医学数据分析实训 项目九 糖尿病风险预测
文章目录
- 综合实践二 糖尿病遗传风险预测
- 一、分析目标
- 二、实现步骤
- 三、数据准备
- 四、特征工程
- 五、模型构建
- 六、性能度量
- 七、提交要求
- 综合实践任务二 糖尿病遗传风险预测代码
- (一)数据准备
- (二)特征工程
- (三)模型构建
- (四)性能度量
综合实践二 糖尿病遗传风险预测
本实践项目的数据集包含“train.csv”和“test.csv”两部分,部分特征名已经做了脱敏处理。训练集中包含年龄、性别、各项体检指标及目标血糖值。测试集相对于训练集缺少了对应的血糖值。训练集中包含 42个数据特征,其中 37 个为医学指标特征,数据集中的第一行为特征名称,其余每行代表一个个体。部分特征内容在部分人群中有缺失。
请将以上体检数据集进行预处理,并在处理后的数据集的基础上,结合交叉验证,运用一种基于决策树算法的梯度提升框架的 LightGBM 算法对训练集进行训练,建立预测模型,实现血糖预测功能。
一、分析目标
结合体检数据集,实现以下分析目标:
- 以血糖值为目标建立模型,实现血糖预测功能;
- 预测糖尿病遗传风险并对预测结果进行分析;
二、实现步骤
- 对数据集“train.csv”和“test.csv”中的数据进行数据探索、数据清洗、特征工程等操作;
- 结合交叉验证和 LightGBM 算法构建模型;
- 对模型结果进行分析,并进行模型评价;
三、数据准备
- 对数据集进行描述性统计分析;
- 对数据集“train.csv”和“test.csv”中的缺失值、重复值、异常值,以及格式与内容不规范的数据进行数据清洗;
- 结合数据集“train.csv”中的数据,分别绘制图形分析性别、年龄与血糖值的关系;
- 计算相关系数,得到数据集“train.csv”中每个指标与血糖值的相关系数,从而分析各特征与血糖值的相关性;
四、特征工程
- 结合统计分析结果和特征相关性,筛选数据集“train.csv”和“test.csv”中的特征;
- 将性别特征值转化为数值型数据;
- 根据年龄和血糖值之间的关系,筛选出高血糖分布的年龄段数据;
五、模型构建
- 利用 k 折交叉验证 model_selection.KFold() 将原始数据集 “train.csv” 划分为训练集和测试集两部分;
- 使用每次划分的训练集对 LightGBM 分类器进行训练,使用测试集评估 LightGBM 模型;
- 使用 LightGBM 模型预测测试集中的血糖值;
六、性能度量
- 使用多种评价指标对模型进行评价;
- 根据评价效果对模型进行优化;
- 绘制折线图分析血糖的真实值与预测值;
- 筛选出预测数据中血糖值在正常范围内(3.9~6.1 毫摩尔 / 升)的数据;
- 获得高血糖风险个体信息的数据;
七、提交要求
- 提交实现本实践任务的所有代码(可执行,非 .doc、.txt 等文本格式);
- 提交综合实践任务书(word格式),包括小组成员分工、分析目的、数据预处理、算法介绍、结果分析等内容;
- 提交预处理之后的数据集,以及所有可视化图表(命名规范,.jpg 格式);
综合实践任务二 糖尿病遗传风险预测代码
(一)数据准备
# 导入本案例所需的 Python 包;
import matplotlib.pyplot as plt# 设置显示中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
# 设置正常显示符号
plt.rcParams['axes.unicode_minus'] = False
import seaborn as sns
import pandas as pd# 读取数据集;
datatest = pd.read_csv('data/test.csv', encoding='gbk')
datatrain = pd.read_csv('data/train.csv', encoding='gbk')print(datatest.head())
print(datatrain.head())# 1. 对数据集进行描述性统计分析;# 对test数据集进行描述性统计分析
print("test数据集的描述性统计分析:")
print(datatest.describe())
print(datatest.info())
print(datatest.shape)# 对train数据集进行描述性统计分析
print("train数据集的描述性统计分析:")
print(datatrain.describe())
print(datatrain.info())
print(datatrain.shape)
发现要对性别,为数值型数据,日期格式化
#2. 对数据集“train.csv”和“test.csv”中的缺失值、重复值、异常值,以及格式与内容不规范的数据进行数据清洗;
import numpy as np
from scipy import stats# 检查缺失值
missing_train = datatrain.isnull().sum()
missing_test = datatest.isnull().sum()print("训练集中缺失值:")
print(missing_train[missing_train > 0])
print("\n测试集中缺失值:")
print(missing_test[missing_test > 0])# 处理缺失值
datatrain.dropna(inplace=True) # 删除缺失值较多的行
