第13章_事务基础知识
第13章_事务基础知识
🏠个人主页:shark-Gao
🧑个人简介:大家好,我是shark-Gao,一个想要与大家共同进步的男人😉😉
🎉目前状况:23届毕业生,目前在某公司实习👏👏
❤️欢迎大家:这里是CSDN,我总结知识的地方,欢迎来到我的博客,我亲爱的大佬😘
🖥️个人小站 :个人博客,欢迎大家访问
配套视频参考:MySQL数据库天花板–康师傅
1. 数据库事务概述
1.1 存储引擎支持情况
SHOW ENGINES 命令来查看当前 MySQL 支持的存储引擎都有哪些,以及这些存储引擎是否支持事务。
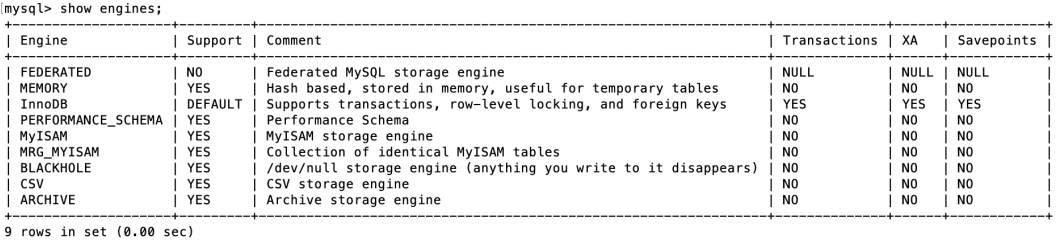
能看出在 MySQL 中,只有InnoDB 是支持事务的。
1.2 基本概念
**事务:**一组逻辑操作单元,使数据从一种状态变换到另一种状态。
**事务处理的原则:**保证所有事务都作为 一个工作单元 来执行,即使出现了故障,都不能改变这种执行方 式。当在一个事务中执行多个操作时,要么所有的事务都被提交( commit ),那么这些修改就 永久 地保 存下来;要么数据库管理系统将 放弃 所作的所有 修改 ,整个事务回滚( rollback )到最初状态。
# 案例:AA用户给BB用户转账100
update account set money = money - 100 where name = 'AA';
# 服务器宕机
update account set money = money + 100 where name = 'BB';
1.3 事务的ACID特性
- 原子性(atomicity):
原子性是指事务是一个不可分割的工作单位,要么全部提交,要么全部失败回滚。即要么转账成功,要么转账失败,是不存在中间的状态。如果无法保证原子性会怎么样?就会出现数据不一致的情形,A账户减去100元,而B账户增加100元操作失败,系统将无故丢失100元。
- 一致性(consistency):
(国内很多网站上对一致性的阐述有误,具体你可以参考 Wikipedia 对Consistency的阐述)
根据定义,一致性是指事务执行前后,数据从一个 合法性状态 变换到另外一个 合法性状态 。这种状态是 语义上 的而不是语法上的,跟具体的业务有关。
那什么是合法的数据状态呢?满足 预定的约束 的状态就叫做合法的状态。通俗一点,这状态是由你自己来定义的(比如满足现实世界中的约束)。满足这个状态,数据就是一致的,不满足这个状态,数据就 是不一致的!如果事务中的某个操作失败了,系统就会自动撤销当前正在执行的事务,返回到事务操作 之前的状态。
**举例1:**A账户有200元,转账300元出去,此时A账户余额为-100元。你自然就发现此时数据是不一致的,为什么呢?因为你定义了一个状态,余额这列必须>=0。
**举例2:**A账户有200元,转账50元给B账户,A账户的钱扣了,但是B账户因为各种意外,余额并没有增加。你也知道此时的数据是不一致的,为什么呢?因为你定义了一个状态,要求A+B的总余额必须不变。
**举例3:**在数据表中我们将姓名字段设置为唯一性约束,这时当事务进行提交或者事务发生回滚的时候,如果数据表的姓名不唯一,就破坏了事务的一致性要求。
- 隔离型(isolation):
事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能相互干扰。
如果无法保证隔离性会怎么样?假设A账户有200元,B账户0元。A账户往B账户转账两次,每次金额为50 元,分别在两个事务中执行。如果无法保证隔离性,会出现下面的情形:
UPDATE accounts SET money = money - 50 WHERE NAME = 'AA';
UPDATE accounts SET money = money + 50 WHERE NAME = 'BB';
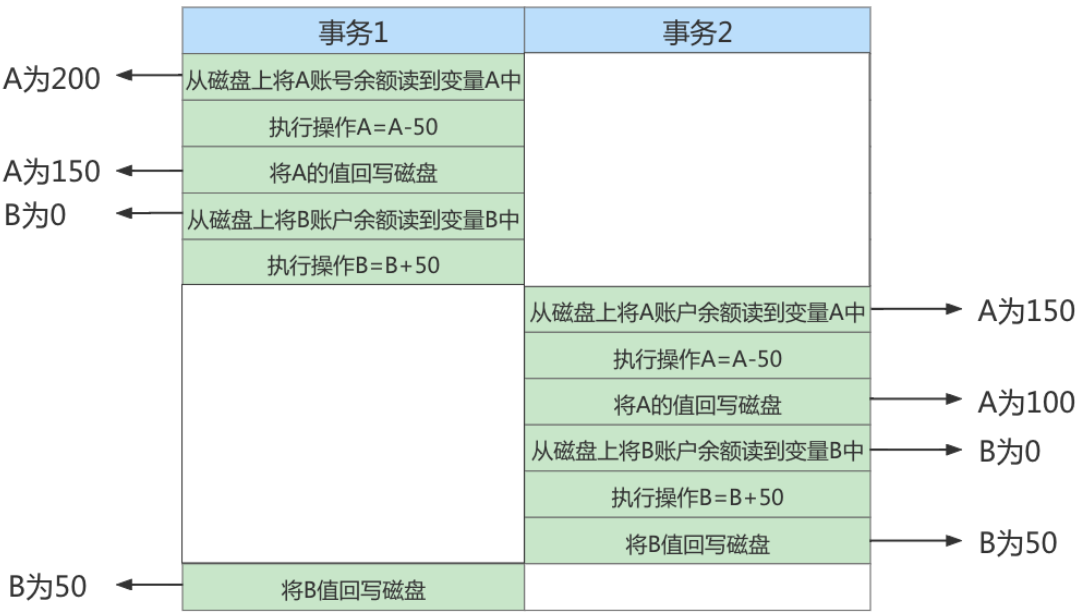
持久性(durability):
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是 永久性的 ,接下来的其他操作和数据库 故障不应该对其有任何影响。
持久性是通过 事务日志 来保证的。日志包括了 重做日志 和 回滚日志 。当我们通过事务对数据进行修改 的时候,首先会将数据库的变化信息记录到重做日志中,然后再对数据库中对应的行进行修改。这样做 的好处是,即使数据库系统崩溃,数据库重启后也能找到没有更新到数据库系统中的重做日志,重新执 行,从而使事务具有持久性。
总结
ACID是事务的四大特征,在这四个特性中,原子性是基础,隔离性是手段,一致性是约束条件, 而持久性是我们的目的。
数据库事务,其实就是数据库设计者为了方便起见,把需要保证
原子性、隔离性、一致性和持久性的一个或多个数据库操作称为一个事务。
1.4 事务的状态
我们现在知道 事务 是一个抽象的概念,它其实对应着一个或多个数据库操作,MySQL根据这些操作所执 行的不同阶段把 事务 大致划分成几个状态:
-
活动的(active)
事务对应的数据库操作正在执行过程中时,我们就说该事务处在
活动的状态。 -
部分提交的(partially committed)
当事务中的最后一个操作执行完成,但由于操作都在内存中执行,所造成的影响并
没有刷新到磁盘时,我们就说该事务处在部分提交的状态。 -
失败的(failed)
当事务处在
活动的或者 部分提交的 状态时,可能遇到了某些错误(数据库自身的错误、操作系统 错误或者直接断电等)而无法继续执行,或者人为的停止当前事务的执行,我们就说该事务处在 失 败的 状态。 -
中止的(aborted)
如果事务执行了一部分而变为
失败的状态,那么就需要把已经修改的事务中的操作还原到事务执 行前的状态。换句话说,就是要撤销失败事务对当前数据库造成的影响。我们把这个撤销的过程称之为回滚。当回滚操作执行完毕时,也就是数据库恢复到了执行事务之前的状态,我们就说该事 务处在了中止的状态。举例:
UPDATE accounts SET money = money - 50 WHERE NAME = 'AA';UPDATE accounts SET money = money + 50 WHERE NAME = 'BB'; -
提交的(committed)
当一个处在
部分提交的状态的事务将修改过的数据都同步到磁盘上之后,我们就可以说该事务处在了提交的状态。一个基本的状态转换图如下所示:
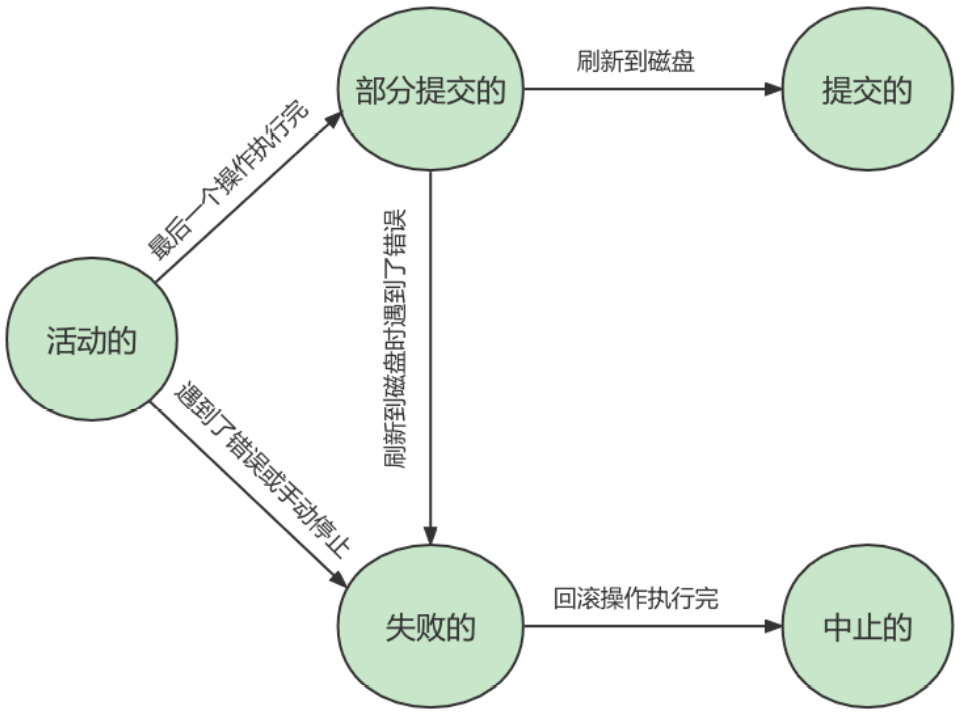
图中可见,只有当事务处于
提交的或者中止的状态时,一个事务的生命周期才算是结束了。对于已经提交的事务来说,该事务对数据库所做的修改将永久生效,对于处于中止状态的事务,该事务对数据库所做的所有修改都会被回滚到没执行该事务之前的状态。
2. 如何使用事务
使用事务有两种方式,分别为 显式事务 和 隐式事务 。
2.1 显式事务
步骤1: START TRANSACTION 或者 BEGIN ,作用是显式开启一个事务。
mysql> BEGIN;
#或者
mysql> START TRANSACTION;
START TRANSACTION 语句相较于 BEGIN 特别之处在于,后边能跟随几个 修饰符 :
① READ ONLY :标识当前事务是一个 只读事务 ,也就是属于该事务的数据库操作只能读取数据,而不能修改数据。
补充:只读事务中只是不允许修改那些其他事务也能访问到的表中的数据,对于临时表来说(我们使用 CREATE TMEPORARY TABLE 创建的表),由于它们只能再当前会话中可见,所有只读事务其实也是可以对临时表进行增、删、改操作的。
