PostgreSQL - pgvector 插件构建向量数据库并进行相似度查询
在现代的机器学习和人工智能应用中,向量相似度检索是一个非常重要的技术,尤其是在文本、图像或其他类型的嵌入向量的操作中。本文将介绍如何在 PostgreSQL 中安装 pgvector 插件,用于存储和检索向量数据,并展示如何通过 Python 脚本向数据库插入向量并执行相似度查询。
一、安装 PostgreSQL 并配置 pgvector 插件
1. 安装 PostgreSQL
首先,确保你已经安装了 PostgreSQL。可以通过 Docker 快速安装 PostgreSQL。
docker pull postgres
docker run --name my_postgres -e POSTGRES_PASSWORD=mysecretpassword -e POSTGRES_USER=myuser -e POSTGRES_DB=mydb -p 5432:5432 -d postgres
上述命令会启动一个名为 my_postgres 的容器,并暴露 5432 端口以便外部连接。
2. 安装 pgvector 插件
pgvector 插件可以让你在 PostgreSQL 中存储向量,并支持高效的向量相似度查询。通过以下步骤安装 pgvector:
进入 PostgreSQL 容器后,执行以下命令:
docker exec -it my_postgres bash
apt update
apt install -y postgresql-server-dev-all make gcc
git clone https://github.com/pgvector/pgvector.git
cd pgvector
make
make install
3. 创建数据库并启用 pgvector 插件
进入 PostgreSQL 终端,创建一个数据库并启用 pgvector 插件:
psql -U myuser -d mydb
在 PostgreSQL 终端中执行:
CREATE EXTENSION vector;
这样我们就可以使用 pgvector 插件来存储和检索向量了。
二、创建向量表
接下来,我们需要创建一个用于存储向量的表。假设我们有一个名为 knowledge.vector_data 的表,它将存储用户 ID、文件 ID、文本内容以及对应的向量。
-- 创建 schema
CREATE SCHEMA knowledge;-- 创建 vector_data 表
CREATE TABLE knowledge.vector_data (id SERIAL PRIMARY KEY, -- 自动递增的主键user_id BIGINT NOT NULL DEFAULT 0,file_id BIGINT NOT NULL DEFAULT 0,content VARCHAR(65535) NOT NULL DEFAULT '', -- 存储文本内容featrue VECTOR(1024), -- 存储1024维向量created TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);-- 创建 HNSW 索引并指定操作符类 (例如,使用余弦相似度)
CREATE INDEX ON knowledge.vector_data USING hnsw (featrue vector_cosine_ops);
这个表将存储文本内容及其对应的 1024 维向量。我们选择 1024 维是因为一些嵌入模型生成的向量维度较高。如果你的向量维度不同,可以调整此值。
三、Python 测试程序:向量化并插入数据库
接下来,我们将编写一个 Python 脚本,将一些测试句子向量化后插入数据库,并进行相似度查询。
1. 安装所需 Python 库
首先,你需要安装 sentence-transformers 库来进行句子的向量化处理,并使用 psycopg2 连接 PostgreSQL:
pip install sentence-transformers psycopg2 numpy
2. 完整的 Python 脚本
以下是完整的 Python 脚本,它可以将测试语句向量化后插入 PostgreSQL 数据库,然后执行相似度查询并返回相似的句子及其相似度评分:
import psycopg2
from sentence_transformers import SentenceTransformer
import numpy as np# 数据库连接信息
DB_HOST = "localhost"
DB_PORT = "5432"
DB_NAME = "mydb"
DB_USER = "myuser"
DB_PASSWORD = "mysecretpassword"# 连接 PostgreSQL 数据库
def connect_db():conn = psycopg2.connect(host=DB_HOST,port=DB_PORT,dbname=DB_NAME,user=DB_USER,password=DB_PASSWORD)return conn# 向量化函数,并将向量扩展到 1024 维
def vectorize_sentences(sentences, target_dim=1024):# 使用预训练模型 "all-MiniLM-L6-v2" 向量化句子model = SentenceTransformer('all-MiniLM-L6-v2')sentence_vectors = model.encode(sentences)# 将 384 维向量扩展到 1024 维,使用 0 进行填充padded_vectors = [np.pad(vector, (0, target_dim - len(vector)), 'constant') for vector in sentence_vectors]return padded_vectors# 将向量插入数据库
def insert_vectors_to_db(sentences, vectors):conn = connect_db()cursor = conn.cursor()# 将句子和其对应的向量插入表中for sentence, vector in zip(sentences, vectors):sql = """INSERT INTO knowledge.vector_data (user_id, file_id, content, featrue)VALUES (%s, %s, %s, %s)"""cursor.execute(sql, (1, 1, sentence, vector.tolist())) # 假设 user_id 和 file_id 为 1print(f"Inserted sentence: {sentence}")conn.commit()cursor.close()conn.close()# 查询最相似的句子
def query_similar_sentences(target_vector):conn = connect_db()cursor = conn.cursor()# 转换向量为 PostgreSQL 可接受的格式vector_str = '{' + ','.join(map(str, target_vector)) + '}'# 查询相似句子sql = """SELECT content, 1 - (featrue <=> %s) AS similarityFROM knowledge.vector_dataORDER BY featrue <=> %s ASCLIMIT 5;"""cursor.execute(sql, (vector_str, vector_str))results = cursor.fetchall()for row in results:print(f"Sentence: {row[0]}, Similarity: {row[1]}")cursor.close()conn.close()if __name__ == "__main__":# 测试语句sentences = ["This is a test sentence.","Another sentence for testing.","PostgreSQL vector database integration."]# 向量化测试语句,并扩展到 1024 维vectors = vectorize_sentences(sentences, target_dim=1024)# 将向量插入数据库insert_vectors_to_db(sentences, vectors)# 目标句子,用于查询相似句子target_sentence = "This is a test sentence."# 获取目标句子的向量target_vector = vectorize_sentences([target_sentence], target_dim=1024)[0]# 查询最相似的句子query_similar_sentences(target_vector)
四、执行流程
- 向量化并插入数据库:通过
insert_vectors_to_db函数,脚本会将输入的测试语句向量化,并将其存储到 PostgreSQL 中的knowledge.vector_data表。 - 相似度查询:通过
query_similar_sentences函数,脚本会根据输入的目标句子,查询出最相似的句子,并按相似度排序返回结果。
五、结论
通过本文的步骤,你可以在 PostgreSQL 中使用 pgvector 插件存储和查询向量数据。这种方法可以用于文本、图像等数据的相似度检索。我们利用 sentence-transformers 生成句子嵌入,将其存储在 PostgreSQL 数据库中,并通过 SQL 查询高效地返回相似的句子。
使用向量数据库,可以让我们在处理大量嵌入数据时,充分发挥数据库和机器学习的结合力量,实现高效、快速的向量检索。
相关文章:

PostgreSQL - pgvector 插件构建向量数据库并进行相似度查询
在现代的机器学习和人工智能应用中,向量相似度检索是一个非常重要的技术,尤其是在文本、图像或其他类型的嵌入向量的操作中。本文将介绍如何在 PostgreSQL 中安装 pgvector 插件,用于存储和检索向量数据,并展示如何通过 Python 脚…...

UR机器人坐标系转化
UR机器人读取上来的坐标系是旋转矢量,每次都要查一下怎么转换,在这里记录以下...

【每日一题】LeetCode 2306.公司命名(位运算、数组、哈希表、字符串、枚举)
【每日一题】LeetCode 2306.公司命名(位运算、数组、哈希表、字符串、枚举) 题目描述 给定一个字符串数组 ideas,表示在公司命名过程中使用的名字列表。我们需要从 ideas 中选择两个不同的名字,称为 ideaA 和 ideaB。然后交换 i…...

240922-chromadb的基本使用
A. 背景介绍 ChromaDB 是一个较新的开源向量数据库,专为高效的嵌入存储和检索而设计。与其他向量数据库相比,ChromaDB 更加专注于轻量化、简单性和与机器学习模型的无缝集成。它的核心目标是帮助开发者轻松管理和使用高维嵌入向量,特别是与生…...

