人工智能与机器学习原理精解【21】
文章目录
- SVM
- 求两线段上距离最近的两个点
- 问题描述:
- 距离函数:
- 解法:
- 具体步骤:
- 特别注意:
- 示例代码
- SVM思想的介入
- 1. **SVM 的基本思想**
- 超平面:
- 2. **分类间隔(Margin)**
- 1. **分类间隔的定义**
- 2. **几何间隔与函数间隔**
- 3. **最大化分类间隔**
- 4. **支持向量与分类间隔**
- 5. **最大化间隔的意义**
- 3. **硬间隔与软间隔**
- 4. **对偶问题与核技巧**
- 核函数
- 5. **支持向量**
- 1. **支持向量的定义**
- 2. **支持向量的性质**
- 3. **支持向量的作用**
- 4. **支持向量的计算**
- 5. **支持向量的重要性**
- 总结
- 6. **优化目标与拉格朗日乘子法**
- 1. **SVM 的原始优化问题**
- 2. **拉格朗日乘子法**
- 3. **求解原始问题的对偶问题**
- 4. **对偶问题**
- 5. **支持向量的定义**
- 6. **核函数与对偶问题的扩展**
- 7. **最终分类器**
- 总结
- 7. **SVM 的扩展**
- 1. **核方法(Kernel Methods)**
- 核函数的作用
- 常见的核函数
- 2. **软间隔 SVM(Soft Margin SVM)**
- 软间隔 SVM 的优化问题
- 3. **多分类 SVM**
- 一对多(One-vs-All, OvA)
- 一对一(One-vs-One, OvO)
- 直接多分类 SVM
- 4. **支持向量回归(Support Vector Regression, SVR)**
- SVR 的目标函数
- 5. **在线 SVM(Online SVM)**
- 在线学习的特点
- 6. **结构化 SVM(Structured SVM)**
- 应用场景
- 7. **概率 SVM**
- 8. **增强型 SVM**
- 8. **SVM 的优势与局限**
- 总结:
- 在Julia中,SVM实现
- 参考文献
SVM
求两线段上距离最近的两个点
在支持向量机(SVM)的框架下,求解两条线段之间距离最近的两个点可以视为一个最优化问题。通常这个问题不直接涉及传统的SVM模型(用于分类或回归),而是与凸优化更为相关。这里我们可以使用几何方法和最优化技术来解决该问题。以下是求解思路:
问题描述:
给定两条线段:
- 第一条线段上的点为 P 1 ( t ) = ( 1 − t ) A 1 + t B 1 P_1(t) = (1 - t) A_1 + t B_1 P1(t)=(1−t)A1+tB1, 其中 A 1 A_1 A1 和 B 1 B_1 B1是线段的两个端点, t ∈ [ 0 , 1 ] t \in [0, 1] t∈[0,1]。
- 第二条线段上的点为 P 2 ( s ) = ( 1 − s ) A 2 + s B 2 P_2(s) = (1 - s) A_2 + s B_2 P2(s)=(1−s)A2+sB2, 其中 A 2 A_2 A2和 B 2 B_2 B2 是线段的两个端点, s ∈ [ 0 , 1 ] s \in [0, 1] s∈[0,1]。
我们需要找到 P 1 ( t ) P_1(t) P1(t) 和 P 2 ( s ) P_2(s) P2(s)之间的最小距离,即最小化两个点之间的欧氏距离。
距离函数:
两个点之间的距离函数可以写为:
d ( t , s ) = ∥ P 1 ( t ) − P 2 ( s ) ∥ = ∥ ( 1 − t ) A 1 + t B 1 − ( ( 1 − s ) A 2 + s B 2 ) ∥ d(t, s) = \| P_1(t) - P_2(s) \| = \left\| (1 - t) A_1 + t B_1 - \left( (1 - s) A_2 + s B_2 \right) \right\| d(t,s)=∥P1(t)−P2(s)∥=∥(1−t)A1+tB1−((1−s)A2+sB2)∥
我们希望最小化 ( d(t, s) ),即:
min t , s ∈ [ 0 , 1 ] d ( t , s ) \min_{t, s \in [0, 1]} d(t, s) t,s∈[0,1]mind(t,s)
解法:
该问题本质上是一个二元函数的约束最优化问题。可以通过以下步骤求解:
-
构造目标函数:
展开距离平方 ( d(t, s)^2 ),这样我们避免求平方根,简化最小化问题:
f ( t , s ) = ( ( 1 − t ) A 1 + t B 1 − ( 1 − s ) A 2 − s B 2 ) 2 f(t, s) = \left( (1 - t) A_1 + t B_1 - (1 - s) A_2 - s B_2 \right)^2 f(t,s)=((1−t)A1+tB1−(1−s)A2−sB2)2 -
优化求解:
为了求解最小值,可以对 t t t和 s s s 分别求偏导数:
∂ f ∂ t = 0 , ∂ f ∂ s = 0 \frac{\partial f}{\partial t} = 0, \quad \frac{\partial f}{\partial s} = 0 ∂t∂f=0,∂s∂f=0
这些方程可能是非线性的,可以通过数值优化算法(如梯度下降法、牛顿法等)来求解。同时,我们需要保证 ( t ) 和 ( s ) 在区间 ( [0, 1] ) 之内,必要时可以使用投影来处理约束。 -
检查边界条件:
除了对内部点进行优化,还需要检查线段的端点,即 t = 0 t = 0 t=0或 t = 1 t = 1 t=1以及 s = 0 s = 0 s=0或 ( s = 1 ) 的情况。比较这些端点条件下的距离,以确保找到全局最小值。
具体步骤:
- 确定 A 1 A_1 A1、 B 1 B_1 B1、 A 2 A_2 A2 和 B 2 B_2 B2 的坐标。
- 根据上述公式计算目标函数 f ( t , s ) f(t, s) f(t,s)。
- 使用数值方法(如梯度下降或其他优化工具)求解最优 t t t 和 s s s。
- 比较端点与内部的结果,找到最小距离。
特别注意:
这类问题通常不是直接通过SVM求解,而是通过凸优化或几何算法来处理。然而,类似的支持向量思想可以应用于“寻找两组数据之间的最小距离”问题中。如果你希望利用SVM框架去解决两类数据之间的“最近点”问题,可以通过最小化分类间隔(margin)来实现。
示例代码
-
要求两线段距离最近的两个点,我们可以使用之前提到的向量和参数方程方法,然后利用微积分中的优化技术(如求导并令导数为零)来找到最小距离。
-
不过,对于具体的实现,我们可以选择一种更直观且易于编码的方法:遍历其中一条线段的点,并在另一条线段上找到与其距离最近的点,然后记录并更新最小距离和对应的点。虽然这种方法可能不是最高效的(因为它的时间复杂度接近O(n),其中n是遍历的细粒度),但它易于理解和实现。
-
为了更高效地解决这个问题,我们可以使用一种基于几何的算法,该算法通过计算两线段之间的最短向量(该向量垂直于其中一条线段或同时垂直于两条线段的公垂线,如果存在的话)来找到最近点。这种方法通常涉及解一个二次方程或利用向量的投影和拒绝性质。
下面是一个在Julia中实现这种高效算法的例子:
using LinearAlgebrafunction closest_points_on_segments(A, B, C, D)# Convert points to vectorsu = B - Av = D - Cw = A - C# Compute dot productsa = dot(u, u)b = dot(u, v)c = dot(v, v)d = dot(u, w)e = dot(v, w)# Compute the parameter of the closest point on segment AB (t) and CD (s)DENOM = a * c - b * bif DENOM == 0 # Segments are parallelif e == 0 # Segments are collinear# In this case, any point on one segment is the closest to any point on the other# We choose the endpoints of segment AB and the corresponding point on CDt = 0.0if dot(w, v) < 0s = 0.0elseif dot(w + u, v) > 0s = 1.0elses = -d / b # or s = e / c, since b == 0 when segments are parallelendelse # Segments are not collinear but parallel# The closest points are the endpoints of the segments that are closest to each other# We can project one segment onto the other and find the closest points# Here we assume that the segments do not overlap, so we only need to check endpointst0 = -d / at1 = (e - b) / cif t0 < 0t = 0.0s = e / celseif t0 > 1t = 1.0s = (e - b) / celset = t0s = 0.0end# If t1 is within [0, 1], use it instead of s computed aboveif 0 <= t1 <= 1s = t1# Recompute t based on s if necessary (usually not needed if we only care about one of the segments)# t = (d + b * s) / a # This is not needed since we already have t from aboveendendelse # Segments are not parallels = (b * e - c * d) / DENOMt = (a * e - b * d) / DENOM# Clamp s and t to be within [0, 1] since they represent parameters on the segmentss = clamp(s, 0.0, 1.0)t = clamp(t, 0.0, 1.0)end# Compute the closest pointsP = A + t * uQ = C + s * vreturn P, Q
