【第十一章:Sentosa_DSML社区版-机器学习之分类】
目录
11.1 逻辑回归分类
11.2 决策树分类
11.3 梯度提升决策树分类
11.4 XGBoost分类
11.5 随机森林分类
11.6 朴素贝叶斯分类
11.7 支持向量机分类
11.8 多层感知机分类
11.9 LightGBM分类
11.10 因子分解机分类
11.11 AdaBoost分类
11.12 KNN分类
【第十一章:Sentosa_DSML社区版-机器学习之分类】
11.1 逻辑回归分类
1.算子介绍
逻辑回归虽然叫做回归,但属于分类算法中的二分类,又称logistic回归分析,是一种广义的线性回归分析模型,逻辑回归是在线性回归的基础上,通过sigmod函数映射,将数据由回归转为分类。
2.算子类型
机器学习/分类算子
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| reg_param | 正则化参数 | 必填 | Double | 默认(0.0) | >=0 | 正则化系数 |
| fit_intercept | 是否拟合截距 | 必填 | Boolean | 是 | 单选:是,否 | 是否拟合截距 |
| standardization | 是否对数据归一化 | 必填 | Boolean | 是 | 单选:是,否 | 是否对数据归一化 |
| elastic_net | 弹性网络混合参数 | 必填 | Double | 默认0.0 | [0,1] | 弹性网络则是同时使用了L1和L2作为正则化项,参数中elastic_net为L1范数惩罚项所占比例。若=0时,弹性网络只剩L2范数的惩罚项。若等于1弹性网络退化为L1范数的惩罚项参数值越大对参数惩罚越大,越不容易过拟合 |
| max_iteration | 最大迭代次数 | 必填 | Int | 默认(100) | >0 | 最大迭代次数 |
| tolerance | 收敛偏差 | 必填 | Double | 默认(1E-6) | >= 0 | 收敛偏差 |
| family | 回归类别 | 必填 | String | 默认(auto) | 单选:auto,binomial,multinomial | 选择逻辑回归的类型auto:根据分类类别个数自动决定,若类别数为1个或者2个则为二元逻辑回归,否则为多元逻辑回归binomial:二元逻辑回归multinomial:多元逻辑回归 |
| aggregation_depth | 聚合树的深度 | 必填 | Integer | 2 | >=2 | 聚合树的深度 |
| Wight | 权重列设置 | 非必填 | String | 无 | 无 | 在建模时,有时不同的样本可能有不同的权重。我们需要支持用户在建模时指定权重列。 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
逻辑回归分类算子属性设置如图所示。

逻辑回归分类算子属性设置
其中弹性网格混合参数是同时使用L1和L2作为正则化项时, L1范数惩罚项所占比例,具体参照算子属性表格。正则化参数是损失函数中整个正则化项的参数。当运行到达最大迭代次数或收敛偏差小于设定的收敛偏差时停止迭代。聚合树深度为spark优化算法的参数,默认为2,当特征维度过大或数据分区过大时,建议调为更大的值。
(3)算子的运行
逻辑回归分类为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接逻辑回归算子,右击算子,点击运行,得到逻辑回归分类模型。

运行逻辑回归分类算子获得逻辑回归分类模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

逻辑回归分类模型算子流
右击模型可以查看模型的模型信息

模型信息
模型的运行结果如图所示

逻辑回归分类模型运行结果
模型的评估结果如图所示

逻辑回归分类模型评估结果
11.2 决策树分类
1.算子介绍
决策树分类是一种简单易用的非参数分类器模型,它会在用户选定的特征列上不断进行分裂,使得在每一分支对目标变量纯度逐渐增高。直至到达分支目标变量一致,或者满足用户设置的终止条件。
2.算子类型
机器学习/分类算子
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| max_depth | 树的最大深度 | 必填 | Int | 默认5 | >=0且<=30 | 树的最大深度 |
| max_bins | 连续型属性划分最大分桶数 | 必填 | Int | 默认32 | >=2 | 连续型属性划分最大分桶数 |
| min_instances_per_node | 最小实例数 | 必填 | Int | 默认1 | >=1 | 最小实例数 |
| min_infoGain | 最小信息增益 | 必填 | Double | 默认0.0 | >=0.0 | 在树节点上考虑分割的最小信息增益 |
| impurity | 信息纯度计算方式 | 必填 | String | 默认(gini) | 单选:基尼,熵 | 用于信息增益计算的判据(不区分大小写)。支持:“熵”和“基尼”。GBT的算法是忽略该设置的 |
| Wight | 权重列设置 | 非必填 | String | 无 | 无 | 在建模时,有时不同的样本可能有不同的权重。我们需要支持用户在建模时指定权重列。 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
决策树分类算子属性设置如图所示

决策树分类算子属性设置
前端可配置属性如图所示,树的最大深度,连续型属性划分最大分桶数,最小实例数,最小信息增益都是用来控制构建聚合树时的分裂程度。
(3)算子的运行
决策树分类为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接决策树分类算子,右击算子,点击运行,得到决策树分类器模型

