MySQL常见面试总结
MySQL基础
什么是关系型数据库?
顾名思义,关系型数据库(RDB,Relational Database)就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
关系型数据库中,我们的数据都被存放在了各种表中(比如用户表),表中的每一行就存放着一条数据(比如一个用户的信息)。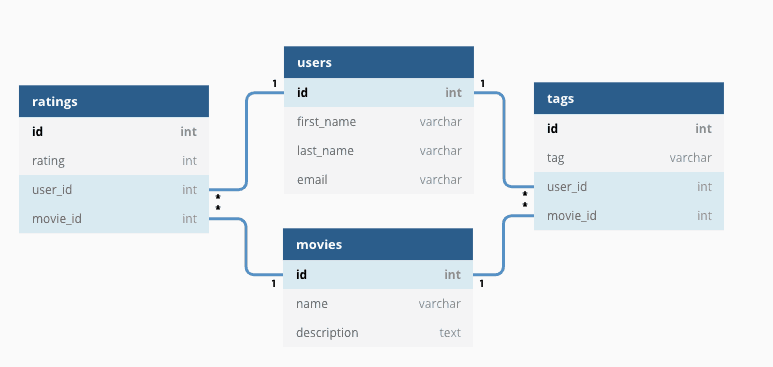
大部分关系型数据库都使用 SQL 来操作数据库中的数据。并且,大部分关系型数据库都支持事务的四大特性(ACID)。
有哪些常见的关系型数据库呢?
MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录的存储就是用的 SQLite) ……。
什么是SQL?
SQL 是一种结构化查询语言(Structured Query Language),专门用来与数据库打交道,目的是提供一种从数据库中读写数据的简单有效的方法。
几乎所有的主流关系数据库都支持 SQL ,适用性非常强。并且,一些非关系型数据库也兼容 SQL 或者使用的是类似于 SQL 的查询语言。
SQL 可以帮助我们:
- 新建数据库、数据表、字段;
- 在数据库中增加,删除,修改,查询数据;
- 新建视图、函数、存储过程;
- 对数据库中的数据进行简单的数据分析;
- 搭配 Hive,Spark SQL 做大数据;
- 搭配 SQLFlow 做机器学习;
什么是MySQL?
MySQL 是一种关系型数据库,主要用于持久化存储我们的系统中的一些数据比如用户信息。
由于 MySQL 是开源免费并且比较成熟的数据库,因此,MySQL 被大量使用在各种系统中。任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL 的默认端口号是3306。
MySQL有什么优点?
MySQL 主要具有下面这些优点:
- 成熟稳定,功能完善。
- 开源免费。
- 文档丰富,既有详细的官方文档,又有非常多优质文章可供参考学习。
- 开箱即用,操作简单,维护成本低。
- 兼容性好,支持常见的操作系统,支持多种开发语言。
- 社区活跃,生态完善。
- 事务支持优秀, InnoDB 存储引擎默认使用 REPEATABLE-READ 并不会有任何性能损失,并且,InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的。
- 支持分库分表、读写分离、高可用。
MySQL字段类型
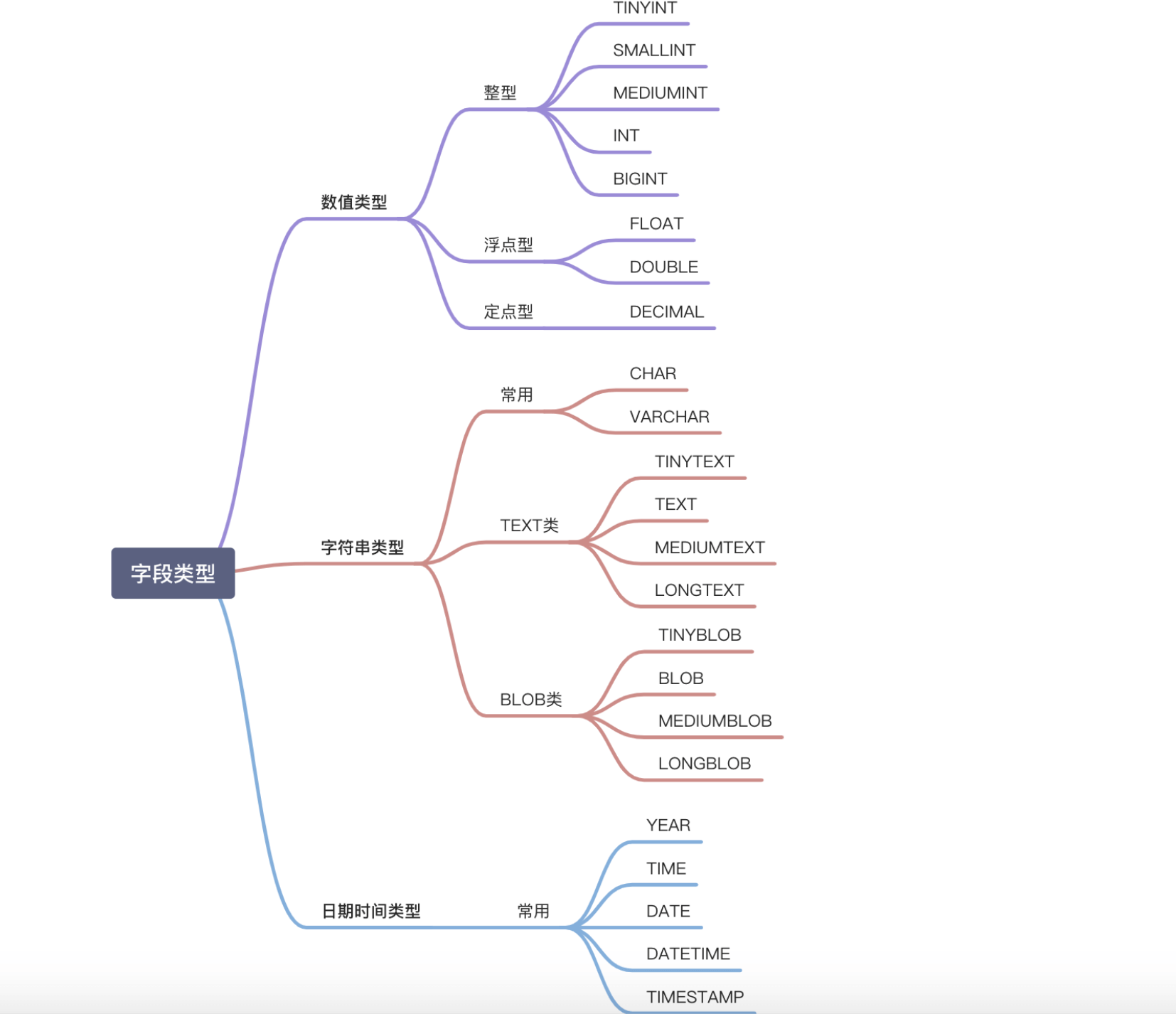
MySQL字段类型可以简单分为三大类:
- 数值类型:整型(TINYINT、SMALLINT、MEDIUMINT、INT 和 BIGINT)、浮点型(FLOAT 和 DOUBLE)、定点型(DECIMAL)
- 字符串类型:CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB 等,最常用的是 CHAR 和 VARCHAR。
- 日期时间类型:YEAR、TIME、DATE、DATETIME 和 TIMESTAMP 等。
整数类型的unsigned属性有什么用?
MySQL 中的整数类型可以使用可选的 UNSIGNED 属性来表示不允许负值的无符号整数。使用 UNSIGNED 属性可以将正整数的上限提高一倍,因为它不需要存储负数值。
例如, TINYINT UNSIGNED 类型的取值范围是 0 ~ 255,而普通的 TINYINT 类型的值范围是 -128 ~ 127。INT UNSIGNED 类型的取值范围是 0 ~ 4,294,967,295,而普通的 INT 类型的值范围是 -2,147,483,648 ~ 2,147,483,647。
对于从 0 开始递增的 ID 列,使用 UNSIGNED 属性可以非常适合,因为不允许负值并且可以拥有更大的上限范围,提供了更多的 ID 值可用。
CHAR和VARCHAR的区别是什么?
CHAR 和 VARCHAR 是最常用到的字符串类型,两者的主要区别在于:CHAR 是定长字符串,VARCHAR 是变长字符串。
CHAR 在存储时会在右边填充空格以达到指定的长度,检索时会去掉空格;VARCHAR 在存储时需要使用 1 或 2 个额外字节记录字符串的长度,检索时不需要处理。
CHAR 更适合存储长度较短或者长度都差不多的字符串,例如 Bcrypt 算法、MD5 算法加密后的密码、身份证号码。VARCHAR 类型适合存储长度不确定或者差异较大的字符串,例如用户昵称、文章标题等。
CHAR(M) 和 VARCHAR(M) 的 M 都代表能够保存的字符数的最大值,无论是字母、数字还是中文,每个都只占用一个字符。
VARCHAR(100)和VARCHAR(10)的区别是什么?
VARCHAR(100)和 VARCHAR(10)都是变长类型,表示能存储最多 100 个字符和 10 个字符。因此,VARCHAR (100) 可以满足更大范围的字符存储需求,有更好的业务拓展性。而 VARCHAR(10)存储超过 10 个字符时,就需要修改表结构才可以。
虽说 VARCHAR(100)和 VARCHAR(10)能存储的字符范围不同,但二者存储相同的字符串,所占用磁盘的存储空间其实是一样的,这也是很多人容易误解的一点。
不过,VARCHAR(100) 会消耗更多的内存。这是因为 VARCHAR 类型在内存中操作时,通常会分配固定大小的内存块来保存值,即使用字符类型中定义的长度。例如在进行排序的时候,VARCHAR(100)是按照 100 这个长度来进行的,也就会消耗更多内存。
DECIMAL和FLOAT/DOUBLE的区别是什么?
DECIMAL 和 FLOAT 的区别是:DECIMAL 是定点数,FLOAT/DOUBLE 是浮点数。DECIMAL 可以存储精确的小数值,FLOAT/DOUBLE 只能存储近似的小数值。
DECIMAL 用于存储具有精度要求的小数,例如与货币相关的数据,可以避免浮点数带来的精度损失。
在 Java 中,MySQL 的 DECIMAL 类型对应的是 Java 类 java.math.BigDecimal。
为什么不推荐使用TEXT和BLOG?
在日常开发中,很少使用 TEXT 类型,但偶尔会用到,而 BLOB 类型则基本不常用。如果预期长度范围可以通过 VARCHAR 来满足,建议避免使用 TEXT。
数据库规范通常不推荐使用 BLOB 和 TEXT 类型,这两种类型具有一些缺点和限制,例如:
- 不能有默认值。
