【二叉平衡搜索树】Treap
前置
本篇是平衡树-treap的补充学习笔记。
Treap- 树堆
学习基础:适合一定基础的:比如,实现了经典二叉搜索树(常用的几个函数写过), 和二叉堆(数组的上浮下沉会写吗?),至少了解旋转的概念且写过旋转的接口(有一定理解,比如实现AVL树/红黑树)(涉及到相关思想)。
实现语言:Java。 —其它语言的小伙伴可拷贝我的代码转译成自己的语言(笔者虽然多语言学习,但使用侧重点不同, 对语言的理解也浅薄, 频繁切换语言不妥。)
纯根据理解手写。
来源:算法导论---红黑树章节后的treap思考题
参考书籍:算法导论
- 有关问题:
- 算法导论第6章堆排序详细地说明了:二叉堆概念, 上浮和下沉操作的相关概念伪代码。实现一下二叉堆(优先级队列)
- 算法导论第12章介绍了
transplant接口, 和二叉搜索树的其它好用的函数。 - 算法导论第13章介绍了红黑树, 红黑树的代码很难写且不易理解,只需了解一下旋转这个操作和伪代码即可。
- 可以去油管或者b站, 或者搜索引擎查找相关问题。
笔者水平有限, 本篇基于笔记改写, 缺点很多, 不太适合新手, 适合部分熟悉的朋友回顾复习, 在此见谅。
引入
- 对于一般的二叉搜索树, 已知n个数据序列插入到一个二叉搜索树有可能得到性能极差(高度极不平衡的二叉搜索树)。这种单支树的例子, 相信你已经不会陌生了。对于随机化构建的二叉搜索树, 经过概率论分析的数学期望, 得到的二叉搜索树是趋向平衡的。
之前写过一篇动态随机化的平衡树结构-----跳表, 非形式地讨论了这个问题。
接下来, 介绍另一种动态随机化的平衡树结构-----Treap。
为什么有了随机化构建, 而依旧有研究动态化构建的必要呢? 尽管在跳表篇给了解释, 但此篇为不甚了解的朋友作出非严格地说明。已知n个数据构建随机二叉搜索树, 当然可行。 缺点? 如果我们未知数据量n呢?或者随机化二叉搜索树,我们还要动态地插入删除呢?, 在只允许我们一次取一个数据的场景, 经典的随机化构建二叉搜索树不现实了。 我都拿不到所有数据,如何随机化地插入二叉搜索树呢? 相比
Treap和跳表动态树结构, 经典随机二叉搜索树可以说是静态结构。
介绍
Treap 是一种弱平衡的树结构, 什么叫做弱平衡呢? 不同平衡树对平衡的定义不同, 确切的,它们对平衡的宏观定义是相同的(维持一棵好性能的树), 但对树的平衡严格程度要求是不一样的。
一般地, 弱平衡树更好实现, 相比于强平衡的AVL(左右子树高度差不为1), 红黑树(左右高度差小于2倍), 跳表明显好实现多了。其次,强平衡树在高度上有最坏的保证(最坏也是性能比较好的),弱平衡树最坏保证是经典二叉搜索树的最坏情况(单支链表的情况)。
归咎原因, 弱平衡没有在高度上严格保证, 这里的Treap还把基本操作交给概率这一事物, 平均来看很好, 但失败的后果会很糟糕(虽然失败导致最坏的情况从概率数字来看几乎不可能发生)。
现在,我们可以正式地介绍一下Treap了,
在此,简单回顾一下:
对于二叉搜索树: 基本性质: 左子树的key <= 根 <= 右子树的key。
对于二叉堆:基本性质:孩子的key>=父亲的key(最小堆), 兄弟之间的大小关系不在意。
综合二者性质,依旧让key的关系满足: 左 < 根 < 右, 可以取等自己调整一下。但我个人风格是key最好互异。
堆的性质从何体现, 我们引入了一个priority字段,表示优先级。
类比二叉堆的最小堆, 那么最小Treap,满足parent.priority < node.priority
![![[Pasted image 20240927090041.png]]](https://i-blog.csdnimg.cn/direct/643fc2a2a3a44d529ab027df262e176f.png)
综合:
Treap 具有以下几个重要性质:
-
二叉搜索树性质:对于每个节点,其左子树的所有节点的键值小于该节点的键值,而右子树的所有节点的键值大于该节点的键值。假设键值是不一样的。
-
堆性质:每个节点的优先级大于或等于其子节点的优先级。这条性质导致这个结构和堆一致。
-
随机性:节点的优先级通常是随机生成器(如
Java中的Random对象)生成的,这使得Treap的结构在插入和删除操作中保持平均 O ( l o g n ) O(log n) O(logn) 的时间复杂度。 -
动态平衡性:支持随机化的动态插入,删除, 比随机化二叉搜索树自由。
实现
- 以下代码比较简单, 若你是学Java的应该不难读懂,其它语言的小伙伴可以借助
chatgpt翻译成自己的语言,这是一种我比较经典的写法了。
import java.util.Random;
import java.util.Comparator;
public class Treap<K,V> { //比较器, 可以手动传递比较器对象, 否则K必须实现Comparable接口 private Comparator<? super K> comparator; //随机数生成器, 为每一个节点生成一个随机数 private final Random random = new Random(); private Node<K,V> root; //根节点 public class Node<K,V>{ K key; //键 V value; //值 Node<K,V> left; //左子树 Node<K,V> right; //右子树 Node<K,V> parent; //父指针 int priority; //优先级 public Node(K key, V value) { this.key = key; this.value = value; left = right = parent = null; priority = random.nextInt();//为新生成的节点分配一个随机数。 } } public Treap(){ this(null); } public Treap(Comparator<? super K> comparator) { this.comparator = comparator; }
}
查询操作
查询操作, 方法思路同经典二叉搜索树, 在此不多赘述。
- 下面实现了三个方法, 核心关注
search方法,contains返回一个布尔值,判断关键字key的节点是否存在。get方法根据键获取值。
public Node<K,V> search(K key){ if(root == null){ return null; //这里单独检查一下。} Node<K,V> current = root;//遍历Treap int cmp = 0; //记录比较结果if(comparator != null){ //比较器不为空,那么优先使用比较器。 while(current!=null){ cmp = comparator.compare(current.key, key); if(cmp==0){ return current;//找到了!直接返回节点的引用。 } else if(cmp<0){ //当前值太小了, 前往右子树current = current.right; } else{ //cmp>0 current = current.left; } } } else{ //comparator == null @SuppressWarnings("unchecked!") Comparable<? super K> comparable = (Comparable<? super K>)current.key; // 使用者必须确保K类型是可比较的, 否则报错。 cmp = comparable.compareTo(key); while(current != null){ comparable = (Comparable<? super K>)current.key; cmp = comparable.compareTo(key); //逻辑与比较器相同if(cmp==0){ return current; } else if(cmp<0){ current = current.right; } else{ current = current.left; } } } return null;//出循环了即为空。
