【线程】线程的控制
本文重点:理解线程控制的接口
前言
内核中是没有很明确线程的概念的,只有轻量级进程的概念,不会提供直接给我们线程的系统调用,而会给我们提供轻量级进程的系统调用。我们用户是需要线程的接口的,在应用层,人们封装了轻量级进程的系统调用,为用户直接提供线程的接口,这个封装的就是线程库pthread库,这个是第三方库,几乎所有的Linux系统都会自带这个库,当我们进行编译链接时,要指定这个库
线程的创建
函数pthread_create

![]()
参数:
thread:输出型参数,返回线程ID
attr:设置线程的属性,attr为nullptr表示使用默认属性
start_routine:是个函数指针,线程启动后要执行的函数
arg:传给线程启动函数的参数,线程被创建成功,新线程回调线程函数的时候需要参数,这个参数是给线程函数传递的返回值:成功返回0,失败返回错误码
传统的一些函数是,成功返回0,失败返回-1,并且对全局变量errno赋值以指示错误。
pthreads函数出错时不会设置全局变量errno(而大部分其他线程函数会这样做)。而是将错误代码通过返回值返回
pthreads同样也提供了线程内的errno变量,以支持其它使用errno的代码。对于pthreads函数的错误,建议通过返回值判定,因为读取返回值要比读取线程内的errno变量的开销更小
线程的函数的参数和返回值,不仅仅可以用来进行传递一般参数,也可以传递对象
#include<iostream>
#include<pthread.h>
#include<unistd.h>
#include<stdlib.h>using namespace std;void* threadroutine(void * arg)
{const char* name=(const char*)arg;while(true){cout<<name<<",pid: "<<getpid()<<endl;sleep(2);}
}int main()
{pthread_t tid;pthread_create(&tid,nullptr,threadroutine,(void*)"new thread");while(true){cout<<"main thread,pid: "<<getpid()<<endl;sleep(1);}return 0;
}
发现它们的pid是一样的
ps -aL 查看系统轻量级进程

LWP(light weight process):线程ID,这个线程ID属于进程调度的范畴。因为线程是轻量级进程,是操作系统调度器的最小单位,所以需要一个数值来唯一表示该线程。
我们发现一个PID和LWP是一样的,那这个就是主线程,其他就是创建出来的线程
线程组内的第一个线程,在用户态被称为主线程(main thread),内核在创建第一个线程时,会将线程组的ID的值设置成第一个线程的线程ID,既主线程的进程描述符。所以线程组内存在一个线程ID等于进程ID,而该线程即为线程组的主线程
至于线程组其他线程的ID则有内核负责分配,其线程组ID总是和主线程的线程组ID一致,无论是主线程直接创建线程,还是创建出来的线程再次创建线程,都是这样
强调一点,线程和进程不一样,进程有父进程的概念,但在线程组里面,所有的线程都是对等关系
线程的终止
如果需要只终止某个线程而不终止整个进程,可以有三种方法:
1. 从线程函数return。这种方法对主线程不适用,从main函数return相当于调用exit。
2. 线程可以调用pthread_ exit终止自己。
3. 一个线程可以调用pthread_ cancel终止同一进程中的另一个线程。
注意:以前的进程终止函数exit是用来终止进程的
函数pthread_exit

参数和线程函数的返回值类型是一样的都是void*,这就和return终止线程差不多了
需要注意,pthread_exit或者return返回的指针所指向的内存单元必须是全局的或者是用malloc分配的,不能在线程函数的栈上分配,因为当其它线程得到这个返回指针时线程函数已经退出了。
函数pthread_cancel
取消执行中的线程

线程的等待
在进程里有个进程等待,父进程等待子进程,是为了防止僵尸进程,回收子进程,防止内存泄漏
为什么需要线程等待?已经退出的线程,其空间没有被释放,仍然在进程的地址空间内。创建新的线程不会复用刚才退出线程的地址空间。那么线程中也要有线程等待,如果没有,那么也会有类似于僵尸的状态
函数pthread_join