- 在使用临时表时无法使用内存临时表,只能在磁盘上创建临时表(《高性能 MySQL》书中有提到)。
- 检索效率较低。
- 不能直接创建索引,需要指定前缀长度。
- 可能会消耗大量的网络和 IO 带宽。
- 可能导致表上的 DML 操作变慢。
DATETIME和TIMESTAMP的区别是什么?
DATETIME 类型没有时区信息,TIMESTAMP 和时区有关。
TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
- DATETIME:1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
- Timestamp:1970-01-01 00:00:01 ~ 2037-12-31 23:59:59
NULL和‘ ’的区别是什么?
NULL 跟 ''(空字符串)是两个完全不一样的值,区别如下:
NULL代表一个不确定的值,就算是两个NULL,它俩也不一定相等。例如,SELECT NULL=NULL的结果为 false,但是在我们使用DISTINCT,GROUP BY,ORDER BY时,NULL又被认为是相等的。''的长度是 0,是不占用空间的,而NULL是需要占用空间的。NULL会影响聚合函数的结果。例如,SUM、AVG、MIN、MAX等聚合函数会忽略NULL值。COUNT的处理方式取决于参数的类型。如果参数是*(COUNT(*)),则会统计所有的记录数,包括NULL值;如果参数是某个字段名(COUNT(列名)),则会忽略NULL值,只统计非空值的个数。- 查询
NULL值时,必须使用IS NULL或IS NOT NULLl来判断,而不能使用 =、!=、 <、> 之类的比较运算符。而''是可以使用这些比较运算符的。
Boolean类型如何表示?
MySQL 中没有专门的布尔类型,而是用 TINYINT(1) 类型来表示布尔值。TINYINT(1) 类型可以存储 0 或 1,分别对应 false 或 true。
MySQL基础架构
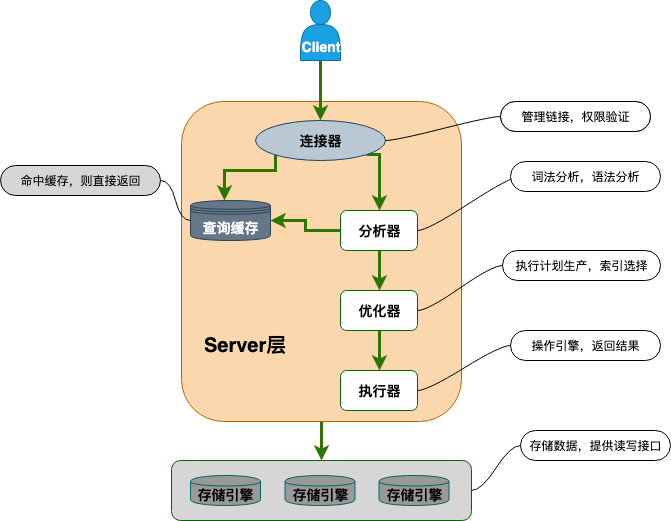
MySQL 主要由下面几部分构成:
- 连接器: 身份认证和权限相关(登录 MySQL 的时候)。
- 查询缓存: 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
- 分析器: 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
- 优化器: 按照 MySQL 认为最优的方案去执行。
- 执行器: 执行语句,然后从存储引擎返回数据。 执行语句之前会先判断是否有权限,如果没有权限的话,就会报错。
- 插件式存储引擎:主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。
MySQL存储引擎
MySQL支持哪些存储引擎?默认使用哪个?
MySQL 支持多种存储引擎,你可以通过 SHOW ENGINES 命令来查看 MySQL 支持的所有存储引擎。
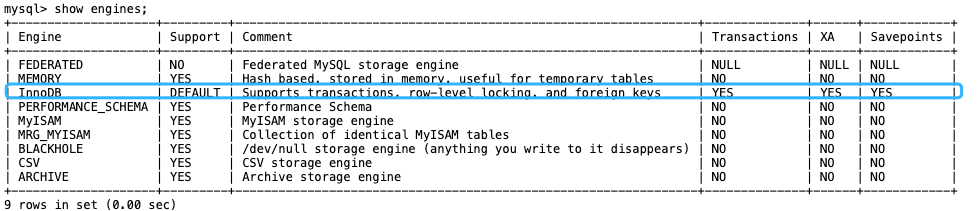 查看 MySQL 提供的所有存储引擎
查看 MySQL 提供的所有存储引擎
从上图我们可以查看出, MySQL 当前默认的存储引擎是 InnoDB。并且,所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务
MySQL 5.5.5 之前,MyISAM 是 MySQL 的默认存储引擎。5.5.5 版本之后,InnoDB 是 MySQL 的默认存储引擎。
MySQL存储引擎架构了解吗?
MySQL 存储引擎采用的是 插件式架构 ,支持多种存储引擎,我们甚至可以为不同的数据库表设置不同的存储引擎以适应不同场景的需要。存储引擎是基于表的,而不是数据库。
MyISAM和InnoDB有什么区别?
总结:
- InnoDB 支持行级别的锁粒度,MyISAM 不支持,只支持表级别的锁粒度。
- MyISAM 不提供事务支持。InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别。
- MyISAM 不支持外键,而 InnoDB 支持。
- MyISAM 不支持 MVCC,而 InnoDB 支持。
- 虽然 MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。
- MyISAM 不支持数据库异常崩溃后的安全恢复,而 InnoDB 支持。
- InnoDB 的性能比 MyISAM 更强大。
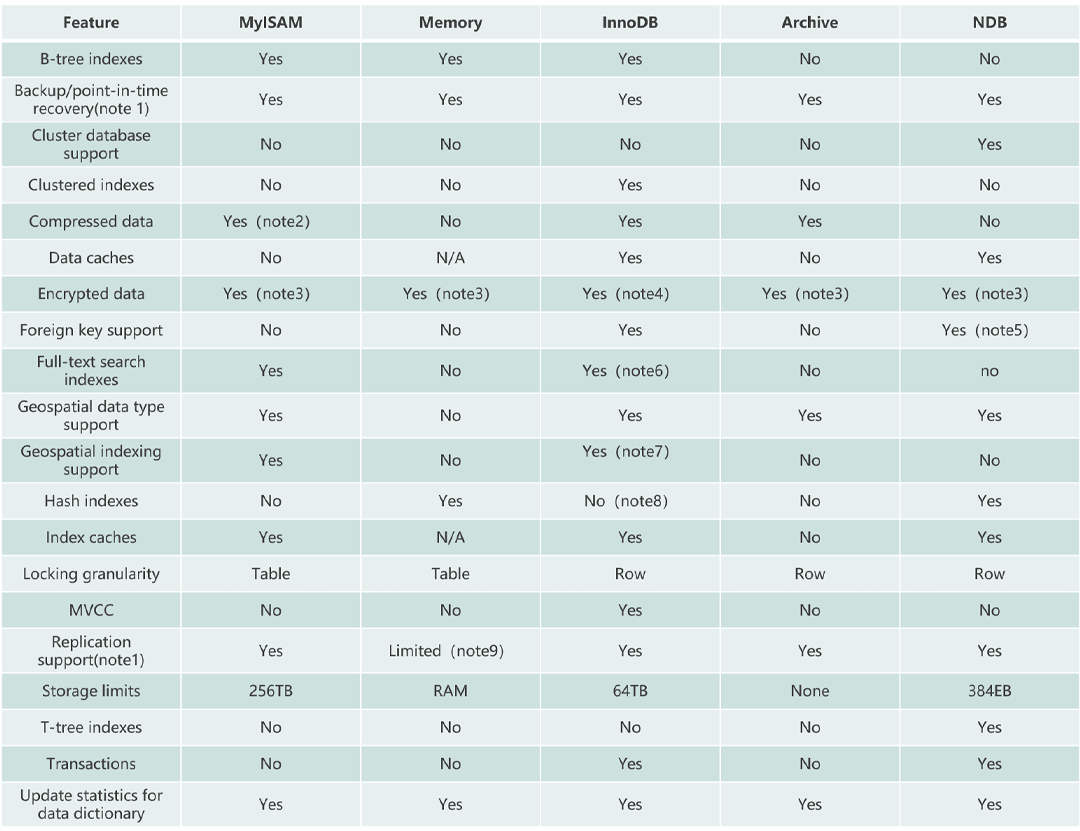
常见MySQL存储引擎对比
MyISAM和InnoDB如何选择?
大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊)。
因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由使用 MyISAM 了,老老实实用默认的 InnoDB 就可以了!
MySQL索引
内容比较多,另起了一篇文章
MySQL查询缓存
MySQL 查询缓存是查询结果缓存。执行查询语句的时候,会先查询缓存,如果缓存中有对应的查询结果,就会直接返回。
查询缓存会在同样的查询条件和数据情况下,直接返回缓存中的结果。但需要注意的是,查询缓存的匹配条件非常严格,任何细微的差异都会导致缓存无法命中。这里的查询条件包括查询语句本身、当前使用的数据库、以及其他可能影响结果的因素,如客户端协议版本号等。
查询缓存不命中的情况:
- 任何两个查询在任何字符上的不同都会导致缓存不命中。
- 如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
- 缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十 MB 比较合适。
MySQL 5.6 开始,查询缓存已默认禁用。MySQL 8.0 开始,已经不再支持查询缓存了
MySQl日志
内容比较多,另起了一篇文章
MySQL事务
何谓事务?
何为事务? 一言蔽之,事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作,这两个操作必须都成功或者都失败。
- 将小明的余额减少 1000 元
- 将小红的余额增加 1000 元。
事务会把这两个操作就可以看成逻辑上的一个整体,这个整体包含的操作要么都成功,要么都要失败。这样就不会出现小明余额减少而小红的余额却并没有增加的情况。