}
//根据serach结果造contains函数和get函数
public boolean contains(K key){ return search(key) != null;
} public V get(K key){ return search(key) != null ? search(key).value : null;
}
插入操作
写法很简单, 套路更简单。
经典BST插入+二叉堆的上浮调整。
TREAP-INSERT(T, x):y <- T.rootp <- NILwhile y ≠ NIL:p <- yif y.key == x.key:// Update the valuey.val <- x.valreturnelseif y.key > x.key:y <- y.leftelse: // y.key < x.keyy <- y.rightif p == NIL:T.root <- x // Insert as root if tree was emptyelseif p.left == y:p.left <- xelse:p.right <- xsiftUp(T, x) // Perform the sift up operation这张图举例:
BST操作不多说, 下面来说明指针版本的上浮操作处理, 旋转又来了。
可能数组的堆上浮写熟悉了, 头一次处理指针版本的。
![![[Pasted image 20240927122757.png]]](https://i-blog.csdnimg.cn/direct/91e2cac34eda4ec5b839b608eb1b006d.png)
public void put(K key, V value){ if(key != null) { insert(new Node(key, value)); }
}
public void insert(K key, V value){ if(key != null) { insert(new Node(key, value)); }
}
public void insert(Node<K,V> node) { if (root == null) { root = node; //这里单独处理, 保证后续代码在非空情形下return; } Node<K,V> current = root; // 当前节点 Node<K,V> parent = null; // 父节点 int cmp = 0; // 遍历查找插入位置 while (current != null) { parent = current; if (comparator != null) { cmp = comparator.compare(node.key, current.key); } else { @SuppressWarnings("unchecked") Comparable<? super K> comparable = (Comparable<? super K>) current.key; cmp = comparable.compareTo(node.key); } if (cmp == 0) { current.value = node.value; // 更新值 return; } else if (cmp < 0) { current = current.right; // 前往右子树 } else { current = current.left; // 前往左子树 } } // 插入节点 node.parent = parent; if (cmp < 0) { parent.right = node; // 插入到右子树 } else { parent.left = node; // 插入到左子树 } siftUp(node); // 上浮操作
}
旋转接口
这里眼熟一下, 实现avl或者红黑树,简单回顾一下左旋和右旋两个接口。
private void leftRotate(Node<K,V> x) {Node<K,V> y = x.right;x.right = y.left;if (y.left != null) {y.left.parent = x;}y.parent = x.parent;if (x.parent == null) {root = y; // y 变为新的根节点} else if (x == x.parent.left) {x.parent.left = y; // x 是左子节点} else {x.parent.right = y; // x 是右子节点}y.left = x; // x 变为 y 的左子节点x.parent = y; // 更新 x 的父指针
}private void rightRotate(Node<K,V> y) {Node<K,V> x = y.left;y.left = x.right;if (x.right != null) {x.right.parent = y;}x.parent = y.parent;if (y.parent == null) {root = x; // x 变为新的根节点} else if (y == y.parent.left) {y.parent.left = x; // y 是左子节点} else {y.parent.right = x; // y 是右子节点}x.right = y; // y 变为 x 的右子节点y.parent = x; // 更新 y 的父指针
}siftUp
private void siftUp(Node<K, V> node){ //上浮的临界是根节点,到根节点就必须终止了。 //这里直接node.parent, 不需要申请新变量。---对可读性没多大英影响 while(node != root && node.priority < node.parent.priority){ //开始上浮 if(node.parent.left == node){ //执行右旋 rightRotate(node.parent); } else{ //parent.right == node //执行左旋 leftRotate(node.parent); } //经过旋转后,原先的父亲节点指针parent成为node的孩子节点 node.parent = node.parent; }
}
删除
以下两个接口函数, 你必须在BST中学明白了。
这两个方法在Treap的删除操作中非常重要。
transplant && minimum
transplant方法:用于替换树中一个节点u为另一个节点v,并更新它们的父节点关系。minimum方法:用于查找给定节点的最小值节点,通过遍历左子树实现。
private void transplant(Node<K,V> u, Node<K,V> v) {if (u.parent == null) {root = v; // u 是根节点} else if (u == u.parent.left) {u.parent.left = v; // u 是左子节点} else {u.parent.right = v; // u 是右子节点}if (v != null) {v.parent = u.parent; // 更新 v 的父指针}
}public Node<K,V> minimum(Node<K,V> node) {if (node == null) {return null; // 如果节点为空,返回 null}while (node.left != null) {node = node.left; // 一直遍历左子树,直到找到最小值}return node;