运行决策树分类算子获得决策树分类模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

决策树分类模型算子流
右击模型,查看模型的模型信息

决策树分类模型信息
模型的运行结果如图所示

决策树分类模型运行结果
模型的评估结果如图所示

决策树分类模型评估结果
11.3 梯度提升决策树分类
1.算子介绍
梯度提升决策树分类是一个Boosting聚合模型,它是由多个决策树一起组合和来预测。多个决策树之间是顺序组合关系,每一个决策树模型都会修正之前所有模型预测的误差。这样经过多个模型的修正,从而提升了整个聚合模型的预测精度。
2.算子类型
机器学习/分类算子
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| max_depth | 树的最大深度 | 必填 | Int | 默认5 | >=0且<=30 | 树的最大深度 |
| max_bins | 连续型属性划分最大分桶数 | 必填 | Int | 默认32 | >=2 | 连续型属性划分最大分桶数 |
| min_instances_per_node | 最小实例数 | 必填 | Int | 默认1 | >=1 | 最小实例数 |
| min_infoGain | 最小信息增益 | 必填 | Double | 默认0.0 | >=0.0 | 在树节点上考虑分割的最小信息增益 |
| feature_subset_strategy | 树节点拆分的策略 | 必填 | String | 默认(auto) | 单选:auto,all,onethird,sqrt,log2,选择n时,则由用户输入具体>0的数值。 | “auto”:自动选择,如果子树个数为1时,则使用全部特征。如果子树个数> 1时(森林),则设置为sqrt(特征数量);“all”:使用所有特征;“onethird”:使用1/3的特征;“sqrt”:使用sqrt(特征数量);“log2”:使用log2(特征数量);“n”:当n在范围(0,1.0]时,为n*特征数。当n在范围(1,+∞)时,为特征数和n值两个之间的最小值。 |
| subsampling_rate | 子树的训练比例 | 必填 | String | 1.0 | (0,1] | 用于学习每个决策树的训练数据的比例 |
| max_iter | 最大迭代次数 | 必填 | Integer | 100 | >0 | 最大迭代次数 |
| step | 步长 | 必填 | Double | 1.0 | (0.0,1.0] | |
| Wight | 权重列设置 | 非必填 | String | 无 | 无 | 在建模时,有时不同的样本可能有不同的权重。我们需要支持用户在建模时指定权重列。 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
梯度提升决策树分类算子的属性设置如图所示

梯度提升决策树分类属性设置
前端可配置属性如图所示,树的最大深度,最大容器数,最小实例数,最小信息增益都是用来控制构建梯度提升决策树时的分裂程度。子树的训练比例指,在学习每个决策树时所用训练数据的比例。子树的训练比例和步长都是为了防止过拟合。树节点拆分策略为树的每个节点拆分时要考虑的特征数,各选项的具体意义见算子的属性说明表格。
(3)算子的运行
梯度提升决策树分类为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接梯度提升决策树分类器算子,右击算子,点击运行,得到梯度提升决策树分类模型。

运行梯度提升决策树分类算子获得梯度提升决策树分类模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

梯度提升决策树分类模型算子流
右击模型,查看模型的模型信息,如图所示。

梯度提升决策树分类模型信息
模型的运行结果如图所示

梯度提升决策树分类模型运行结果
模型的评估结果如图所示

梯度提升决策树分类模型评估结果
11.4 XGBoost分类
1.算子介绍
XGBoost是Extreme Gradient Boosting的缩写,它是一个优化的分布式梯度增强库,具有高效、灵活和可移植性。在梯度增强框架下实现了机器学习算法。XGBoost提供了一种并行树增强(也称为GBDT、GBM),可以快速、准确地解决许多数据科学问题。并且在分布式运行环境下进行了优化,可以解决数十亿规模的样本训练问题。
2.算子类型
机器学习/分类算子
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| num_round | 迭代次数 | 必填 | Int | 100 | [1, Int. MaxValue] | 算法的迭代次数(树的数量) |
| eta | 学习率 | 必填 | Double | 0.3 | [0.0,1.0] | 更新中减少的步长来防止过拟合。 |
| gamma | 最小分裂损失 | 必填 | Double | 0 | [0, Double.MaxValue] | 在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关,所以是需要调整的。 |
| max_depth | 树的最大深度 | 必填 | Int | 6 | [1, Int.MaxValue] | 这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。 |
| min_child_weight | 最小叶子节点样本权重和 | 必填 | Double | 1 | [0, Double.MaxValue] | 这个参数用于避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。 但是如果这个值过高,会导致欠拟合。这个参数需要使用CV来调整。 |
| subsample | 子采样率 | 必填 | Double | 1 | (0,1] | 将其设置为0.5意味着XGBoost随机收集了一半的数据实例以生成树,这将防止过度拟合,子采样将在每次boosting迭代中发生一次。 |
| colsample_bytree | 每棵树随机采样的列数占比 | 必填 | Double | 0.8 | (0,1] | 用来控制每棵随机采样的列数的占比(每一列是一个特征)。 我们一般设置成0.8左右, 典型值:0.5-1范围: (0,1] |
| tree_method | 树构造算法 | 必填 | String | "auto" | 可选择"auto",“hist”,“approx” | auto:使用启发式方法选择最快的方法, hist: 更快的直方图优化的近似贪婪算, approx:使用分位数草图和梯度直方图的近似贪婪算法 |
| grow_policy | 添加节点方式 | 必填 | String | "depthwise" | 仅在tree_method为hist的时候生效,可选择: “depthwise”, “lossguide” | depthwise: 在最靠近根的节点处拆分, lossguide: 在损耗变化最大的节点处拆分 |
| max_bins | 最大箱数 | 必填 | Integer | 256 | 仅在tree_method为hist的时候生效,[1, Int. MaxValue) | 用于存储连续特征的最大不连续回收箱数,增加此数目可提高拆分的最佳性,但需要增加计算时间。 |
| single_precision_histogram | 是否单精度 | 必填 | Boolean | 否 | 单选:是,否 | 仅在tree_method设置为hist时使用 false:双精度 true: 单精度 |
| scale_pos_weight | 正负样本不均衡调节权重 | 必填 | Double | 1 | >0 | 在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负样本的数目与正样本数目的比值. |
| lambda | L2正则化项 | 必填 | Double | 1 | >= 0 | 关于权重的L2正则化项。增加此值将使模型更加保守。 |
| alpha | L1正则化项 | 必填 | Double | 0 | >=0 | 关于权重的L1正则化项。增加此值将使模型更加保守。 |
| eval_metric | 评估指标 | 必填 | String | 根据优化目标默认 | 可选择[“logloss”,“error”] | logloss:对数损失; error:分类错误率 |
| base_score | 初始预测分数 | 必填 | Double | 0.5 | >0 | 所有实例的初始预测分数,全局偏差. 在迭代次数少的情况下,可加快收敛速度,对于足够数量的迭代,更改此值不会产生太大影响 |
| num_round | 迭代次数 | 必填 | Int | 100 | [1, Int. MaxValue] | 算法的迭代次数(树的数量) |
| Wight | 权重列设置 | 非必填 | String | 无 | 无 | 在建模时,有时不同的样本可能有不同的权重。我们需要支持用户在建模时指定权重列。 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
XGBoost分类的属性设置如图所示