② READ WRITE :标识当前事务是一个 读写事务 ,也就是属于该事务的数据库操作既可以读取数据, 也可以修改数据。
③ WITH CONSISTENT SNAPSHOT :启动一致性读。
比如:
START TRANSACTION READ ONLY; # 开启一个只读事务
START TRANSACTION READ ONLY, WITH CONSISTENT SNAPSHOT # 开启只读事务和一致性读
START TRANSACTION READ WRITE, WITH CONSISTENT SNAPSHOT # 开启读写事务和一致性读
注意:
READ ONLY和READ WRITE是用来设置所谓的事务访问模式的,就是以只读还是读写的方式来访问数据库中的数据,一个事务的访问模式不能同时即设置为只读的也设置为读写的,所以不能同时把READ ONLY和READ WRITE放到START TRANSACTION语句后边。- 如果我们不显式指定事务的访问模式,那么该事务的访问模式就是
读写模式
**步骤2:**一系列事务中的操作(主要是DML,不含DDL)
**步骤3:**提交事务 或 中止事务(即回滚事务)
# 提交事务。当提交事务后,对数据库的修改是永久性的。
mysql> COMMIT;
# 回滚事务。即撤销正在进行的所有没有提交的修改
mysql> ROLLBACK;# 将事务回滚到某个保存点。
mysql> ROLLBACK TO [SAVEPOINT]
其中关于SAVEPOINT相关操作有:
# 在事务中创建保存点,方便后续针对保存点进行回滚。一个事务中可以存在多个保存点。
SAVEPOINT 保存点名称;
# 删除某个保存点
RELEASE SAVEPOINT 保存点名称;
2.2 隐式事务
MySQL中有一个系统变量 autocommit :
mysql> SHOW VARIABLES LIKE 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.01 sec)
当然,如果我们想关闭这种 自动提交 的功能,可以使用下边两种方法之一:
-
显式的的使用
START TRANSACTION或者BEGIN语句开启一个事务。这样在本次事务提交或者回滚前会暂时关闭掉自动提交的功能。 -
把系统变量
autocommit的值设置为OFF,就像这样:SET autocommit = OFF; #或 SET autocommit = 0;
2.3 隐式提交数据的情况
-
数据定义语言(Data definition language,缩写为:DDL)
数据库对象,指的就是
数据库、表、视图、存储过程等结构。当我们CREATE、ALTER、DROP等语句去修改数据库对象时,就会隐式的提交前边语句所属于的事务。即:BEGIN;SELECT ... # 事务中的一条语句 UPDATE ... # 事务中的一条语句 ... # 事务中的其他语句CREATE TABLE ... # 此语句会隐式的提交前边语句所属于的事务 -
隐式使用或修改mysql数据库中的表
当我们使用
ALTER USER、CREATE USER、DROP USER、GRANT、RENAME USER、REVOKE、SET PASSWORD等语句时也会隐式的提交前边语句所属于的事务。 -
事务控制或关于锁定的语句
① 当我们在一个事务还没提交或者回滚时就又使用 START TRANSACTION 或者 BEGIN 语句开启了另一个事务时,会隐式的提交上一个事务。即:
BEGIN;SELECT ... # 事务中的一条语句 UPDATE ... # 事务中的一条语句 ... # 事务中的其他语句BEGIN; # 此语句会隐式的提交前边语句所属于的事务② 当前的 autocommit 系统变量的值为 OFF ,我们手动把它调为 ON 时,也会 隐式的提交前边语句所属的事务。
③ 使用 LOCK TABLES 、 UNLOCK TABLES 等关于锁定的语句也会 隐式的提交 前边语句所属的事务。
-
加载数据的语句
使用
LOAD DATA语句来批量往数据库中导入数据时,也会隐式的提交前边语句所属的事务。 -
关于MySQL复制的一些语句
使用
START SLAVE、STOP SLAVE、RESET SLAVE、CHANGE MASTER TO等语句会隐式的提交前边语句所属的事务 -
其他的一些语句
使用
ANALYZE TABLE、CACHE INDEX、CAECK TABLE、FLUSH、LOAD INDEX INTO CACHE、OPTIMIZE TABLE、REPAIR TABLE、RESET等语句也会隐式的提交前边语句所属的事务。
2.4 使用举例1:提交与回滚
我们看下在 MySQL 的默认状态下,下面这个事务最后的处理结果是什么。
情况1:
CREATE TABLE user(name varchar(20), PRIMARY KEY (name)) ENGINE=InnoDB;BEGIN;
INSERT INTO user SELECT '张三';
COMMIT;BEGIN;
INSERT INTO user SELECT '李四';
INSERT INTO user SELECT '李四';
ROLLBACK;SELECT * FROM user;
运行结果(1 行数据):
mysql> commit;
Query OK, 0 rows affected (0.00 秒)mysql> BEGIN;
Query OK, 0 rows affected (0.00 秒)mysql> INSERT INTO user SELECT '李四';
Query OK, 1 rows affected (0.00 秒)mysql> INSERT INTO user SELECT '李四';
Duplicate entry '李四' for key 'user.PRIMARY'
mysql> ROLLBACK;
Query OK, 0 rows affected (0.01 秒)mysql> select * from user;
+--------+
| name |
+--------+
| 张三 |
+--------+
1 行于数据集 (0.01 秒)
情况2:
CREATE TABLE user (name varchar(20), PRIMARY KEY (name)) ENGINE=InnoDB;BEGIN;
INSERT INTO user SELECT '张三';
COMMIT;INSERT INTO user SELECT '李四';
INSERT INTO user SELECT '李四';
ROLLBACK;
运行结果(2 行数据):
mysql> SELECT * FROM user;
+--------+
| name |
+--------+
| 张三 |
| 李四 |
+--------+
2 行于数据集 (0.01 秒)
情况3:
CREATE TABLE user(name varchar(255), PRIMARY KEY (name)) ENGINE=InnoDB;SET @@completion_type = 1;
BEGIN;
INSERT INTO user SELECT '张三';
COMMIT;INSERT INTO user SELECT '李四';
INSERT INTO user SELECT '李四';
ROLLBACK;SELECT * FROM user;
运行结果(1 行数据):
mysql> SELECT * FROM user;
+--------+
| name |
+--------+
| 张三 |
+--------+
1 行于数据集 (0.01 秒)