datatest.dropna(subset=['性别'], inplace=True) # 确保性别列不为空# 内容不规范的数据进行数据清
# 转换性别特征为数值型
datatrain['性别'] = datatrain['性别'].map({'男': 1, '女': 0})
datatest['性别'] = datatest['性别'].map({'男': 1, '女': 0})# 清洗日期列:将其转换为 datetime 格式
datatrain['体检日期'] = pd.to_datetime(datatrain['体检日期'], errors='coerce', dayfirst=True)
datatest['体检日期'] = pd.to_datetime(datatest['体检日期'], errors='coerce', dayfirst=True)# 将日期转换为时间戳(单位为秒)
datatrain['体检日期'] = (datatrain['体检日期'].astype(np.int64) // 10 ** 9) # 转换为秒
datatest['体检日期'] = (datatest['体检日期'].astype(np.int64) // 10 ** 9) # 转换为秒# 处理异常值
numeric_cols = datatrain.select_dtypes(include=[np.number]).columns
z_scores_train = stats.zscore(datatrain[numeric_cols])
abs_z_scores_train = np.abs(z_scores_train)
datatrain = datatrain[(abs_z_scores_train < 3).all(axis=1)]# 检查特征中是否有NaN
print("数据集中NaN数量:")
print(datatrain[['年龄', '血糖']].isnull().sum())# 打印前几行数据以检查
print("训练集前几行数据:")
print(datatrain[['年龄', '血糖']].head())# 保存数据
datatrain.to_csv('data/train_clean.csv', index=False)
datatest.to_csv('data/test_clean.csv', index=False)
训练集中缺失值:
*r-谷氨酰基转换酶 1406
*丙氨酸氨基转换酶 1406
*天门冬氨酸氨基转换酶 1406
*总蛋白 1406
*球蛋白 1406
*碱性磷酸酶 1406
中性粒细胞% 21
乙肝e抗体 5110
乙肝e抗原 5110
乙肝核心抗体 5110
乙肝表面抗体 5110
乙肝表面抗原 5110
低密度脂蛋白胆固醇 1395
单核细胞% 21
嗜碱细胞% 21
嗜酸细胞% 21
尿素 1572
尿酸 1572
总胆固醇 1395
淋巴细胞% 21
甘油三酯 1395
白球比例 1406
白细胞计数 21
白蛋白 1406
红细胞体积分布宽度 21
红细胞压积 21
红细胞平均体积 21
红细胞平均血红蛋白浓度 21
红细胞平均血红蛋白量 21
红细胞计数 21
肌酐 1572
血小板体积分布宽度 29
血小板平均体积 29
血小板比积 29
血小板计数 21
血红蛋白 21
高密度脂蛋白胆固醇 1395
dtype: int64测试集中缺失值:
*天门冬氨酸氨基转换酶 185
*丙氨酸氨基转换酶 185
*碱性磷酸酶 185
*r-谷氨酰基转换酶 185
*总蛋白 185
白蛋白 185
*球蛋白 185
白球比例 185
甘油三酯 176
总胆固醇 176
高密度脂蛋白胆固醇 176
低密度脂蛋白胆固醇 176
尿素 194
肌酐 194
尿酸 194
乙肝表面抗原 831
乙肝表面抗体 831
乙肝e抗原 831
乙肝e抗体 831
乙肝核心抗体 831
白细胞计数 5
红细胞计数 5
血红蛋白 5
红细胞压积 5
红细胞平均体积 5
红细胞平均血红蛋白量 5
红细胞平均血红蛋白浓度 5
红细胞体积分布宽度 5
血小板计数 5
血小板平均体积 6
血小板体积分布宽度 6
血小板比积 6
中性粒细胞% 5
淋巴细胞% 5
单核细胞% 5
嗜酸细胞% 5
嗜碱细胞% 5
dtype: int64
数据集中NaN数量:
年龄 0
血糖 0
dtype: int64
#3. 结合数据集“train.csv”中的数据,分别绘制图形分析性别、年龄与血糖的关系;
import os# 绘制性别与血糖值的关系
plt.figure(figsize=(8, 6))
sns.boxplot(x='性别', y='血糖', data=datatrain)
plt.title('性别与血糖的关系')
plt.xlabel('性别 (0: 女, 1: 男)')
plt.ylabel('血糖')
plt.xticks([0, 1], ['女', '男'])
# 保存图片
if not os.path.exists('output'):os.makedirs('output')
plt.savefig('output/性别与血糖的关系.png')
plt.show()# 绘制年龄与血糖值的关系
plt.figure(figsize=(8, 6))
sns.scatterplot(x='年龄', y='血糖', data=datatrain)
plt.title('年龄与血糖的关系')
plt.xlabel('年龄')
plt.ylabel('血糖')
plt.savefig('output/年龄与血糖的关系.png')
plt.show()