end# Example usage
A = [1.0, 2.0, 3.0]
B = [4.0, 5.0, 6.0]
C = [7.0, 8.0, 0.0]
D = [10.0, 11.0, -1.0]P, Q = closest_points_on_segments(A, B, C, D)
println("Closest point on AB: $P")
println("Closest point on CD: $Q")
注意:
- 这个实现考虑了线段平行和共线的情况。当线段平行但不共线时,它会找到与另一条线段距离最近的端点。当线段共线时,它会找到重叠部分(如果存在)内的任意一点或最接近的端点。
clamp函数用于确保参数s和t在 [0, 1] 范围内,这样计算出的点就一定在线段上。- 这个算法的时间复杂度是 O(1),因为它只涉及基本的数学运算和条件检查。
SVM思想的介入
支持向量机(SVM,Support Vector Machine)是一种用于分类、回归和异常检测的监督学习模型。SVM 的理论基础源自统计学习理论,主要用于解决二分类问题,但它也可以扩展到多分类任务和回归问题。
在Julia中实现支持向量机(SVM)通常可以利用现有的机器学习库,如LIBSVM、scikit-learn的Julia接口(通过scikit-learn-kit),或者使用Julia自身的机器学习库如MLJ。不过,如果你想要从头开始实现SVM以更好地理解其工作原理,你可以使用Julia的基础数学和优化功能。
这里,我将提供一个简单的SVM实现的框架,用于求解两线段之间距离最近的两个点。不过请注意,标准的SVM是用于分类任务的,而我们这里的问题更类似于一个几何问题。为了使用SVM的思想,我们可以将其转化为一个优化问题,即寻找一个超平面(在这里是一条直线),使得这条直线能够最大化两线段上点到它的距离的最小值(即边际)。
然而,对于两线段之间距离最近的两个点的问题,更直接的方法是使用几何算法,而不是SVM。不过,为了展示如何在Julia中实现SVM的基本思想,我将提供一个简化的SVM风格的优化问题。
首先,我们需要定义线段的端点,并创建一个函数来计算点到直线的距离。然后,我们可以设置一个优化问题,使用Julia的优化库(如Optim)来求解。
以下是一个简化的Julia代码示例,用于求解两线段上距离最近的两个点(但请注意,这不是标准的SVM实现):
using Optim# 定义线段的端点
A = [1.0, 2.0]
B = [4.0, 6.0]
C = [3.0, 1.0]
D = [6.0, 3.0]# 计算点到直线的距离
function point_to_line_distance(p, l1, l2)# l1, l2 是直线上的两点,p 是要计算距离的点normal_vector = [l2[2] - l1[2], -(l2[1] - l1[1])] # 直线的法向量numerator = dot(normal_vector, [p[1] - l1[1], p[2] - l1[2]])denominator = norm(normal_vector)return abs(numerator / denominator)
end# 定义一个函数,用于优化
function objective_function(params)# params 包含两个点 P 和 Q 的坐标,分别在线段 AB 和 CD 上P = [params[1], A[2] + (B[2] - A[2]) * params[1]] # P 点在 AB 上,由参数 params[1] 确定Q = [params[2], C[2] + (D[2] - C[2]) * params[2]] # Q 点在 CD 上,由参数 params[2] 确定# 计算 P 和 Q 之间的距离return norm(P - Q)
end# 设置优化问题的初始猜测和边界
initial_guess = [0.5, 0.5] # 假设 P 和 Q 分别在 AB 和 CD 的中点
lower_bounds = [0.0, 0.0] # 参数的下界
upper_bounds = [1.0, 1.0] # 参数的上界# 使用 Optim 库进行优化
options = Optim.options(iterations = 1000, g_tol = 1e-6)
result = Optim.optimize(objective_function, lower_bounds, upper_bounds, initial_guess, Fminbox(LBFGSBox()), options)# 输出结果
optimized_params = Optim.minimizer(result)
P = [optimized_params[1], A[2] + (B[2] - A[2]) * optimized_params[1]]
Q = [optimized_params[2], C[2] + (D[2] - C[2]) * optimized_params[2]]
println("Closest point on AB: $P")
println("Closest point on CD: $Q")
println("Minimum distance: $(norm(P - Q))")
注意:
- 上面的代码示例并不是一个真正的SVM实现,而是一个简化的优化问题,用于找到两线段上距离最近的两个点。
- 我使用了
Optim库来进行优化,但你需要确保已经安装了这个库(使用Pkg.add("Optim"))。 - 代码中的
objective_function函数计算了由params参数确定的两个点P和Q之间的距离。这里假设了线段是线性的,并且点P和Q分别由线段AB和CD上的参数(即它们在各自线段上的位置比例)来确定。 - 这个优化问题假设了线段的端点是已知的,并且线段是直线。对于更复杂的情况,比如曲线或者未知端点,需要不同的方法来处理。
以下是 SVM 的核心理论与原理:
1. SVM 的基本思想
SVM 的主要目的是在特征空间中找到一个超平面,将不同类别的数据尽可能分开,并使得分类间隔(margin)最大化。换句话说,SVM 寻找一个分隔两类数据的最佳超平面,使得离超平面最近的样本点(支持向量)到超平面的距离最大化。
超平面:
对于二维空间,超平面就是一条线;对于三维空间,超平面就是一个平面;在更高维空间中,超平面就是一个更高维的分隔空间。它的数学形式是:
w T x + b = 0 w^T x + b = 0 wTx+b=0
其中, w w w是法向量,决定了超平面的方向; b b b是偏置项,决定了超平面与原点的距离。
2. 分类间隔(Margin)
在支持向量机(SVM)中,分类间隔(Margin) 是一个非常重要的概念。它是指分离超平面到离它最近的正类和负类样本点之间的距离。SVM 的目标就是要找到能够最大化这个间隔的分离超平面,因为更大的分类间隔通常意味着模型的泛化能力更强。
1. 分类间隔的定义
设 w w w是超平面的法向量, b b b 是偏置项,超平面的方程为:
w T x + b = 0 w^T x + b = 0 wTx+b=0
对于任意的样本点 $x_i $,它到超平面的距离 d d d可以通过以下公式计算:
d = ∣ w T x i + b ∣ ∥ w ∥ d = \frac{|w^T x_i + b|}{\|w\|} d=∥w∥∣wTxi+b∣
其中, w T x i + b w^T x_i + b wTxi+b是点 x i x_i xi到超平面的代数距离, ∥ w ∥ \|w\| ∥w∥是法向量 w w w的欧氏范数。
2. 几何间隔与函数间隔
-
几何间隔(Geometric Margin):几何间隔是超平面到最近点的距离。在 SVM 中,我们希望最大化分类间隔,以增强模型的泛化能力。
-
函数间隔(Functional Margin):对于每个样本 ( x i , y i ) (x_i, y_i) (xi,yi),函数间隔定义为:
γ i = y i ( w T x i + b ) \gamma_i = y_i (w^T x_i + b) γi=yi(wTxi+b)