当我们设置 autocommit=0 时,不论是否采用 START TRANSACTION 或者 BEGIN 的方式来开启事 务,都需要用 COMMIT 进行提交,让事务生效,使用 ROLLBACK 对事务进行回滚。
当我们设置 autocommit=1 时,每条 SQL 语句都会自动进行提交。 不过这时,如果你采用 START TRANSACTION 或者 BEGIN 的方式来显式地开启事务,那么这个事务只有在 COMMIT 时才会生效, 在 ROLLBACK 时才会回滚。
2.5 使用举例2:测试不支持事务的engine
CREATE TABLE test1(i INT) ENGINE=InnoDB;CREATE TABLE test2(i INT) ENGINE=MYISAM;
针对于InnoDB表
BEGIN;
INSERT INTO test1 VALUES(1);
ROLLBACK;SELECT * FROM test1;
结果:没有数据
针对于MYISAM表:
BEGIN;
INSERT INTO test1 VALUES(1);
ROLLBACK;SELECT * FROM test2;
结果:有一条数据
2.6 使用举例3:SAVEPOINT
创建表并添加数据:
CREATE TABLE account(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(15),
balance DECIMAL(10,2)
);INSERT INTO account(NAME,balance)
VALUES
('张三',1000),
('李四',1000);
BEGIN;
UPDATE account SET balance = balance - 100 WHERE NAME = '张三';
UPDATE account SET balance = balance - 100 WHERE NAME = '张三';
SAVEPOINT s1; # 设置保存点
UPDATE account SET balance = balance + 1 WHERE NAME = '张三';
ROLLBACK TO s1; # 回滚到保存点
结果:张三:800.00
ROLLBACK;
结果:张三:1000.00
3. 事务隔离级别
MySQL是一个 客户端/服务器 架构的软件,对于同一个服务器来说,可以有若干个客户端与之连接,每 个客户端与服务器连接上之后,就可以称为一个会话( Session )。每个客户端都可以在自己的会话中 向服务器发出请求语句,一个请求语句可能是某个事务的一部分,也就是对于服务器来说可能同时处理多个事务。事务有 隔离性 的特性,理论上在某个事务 对某个数据进行访问 时,其他事务应该进行排队 ,当该事务提交之后,其他事务才可以继续访问这个数据。但是这样对 性能影响太大 ,我们既想保持事务的隔离性,又想让服务器在处理访问同一数据的多个事务时 性能尽量高些 ,那就看二者如何权衡取 舍了。
3.1 数据准备
CREATE TABLE student (studentno INT,name VARCHAR(20),class varchar(20),PRIMARY KEY (studentno)
) Engine=InnoDB CHARSET=utf8;
然后向这个表里插入一条数据:
INSERT INTO student VALUES(1, '小谷', '1班');
现在表里的数据就是这样的:
mysql> select * from student;
+-----------+--------+-------+
| studentno | name | class |
+-----------+--------+-------+
| 1 | 小谷 | 1班 |
+-----------+--------+-------+
1 row in set (0.00 sec)
3.2 数据并发问题
针对事务的隔离性和并发性,我们怎么做取舍呢?先看一下访问相同数据的事务在 不保证串行执行 (也 就是执行完一个再执行另一个)的情况下可能会出现哪些问题:
1. 脏写( Dirty Write )
对于两个事务 Session A、Session B,如果事务Session A 修改了 另一个 未提交 事务Session B 修改过 的数据,那就意味着发生了 脏写,示意图如下:

Session A 和 Session B 各开启了一个事务,Sesssion B 中的事务先将studentno列为1的记录的name列更新为’李四’,然后Session A中的事务接着又把这条studentno列为1的记录的name列更新为’张三’。如果之后Session B中的事务进行了回滚,那么Session A中的更新也将不复存在,这种现象称之为脏写。这时Session A中的事务就没有效果了,明明把数据更新了,最后也提交事务了,最后看到的数据什么变化也没有。这里大家对事务的隔离性比较了解的话,会发现默认隔离级别下,上面Session A中的更新语句会处于等待状态,这里只是跟大家说明一下会出现这样的现象。
2. 脏读( Dirty Read )
对于两个事务 Session A、Session B,Session A 读取 了已经被 Session B 更新 但还 没有被提交 的字段。 之后若 Session B 回滚 ,Session A 读取 的内容就是 临时且无效 的。
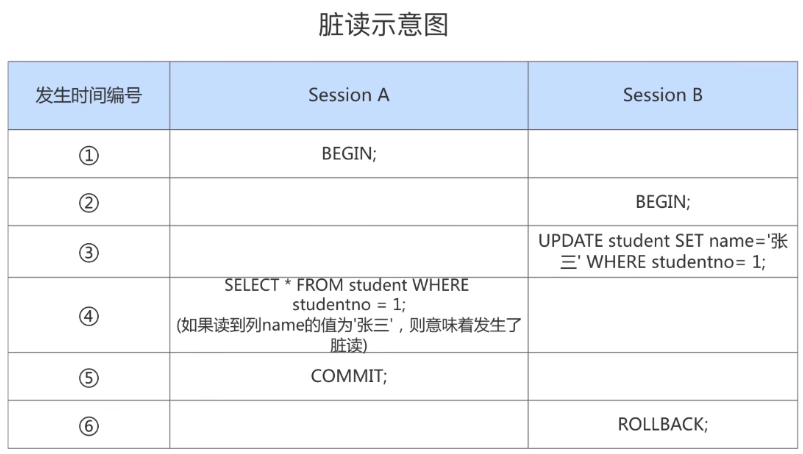
Session A和Session B各开启了一个事务,Session B中的事务先将studentno列为1的记录的name列更新 为’张三’,然后Session A中的事务再去查询这条studentno为1的记录,如果读到列name的值为’张三’,而 Session B中的事务稍后进行了回滚,那么Session A中的事务相当于读到了一个不存在的数据,这种现象就称之为 脏读 。
3. 不可重复读( Non-Repeatable Read )
对于两个事务Session A、Session B,Session A 读取了一个字段,然后 Session B 更新了该字段。 之后 Session A 再次读取 同一个字段, 值就不同 了。那就意味着发生了不可重复读。
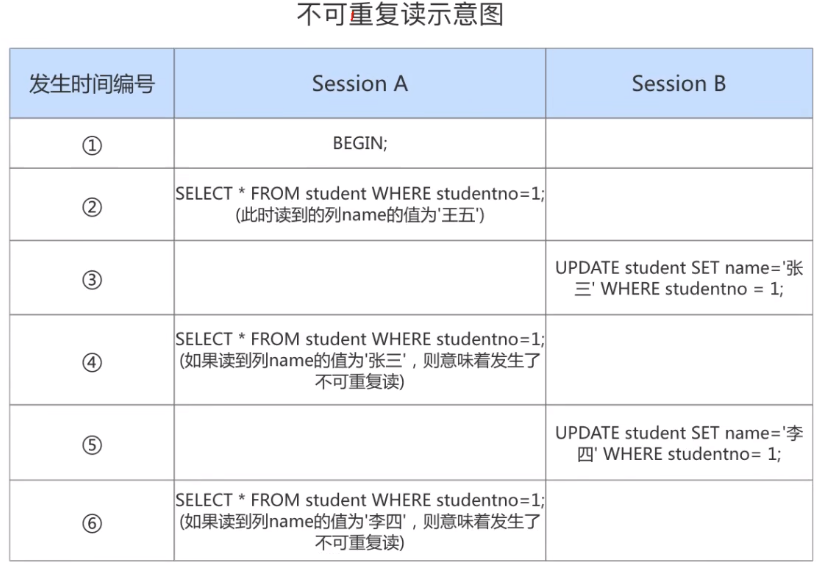
我们在Session B中提交了几个 隐式事务 (注意是隐式事务,意味着语句结束事务就提交了),这些事务 都修改了studentno列为1的记录的列name的值,每次事务提交之后,如果Session A中的事务都可以查看到最新的值,这种现象也被称之为 不可重复读 。
4. 幻读( Phantom )
对于两个事务Session A、Session B, Session A 从一个表中 读取 了一个字段, 然后 Session B 在该表中 插 入 了一些新的行。 之后, 如果 Session A 再次读取 同一个表, 就会多出几行。那就意味着发生了幻读。

