码、对 网络安全停留在课本概念的小白,靠着 3 次参赛经历,不仅吃透了操作系统、计算机…...

如何用Win11Debloat免费为Windows系统瘦身:终极优化指南
如何用Win11Debloat免费为Windows系统瘦身:终极优化指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...