12 Cache Memory
内存的层次结构
计算机内存的层级结构是一种将不同类型的存储设备按照速度、容量和访问时间组织起来的方式。这种层级结构提高了计算机的性能,使得处理器能够高效地访问数据。通常,内存层级结构可分为以下几个层次:
-
寄存器:寄存器是位于CPU内部的极高速存储单元,用于存储计算所需的立即数值和数据。它们的数量有限,但访问速度非常快,通常只需要一个CPU周期。
-
高速缓存(Cache):高速缓存是一种较小但速度快的内存,位于处理器附近。它用于暂存CPU可能频繁访问的数据。高速缓存通常分为三级:L1、L2和L3,其中L1和L2位于每个核心内,L3则为所有核心共享。随着层次的降低,容量变大但速度变慢。
-
主内存(RAM):主内存,也称为随机访问存储器(RAM),是计算机的主要内存。RAM存储运行中的程序和数据,但只在系统供电时有效。RAM比高速缓存容量大得多,但访问速度较慢。
-
虚拟内存:虚拟内存是操作系统用硬盘空间模拟RAM的一种技术,用于在RAM不足时扩展可用内存。虚拟内存访问速度远慢于RAM,但可以处理大量数据。
-
辅助存储(硬盘/固态硬盘):辅助存储设备,如硬盘驱动器(HDD)和固态硬盘(SSD),用于长期存储数据和程序。与RAM相比,这些设备的访问速度较慢,但容量大且在断电后仍可保持数据。
总体来说,计算机内存的层级结构遵循一个基本原则:从上到下,存储设备的速度逐渐减慢,但容量和访问时间逐渐增加。计算机系统通过这种层级结构实现高性能,同时在不同层次之间找到速度与容量的平衡。

