深度学习(入门)03:监督学习
1、监督学习简介
监督学习(Supervised Learning)是一种重要的机器学习方法,它的目标是通过“已知输入特征”来预测对应的标签。在监督学习中,每一个“特征-标签”对被称为样本(example),这些样本通常包含明确的标签,用于训练模型。
1. 什么是监督学习?
监督学习的核心在于构建一个模型,将输入特征映射到相应的标签,从而实现预测。举一个简单的例子,假如我们需要预测某位患者是否会心脏病发作,那么“心脏病发作”或“心脏病没有发作”就是标签,而输入特征则可能是患者的生命体征,例如心率、舒张压、收缩压等。
2. 监督学习如何运作?
监督学习的运作基于一个标记过的数据集。这个数据集包含了许多样本,并且每个样本都附带真实标签。通过训练过程,模型能够学习并近似估计给定输入特征的条件概率。这种方法广泛应用于工业场景中,因为许多问题都可以被描述为“在已有数据的基础上,估计未知信息”。
常见的应用场景包括:
- 基于计算机断层扫描(CT)图像预测是否为癌症;
- 根据英语句子预测正确的法语翻译;
- 根据本月财务数据预测下个月的股票价格。
3. 监督学习的步骤
监督学习的过程通常可以分为三个主要步骤:
-
数据采集与标签:从大量数据样本中随机选取一个子集,并获取每个样本的真实标签。这些标签有时是现成的(如患者的恢复情况),有时需要人工标记(如图像分类)。最终,这些特征和标签构成了训练数据集。
-
选择算法并训练模型:选择一个适合的有监督学习算法,并使用训练数据集作为输入,输出一个完成训练的模型。
-
模型预测:将之前未见过的样本特征输入到已经训练完成的模型中,使用模型输出的结果作为预测的标签。
下图展示了整个监督学习过程的逻辑结构:

4. 多种模型与建模决策
监督学习的模型形式多种多样,具体选择取决于输入和输出的类型、大小和数量。例如,在处理不同长度的序列数据时,我们需要使用不同的模型来进行建模。尽管一些模型可能比较简单,但在面对不同类型的问题时,往往需要进行复杂的建模决策。
2、常见的监督学习
2.1回归
回归问题的本质在于预测连续数值型输出。下面我们详细解释一下什么是连续:
“连续”是指输出的值可以在一个连续的数值范围内取任意实数,而不是仅限于某些特定的点或离散的值。简单来说,连续数值是指没有中断或离散的间隔,数据可以在一个区间内平滑变化。
例如:
-
房价预测:房价可能是100,000美元、250,000美元,甚至可以是123,456.78美元。它可以是任何值,不是固定在某些离散的类别里(比如高价、中价、低价)。
-
温度预测:温度可能是23.5℃、24.8℃等,也可以是25.123℃,温度值可以变化为任何小数点后的数,而不是仅限于整度。
-
时间预测:比如你预测一个项目完成需要10.5天,输出的时间是连续的,它可以是10天、10.1天、10.2天等等,而不是固定在整数的天数上。
连续 vs 离散
- 连续:可以取任意数值(例如:1.2、3.456、10.56789……)。
- 离散:只能取固定的值或类别(例如:1、2、3……,或类别A、类别B)。
因此,连续是指输出的值可以在某个区间内取到任何值,没有跳跃或间断。
具体来说,回归问题的目标是找到一个数学模型,将输入特征(如房屋的面积、卧室数量等)与对应的连续数值标签(如房屋价格、电影评分等)联系起来,使得模型能够根据给定的输入特征对标签进行合理的预测。
总结回归问题的本质有以下几个关键点:
-
输出是连续数值:回归问题不同于分类问题,后者的输出是离散的类别标签,而回归问题的输出是实数,可以在某个范围内取任何值。例如,房价、温度、降雨量等都是连续数值,因此属于回归问题。
-
特征与标签之间的映射关系:回归模型的任务是学习输入特征与输出标签之间的关系,通常通过拟合一个函数来描述这种关系。这个函数可以是线性的(如线性回归)或非线性的(如多项式回归、神经网络回归等)。
-
误差最小化:回归模型的目标是最小化预测值与真实值之间的差距,常见的损失函数是平方误差损失函数,即最小化预测值和实际标签值之间差异的平方和。这个过程帮助模型不断调整参数,提升预测的精确度。
-
解决“有多少”类问题:回归问题通常解决涉及“有多少”或“预测数值”的问题,比如“这栋房子的售价是多少?”或“这次手术需要多少时间?”。
因此,回归问题的本质是通过模型学习特征和数值型标签之间的映射关系,最终实现对连续值的准确预测。
2.2分类
分类(Classification)是一种监督学习任务,主要用于解决“哪一个”的问题。分类的目标是将输入数据分配到特定的类别中。换句话说,分类模型会根据给定的特征,预测一个样本属于哪个类别(class)。让我们来详细了解分类。
分类问题的核心是模型根据输入特征预测出每个类别的概率,然后选择概率最大的那个类别作为最终的输出结果。
具体来说:
- 模型输出的是每个类别的概率,比如对于一个手写数字识别模型,模型可能会输出0是5%的概率,1是10%的概率,2是85%的概率,等等。
- 最终的预测结果是概率最大的类别。在这个例子中,模型会预测数字是2,因为它的概率(85%)最高。
所以,分类问题中的模型确实会输出概率,但是最终的预测结果是根据概率最高的类别来决定的,不是直接输出最大的概率值本身。
你理解的大部分是对的,正确的表述应该是:分类模型会输出各个类别的概率,最终根据最高的概率来预测样本所属的类别。
1. 分类任务的定义
分类问题希望模型能够预测样本属于哪个类别。每个类别代表不同的分类结果,例如在手写数字识别中,类别可以是数字0到9中的任意一个。分类问题的核心就是预测某个样本属于某个特定类别。
2. 分类的基本形式
-
二项分类(Binomial Classification):这是最简单的分类问题,只有两个类别。比如,判断一张图片是猫还是不是猫,这就属于二项分类。输出结果可能是{0, 1},0代表“不是猫”,1代表“是猫”。
-
多项分类(Multiclass Classification):当类别多于两个时,分类问题称为多项分类。例如,手写数字识别中,数字从0到9共10个类别,模型需要预测某个数字对应哪一个类别。
3. 分类模型的输出与不确定性
分类模型的输出通常是每个类别的概率值。假设你有一张图片,分类模型可能会预测这张图片是猫的概率为0.9(即90%确定是猫)。这个概率值表达了模型的不确定性:模型越确定某个样本属于某个类别,该类别的概率越高。
即使模型输出的概率最高的类别并不代表它绝对正确。例如,一个毒蘑菇检测分类器预测蘑菇是有毒的概率为0.2,这意味着有80%的概率蘑菇是无毒的,但我们仍然不敢冒险,因为有20%的风险可能是致命的。这说明在某些应用中,我们需要考虑风险而不仅仅是模型的预测概率。
4. 损失函数与分类问题