Session A中的事务先根据条件 studentno > 0这个条件查询表student,得到了name列值为’张三’的记录; 之后Session B中提交了一个 隐式事务 ,该事务向表student中插入了一条新记录;之后Session A中的事务 再根据相同的条件 studentno > 0查询表student,得到的结果集中包含Session B中的事务新插入的那条记 录,这种现象也被称之为 幻读 。我们把新插入的那些记录称之为 幻影记录 。

3.3 SQL中的四种隔离级别
上面介绍了几种并发事务执行过程中可能遇到的一些问题,这些问题有轻重缓急之分,我们给这些问题 按照严重性来排一下序:
脏写 > 脏读 > 不可重复读 > 幻读
我们愿意舍弃一部分隔离性来换取一部分性能在这里就体现在:设立一些隔离级别,隔离级别越低,并发问题发生的就越多。 SQL标准 中设立了4个 隔离级别 :
READ UNCOMMITTED:读未提交,在该隔离级别,所有事务都可以看到其他未提交事务的执行结 果。不能避免脏读、不可重复读、幻读。READ COMMITTED:读已提交,它满足了隔离的简单定义:一个事务只能看见已经提交事务所做 的改变。这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。可以避免脏读,但不可 重复读、幻读问题仍然存在。REPEATABLE READ:可重复读,事务A在读到一条数据之后,此时事务B对该数据进行了修改并提 交,那么事务A再读该数据,读到的还是原来的内容。可以避免脏读、不可重复读,但幻读问题仍 然存在。这是MySQL的默认隔离级别。SERIALIZABLE:可串行化,确保事务可以从一个表中读取相同的行。在这个事务持续期间,禁止 其他事务对该表执行插入、更新和删除操作。所有的并发问题都可以避免,但性能十分低下。能避 免脏读、不可重复读和幻读。
SQL标准 中规定,针对不同的隔离级别,并发事务可以发生不同严重程度的问题,具体情况如下:
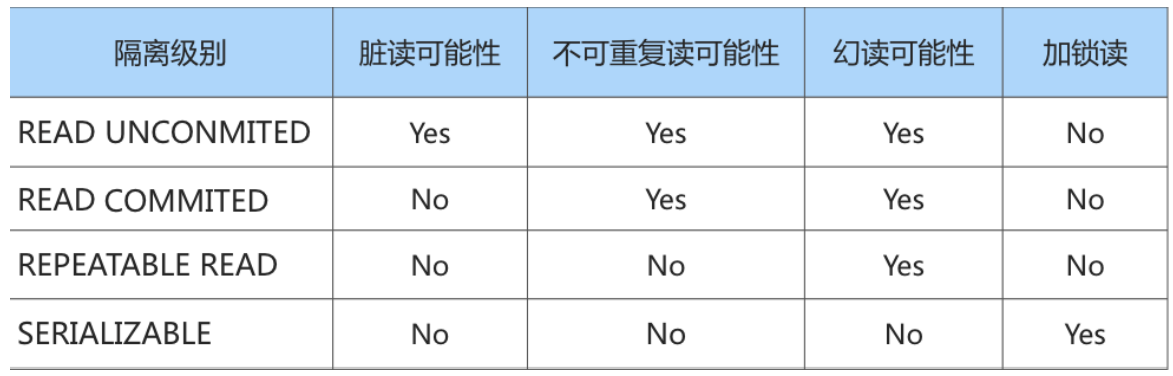
脏写 怎么没涉及到?因为脏写这个问题太严重了,不论是哪种隔离级别,都不允许脏写的情况发生。
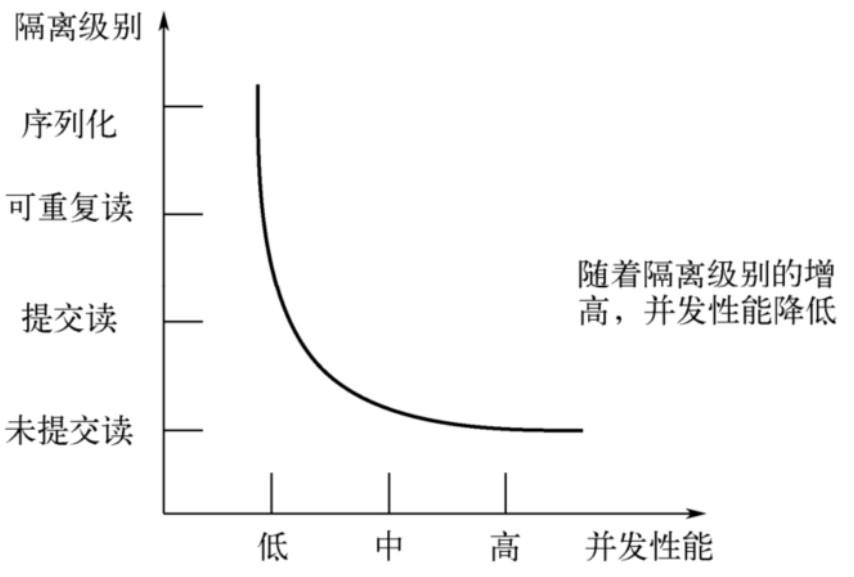
不同的隔离级别有不同的现象,并有不同的锁和并发机制,隔离级别越高,数据库的并发性能就越差,4 种事务隔离级别与并发性能的关系如下:
3.4 MySQL支持的四种隔离级别

MySQL的默认隔离级别为REPEATABLE READ,我们可以手动修改一下事务的隔离级别。
# 查看隔离级别,MySQL 5.7.20的版本之前:
mysql> SHOW VARIABLES LIKE 'tx_isolation';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| tx_isolation | REPEATABLE-READ |
+---------------+-----------------+
1 row in set (0.00 sec)
# MySQL 5.7.20版本之后,引入transaction_isolation来替换tx_isolation# 查看隔离级别,MySQL 5.7.20的版本及之后:
mysql> SHOW VARIABLES LIKE 'transaction_isolation';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+
1 row in set (0.02 sec)#或者不同MySQL版本中都可以使用的:
SELECT @@transaction_isolation;
3.5 如何设置事务的隔离级别
通过下面的语句修改事务的隔离级别:
SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL 隔离级别;
#其中,隔离级别格式:
> READ UNCOMMITTED
> READ COMMITTED
> REPEATABLE READ
> SERIALIZABLE
或者:
SET [GLOBAL|SESSION] TRANSACTION_ISOLATION = '隔离级别'
#其中,隔离级别格式:
> READ-UNCOMMITTED
> READ-COMMITTED
> REPEATABLE-READ
> SERIALIZABLE
关于设置时使用GLOBAL或SESSION的影响:
-
使用 GLOBAL 关键字(在全局范围影响):
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE; #或 SET GLOBAL TRANSACTION_ISOLATION = 'SERIALIZABLE';则:
- 当前已经存在的会话无效
- 只对执行完该语句之后产生的会话起作用
-
使用
SESSION关键字(在会话范围影响):SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; #或 SET SESSION TRANSACTION_ISOLATION = 'SERIALIZABLE';则:
- 对当前会话的所有后续的事务有效
- 如果在事务之间执行,则对后续的事务有效
- 该语句可以在已经开启的事务中间执行,但不会影响当前正在执行的事务
如果在服务器启动时想改变事务的默认隔离级别,可以修改启动参数transaction_isolation的值。比如,在启动服务器时指定了transaction_isolation=SERIALIZABLE,那么事务的默认隔离界别就从原来的REPEATABLE-READ变成了SERIALIZABLE。
小结:
数据库规定了多种事务隔离级别,不同隔离级别对应不同的干扰程度,隔离级别越高,数据一致性就越好,但并发性越弱。
3.6 不同隔离级别举例
初始化数据:
TRUNCATE TABLE account;
INSERT INTO account VALUES (1,'张三','100'), (2,'李四','0');
演示1. 读未提交之脏读
设置隔离级别为未提交读:

脏读就是指当前事务就在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问了这个数据,然后使用了这个数据。
演示2:读已提交

演示3. 不可重复读
设置隔离级别为可重复读,事务的执行流程如下:

当我们将当前会话的隔离级别设置为可重复读的时候,当前会话可以重复读,就是每次读取的结果集都相同,而不管其他事务有没有提交。但是在可重复读的隔离级别上会出现幻读的问题。
演示4:幻读


4. 事务的常见分类
从事务理论的角度来看,可以把事务分为以下几种类型:
- 扁平事务(Flat Transactions)
- 带有保存点的扁平事务(Flat Transactions with Savepoints)
- 链事务(Chained Transactions)
- 嵌套事务(Nested Transactions)
- 分布式事务(Distributed Transactions)
相关文章:
第13章_事务基础知识
第13章_事务基础知识 🏠个人主页:shark-Gao 🧑个人简介:大家好,我是shark-Gao,一个想要与大家共同进步的男人😉😉 🎉目前状况:23届毕业生,目前…...

LeetCode笔记:Biweekly Contest 101
LeetCode笔记:Biweekly Contest 101 1. 题目一 1. 解题思路2. 代码实现 2. 题目二 1. 解题思路2. 代码实现 3. 题目三 1. 解题思路2. 代码实现 4. 题目四 1. 解题思路2. 代码实现 比赛链接:https://leetcode.com/contest/biweekly-contest-101/ 1. 题…...

new和malloc两个函数详细实现与原理分析
1.申请的内存所在位置 new操作符从自由存储区(free store)上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。自由存储区是C基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储…...

[ROC-RK3568-PC] [Firefly-Android] 10min带你了解LCD的使用
🍇 博主主页: 【Systemcall小酒屋】🍇 博主追寻:热衷于用简单的案例讲述复杂的技术,“假传万卷书,真传一案例”,这是林群院士说过的一句话,另外“成就是最好的老师”,技术…...

【redis】redis分布式锁
目录一、为什么需要分布式锁二、分布式锁的实现方案三、redis分布式锁3.1 简单实现3.2 成熟的实现一、为什么需要分布式锁 1.在java单机服务中,jvm内部有一个全局的锁监视器,只有一个线程能获取到锁,可以实现线程之间的互斥 2.当有多个java服…...
UEditorPlus v3.0.0 接口请求头参数,插入换行优化,若干问题优化
UEditor是由百度开发的所见即所得的开源富文本编辑器,基于MIT开源协议,该富文本编辑器帮助不少网站开发者解决富文本编辑器的难点。 UEditorPlus 是有 ModStart 团队基于 UEditor 二次开发的富文本编辑器,主要做了样式的定制,更符…...

LabVIEW 2015介绍
这里写目录标题LabVIEW 2015安装包LabVIEW 2020安装包Labview2015安装过程1、LabVIEW 2015 的介绍2、LabVIEW 2015 的特点3、LabVIEW 2015 的功能4、LabVIEW 2015 快捷键LabVIEW 2015安装包 链接:https://pan.baidu.com/s/1I1cxtbBkmJbHvDTc5JnOyQ 提取码࿱…...

大一被忽悠进了培训班
大家好,我是帅地。 最近我的知识星球开始营业,不少大一大二的小伙伴也是纷纷加入了星球,并且咨询的问题也是五花八门,反正就是,各种迷茫,其中有一个学弟,才大一,就报考培训班&#…...

编写一个存储过程,输入一个日期,判定其距离年底还有多少天
--编写一个存储过程,输入一个日期,判定其距离年底还有多少天 create or replace procedure sp_end(i_date varchar2,o_end out varchar2) is --声明两个变量,v_end存放经过转化的年底日期,v_errm用来存放异常 v_end date; v_errm…...
HTB-Inject
HTB-Inject信息收集开机root信息收集 228080 8080端口如下。 主界面有一个上传图片的功能。 简单测试后发现对上传文件后缀名应该有过滤,只允许jpg后缀名文件上传。将一个内容为”test“的txt文件修改后缀为jpg后上传会出现错误。 验证一下是否存在LFI。 验证一…...
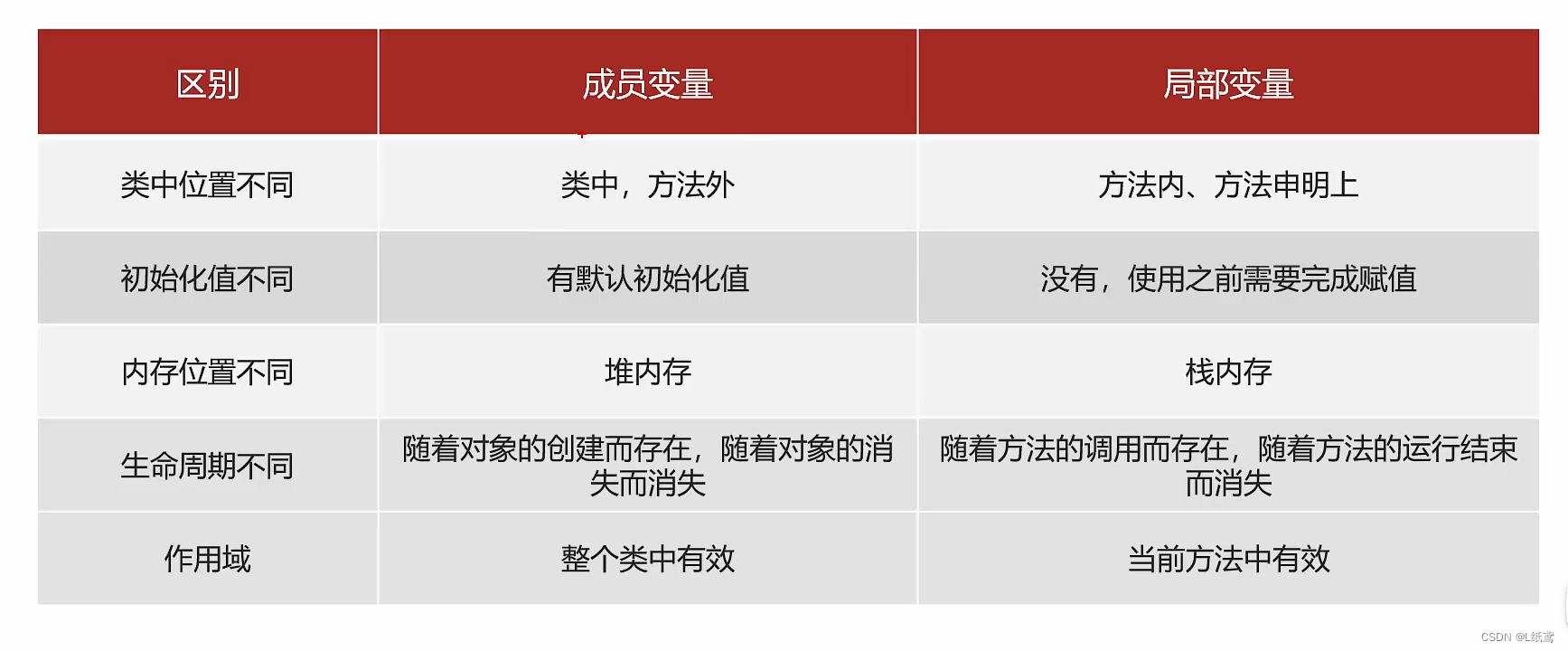
java基础知识——13.类与对象
这篇文章,我们来介绍java中的类与对象 目录 1.面向对象的介绍 2.类的设计与使用 2.1 类和对象 2.1.1 如何定义类 2.2 类的注意事项 3.封装 3.1 private关键字 4.this关键字 5.构造方法 6.标准JavaBean 7.对象内存图 8.成员变量与局部变量 1.面向对象的…...