# 4. 计算相关系数,得到数据集“train.csv”中每个指标与血糖值的相关系数,从而分析各特征与血糖值的相关性;
# 计算相关系数
correlation_matrix = datatrain.corr()# 获取血糖值与其他特征的相关系数
glucose_correlation = correlation_matrix['血糖'].sort_values(ascending=False)# 打印相关系数
print("各特征与血糖的相关系数:")
print(glucose_correlation)# 可视化相关系数热图(这个可以不要,做图后,发现没有必要使用热力图)
plt.figure(figsize=(12, 10)) # 调整图形大小
sns.heatmap(correlation_matrix, annot=False, fmt='.2f', cmap='coolwarm',linewidths=0.5, linecolor='gray', cbar_kws={'shrink': 0.8})# 设置坐标轴标签的旋转角度
plt.xticks(rotation=45, ha='right', fontsize=10)
plt.yticks(fontsize=10)# 设置标题
plt.title('相关系数热图', fontsize=16)plt.tight_layout()
plt.show()
(二)特征工程
#1. 结合统计分析结果和特征相关性,筛选数据集“train.csv”和“test.csv”中的特征;
# 获取与血糖相关的特征
correlation_with_glucose = correlation_matrix['血糖'].sort_values(ascending=False)
print("与血糖的相关系数:")
print(correlation_with_glucose)
with open('output/与血糖的相关系数.txt', 'a') as f:f.write("与血糖的相关系数:\n")f.write(str(correlation_with_glucose) + "\n")# 筛选出相关系数绝对值大于某个阈值的特征
threshold = 0.1 # 可以调整
selected_features = correlation_with_glucose[abs(correlation_with_glucose) > threshold].index.tolist()# 确保血糖是最后一个特征
if '血糖' in selected_features:selected_features.remove('血糖')
selected_features.append('血糖')
print(f"选择的特征: {selected_features}")# 筛选训练集和测试集的特征
X_train = datatrain[selected_features]
X_test = datatest[selected_features[:-1]] # 不包括目标变量# 打印选择的特征集信息
print("筛选后的训练集特征:")
print(X_train.head())
print("\n筛选后的测试集特征:")
print(X_test.head())#2. 将性别特征值转化为数值型数据;
# 已经转化为数值型数据,只需要查看转换后的性别数据
print("\n训练集中性别特征转化后的数据:")
print(datatrain[selected_features][['性别']].head())print("\n测试集中性别特征转化后的数据:")
print(datatrain[selected_features][['性别']].head())
#3. 根据年龄和血糖之间的关系,筛选出高血糖分布的年龄段数据;
# 定义高血糖标准
high_glucose_threshold = 6.1 # 血糖值大于 6.1 mmol/L 视为高血糖# 筛选高血糖分布的年龄段数据
high_glucose_data = datatrain[datatrain['血糖'] > high_glucose_threshold]# 打印高血糖数据及其年龄
print("高血糖记录的年龄段数据:")
print(high_glucose_data[['年龄', '血糖']])# 分析年龄分布,可以绘制直方图
# 绘制高血糖年龄分布图
plt.figure(figsize=(10, 6))# 折线图和直方图分开设置颜色和透明度
sns.histplot(high_glucose_data['年龄'], bins=10, kde=True, color='skyblue', alpha=0.5)plt.title('高血糖分布的年龄段', fontsize=14)
plt.xlabel('年龄', fontsize=12)