XGBoost分类属性设置
前端可配置属性如图所示,评估指标即算法的损失函数,有对数损失和分类错误率两种;学习率,树的最大深度,最小叶子节点样本权重和,子采样率,最小分裂损失,每棵树随机采样的列数占比,L1正则化项和L2正则化项都是用来防止算法过拟合。当子节点样本权重和不大于所设的最小叶子节点样本权重和时不对该节点进行进一步划分。最小分裂损失指定了节点分裂所需的最小损失函数下降值。添加节点方式、最大箱数、是否单精度,这三个参数是当树构造方法是为hist的时候,才生效。参数的具体意义参考算子属性说明表格。
(3)算子的运行
XGBoost分类为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接XGBoost分类算子,右击算子,点击运行,得到XGBoost分类模型。

运行XGBoost分类算子获得XGBoost分类模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

XGBoost分类模型算子流
右击模型,查看模型的模型信息

XGBoost分类模型信息
模型的运行结果如图所示

XGBoost分类模型运行结果
模型的评估结果如图所示

XGBoost分类模型评估结果
11.5 随机森林分类
1.算子介绍
随机森林是一种常用的分类和回归方法。它是一种Bagging的模型聚合方法。它内部集成了大量的决策树模型。每个模型都会选取一部分特征和一部分训练样本。最终由多个决策树模型来共同决定预测值。随机森林算法可以充分利用集群的性能,提高最终聚合模型的精度,并且大大改善模型的过拟合问题。
2.算子类型
机器学习/分类算子
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| max_depth | 树的最大深度 | 必填 | Int | 5 | >=0且<=30 | 树的最大深度:深度0表示1叶节点; 深度1表示1个内部节点+ 2个叶节点 |
| max_bins | 连续型属性划分最大分桶数连续型属性划分最大分桶数 | 必填 | Int | 32 | >=2 | 用于离散连续特性和选择如何在每个节点上分割特性的最大容器数 |
| min_instances_per_node | 最小实例数 | 必填 | Int | 1 | >=1 | 每个子节点在分割后必须拥有的最小实例数, |
| min_infoGain | 最小信息增益 | 必填 | double | 0.0 | >=0.0 | 在树节点上考虑分割的最小信息增益 |
| feature_subset_strategy | 树节点拆分的策略 | 必填 | String | auto | 单选:auto,all,onethird,sqrt,log2,选择n时,则由用户输入具体>0的数值。 | “auto”:自动选择,如果子树个数为1时,则使用全部特征。如果子树个数> 1时(森林),则设置为sqrt(特征数量);“all”:使用所有特征;“onethird”:使用1/3的特征;“sqrt”:使用sqrt(特征数量);“log2”:使用log2(特征数量);“n”:当n在范围(0,1.0]时,为n*特征数。当n在范围(1,+∞)时,为特征数和n值两个之间的最小值。 |
| num_trees | 树的数量 | 必填 | Int | 20 | >=1 | 要训练的树数 |
| subsampling_rate | 子树的训练比例 | 必填 | Double | 1.0 | (0,1] | 用于学习每个决策树的训练数据的一部分,范围。(默认= 1.0) |
| Wight | 权重列 | 非必填 | String | 无 | 无 | 在建模时,有时不同的样本可能有不同的权重。我们需要支持用户在建模时指定权重列。 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作。
(2)算子属性设置
随机森林分类的属性设置如图所示

随机森林分类属性设置
前端可配置属性如图所示,树的最大深度,最大容器数,最小实例数,最小信息增益都是用来控制构建随机森林时树的分裂程度。子树的训练比例指,在学习每个决策树时所用训练数据的比例。树节点拆分策略为树的每个节点拆分时要考虑的特征数,各选项的具体意义见算子的属性说明表格。
(3)算子的运行
随机森林分类为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接随机森林分类算子,右击算子,点击运行,得到随机森林分类模型。

运行随机森林分类算子获得随机森林分类模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

随机森林分类模型算子流
右击模型,查看模型的模型信息

随机森林分类模型信息
模型的运行结果如图所示

随机森林分类器型运行结果
模型的评估结果如图所示

随机森林分类器型评估结果
11.6 朴素贝叶斯分类
1.算子介绍
朴素贝叶斯是一组基于贝叶斯定理的简单概率多类分类器,每对特征之间具有强(朴素)独立性假设。朴素贝叶斯通过计算了给定每个标签的每个特征的条件概率分布来建立模型。朴素贝叶斯模型通过应用贝叶斯定理计算给定观测值的每个标签的条件概率分布来进行预测。
2.算子类型
机器学习/分类算子
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| smoothing | 平滑参数 | 必填 | Double | 1.0 | >=0 | 平滑参数默认值为1.0 |
| Wight | 权重列设置 | 非必填 | String | 无 | 无 | 在建模时,有时不同的样本可能有不同的权重。我们需要支持用户在建模时指定权重列。 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
朴素贝叶斯的属性设置如图所示

朴素贝叶斯分类属性设置
(3)算子的运行
朴素贝叶斯为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接朴素贝叶斯器算子,右击算子,点击运行,得到朴素贝叶斯模型。

运行朴素贝叶斯算子获得朴素贝叶斯模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

朴素贝叶斯模型算子流
右击模型,查看模型的模型信息

朴素贝叶斯模型信息
模型的运行结果如图所示

朴素贝叶斯模型运行结果
模型的评估结果如图所示

朴素贝叶斯模型评估结果
11.7 支持向量机分类
1.算子介绍
支持向量机是一个功能强大且能有效防止过拟合的机器学习算法。它通过在高维空间中构造超平面或者超平面集合。通过对核函数的选择,支持向量机不仅可以进行线性划分,还可以支持非线性划分。
2.算子类型
机器学习/分类算子。
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| kernel_type | 核函数类型 | 必选 | String | linear | 单选:"linear", "rbf", "polynomial", "sigmoid" | 核函数类型 |
| ratio | 抽样比例 | 必选 | Double | 0.1 | >0 且<=1 | 抽样比例 |
| group_num | 子模型个数 | 必选 | Integer | 10 | >=1 | 子模型个数 |
| c | 惩罚因子 | 必选 | Double | 1.0 | >0 | 惩罚因子 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作。
(2)算子属性设置
当选择线性核函数时,支持向量机的属性设置如图所示