其中 y i y_i yi是样本的标签(+1 或 -1)。函数间隔表示样本点在超平面一侧的代数距离。SVM 的目标是最大化函数间隔,同时满足所有样本点正确分类的约束。
3. 最大化分类间隔
SVM 的核心思想是最大化最小的几何间隔,即找到一个能够使得两类样本尽可能分开的超平面。具体来说,分类间隔是指正类和负类支持向量到分离超平面的距离之和。
假设数据是线性可分的,SVM 的优化目标为:
min w , b 1 2 ∥ w ∥ 2 \min_{w, b} \frac{1}{2} \|w\|^2 w,bmin21∥w∥2
其中 ∥ w ∥ 2 \|w\|^2 ∥w∥2是正则化项,约束条件是每个样本都要被正确分类,即:
y i ( w T x i + b ) ≥ 1 ∀ i y_i (w^T x_i + b) \geq 1 \quad \forall i yi(wTxi+b)≥1∀i
这是一个凸优化问题,可以通过拉格朗日对偶问题来求解。
4. 支持向量与分类间隔
支持向量是那些位于间隔边界上的样本点,这些点到超平面的距离等于分类间隔。因此,支持向量对最终的超平面起到了决定性的作用,而非支持向量的样本点不会影响超平面的构建。
对于硬间隔 SVM,分类间隔可以通过这些支持向量的距离来定义,并且这些支持向量满足:
y i ( w T x i + b ) = 1 y_i (w^T x_i + b) = 1 yi(wTxi+b)=1
在软间隔 SVM 中,引入了松弛变量 ( \xi_i ),允许部分样本点出现在错误的一侧,以实现更好的泛化效果。软间隔的优化目标是平衡分类间隔的大小与分类错误的数量:
min w , b , ξ 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ξ i \min_{w, b, \xi} \frac{1}{2} \|w\|^2 + C \sum_{i=1}^n \xi_i w,b,ξmin21∥w∥2+Ci=1∑nξi
其中 C C C是惩罚参数,控制分类间隔与错误分类之间的权衡。
5. 最大化间隔的意义
最大化分类间隔的意义在于它能提高模型的鲁棒性和泛化能力。较大的间隔意味着分类器对噪声和数据分布的变化不太敏感,从而降低了过拟合的风险。
3. 硬间隔与软间隔
-
硬间隔 SVM:假设数据是线性可分的,SVM 通过严格最大化分类间隔来构造一个完美的分离超平面。在这种情况下,不允许任何数据点落在错误的一侧或超平面上。
-
软间隔 SVM:当数据不可线性分时,引入松弛变量 ( \xi_i ),允许一些点可以出现在分类间隔或者错误分类的情况下。目标是在最大化分类间隔的同时,最小化分类错误。软间隔问题的目标函数为:
min w , b , ξ 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ξ i \min_{w, b, \xi} \frac{1}{2} \|w\|^2 + C \sum_{i=1}^n \xi_i w,b,ξmin21∥w∥2+Ci=1∑nξi
其中, C C C 是正则化参数,用于权衡分类间隔的大小和分类错误的惩罚。
4. 对偶问题与核技巧
SVM 的原始问题可以通过拉格朗日对偶性转换为一个对偶问题,从而避免直接处理高维空间中的数据。对偶问题的优化目标是通过拉格朗日乘子 ( \alpha ) 来定义的:
max α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j K ( x i , x j ) \max_{\alpha} \sum_{i=1}^n \alpha_i - \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n \alpha_i \alpha_j y_i y_j K(x_i, x_j) αmaxi=1∑nαi−21i=1∑nj=1∑nαiαjyiyjK(xi,xj)
其中, K ( x i , x j ) K(x_i, x_j) K(xi,xj) 是核函数,用于计算数据点在高维空间中的内积。
核函数
当数据在原始空间中不可分时,可以通过核函数将数据映射到一个高维空间,使得数据在该空间中线性可分。常用的核函数包括:
- 线性核: K ( x , x ′ ) = x T x ′ K(x, x') = x^T x' K(x,x′)=xTx′
- 多项式核: K ( x , x ′ ) = ( x T x ′ + c ) d K(x, x') = (x^T x' + c)^d K(x,x′)=(xTx′+c)d
- 高斯核(RBF 核): K ( x , x ′ ) = exp ( − ∥ x − x ′ ∥ 2 2 σ 2 ) K(x, x') = \exp(-\frac{\|x - x'\|^2}{2\sigma^2}) K(x,x′)=exp(−2σ2∥x−x′∥2)
- Sigmoid 核: K ( x , x ′ ) = tanh ( κ x T x ′ + θ ) K(x, x') = \tanh(\kappa x^T x' + \theta) K(x,x′)=tanh(κxTx′+θ)
5. 支持向量
SVM 模型的决策只依赖于那些位于分类间隔边界上的数据点,这些点称为支持向量。支持向量是那些最接近分离超平面的点,它们决定了最终的超平面的位置。如果移除这些点,超平面的位置将会改变。
在支持向量机(SVM)中,支持向量(Support Vectors) 是位于分类间隔边界上的数据点,它们在确定超平面的过程中起到了至关重要的作用。支持向量与超平面的距离等于分类间隔,并且它们是使得分类间隔最大化的关键。
1. 支持向量的定义
支持向量是那些位于分类间隔边界上的样本点。SVM 的决策边界(超平面)是通过这些支持向量来确定的,而非支持向量的点对最终的超平面没有影响。设定决策边界的目标是让正负类样本的分类间隔最大化,因此,只有那些紧贴分类间隔的点(即支持向量)对超平面的位置有贡献。
在二分类问题中,SVM 通过找到能将数据正确分类并且最大化分类间隔的超平面来构建模型。数学上,超平面的方程是:
w T x + b = 0 w^T x + b = 0 wTx+b=0
其中 w w w 是法向量,决定超平面的方向, b b b 是偏置,决定超平面到原点的距离。
2. 支持向量的性质
- 距离最近:支持向量是距离超平面最近的点,位于间隔的边界上。正类支持向量满足 w T x i + b = 1 w^T x_i + b = 1 wTxi+b=1,负类支持向量满足 w T x i + b = − 1 w^T x_i + b = -1 wTxi+b=−1。
- 定义超平面:超平面的最终位置完全由这些支持向量决定,移除非支持向量的点不会影响超平面的位置。
- 满足约束:在优化过程中,支持向量是那些对应的拉格朗日乘子 $\alpha_i4 不为零的点。优化问题的拉格朗日乘子形式为:
max α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j K ( x i , x j ) \max_{\alpha} \sum_{i=1}^n \alpha_i - \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n \alpha_i \alpha_j y_i y_j K(x_i, x_j) αmaxi=1∑nαi−21i=1∑nj=1∑nαiαjyiyjK(xi,xj)
其中, α i \alpha_i αi 为支持向量的拉格朗日乘子。对于非支持向量, α i = 0 \alpha_i = 0 αi=0;而支持向量对应的 α i > 0 \alpha_i > 0 αi>0。
3. 支持向量的作用
支持向量起到了以下几个关键作用:
-
决定分类边界:支持向量是超平面两侧最近的点,决定了分类边界的位置和方向。超平面和分类间隔的大小由支持向量完全确定。
-
优化问题中的关键点:在 SVM 的凸优化问题中,支持向量是那些约束条件处于“活跃”状态的点,即满足 y i ( w T x i + b ) = 1 y_i (w^T x_i + b) = 1 yi(wTxi+b)=1或 y i ( w T x i + b ) = − 1 y_i (w^T x_i + b) = -1 yi(wTxi+b)=−1的点。
-
泛化性能:支持向量的数目直接影响 SVM 的泛化能力。较少的支持向量通常意味着分类器的复杂度较低,从而提升模型的泛化能力。
4. 支持向量的计算
支持向量是在优化过程中通过求解二次规划问题找到的。SVM 的目标是最大化分类间隔并找到最优的超平面。通过引入拉格朗日乘子和对偶问题,SVM 解决了如下问题:
min w , b 1 2 ∥ w ∥ 2 \min_{w, b} \frac{1}{2} \|w\|^2 w,bmin21∥w∥2
约束条件为:
y i ( w T x i + b ) ≥ 1 ∀ i y_i (w^T x_i + b) \geq 1 \quad \forall i yi(wTxi+b)≥1∀i
优化求解过程中,支持向量是那些对应的拉格朗日乘子 ( \alpha_i > 0 ) 的点,它们决定了超平面的最终位置。
5. 支持向量的重要性
支持向量的存在体现了 SVM 的高效性:即使在数据量较大的情况下,只有一部分数据点(即支持向量)对最终模型产生影响。这种特性使得 SVM 在高维数据的分类任务中表现良好。
此外,支持向量对于 SVM 的泛化能力至关重要。通过支持向量来确定的超平面在数据分布上具有良好的鲁棒性,因此即使面对新的测试样本,SVM 通常仍能保持较好的分类性能。
总结
支持向量是 SVM 中的核心概念,它们位于分类间隔的边界上,决定了超平面的最终位置。支持向量通过最大化分类间隔来确保模型的泛化能力,并且它们是 SVM 模型的主要决策依据。