}
删除
public void delete(Node<K,V> node) {if (node.left == null) {transplant(node, node.right); // 只有右子树} else if (node.right == null) {transplant(node, node.left); // 只有左子树} else {// 找到右子树中的最小节点Node<K,V> leftMin = minimum(node.right);if (leftMin.parent != node) {transplant(leftMin, leftMin.right);leftMin.right = node.right;if (leftMin.right != null) {leftMin.right.parent = leftMin;}}transplant(node, leftMin);leftMin.left = node.left;leftMin.left.parent = leftMin;}siftDown(node); // 维护 Treap 的性质
}siftDown
private void siftDown(Node<K,V> node) {Node<K,V> child = node.left;boolean isLeft = true;//左孩子还是右孩子,while (child != null) {// 选择优先级较高的孩子节点if (node.right != null && node.right.priority > child.priority) {child = node.right;isLeft = false;}// 执行旋转if (child.priority > node.priority) {if (isLeft) {rightRotate(node);} else {leftRotate(node);}node = child; // 更新当前节点为孩子节点child = (isLeft) ? node.left : node.right; // 继续下沉isLeft = true; // 重置为左子树} else {break; // 如果当前节点的优先级已大于所有孩子,结束}}
}其它问题思考
Treap的唯一性
给定一组关键字和优先级均互异的节点, 可以组成唯一的Treap树与这些节点关联。
第一步, 根的唯一性:根节点是具有最高优先级的节点, 由于每个键值的优先级是唯一的,所以具有最高优先级的节点也是唯一的。比如最小`Treap中,根节点是最小的priority。
第二步, 递归构建。 由于根节点唯一了, 那么可以分组,一组的节点的key均小于root.key, 另一组均大于root.key。那么左右两边的序列元素确定了。
第三步, 递归中子树遵循第一条, 因此结构必定唯一。 因为树是由递归定义的。
以上性质涉及,二叉搜索树的有序性, 堆的性质。总之, 可以证明满足上述条件的Treap具有唯一性。 证毕!
待补充。。。
由于其它问题,比如树的期望高度证明需要概率知识, 数学这一块依旧是硬伤。
在此就不献丑了, 留待日后补充。
总源码
关于Treap实现有多种方案。 比如,我的方案是旋转treap,可以参考treap。
有兴趣的小伙伴可以根据我的代码拓展很多功能, 在此篇就不写多了, 只能说本篇的可拓展性强吧
学艺不精, 难免错误, 希望并感谢大佬您提出宝贵的意见, 谢邀。
感谢我的朋友们的鼓励,和数学编程问题的指导, 这几天精神真是颓废, 今天好多了。
import java.util.Random;
import java.util.Comparator;
public class Treap<K,V> { //比较器, 可以手动传递比较器对象, 否则K必须实现Comparable接口 private Comparator<? super K> comparator; //随机数生成器, 为每一个节点生成一个随机数 private final Random random = new Random(); private Node<K,V> root; //根节点 public class Node<K,V>{ K key; //键 V value; //值 Node<K,V> left; //左子树 Node<K,V> right; //右子树 Node<K,V> parent; //父指针 int priority; //优先级 public Node(K key, V value) { this.key = key; this.value = value; left = right = parent = null; priority = random.nextInt();//为新生成的节点分配一个随机数。 } } public Treap(){ this(null); } public Treap(Comparator<? super K> comparator) { this.comparator = comparator; }
public Node<K,V> search(K key){ if(root == null){ return null; //这里单独检查一下。} Node<K,V> current = root;//遍历Treap int cmp = 0; //记录比较结果if(comparator != null){ //比较器不为空,那么优先使用比较器。 while(current!=null){ cmp = comparator.compare(current.key, key); if(cmp==0){ return current;//找到了!直接返回节点的引用。 } else if(cmp<0){ //当前值太小了, 前往右子树current = current.right; } else{ //cmp>0 current = current.left; } } } else{ //comparator == null @SuppressWarnings("unchecked!") Comparable<? super K> comparable = (Comparable<? super K>)current.key; // 使用者必须确保K类型是可比较的, 否则报错。 cmp = comparable.compareTo(key); while(current != null){ comparable = (Comparable<? super K>)current.key; cmp = comparable.compareTo(key); //逻辑与比较器相同if(cmp==0){ return current; } else if(cmp<0){ current = current.right; } else{ current = current.left; } } } return null;//出循环了即为空。
}
//根据serach结果造contains函数和get函数
public boolean contains(K key){ return search(key) != null;
} public V get(K key){ return search(key) != null ? search(key).value : null;
}
public void put(K key, V value){ if(key != null) { insert(new Node(key, value)); }
}
public void insert(K key, V value){ if(key != null) { insert(new Node(key, value)); }
