Pyspark_结构化流4
Pyspark
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Pyspark_结构化流4
#博学谷IT学习技术支持
文章目录
- Pyspark
- 前言
- 一、数据模拟器代码
- 二、需求说明和代码实现
- 总结
前言
接上次继续Pyspark_结构化流,今天主要是一个结构化流结合kafka的一个小案例。
一、数据模拟器代码
1- 创建一个topic, 放置后续物联网数据: search-log-topic
./kafka-topics.sh --create --zookeeper node1:2181 --topic search-log-topic --partitions 3 --replication-factor 2
import json
import random
import time
import os
from kafka import KafkaProducer# 锁定远端操作环境, 避免存在多个版本环境的问题
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"# 快捷键: main 回车
if __name__ == '__main__':print("模拟物联网数据")# 1- 构建一个kafka的生产者:producer = KafkaProducer(bootstrap_servers=['node1:9092', 'node2:9092', 'node3:9092'],acks='all',value_serializer=lambda m: json.dumps(m).encode("utf-8"))# 2- 物联网设备类型deviceTypes = ["洗衣机", "油烟机", "空调", "窗帘", "灯", "窗户", "煤气报警器", "水表", "燃气表"]while True:index = random.choice(range(0, len(deviceTypes)))deviceID = f'device_{index}_{random.randrange(1, 20)}'deviceType = deviceTypes[index]deviceSignal = random.choice(range(10, 100))# 组装数据集print({'deviceID': deviceID, 'deviceType': deviceType, 'deviceSignal': deviceSignal,'time': time.strftime('%s')})# 发送数据producer.send(topic='search-log-topic',value={'deviceID': deviceID, 'deviceType': deviceType, 'deviceSignal': deviceSignal,'time': time.strftime('%s')})# 间隔时间 5s内随机time.sleep(random.choice(range(1, 5)))生成的kafka数据
{‘deviceID’: ‘device_0_14’, ‘deviceType’: ‘洗衣机’, ‘deviceSignal’: 18, ‘time’: ‘1680157073’}
{‘deviceID’: ‘device_2_8’, ‘deviceType’: ‘空调’, ‘deviceSignal’: 30, ‘time’: ‘1680157074’}
{‘deviceID’: ‘device_0_17’, ‘deviceType’: ‘洗衣机’, ‘deviceSignal’: 84, ‘time’: ‘1680157076’}
{‘deviceID’: ‘device_2_15’, ‘deviceType’: ‘空调’, ‘deviceSignal’: 99, ‘time’: ‘1680157078’}
{‘deviceID’: ‘device_1_17’, ‘deviceType’: ‘油烟机’, ‘deviceSignal’: 50, ‘time’: ‘1680157081’}
二、需求说明和代码实现
求: 各种信号强度>30的设备的各个类型的数量和平均信号强度,先过滤再聚合
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
import os# 锁定远端环境, 确保环境统一
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("综合案例: 物联网案例实现")# 1- 创建SparkSession对象spark = SparkSession.builder \.appName('file_source') \.master('local[1]') \.config('spark.sql.shuffle.partitions', 4) \.getOrCreate()# 2- 从Kafka中读取消息数据df = spark.readStream \.format('kafka') \.option('kafka.bootstrap.servers', 'node1:9092,node2:9092,node3:9092') \.option('subscribe', 'search-log-topic') \.option('startingOffsets', 'earliest') \.load()# 3- 处理数据# 求: 各种信号强度>30的设备的各个类型的数量和平均信号强度,先过滤再聚合# 数据: {'deviceID': 'device_4_4', 'deviceType': '灯', 'deviceSignal': 20, 'time': '1677243108'}df = df.selectExpr('CAST(value AS STRING)')# 思考 如何做呢?# 需要将这个Json字符串中各个字段都获取出来, 形成一个多列的数据# 专业名称: JSON拉平# 涉及函数: get_json_object() json_tuple()# df.createTempView('t1')# SQL# df = spark.sql("""# select# get_json_object(value,'$.deviceID') as deviceID,# get_json_object(value,'$.deviceType') as deviceType,# get_json_object(value,'$.deviceSignal') as deviceSignal,# get_json_object(value,'$.time') as time# from t1# """)# df = spark.sql("""# select# json_tuple(value,'deviceID','deviceType','deviceSignal','time') as (deviceID,deviceType,deviceSignal,time)# from t1# """)# DSL# df = df.select(# F.get_json_object('value', '$.deviceID').alias('deviceID'),# F.get_json_object('value','$.deviceType').alias('deviceType'),# F.get_json_object('value','$.deviceSignal').alias('deviceSignal'),# F.get_json_object('value','$.time').alias('time')# )df = df.select(F.json_tuple('value', 'deviceID', 'deviceType', 'deviceSignal', 'time').alias('deviceID', 'deviceType','deviceSignal', 'time'))# 求: 各种信号强度>30的设备的各个类型的数量和平均信号强度,先过滤再聚合df = df.where(df['deviceSignal'] > 30).groupBy('deviceType').agg(F.count('deviceID').alias('device_cnt'),F.round(F.avg('deviceSignal'), 2).alias('deviceSignal_avg'))# 4- 打印结果df.writeStream.format('console').outputMode('complete').start().awaitTermination()总结
今天主要和大家分享了如何用Pyspark_结构化流结合kafka模拟物连网小案例。
相关文章:

Pyspark_结构化流4
Pyspark 注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hi…...

Linux cmp 命令
Linux cmp 命令用于比较两个文件是否有差异。 当相互比较的两个文件完全一样时,则该指令不会显示任何信息。若发现有所差异,预设会标示出第一个不同之处的字符和列数编号。若不指定任何文件名称或是所给予的文件名为"-",则cmp指令…...

Python入门到高级【第五章】
预计更新第一章. Python 简介 Python 简介和历史Python 特点和优势安装 Python 第二章. 变量和数据类型 变量和标识符基本数据类型:数字、字符串、布尔值等字符串操作列表、元组和字典 第三章. 控制语句和函数 分支结构:if/else 语句循环结构&#…...

C语言中(i++)+ (i++)真的每次都等于3吗?
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言结论证明首先,登场的是我们的VC6.0(还有Linux)最后一位,我使用了小熊猫C(还有Clion)请添加…...

Cursor,程序员的 AI 代码编辑助手
相信大家都或多或少地听说过、了解过 chatGPT ,半个月前发布的 GPT-4 ,可谓是 AI 赛道上的一个王炸 那么今天咸鱼给大家分享一个开源的 AI 代码编辑器——Cursor,让各位程序员在编程之路上一骑绝尘 😃 介绍 Cursor 是一个人工智…...
基于XML的自动装配~
基于XML的自动装配之场景模拟: 自动装配:根据指定的策略,在IOC容器中匹配某一个bean,自动为指定的bean中所依赖的类类型或者接口类型赋值 之前我们学过的依赖注入,我们在为不同属性赋值时,例如类类型的属性…...
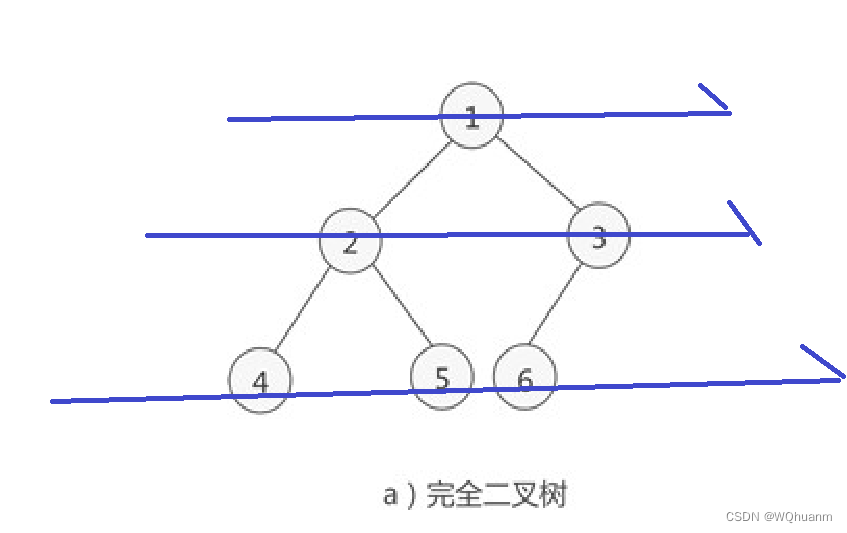
完全二叉树的4种遍历方式
一张二叉树的图 1,二叉树的特点 每个点p的左儿子是p*2,右儿子是p*21,可以分别表示为p<<1与p<<1|1节点的序号是从左到右,从上到下增加的每个点至多2个儿子(屁话(bushi)) 2ÿ…...
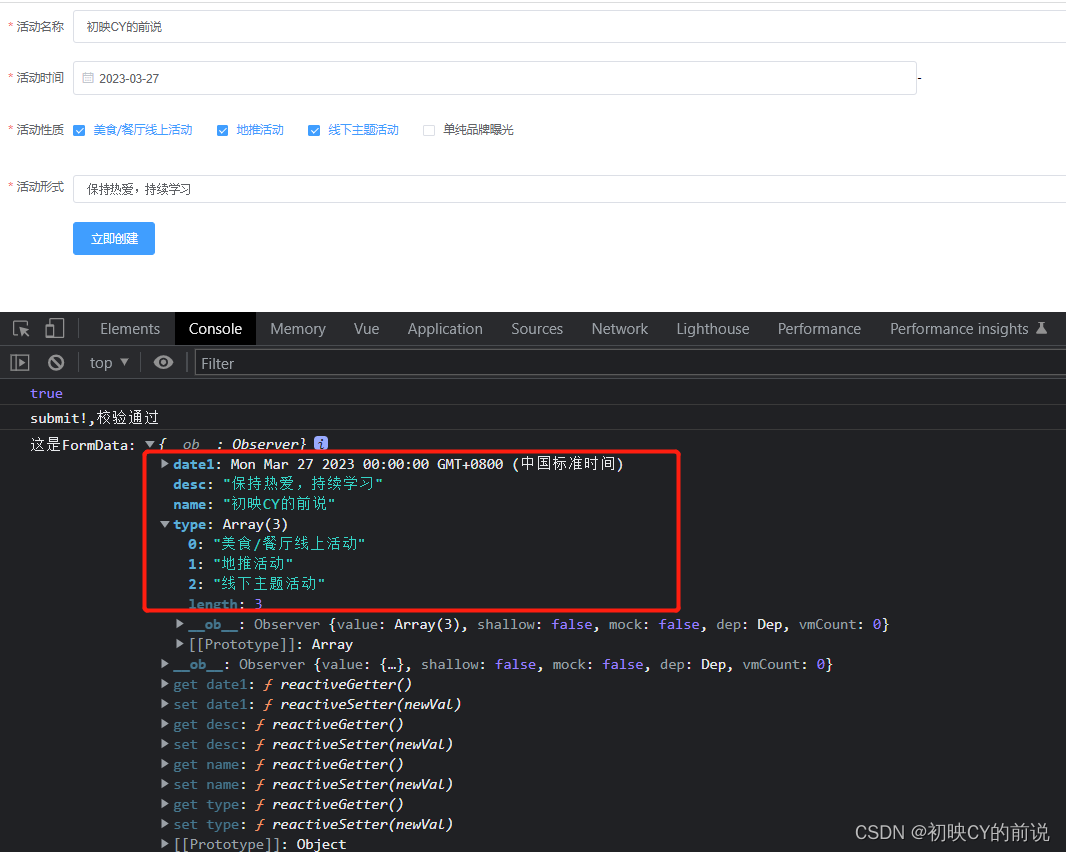
【vue2】使用elementUI进行表单验证实操(附源码)
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:vue使用elementUI进行表单验证实操(附源码) 【前言】我们在构建一…...