6. 优化目标与拉格朗日乘子法
为了最大化分类间隔,SVM 引入了一个凸二次规划(QP)问题:
min w , b 1 2 ∥ w ∥ 2 \min_{w, b} \frac{1}{2} \|w\|^2 w,bmin21∥w∥2
并且满足约束条件:
y i ( w T x i + b ) ≥ 1 ∀ i y_i (w^T x_i + b) \geq 1 \quad \forall i yi(wTxi+b)≥1∀i
该问题可以通过引入拉格朗日乘子法来求解,并通过对偶问题使优化问题简化,最终求得最优解。
SVM 的拉格朗日乘子法用于将其优化问题从原始空间转换为对偶问题,从而简化求解过程,特别是在处理高维或非线性数据时起到了关键作用。
1. SVM 的原始优化问题
SVM 的目标是找到一个分离超平面,使得分类间隔最大化,并满足正确分类的约束条件。假设我们有一个二分类问题,训练数据集为 ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) (x_1, y_1), (x_2, y_2), \dots, (x_n, y_n) (x1,y1),(x2,y2),…,(xn,yn),其中 x i ∈ R d x_i \in \mathbb{R}^d xi∈Rd 是样本点, y i ∈ { − 1 , 1 } y_i \in \{-1, 1\} yi∈{−1,1} 是标签。
在 SVM 中,最优的超平面 w T x + b = 0 w^T x + b = 0 wTx+b=0 需要满足两个目标:
- 最大化分类间隔,即最小化 ∥ w ∥ 2 \|w\|^2 ∥w∥2。
- 满足每个样本点的分类约束条件,即:
y i ( w T x i + b ) ≥ 1 ∀ i y_i (w^T x_i + b) \geq 1 \quad \forall i yi(wTxi+b)≥1∀i
因此,SVM 的优化问题可以表示为:
min w , b 1 2 ∥ w ∥ 2 \min_{w, b} \frac{1}{2} \|w\|^2 w,bmin21∥w∥2
并且满足约束条件:
y i ( w T x i + b ) ≥ 1 ∀ i y_i (w^T x_i + b) \geq 1 \quad \forall i yi(wTxi+b)≥1∀i
2. 拉格朗日乘子法
为了将这个约束优化问题转化为无约束的优化问题,可以引入拉格朗日乘子法。拉格朗日乘子法通过引入一组非负的拉格朗日乘子 α i \alpha_i αi 来处理不等式约束,将约束问题转化为拉格朗日函数。
拉格朗日函数定义为:
L ( w , b , α ) = 1 2 ∥ w ∥ 2 − ∑ i = 1 n α i ( y i ( w T x i + b ) − 1 ) L(w, b, \alpha) = \frac{1}{2} \|w\|^2 - \sum_{i=1}^n \alpha_i \left( y_i (w^T x_i + b) - 1 \right) L(w,b,α)=21∥w∥2−i=1∑nαi(yi(wTxi+b)−1)
其中, α i ≥ 0 \alpha_i \geq 0 αi≥0 是拉格朗日乘子,代表对每个样本点的约束的重要性。
3. 求解原始问题的对偶问题
通过拉格朗日乘子法,原始问题的目标是同时最小化 w w w 和 b b b,并最大化 α \alpha α 以满足约束条件。我们首先对 L ( w , b , α ) L(w, b, \alpha) L(w,b,α) 对 w w w 和 b b b 进行最小化,然后对 α \alpha α 进行最大化。
计算最优 w w w 和 b b b:
对 L ( w , b , α ) L(w, b, \alpha) L(w,b,α) 分别对 w w w 和 b b b 求导,得到以下结果:
-
对 w w w 求导:
∂ L ∂ w = w − ∑ i = 1 n α i y i x i = 0 \frac{\partial L}{\partial w} = w - \sum_{i=1}^n \alpha_i y_i x_i = 0 ∂w∂L=w−i=1∑nαiyixi=0
所以:
w = ∑ i = 1 n α i y i x i w = \sum_{i=1}^n \alpha_i y_i x_i w=i=1∑nαiyixi -
对 b b b 求导:
∂ L ∂ b = − ∑ i = 1 n α i y i = 0 \frac{\partial L}{\partial b} = - \sum_{i=1}^n \alpha_i y_i = 0 ∂b∂L=−i=1∑nαiyi=0
因此:
∑ i = 1 n α i y i = 0 \sum_{i=1}^n \alpha_i y_i = 0 i=1∑nαiyi=0
将 w w w 的表达式代入拉格朗日函数中,消去 w w w 和 b b b,可以得到对偶问题:
4. 对偶问题
SVM 的对偶问题可以表示为:
max α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j ( x i T x j ) \max_{\alpha} \sum_{i=1}^n \alpha_i - \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n \alpha_i \alpha_j y_i y_j (x_i^T x_j) αmaxi=1∑nαi−21i=1∑nj=1∑nαiαjyiyj(xiTxj)
其中约束条件为:
α i ≥ 0 ∀ i \alpha_i \geq 0 \quad \forall i αi≥0∀i
∑ i = 1 n α i y i = 0 \sum_{i=1}^n \alpha_i y_i = 0 i=1∑nαiyi=0
这是一个凸优化问题,可以使用二次规划算法(Quadratic Programming, QP)来求解。
5. 支持向量的定义
在优化过程中,只有 α i > 0 \alpha_i > 0 αi>0 的点称为支持向量,支持向量是对最终超平面起作用的点。这意味着那些 α i = 0 \alpha_i = 0 αi=0 的点不会影响分类超平面的构建,而支持向量决定了超平面的具体位置和分类边界。
6. 核函数与对偶问题的扩展
SVM 的对偶问题形式化之后,核函数可以方便地应用于非线性分类问题。在非线性分类中,数据点在原始空间中可能不可分,但通过核函数将数据映射到一个高维特征空间,数据在高维空间中是线性可分的。
对偶问题中的 x i T x j x_i^T x_j xiTxj 可以用核函数 K ( x i , x j ) K(x_i, x_j) K(xi,xj) 替代,这样我们就不需要显式地进行高维映射,而是通过核函数直接计算高维空间中样本点之间的内积。
常用的核函数包括:
- 线性核: K ( x i , x j ) = x i T x j K(x_i, x_j) = x_i^T x_j K(xi,xj)=xiTxj
- 多项式核: K ( x i , x j ) = ( x i T x j + c ) d K(x_i, x_j) = (x_i^T x_j + c)^d K(xi,xj)=(xiTxj+c)d
- 高斯核(RBF 核): K ( x i , x j ) = exp ( − ∥ x i − x j ∥ 2 2 σ 2 ) K(x_i, x_j) = \exp\left(-\frac{\|x_i - x_j\|^2}{2\sigma^2}\right) K(xi,xj)=exp(−2σ2∥xi−xj∥2)
- Sigmoid 核: K ( x i , x j ) = tanh ( κ x i T x j + θ ) K(x_i, x_j) = \tanh(\kappa x_i^T x_j + \theta) K(xi,xj)=tanh(κxiTxj+θ)
7. 最终分类器
通过求解对偶问题得到最优的 α i \alpha_i αi,我们可以构建最终的分类决策函数:
f ( x ) = sign ( ∑ i = 1 n α i y i K ( x i , x ) + b ) f(x) = \text{sign}\left( \sum_{i=1}^n \alpha_i y_i K(x_i, x) + b \right) f(x)=sign(i=1∑nαiyiK(xi,x)+b)
其中, K ( x i , x ) K(x_i, x) K(xi,x) 是核函数,表示在高维空间中样本点之间的关系。
总结
SVM 的拉格朗日乘子法通过引入拉格朗日乘子,将约束优化问题转化为对偶问题,从而简化了求解过程。对偶问题能够很好地利用核函数进行非线性映射,允许我们在高维空间中处理复杂的分类问题。支持向量是那些对分类决策有关键作用的点,最终的分类器依赖于支持向量的拉格朗日乘子 α i \alpha_i αi。
7. SVM 的扩展
SVM 不仅可以解决二分类问题,还可以通过不同的扩展方法解决多分类和回归问题。
- 多分类 SVM:可以通过“一对一”或“一对多”的策略扩展到多分类任务。
- 支持向量回归(SVR):SVM 还可以用于回归任务,通过控制预测值与真实值之间的偏差来构建回归模型。
支持向量机(SVM)最初设计用于线性可分的二分类问题,但其强大的理论基础和可扩展性使其能够适应各种更复杂的任务。以下是 SVM 的主要扩展形式,涵盖非线性问题、多分类问题、回归问题等。
1. 核方法(Kernel Methods)
核方法是 SVM 最常见且最重要的扩展之一,用于处理非线性问题。原始的 SVM 仅适用于线性可分的数据,但通过使用核函数,SVM 能够在更高维的特征空间中解决非线性可分的问题。