}
public void insert(Node<K,V> node) { if (root == null) { root = node; //这里单独处理, 保证后续代码在非空情形下return; } Node<K,V> current = root; // 当前节点 Node<K,V> parent = null; // 父节点 int cmp = 0; // 遍历查找插入位置 while (current != null) { parent = current; if (comparator != null) { cmp = comparator.compare(node.key, current.key); } else { @SuppressWarnings("unchecked") Comparable<? super K> comparable = (Comparable<? super K>) current.key; cmp = comparable.compareTo(node.key); } if (cmp == 0) { current.value = node.value; // 更新值 return; } else if (cmp < 0) { current = current.right; // 前往右子树 } else { current = current.left; // 前往左子树 } } // 插入节点 node.parent = parent; if (cmp < 0) { parent.right = node; // 插入到右子树 } else { parent.left = node; // 插入到左子树 } siftUp(node); // 上浮操作
}
private void leftRotate(Node<K,V> x) {Node<K,V> y = x.right;x.right = y.left;if (y.left != null) {y.left.parent = x;}y.parent = x.parent;if (x.parent == null) {root = y; // y 变为新的根节点} else if (x == x.parent.left) {x.parent.left = y; // x 是左子节点} else {x.parent.right = y; // x 是右子节点}y.left = x; // x 变为 y 的左子节点x.parent = y; // 更新 x 的父指针
}private void rightRotate(Node<K,V> y) {Node<K,V> x = y.left;y.left = x.right;if (x.right != null) {x.right.parent = y;}x.parent = y.parent;if (y.parent == null) {root = x; // x 变为新的根节点} else if (y == y.parent.left) {y.parent.left = x; // y 是左子节点} else {y.parent.right = x; // y 是右子节点}x.right = y; // y 变为 x 的右子节点y.parent = x; // 更新 y 的父指针
}
private void siftUp(Node<K, V> node){ //上浮的临界是根节点,到根节点就必须终止了。 //这里直接node.parent, 不需要申请新变量。---对可读性没多大英影响 while(node != root && node.priority < node.parent.priority){ //开始上浮 if(node.parent.left == node){ //执行右旋 rightRotate(node.parent); } else{ //parent.right == node //执行左旋 leftRotate(node.parent); } //经过旋转后,原先的父亲节点指针parent成为node的孩子节点 node.parent = node.parent; }
}
private void transplant(Node<K,V> u, Node<K,V> v) {if (u.parent == null) {root = v; // u 是根节点} else if (u == u.parent.left) {u.parent.left = v; // u 是左子节点} else {u.parent.right = v; // u 是右子节点}if (v != null) {v.parent = u.parent; // 更新 v 的父指针}
}public Node<K,V> minimum(Node<K,V> node) {if (node == null) {return null; // 如果节点为空,返回 null}while (node.left != null) {node = node.left; // 一直遍历左子树,直到找到最小值}return node;
}
public void delete(Node<K,V> node) {if (node.left == null) {transplant(node, node.right); // 只有右子树} else if (node.right == null) {transplant(node, node.left); // 只有左子树} else {// 找到右子树中的最小节点Node<K,V> leftMin = minimum(node.right);if (leftMin.parent != node) {transplant(leftMin, leftMin.right);leftMin.right = node.right;if (leftMin.right != null) {leftMin.right.parent = leftMin;}}transplant(node, leftMin);leftMin.left = node.left;leftMin.left.parent = leftMin;}siftDown(node); // 维护 Treap 的性质
}
private void siftDown(Node<K,V> node) {Node<K,V> child = node.left;boolean isLeft = true;//左孩子还是右孩子,while (child != null) {// 选择优先级较高的孩子节点if (node.right != null && node.right.priority > child.priority) {child = node.right;isLeft = false;}// 执行旋转if (child.priority > node.priority) {if (isLeft) {rightRotate(node);} else {leftRotate(node);}node = child; // 更新当前节点为孩子节点child = (isLeft) ? node.left : node.right; // 继续下沉isLeft = true; // 重置为左子树} else {break; // 如果当前节点的优先级已大于所有孩子,结束}}
}
}红尘漩涡不由己, 何朝散发弄扁舟。
乘风破浪三万里, 方是我辈魔道人。
—20240927
— author:Autumn Whisper。
相关文章:
【二叉平衡搜索树】Treap
前置 本篇是平衡树-treap的补充学习笔记。 Treap - 树堆 学习基础:适合一定基础的:比如,实现了经典二叉搜索树(常用的几个函数写过), 和二叉堆(数组的上浮下沉会写吗?)&a…...