函数的作用:等待指定线程,可以获取这个线程函数的返回值void*(终止状态)
参数:
thread:线程ID
value_ptr:它指向一个指针,就是指向线程创建时,调用的线程函数的返回值void*
返回值:成功返回0;失败返回错误码

调用该函数的线程将阻塞等待,直到id为thread的线程终止。thread线程以不同的方法终止,通过pthread_join得到的终止状态是不同的,总结如下:
1. 如果thread线程通过return返回,value_ ptr所指向的单元里存放的是thread线程函数的返回值。
2. 如果thread线程被别的线程调用pthread_ cancel异常终掉,value_ ptr所指向的单元里存放的是常数PTHREAD_CANCELED(一个宏常数,就是-1)。
3. 如果thread线程是自己调用pthread_exit终止的,value_ptr所指向的单元存放的是传pthread_exit的参数。
4. 如果对thread线程的终止状态不感兴趣,可以传nullptr给value_ ptr参数。
#include<iostream>
#include<pthread.h>
#include<unistd.h>
#include<stdlib.h>using namespace std;void* threadroutine(void * arg)
{const char* name=(const char*)arg;int cnt=5;while(true){cout<<name<<",pid: "<<getpid()<<endl;sleep(1);cnt--;if(cnt==0) break;}return (void*)1;//我的当前平台,地址是64位,8字节,而int是4字节,不进行强转会导致混乱
}int main()
{pthread_t tid;pthread_create(&tid,nullptr,threadroutine,(void*)"new thread");void * retval;pthread_join(tid,&retval);// main thread等待的时候,默认是阻塞等待的!cout << "main thread quit ..., ret: " << (long long int)retval << endl;return 0;
}
为什么我们在这里join的时候不考虑异常呢??因为做不到,线程异常了整个进程都会挂掉。线程的健壮性低
线程的分离
上面的线程等待,只能阻塞等待,那如果不想阻塞怎么办,并且不关心线程的返回值,那就让线程分离,线程分离之后,主线程就不管了,主线程就干自己的事了,自己的资源自己释放回收了,虽然线程分离了,但是还是属于这个进程的
可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离
joinable和分离是冲突的,一个线程不能既是joinable又是分离的,也就是说,线程分离了,主线程就不用等待回收线程了

#include<iostream>
#include<cstring>
#include<unistd.h>
#include<pthread.h>
void* PthreadRoutine(void* args)
{int i=0;pthread_detach(pthread_self());while(i<3){cout<<"child thread ,pid: "<<getpid()<<endl;i++;sleep(1);}return nullptr;
}
int main()
{pthread_t tid;pthread_create(&tid,nullptr,PthreadRoutine,nullptr);sleep(1);//确保分离成功int n=pthread_join(tid,nullptr);printf("n = %d, who = 0x%x, why: %s\n", n, tid, strerror(n));return 0;}

线程ID及进程地址空间布局
pthread_ create函数会产生一个线程ID,存放在第一个参数指向的地址中。该线程ID和前面说的线程ID不是一回事。前面讲的线程ID属于进程调度的范畴。因为线程是轻量级进程,是操作系统调度器的最小单位,所以需要一个数值来唯一表示该线程。
pthread_ create函数第一个参数指向一个虚拟内存单元,该内存单元的地址即为新创建线程的线程ID,属于NPTL线程库的范畴。线程库的后续操作,就是根据该线程ID来操作线程的。
线程库NPTL提供了pthread_ self函数,可以获得线程自身的ID
函数pthread_self

函数clone

这个函数clone是系统调用,用来创建轻量级进程的,前言说的pthread库的底层就是用这个函数封装的

使用线程库,是要加载到内存的,它是动态库,所以会在地址空间的共享区。
线程的概念是库给我们维护的,线程库注定要维护多个线程,线程库要管理这些线程,先描述再组织,每个线程都会有一个库级别的结构体tcb,这个结构体的起始地址就是线程的id