何谓数据库事务?
大多数情况下,我们在谈论事务的时候,如果没有特指分布式事务,往往指的就是数据库事务。
数据库事务在我们日常开发中接触的最多了。如果你的项目属于单体架构的话,你接触到的往往就是数据库事务了。
那数据库事务有什么作用呢?
简单来说,数据库事务可以保证多个对数据库的操作(也就是 SQL 语句)构成一个逻辑上的整体。构成这个逻辑上的整体的这些数据库操作遵循:要么全部执行成功,要么全部不执行 。
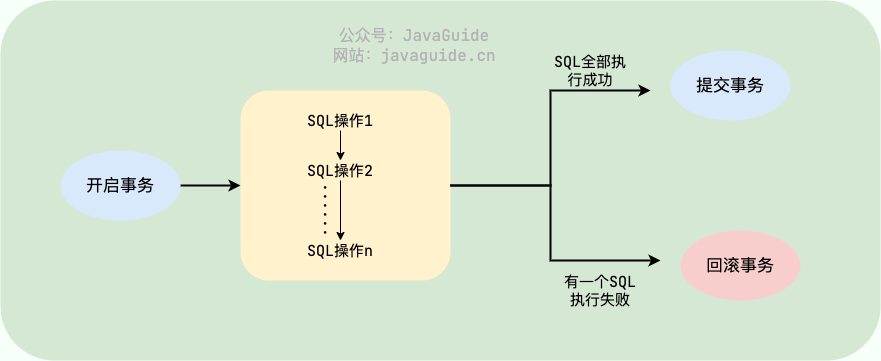
另外,关系型数据库(例如:MySQL、SQL Server、Oracle 等)事务都有 ACID 特性
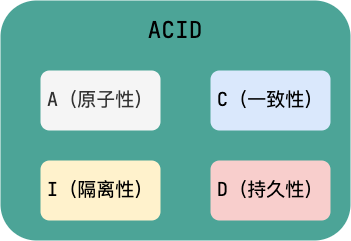
- 原子性(
Atomicity):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用; - 一致性(
Consistency):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的; - 隔离性(
Isolation):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的; - 持久性(
Durability):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
并发事务带来了哪些问题?
脏读(Dirty read)
一个事务读取数据并且对数据进行了修改,这个修改对其他事务来说是可见的,即使当前事务没有提交。这时另外一个事务读取了这个还未提交的数据,但第一个事务突然回滚,导致数据并没有被提交到数据库,那第二个事务读取到的就是脏数据,这也就是脏读的由来。
例如:事务 1 读取某表中的数据 A=20,事务 1 修改 A=A-1,事务 2 读取到 A = 19,事务 1 回滚导致对 A 的修改并未提交到数据库, A 的值还是 20。
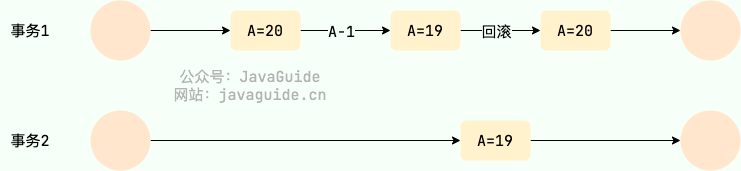
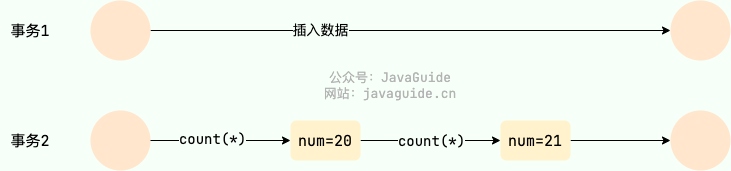
丢失修改(Lost to modify)
在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。
例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 先修改 A=A-1,事务 2 后来也修改 A=A-1,最终结果 A=19,事务 1 的修改被丢失。
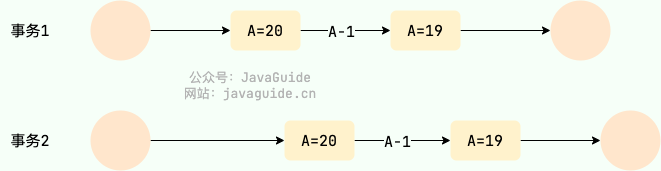
不可重复读(Unrepeatable read)
指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 修改 A=A-1,事务 2 再次读取 A =19,此时读取的结果和第一次读取的结果不同。
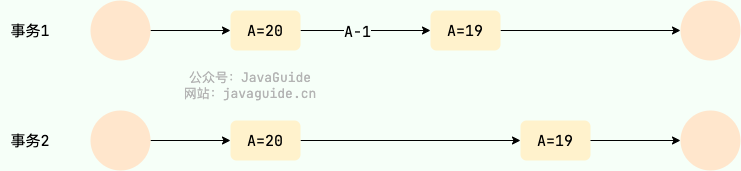
幻读(Phantom read)
幻读与不可重复读类似。它发生在一个事务读取了几行数据,接着另一个并发事务插入了一些数据时。在随后的查询中,第一个事务就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
例如:事务 2 读取某个范围的数据,事务 1 在这个范围插入了新的数据,事务 2 再次读取这个范围的数据发现相比于第一次读取的结果多了新的数据。
不可重复读和幻读有什么区别?
- 不可重复读的重点是内容修改或者记录减少比如多次读取一条记录发现其中某些记录的值被修改;
- 幻读的重点在于记录新增比如多次执行同一条查询语句(DQL)时,发现查到的记录增加了。
幻读其实可以看作是不可重复读的一种特殊情况,单独把幻读区分出来的原因主要是解决幻读和不可重复读的方案不一样。
举个例子:执行 delete 和 update 操作的时候,可以直接对记录加锁,保证事务安全。而执行 insert 操作的时候,由于记录锁(Record Lock)只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁(Gap Lock)。也就是说执行 insert 操作的时候需要依赖 Next-Key Lock(Record Lock+Gap Lock) 进行加锁来保证不出现幻读。
并发事务的控制方式有哪些?
MySQL 中并发事务的控制方式无非就两种:锁 和 MVCC。锁可以看作是悲观控制的模式,多版本并发控制(MVCC,Multiversion concurrency control)可以看作是乐观控制的模式。
锁 控制方式下会通过锁来显式控制共享资源而不是通过调度手段,MySQL 中主要是通过 读写锁 来实现并发控制。
- 共享锁(S 锁):又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
- 排他锁(X 锁):又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条记录加任何类型的锁(锁不兼容)。
读写锁可以做到读读并行,但是无法做到写读、写写并行。另外,根据根据锁粒度的不同,又被分为 表级锁(table-level locking) 和 行级锁(row-level locking) 。InnoDB 不光支持表级锁,还支持行级锁,默认为行级锁。行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类。
MVCC 是多版本并发控制方法,即对一份数据会存储多个版本,通过事务的可见性来保证事务能看到自己应该看到的版本。通常会有一个全局的版本分配器来为每一行数据设置版本号,版本号是唯一的。
MVCC 在 MySQL 中实现所依赖的手段主要是: 隐藏字段、read view、undo log。
- undo log : undo log 用于记录某行数据的多个版本的数据。
- read view 和 隐藏字段 : 用来判断当前版本数据的可见性。
SQL标准定义了哪些事务隔离级别?
SQL 标准定义了四个隔离级别:
- READ-UNCOMMITTED(读取未提交) :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交) :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读) :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化) :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | × | √ | √ |
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
MySQL的隔离级别是基于锁实现的吗?
MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
MySQL的默认隔离级别是什么?
MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)。我们可以通过SELECT @@tx_isolation;命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;
MySQL锁
锁是一种常见的并发事务的控制方式。
表级锁和行级锁了解吗?有什么区别?
MyISAM 仅仅支持表级锁(table-level locking),一锁就锁整张表,这在并发写的情况下性非常差。InnoDB 不光支持表级锁(table-level locking),还支持行级锁(row-level locking),默认为行级锁。
行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。
表级锁和行级锁对比:
- 表级锁: MySQL 中锁定粒度最大的一种锁(全局锁除外),是针对非索引字段加的锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。不过,触发锁冲突的概率最高,高并发下效率极低。表级锁和存储引擎无关,MyISAM 和 InnoDB 引擎都支持表级锁。
- 行级锁: MySQL 中锁定粒度最小的一种锁,是 针对索引字段加的锁 ,只针对当前操作的行记录进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。行级锁和存储引擎有关,是在存储引擎层面实现的。
行级锁的使用有什么注意事项?
InnoDB 的行锁是针对索引字段加的锁,表级锁是针对非索引字段加的锁。当我们执行 UPDATE、DELETE 语句时,如果 WHERE条件中字段没有命中唯一索引或者索引失效的话,就会导致扫描全表对表中的所有行记录进行加锁。这个在我们日常工作开发中经常会遇到,一定要多多注意!!!
不过,很多时候即使用了索引也有可能会走全表扫描,这是因为 MySQL 优化器的原因。
InnoDB有哪几类行锁?
InnoDB 行锁是通过对索引数据页上的记录加锁实现的,MySQL InnoDB 支持三种行锁定方式:
- 记录锁(Record Lock):也被称为记录锁,属于单个行记录上的锁。
- 间隙锁(Gap Lock):锁定一个范围,不包括记录本身。
- 临键锁(Next-Key Lock):Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题(MySQL 事务部分提到过)。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
在 InnoDB 默认的隔离级别 REPEATABLE-READ 下,行锁默认使用的是 Next-Key Lock。但是,如果操作的索引是唯一索引或主键,InnoDB 会对 Next-Key Lock 进行优化,将其降级为 Record Lock,即仅锁住索引本身,而不是范围。
共享锁和排他锁呢?
不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类:
- 共享锁(S 锁):又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
- 排他锁(X 锁):又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条事务加任何类型的锁(锁不兼容)。
排他锁与任何的锁都不兼容,共享锁仅和共享锁兼容。
| S 锁 | X 锁 | |
|---|---|---|
| S 锁 | 不冲突 | 冲突 |
| X 锁 | 冲突 | 冲突 |
意向锁有什么作用?
如果需要用到表锁的话,如何判断表中的记录没有行锁呢,一行一行遍历肯定是不行,性能太差。我们需要用到一个叫做意向锁的东东来快速判断是否可以对某个表使用表锁。
意向锁是表级锁,共有两种:
- 意向共享锁(Intention Shared Lock,IS 锁):事务有意向对表中的某些记录加共享锁(S 锁),加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(Intention Exclusive Lock,IX 锁):事务有意向对表中的某些记录加排他锁(X 锁),加排他锁之前必须先取得该表的 IX 锁。
意向锁是由数据引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InnoDB 会先获取该数据行所在在数据表的对应意向锁。
意向锁之间是互相兼容的。
| IS 锁 | IX 锁 | |
|---|---|---|
| IS 锁 | 兼容 | 兼容 |
| IX 锁 | 兼容 | 兼容 |
意向锁和共享锁和排它锁互斥(这里指的是表级别的共享锁和排他锁,意向锁不会与行级的共享锁和排他锁互斥)。
| IS 锁 | IX 锁 | |
|---|---|---|
| S 锁 | 兼容 | 互斥 |
| X 锁 | 互斥 | 互斥 |
当前读和快照读有什么区别?
快照读(一致性非锁定读)就是单纯的 SELECT 语句,但不包括下面这两类 SELECT 语句:
SELECT ... FOR UPDATE
# 共享锁 可以在 MySQL 5.7 和 MySQL 8.0 中使用
SELECT ... LOCK IN SHARE MODE;
# 共享锁 可以在 MySQL 8.0 中使用
SELECT ... FOR SHARE;
快照即记录的历史版本,每行记录可能存在多个历史版本(多版本技术)。
快照读的情况下,如果读取的记录正在执行 UPDATE/DELETE 操作,读取操作不会因此去等待记录上 X 锁的释放,而是会去读取行的一个快照。
只有在事务隔离级别 RC(读取已提交) 和 RR(可重读)下,InnoDB 才会使用一致性非锁定读:
- 在 RC 级别下,对于快照数据,一致性非锁定读总是读取被锁定行的最新一份快照数据。
- 在 RR 级别下,对于快照数据,一致性非锁定读总是读取本事务开始时的行数据版本。
快照读比较适合对于数据一致性要求不是特别高且追求极致性能的业务场景。
当前读 (一致性锁定读)就是给行记录加 X 锁或 S 锁。
当前读的一些常见 SQL 语句类型如下:
# 对读的记录加一个X锁
SELECT...FOR UPDATE
# 对读的记录加一个S锁
SELECT...LOCK IN SHARE MODE
# 对读的记录加一个S锁
SELECT...FOR SHARE
# 对修改的记录加一个X锁
INSERT...