plt.ylabel('频率', fontsize=12)# 显示网格
plt.grid(True, linestyle='--', alpha=0.6)
plt.savefig('output/高血糖分布的年龄段.png')plt.show()
(三)模型构建
- 利用 k 折交叉验证 model_selection.KFold()将原始数据集“train.csv”划分为训练集和测试集两部分;
- 使用每次划分的训练集对 LightGBM 分类器进行训练,使用测试集评估LightGBM 模型;
- 使用 LightGBM 模型预测测试集中的血糖值;
from sklearn.model_selection import KFold
import lightgbm as lgb
from sklearn.metrics import mean_squared_error, r2_score
# 设置参数
n_splits = 5 # k 折交叉验证的折数
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
# 准备特征和目标变量
X = X_train.drop(columns=['血糖']) # 不包括目标变量 血糖
y = X_train['血糖']# 初始化 LightGBM 模型
model = lgb.LGBMRegressor()
# 存储每次交叉验证的结果
results = []
# 进行 k 折交叉验证
for train_index, test_index in kf.split(X):X_train_cv, X_test_cv = X.iloc[train_index], X.iloc[test_index]y_train_cv, y_test_cv = y.iloc[train_index], y.iloc[test_index]# 训练模型model.fit(X_train_cv, y_train_cv)# 预测y_pred = model.predict(X_test_cv)# 计算评价指标mse = mean_squared_error(y_test_cv, y_pred)r2 = r2_score(y_test_cv, y_pred)results.append((mse, r2))
# 输出平均结果
average_mse = np.mean([result[0] for result in results])
average_r2 = np.mean([result[1] for result in results])
print(f"平均均方误差: {average_mse:.4f}")
print(f"平均 R^2 值: {average_r2:.4f}")# 使用训练好的模型预测测试集
predictions = model.predict(X_test)# 将预测结果保存
datatest['预测血糖'] = predictions
datatest.to_csv('结果分析/LightGBM模型预测测试集中的血糖值.csv', index=False)
平均均方误差: 0.7351
平均 R^2 值: 0.1289
模型训练的结果显示平均均方误差为0.7351,而平均R²值为0.1289。这表明模型的性能并不理想,R²值接近于0,意味着模型对数据的解释能力较弱。
(四)性能度量
1.使用多种评价指标对模型进行评价;
2.根据评价效果对模型进行优化;
3.绘制折线图分析血糖的真实值与预测值;
4.筛选出预测数据中血糖值在正常范围内(3.9~6.1 毫摩尔/升)的数据;
5.获得高血糖风险个体信息的数据;
# 1. 使用多种评价指标对模型进行评价# 导入必要的库
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import matplotlib.pyplot as plt
import seaborn as sns# 1. 使用多种评价指标对模型进行评价
print(f"平均均方误差: {average_mse:.4f}")
print(f"平均 R^2 值: {average_r2:.4f}")平均均方误差: 0.7351
平均 R^2 值: 0.1289
结果很差,没必要优化了,这个项目写的不好
# 3. 绘制折线图分析血糖的真实值与预测值
plt.figure(figsize=(10, 6))
plt.plot(y_test_cv.values, label='真实值', marker='o')
plt.plot(y_pred, label='预测值', marker='x')
plt.title('真实值与预测值对比')
plt.xlabel('样本')
plt.ylabel('血糖值')
plt.legend()
plt.grid(True)
plt.savefig('结果分析/真实值与预测值对比.png')
plt.show()