Cache
是什么?
Cache(高速缓存)是一种位于CPU与主内存之间的小型、高速内存,用于暂存处理器可能频繁访问的数据。高速缓存的目的是减少CPU访问主内存的时间,从而提高计算机的性能。
高速缓存通常分为三级:L1、L2和L3,其中L1和L2位于每个CPU核心内,L3则为所有核心共享。随着层次的降低,容量变大但速度变慢。
工作原理?
- 本地性原理:Cache利用了程序访问数据和指令的本地性原理,即程序在短时间内倾向于访问相邻的内存地址(空间本地性)以及在一段时间内多次访问相同的内存地址(时间本地性)。因此,高速缓存将最近访问过的数据和指令暂存在其中,以便在下次访问时能更快地获取
- Cache映射:高速缓存将主内存的部分内容分成块(Block),并按照一定的映射策略将这些块放入Cache行(Cache Line)。常见的映射策略有全相联映射、直接映射和组相联映射。
- 替换策略:当高速缓存已满,需要为新的数据腾出空间时,Cache会使用一种替换策略来确定哪个数据块应该被替换。常见的替换策略有最近最少使用(LRU)和随机替换(Random)。
- 写策略:当处理器需要修改高速缓存中的数据时,Cache需要决定何时将这些更改写回主内存。常见的写策略有写回(Write-Back)和写直达(Write-Through)。
高速缓存的作用?
- 减少访问延迟:通过在快速缓存中存储最近访问的数据,CPU能够更快地获取所需数据,从而减少访问延迟。
- 减轻主内存负担:Cache的存在可以减少对主内存的访问次数,从而降低主内存的负担。
- 提高处理器性能:由于CPU可以更快地访问Cache中的数据,因此可以提高处理器的性能。
总之,Cache的作用是通过利用程序的访问本地性和采用一定的映射、替换、写策略来提高数据访问速度,从而提升计算机性能。
Cache的组织结构
高速缓存(Cache)的组织结构是指将数据从主内存映射到Cache中的方式。常见的Cache组织结构有以下几种:
- 直接映射(Direct-Mapped):在直接映射结构中,主内存的每个数据块只能映射到Cache的一个特定位置。映射关系由以下公式决定:Cache行 = 主内存块号 % Cache行数。这种结构简单且实现容易,但可能导致映射冲突,即多个主内存块需要映射到同一个Cache行,从而降低Cache的利用率。
- 全相联映射(Fully Associative):在全相联映射结构中,主内存的任何数据块都可以映射到Cache的任意位置。这种结构在查找数据时需要遍历整个Cache,因此需要较复杂的搜索电路。全相联映射避免了映射冲突,但实现起来相对复杂且成本较高。
- 组相联映射(Set Associative):组相联映射结构是直接映射和全相联映射的折中方案。Cache被划分为多个组(Set),每个组包含若干行。主内存的数据块可以映射到同一组内的任意Cache行。组相联映射相对于直接映射减少了映射冲突,而相对于全相联映射降低了实现复杂性。
以上三种高速缓存组织结构在实际应用中具有不同的性能特点。直接映射结构实现简单,但可能导致较高的映射冲突;全相联映射能充分利用Cache,但实现复杂且成本较高;组相联映射则在实现复杂性和Cache利用率之间取得平衡,通常在现代计算机系统中得到广泛应用。
Cache的寻址方式
Cache的寻址方式是指如何从内存地址中提取相关信息以确定数据在Cache中的位置。主要有以下三种寻址方式:直接映射、组相联映射和全相联映射。这些寻址方式影响了如何从内存地址中提取索引、标记和块内偏移。
- 直接映射(Direct-Mapped):
在直接映射中,每个内存块只能映射到一个特定的Cache行。内存地址被划分为三部分:块内偏移 (Block Offset)、索引(Index)和标记(Tag)。
块内偏移:用于定位数据块中的特定字节。
索引:用于定位Cache中的特定行。
标记:用于验证数据是否存在于Cache中。
- 组相联映射(Set Associative):
在组相联映射中,Cache被分为多个组,每个组包含若干行。内存地址同样被划分为三部分:块内偏移(Block Offset)、组索引(Set Index)和标记(Tag)。
块内偏移:用于定位数据块中的特定字节。
组索引:用于定位Cache中的特定组。
标记:用于验证数据是否存在于Cache的指定组中。
- 全相联映射(Fully Associative):
在全相联映射中,任何内存块都可以映射到Cache的任意行。内存地址只需划分为两部分:块内偏移(Block Offset)和标记(Tag)。
块内偏移:用于定位数据块中的特定字节。
标记:用于验证数据是否存在于Cache中。
Cache 读操作
高速缓存(Cache)的读操作涉及从Cache中获取数据。当CPU需要访问某个内存地址的数据时,Cache读操作遵循以下步骤:
+索引和标记:首先,从要访问的内存地址中提取索引和标记。索引用于定位Cache中的目标行或组,而标记用于在之后的步骤中验证数据是否存在于Cache中。
- 检查Cache:在确定了目标Cache行或组后,检查该行(直接映射)或组内的所有行(组相联映射、全相联映射)的标记,以确定要访问的数据是否存在于Cache中。如果找到匹配的标记,说明发生了Cache命中(Cache Hit)。
- 读取数据:如果发生Cache命中,CPU从Cache中读取相应的数据,并将其传输至寄存器或其他处理单元进行处理。