分类问题中常用的损失函数是交叉熵损失函数(Cross-Entropy Loss)。交叉熵衡量模型预测的概率分布与真实标签分布之间的差异,模型训练的目标是最小化这个差异,使得预测更加准确。
5. 层次分类(Hierarchical Classification)
分类问题并不总是简单的二项或多项分类,有些分类任务需要考虑类别之间的关系,这就是层次分类。在层次分类中,类别之间存在某种结构性或血缘关系。例如,动物分类中,将狮子狗误认为雪纳瑞并不是一个严重的错误,但如果把狮子狗误认为恐龙,显然是不合理的。
层次分类的问题在于错误分类的严重性会因类别的关系不同而不同。例如,将有毒的响尾蛇误认为无毒的乌梢蛇可能是致命的,而错误地将狮子狗当作雪纳瑞则没有那么严重。
6. 分类任务的应用
分类广泛应用于很多实际场景,如:
- 手写字符识别:判断手写数字属于0到9中的哪个数字。
- 图片分类:判断一张图片是猫、狗还是其他动物。
- 文本分类:判断一篇文章的主题类别,比如是体育、政治还是娱乐。
总结:
分类是解决“哪一个”问题的任务,目标是预测一个样本属于哪个类别。它分为二项分类和多项分类,输出的结果是类别的概率分布,模型会根据最高的概率选择最可能的类别。分类任务还可以处理复杂的层次结构,通过考虑类别之间的关系,减少错误分类的严重性。
2.3多标签分类
多标签分类与常见的二项或多项分类不同,它允许每个样本同时属于多个类别。下面是主要内容的概括:
-
分类问题的局限性:虽然二项分类和多项分类可以处理简单的任务(如区分猫和狗),但在复杂场景中,单一类别的分类方法可能不够。例如,面对包含多种动物的图像(如图中有猫、公鸡、狗和驴),我们希望模型能识别多个不相互排斥的类别,即多标签分类。
-
多标签分类定义:多标签分类的任务是为一个样本分配多个标签。例如,在技术博客上,一篇文章可能会被标记为“机器学习”“云计算”“Linux”等多个相关标签,因为这些概念可以同时出现。
-
实际应用:
-
假设你有一张包含猫、狗和树的图片。对于多标签分类:
- 模型会分别预测图中有“猫”的概率、有“狗”的概率、有“树”的概率。
- 输出可能是:猫(90%)、狗(85%)、树(95%)。
-
2.4搜索与排序
在信息检索领域,如网络搜索,目标不仅是找到相关的结果,还需要对结果进行排序。例如,搜索引擎通过为每个页面分配相关性分数,将最相关的结果放在前面。早期的谷歌使用 PageRank 算法为页面评分,现代搜索引擎则结合机器学习和用户行为来提高搜索结果的准确性和排序质量。
搜索与排序的核心在于找到最相关的结果并以合适的顺序呈现给用户。具体来说:
-
相关性:在搜索任务中,核心目标是根据用户的查询,从海量数据中检索出最相关的内容。相关性是关键,模型需要评估每个结果与用户查询的匹配度。相关性通常通过机器学习算法、查询关键字与内容的匹配程度、以及用户行为数据来衡量。
-
排序:找到相关结果后,排序是另一个核心步骤。不同的结果可能具有不同的相关性,排序的任务是确保最符合用户需求的结果排在前面。排序依赖于相关性分数,也可以结合其他因素,如点击率、页面质量、用户个性化偏好等。
-
用户体验:搜索和排序的最终目标是优化用户体验,确保用户在最短的时间内找到最需要的信息。因此,排序不仅要准确反映结果的相关性,还要满足用户的直观需求和行为模式。
总结
搜索的核心在于从海量信息中找到最相关的内容,排序的核心则是确保这些相关结果按照相关性高低排列,以提升用户的检索效率和体验。
2.5序列学习
1. 序列学习的特点:
- 序列学习处理可变长度的输入和输出,与传统机器学习中固定大小的输入和输出不同。模型不仅需要处理当前的输入,还需要记住历史信息,因为输入间往往有顺序或时间上的关系。
- 常见的应用场景包括:视频处理、语言翻译、语音识别、医学监控等。
2. 序列学习的应用:
- 视频处理:视频由连续帧组成,每帧之间的信息是相关的,模型需要记住前一帧的信息来理解后一帧。
- 医学监控:病人的生命体征是随时间变化的序列数据,模型需要综合考虑多小时的历史数据做出准确预测。
- 机器翻译:输入和输出都是文本序列,不同语言的词序和长度通常不一致,模型需要处理序列之间的对齐和转换。
- 自动语音识别:将音频序列转换为文本,音频帧和文本之间没有一一对应关系,因此模型要将长输入序列压缩成较短的输出文本。
3. 特殊序列学习任务:
- 标记和解析:对文本序列进行标记,比如识别句中的实体(命名实体识别)。
- 语音识别:从音频输入生成文本输出。
- 文本到语音:从文本输入生成音频输出,处理从短文本到长音频的转换。
- 机器翻译:将一个语言的序列转换为另一种语言,可能需要处理输入和输出顺序不一致的问题。
相关文章:
深度学习(入门)03:监督学习
1、监督学习简介 监督学习(Supervised Learning)是一种重要的机器学习方法,它的目标是通过“已知输入特征”来预测对应的标签。在监督学习中,每一个“特征-标签”对被称为样本(example),这些样…...

