ElasticSearch序列 - SpringBoot整合ES:根据指定的 ids 查询
文章目录
- 1. ElasticSearch 根据 ids 查询文档
- 2. SpringBoot整合ES实现 ids 查询
1. ElasticSearch 根据 ids 查询文档
① 索引文档,构造数据
PUT /my_index/_doc/1
{"price":10
}PUT /my_index/_doc/2
{"price":20
}PUT /my_index/_doc/3
{"price":30
}
② 查询文档 id 为 1 或者 2 的文档:
GET /my_index/_search
{"query": {"ids": {"values": [1,2]}}
}
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"price" : 10}},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"price" : 20}}]}
}
我们索引文档时,文档的id为整型,为什么查询出来的文档 id为字符串类型呢?如果我们使用字符串类型的文档id查询呢?
GET /my_index/_search
{"query": {"ids": {"values": ["1","2"]}}
}
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"price" : 10}},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"price" : 20}}]}
}
可以看到仍然可以查询到匹配的文档。
在Elasticsearch中,文档ID可以是任何字符串类型,包括数字、字母、符号等。即使您在索引文档时使用了整数作为ID,Elasticsearch也会将其转换为字符串类型,并将其存储在内部索引中。当您查询文档时,Elasticsearch会将文档ID作为字符串类型返回。
如果您需要将查询结果中的文档ID转换为整数类型,可以在查询结果中进行转换。例如,在使用Java API执行查询时,您可以使用以下代码将文档ID转换为整数类型:
SearchResponse response = client.prepareSearch("my_index").setQuery(QueryBuilders.matchAllQuery()).get();for (SearchHit hit : response.getHits().getHits()) {int id = Integer.parseInt(hit.getId());// do something with the integer ID
}
在上面的代码中,我们首先执行一个查询,并使用getHits方法获取查询结果。然后,我们遍历查询结果中的每个文档,并使用Integer.parseInt方法将文档ID转换为整数类型。
2. SpringBoot整合ES实现 ids 查询
GET /my_index/_search
{"query": {"ids": {"values": [1,2]}}
}
@Slf4j
@Service
public class ElasticSearchImpl {@Autowiredprivate RestHighLevelClient restHighLevelClient;public void searchUser() throws IOException {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// ids 查询IdsQueryBuilder idsQueryBuilder = new IdsQueryBuilder();// IdsQueryBuilder addIds(String... ids) idsQueryBuilder.addIds("1", "2");searchSourceBuilder.query(idsQueryBuilder);SearchRequest searchRequest = new SearchRequest(new String[]{"my_index"},searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);System.out.println(searchResponse);}
}
如果我们想根据 ids 去查询文档的话,一般会使用 terms 查询:
GET /my_index/_search
{"query": {"terms": {"_id": ["1","2"]}}
}
需要注意的是主键为_id,而不是id,如果使用id则查询结果会为空。
@Slf4j
@Service
public class ElasticSearchImpl {@Autowiredprivate RestHighLevelClient restHighLevelClient;public void searchUser() throws IOException {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// terms 查询List<String> ids = Arrays.asList("1","2");TermsQueryBuilder termsQueryBuilder = new TermsQueryBuilder("_id",ids);searchSourceBuilder.query(termsQueryBuilder);SearchRequest searchRequest = new SearchRequest(new String[]{"my_index"},searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);System.out.println(searchResponse);}
}
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_index","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"price" : 10}},{"_index" : "my_index","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"price" : 20}}]}
}
相关文章:

ElasticSearch序列 - SpringBoot整合ES:根据指定的 ids 查询
文章目录1. ElasticSearch 根据 ids 查询文档2. SpringBoot整合ES实现 ids 查询1. ElasticSearch 根据 ids 查询文档 ① 索引文档,构造数据 PUT /my_index/_doc/1 {"price":10 }PUT /my_index/_doc/2 {"price":20 }PUT /my_index/_doc/3 {&qu…...
Spark SQL实战(08)-整合Hive
1 整合原理及使用 Apache Spark 是一个快速、可扩展的分布式计算引擎,而 Hive 则是一个数据仓库工具,它提供了数据存储和查询功能。在 Spark 中使用 Hive 可以提高数据处理和查询的效率。 场景 历史原因积累下来的,很多数据原先是采用Hive…...
堆(数据结构系列11)
目录 前言: 1.优先级队列概念 2.堆的概念 3.堆的存储方式 4.堆的创建 5.创建堆的时间复杂度 6.堆的插入和删除 6.1堆的插入 6.2堆的删除 结束语: 前言: 上一次博客中小编主要与大家分享了 二叉树一些相关的知识点和一些练习题&…...
算法训练第四十二天|01背包问题 二维 、01背包问题 一维、416. 分割等和子集
动态规划part0401背包问题 二维01 背包二维dp数组01背包完整c测试代码总结01背包问题 一维一维dp数组(滚动数组)一维dp01背包完整C测试代码416. 分割等和子集题目描述思路01背包问题总结01背包问题 二维 视频链接:https://www.bilibili.com/…...
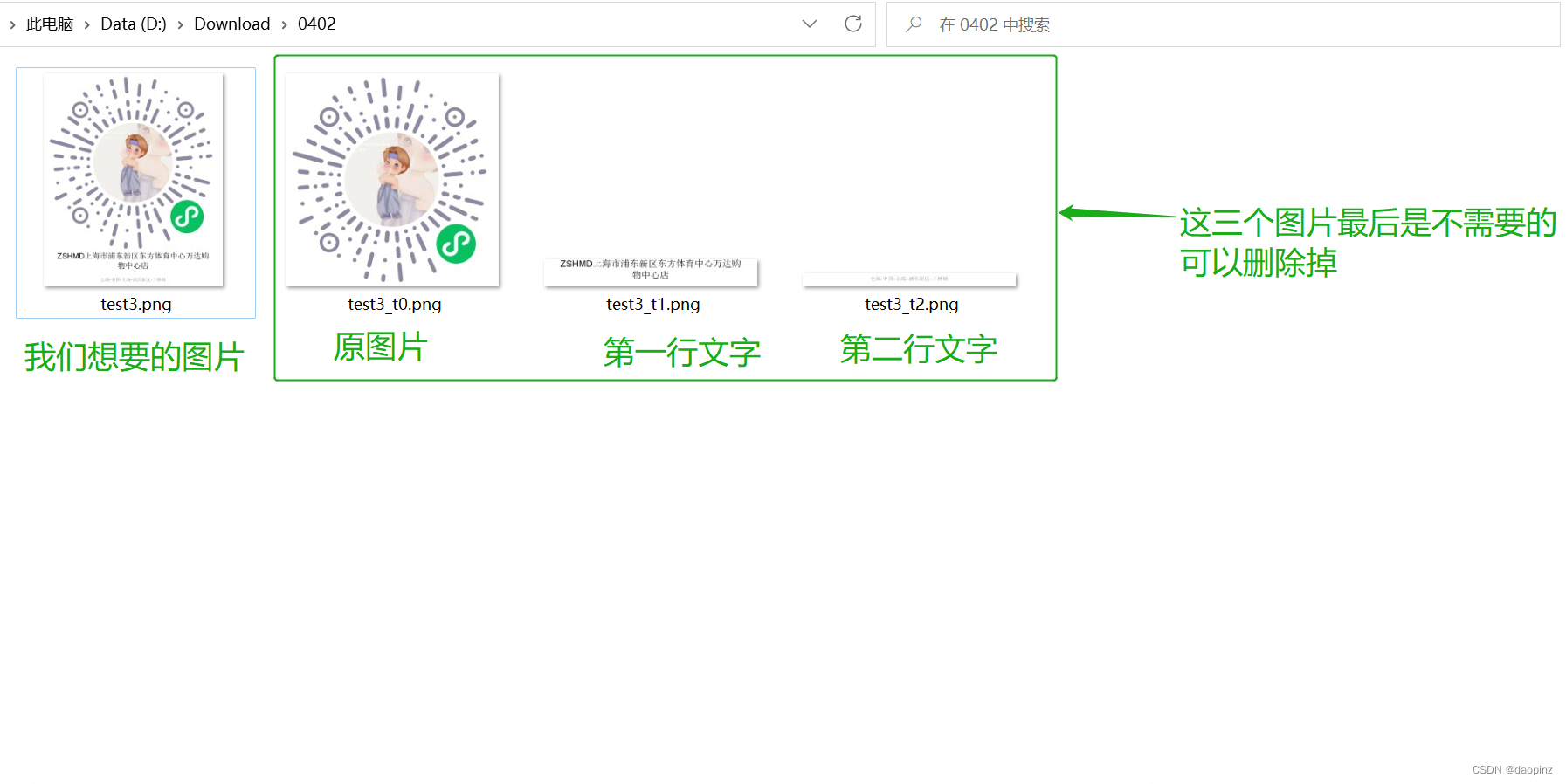
Java-如何使用Java将图片和文字拼接在一起(并非是给图片加水印)
之前有遇到一个问题 问题背景:项目中,有一个功能,管理端可以将客户创建的小程序码下载到本地,方便客户将对应门店的小程序码打印出来并张贴到门店,做门店的引流和会员入会。 具体问题:当小程序码的数量较少…...