核函数的作用
核函数 K ( x i , x j ) K(x_i, x_j) K(xi,xj) 通过将数据映射到高维空间(隐式映射),在这个高维空间中进行线性分类,而不需要显式地计算映射后的特征。核技巧的优点在于,只需要计算原始空间中数据点的内积,就能避免直接处理高维空间中复杂的计算。
常见的核函数
- 线性核函数:适用于线性可分的数据。
K ( x i , x j ) = x i T x j K(x_i, x_j) = x_i^T x_j K(xi,xj)=xiTxj - 多项式核函数:用于某些多项式分布的数据。
K ( x i , x j ) = ( x i T x j + c ) d K(x_i, x_j) = (x_i^T x_j + c)^d K(xi,xj)=(xiTxj+c)d - 高斯核(RBF 核函数):常用于处理复杂非线性数据。
K ( x i , x j ) = exp ( − ∥ x i − x j ∥ 2 2 σ 2 ) K(x_i, x_j) = \exp\left(-\frac{\|x_i - x_j\|^2}{2\sigma^2}\right) K(xi,xj)=exp(−2σ2∥xi−xj∥2) - Sigmoid 核函数:与神经网络中的激活函数类似。
K ( x i , x j ) = tanh ( κ x i T x j + θ ) K(x_i, x_j) = \tanh(\kappa x_i^T x_j + \theta) K(xi,xj)=tanh(κxiTxj+θ)
2. 软间隔 SVM(Soft Margin SVM)
现实中的数据往往是线性不可分的,存在噪声和异常点。因此,软间隔 SVM 允许某些样本点违反分类间隔,但通过引入松弛变量 ξ i \xi_i ξi 来控制这些点的数量和程度。
软间隔 SVM 的优化问题
min w , b , ξ 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ξ i \min_{w, b, \xi} \frac{1}{2} \|w\|^2 + C \sum_{i=1}^n \xi_i w,b,ξmin21∥w∥2+Ci=1∑nξi
其中, C C C是正则化参数,用来权衡分类间隔的大小与误分类的惩罚,松弛变量 ξ i ≥ 0 \xi_i \geq 0 ξi≥0 允许部分数据点位于错误的一侧。 C C C值较大时,模型更注重分类正确性,较小时则更注重间隔的最大化。
3. 多分类 SVM
SVM 本质上是二分类模型,但可以通过策略扩展为多分类器。
一对多(One-vs-All, OvA)
- 为每一个类别训练一个二分类器,将该类别与其他所有类别进行区分。
- 适用于类别数量较少的情况。
一对一(One-vs-One, OvO)
- 为每一对类别训练一个分类器,对 k k k 个类别,训练 k ( k − 1 ) / 2 k(k-1)/2 k(k−1)/2 个分类器。
- 投票法确定最终分类结果。
直接多分类 SVM
- 尝试通过一个优化问题同时解决多个分类器的构建。虽然理论上可行,但在实践中通常较复杂且较少使用。
4. 支持向量回归(Support Vector Regression, SVR)
SVM 也可以扩展用于回归任务,这就是支持向量回归(SVR)。SVR 不再试图找到分类超平面,而是寻找一个函数使得大多数数据点落入一个允许的误差范围内(称为 ϵ \epsilon ϵ-tube)。SVR 通过最大化间隔并最小化超出 ( \epsilon )-tube 的点的惩罚,来达到最优的回归效果。
SVR 的目标函数
min w , b , ξ , ξ ∗ 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ( ξ i + ξ i ∗ ) \min_{w, b, \xi, \xi^*} \frac{1}{2} \|w\|^2 + C \sum_{i=1}^n (\xi_i + \xi_i^*) w,b,ξ,ξ∗min21∥w∥2+Ci=1∑n(ξi+ξi∗)
其中, ξ i \xi_i ξi 和 ξ i ∗ \xi_i^* ξi∗是松弛变量,表示预测值偏离 ϵ \epsilon ϵ-tube 的程度。
5. 在线 SVM(Online SVM)
传统的 SVM 是批处理模型,要求一次处理所有数据,然而在一些应用中(如流数据、实时系统),数据是动态变化的。因此,在线 SVM 提出了一种逐步学习模型的方法,即每次只用新到的数据对模型进行更新。
在线学习的特点
- 处理动态数据,适用于流数据的场景。
- 逐步更新模型,而不必每次从头开始训练。
6. 结构化 SVM(Structured SVM)
结构化 SVM 是用于处理复杂输出结构的扩展模型,通常用于自然语言处理、图像分析等任务中。输出不再是简单的标量或类别标签,而是可能是序列、树结构、图等更复杂的形式。
应用场景
- 序列标注(如 POS 标注、命名实体识别)
- 依存句法分析
- 图像分割等
7. 概率 SVM
SVM 本身是一个确定性模型,即在分类时直接给出类别标签而非概率。但在某些情况下,预测结果的概率分布信息可能更加有用。概率 SVM 的目标是通过后处理技术(如 Platt 缩放法)将 SVM 的输出转换为概率估计。
8. 增强型 SVM
增强型 SVM 将 SVM 与其他技术结合起来,以提高模型性能或适应特定的任务需求。例如:
- 集成 SVM(Ensemble SVM):通过多个 SVM 的集成(如 Bagging、Boosting)来提高预测精度。
- 混合模型:将 SVM 与其他机器学习算法(如神经网络、决策树)结合使用,形成混合模型。
8. SVM 的优势与局限
-
优势:
- 能有效处理高维空间数据,尤其适合于维度较高的场景。
- 对于数据集中的噪声具有较强的鲁棒性。
- 在合适的核函数选择下,SVM 具有良好的泛化能力。
-
局限:
- 对于大规模数据集,训练时间较长,且内存需求较高。
- 在处理噪声和重叠数据时,参数 ( C ) 和核函数的选择较为敏感。
- 核函数的选择和参数调整相对复杂,依赖经验和调参技巧。
总结:
SVM 是一种强大的监督学习模型,其核心思想是通过最大化分类间隔来实现良好的分类效果。核技巧的引入使得它能够应对非线性分类问题。SVM 的优化问题通过凸二次规划求解,在理论上具有稳健性和收敛性。
在Julia中,SVM实现
MLJ(Machine Learning in Julia)是一个非常流行的机器学习库,它提供了统一的接口来访问多种机器学习算法,包括支持向量机(SVM)。MLJ不仅简化了模型训练和评估的过程,还允许用户轻松地比较和组合不同的机器学习算法。
要使用MLJ中的SVM,你需要首先安装MLJ库以及相关的SVM实现。在Julia中,你可以使用以下命令来安装这些库:
using Pkg
Pkg.add("MLJ")
Pkg.add("MLJLinearModels") # 对于线性SVM
# 或者,如果你需要非线性SVM(比如使用RBF核),你可能需要安装另一个包,如:
# Pkg.add("LibSVM") # 注意:LibSVM在MLJ中可能需要通过特定的接口来使用
安装完成后,你可以按照以下步骤来使用MLJ中的SVM:
-
导入库:
首先,你需要导入MLJ库以及任何其他相关的库。using MLJ using MLJLinearModels # 对于线性SVM # 或者,如果你安装了LibSVM,也可以导入它(但请注意,下面的示例将使用线性SVM) -
准备数据:
你需要将你的数据准备为MLJ可以处理的格式。通常,这意味着将数据存储在DataFrame中,并将特征和目标变量分开。 -
定义模型:
在MLJ中,你可以使用@load宏来加载特定的机器学习算法。对于线性SVM,你可以这样做:svm_model = @load LinearSVC请注意,
LinearSVC是线性支持向量分类器的缩写。如果你需要其他类型的SVM(比如使用不同的核函数),你可能需要查找并加载相应的模型。 -
训练模型:
使用MLJ的fit!函数来训练你的模型。你需要提供模型、数据以及任何必要的参数。# 假设你有一个DataFrame `df`,其中`X`是特征,`y`是目标变量 X = df[:, :-1] # 所有列除了最后一列都是特征 y = df[:, end] # 最后一列是目标变量# 将数据划分为训练集和测试集(可选) train, test = partition(eachindex(y), 0.8, shuffle=true)# 训练模型 fit_result = fit!(svm_model, X[train, :], y[train]) -
评估模型:
使用MLJ的evaluate!函数或其他相关函数来评估你的模型性能。# 预测测试集 predictions = predict(svm_model, fit_result, X[test, :])# 评估性能 performance = evaluate!(predictions, y[test], accuracy) println("Accuracy: ", performance) -
调整参数(可选):
MLJ允许你轻松地调整模型的参数。你可以使用param_grid或RandomSearch等函数来进行参数搜索。
请注意,上面的代码是一个简化的示例,它假设你已经有了适当格式的数据,并且没有进行任何数据预处理或特征工程。在实际应用中,你可能需要花费更多的时间来准备和清洗数据,以及选择和调整模型的参数。
参考文献
- 文心一言
- chatgpt
相关文章:

人工智能与机器学习原理精解【21】
文章目录 SVM求两线段上距离最近的两个点问题描述:距离函数:解法:具体步骤:特别注意:示例代码 SVM思想的介入1. **SVM 的基本思想**超平面: 2. **分类间隔(Margin)**1. **分类间隔的…...
【MySQL 01】数据库基础
目录 1.数据库是什么 2.基本操作 数据库服务器连接操作 数据库和数据库表的创建 服务器,数据库,表关系 数据逻辑存储 3.MySQL架构 4.SQL分类 5.存储引擎 1.数据库是什么 mysql&&mysqld: mysql:这通常指的是 MySQL …...

C语言字符学习中级使用库解决问题
学习C语言中的字符处理,对于初学者来说,理解字符的基本概念以及如何进行操作是非常重要的。字符处理是指对单个字符或一组字符(字符串)的操作。为了更好地理解,下面从基础开始介绍,并结合一些常用的函数和示…...

网络管理:网络故障排查指南
在现代IT环境中,网络故障是不可避免的。快速、有效地排查和解决网络故障是确保业务连续性和用户满意度的关键。本文将详细介绍网络故障排查的基本方法和步骤,确保内容通俗易懂,并配以代码示例和必要的图片说明。 一、网络故障排查的基本步骤 确认故障现象 确认用户报告的故…...
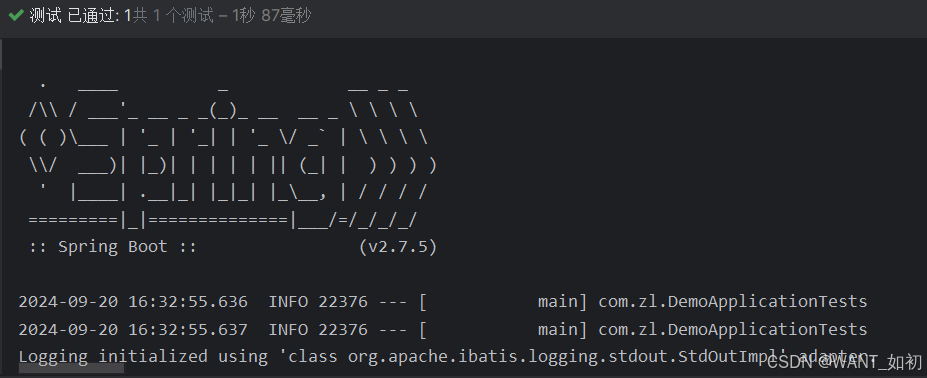
Springboot常见问题(bean找不到)
如图错误显示userMapper bean没有找到。 解决方案: mapper包位置有问题:因为SpringBoot默认的包扫描机制会扫描启动类所在的包同级文件和子包下的文件。注解问题: 比如没有加mapper注解 然而无论是UserMapper所在的包位置还是Mapper注解都是…...