Spring Boot 应用Kafka讲解和案例示范
Kafka 是一款高吞吐量、低延迟的分布式消息系统。本文将详细介绍如何在 Spring Boot 项目中使用 Kafka 进行消息接收与消费,并结合幂等和重试机制,确保消息消费的可靠性和系统的扩展性。我们将以电商交易系统为案例进行深入解析。 1. 系统架构概览 在电…...

以到手价为核心的品牌电商价格监测
在当今竞争激烈的电商时代,品牌的价格监测至关重要。传统的页面价监测已无法满足品牌对渠道管控的需求,而到手价监测则成为品牌控价的关键所在。 力维网络,作为深耕数据监测服务多年的专业机构,拥有自主开发的数据监测系统&#…...

Android中使用RecyclerView制作横向轮播列表及索引点
在Android开发中,RecyclerView是一个非常强大的组件,用于展示列表数据。它不仅支持垂直滚动,还能通过配置不同的LayoutManager实现横向滚动,非常适合用于制作轮播图或横向列表。本文将详细介绍如何使用RecyclerView在Android应用中…...

Llama 3.1 技术研究报告-2
3.3 基础设施、扩展性和效率 我们描述了⽀持Llama 3 405B⼤规模预训练的硬件和基础设施,并讨论了⼏项优化措施,这些措施提⾼了训练效率。 3.3.1 训练基础设施 Llama 1和2模型在Meta的AI研究超级集群(Lee和Sengupta,2022&#x…...
【深度学习】05-RNN循环神经网络-02- RNN循环神经网络的发展历史与演化趋势/LSTM/GRU/Transformer
RNN网络的发展历史与演化趋势 RNN(Recurrent Neural Network,循环神经网络)是一类用于处理序列数据的神经网络,特别擅长捕捉数据的时间或上下文依赖性。在其发展的过程中,不断出现各种改进和变体,以解决不…...