- 处理Cache未命中:如果在Cache中未找到匹配的标记,说明发生了Cache未命中(Cache Miss)。在这种情况下,CPU需要从主内存中读取所需数据,并将其加载到Cache。根据Cache的组织结构和替换策略(如LRU、FIFO等),可能需要将Cache中的某个数据块替换为新读取的数据。
- 更新替换信息:如果Cache使用了某种替换策略(如LRU),则需要在读取数据后更新相应的替换信息,以便在将来需要替换数据时作出正确的决策。
总结:Cache的读操作包括从内存地址中提取索引和标记、检查Cache行或组、读取数据(如果命中),以及处理Cache未命中的情况。在读操作过程中,还可能需要更新替换策略相关的信息。
Cache 写操作
Cache的写操作涉及将数据写入Cache以及可能的写回到主内存。当CPU需要将数据写入某个内存地址时,Cache写操作遵循以下步骤:
- 索引和标记:首先,从要访问的内存地址中提取索引和标记。索引用于定位Cache中的目标行或组,而标记用于在之后的步骤中验证数据是否存在于Cache中。
- 检查Cache:在确定了目标Cache行或组后,检查该行(直接映射)或组内的所有行(组相联映射、全相联映射)的标记,以确定要访问的数据是否存在于Cache中。如果找到匹配的标记,说明发生了Cache命中(Cache Hit)。
- 写策略:在Cache命中的情况下,CPU将数据写入相应的Cache行。此时,根据Cache的写策略(写回Write-Back或写直达Write-Through),需要执行不同的操作。
写回(Write-Back):将数据写入Cache,并将该Cache行标记为“已修改”(Dirty)。在之后的某个时间点,当这个已修改的Cache行被替换出Cache时,才将其写回到主内存。这种策略减少了对主内存的写操作次数,提高了性能。
写直达(Write-Through):将数据同时写入Cache和主内存。这种策略保证了Cache与主内存中的数据始终保持一致,但可能导致更多的主内存写操作,降低性能。
处理Cache未命中:如果在Cache中未找到匹配的标记,说明发生了Cache未命中(Cache Miss)。此时,根据Cache的写策略和分配策略(写分配Write-Allocate或非写分配No-Write-Allocate),需要执行不同的操作。
写分配(Write-Allocate):从主内存中加载要写入的数据块到Cache,然后再执行写操作。这种策略适用于预期后续对相同数据块的读操作,因为它已经被加载到Cache。
非写分配(No-Write-Allocate):直接将数据写入主内存,而不将数据块加载到Cache。这种策略适用于预期后续不会再访问相同数据块的情况。
总结:Cache的写操作包括从内存地址中提取索引和标记、检查Cache行或组、根据写策略将数据写入Cache和/或主内存,并根据分配策略处理Cache未命中的情况。在写操作过程中,还可能需要更新替换策略相关的信息。
Cache 性能的度量
Cache性能的度量主要关注两个方面:命中率(Hit Rate)和访问时间(Access Time)。这些度量指标反映了Cache对整体系统性能的影响。
- 命中率(Hit Rate):命中率是指Cache中成功找到所需数据或指令的概率。命中率的计算公式为:
命中率 = Cache命中次数 / 总访问次数命中率可以进一步细分为读命中率(Read Hit Rate)和写命中率(Write Hit Rate),分别表示读操作和写操作的命中率。高命中率意味着CPU更多地从高速Cache中获取所需数据,而不是从较慢的主内存中获取,从而提高系统性能。
- 访问时间(Access Time):访问时间是指从发出访问请求到获取所需数据所花费的时间。Cache访问时间可以分为以下几部分:
Cache命中时间(Hit Time):在Cache命中的情况下,从Cache中获取数据所需的时间。
Cache未命中时间(Miss Time):在Cache未命中的情况下,从主内存中获取数据所需的时间。
Cache未命中惩罚(Miss Penalty):额外花费的时间,用于从主内存中加载数据并更新Cache。总访问时间(Average Access Time)是一个综合指标,表示处理器在平均情况下访问数据所需的时间。总访问时间的计算公式为:
总访问时间 = Cache命中时间 + (命中率 × Cache未命中惩罚)为了提高Cache性能,设计者通常会优化命中率和访问时间。这可以通过调整Cache的组织结构、替换策略、写策略等方法来实现。然而,这些优化往往伴随着权衡,例如增加Cache容量可能会提高命中率,但同时也可能增加访问时间。因此,Cache性能优化需要在不同因素之间找到合适的平衡。
分块技术
分块技术(Block,也称Cache Line)是Cache设计中的一种重要概念。当CPU需要访问主内存中的某个数据时,它不仅会将所需的数据加载到Cache中,而且还会将数据所在的整个块加载到Cache中。块是主内存中连续的数据单元,大小通常为2的整数次幂,如32字节、64字节或128字节等。
分块技术的主要优点:
- 利用空间局部性(Spatial Locality):