# 4. 筛选出预测数据中血糖值在正常范围内的数据
normal_glucose_data = datatest[(datatest['预测血糖'] >= 3.9) & (datatest['预测血糖'] <= 6.1)]
print("正常血糖范围内的预测数据:")
print(normal_glucose_data[['id', '预测血糖']])# 5. 获得高血糖风险个体信息的数据
high_risk_data = datatest[datatest['预测血糖'] > 6.1]
print("高血糖风险个体的信息:")
print(high_risk_data[['id', '预测血糖']])
相关文章:
医学数据分析实训 项目九 糖尿病风险预测
文章目录 综合实践二 糖尿病遗传风险预测一、分析目标二、实现步骤三、数据准备四、特征工程五、模型构建六、性能度量七、提交要求 综合实践任务二 糖尿病遗传风险预测代码(一)数据准备(二)特征工程(三)模…...

C语言-文件操作-一些我想到的、见到的奇怪的问题
博客主页:【夜泉_ly】 本文专栏:【C语言】 欢迎点赞👍收藏⭐关注❤️ C语言-文件操作-一些我想到的、见到的奇怪的问题 前言1.在不关闭文件的情况下,连续多次调用 fopen() 打开同一个文件,会发生什么?1.1过…...

变电站设备检测系统源码分享
变电站设备检测检测系统源码分享 [一条龙教学YOLOV8标注好的数据集一键训练_70全套改进创新点发刊_Web前端展示] 1.研究背景与意义 项目参考AAAI Association for the Advancement of Artificial Intelligence 项目来源AACV Association for the Advancement of Computer V…...

电机foc线上课程开课啦
凌鸥学园电机控制学习盛宴,诚邀您的加入 🎓免费学习,荣誉加冕 凌鸥学园提供免费的电机控制课程,从基础到专业,全程无负担。 📚全面课程体系,灵活学习模式 凌鸥学园提供从基础到专业的全面课程…...

解决Mac 默认设置 wps不能双面打印的问题
目录 问题描述: 问题解决: 问题描述: 使用mac电脑的时候,发现wps找不到双面打印的按钮,导致使用wps打开的所有文件都不能自动双面打印 问题解决: mac的wps也是有双面打印的选项,只是默认被关…...
智谱清影 - CogVideoX-2b-部署与使用
🍑个人主页:Jupiter. 🚀 所属专栏:Linux从入门到进阶 欢迎大家点赞收藏评论😊 目录 体验地址:[丹摩DAMODEL官网](https://www.damodel.com/console/overview) CogVideoX 简介本篇将详细介绍使用丹摩服务器部…...

python queue.Queue介绍
queue.Queue 是 Python 中的线程安全队列,适合用于多线程或多进程环境中进行任务和数据的共享。queue.Queue 提供了 FIFO(先进先出)队列的实现,并包含线程锁机制以保证在多线程环境下数据的安全性。 queue.Queue 的主要方法&…...

Qt 每日面试题 -3
21、static和const的使用 static : 静态变量声明,分为局部静态变量,全局静态变量,类静态成员变量。也可修饰类成员函数。 有以下几类∶ 局部静态变量 : 存储在静态存储区,程序运行期间只被初始化一次,作用域仍然为局部…...

TypeScript系列:第四篇 - typeof 与 keyof
在 TypeScript系列:第三篇 - 泛型 有提及 keyof 的使用。 本文将详细介绍 keyof 和 typeof 运算符的基本概念、应用场景以及如何结合使用它们来提高代码的类型安全性。 #mermaid-svg-bnMG6PMTxMI4iafc {font-family:"trebuchet ms",verdana,arial,sans-se…...