工厂模式和抽象工厂模式的实验报告
1. 实验结果: 记录并附上不同模型对象(例如:士兵、机器人、骑士)的展示效果截图。 2. 性能分析: 记录并比较抽象工厂模式与直接实例化的性能测试结果,分析它们在不同数量级对象创建时的开销与效益。 2.1…...

C标准库<string.h>-str、strn开头的函数
char *strcat(char *dest, const char *src) 函数功能 strcat 函数用于将一个字符串追加到另一个字符串的尾部。 参数解释 dest:指向目标字符串的指针,这个字符串的尾部将被追加 src 字符串的内容。src:指向源字符串的指针,其…...

Anaconda/Miniconda的删除和安装
要在 MacBook 上删除 Anaconda 或 Miniconda,并重新安装它,您可以按照以下步骤进行操作。 删除 Anaconda/Miniconda 1. 删除 Anaconda/Miniconda 文件和目录 打开 终端 并运行以下命令来删除安装目录。 对于 Anaconda,通常安装在 ~/anaconda3: rm -rf ~/anaconda3对于…...

【Harmony】轮播图特效,持续更新中。。。。
效果预览 swiper官网例子 Swiper 高度可变化 两边等长露出,跟随手指滑动 Swiper 指示器导航点位于 Swiper 下方 卡片楼层层叠一 一、官网 例子 参考代码: // xxx.ets class MyDataSource implements IDataSource {private list: number[] []cons…...

Go 并发模式:管道的妙用
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在编写程序时,我们通常不会一口气写出一个冗长的函数。相反,我们通过构建函数、结构体和方法等抽象来简化代码。这不仅有助于隐藏不重要的细节,还使我们能够专注于某一部分代码,而不必担心影响其他部分。然而…...

CAN通信详解
1、CAN介绍 1.1、什么是CAN? CAN(Controller Area Network) 即控制器局域网,是ISO国际标准化的串行通信协议。 开发目的:为了满足汽车产业的“减少线束的数量”、“通过多个LAN,进行大量数据的高速通信”…...

52 文本预处理_by《李沐:动手学深度学习v2》pytorch版
系列文章目录 例如:第一章 Python 机器学习入门之pandas的使用 文章目录 系列文章目录一、理论部分二、代码读取数据集词元化词表整合所有功能小结练习 一、理论部分 对于序列数据处理问题,我们在序列处理中评估了所需的统计工具和预测时面临的挑战。 …...

【python】字符串扩展-格式化的精度控制
字符串扩展 字符串的三种定义方式字符串拼接字符串格式化格式化的精度控制字符串格式化方式2对表达式进行格式化 学习目标 掌握格式化字符串的过程中做数字的精度控制 字符串格式化 name "小明" set_up_year 2006 stock_price 19.99 message "我是&…...

C++第一次练习
题目1 class Solution { public:bool isletter(char s){if(s<z&&s>a)return true;if(s>A&&s<Z)return true;return false;}string reverseOnlyLetters(string s) {if(s.empty()){return s;}int left,right;left0;rights.size()-1;while(left<ri…...

计算机毕业设计 基于Python的医疗预约与诊断系统 Django+Vue 前后端分离 附源码 讲解 文档
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...

JAVA基础:正则表达式,String的intern方法,StringBuilder可变字符串特点与应用,+连接字符串特点
1 String中的常用方法2 1.1 split方法 将字符串按照指定的内容进行分割,将分割成的每一个子部分组成一个数组 分割内容不会出现在数组中 实际上该方法不是按照指定的简单的符号进行分割的,而是按照正则表达式进行分割 1.2 正则表达式 用简单的符号组合…...

前端接口报错302 [已解决]
前端接口报错302 [已解决] 在前端开发中,与后端接口的交互是项目成功的关键。然而,遇到如302这样的状态码报错时,可能会让开发者感到困惑。本文将通过详细解析和多个代码案例,帮助你深入理解前端接口报错302,并提供有效…...