架构设计笔记-5-软件工程基础知识
知识要点 按软件过程活动,将软件工具分为软件开发工具、软件维护工具、软件管理和软件支持工具。 软件开发工具:需求分析工具、设计工具、编码与排错工具。 软件维护工具:版本控制工具、文档分析工具、开发信息库工具、逆向工程工具、再工…...

Solidity——抽象合约和接口详解
🚀本系列文章为个人学习笔记,目的是巩固知识并记录我的学习过程及理解。文笔和排版可能拙劣,望见谅。 Solidity中的抽象合约和接口详解 目录 什么是抽象合约?抽象合约的语法接口(Interface)的定义接口的语…...
Fyne ( go跨平台GUI )中文文档-入门(一)
本文档注意参考官网(developer.fyne.io/) 编写, 只保留基本用法go代码展示为Go 1.16 及更高版本, ide为goland2021.2 这是一个系列文章: Fyne ( go跨平台GUI )中文文档-入门(一)-CSDN博客 Fyne ( go跨平台GUI )中文文档-Fyne总览(二)-CSDN博客 Fyne ( go跨平台GUI )…...

Google 扩展 Chrome 安全和隐私功能
过去一周,谷歌一直在推出新特性和功能,旨在让用户在 Chrome 上的桌面体验更加安全,最新的举措是扩展在多个设备上保存密钥的功能。 到目前为止,Chrome 网络用户只能将密钥保存到 Android 上的 Google 密码管理器,然后…...

css 缩放会变动的需要使用转换
position: fixed;top: 170px;left: 50%;transform: translate(-50%, -50%);...
数据库neo4j数据备份)
(17)数据库neo4j数据备份
图数据库备份 假设图数据库安装位置:/root/shuzihua/neo4j-community-3.5.8 1.数据导出 进入/root/shuzihua/neo4j-community-3.5.8/bin目录;执行 neo4j stop 停止服务;/root/shuzihua/neo4j-community-3.5.8/data/databases/graph.db&#…...

从零开始学习Python
目录 从零开始学习Python 引言 环境搭建 安装Python解释器 选择IDE 基础语法 注释 变量和数据类型 变量命名规则 数据类型 运算符 算术运算符 比较运算符 逻辑运算符 输入和输出 控制流 条件语句 循环语句 for循环 while循环 循环控制语句 函数和模块 定…...

前端框架的对比和选择
在当今的前端开发领域,有多种流行的前端框架可供选择,如 Vue、React 和 Angular。以下是这些框架的对比以及 Vue 的优势: 一、React 特点: 声明式编程:使用 JSX 语法,使得组件的结构和行为更加清晰。虚拟…...

《机器学习》周志华-CH7(贝叶斯分类)
7.1贝叶斯决策论 对分类任务而言,在所有相关概率已知的理想情形下,贝叶斯决策论考虑如何基于这些概率核误判损失来选择最优的类别标记。 R ( x i ∣ x ) ∑ j 1 N λ i j P ( c j ∣ x ) \begin{equation} R(x_{i}|x)\sum_{j1}^{N}\lambda_{ij}P(c_{j}…...
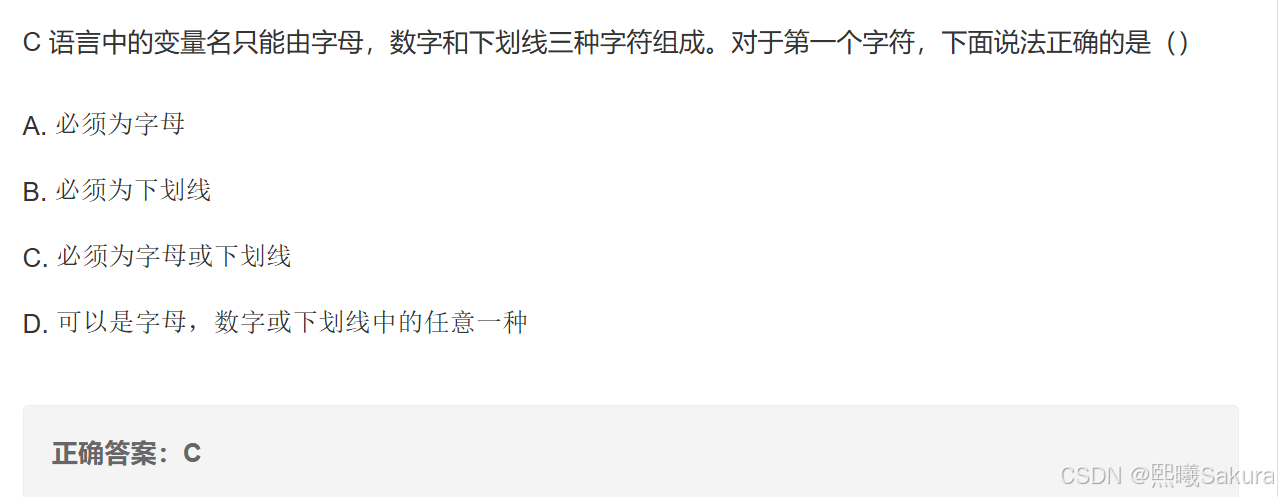
【C/C++】错题记录(一)
题目一 这道题主要考查了用户对标准库函数的使用规则的理解。 选项 A,一般情况下用户调用标准库函数前不需要重新定义,该项说法错误。 选项 B,即使包含了标准库头文件及相关命名空间,也不允许用户重新定义标准库函数,…...
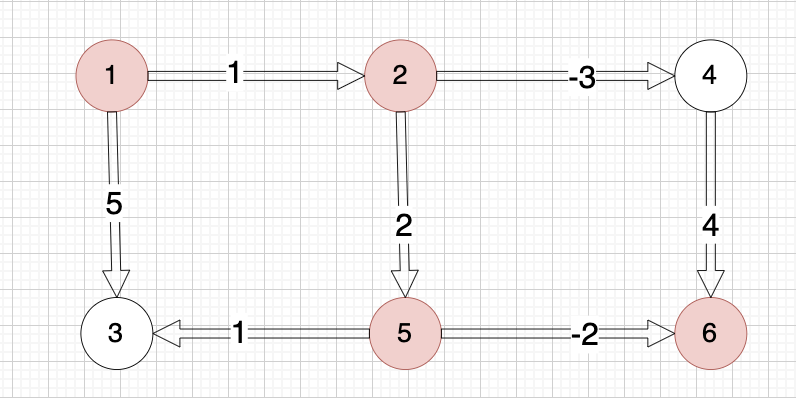
【代码随想录训练营第42期 Day60打卡 - 图论Part10 - Bellman_ford算法系列运用
目录 一、Bellman_ford算法的应用 二、题目与题解 题目一:卡码网 94. 城市间货物运输 I 题目链接 题解:队列优化Bellman-Ford算法(SPFA) 题目二:卡码网 95. 城市间货物运输 II 题目链接 题解: 队列优…...