UPDATE...
DELETE...
自增锁有了解吗?
不太重要的一个知识点,简单了解即可。
关系型数据库设计表的时候,通常会有一列作为自增主键。InnoDB 中的自增主键会涉及一种比较特殊的表级锁— 自增锁(AUTO-INC Locks) 。
更准确点来说,不仅仅是自增主键,AUTO_INCREMENT的列都会涉及到自增锁,毕竟非主键也可以设置自增长。
如果一个事务正在插入数据到有自增列的表时,会先获取自增锁,拿不到就可能会被阻塞住。这里的阻塞行为只是自增锁行为的其中一种,可以理解为自增锁就是一个接口,其具体的实现有多种。
MySQL性能优化
内容比较多,另起了一篇文章
能用MySQL直接存储文件(比如图片)吗?
可以是可以,直接存储文件对应的二进制数据即可。不过,还是建议不要在数据库中存储文件,会严重影响数据库性能,消耗过多存储空间。
可以选择使用云服务厂商提供的开箱即用的文件存储服务,成熟稳定,价格也比较低
也可以选择自建文件存储服务,实现起来也不难,基于 FastDFS、MinIO(推荐) 等开源项目就可以实现分布式文件服务。
数据库只存储文件地址信息,文件由文件存储服务负责存储。
MySQL如何存储IP地址?
可以将 IP 地址转换成整形数据存储,性能更好,占用空间也更小。
MySQL 提供了两个方法来处理 ip 地址
INET_ATON():把 ip 转为无符号整型 (4-8 位)INET_NTOA():把整型的 ip 转为地址
插入数据前,先用 INET_ATON() 把 ip 地址转为整型,显示数据时,使用 INET_NTOA() 把整型的 ip 地址转为地址显示即可。
有哪些常见的SQL优化手段
内容有点多,会另起一篇文章
如何分析SQL的性能
我们可以使用 EXPLAIN 命令来分析 SQL 的 执行计划 。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
EXPLAIN 并不会真的去执行相关的语句,而是通过 查询优化器 对语句进行分析,找出最优的查询方案,并显示对应的信息。
EXPLAIN 适用于 SELECT, DELETE, INSERT, REPLACE, 和 UPDATE语句,我们一般分析 SELECT 查询较多。
我们这里简单来演示一下 EXPLAIN 的使用。
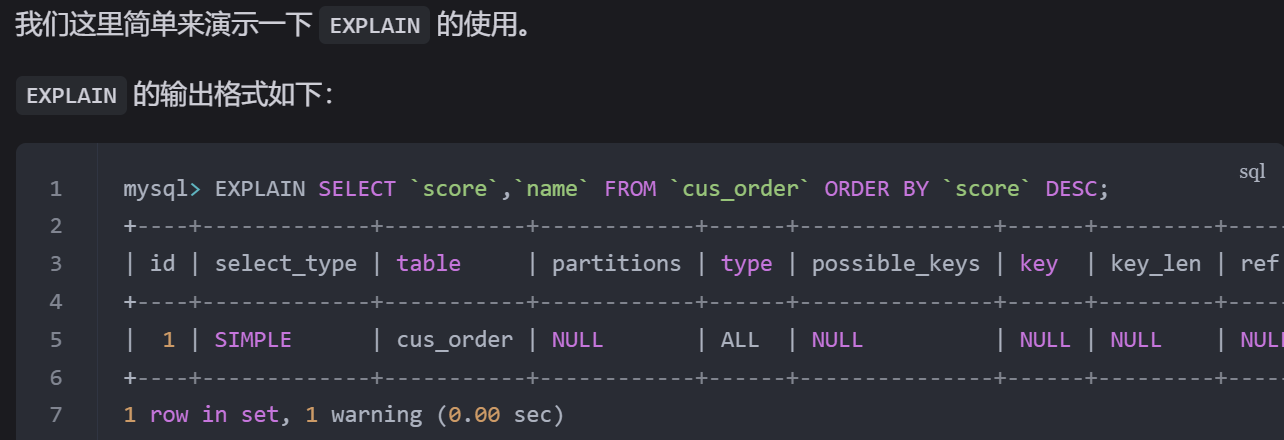
各个字段的含义如下:
| 列名 | 含义 |
|---|---|
| id | SELECT 查询的序列标识符 |
| select_type | SELECT 关键字对应的查询类型 |
| table | 用到的表名 |
| partitions | 匹配的分区,对于未分区的表,值为 NULL |
| type | 表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际用到的索引 |
| key_len | 所选索引的长度 |
| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
| rows | 预计要读取的行数 |
| filtered | 按表条件过滤后,留存的记录数的百分比 |
| Extra | 附加信息 |
读写分离和分库分表了解吗?
内容有点多,会另起一篇文章
深度分页如何优化?
内容有点多,会另起一篇文章
数据冷热分离如何做?
内容有点多,会另起一篇文章
MySQL性能怎么优化?
MySQL 性能优化是一个系统性工程,涉及多个方面,在面试中不可能面面俱到。因此,建议按照“点-线-面”的思路展开,从核心问题入手,再逐步扩展,展示出你对问题的思考深度和解决能力。
1. 抓住核心:慢 SQL 定位与分析
性能优化的第一步永远是找到瓶颈。面试时,建议先从 慢 SQL 定位和分析 入手,这不仅能展示你解决问题的思路,还能体现你对数据库性能监控的熟练掌握:
- 监控工具: 介绍常用的慢 SQL 监控工具,如 MySQL 慢查询日志、Performance Schema 等,说明你对这些工具的熟悉程度以及如何通过它们定位问题。
- EXPLAIN 命令: 详细说明
EXPLAIN命令的使用,分析查询计划、索引使用情况,可以结合实际案例展示如何解读分析结果,比如执行顺序、索引使用情况、全表扫描等。
2. 由点及面:索引、表结构和 SQL 优化
定位到慢 SQL 后,接下来就要针对具体问题进行优化。 这里可以重点介绍索引、表结构和 SQL 编写规范等方面的优化技巧:
- 索引优化: 这是 MySQL 性能优化的重点,可以介绍索引的创建原则、覆盖索引、最左前缀匹配原则等。如果能结合你项目的实际应用来说明如何选择合适的索引,会更加分一些。
- 表结构优化: 优化表结构设计,包括选择合适的字段类型、避免冗余字段、合理使用范式和反范式设计等等。
- SQL 优化: 避免使用
SELECT *、尽量使用具体字段、使用连接查询代替子查询、合理使用分页查询、批量操作等,都是 SQL 编写过程中需要注意的细节。
3. 进阶方案:架构优化
当面试官对基础优化知识比较满意时,可能会深入探讨一些架构层面的优化方案。以下是一些常见的架构优化策略:
- 读写分离: 将读操作和写操作分离到不同的数据库实例,提升数据库的并发处理能力。
- 分库分表: 将数据分散到多个数据库实例或数据表中,降低单表数据量,提升查询效率。但要权衡其带来的复杂性和维护成本,谨慎使用。
- 数据冷热分离:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在存储在低成本、低性能的介质中,热数据高性能存储介质中。
- 缓存机制: 使用 Redis 等缓存中间件,将热点数据缓存到内存中,减轻数据库压力。这个非常常用,提升效果非常明显,性价比极高!
4. 其他优化手段
除了慢 SQL 定位、索引优化和架构优化,还可以提及一些其他优化手段,展示你对 MySQL 性能调优的全面理解:
- 连接池配置: 配置合理的数据库连接池(如 连接池大小、超时时间 等),能够有效提升数据库连接的效率,避免频繁的连接开销。
- 硬件配置: 提升硬件性能也是优化的重要手段之一。使用高性能服务器、增加内存、使用 SSD 硬盘等硬件升级,都可以有效提升数据库的整体性能。
5.总结
在面试中,建议按优先级依次介绍慢 SQL 定位、索引优化、表结构设计和 SQL 优化等内容。架构层面的优化,如读写分离和分库分表、数据冷热分离 应作为最后的手段,除非在特定场景下有明显的性能瓶颈,否则不应轻易使用,因其引入的复杂性会带来额外的维护成本。
相关文章:
MySQL常见面试总结
MySQL基础 什么是关系型数据库? 顾名思义,关系型数据库(RDB,Relational Database)就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多&…...