Metasploit入门到高级【第三章】
来自公粽号:Kali与编程预计更新第一章:Metasploit 简介 Metasploit 是什么Metasploit 的历史和发展Metasploit 的组成部分 第二章:Kali Linux 入门 Kali Linux 简介Kali Linux 安装和配置常用命令和工具介绍 第三章:Metasploi…...
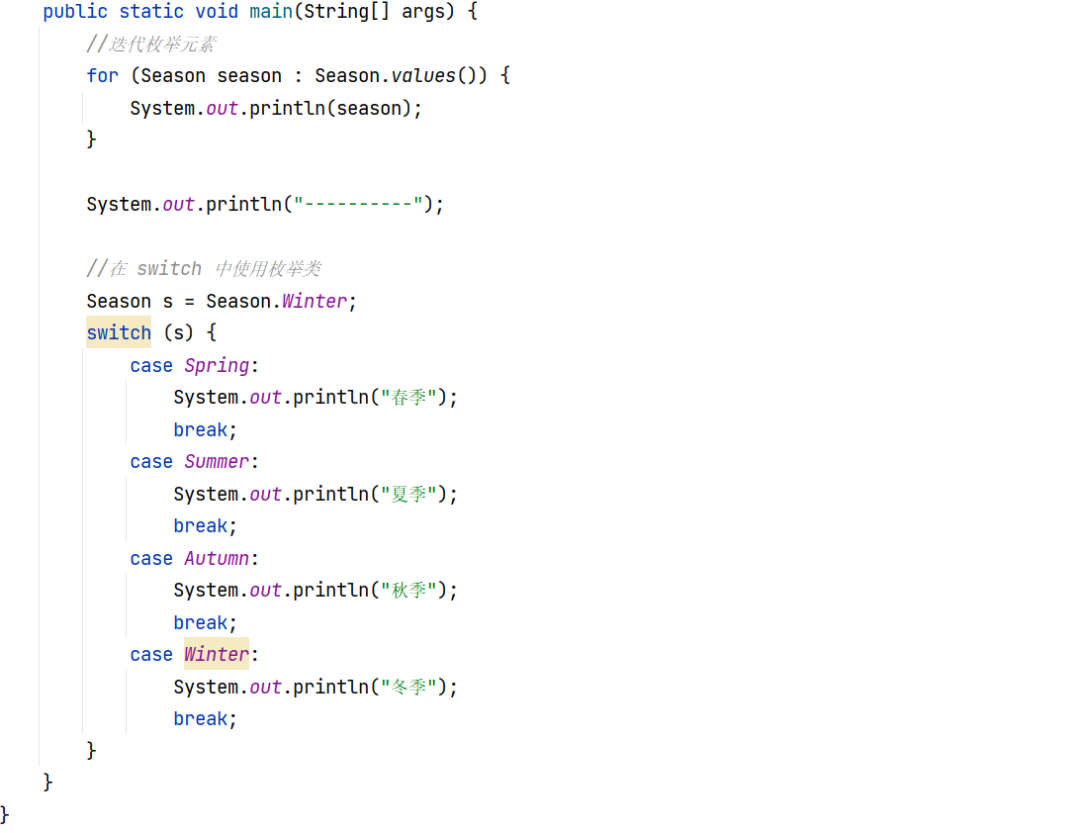
枚举的使用
Java 枚举是一个特殊的类,一般表示一组常量,比如一年的 4 个季节,一个年的 12 个月份,一个星期的 7 天,方向有东南西北等。1 问题如何在类中使用枚举,例如枚举出一年的四个季度,并且通过迭代枚举…...