JUC之阻塞队列解读(BlockingQueue)
目录 BlockingQueue 简介 BlockingQueue 核心方法 1.放入数据 2.获取数据 入门代码案例 常见的 BlockingQueue ArrayBlockingQueue(常用) LinkedBlockingQueue(常用) PriorityBlockingQueue SynchronousQueue LinkedTransferQueue LinkedBlockingDeque 小结 Bloc…...
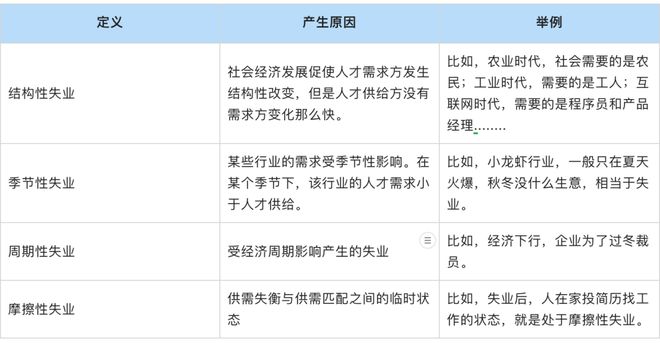
LCHub:ChatGPT4和低代码来临,程序员面临下岗?
一个网友吐槽道: “ 建站出来了,你们说程序员会失业。 低代码出来了,你们说程序员会失业。 Copilot出来了,你们说程序员会失业。 Chatgpt出来了,你们说程序员会失业 虽然这只是网友的吐槽,但却引起了小编的好奇。为何程序员那么容易被新技术取代?今天小编打算跟大家…...
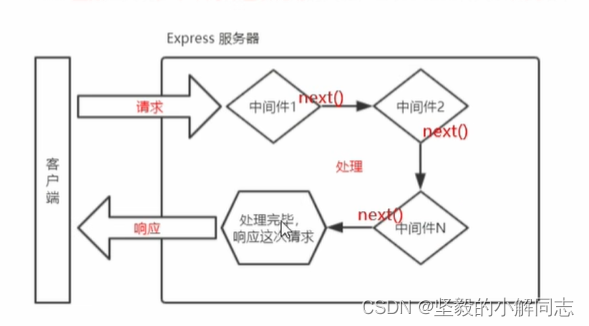
【Node.js】Express框架的基本使用
✍️ 作者简介: 前端新手学习中。 💂 作者主页: 作者主页查看更多前端教学 🎓 专栏分享:css重难点教学 Node.js教学 从头开始学习 目录 初识Express Express简介 什么是Express 进一步理解 Express Express能做什么 Express的基本使用 …...
使用docker 和 kubnernetes 部署单节点/多节点 kafka 环境
参考资料 https://kafka.apachecn.org/documentation.html#configuration kafka的broker有三个核心配置 broker.idlog.dirszookeeper.connect docker启动单节点kafka环境 启动zookeeper 可配置的环境变量,https://gallery.ecr.aws/bitnami/zookeeper $ docker …...
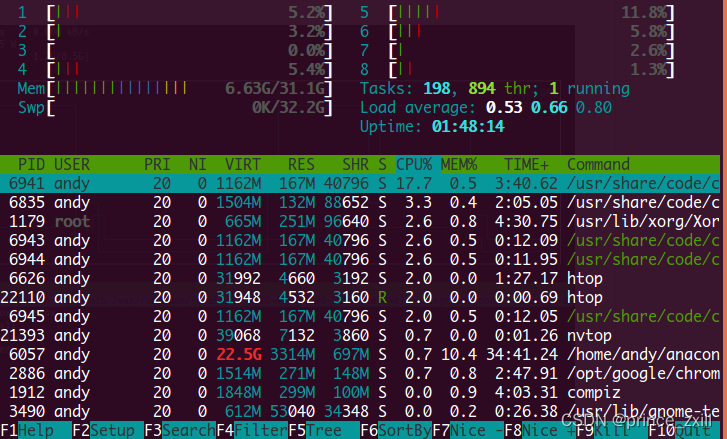
Linux使用:环境变量指南和CPU和GPU利用情况查看
Linux使用:环境变量指南和CPU和GPU利用情况查看Linux环境变量初始化与对应文件的生效顺序Linux的变量种类设置环境变量直接运行export命令定义变量修改系统环境变量修改用户环境变量修改环境变量配置文件环境配置文件的区别profile、 bashrc、.bash_profile、 .bash…...
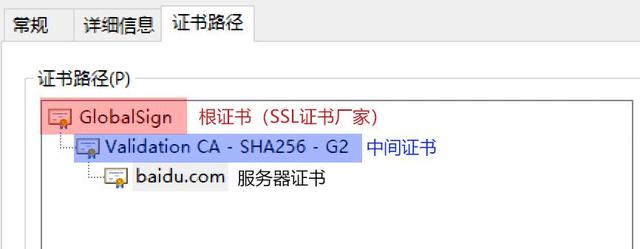
深入浅出 SSL/CA 证书及其相关证书文件(pem、crt、cer、key、csr)
互联网是虚拟的,通过互联网我们无法正确获取对方真实身份。数字证书是网络世界中的身份证,数字证书为实现双方安全通信提供了电子认证。数字证书中含有密钥对所有者的识别信息,通过验证识别信息的真伪实现对证书持有者身份的认证。数字证书可…...
 - 概念 基本使用)
Compose(1/N) - 概念 基本使用
一、概念 1.1 解决的问题 APP展示的数据绝大多数不是静态数据而是会实时更新,传统的命令式UI写法更新界面繁琐且容易同步错误。1.2 Compose优势 由一个个可组合的Composable函数(可看作是一个Layout布局)拼成界面,方便维护和复用…...
2023高质量Java面试题集锦:高级Java工程师面试八股汇总
人人都想进大厂,当然我也不例外。早在春招的时候我就有向某某某大厂投岗了不少简历,可惜了,疫情期间都是远程面试,加上那时自身也有问题,导致屡投屡败。突然也意识到自己肚子里没啥货,问个啥都是卡卡卡卡&a…...