记录一次学习--委派攻击学习
目录 为什么要使用委派 什么账号可以使用委派 非约束性委派 这里有一张图 利用 流程 约束性委派 这里有一张图 如何利用 条件 具体流程 为什么要使用委派 这个是因为可能A服务需要B服务的支持,但是A服务的权限不可以使用B服务。然后这时就可以让域用户将…...

前端列表数据太多导致页面卡顿就这么处理
前端列表数据太多页面卡顿就这么处理 实际场景什么是虚拟列表虚拟列表实现原理实战中虚拟列表的问题及相应解决方案 实际场景 首先看以下两个实际场景: 场景一:有一个数据列表,数据量非常大且每一个数据项都有几十列甚至更多,且后…...

机器学习_神经网络_深度学习
【神经网络——最易懂最清晰的一篇文章 - CSDN App】https://blog.csdn.net/illikang/article/details/82019945?type=blog&rId=82019945&refer=APP&source=weixin_45387165 参考以上资料,可对神经网络有初步了解。接下来可参考书籍等投身实际项目中使用。 书…...

MT6765/MT6762(R/D/M)/MT6761(MT8766)安卓核心板参数比较_MTK联发科4G智能模块
联发科Helio P35 MT6765安卓核心板 MediaTek Helio P35 MT6765是智能手机的主流ARM SoC,于2018年末推出。它在两个集群中集成了8个ARM Cortex-A53内核(big.LITTLE)。四个性能内核的频率高达2.3GHz。集成显卡为PowerVR GE8320,频率…...

TikTok五分钟开户快速步骤流程!
1、注册您的账户 首先,访问TikTok广告管理器的注册页面(https://ads.tiktok.com/i18n/signup/)以创建账户。您可以选择使用电子邮件或手机号码进行注册。输入您的电子邮件和密码后,您需要同意TikTok的广告条款,然后点击…...

BFS 解决拓扑排序 , 课程表 , 课程表 II , 火星词典
文章目录 拓扑排序简介1.有向无环图(DAG图)2.AOV网:顶点活动图3.拓扑排序4.实现拓扑排序 207. 课程表210. 课程表 IILCR 114. 火星词典 拓扑排序简介 1.有向无环图(DAG图) 像这样只能从一个点到另一个点有方向的图&a…...

web安全攻防渗透测试实战指南_web安全攻防渗透测试实战指南,零基础入门到精通,收藏这一篇就够了
1. Nmap的基本 Nmap ip 6 ip Nmap -A 开启操作系统识别和版本识别功能 – T(0-6档) 设置扫描的速度 一般设置T4 过快容易被发现 -v 显示信息的级别,-vv显示更详细的信息 192.168.1.1/24 扫描C段 192.168.11 -254 上 nmap -A -T4 -v -i…...

大模型如何赋能智慧城市新发展?
国家数据局近期发布的《数字中国发展报告(2023)》显示,我国数据要素市场化改革步伐进一步加快,数字经济规模持续壮大,数字技术应用场景不断拓展。这一成就的背后是数字技术广泛应用,数字技术不仅影响着老百…...