C++学习9.27
1、顺序表、栈、队列都更改成模板类 (1)顺序表 #include <iostream> #include <cstring>using namespace std;template <typename T1,typename T2,typename T3> class My_string { private:T1 *ptr; //指向字符数组的指针T2…...

【STM32开发环境搭建】-1-Keil(MDK) 5.27软件安装和注册教程
目录 1 安装前装备工作 2 安装KEIL(MDK-ARM) 5.27软件 3 注册KEIL(MDK-ARM) 5.27软件,获取License许可证 4 手动安装STM32F0,STM32F1,STM32F4,STM32F7,STM32H7的支持包 4.1 下载STM32的支持包 4.2 安装STM32的支…...

武汉正向科技格雷母线公司,无人天车系统,采用格雷母线定位技术
正向科技-格雷母线高精确定位技术-实操视频 高精度格雷母线内胆采用刚性内胆,基板采用精密度数控加工工艺,穿线卡采用高精度模具制作,不采用泡沫板填充,提高了地址检测精度和线性度。 最新一代的格雷母线定位技术特点是全数字化检…...
【保姆级教程】批量下载Pexels视频Python脚本(以HumanVid数据集为例)
目录 方案一:转换链接为download模式 方案二:获取源链接后下载 附录:HumanVid链接 方案一:转换链接为download模式 将下载链接的后缀加入 /download 然后用下面的脚本下载: import argparse import json import o…...
Python画笔案例-067 绘制配乐七角星
1、绘制橙子 通过 python 的turtle 库绘制 配乐七角星,如下图: 2、实现代码 绘制 配乐七角星 ,以下为实现代码: """配乐七角星.py本程序需要coloradd模块支持,安装方法:pip install coloradd""" import turtle from coloradd import color…...

Spark Job 对象 详解
在 Apache Spark 中,Job 对象是执行逻辑的核心组件之一,它代表了对一系列数据操作(如 transformations 和 actions)的提交。理解 Job 的本质和它在 Spark 中的运行机制,有助于深入理解 Spark 的任务调度、执行模型和容…...