MySQL多表查询 子查询效率(DQL语句)
多表关系 项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种: 一对多(多…...
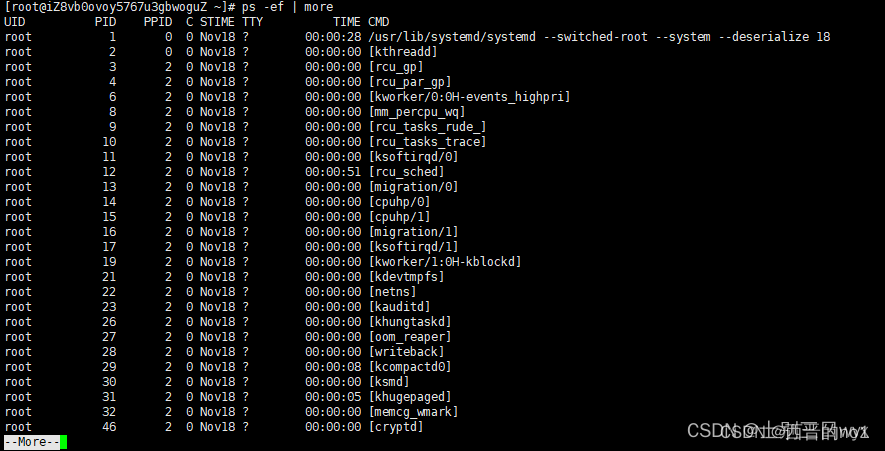
Linux中 ps命令详解
一、基础概念 指令: ps 作用:查看系统进程,比如正在运行的进程有哪些,什么时候开始运行的,哪个用户运行的,占用了多少资源。 参数: -e 显示所有进程-f 显示所有字段(UID&…...