随记——机器学习
前言 本来有个500块钱的单子,用机器学习做一个不知道什么鸟的识别,正好有数据集,跑个小项目,过一下机器学习图像识别的流程,用很短的时间记录下来..... 一、数据预处理 将数据集分为训练集和测试集,直接…...
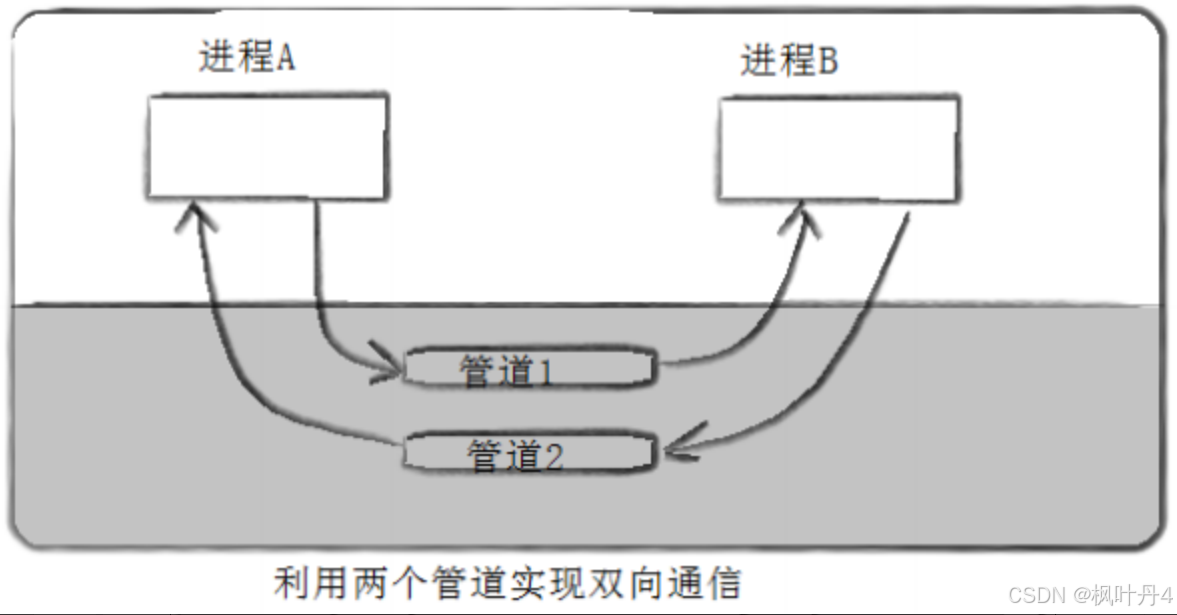
【在Linux世界中追寻伟大的One Piece】进程间通信
目录 1 -> 进程间通信介绍 1.1 -> 进程间通信目的 1.2 -> 进程间通信发展 1.3 -> 进程间通信分类 1.3.1 -> 管道 1.3.2 -> System V IPC 1.3.3 -> POSIX IPC 2 -> 管道 2.1 -> 什么是管道 2.2 -> 匿名管道 2.3 -> 实例代码 2.4 -…...
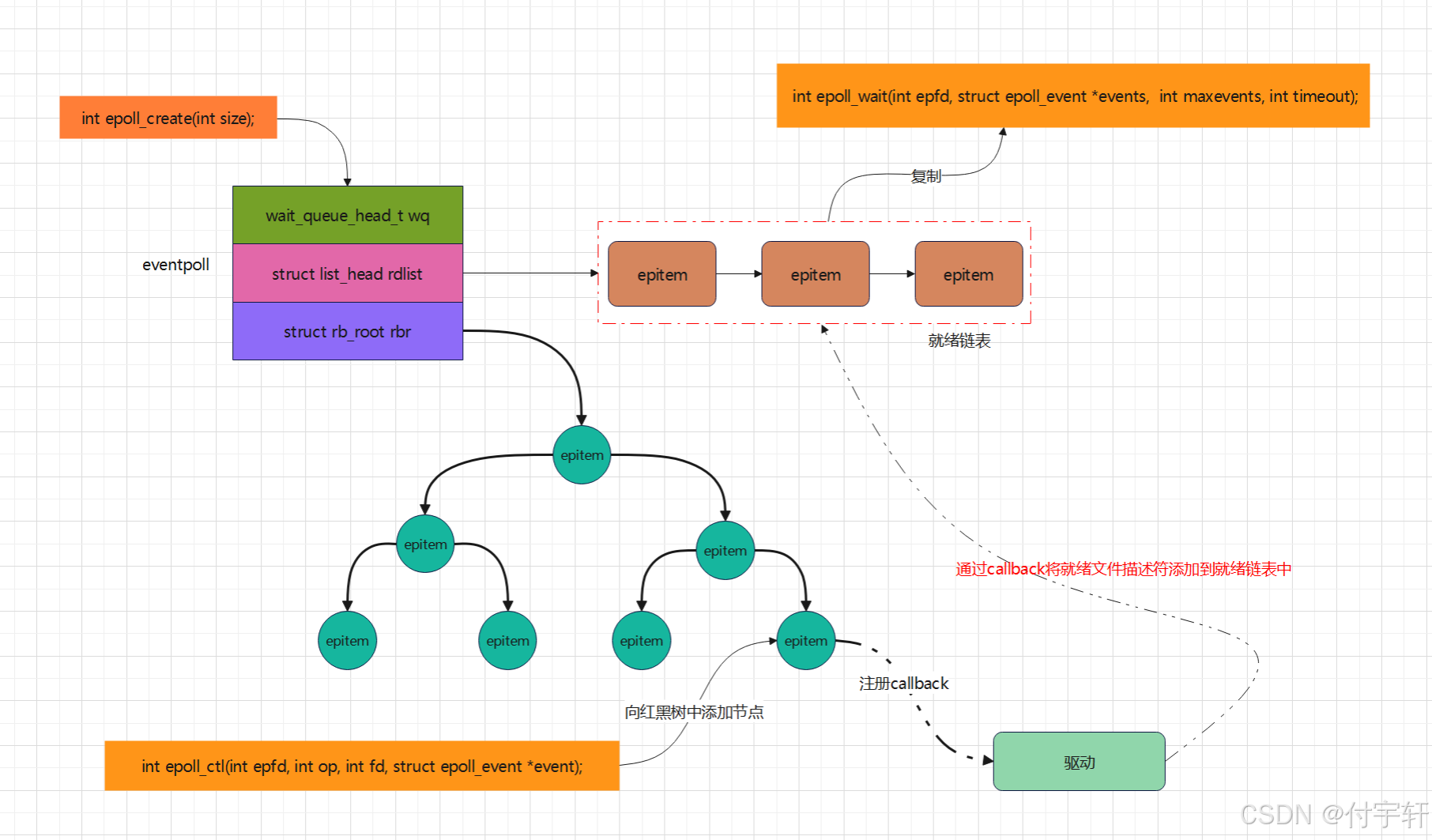
多路复用IO
一。进程处理多路IO请求 在没有多路复用IO之前,对于多路IO请求,一般只有阻塞与非阻塞IO两种方式 1.1 阻塞IO 需要结合多进程/多线程,每个进程/线程处理一路IO 缺点:客户端越多,需要创建的进程/线程越多,…...

C++ prime plus-7-編程練習
1, #include <iostream>// 函数声明 double harmonicMean(double x, double y);int main() {double x, y, result;while (true) {std::cout << "请输入两个数(其中一个为0时结束): ";std::cin >> x >> y;…...