Python进阶语法
1.1 Python进阶语法 1.1.1 交换变量 一行代码快速交换两个变量,无需创建临时变量。 from icecream import ica 2 b 4 a, b b, a ic(a, b)ic| a: 4, b: 2 1.1.2 链式比较 from icecream import ica 97 if 90 < a < 100:ic(a)ic| a: 97 1.1.3 初始化列表…...

Pyspark_结构化流4
Pyspark 注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hi…...

Linux cmp 命令
Linux cmp 命令用于比较两个文件是否有差异。 当相互比较的两个文件完全一样时,则该指令不会显示任何信息。若发现有所差异,预设会标示出第一个不同之处的字符和列数编号。若不指定任何文件名称或是所给予的文件名为"-",则cmp指令…...

Python入门到高级【第五章】
预计更新第一章. Python 简介 Python 简介和历史Python 特点和优势安装 Python 第二章. 变量和数据类型 变量和标识符基本数据类型:数字、字符串、布尔值等字符串操作列表、元组和字典 第三章. 控制语句和函数 分支结构:if/else 语句循环结构&#…...

C语言中(i++)+ (i++)真的每次都等于3吗?
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言结论证明首先,登场的是我们的VC6.0(还有Linux)最后一位,我使用了小熊猫C(还有Clion)请添加…...