C#中NModbus4中常用的方法
NModbus4 是一个用于 Modbus 协议通信的 C# 库,它支持串行 ASCII、RTU、TCP 和 UDP 协议。以下是 NModbus4 中常用的一些方法: 创建连接: ModbusSerialMaster.CreateRtu(SerialPort serialPort): 创建一个 RTU 串行连接。ModbusSerialMaster.…...
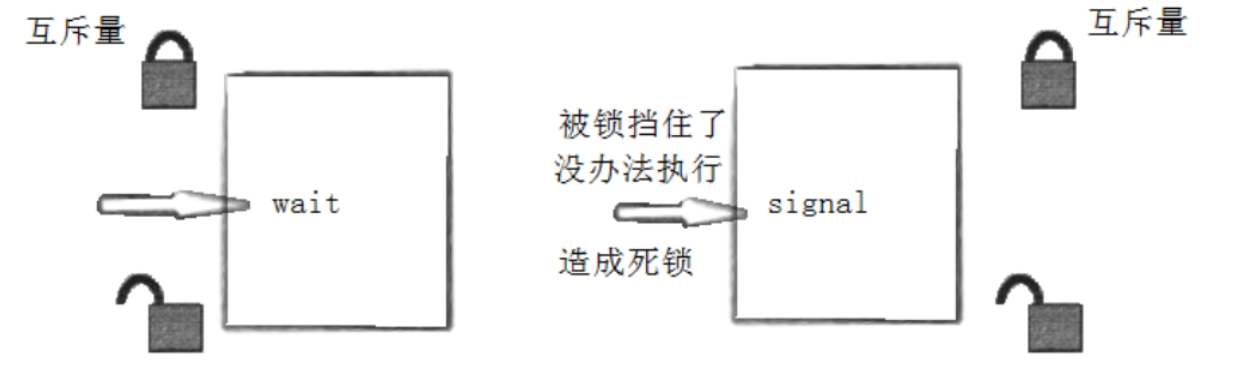
【Linux】线程同步与互斥
一、线程间互斥 1 .进程线程间的互斥相关概念 临界资源:多线程执行流共享的资源就叫做临界资源 临界区:每个线程内部,访问临界资源的代码,就叫做临界区 互斥:任何时刻,互斥保证有且只有一个执行流进入临界…...
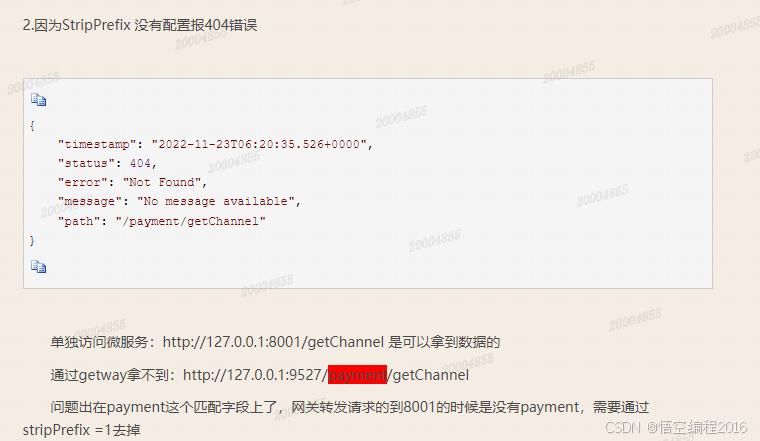
003、网关路由问题
1. nginx配置404跳转回默认路由 https://blog.csdn.net/masteryee/article/details/83689954 https://blog.csdn.net/IbcVue/article/details/133230460 https://www.jb51.net/server/317970ynk.htm https://blog.csdn.net/u014438244/article/details/120531287 https://blog…...

Eclipse 快捷键:提高开发效率的利器
Eclipse 快捷键:提高开发效率的利器 Eclipse 是一款广泛使用的集成开发环境(IDE),它为Java、C、PHP等编程语言提供了强大的开发支持。对于开发者来说,熟练掌握Eclipse的快捷键不仅能提高编码效率,还能减少…...

Agent智能体
Agent(智能体)是一个能够感知环境并采取行动的自主实体,通常被设计用于在特定的环境中执行任务。智能体可以通过学习、推理等方式来决策,目标是最大化某种效用或实现某个预定的目标。它们广泛应用于自动化系统、游戏AI、机器人、自…...