JDK8新增特性(值得收藏)
1.Lamdba表达式 就相当于要使用接口Lock就不需要再创建一个类去实现接口了,直接用Lambda表达式省略了在创建的那个类。 Lamdba表达式是什么? “->”,Lambda操作符或箭 头操作符,它将Lambda表达式分割为两部分。 左边:指Lam…...
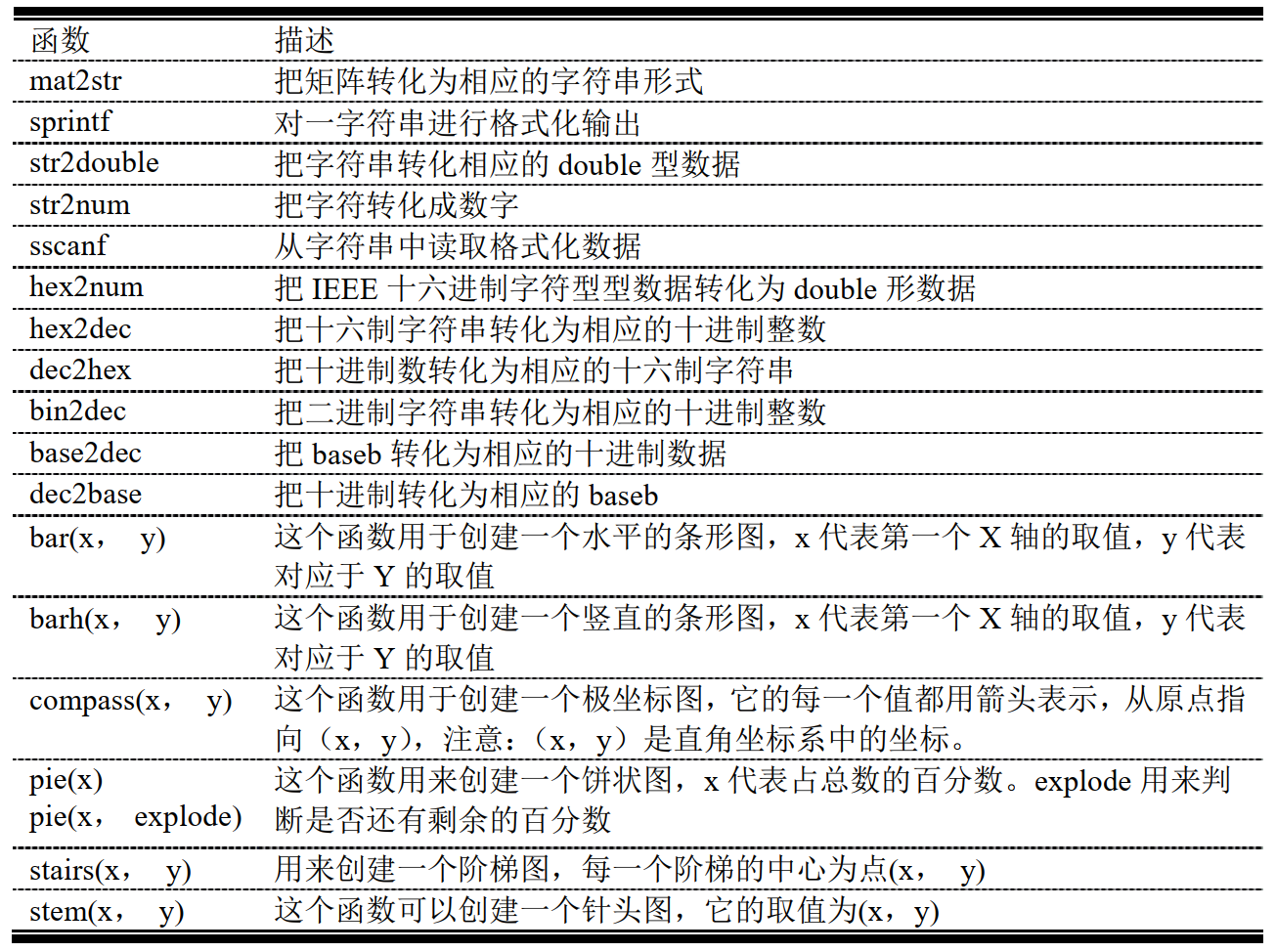
MATLAB系列06:复数数据、字符数据和附加画图类
MATLAB系列06:复数数据、字符数据和附加画图类 6. 复数数据、字符数据和附加画图类6.1 复数数据6.1.1 复变量( complex variables)6.1.2 带有关系运算符的复数的应用6.1.3 复函数( complex function)6.1.4 复数数据的作…...

【永磁同步电机(PMSM)】 4. 同步旋转坐标系仿真模型
【永磁同步电机(PMSM)】 4. 同步旋转坐标系仿真模型 1. Clarke 变换的模型与仿真1.1 Clarke 变换1.2 Clarke 变换的仿真模型 2. Park 变换的模型与仿真2.1 Park 变换2.2 Park 变换的仿真模型 3. Simscape标准库变换模块3.1 abc to Alpha-Beta-Zero 模块3…...

CSAPP Attack Lab
个人感觉非常有意思的一个 Lab,涉及的知识面比较窄,主要关注 缓冲区溢出漏洞 这一个方面,并基于此进行代码攻击,体验一把做黑客的感觉,对应知识点为书中的 3.10 节内容。 这个 Lab 上手便给了我当头一棒,在…...

通信工程学习:什么是NFVI网络功能虚拟化基础设施层
NFVI:网络功能虚拟化基础设施层 NFVI(Network Functions Virtualization Infrastructure)即网络功能虚拟化基础设施层,是NFV(Network Functions Virtualization,网络功能虚拟化)架构中的一个重要…...

不在同一局域网怎么远程桌面?非局域网环境下,实现远程桌面访问的5个方法分享!
非局域网环境下,怎么远程桌面?还能做到吗? 在企业管理中,远程桌面访问已成为提高工作效率、实现跨地域协同工作的关键工具。 然而,当被控端与控制端不在同一局域网时,如何实现远程桌面连接成为了许多企业…...