Cursor,程序员的 AI 代码编辑助手
相信大家都或多或少地听说过、了解过 chatGPT ,半个月前发布的 GPT-4 ,可谓是 AI 赛道上的一个王炸 那么今天咸鱼给大家分享一个开源的 AI 代码编辑器——Cursor,让各位程序员在编程之路上一骑绝尘 😃 介绍 Cursor 是一个人工智…...
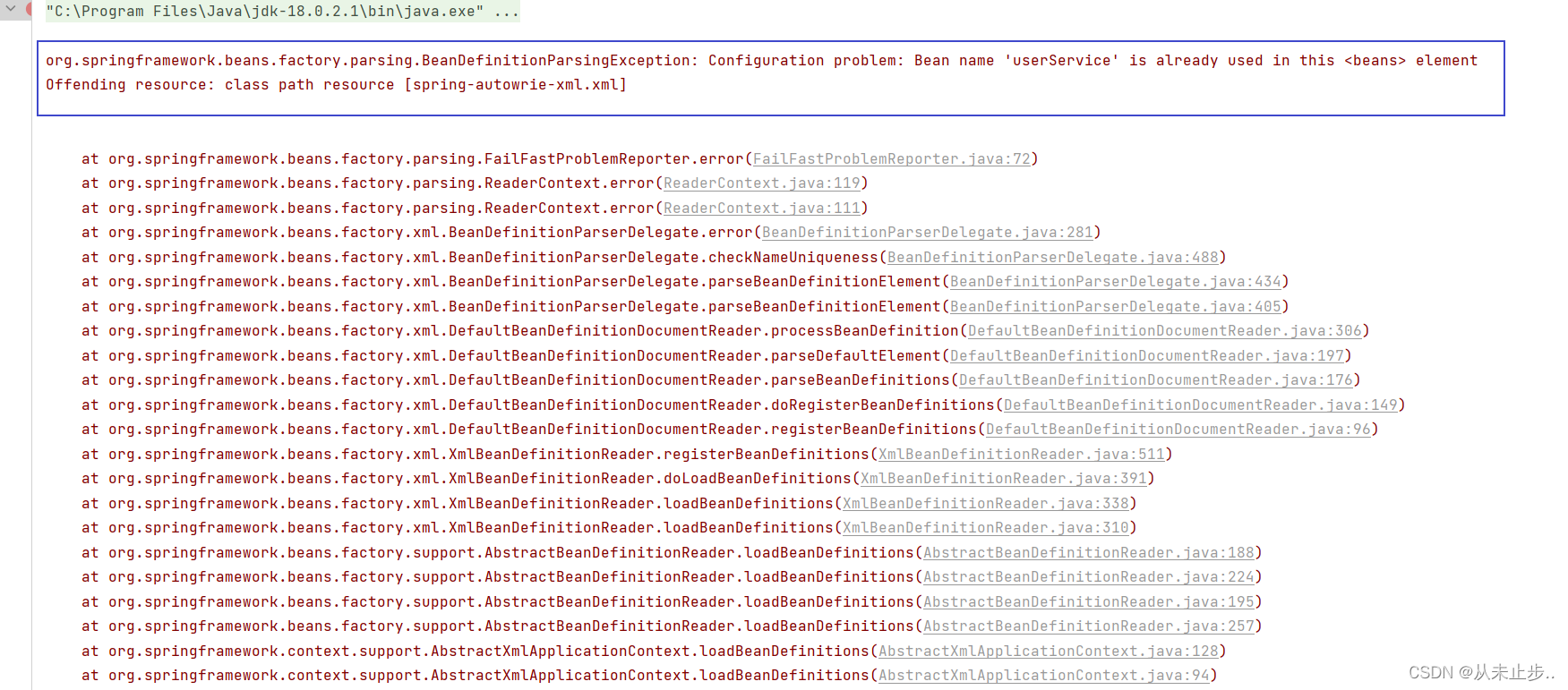
基于XML的自动装配~
基于XML的自动装配之场景模拟: 自动装配:根据指定的策略,在IOC容器中匹配某一个bean,自动为指定的bean中所依赖的类类型或者接口类型赋值 之前我们学过的依赖注入,我们在为不同属性赋值时,例如类类型的属性…...
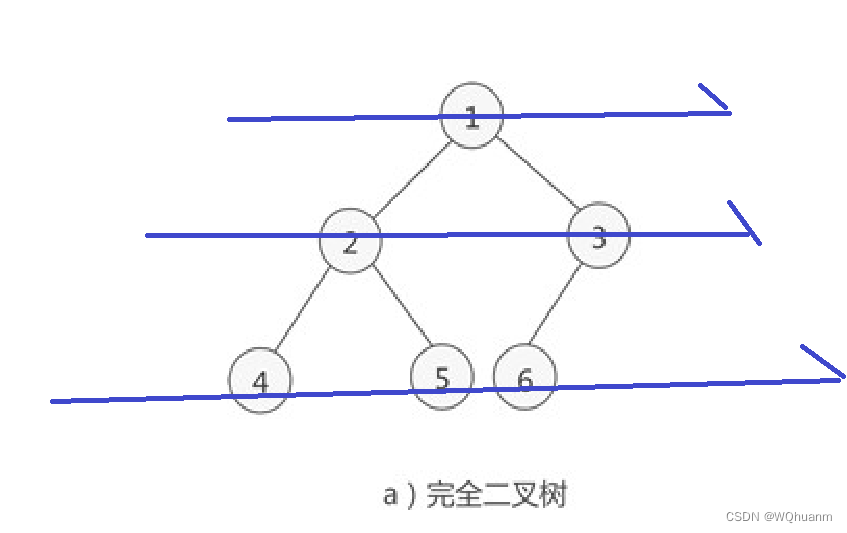
完全二叉树的4种遍历方式
一张二叉树的图 1,二叉树的特点 每个点p的左儿子是p*2,右儿子是p*21,可以分别表示为p<<1与p<<1|1节点的序号是从左到右,从上到下增加的每个点至多2个儿子(屁话(bushi)) 2ÿ…...
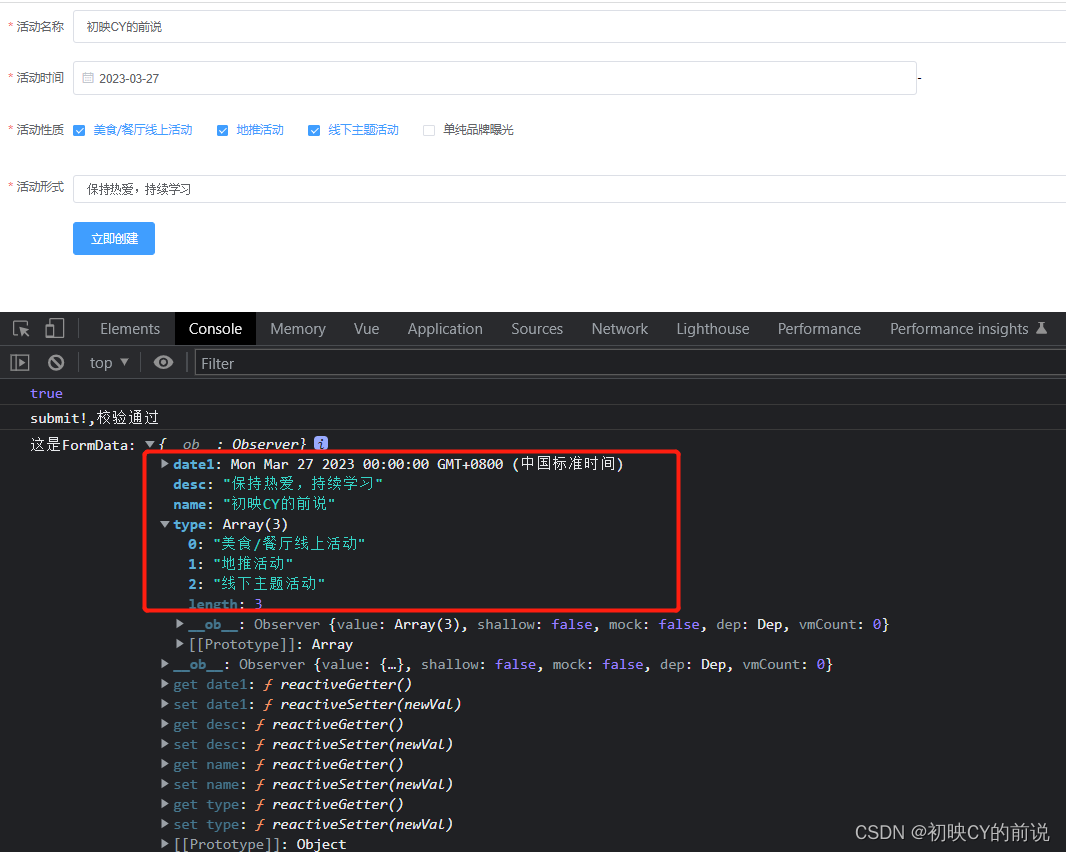
【vue2】使用elementUI进行表单验证实操(附源码)
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:vue使用elementUI进行表单验证实操(附源码) 【前言】我们在构建一…...