【网络安全】利用未授权API接口实现创建Support Ticket
未经许可,不得转载。 文章目录 正文目标为一个技术平台,客户可以通过该平台预订不同类型的服务。 正文 redacted.com 是主域,但所有流量都通过 api.redacted.com。我过去曾使用该公司预订了一些服务,因此我的帐户中有预订历史。 我对我的订单开具了 Support Ticket,此时…...

气压高度加误差的两种方法(直接添加 vs 换算到气压误差),附MATLAB程序
在已知高度真实值时,如果需要计算此高度下的气压计误差,可考虑本文所述的两种方法 气压高度 气压与高度之间的关系可以用大气压的垂直变化来描述。随着高度的增加,气压通常会下降。这是因为空气的密度在高度增加时减少,导致上方空气柱对下方空气施加的压力减小。 主要关系…...
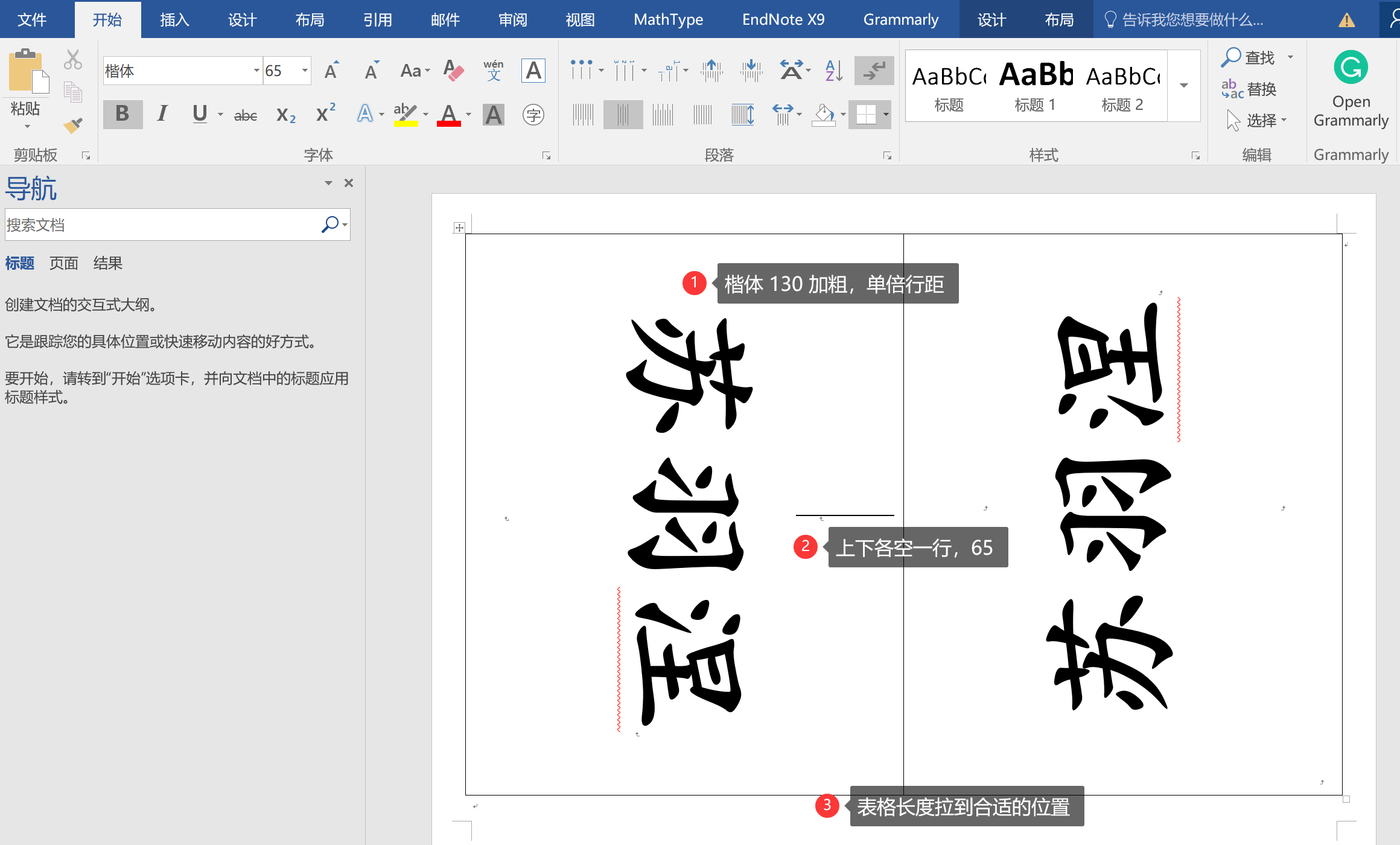
Word 制作会议名牌教程
文章目录 Part.I IntroductionPart.II 制作步骤 Part.I Introduction 本文详细介绍了如何用 Word 制作会议名牌,附有笔者制作好的一个成品(戳我下载~)。 下面是一些常识 会议名牌尺寸:100mm 180mm Part.II 制作步骤 1、新建文…...