【Python语言基础】——Python 关键字
Python语言基础——Python 关键字 文章目录Python语言基础——Python 关键字一、Python 关键字一、Python 关键字 Python 有一组关键字,这些关键字是保留字,不能用作变量名、函数名或任何其他标识符: 关键字 描述 and 逻辑运算符。 as 创建别…...
关键字和保留字)
Java SE 基础(8)关键字和保留字
关键字 定义:被Java 语言赋予了特殊含义,用做专门用途的字符串(单词) 特点: 关键字中所有字母都为小写 用于定义数据类型的关键字 class、interface、 enum 、byte 、short、 int 、long、 float、 double、 char 、…...

【人生底稿 28】新疆出差终章:几番波折终汇报,尽兴踏归津门路
三日游玩尽数落幕,忙碌工作正式回归。轻松的闲暇时光悄然收尾,紧绷的工作状态再次上线。整趟新疆之行,在起伏辗转中迎来最终收尾。一、深夜复盘材料,彻夜待汇报游玩结束回到酒店,我没有松懈休息,静下心重新…...

高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题
高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题 解析几何作为高考数学的压轴题型,常常让考生望而生畏。面对复杂的计算和抽象的条件,如何在有限时间内快速找到突破口?极点极线理论作为高等几何中的重要工具&#x…...

进化算法驱动机械爪设计优化:从原理到EvoClaw项目实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“EvoClaw”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“进化算法驱动的机械爪设计优化”的开源项目。简单来说,就是利用计算机…...

猫抓插件:5分钟掌握浏览器资源嗅探的终极武器
猫抓插件:5分钟掌握浏览器资源嗅探的终极武器 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容无处不在的今天,你…...

如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南
如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...

数据流编排与异步任务调度中间件kelivo部署与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫“Chevey339/kelivo”。乍一看这个标题,可能有点摸不着头脑,它不像那些直接告诉你“XX管理系统”或“XX工具库”的项目名那么直白。但恰恰是这种看似神秘的命名,背后往往隐藏…...

从单体智能到组织智能:AgentOrg多智能体系统架构与实战
1. 项目概述:从单体智能到组织智能的范式跃迁最近在AI Agent领域,一个名为“AgentOrg”的开源项目引起了我的注意。这个由Angelopvtac发起的项目,其核心思想非常吸引人:它不再将AI Agent视为一个孤立的、执行单一任务的智能体&…...

系统管理员AI编程实战:基于Claude的运维自动化脚本开发指南
1. 项目概述:一个面向系统管理员的Claude-Code学习与实践仓库最近在整理自己的技术栈时,发现很多系统管理员同行对如何将大型语言模型(LLM)高效地融入日常运维工作流感到困惑。大家普遍觉得这些AI工具很强大,但具体到写…...

树莓派5驱动128x128 LED矩阵:打造复古PICO-8游戏艺术墙
1. 项目概述与核心思路我一直对复古游戏和像素艺术情有独钟,也一直想在家里弄一个既有科技感又能玩的装饰品。最近,我把树莓派5、四块64x64的RGB LED矩阵面板和PICO-8幻想游戏机捣鼓到了一起,成功在墙上挂起了一个128x128像素的“游戏艺术墙”…...