JUC之阻塞队列解读(BlockingQueue)
目录 BlockingQueue 简介 BlockingQueue 核心方法 1.放入数据 2.获取数据 入门代码案例 常见的 BlockingQueue ArrayBlockingQueue(常用) LinkedBlockingQueue(常用) PriorityBlockingQueue SynchronousQueue LinkedTransferQueue LinkedBlockingDeque 小结 Bloc…...
LCHub:ChatGPT4和低代码来临,程序员面临下岗?
一个网友吐槽道: “ 建站出来了,你们说程序员会失业。 低代码出来了,你们说程序员会失业。 Copilot出来了,你们说程序员会失业。 Chatgpt出来了,你们说程序员会失业 虽然这只是网友的吐槽,但却引起了小编的好奇。为何程序员那么容易被新技术取代?今天小编打算跟大家…...
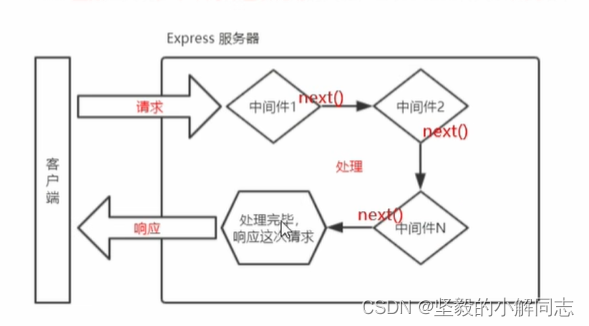
【Node.js】Express框架的基本使用
✍️ 作者简介: 前端新手学习中。 💂 作者主页: 作者主页查看更多前端教学 🎓 专栏分享:css重难点教学 Node.js教学 从头开始学习 目录 初识Express Express简介 什么是Express 进一步理解 Express Express能做什么 Express的基本使用 …...
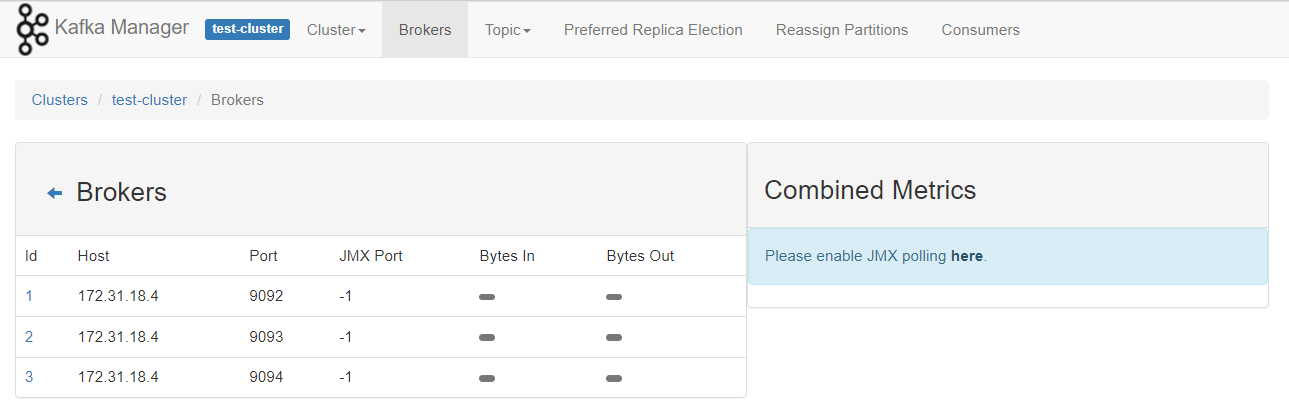
使用docker 和 kubnernetes 部署单节点/多节点 kafka 环境
参考资料 https://kafka.apachecn.org/documentation.html#configuration kafka的broker有三个核心配置 broker.idlog.dirszookeeper.connect docker启动单节点kafka环境 启动zookeeper 可配置的环境变量,https://gallery.ecr.aws/bitnami/zookeeper $ docker …...