浮动静态路由
浮动静态路由 首先我们知道静态路由的默认优先级是60,然后手动添加一条静态路由优先级为80的路由作为备份路由。当主路由失效的备份路由就会启动。 一、拓扑图 二、基本配置 1.R1: <Huawei>system-view [Huawei]sysname R1 [R1]interface GigabitEthernet…...

独立开发者如何借助Taotoken多模型能力打造全能AI助手应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken多模型能力打造全能AI助手应用 对于独立开发者或小型工作室而言,构建一个功能全面的AI助手…...
)
ElevenLabs语音合成效果翻倍的秘密(行业未公开的声学参数调优矩阵)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音合成效果翻倍的核心洞察 关键瓶颈在于语音上下文建模粒度 ElevenLabs 的高质量语音合成并非单纯依赖更大模型参数量,而是通过细粒度的语义-韵律联合编码实现自然度跃升。…...

BG3ModManager:博德之门3模组管理终极解决方案
BG3ModManager:博德之门3模组管理终极解决方案 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经为《博德之门3》的模组管理而烦…...

Performance-Fish:深度解析《环世界》400%性能优化核心技术
Performance-Fish:深度解析《环世界》400%性能优化核心技术 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish 是专为《环世界》(RimWorld&#…...

告别Python依赖!手把手教你用C++复现Librosa的Mel频谱和MFCC特征提取
高性能C音频特征提取实战:从Librosa原理到嵌入式部署优化 在语音识别和音频分析领域,Mel频谱和MFCC特征提取是基础但关键的技术环节。许多开发者习惯使用Python的Librosa库快速实现原型,但当需要部署到生产环境时,Python的解释器性…...

【避坑指南】VSCode+EIDE+Keil混合开发环境:从零搭建到项目无缝迁移
1. 为什么需要VSCodeEIDEKeil混合开发环境? 作为一名嵌入式开发者,我深知Keil这个老牌IDE在开发效率上的痛点:代码补全弱、界面老旧、多窗口管理混乱。但直接完全迁移到VSCode又面临工程兼容性问题,特别是对传统AC5编译器的支持。…...

技术视角:Sketchfab数据提取工具深度解析3D模型下载机制
技术视角:Sketchfab数据提取工具深度解析3D模型下载机制 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 在WebGL技术日益成熟的今天,Sketch…...

JetBrains IDE 30天试用重置:一键解决方案的完整实践指南
JetBrains IDE 30天试用重置:一键解决方案的完整实践指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 当您正专注于代码调试时,IDE突然弹出"评估期已结束"的红色警告…...

初创团队如何通过Taotoken的Token Plan实现成本可控的AI应用开发
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何通过Taotoken的Token Plan实现成本可控的AI应用开发 对于预算敏感的初创团队和独立开发者而言,在开发AI应…...

基于MCP与Apify构建AI驱动的投资另类数据研究工具
1. 项目概述:当投资研究遇上AI代理如果你是一名量化研究员、对冲基金分析师,或者只是一个对金融市场充满好奇、希望用数据驱动决策的独立投资者,那么你肯定对“另类数据”这个词不陌生。传统的财报、股价、宏观经济指标,这些“传统…...