线性核函数支持向量机属性设置
核函数将原始特征空间映射为更高维的空间,在原始空间中不可分的数据在高维空间中可能变成线性可分。容忍度因子C即惩罚因子,C越大,容易出现过拟合;C越小,容易出现欠拟合。提前退出次数为:训练结束前有多少次迭代的数据未发生变化,则训练提前停止。
(3)算子的运行
支持向量机为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接支持向量机算子,右击算子,点击运行,得到支持向量机模型。

运行支持向量机算子获得支持向量机模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

支持向量机模型算子流
右击模型,查看模型的模型信息

支持向量机模型信息
模型的运行结果如图所示

支持向量机模型运行结果
模型的评估结果如图所示

支持向量机模型评估结果
11.8 多层感知机分类
1.算子介绍
多层感知是一种前馈人工神经网络模型,其将输入的多个数据集映射到单一的输出的数据集上,多层感知机层与层之间是全连接的,最底层是输入层,中间是隐藏层,最后是输出层。
2.算子类型
机器学习/分类算子
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| layers | 隐藏层数设置(逗号分隔的整数) | 必填 | List<String> | 逗号分隔的整型 | 从输入层到输出层的层数。用逗号分隔的整数,例如780,100,10表示780个输入,100个神经元的隐藏层和10个神经元的输出层 | |
| solver | 优化算法 | 必选 | String | l-bfgs | 单选:l-bfgs gd | 优化算法。支持选项:“l-bfgs”/“gd”默认l-bfgs |
| max_iteration | 最大迭代次数 | 必填 | Int | 100 | >0 | 最大迭代次数 |
| tolerance | 收敛偏差 | 必填 | Double | 1E-6 | >= 0 | 收敛偏差 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作。
(2)算子属性设置
当优化算法为拟牛顿法时,多层感知机的属性设置如图所示

多层感知机分类算子属性设置
算子将非数值型Feature转换为数值型,且自动计算输入层神经元个数和输出层神经元个数,用户只需设置隐藏层神经元个数,各隐藏层之间用逗号分隔。
(3)算子的运行
多层感知机为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接多层感知机算子,右击算子,点击运行,得到多层感知机模型。

运行多层感知机获得多层感知机模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

多层感知机模型算子流
右击模型,查看模型的模型信息

多层感知机模型信息
模型的运行结果如图所示

多层感知机模型运行结果
模型的评估结果如图所示

图4.5.1.8-6 多层感知机模型评估结果
11.9 LightGBM分类
1.算子介绍
LightGBM属于Boosting集合模型中的一种,它和XGBoost一样是对GBDT的高效实现。LightGBM在很多方面会比XGBoost表现更为优秀。它有以下优势:更快的训练效率、低内存使用、更高的准确率、支持并行化学习、可处理大规模数据。
2.算子类型
机器学习/分类算子
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| objective | 学习目标 | 必填 | String | multiclass | binary,multiclass,multiclassova | 二分类、多分类、one-vs-all二分类 |
| boosting_tye | 基学习器 | 必填 | String | gbdt | gbdt,rf,dart,goss | gbdt:梯度提升数,rf:随机森林,dart:dropout+mart,goss:单边梯度重采样 |
| num_iterations | 迭代次数 | 必填 | Integer | 100 | [1, Int.MaxValue] | 迭代次数 |
| learning_rate | 学习率 | 必填 | Double | 0.1 | (0,1] | 学习率 |
| max_depth | 最大深度 | 必填 | Integer | -1 | [Int.MinValue, Int.MaxValue] | 树模型最大深度的限制,当数据量较小时,用来处理过拟合,树仍然通过leaf-wise生长,<=0意味着没有限制 |
| num_leaves | 叶子数量 | 必填 | Integer | 31 | [2, Int.MaxValue] | 叶子数量 |
| min_sum_hessian_in_leaf | 最小叶子节点Hessian和 | 必填 | Double | 1e-3 | [0, Int.MaxValue] | 可以防止过拟合 |
| bagging_fraction | Bagging比例 | 必填 | Double | 1.0 | (0,1] | 可以在不进行重采样的情况下随机选择部分数据来加速训练,为了启用bagging。rf时这个参数需要小于1,且bagging_freq > 0。 |
| bagging_freq | Bagging频率 | 必填 | Integer | 0 | [0, Int.MaxValue] | 0意味着关闭bagging, k意味着k次迭代进行一次bagging,此外如果要用bagging,bagging_fraction必须同时小于1.0。 |
| bagging_seed | Bagging种子 | 必填 | Integer | 3 | >0 | Bagging种子。 |
| lambda_l2 | L2正则 | 必填 | Double | 0 | >= 0 | 关于权重的L2正则化项。增加此值将使模型更加保守。 |
| lambda_l1 | L1正则 | 必填 | Double | 0 | >=0 | 关于权重的L1正则化项。增加此值将使模型更加保守。 |
| feature_fraction | 特征采样比例 | 必填 | Double | 1.0 | (0.0,1.0] | 如果该参数小于1.0, 在每个迭代,lightgbm会随机选择部分特征进行训练,加速训练,防止过拟合 |
| early_stopping_round | 提前终止迭代 | 必填 | Integer | 0 | >=0 | 如果一个验证集的metric在过去的 early_stopping_round轮次中没有提升则终止训练,<=0意味着关闭 |
| max_bin | 最大箱数 | 必填 | Integer | 255 | (0,infinite) | 较少的箱数可能会降低精度,但是会避免过拟合 |
| generate_missing_lebels | 补齐缺失标签 | 必填 | Boolean | 否 | 单选:是,否 | 补齐缺失标签 |
| is_provide_training_metric | 输出训练metric结果 | 必填 | Boolean | 否 | 单选:是,否 | 训练时提供metric结果 |
| Wight | 权重列设置 | 非必填 | String | 无 | 无 | 在建模时,有时不同的样本可能有不同的权重。我们需要支持用户在建模时指定权重列。 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
LightGBM分类的属性设置如图所示




LightGBM分类属性设置
(3)算子的运行
LightGBM分类为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接LightGBM分类算子,右击算子,点击运行,得到LightGBM分类模型。