mRNA疫苗序列生物信息学分析:从密码子优化到免疫原性预测
1. 项目概述:解码两大mRNA疫苗的“核心蓝图”作为一名在生物信息学和基因组学领域摸爬滚打了十多年的“老码农”,我见过太多令人兴奋的数据集,但当我第一次在GitHub上看到这个名为“Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-se…...

Speechless:三步完成微博PDF备份的终极免费Chrome扩展
Speechless:三步完成微博PDF备份的终极免费Chrome扩展 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 在数字时代,我们的社交…...

终极macOS清理神器:Pearcleaner 3步彻底卸载应用不留痕迹
终极macOS清理神器:Pearcleaner 3步彻底卸载应用不留痕迹 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾将macOS应用拖入废纸篓后&…...

Nix构建确定性AI编程环境:解决Cursor编辑器依赖冲突难题
1. 项目概述:当代码编辑器遇上Nix的确定性魔法 最近在折腾开发环境时,我遇到了一个老生常谈但又无比头疼的问题:团队里新来的同事怎么也跑不起来我本地运行得好好的一个代码辅助工具链。依赖版本冲突、系统库路径不对、甚至是因为他用的macO…...

从零到一:基于HappyBase的HBase Python应用实战指南
1. 环境准备与基础配置 第一次接触HBase和HappyBase时,环境配置往往是最让人头疼的部分。记得我刚开始搭建环境时,花了整整两天时间才把所有服务调通。为了让各位少走弯路,我把这些年积累的经验都整理在这里。 首先需要明确的是,…...

Ruby中文分词利器Rurima:纯Ruby实现的高性能分词引擎详解
1. 项目概述:一个为Ruby打造的现代中文分词引擎在Ruby社区里,处理中文文本一直是个有点“硌脚”的活儿。如果你做过中文搜索、内容分析或者简单的词频统计,肯定遇到过这个经典难题:怎么把一串连续的中文字符,准确地切割…...

JVM调优实战:让你的服务性能提升50%
一、背景 线上一个核心订单服务,QPS 3000左右,经常出现接口超时告警。监控显示: 平均RT: 180ms(要求<100ms)Full GC频率: 每天20次,每次STW 1.5sCPU使用率: 峰值85%服务规格: 8C16G,堆内存…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

Aurora框架解析:一体化高性能云原生开发平台的设计与实践
1. 项目概述与核心价值如果你在开源社区里混迹过一段时间,尤其是对现代化、高性能的Web开发框架感兴趣,那么“Aurora”这个名字你大概率不会陌生。它不是一个简单的库或者工具,而是一个由社区驱动的、旨在构建下一代企业级应用开发平台的雄心…...

Mantic.sh:Bash脚本实现的终端命令自动化与效率提升工具
1. 项目概述:一个为开发者打造的终端效率工具如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你肯定对效率工具有着近乎偏执的追求。从cd到ls,从grep到awk,我们依赖这些…...