SparkSQL-初识
一、概览 Spark SQL and DataFrames - Spark 3.5.2 Documentation 我们先看下官网的描述: SparkSQL是用于结构化数据处理的Spark模块,与基本的Spark RDD API不同。Spark SQL提供的接口为Spark提供了更多关于正在执行的数据和计算结构的信息。在内部&a…...
机制的迭代和优化历史)
Go语言的垃圾回收(GC)机制的迭代和优化历史
Go语言的垃圾回收(GC)机制自Go语言发布以来经历了多次重要的迭代和优化,以提高性能和减少程序运行时的停顿时间。 以下是一些关键的版本和相应的GC优化: Go版本GC耗时情况主要改进点Go 1.0-1.4可能达到几百毫秒至秒级使用简单的标…...

thinkphp8 从入门到放弃(后面会完善用到哪里写到哪)
thinkphp8 从入门到放弃 引言 thinkphp* 大道至简一、 thinkphp8 安装安装Composerthinkphp 安装命令(tp-项目名称)多应用安装(一个项目不会只有一个应用)安装完文件目录如下本地部署配置伪静态好了项目可以run 二、架构服务(Service…...
对于电商跨境电商独立站中源代码建站和SaaS建站的区别
电商跨境电商独立站的搭建有多种方式,作为电商企业,搭建完全自主控制的电商独立站,对于电商企业的发展和运营有着至关重要的作用。下面推荐一个使用多年的跨境电商独立站系统源码,做简要介绍,据说前段时间火爆的Pandab…...
使用vite+react+ts+Ant Design开发后台管理项目(二)
前言 本文将引导开发者从零基础开始,运用vite、react、react-router、react-redux、Ant Design、less、tailwindcss、axios等前沿技术栈,构建一个高效、响应式的后台管理系统。通过详细的步骤和实践指导,文章旨在为开发者揭示如何利用这些技术…...

CoPaw:让AI代码助手深度适配个人项目与团队规范的工程化实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫CoPaw,作者是 alexgzx。光看名字可能有点摸不着头脑,但如果你对 AI 辅助编程、代码生成或者想提升自己的开发效率感兴趣,那这个项目绝对值得你花时间研究一下。简单来说…...

Agent OS:AI智能体开发的操作系统级解决方案
1. 项目概述:一个为AI智能体而生的操作系统最近在AI智能体开发圈子里,一个名为“Agent OS”的项目热度持续攀升。它来自Rivet.dev团队,定位非常清晰:一个专为构建、运行和管理AI智能体而设计的操作系统。如果你正在尝试将大语言模…...

DaVinci Developer与Configurator Pro联调指南:如何高效设计SWC并集成到ECU工程
DaVinci Developer与Configurator Pro联调实战:从SWC设计到ECU集成的全流程解析 在汽车电子控制单元(ECU)开发领域,工具链的协同效率直接决定了项目进度和质量。作为Vector公司AUTOSAR工具链的核心组件,DaVinci Develo…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

如何快速突破平台限制:跨平台Steam创意工坊模组下载终极指南
如何快速突破平台限制:跨平台Steam创意工坊模组下载终极指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼…...

QKeyMapper深度解析:现代输入设备管理系统的架构揭秘与实战指南
QKeyMapper深度解析:现代输入设备管理系统的架构揭秘与实战指南 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠&a…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

Arm CoreLink PCK-600电源管理架构与寄存器编程详解
1. Arm CoreLink PCK-600电源控制架构解析在嵌入式系统设计中,电源管理单元(PMU)是实现高效能耗控制的核心组件。Arm CoreLink PCK-600作为业界领先的电源控制解决方案,其架构设计体现了现代SoC电源管理的先进理念。PCK-600系列采…...

Arm Morello平台模型与CHERI安全扩展开发指南
1. Arm Morello平台模型概述Morello是Arm公司推出的实验性处理器架构,基于CHERI(Capability Hardware Enhanced RISC Instructions)安全扩展技术。这个平台模型本质上是一个功能准确的虚拟硬件环境,允许开发者在物理芯片问世前18-…...
)
【限时解密】Midjourney未公开的Tea印相冷启动协议:如何绕过默认sampler干扰,直触胶片模拟内核(仅剩37位开发者掌握)
更多请点击: https://intelliparadigm.com 第一章:Midjourney Tea印相冷启动协议的起源与本质 Midjourney Tea印相冷启动协议(Tea-Init Protocol)并非官方标准,而是由东亚AI艺术协作社区在2023年自发演化出的一套轻量…...