计算1 / 1 - 1 / 2 + 1 / 3 - 1 / 4 + 1 / 5 …… + 1 / 99 - 1 / 100 的值,打印出结果
我们写这道题的时候需要俩变量接受,一个总数一个分母,我们发现分母变化是有规律的从1~100循环。 #include<stdio.h> int main() {int i 0;int tag 1;double sum 0.0;for (i 1; i < 101; i){if (i % 2 0){sum sum - 1.0 / i;}else{sum s…...
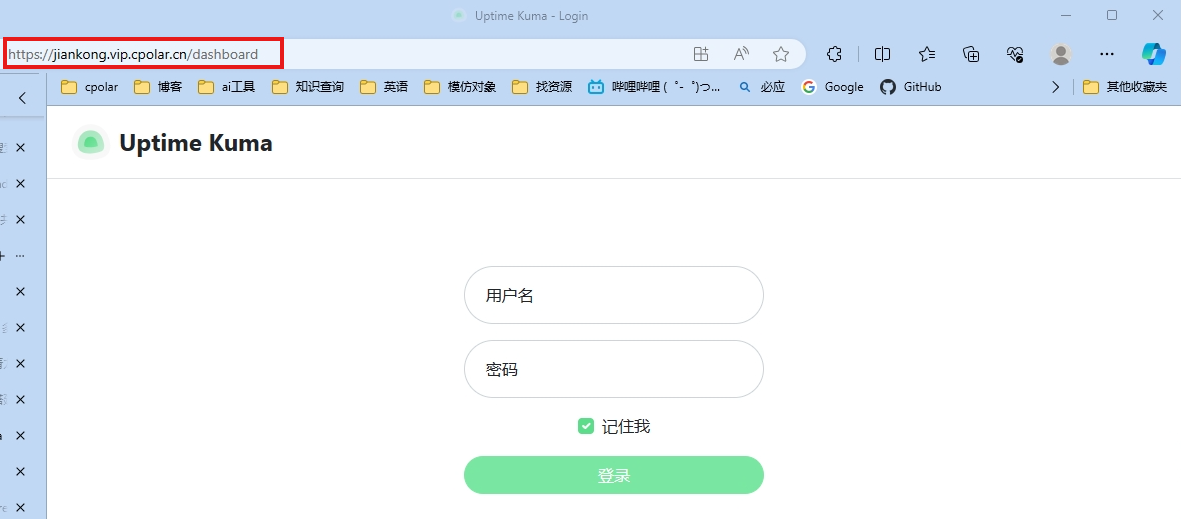
Linux本地服务器搭建开源监控服务Uptime Kuma与远程监控实战教程
文章目录 前言**主要功能**一、前期准备本教程环境为:Centos7,可以跑Docker的系统都可以使用本教程安装。本教程使用Docker部署服务,如何安装Docker详见: 二、Docker部署Uptime Kuma三、实现公网查看网站监控四、使用固定公网地址…...

JS 历史简介
目录 1. JS 历史简介 2. JS 技术特征 1. JS 历史简介 举例:在提交用户的注册信息的时候,为避免注册出现错误后重新填写信息,可以在写完一栏信息后进行校验,并提示是否出现错误,这样会大大提高用户提交的成功率&…...

爬虫逆向学习(七):补环境动态生成某数四代后缀MmEwMD
声明:本篇文章内容是整理并分享在学习网上各位大佬的优秀知识后的实战与踩坑记录 前言 这篇文章主要是研究如何动态生成后缀参数MmEwMD的,它是在文章爬虫逆向学习(六):补环境过某数四代的基础上进行研究的,代码也是在它基础上增…...

光伏电站并网验收需要注意什么细节
一、设备质量及安装验收 光伏组件:检查光伏组件的外观是否完好无损,无明显的缺陷和破损,表面是否清洁无污染。同时,需要验证光伏组件的型号、参数是否与设备台账资料一致。 逆变器:确认逆变器具备防雷、防尘、防潮等…...

页面禁用鼠标右键属于反爬虫措施吗 ?
是的,禁用鼠标右键通常被视为一种反爬虫(anti-scraping)措施。网站开发者常常采用这种技术来防止用户通过右键菜单复制文本、图像或其他内容,特别是在内容保护和数据安全方面。以下是禁用鼠标右键的一些背景和目的: 1…...
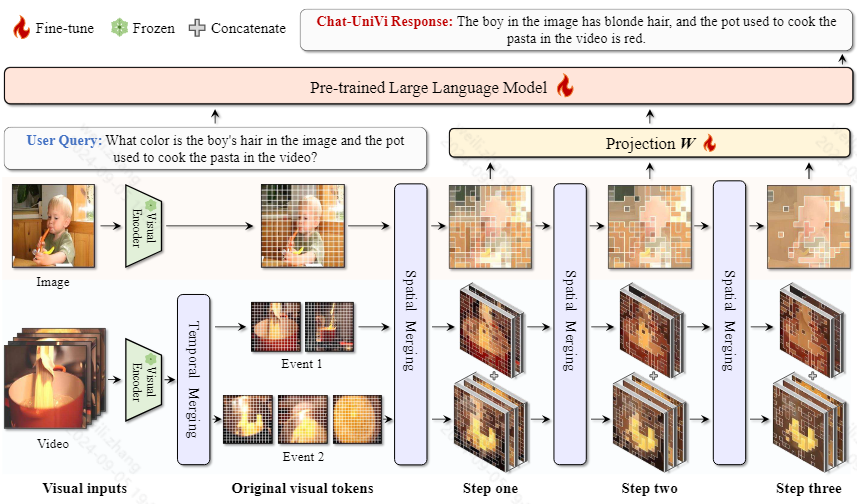
视频理解大模型最新进展
文章目录 Video-LLaMAVision-Language BranchAudio-Language Branch Video-ChatGPTMiniGPT4-videoCogVLM2-Video(1)Pre-training(2)Post-training Qwen2-VLMA-LMMChat-UniVi大模型对比 Video-LLaMA 2023:阿里达摩院的…...

HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁
HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是专为《Honey Select 2》…...

终极免费城通网盘直连解析工具:告别下载限速的完整指南
终极免费城通网盘直连解析工具:告别下载限速的完整指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载速度慢、等待时间长而烦恼吗?ctfileGet是一款专为城通…...

完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题
完整实战指南:使用N_m3u8DL-RE高效解决流媒体下载难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

告别ET1100?聊聊AX58100这颗高性价比EtherCAT从站芯片的升级体验
告别ET1100?AX58100高性价比EtherCAT从站芯片的工业升级实战 当工业设备制造商面临从传统控制架构向实时以太网迁移时,EtherCAT从站芯片的选型往往成为关键转折点。十年前,ET1100凭借其稳定的性能和相对友好的开发门槛,成为许多工…...
)
别再点‘忽略’了!开机弹出Visual C++ Runtime Library错误的终极排查指南(附Adobe软件关联排查)
Visual C Runtime Library错误:从崩溃到根治的全链路解决方案 每次开机时那个刺眼的Visual C Runtime Library错误弹窗,就像一位不请自来的访客,固执地打断你的工作节奏。对于依赖Adobe Creative Cloud或达芬奇等创意工具的专业人士来说&…...

Kubernetes自动化更新利器Keel:实现容器镜像的持续部署
1. 项目概述:为什么我们需要一个“自动化的应用更新管家”? 如果你和我一样,负责维护着几个、十几个,甚至几十个运行在Kubernetes或Docker环境中的应用,那你一定对“更新”这件事又爱又恨。爱的是,新版本意…...

Otter多模态大模型实战:从Flamingo架构到指令调优与部署优化
1. 项目概述:一个能“看懂”世界的多模态大模型最近在折腾多模态大模型(Multimodal Large Language Models, MLLMs)的朋友,应该对 Otter 这个名字不陌生。它不是一个独立的产品,而是一个开源的研究项目,全称…...

基于Go的轻量级自托管IM系统OpenWhisp部署与架构解析
1. 项目概述:一个开源的即时通讯解决方案最近在折腾一个内部协作工具,需要集成一个轻量级的即时通讯模块。市面上成熟的方案不少,但要么是SaaS服务,数据不在自己手里,心里不踏实;要么是像Rocket.Chat、Matt…...

Agent Framework 中的 Workflow Composition
在前面的文章中,我们已经介绍了 Agent Framework 中如何定义流程节点,以及 Workflow 的流式执行事件。 如果你对这些概念还不太熟悉,可以先回顾上一篇文章: Agent Framework 定义流程节点以及节点的流式输出 这一节我们来介绍 Wor…...

开源机械臂技能化控制:从硬件驱动到应用集成的实践指南
1. 项目概述:从开源机械臂到技能控制台最近在机器人控制领域,一个名为esmatcm/openclaw-control-console-skill的项目引起了我的注意。乍一看,这像是一个围绕开源机械臂OpenClaw的控制台技能项目。作为一名长期混迹于硬件开源社区和机器人应用…...