除了主线程外,所有的其他线程的独立栈,都在共享区,具体来讲,是在pthread库中,tid指向用户的tcb。全局变量和堆区都是线程共享的,栈不是,每个线程都有自己的独立栈
目前,我们的原生线程,pthread库,原生线程库,C++11 语言本身也已经支持多线程了 vs 原生线程库。其实C++的多线程底层封装的就是Linux系统下的原生线程库,为什么C++移值性高,就是因为C++的代码在不同平台上都可以跑,在Linux下跑多线程底层就是Linux的原生线程库,在Windows跑,底层就是Windows的原生线程库,C++语音在底层设计时,不同的系统有不同的设计,但是在上层看来都一样
#include <iostream>
#include <thread>using namespace std;void threadrun()
{while(true){cout << "I am a new thead for C++" << endl;sleep(1);}
}int main()
{thread t1(threadrun);t1.join();return 0;
}多线程的创建
1.创建多线程
#include<iostream>
#include<string>
#include<vector>
#include<unistd.h>
#include<pthread.h>using namespace std;#define NUM 4class ThreadData
{
public:ThreadData(int number){_threadname="thread-"+to_string(number);}
public:string _threadname;
};string toHex(pthread_t tid)
{char buf[128];snprintf(buf,sizeof(buf),"0x%x",tid);return buf;}
void* ThreadRoutine(void* args)
{ThreadData* td=static_cast<ThreadData*>(args);string tid=toHex(pthread_self());pid_t pid=getpid();int i=0;while(i<3){cout<<td->_threadname<<" pid: "<<pid<<" tid: "<<tid<<endl;i++;sleep(1);}delete td;return nullptr;
}
int main()
{vector<pthread_t> tids;//创建多线程for(int i=1;i<=NUM;i++){pthread_t tid;ThreadData* td=new ThreadData(i);pthread_create(&tid,nullptr,ThreadRoutine,td);tids.push_back(tid);sleep(1);}//等待多线程for(auto tid:tids){pthread_join(tid,nullptr);}cout<<"main thread wait success"<<endl;return 0;
}

上面代码在主线程开辟的堆空间传递给了子线程,子线程还可以利用,说明堆空间是被所有线程共享的
2.验证全局变量共享
在上面代码上加个全局变量g_val,在子线程打印他的地址
#include<iostream>
#include<string>
#include<vector>
#include<unistd.h>
#include<pthread.h>using namespace std;#define NUM 4
int g_val=0;//定义一个全局class ThreadData
{
public:ThreadData(int number){_threadname="thread-"+to_string(number);}
public:string _threadname;
};string toHex(pthread_t tid)
{char buf[128];snprintf(buf,sizeof(buf),"0x%x",tid);return buf;}
void* ThreadRoutine(void* args)
{ThreadData* td=static_cast<ThreadData*>(args);string tid=toHex(pthread_self());pid_t pid=getpid();int i=0;while(i<3){cout<<td->_threadname<<" pid: "<<pid<<" tid: "<<tid<<",g_val: "<<g_val<<",&g_val: "<<&g_val<<endl;i++;sleep(1);}delete td;return nullptr;
}
int main()
{vector<pthread_t> tids;//创建多线程for(int i=1;i<=NUM;i++){pthread_t tid;ThreadData* td=new ThreadData(i);pthread_create(&tid,nullptr,ThreadRoutine,td);tids.push_back(tid);sleep(1);}//等待多线程for(auto tid:tids){pthread_join(tid,nullptr);}cout<<"main thread wait success"<<endl;return 0;
}

发现这个全局变量的地址都是一样的,说明全局变量被所有线程共享
3.线程的局部存储
如果线程不想共享全局变量,想要自己私有的全局变量,那么在全局变量加__thread修饰(两个下划线),这个是个编译选项,只能用来定义内置类型,不能修饰自定义类型,那么这个全局变量就不在全局区了,就在线程的栈结构的局部存储中,这个是线程级别的全局变量,也就是在某个线程里面时全局的