vue复制信息到粘贴框
npm install vue-clipboard2main.js文件引入 import VueClipboard from vue-clipboard2 Vue.use(VueClipboard)页面应用 copyInfo(info){let that thislet copyData 项目名称:${info.projectName}\n 用户名:${info.username}\n 初始密码:${…...
STM32基础笔记
第一章、STM32基本介绍 总内容 计算机技术简介环境安装、项目流程搭建最小系统时钟系统启动相关:启动文件、启动流程、启动方式GPIOUSARTNVIC: 外部中断_串口中断( DMA )TIMERADCDHT11: 单总线协议SPI : LCD屏 ## **1、计算机技术简介** 1.通用计算机/专用计算机…...

【深入学习Redis丨第六篇】Redis哨兵模式与操作详解
〇、前言 哨兵是一个分布式系统,你可以在一个架构中运行多个哨兵进程,这些进程使用流言协议来接收关于Master主服务器是否下线的信息,并使用投票协议来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master。 文章目录 〇、…...

开源项目 GAN 漫画风格化 UGATIT
开源项目:DataBall / UGATIT GitCode * 数据集 * [该项目制作的训练集的数据集下载地址(百度网盘 Password: gxl1 )](https://pan.baidu.com/s/1683TRcv3r3o7jSitq3VyYA) * 预训练模型 * [预训练模型下载地址(百度网盘 Password: khbg )](https://pan.ba…...

Qwen2.5-72B-Instruct-GPTQ-Int4部署教程:vLLM与HuggingFace Transformers对比
Qwen2.5-72B-Instruct-GPTQ-Int4部署教程:vLLM与HuggingFace Transformers对比 1. 模型简介 Qwen2.5-72B-Instruct-GPTQ-Int4是Qwen大语言模型系列的最新版本,具有720亿参数规模。相比前代Qwen2,这个版本在多个方面实现了显著提升ÿ…...

Jailer命令行大师课:自动化数据库子集化的10个技巧
Jailer命令行大师课:自动化数据库子集化的10个技巧 【免费下载链接】Jailer Database Subsetting and Relational Data Browsing Tool. 项目地址: https://gitcode.com/gh_mirrors/ja/Jailer Jailer是一款强大的开源数据库子集化工具,专注于从生产…...

AudioSeal实战教程:Python API调用AudioSeal模型实现批量音频水印处理
AudioSeal实战教程:Python API调用AudioSeal模型实现批量音频水印处理 1. 项目概述与核心价值 AudioSeal是Meta开源的专业级音频水印系统,专门用于AI生成音频的检测和溯源。这个工具能帮助内容创作者、平台运营者和版权方解决一个关键问题:…...

Mirage Flow 硬件开发入门:Keil5 MDK安装与嵌入式AI项目创建
Mirage Flow 硬件开发入门:Keil5 MDK安装与嵌入式AI项目创建 如果你对把AI模型塞进一个小小的单片机里感到好奇,想亲手试试让硬件“聪明”起来,那么你来对地方了。很多朋友在第一步——搭建开发环境上就卡住了,面对一堆安装包和配…...
)
Java医疗系统通过等保三级测评前,这8个高危漏洞必须在72小时内闭环(附OWASP Top 10映射清单)
第一章:医疗Java系统等保三级合规性基线与高危漏洞判定标准在医疗行业,Java系统承载着电子病历、HIS、LIS、PACS等核心业务,其安全合规性直接关系患者隐私与公共健康。等保三级要求系统具备完善的身份鉴别、访问控制、安全审计、入侵防范及可…...

Flash内容重生:CefFlashBrowser如何让经典Flash游戏与课件重获新生
Flash内容重生:CefFlashBrowser如何让经典Flash游戏与课件重获新生 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 你是否还在怀念那些曾经风靡一时的Flash游戏?是…...

AI-AGENT概念解析 - LLM领域训练
**问题:对于LLM大模型的应用来说,不同的专业需要不同的大模型去进行相应的专业训练吗?同时,不同的大模型训练为不同的专业,那同一个大模型可以为不同的专业进行训练吗?如果可以,那是怎么训练的&…...

2024年TVBOX源接口终极整理:手把手教你如何筛选稳定高速线路
2024年TVBOX源接口高效筛选与优化指南 在流媒体内容消费日益普及的今天,TVBOX作为一款开源播放器解决方案,凭借其强大的扩展性和丰富的资源获取能力,赢得了众多技术爱好者的青睐。然而,面对网络上浩如烟海的源接口资源,…...

3分钟掌握医学文献关键信息:本草模型如何从肝癌研究中提取核心知识
3分钟掌握医学文献关键信息:本草模型如何从肝癌研究中提取核心知识 【免费下载链接】Huatuo-Llama-Med-Chinese Repo for BenTsao [original name: HuaTuo (华驼)], Instruction-tuning Large Language Models with Chinese Medical Knowledge. 本草(原名…...

SAM 3图文对话式分割:‘红色书包’‘戴眼镜的人’等自然语言识别案例
SAM 3图文对话式分割:‘红色书包’‘戴眼镜的人’等自然语言识别案例 1. 引言:让AI看懂你的图片 你有没有遇到过这样的情况?看到一张照片,想找出里面某个特定的人或物体,但手动圈选太麻烦,特别是当图片中…...