用Promise实现前端并发请求
/** * 构造假请求 */ async function request(url) {return new Promise((resolve) > {setTimeout(() > {resolve(url);},// Math.random() * 500 800,1000,);}); }请求一次,查看耗时,预计应该是1s: async function requestOnce() {c…...
通过队列实现栈
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 实现 MyStack 类: void push(int x) 将元素 x 压入栈顶。int pop() 移除并返回栈顶元素。int to…...
Mac下可以平替paste的软件pastemate,在windows上也能用,还可以实现数据多端同步
Mac平台上非常经典的剪贴板管理工具:「Paste」。作为一款功能完善且易用的工具,「Paste」在实际使用中体现出了许多令人欣赏的特点。但是它是一个收费软件,一年至少要24美元. 现有一平替软件pastemate,功能更加丰富,使用更加方便。 下载地址…...

基于Python与Playwright的招聘信息自动化聚合与智能筛选工具实践
1. 项目概述:一个面向求职者的自动化信息聚合与投递工具最近在和一些做开发的朋友聊天,发现大家普遍有个痛点:找工作太费时间了。每天要在几个招聘App之间来回切换,重复筛选岗位、刷新列表、投递简历,机械性的操作占据…...

5分钟终极指南:在Blender中完美导入Rhino 3dm文件的完整教程
5分钟终极指南:在Blender中完美导入Rhino 3dm文件的完整教程 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 你是否正在寻找一种简单、快速且免费的方法,…...

ComfyUI-Manager 3步深度优化:构建稳定高效的AI工作流管理平台
ComfyUI-Manager 3步深度优化:构建稳定高效的AI工作流管理平台 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vario…...

2026年冰袋吸水粉厂家大揭秘:选择指南与行业趋势题
随着冷链物流行业的快速发展,冰袋吸水粉作为冷链运输中不可或缺的保冷材料,其市场需求持续增长。然而,市场上冰袋吸水粉的质量参差不齐,如何选择一家值得信赖的厂家成为许多采购商关注的重点。本文将从行业背景、技术特点及市场趋…...

4.AI大模型-幻觉、记忆、参数-大模型底层运行机制
内容参考于:图灵AI大模型全栈 幻觉: 大模型的幻觉主要有两种,一种是回答的答案和问的问题不搭边,就是说回答的答案是乱编的,是没有真实性的,另一种是给了AI正确的资料,但是AI并没有根据我们给的…...
)
紧急更新!MJ v6.1新增--style raw对表现主义的影响深度解析(附6种失效场景急救方案)
更多请点击: https://intelliparadigm.com 第一章:紧急更新!MJ v6.1新增--style raw对表现主义的影响深度解析(附6种失效场景急救方案) MidJourney v6.1 引入的 --style raw 参数并非简单降低美学修饰,而是…...

ROFL-Player:终极免费英雄联盟回放播放器解决方案
ROFL-Player:终极免费英雄联盟回放播放器解决方案 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player ROFL-Player是一款专门为《…...

AI 术语通俗词典:优化器
优化器是机器学习、深度学习、神经网络和人工智能中非常核心的一个术语。它用来描述:模型在得到梯度之后,如何更新权重和偏置,使损失函数逐渐变小。 换句话说,优化器是在回答:模型已经知道自己错在哪里之后,…...

告别手写代码:用达芬奇Configurator+DBC文件,5分钟搞定AUTOSAR CAN控制器配置
达芬奇ConfiguratorDBC文件:5分钟完成AUTOSAR CAN控制器高效配置指南 在汽车电子开发领域,AUTOSAR架构的普及使得嵌入式软件开发流程日益标准化,但随之而来的配置复杂度也让许多工程师头疼。特别是在CAN通信配置环节,传统的手动逐…...
)
告别U盘!用PXE网络批量装UOS,一台电脑搞定所有(附Arm/Mips/X86全架构配置)
告别U盘!用PXE网络批量装UOS,一台电脑搞定所有(附Arm/Mips/X86全架构配置) 在国产化替代的大背景下,UOS操作系统凭借其出色的兼容性和安全性,正被越来越多的企业和机构采用。然而,当面对数十台甚…...