运行LightGBM分类算子获得LightGBM分类模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

LightGBM分类模型算子流
右击模型,查看模型的模型信息

LightGBM分类模型信息
模型的运行结果如图所示

LightGBM分类模型运行结果
模型的评估结果如图所示

LightGBM分类模型评估结果
11.10 因子分解机分类
1.算子介绍
因子分解机是一种基于矩阵分解的机器学习算法,可以解决特征组合以及高维稀疏矩阵问题的强大的机器学习算法,首先是特征组合,通过对两两特征组合,引入交叉项特征,提高模型得分;其次是高维灾难,通过引入隐向量(对参数矩阵进行矩阵分解),完成对特征的参数估计。目前FM算法是推荐领域被验证的效果较好的推荐方案之一。
2.算子类型
机器学习/分类算子。
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| solver | 优化求解算法 | 必选 | String | adamW | 单选:adamW,gd | 优化求解算法 |
| bias | 是否拟合截距 | 必选 | Boolean | 是 | 单选:是,否 | 是否拟合截距,即0次项 |
| one_way_interaction | 是否拟合一次项 | 必选 | Boolean | 是 | 单选:是,否 | 是否拟合一次项 |
| dimension | 设置因子维度 | 必选 | Int | 8 | >0 | 因子维度 |
| reg_params | L2正则化参数 | 必选 | Double | 0.01 | >0 | L2正则化系数 |
| max_itert | 最大迭代次数 | 必选 | Int | 100 | >0 | 最大迭代次数 |
| init_stdev | 设置初始系数的标准差 | 必选 | Double | 0.05 | >0.0 | 设置初始系数的标准差 |
| step_size | 学习率 | 必选 | Double | 0.01 | >0.0 | 学习率 |
| tolerance_conver_iter | 迭代的收敛误差 | 必选 | Double | 1E-6 | >0.0 | 迭代的收敛误差 |
| Wight | 权重列设置 | 非必填 | String | 无 | 无 | 在建模时,有时不同的样本可能有不同的权重。我们需要支持用户在建模时指定权重列。 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
当优化求解算法选择adamW时,因子分解机分类算子的属性设置如图所示

优化求解算法选择adamW时因子分解机属性设置
adamW(Adam Weight Decay Regularization):Adam可以看作是RMSprob和动量SGD的结合,目的在于抑制震荡加速收敛。 Adamw则是在Adam的更新策略中采用了计算整体损失函数的梯度来进行更新而不是只计算不带正则项部分的梯度进行更新之后再进行权重衰减。
当优化求解算法选择gd时,因子分解机的属性设置如图所示

优化求解算法选择GD时因子分解机属性设置
GD (Gradient Descent): 最为经典的凸优化优化器,通过loss反向传导计算参数的梯度,沿着负梯度的方向更新参数。
(3)算子的运行
因子分解机分类为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。为了训练得到更好的模型,训练数据需要使用标准化算子或者归一化算子进行处理。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接因子分解机分类算子,右击算子,点击运行,得到因子分解机分类模型。

运行因子分解机分类算子获得模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

因子分解机模型算子流
右击模型,查看模型的模型信息

因子分解机模型信息
模型的运行结果如图所示

因子分解机模型运行结果
模型的评估结果如图所示

因子分解机模型评估结果
11.11 AdaBoost分类
1.算子介绍
AdaBoost是一种Boosting集成方法,主要思想就是将弱的基学习器提升(boost)为强学习器,根据上轮迭代得到的学习器对训练集的预测表现情况调整训练集中的样本权重, 然后据此训练一个新的基学习器,最终的集成结果是多个基学习器的组合。
2.算子类型
机器学习/分类算子。
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| max_depth | 树的最大深度 | 必填 | Int | 5 | >=0且<=30 | 树的最大深度 |
| max_bins | 连续型属性划分最大分桶数 | 必填 | Int | 32 | >=2 | 连续型属性划分最大分桶数 |
| min_instances_per_node | 最小实例数 | 必填 | Int | 1 | >=1 | 最小实例数 |
| min_infoGain | 最小信息增益 | 必填 | Double | 0.0 | >=0.0 | 在树节点上考虑分割的最小信息增益 |
| feature_subset_strategy | 树节点拆分的策略 | 必填 | String | auto | 单选:auto,all,onethird,sqrt,log2,选择n时,则由用户输入具体>0的数值。 | “auto”:自动选择,如果子树个数为1时,则使用全部特征。如果子树个数> 1时(森林),则设置为sqrt(特征数量);“all”:使用所有特征; “onethird”:使用1/3的特征;“sqrt”:使用sqrt(特征数量);“log2”:使用log2(特征数量); “n”:当n在范围(0,1.0]时,为n*特征数。当n在范围(1,+∞)时,为特征数和n值两个之间的最小值 |
| subsampling_rate | 子树的训练比例 | 必填 | Double | 1.0 | (0,1] | 用于学习每个决策树的训练数据的比例 |
| max_iter | 迭代次数 | 必填 | Int | 10 | >0 | 迭代次数,决定Adaboost子树的数量 |
| Wight | 权重列设置 | 非必填 | String | 无 | 无 | 在建模时,有时不同的样本可能有不同的权重。我们需要支持用户在建模时指定权重列。 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
(1)算子初始化
参考公共功能算子初始化操作。
(2)算子属性设置
AdaBoost分类算子的属性设置如图所示

AdaBoost分类属性设置
前端可配置属性如图所示,树的最大深度,连续型属性划分最大分桶数,最小实例数,最小信息增益都是用来控制构建子决策树时的分裂程度。子树的训练比例指,在学习每个决策树时所用训练数据的比例。子树的训练比例都是为了防止过拟合。树节点拆分策略为树的每个节点拆分时要考虑的特征数,各选项的具体意义见算子的属性说明表格。
(3)算子的运行
AdaBoost分类为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接AdaBoost分类算子,右击算子,点击运行,得到AdaBoost分类模型。