北邮22信通:(10)第三章 3.2栈的实现
北邮22信通一枚~ 跟随课程进度每周更新数据结构与算法的代码和文章 持续关注作者 解锁更多邮苑信通专属代码~ 上一篇文章: 北邮22信通:(9)实验1 题目六:模拟内存管理(搬运官方代码)_青…...

Vue3之使用js实现动画
概述 动画的实现其实不仅可以使用CSS的方式实现,而且还可以使用js的方式实现,二者有啥区别呢?CSS更加注重动画的展现,性能更好,而js的方式性能稍微差点,但是可以在动画执行的每一个过程中做些额外的操作。…...

金三银四,你准备好面试了吗? (附30w字软件测试面试题总结)
不知不觉,已是3月下旬。最近有很多小伙伴都在跟我谈论春招面试的问题,其实对于面试,我也没有太多的经验,只能默默地把之前整理的软件测试面试题分享给Ta。今天就来大致的梳理一下软件测试的面试体系(每一部分最后都有相…...

【C语言学习】数组
数组(Array)就是一些列具有相同类型的数据的集合,这些数据在内存中依次挨着存放,彼此之间没有缝隙。 数组不是C语言的专利,Java、C、C#、JavaScript、PHP 等其他编程语言也有数组。 C语言数组属于构造数据类型。一个…...