Django——admin创建和使用
1. Django Admin简介 Django Admin是Django框架自带的一个管理后台工具,它允许开发者通过一个直观的Web界面轻松地管理应用中的数据模型。Admin提供了模型的CRUD(Create,Read, Update, Delete)操作,以及数据的批量处理和搜索功能…...
【硬件(取消注册智慧出行连接状态的监听)】车载系统)
鸿蒙开发(NEXT/API 12)【硬件(取消注册智慧出行连接状态的监听)】车载系统
取消注册智慧出行连接状态的监听。 接口说明 接口名描述[off] (type: ‘smartMobilityStatus’, smartMobilityTypes: SmartMobilityType[], callback?: Callback): void取消注册智慧出行连接状态的监听。 开发步骤** 导入Car Kit模块。 import { smartMobilityCommon } fr…...

JVM中的GC流程与对象晋升机制详解
一、垃圾回收的概念 1.1 什么是垃圾回收? 垃圾回收是自动回收不再使用的对象,从而释放内存的一种机制。通过GC,JVM能够动态地管理内存的分配与回收,避免内存泄漏和溢出。 1.2 GC的重要性 内存管理:GC自动处理对象的…...

SQL:如果字段需要排除某个值但又有空值时,不能直接用“<>”或not in
在 SQL 中,如果字段需要排除某个值但又有空值存在时,不能直接使用“<>”(不等于)或 NOT IN,是因为这些操作会把空值也考虑进去,但通常情况下可能并不希望空值被这样处理。 以下是一些解决方法&#…...

运放模块的选型参数
增益带宽积-----尤其重要: GWB 增益*带宽 压摆率: 高带宽的运放一般都是电流型运放: 注意压摆率计算公式里面的Vopp参数是放大后的电压最大值: 参数,布局一定参考数据手册!!!&…...

win10文件共享设置 - 开启局域网文件共享 - “您没有权限访问,请与网络管理员联系请求访问权限”解决方案
实现步骤: 1、在“网络和共享中心”关闭“密码保护的共享” 2、在“启用和关闭windows功能”中开启SMB文件共享支持。 3、在磁盘安全选项中添加“everyone”用户(重点!) 详细操作: https://blog.csdn.net/Skyirm/a…...

Go基础编程 - 16 - 方法
方法 概述1. 方法定义2. 值方法、指针方法3. 方法集合 匿名字段表达式自定义 error 上一篇:延迟调用(defer) 概述 1. 方法定义 func (receiver T) 方法名(参数列表) (返回值列表){}receiver:接收者参数名T…...

接口报错500InvalidPropertyException: Invalid property ‘xxx[256]‘,@InitBinder的使用
org.springframework.beans.InvalidPropertyException: Invalid property ‘xxx[256]’ of bean class [com.xxl.MailHead]: Invalid list index in property path ‘xxx[256]’; nested exception is java.lang.IndexOutOfBoundsException: Index: 256, Size: 256 从报错可以…...

Web 3.0 介绍
Web 3.0 是互联网的下一代发展阶段,通常被称为去中心化的网络。它与目前的 Web 2.0(以社交媒体、云计算和中心化平台为主导)不同,强调用户对数据和内容的更多掌控,依靠区块链、加密货币、去中心化应用(DApp…...

一起搭WPF界面之界面切换绑定
一起搭WPF界面之界面切换绑定 前言界面填充总结 前言 在主界面中定义Grid网格,界面网格化后,可以模块化搭建界面进行填充。 界面填充 总结 提示:这里对文章进行总结: 例如:以上就是今天要讲的内容,本文仅…...

css 数字比汉字要靠上
这个问题通常是由于数字字体的下排的问题造成的,也就是数字的底部边缘位置比汉字的顶部边缘位置更靠下。为了解决这个问题,可以尝试以下几种方法: 使用CSS的vertical-align属性来调整对齐方式。例如,可以将数字的对齐方式设置为to…...

sentinel原理源码分析系列(三)-启动和初始化
本文是sentinel原理源码分析系列第三篇,分析sentinel启动和初始化 启动/初始化 sentinel初始化分两块,静态初始和适配器(包括aop) 静态初始 1. Root EntranceNode 如果我们用一栋楼类比资源调用,root EntranceNode好比一栋楼的大门&…...

计算机网络(九) —— Tcp协议详解
目录 一,关于Tcp协议 二,Tcp报头字段解析 2.0 协议字段图示 2.1 两个老问题 2.2 16位窗口大小 2.3 32位序号和确认序号 2.4 6个标记位 三,Tcp保证可靠性策略 3.1 确认应答机制(核心) 3.2 超时重传机制 3.3 …...

跨境支付专业术语
跨境支付 跨境支付是指支付或者清结算过程发生在两个及以上的国家地区之间、实现了资金跨国跨地区转移的支付行为。 境外本地支付 境外本地支付是指支付和清结算过程同时发生在单个国家或地区境内,资金在本国家或地区内部转移的支付行为。 国际汇款 国际汇款指跨…...

多级目录SQL分层查询
需求:有多级目录,而目录的层级是不固定的,如下图所示: 数据结构: sql语句: <select id"getList" resultType"com.hikvision.idatafusion.dhidata.bean.vo.knowledgebase.KnowledgeBaseT…...
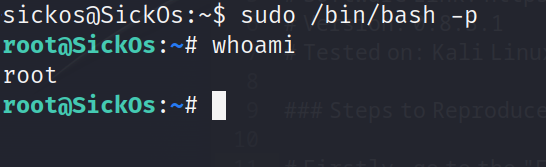
VulnHub-SickOs1.1靶机笔记
SickOs1.1靶机笔记 概述 Vulnhub的靶机sickos1.1 主要练习从互联网上搜取信息的能力,还考察了对代理使用,目录爆破的能力,很不错的靶机 靶机地址: 链接: https://pan.baidu.com/s/1JOTvKbfT-IpcgypcxaCEyQ?pwdytad 提取码: yt…...