地址不一样,并且这个地址挺大的,说明在中间的堆栈之间
4.验证线程具有独立栈结构
在每个线程里面加个变量test_i,打印他的地址
#include<iostream>
#include<string>
#include<vector>
#include<unistd.h>
#include<pthread.h>using namespace std;#define NUM 4class ThreadData
{
public:ThreadData(int number){_threadname="thread-"+to_string(number);}
public:string _threadname;
};string toHex(pthread_t tid)
{char buf[128];snprintf(buf,sizeof(buf),"0x%x",tid);return buf;}
void* ThreadRoutine(void* args)
{ThreadData* td=static_cast<ThreadData*>(args);string tid=toHex(pthread_self());pid_t pid=getpid();int i=0;int test_i=0;while(i<3){cout<<td->_threadname<<" pid: "<<pid<<" tid: "<<tid<<",test_i: "<<test_i<<",&test_i: "<<&test_i<<endl;;i++;sleep(1);}delete td;return nullptr;
}
int main()
{vector<pthread_t> tids;//创建多线程for(int i=1;i<=NUM;i++){pthread_t tid;ThreadData* td=new ThreadData(i);pthread_create(&tid,nullptr,ThreadRoutine,td);tids.push_back(tid);sleep(1);}//等待多线程for(auto tid:tids){pthread_join(tid,nullptr);}cout<<"main thread wait success"<<endl;return 0;
}

发现test_i的地址都不一样,说明它们有独立的栈结构,并不是私有的栈结构,主线程想访问也可以访问的,线程中没有秘密,如果要访问还是可以访问的
相关文章:
【线程】线程的控制
本文重点:理解线程控制的接口 前言 内核中是没有很明确线程的概念的,只有轻量级进程的概念,不会提供直接给我们线程的系统调用,而会给我们提供轻量级进程的系统调用。我们用户是需要线程的接口的,在应用层࿰…...

掌握 Spring:从新手到高手的常见问题汇总
一提起Spring,总感觉有太多知识,无法详尽,有些基础理解就先不说了,相信大家都已经用过Spring了 下面简单针对常见Spring面试题做些回答 核心特性 IOC容器spring事件资源管理国际化校验数据绑定类型转换spirng表达式面向切面编程……...

机器学习——Bagging
Bagging: 方法:集成n个base learner模型,每个模型都对原始数据集进行有放回的随机采样获得随机数据集,然后并行训练。 回归问题:n个base模型进行预测,将得到的预测值取平均得到最终结果。 分类问题…...

日志体系结构与框架:历史、实现与如何在 Spring Cloud 中使用日志体系
文章目录 1. 引言2. 日志体系结构3. 日志框架的发展历程日志框架特点对比 4. 日志记录器的使用与管理使用 SLF4J 和 Logback 的日志记录示例 5. Spring Cloud 中的日志使用5.1 日志框架集成5.2 分布式追踪:Spring Cloud Sleuth 和 Zipkin添加 Sleuth 和 Zipkin 依赖…...

图文深入理解SQL语句的执行过程
List item 本文将深入介绍SQL语句的执行过程。 一.在RDBMS(关系型DB)中,看似很简单的一条已写入DB内存的SQL语句执行过程却非常复杂,也就是说,你执行了一条诸如select count(*) where id 001 from table_name的非常简…...

ubuntu安装StarQuant
安装boost 下面展示一些 内联代码片。 sudo apt install libboost-all-dev -y安装libmongoc-1.0 链接: link // An highlighted block sudo apt install libmongoc-1.0-0 sudo apt install libbson-1.0 sudo apt install cmake libssl-dev libsasl2-dev编译源码 $ git clone…...
)
学习篇 | Jupyter 使用(notebook hub)
1. JupyterHub 1.1 快速尝试 jupyterhub -f/path/jupyter_config.py --no-ssl1.2 长期后台运行 bash -c "nohup jupyterhub -f/path/jupyter_config.py --no-ssl" > ~/jupyterhub.log 2>&1 &1.3 帮助 jupyterhub --help2. Jupyter Notebook 2.1 快…...
-虚拟内存swap交换分区扩展)
【裸机装机系列】8.kali(ubuntu)-虚拟内存swap交换分区扩展
推荐阅读: 1.kali(ubuntu)-为什么弃用ubuntu,而选择基于debian的kali操作系统 linux swap交换分区,相当于win系统虚拟内存的概念。当linux系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前…...