ElasticSearch序列 - SpringBoot整合ES:根据指定的 ids 查询
文章目录1. ElasticSearch 根据 ids 查询文档2. SpringBoot整合ES实现 ids 查询1. ElasticSearch 根据 ids 查询文档 ① 索引文档,构造数据 PUT /my_index/_doc/1 {"price":10 }PUT /my_index/_doc/2 {"price":20 }PUT /my_index/_doc/3 {&qu…...
Spark SQL实战(08)-整合Hive
1 整合原理及使用 Apache Spark 是一个快速、可扩展的分布式计算引擎,而 Hive 则是一个数据仓库工具,它提供了数据存储和查询功能。在 Spark 中使用 Hive 可以提高数据处理和查询的效率。 场景 历史原因积累下来的,很多数据原先是采用Hive…...
堆(数据结构系列11)
目录 前言: 1.优先级队列概念 2.堆的概念 3.堆的存储方式 4.堆的创建 5.创建堆的时间复杂度 6.堆的插入和删除 6.1堆的插入 6.2堆的删除 结束语: 前言: 上一次博客中小编主要与大家分享了 二叉树一些相关的知识点和一些练习题&…...
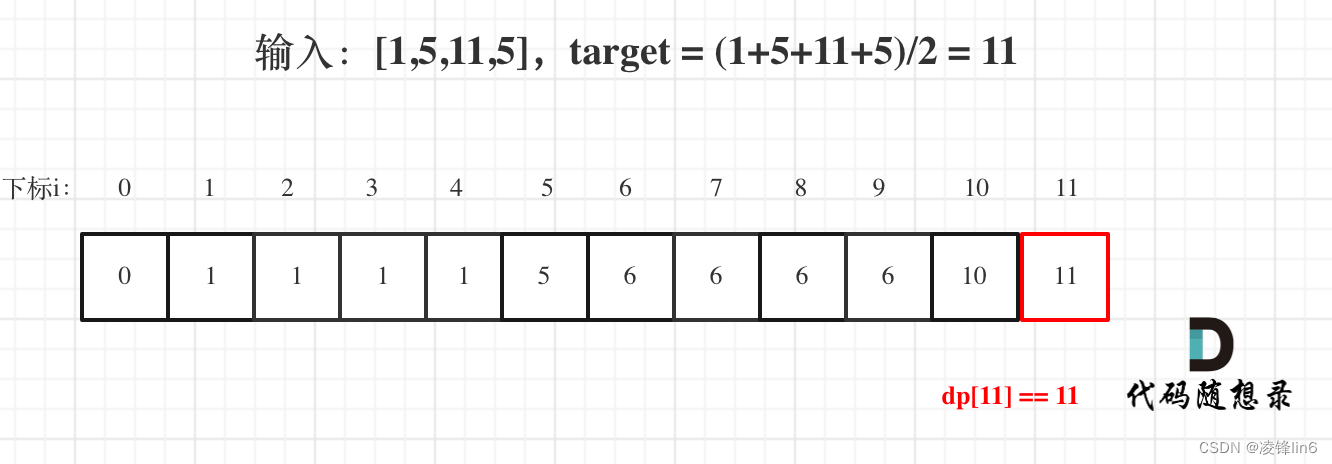
算法训练第四十二天|01背包问题 二维 、01背包问题 一维、416. 分割等和子集
动态规划part0401背包问题 二维01 背包二维dp数组01背包完整c测试代码总结01背包问题 一维一维dp数组(滚动数组)一维dp01背包完整C测试代码416. 分割等和子集题目描述思路01背包问题总结01背包问题 二维 视频链接:https://www.bilibili.com/…...
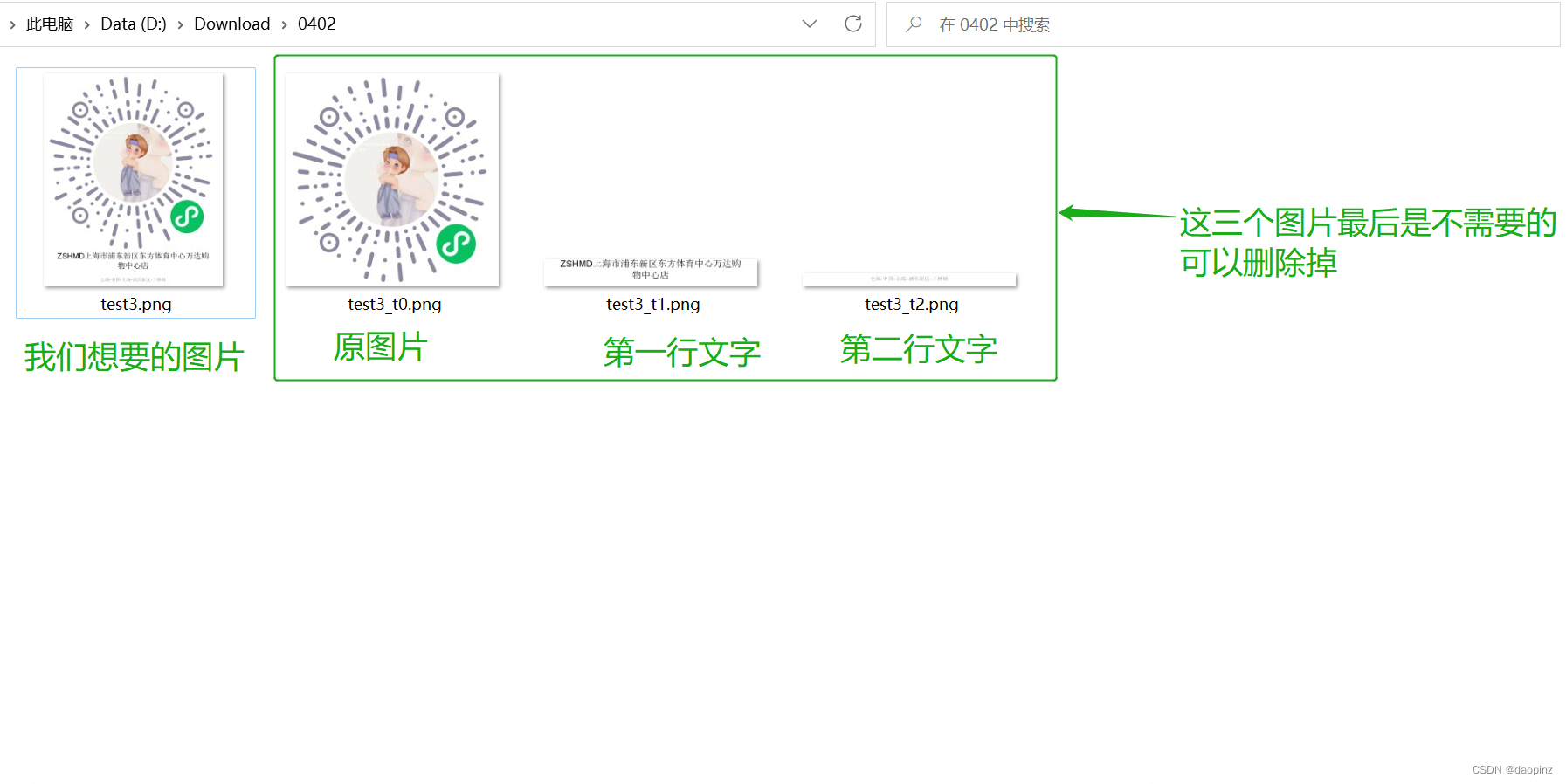
Java-如何使用Java将图片和文字拼接在一起(并非是给图片加水印)
之前有遇到一个问题 问题背景:项目中,有一个功能,管理端可以将客户创建的小程序码下载到本地,方便客户将对应门店的小程序码打印出来并张贴到门店,做门店的引流和会员入会。 具体问题:当小程序码的数量较少…...

Unity游戏接入TapTap登录,从后台配置到打包上线的完整避坑指南
Unity游戏接入TapTap登录的全流程避坑指南:从配置到上线的实战经验 在独立游戏开发领域,TapTap平台凭借其庞大的用户基础和便捷的登录系统,已成为许多开发者的首选接入方案。然而,从后台配置到最终打包上线的完整流程中࿰…...
)
手把手教你给STM32MP157开发板接上HDMI显示器(基于Sii9022A芯片与设备树配置)
STM32MP157开发板HDMI显示实战:从硬件连接到设备树配置全解析 引言 当你第一次拿到STM32MP157开发板时,最令人兴奋的莫过于看到图形界面在屏幕上亮起的那一刻。但现实往往很骨感——手头可能没有配套的LCD屏幕,而HDMI显示器却是大多数开发者桌…...

告别showSoftInput失效:一文读懂Android 11+的WindowInsetsController输入法控制
Android输入法控制演进:从InputMethodManager到WindowInsetsController的深度解析 在移动应用开发中,输入法交互是最基础却又最容易被忽视的细节之一。许多开发者都曾遇到过这样的场景:精心设计的登录界面,光标在输入框闪烁&#…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南
快速免费解锁网易云音乐NCM格式:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾在网易云音乐下载了心爱的歌曲&am…...

终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载
终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的下载速度而烦恼…...

nnU-Net v2实战:从零开始配置环境与训练自定义医学影像数据集
1. 环境配置:搭建nnU-Net v2的基础舞台 第一次接触nnU-Net时,我踩过的最大坑就是环境配置。当时为了赶项目进度,直接用了现有的Python 3.8环境,结果在安装时各种报错,浪费了大半天时间。后来才发现,nnU-Net…...

基于Fire2012算法与FastLED库的Arduino LED篝火制作全攻略
1. 项目概述:用代码点燃一场永不熄灭的数字篝火夏夜、星空、朋友围坐,篝火带来的温暖与氛围是露营的灵魂。但现实是,很多营地禁止明火,或者在城市阳台、室内空间,生一堆真正的火既不安全也不现实。作为一名玩了十多年A…...

Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题!
Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统越用越慢而烦恼吗&…...

Redis增强工具包:封装分布式锁、缓存模板与监控的最佳实践
1. 项目概述:一个Redis开发者的“瑞士军刀”在分布式系统和高并发场景下,Redis几乎成了标配。但用久了你会发现,官方客户端虽然稳定,但在日常开发、调试、运维中,总有些“不够顺手”的地方。比如,想批量按模…...