【Python】数据可视化之点线图
目录 散点图 气泡图 时序图 关系图 散点图 Scatterplot(散点图)是一种用于展示两个变量之间关系的图表类型。在散点图中,每个观测值(或数据点)都被表示为一个点,其中横轴(…...

jupyter使用pytorch
1、激活环境 以下所有命令都在Anaconda Prompt中操作。 conda activate 环境名称我的环境名称是myenv 如果不知道自己的pytorch配在哪个环境,就用下面方法挨个试。 2、安装jupyter 1、安装 pip install jupyter2、如果已经安装,检查jupyter是否已…...

Electron 安装以及搭建一个工程
安装Node.js 在使用Electron进行开发之前,需要安装 Node.js。 官方建议使用最新的LTS版本。 检查 Node.js 是否正确安装: # 查看node版本 node -v # 查看npm版本 npm -v注意 开发者需要在开发环境安装 Node.js 才能编写 Electron 项目,但是…...

RePKG终极指南:如何深度解析Wallpaper Engine资源包与TEX纹理转换
RePKG终极指南:如何深度解析Wallpaper Engine资源包与TEX纹理转换 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg RePKG是一款专为Wallpaper Engine设计的专业级资源包解…...

网盘直链解析工具终极指南:如何3分钟实现9大网盘下载加速
网盘直链解析工具终极指南:如何3分钟实现9大网盘下载加速 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

Swift集成飞书API:使用feishu-swift SDK构建高效机器人
1. 项目概述:一个连接飞书与Swift生态的桥梁 最近在折腾一个内部工具,需要把服务端的一些数据变动实时同步到飞书群里,方便团队同学及时跟进。服务端是用Swift写的,而飞书官方虽然有开放的API,但直接上手去调…...

消化不良试过这5种方法,只有这一种让我坚持下来了
消化不良试过这5种方法,只有这一种让我坚持下来了消化不良这件事,困扰了我将近两年。饭后必定腹胀,吃什么都觉得撑着,有时候一顿饭消化到下一顿才算结束。做了胃镜,结论是没有器质性病变,医生说是功能性消化…...

【建筑学研究降维打击】:为什么顶尖事务所已禁用传统文献管理?NotebookLM智能溯源+跨语言规范比对实战拆解
更多请点击: https://intelliparadigm.com 第一章:NotebookLM建筑学研究辅助的范式革命 NotebookLM 作为 Google 推出的基于用户自有文档的 AI 助手,正悄然重塑建筑学研究的方法论边界。它不再依赖通用知识库的泛化回答,而是以建…...

基于Milvus混合检索与Java SpringBoot的全栈实现
阿里云有数千份产品文档,腾讯云有上万页技术规格,华为云的价格清单每天都在更新,开发者如何在浩如烟海的资料中,3秒内找到“ECS g6.2xlarge在华东区的按量计费价格”?传统关键词搜索解决不了语义理解,纯向量…...

AMD NPU加速GPT-2微调:边缘AI训练实战解析
1. AMD NPU与客户端AI训练的技术背景在AI模型部署领域,边缘计算正经历着从单纯推理到完整训练工作流的范式转变。传统上,像GPT-2这样的语言模型训练完全依赖云端GPU集群,但这种方式存在数据隐私泄露、网络延迟和持续服务依赖等固有缺陷。AMD …...

电源扰动测试与功率分析仪应用实践
1. 电源扰动测试的核心价值与行业需求在电力电子产品的研发验证阶段,电源扰动测试是评估设备可靠性的关键环节。我曾在某工业电源模块项目中,因忽视电源扰动测试导致产品在东南亚市场出现大规模故障——当地电网电压频繁跌落至170V,使得我们的…...

终极营销自动化工作流设计:工程师如何构建高效营销流程
终极营销自动化工作流设计:工程师如何构建高效营销流程 【免费下载链接】Marketing-for-Engineers A curated collection of marketing articles & tools to grow your product. 项目地址: https://gitcode.com/gh_mirrors/ma/Marketing-for-Engineers …...

DotNext内存映射文件:高性能IO操作的终极解决方案
DotNext内存映射文件:高性能IO操作的终极解决方案 【免费下载链接】dotNext Next generation API for .NET 项目地址: https://gitcode.com/gh_mirrors/do/dotNext DotNext作为下一代.NET API,提供了强大的内存映射文件功能,为开发者带…...