异步请求的方法以及原理
异步请求是指在发送请求后,不会阻塞程序的执行,而是继续执行后续的代码,等待请求返回后再执行相应的回调函数。常见的异步请求方法包括使用XMLHttpRequest对象(XHR)和fetch API。 异步请求的方法 1. XMLHttpRequest (X…...

SpringCloud入门(六)Nacos注册中心(下)
一、Nacos环境隔离 Nacos提供了namespace来实现环境隔离功能。 nacos中可以有多个namespace。namespace下可以有group、service等。不同namespace之间相互隔离,例如不同namespace的服务互相不可见。 使用Nacos Namespace 环境隔离 步骤: 1.在Nacos控制…...

【RDMA】mlxlink检查和调试连接状态及相关问题--驱动工具
简介 mlxlink工具用于检查和调试连接状态及相关问题。该工具可以用于不同的链路和电缆(包括被动、电动、收发器和背板)。 属于mft工具套件的一个工具,固件工具 Firmware Tools (MFT):https://blog.csdn.net/bandaoyu/article/details/14242…...

QT For Android开发-打开PPT文件
一、前言 需求: Qt开发Android程序过程中,点击按钮就打开一个PPT文件。 Qt在Windows上要打开PPT文件或者其他文件很容易。可以使用QDesktopServices打开文件,非常方便。QDesktopServices提供了静态接口调用系统级别的功能。 这里用的QDesk…...
SpringBoot教程(三十) | SpringBoot集成Shiro权限框架
SpringBoot教程(三十) | SpringBoot集成Shiro权限框架 一、 什么是Shiro二、Shiro 组件核心组件其他组件 三、流程说明shiro的运行流程 四、SpringBoot 集成 Shiro (shiro-spring-boot-web-starter方式)1. 添加 Shiro 相关 maven2…...

[ffmpeg] 视频格式转换
本文主要梳理 ffmpeg 中的视频格式转换。由于上屏的数据是 rgba,编码使用的是 yuv数据,所以经常会使用到视频格式的转换。 除了使用 ffmpeg进行转换,还可以通过 libyuv 和 directX 写 shader 进行转换。 之前看到文章说 libyuv 之前是 ffmpeg…...
 git-repo https证书认证问题)
git-repo系列教程(3) git-repo https证书认证问题
文章目录 问题描述解决步骤1.下载证书2.测试证书是否正常3.设置环境变量 总结 问题描述 在使用git repo 同步仓库时,发现不能同步,出现如下提示错误: % Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left …...

中序遍历二叉树全过程图解
文章目录 中序遍历图解总结拓展:回归与回溯 中序遍历图解 首先看下中序遍历的代码,其接受一个根结点root作为参数,判断根节点是否为nil,不为nil则先递归遍历左子树。 func traversal(root *TreeNode,res *[]int) {if root nil …...
设计模式 组合模式(Composite Pattern)
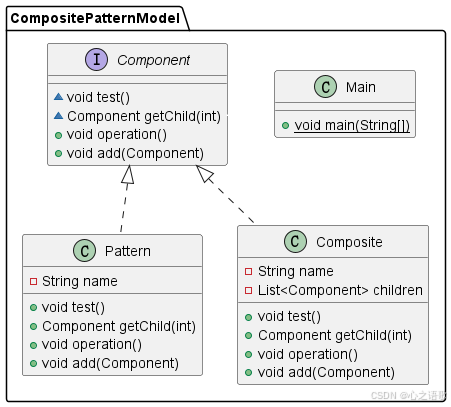
组合模式简绍 组合模式(Composite Pattern)是一种结构型设计模式,它允许你将对象组合成树形结构来表示“部分-整体”的层次结构。组合模式使得客户端可以用一致的方式处理单个对象和组合对象。这样,可以在不知道对象具体类型的条…...