程序在执行过程中,经常访问相邻的内存地址。分块技术利用了空间局部性,将相邻的数据一起加载到Cache中,从而提高了命中率。当CPU访问某个数据后,很可能在不久的将来访问其相邻的数据,这些相邻的数据已经存储在Cache的同一块中,从而实现了Cache命中。- 减少传输次数:
由于Cache和主内存之间的数据传输通常是按块进行的,分块技术可以减少数据传输次数。加载整个数据块到Cache中意味着将来访问该块内的其他数据时,不需要再次从主内存中加载。- 预取(Prefetching):分块技术可以实现预取,即提前将可能在未来访问的数据加载到Cache中。这有助于减少Cache未命中的概率,从而提高性能。
分块技术的主要缺点:- 内存浪费:如果程序没有访问某个数据块中的所有数据,那么将整个数据块加载到Cache中可能会浪费Cache的空间。
- 替换冲突:如果程序访问的数据跨越了多个数据块,这可能会导致Cache中的数据被不断替换,从而降低命中率。这种情况称为替换冲突(Replacement Conflict)。
总之,分块技术是一种在Cache设计中提高性能的关键方法,它利用了程序访问内存的空间局部性,减少了数据传输次数,并实现了预取。然而,这种方法也可能导致内存浪费和替换冲突。因此,在设计Cache时,需要平衡块大小和其他参数以实现最佳性能。
分块技术的Cache Miss分析
Cache Miss(缺失)是指所需数据不在Cache中,需要从主内存中加载。分块技术的Cache Miss可以分为以下三种类型:
- 冷启动缺失(Cold Miss,也称为强制性缺失,Compulsory Miss):
冷启动缺失是指当程序第一次访问某个数据时发生的缺失。因为程序尚未访问过这个数据,它不可能在Cache中。这种类型的缺失是无法避免的,但随着程序执行的进行,冷启动缺失的数量会降低。- 容量缺失(Capacity Miss):
容量缺失是由于Cache容量不足以容纳程序所需的所有数据而引起的。当程序需要访问的数据集大于Cache的容量时,一些数据必须从Cache中替换出去,以便为新数据腾出空间。当再次访问被替换出的数据时,就会发生容量缺失。增加Cache容量可能有助于减少容量缺失,但成本和功耗也会相应增加。- 冲突缺失(Conflict Miss):
冲突缺失是由于Cache替换策略引起的。在直接映射和组相联映射Cache中,不同的数据块可能映射到同一个Cache位置。当程序反复访问这些冲突的数据块时,它们会相互替换,导致冲突缺失。为了减少冲突缺失,可以使用更复杂的Cache组织方式(例如组相联映射或全相联映射)或优化替换策略(例如最近最少使用LRU或其他策略)。
Cache Miss分析有助于理解程序性能瓶颈,并为优化Cache设计提供依据。通过减少不同类型的Cache Miss,可以提高程序性能。例如,为了减少冷启动缺失,可以使用预取策略;为了减少容量缺失,可以考虑增加Cache容量;为了减少冲突缺失,可以调整Cache组织结构和替换策略。然而,优化Cache时需要在性能、成本和功耗之间进行权衡。
Blocking的效果分析
Blocking是一种优化计算机内存层次结构性能的技术。在这种方法中,程序在执行过程中将数据和计算分块,以更有效地利用Cache。这有助于提高Cache命中率,从而提高程序性能。以下是Blocking技术的效果分析:
- 提高Cache命中率:Blocking可以提高Cache命中率,因为程序在处理一个数据块时,相同的数据可能被多次访问。这使得数据在Cache中保持更长时间,从而提高Cache命中率。这对于循环体(Loop)尤为重要,因为循环体中的数据访问可能具有规律性,通过Blocking可以将循环次数减少到一个较小的数,减少Cache Miss。
- 减少访问主内存的次数:由于Blocking技术可以提高Cache命中率,它还可以减少对主内存的访问次数。这有助于提高程序性能,因为主内存访问速度相对较慢。
- 利用局部性原理:Blocking技术利用了程序的空间局部性和时间局部性原理。空间局部性是指程序在执行过程中,经常访问相邻的内存地址。时间局部性是指程序在短时间内可能多次访问相同的数据。Blocking使程序在处理一个数据块时,能够充分利用这些局部性原理,从而提高性能。
- 提高数据重用率:Blocking有助于提高数据重用率,因为在处理一个数据块时,相同的数据可能被多次访问。这使得Cache中的数据得到更多的重用,从而提高程序性能。
Blocking技术的一些些限制:
- 实现复杂性:实施Blocking技术可能会增加程序实现的复杂性,因为需要对程序进行适当的调整以实现分块。这可能包括调整循环次数、数据访问顺序等。
- 需要选择合适的块大小:选择合适的块大小对于实现Blocking技术的效果至关重要。过大的块可能会导致Cache容量不足,而过小的块可能无法充分利用局部性原理。因此,需要根据程序的特点和Cache参数选择合适的块大小。
总之,Blocking技术通过分块处理数据和计算,可以有效地利用Cache,提高程序性能。然而,实现Blocking技术需要考虑实现复杂性和选择合适的块大小等问题。
相关文章:
12 Cache Memory
内存的层次结构 计算机内存的层级结构是一种将不同类型的存储设备按照速度、容量和访问时间组织起来的方式。这种层级结构提高了计算机的性能,使得处理器能够高效地访问数据。通常,内存层级结构可分为以下几个层次: 寄存器:寄存器…...