运行AdaBoost分类算子获得AdaBoost分类模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

AdaBoost分类模型算子流
右击模型,查看模型的模型信息

AdaBoost分类模型信息
模型的运行结果如图所示

AdaBoost分类模型运行结果
模型的评估结果如图所示

AdaBoost分类模型评估结果
11.12 KNN分类
1.算子介绍
K-近邻算法是一种惰性学习模型(lazy learning),也称为基于实例学习模型,这与勤奋学习模型(eager learning)不一样。
勤奋学习模型在训练模型的时候会很耗资源,它会根据训练数据生成一个模型,在预测阶段直接带入数据就可以生成预测的数据,所以在预测阶段几乎不消耗资源。
惰性学习模型在训练模型的时候不会估计由模型生成的参数,他可以即刻预测,但是会消耗较多资源,例如KNN模型,要预测一个实例,需要求出与所有实例之间的距离。
K-近邻算法是一种非参数模型,参数模型使用固定的数量的参数或者系数去定义模型,非参数模型并不意味着不需要参数,而是参数的数量不确定,它可能会随着训练实例数量的增加而增加,当数据量大的时候,看不出解释变量和响应变量之间的关系的时候,使用非参数模型就会有很大的优势,而如果数据量少,可以观察到两者之间的关系的,使用相应的模型就会有很大的优势。
存在一个样本集,也就是训练集,每一个数据都有标签,也就是我们知道样本中每个数据与所属分类的关系,输入没有标签的新数据后,新数据的每个特征会和样本集中的所有数据对应的特征进行比较,算出新数据与样本集其他数据的欧几里得距离,这里需要给出K值,这里会选择与新数据距离最近的K个数据,其中出现次数最多的分类就是新数据的分类,一般k不会大于20。
KNN在做回归和分类的主要区别,在于最后做预测时候的决策不同。在分类预测时,一般采用多数表决法。在做回归预测时,一般使用平均值法。
多数表决法:分类时,哪些样本离我的目标样本比较近,即目标样本离哪个分类的样本更接近。
平均值法: 预测一个样本的平均身高,观察目标样本周围的其他样本的平均身高,我们认为平均身高是目标样本的身高。
2.算子类型
机器学习/分类算子
3.算子属性说明
| 属性 | 页面显示名称 | 选项 | 类型 | 默认值 | 约束规则 | 属性说明 |
| k | K值 | 必填 | Int | 5 | >=2 | K近邻的K值 |
| Wight | 权重列设置 | 非必填 | String | 无 | 无 | 在建模时,有时不同的样本可能有不同的权重。我们需要支持用户在建模时指定权重列。 |
| feature_weight | 是否计算特征重要性 | 必填 | Boolean | 是 | 单选:是,否 | 是否计算特征重要性 |
| show_confusion_matrix | 是否显示训练数据混淆矩阵 | 必填 | Boolean | 是 | 单选:是,否 | 是否显示训练数据混淆矩阵 |
| skip_null_value | 是否跳过空值 | 必填 | Boolean | 是 | 单选:是,否 | 是否跳过空值 |
4.算子使用介绍
(1)算子初始化
参考公共功能算子初始化操作
(2)算子属性设置
KNN分类算子属性设置如图所示

KNN分类算子属性设置
(3)算子的运行
KNN分类为建模算子,需要先训练数据生成模型,再通过模型对相同结构的数据进行处理得到最终结果。具体运行过程如下所述。
首先通过数据读入算子读取数据,中间可以接任意个数据处理算子(例,行处理,列处理等);然后接类型算子,设置Feature列和Label列,再接KNN算子,右击算子,点击运行,得到KNN分类模型。

运行KNN分类算子获得KNN分类模型
模型后可接任意个数据处理算子,再接图表分析算子或数据写出算子,形成算子流执行。模型后也可接评估算子,对模型的分类结果进行评估。

KNN分类模型算子流
右击模型可以查看模型的模型信息

模型信息
模型的运行结果如图所示

KNN分类模型运行结果
模型的评估结果如图所示

KNN分类模型评估结果
为了非商业用途的科研学者、研究人员及开发者提供学习、交流及实践机器学习技术,推出了一款轻量化且完全免费的Sentosa_DSML社区版。以轻量化一键安装、平台免费使用、视频教学和社区论坛服务为主要特点,能够与其他数据科学家和机器学习爱好者交流心得,分享经验和解决问题。文章最后附上官网链接,感兴趣工具的可以直接下载使用
Sentosa_DSML社区版https://sentosa.znv.com/https://sentosa.znv.com/

Sentosa_DSML算子流开发视频
相关文章:
【第十一章:Sentosa_DSML社区版-机器学习之分类】
目录 11.1 逻辑回归分类 11.2 决策树分类 11.3 梯度提升决策树分类 11.4 XGBoost分类 11.5 随机森林分类 11.6 朴素贝叶斯分类 11.7 支持向量机分类 11.8 多层感知机分类 11.9 LightGBM分类 11.10 因子分解机分类 11.11 AdaBoost分类 11.12 KNN分类 【第十一章&…...

kafka3.8的基本操作
Kafka基础理论与常用命令详解(超详细)_kafka常用命令和解释-CSDN博客 [rootk1 bin]# netstat -tunlp|grep 90 tcp6 0 0 :::9092 :::* LISTEN 14512/java [rootk1 bin]# ./kafka-topics.s…...

如何检测并阻止机器人活动
恶意机器人流量逐年增加,占 2023 年所有互联网流量的近三分之一。恶意机器人会访问敏感数据、实施欺诈、窃取专有信息并降低网站性能。新技术使欺诈者能够更快地发动攻击并造成更大的破坏。机器人的无差别和大规模攻击对所有行业各种规模的企业都构成风险。 但您的…...

《linux系统》基础操作
二、综合应用题(共50分) 随着云计算技术、容器化技术和移动技术的不断发展,Unux服务器已经成为全球市场的主导者,因此具备常用服务器的配置与管理能力很有必要。公司因工作需要,需要建立相应部门的目录,搭建samba服务器和FTP服务器,要求将销售部的资料存放在samba服务器…...

EMT-LTR--学习任务间关系的多目标多任务优化
EMT-LTR–学习任务间关系的多目标多任务优化 title: Learning Task Relationships in Evolutionary Multitasking for Multiobjective Continuous Optimization author: Zefeng Chen, Yuren Zhou, Xiaoyu He, and Jun Zhang. journal: IEE…...