在vue中嵌入vitepress,基于markdown文件生成静态网页从而嵌入社团周报系统的一些想法和思路
什么是vitepress vitepress是一种将markdown文件渲染成静态网页的技术 其使用仅需几行命令即可 //在根目录安装vitepress npm add -D vitepress //初始化vitepress,添加相关配置文件,选择主题,描述,框架等 npx vitepress init //…...
神经网络面试题目
1. 批规范化(Batch Normalization)的好处都有啥?、 A. 让每一层的输入的范围都大致固定 B. 它将权重的归一化平均值和标准差 C. 它是一种非常有效的反向传播(BP)方法 D. 这些均不是 正确答案是:A 解析: batch normalization 就…...

C语言题目之单身狗2
文章目录 一、题目二、思路三、代码实现 提示:以下是本篇文章正文内容,下面案例可供参考 一、题目 二、思路 第一步 在c语言题目之打印单身狗我们已经讲解了在一组数据中出现一个单身狗的情况,而本道题是出现两个单身狗的情况。根据一个数…...
)
告别昂贵下载器!用20块的CH347芯片在Vivado里玩转FPGA调试(保姆级XVC配置)
20元打造专业级FPGA调试环境:CH347芯片Vivado全攻略 在电子设计领域,FPGA开发一直被视为硬件工程师的"高端玩具",但配套调试工具的高昂价格往往让个人开发者和学生望而却步。一块正版Xilinx下载器动辄数千元的价格,足以…...

戴尔G15笔记本散热优化:开源温度控制中心TCC-G15完全指南
戴尔G15笔记本散热优化:开源温度控制中心TCC-G15完全指南 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 对于戴尔G15系列笔记本用户而言ÿ…...

Nodejs后端服务接入Taotoken实现AI对话功能的具体步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 后端服务接入 Taotoken 实现 AI 对话功能的具体步骤 1. 准备工作:获取 API 密钥与模型 ID 在开始编写代码之前…...

Unity原生依赖管理:EDM4U原理、避坑与CI/CD工程化实践
1. 为什么Unity项目越来越离不开EDM4U:从“手动拖拽”到“依赖即代码”的真实痛感我第一次在2019年接手一个中型AR项目时,团队还在用最原始的方式管理第三方库:把.dll、.asmdef、Plugins/Android目录下的.aar文件,甚至Unity Packa…...

【ChatGPT】基于李群、李代数与螺旋理论的 Tricept 并联加工机器人控制系统软硬件架构深度拆解、信息图10张、爆炸图10张、C++代码框架
希望还能够有机会去研究他们(前提是能够遇到好领导)深度拆解...

Win11Debloat:Windows 11系统优化终极指南,免费提升电脑性能50%
Win11Debloat:Windows 11系统优化终极指南,免费提升电脑性能50% 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes…...

OpCore-Simplify技术解构:自动化OpenCore EFI配置引擎的架构剖析
OpCore-Simplify技术解构:自动化OpenCore EFI配置引擎的架构剖析 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 在开源系统定制领域&…...

平面四杆机构运动学分析与尺寸优化设计——基于MATLAB的完整实现
平面四杆机构运动学分析与尺寸优化设计——基于MATLAB的完整实现 摘要: 平面四杆机构是机械工程中最基础、应用最广泛的机构之一,其运动学特性直接影响整个机械系统的性能。本文以曲柄摇杆机构为研究对象,系统阐述基于闭环矢量法的运动学建模方法,通过MATLAB实现机构的位移…...

Android FLAG_SECURE限制突破:如何让所有应用都能自由截屏?
Android FLAG_SECURE限制突破:如何让所有应用都能自由截屏? 【免费下载链接】DisableFlagSecure 项目地址: https://gitcode.com/gh_mirrors/dis/DisableFlagSecure 在Android应用开发中,FLAG_SECURE标志常常让用户感到困扰——当你需…...

Diablo Edit2完全指南:掌握暗黑破坏神2存档编辑的艺术
Diablo Edit2完全指南:掌握暗黑破坏神2存档编辑的艺术 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾经在暗黑破坏神2中因为技能点分配失误而懊恼?是否因为刷不到…...