【CSS系列】第一章 · CSS基础
写在前面 Hello大家好, 我是【麟-小白】,一位软件工程专业的学生,喜好计算机知识。希望大家能够一起学习进步呀!本人是一名在读大学生,专业水平有限,如发现错误或不足之处,请多多指正࿰…...

【Java代码审计】表达式注入
1 前置知识 1.1 EL表达式 EL表达式主要功能: 获取数据:可以从JSP四大作用域中获取数据执行运算:执行一些关系运算,逻辑运算,算术运算获取web开发常用对象:通过内置 的11个隐式对象获取想要的数据调用jav…...
Python-GEE遥感云大数据分析、管理与可视化
Python-GEE遥感云大数据分析、管理与可视化近年来遥感技术得到了突飞猛进的发展,航天、航空、临近空间等多遥感平台不断增加,数据的空间、时间、光谱分辨率不断提高,数据量猛增,遥感数据已经越来越具有大数据特征。遥感大数据的出…...
 | 洛谷 P2731 [USACO3.3]骑马修栅栏 Riding the Fences)
信息学奥赛一本通 1375:骑马修栅栏(fence) | 洛谷 P2731 [USACO3.3]骑马修栅栏 Riding the Fences
【题目链接】 ybt 1375:骑马修栅栏(fence) 洛谷 P2731 [USACO3.3]骑马修栅栏 Riding the Fences 【题目考点】 1. 图论:欧拉回路 欧拉回路存在的条件:图中所有顶点的度都是偶数欧拉路径存在的条件:图中只有两个度为奇数的顶点…...
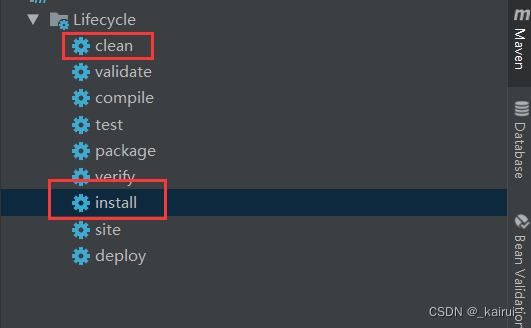
Spring Boot 应用的打包和发布
1. 创建项目(example-fast) 基于 Spring Boot 创建一个 WEB 项目 example-fast。 2. 编译打包 2.1 采用 IDEA 集成的 Maven 环境来对 Spring Boot 项目编译打包,可谓是超级 easy 2.2 mvn 命令打包 # mvn clean 清理编译 # install 打包 #…...