MySQL record 08 part
数据库连接池: Java DataBase Connectivity(Java语言连接数据库) 答: 使用连接池能解决此问题, 连接池,自动分配连接对象,并对闲置的连接进行回收。 常用的数据库连接池: 建立数…...
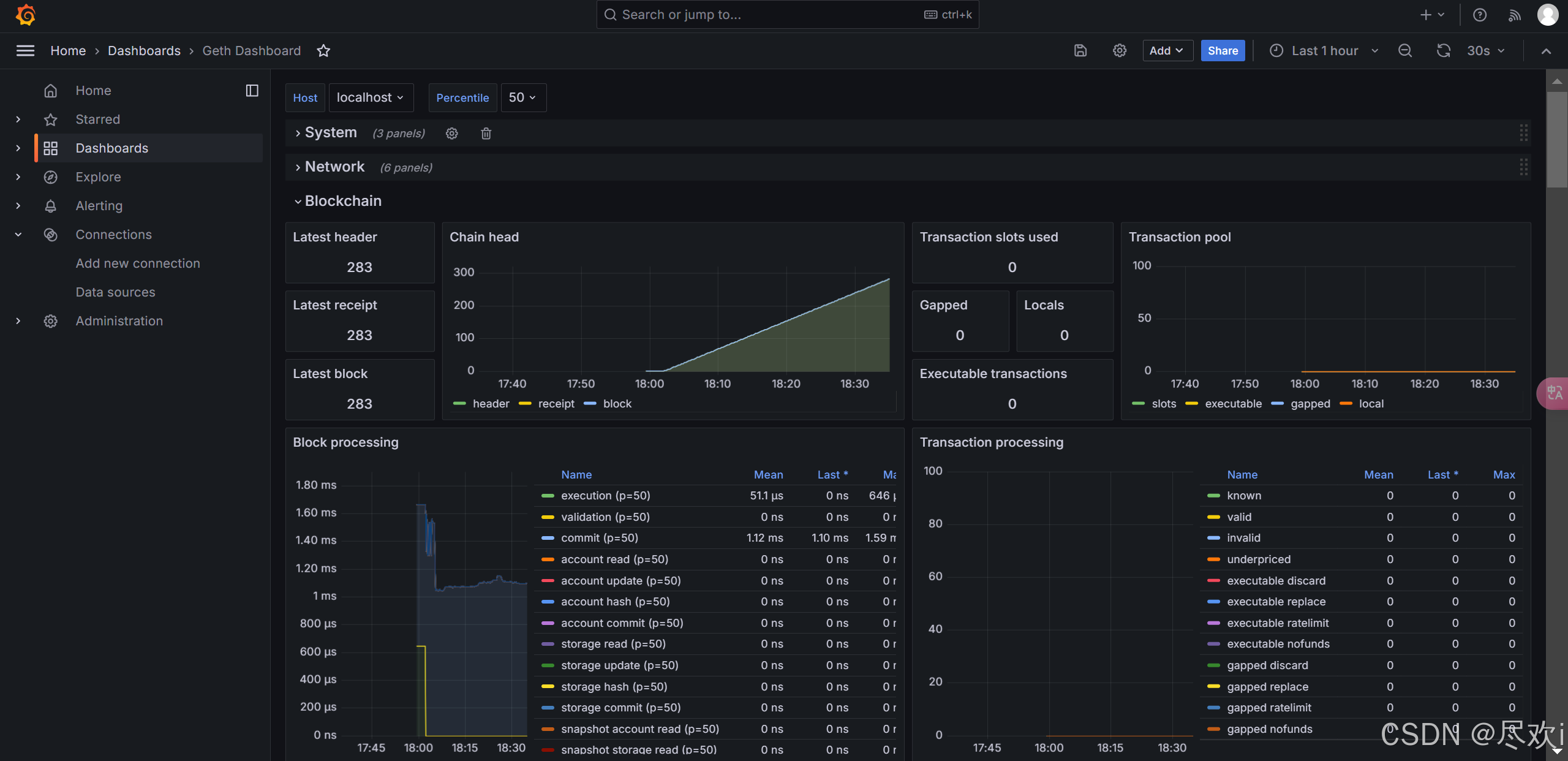
打造以太坊数据监控利器:InfluxDB与Grafana构建Geth可视化分析平台
前言 以太坊客户端收集大量数据,这些数据可以按时间顺序数据库的形式读取。为了简化监控,这些数据可以输入到数据可视化软件中。在此页面上,将配置 Geth 客户端以将数据推送到 InfluxDB 数据库,并使用 Grafana 来可视化数据。 一…...

对onlyoffice进行定制化开发
基于onlyoffice8.0源码,进行二次开发,可实现包括但不限于以下的功能 1、内容控件的插入 2、内容空间的批量替换 3、插入文本 4、插入图片 5、添加,去除水印 6、修改同时在线人数限制 7、内容域的删除 8、页面UI的定制化 9、新增插件开发 10、…...

使用llama.cpp 在推理MiniCPM-1.2B模型
llama.cpp 是一个开源项目,它允许用户在C中实现与LLaMA(Large Language Model Meta AI)模型的交互。LLaMA模型是由Meta Platforms开发的一种大型语言模型,虽然llama.cpp本身并不包含LLaMA模型的训练代码或模型权重,但它…...

分布式环境中,接口超时重试带来的的幂等问题如何解决?
目录标题 幂等不能解决接口超时吗?幂等的重要性什么是幂等?为什么需要幂等?接口超时了,到底如何处理? 如何设计幂等?幂等设计的基本流程实现幂等的8种方案1.selectinsert主键/唯一索引冲突(常用)2.直接insert 主键…...

设计一个推荐系统:使用协同过滤算法
设计一个推荐系统:使用协同过滤算法 在当今数据驱动的时代,推荐系统已经成为了许多在线平台(如电商、社交媒体和流媒体服务)不可或缺的一部分。推荐系统通过分析用户的行为和偏好,向用户推荐可能感兴趣的内容或产品。本文将详细介绍如何设计一个基于协同过滤算法的推荐系…...
Linux 基本指令(二)
目录 1. more指令 2. less指令(重要) 3. head指令 4. tail指令 5. date指令 (1)可以通过选项来指定格式: 编辑 (2)在设定时间方面 (3)时间戳 6. cal指令 7. find指令 8. grep指令 9. alias指令 10. zip指令与unzip指令 (1). zip指令 (2). unzip指令…...