linux:iptables (3) 命令行操练(一)
目录 1.命令行手册查缺补漏 2.开始练习,从最陌生的参数练习开启 2.1 --list-rules -S :打印链或所有链中的规则 2.2 --zero -Z 链或所有链中的零计数器 2.3 --policy -P 修改默认链的默认规则 2.4 --new -N 接下来练习添加和删除自定义链 1.命令行手册查缺补…...
 与synchronized(class) 有啥区别)
synchronized(this) 与synchronized(class) 有啥区别
前言 synchronized(this) 与 synchronized(class) 相同处:均对代码加锁,实现互斥性。synchronized(this) 与 synchronized(class) 区别:作用域不同。 synchronized (this) synchronized(this)使用的是对象锁。this为关键词,表示…...

BOSS直拒、失联招聘,消失的“金三银四”,失业的测试人出路在哪里?
裁员潮涌,经济严冬。最近很多测试人过得并不好,行业缩水对测试岗位影响很直接干脆,究其原因还是测试门槛在IT行业较低,同质化测试人员比较多。但实际上成为一位好测试却有着较高的门槛,一名优秀的测试应当对产品的深层…...

华为OD机试【密室逃生游戏】
密室逃生游戏 题目 小强增在参加《密室逃生》游戏,当前关卡要求找到符合给定 密码 K(升序的不重复小写字母组 成) 的箱子, 并给出箱子编号,箱子编号为 1~N 。 每个箱子中都有一个 字符串 s ,字符串由大写字…...

【Python学习笔记(六)】json解析模块的使用
json解析模块的使用 前言 json 是一种轻量级的数据交换格式,通过对象和数组的组合来表示数据。在 Python3 中可以使用 json 模块来对 json 数据进行编解码。 json 模块 是 Python 标准库模块,无需手动安装,可以直接导入 import json # 导入…...

《Spring系列》第3章 基于注解管理Bean
基于注解方式管理Bean 1.通过注解管理Bean 1) 基础注解 Component Service Controller Repository 2) 基于XML的注解扫描 a> 引入依赖 spring-aop-5.1.5.RELEASE.jarb> 开启组件扫描 最简单的开启注解 <context:component-scan base-package"com.jianan&q…...
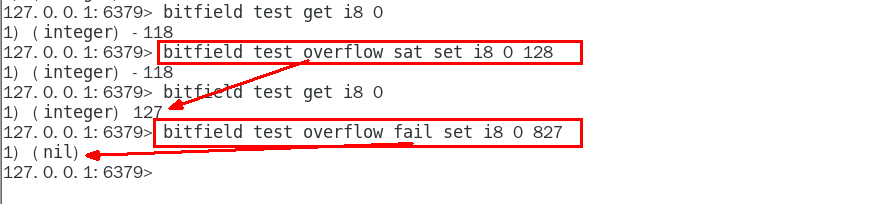
【Redis】十大数据类型(下篇)
文章目录redis位图(bitmap) --- 底子还是string基本命令图示setbit key offset value setbit 键 偏移位 只能零或者1getbit key offset 查看获取字符串长度 strlen统计key中包含1的个数 bitcount keybitop 统计两个比特key是否都为1技术落地:打卡签到,频…...
【第十一届“泰迪杯”数据挖掘挑战赛】B题产品订单的数据分析与需求预测“解题思路“”以及“代码分享”
【第十一届泰迪杯B题产品订单的数据分析与需求预测产品订单的数据分析与需求预测 】第一大问代码分享(后续更新LSTMinformer多元预测多变量模型) PS: 代码全写有注释,通俗易懂,包看懂!!!&…...

Python入门到高级【第一章】
预计更新第一章. Python 简介 Python 简介和历史Python 特点和优势安装 Python 第二章. 变量和数据类型 变量和标识符基本数据类型:数字、字符串、布尔值等字符串操作列表、元组和字典 第三章. 控制语句和函数 分支结构:if/else 语句循环结构&#…...

【泰凌微TLSR8258 zigbee】OTA升级操作方法
目录 程序启动模式多地址启动模式Bootloader 启动模式多地址启动模式 Flash 分布Bootloader 启动模式Flash分布模式OTA升级OTA初始化OTA ServerOTA ClientOTA升级固件生成程序启动模式 在介绍OTA升级操作方法前,我们先介绍一下程序的启动模式,以及不同启动模式的优缺点。 多…...

网络基础设施监控
在过去的几十年里,网络基础设施在规模和功能方面都变得复杂起来。不断增长的业务需求和不断增长的技术能力推动了这种快速增长,监控网络基础设施以确保其最佳性能和最大效率已成为任何希望成为行业领跑者的组织不可或缺的优先事项。 什么是网络基础设施…...

OPNET Modeler 例程——创建一个包交换网络
文章目录一、例程简介二、创建新的包格式三、创建新的链路模型四、创建中心交换节点模型五、创建中心交换节点的进程模型六、创建周边节点模型七、创建周边节点进程模块八、创建网络模型九、收集统计量十、配置并仿真总结一、例程简介 本例程将仿真一个简单的包交换网络&#…...

JSON 基础结构
什么是JSON JSON,说白了就是JavaScript用来处理数据的一种格式,这种格式非常简单易用。 JSON,大部分都是用来处理JavaScript和web服务器端之间的数据交换,把后台web服务器的数据传递到前台,然后使用JavaScript进行处…...

雷达基础知识
雷达频率划分 以下是按照频率和波长划分雷达频段的表格: 波段名称频率范围(GHz)波长范围(cm)应用领域VHF0.03 - 0.3100 - 10气象雷达、空管雷达、航空雷达UHF0.3 - 3100 - 10航空雷达、海上雷达、地面雷达、火控雷达…...

从数据驱动到物理约束:盘点神经网络求解偏微分方程的三大范式与核心进展
1. 神经网络求解偏微分方程的技术背景 偏微分方程(PDE)是描述自然界各种现象的核心数学工具,从流体力学中的纳维-斯托克斯方程到量子力学中的薛定谔方程,再到金融工程中的布莱克-斯科尔斯方程,PDE的身影无处不在。但传…...

小米Tag防丢器深度解析:BLE与UWB双技术路径如何重塑寻物体验
1. 项目概述:小米入局,防丢市场迎来“鲶鱼”在智能硬件领域,防丢追踪器一直是个不温不火但又刚需明确的存在。苹果的AirTag凭借其庞大的Find My网络,几乎定义了行业标准,但也因其生态封闭性,让安卓用户望而…...

嵌入式音频开发避坑指南:如何用一颗模组搞定AEC、ANS与啸叫抑制
摘要:在智能门禁、会议终端、车载语音等嵌入式产品中,回声消除(AEC)、噪声抑制(ANS)和啸叫抑制(AFC)是三大“硬骨头”。本文将深入解析A-59F多功能语音处理模组的架构与特性…...

告别模组冲突:3分钟掌握Nexus Mods App终极游戏模组管理方案
告别模组冲突:3分钟掌握Nexus Mods App终极游戏模组管理方案 【免费下载链接】NexusMods.App Home of the development of the Nexus Mods App 项目地址: https://gitcode.com/gh_mirrors/ne/NexusMods.App 还在为《赛博朋克2077》的模组冲突而烦恼吗&#x…...

基于STM32F401与TM8211的I2S音频播放系统:从WAV解析到硬件驱动全解析
1. 硬件选型与系统架构设计 第一次接触音频项目时,我被各种专业术语搞得晕头转向。后来发现,用"音乐快递员"的比喻就能轻松理解整个系统:STM32F401是快递分拣中心,I2S是运送音乐包裹的高速公路,TM8211则是把…...

如何快速解决AKShare股票数据获取失败:完整的数据采集优化指南
如何快速解决AKShare股票数据获取失败:完整的数据采集优化指南 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirror…...

拯救论文AI检测标红!2026实测5款降重平台,注入“真实感”的手改全攻略
知网和维普的AIGC检测系统又更新了! 在当下的关口,如何在不牺牲质量的前提下,优化初稿表达,安全地降低AI痕迹,成了所有小伙伴们必须解决的一个问题。网络上各种“降AI神器”铺天盖地,这些工具到底靠不靠谱…...

【文学研究者的AI分身已上线】:NotebookLM定制知识图谱构建指南——仅限高校人文实验室内部流通的8项参数配置
更多请点击: https://codechina.net 第一章:【文学研究者的AI分身已上线】:NotebookLM定制知识图谱构建指南——仅限高校人文实验室内部流通的8项参数配置 NotebookLM 的「自定义知识图谱」功能并非通用型索引,而是面向人文学科深…...

如何让GBFR-Logs成为你的碧蓝幻想Relink战斗分析利器
如何让GBFR-Logs成为你的碧蓝幻想Relink战斗分析利器 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr-logs 你是否在《碧蓝幻…...

3分钟掌握TegraRcmGUI:Switch破解必备的RCM注入神器
3分钟掌握TegraRcmGUI:Switch破解必备的RCM注入神器 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI 想要解锁你的Nintendo Switch的无限潜力吗&a…...