Facebook的用户隐私保护:从争议到革新
Facebook早期的数据收集方式引发了隐私担忧。平台的快速增长和用户数据的大规模收集使得隐私问题逐渐显现。尤其是在2018年,剑桥分析事件暴露了数千万用户数据被不当使用的问题。这一事件揭示了Facebook在数据保护方面的严重漏洞,引发了公众对隐私保护的…...

计算机前沿技术-人工智能算法-大语言模型-最新论文阅读-2024-09-23
计算机前沿技术-人工智能算法-大语言模型-最新论文阅读-2024-09-23 本期,我们对大语言模型在表情推荐, 软件安全和 自动化软件漏洞检测等方面如何应用,提供几篇最新的参考文章。 1 Semantics Preserving Emoji Recommendation with Large Language Mod…...
2024.9.20)
C++(学习)2024.9.20
目录 C面向对象的基础知识 this指针 概念 功能 1.类内调用成员 2.区分重名的成员变量和局部变量 3. 链式调用 static关键字 1.静态局部变量 2.静态成员变量 3.静态成员函数 4.单例设计模式 const关键字 1.const修饰成员函数 2.const修饰对象 3.const修饰成员变量…...

让AI激发创作力:OpenAI分享5位专业作家利用ChatGPT写作的案例技巧
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工…...

UEFI EDK2框架学习 (一)
01 Shell界面打印 执行qemu指令后 qemu-system-x86_64 -drive ifpflash,formatraw,fileOVMF.fd -nographic -net none出现shell界面 02 在UEFI shell中创建APP 创建SimplestApp文件夹以及SimplestApp.c、SimplestApp.inf cd edk2 mkdir SimplestAppuuidgen // generate …...

基于 BERT 的自定义中文命名实体识别实现
基于 BERT 的自定义中文命名实体识别实现 在自然语言处理中,命名实体识别(Named Entity Recognition,NER)是一项重要的任务,旨在识别文本中的特定实体,如人名、地名、组织机构名等。本文将介绍如何使用 BERT 模型实现自定义中文命名实体识别,并提供详细的代码分析和解读…...

中秋节特别游戏:给玉兔投喂月饼
🖼️ 效果展示 📜 游戏背景 在中秋这个充满诗意的节日里,玉兔因为贪玩被赶下人间。在这个温柔的夜晚,我们希望通过一个小游戏,让玉兔感受到人间的温暖和关怀。🐰🌙 🎮 游戏设计 人…...

python pdf转word或excel
python pdf转word或excel 直接上源码 main import gradio as gr import pdf2docx as p2d import Pdf2Excel as p2e import utils.id.IdUtil as idUtildef convert_pdf_to(pdf_file, pdf_pwd, pdf_to_type):if pdf_to_type "docx":# Convert PDF to DOCXcv p2d.C…...

华为BGP路由实战:从原理到策略调优的深度解析
1. 华为BGP路由技术入门指南 第一次接触华为BGP路由配置时,我被那些专业术语搞得晕头转向。经过多次实战后才发现,BGP就像互联网世界的邮局系统,负责在不同自治系统(AS)之间传递路由信息。华为设备的BGP实现特别适合企…...

帆软FineReport 10升级实战:从路径映射到安全配置的完整指南
1. 从FineReport 9到10的升级背景与准备工作 最近接手了一个企业级报表系统的升级项目,需要将现有的FineReport 9环境迁移到最新的10版本。在实际操作过程中发现,这不仅仅是简单的版本替换,而是涉及到路径映射、参数调整、安全配置等多个关键…...

从理论到实践:用Magma解锁代数计算新维度
1. 为什么你需要Magma这个代数计算神器 第一次接触Magma是在研究生时期,当时我需要计算一个椭圆曲线上的有理点。用Matlab折腾了整整一周毫无进展,导师随手扔给我一个Magma代码示例,三行命令就解决了问题。那一刻我才明白,专业的事…...

manage-fastapi部署指南:Docker、docker-compose和生产环境配置终极教程
manage-fastapi部署指南:Docker、docker-compose和生产环境配置终极教程 【免费下载链接】manage-fastapi :rocket: CLI tool for FastAPI. Generating new FastAPI projects & boilerplates made easy. 项目地址: https://gitcode.com/gh_mirrors/ma/manage…...

从CVE-2017-11882到CVE-2018-0802:一个Office漏洞的“补丁绕过”实战复现与调试分析
从CVE-2017-11882到CVE-2018-0802:Office漏洞补丁绕过的深度解析与实战复现 漏洞背景与历史沿革 2017年11月,微软修补了一个存在近20年的Office公式编辑器组件漏洞(CVE-2017-11882),该漏洞允许攻击者通过特制的RTF文档…...

STR71X中断服务程序定位与Keil MDK配置详解
1. STR71X中断服务程序定位问题解析在基于ARM7架构的STR71X系列微控制器开发过程中,中断服务程序(ISR)的定位是一个关键但容易被忽视的技术细节。STR71X采用增强型中断控制器(EIC),其硬件设计要求所有中断服务例程必须位于同一个64KB内存段内。这个限制源…...

2026届学术党必备的十大AI学术方案实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek AI工具运用越来越广泛,然而随之出现的信息过多无法承受以及决策变得复杂的状况&…...

Windows右键菜单冒出‘Microsoft WinRT Storage API‘?别慌,用Procmon揪出元凶并修复
Windows右键菜单异常选项排查指南:从Procmon分析到注册表修复 最近不少Windows用户反馈,在右键点击文件或图片时,菜单中突然出现了名为"Microsoft WinRT Storage API"的陌生选项,点击后还会弹出错误提示。这种看似系统级…...

RAG我懂你:从架构到知识库构建
导航 传统大语言模型主要依赖参数中的隐式知识进行回答,容易受到知识过期、幻觉和领域知识不足等问题影响。RAG 的核心思想是:在生成答案之前,先从外部知识库中检索相关信息,再将这些信息作为上下文提供给大语言模型,从…...

JoyCon-Driver:Windows平台上的Switch手柄完美解决方案
JoyCon-Driver:Windows平台上的Switch手柄完美解决方案 【免费下载链接】JoyCon-Driver A vJoy feeder for the Nintendo Switch JoyCons and Pro Controller 项目地址: https://gitcode.com/gh_mirrors/jo/JoyCon-Driver 还在为Nintendo Switch JoyCon控制器…...