Spark SQL实战(08)-整合Hive
1 整合原理及使用
Apache Spark 是一个快速、可扩展的分布式计算引擎,而 Hive 则是一个数据仓库工具,它提供了数据存储和查询功能。在 Spark 中使用 Hive 可以提高数据处理和查询的效率。
场景
历史原因积累下来的,很多数据原先是采用Hive来进行处理的,现想改用Spark操作数据,须要求Spark能够无缝对接已有的Hive的数据,实现平滑过渡。
MetaStore
Hive底层的元数据信息是存储在MySQL中,$HIVE_HOME/conf/hive-site.xml
Spark若能直接访问MySQL中已有的元数据信息 $SPARK_HOME/conf/hive-site.xml
前置条件
在使用 Spark 整合 Hive 之前,需要安装配置以下软件:
- Hadoop:用于数据存储和分布式计算。
- Hive:用于数据存储和查询。
- Spark:用于分布式计算。
整合 Hive
在 Spark 中使用 Hive,需要将 Hive 的依赖库添加到 Spark 的类路径中。在 Java 代码中,可以使用 SparkConf 对象来设置 Spark 应用程序的配置。下面是一个示例代码:
import org.apache.spark.SparkConf;
import org.apache.spark.sql.SparkSession;public class SparkHiveIntegration {public static void main(String[] args) {SparkConf conf = new SparkConf().setAppName("SparkHiveIntegration").setMaster("local[*]").set("spark.sql.warehouse.dir", "/user/hive/warehouse");SparkSession spark = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate();spark.sql("SELECT * FROM mytable").show();spark.stop();}
}
在上面的代码中,首先创建了一个 SparkConf 对象,设置了应用程序的名称、运行模式以及 Hive 的元数据存储路径。然后,创建了一个 SparkSession 对象,启用了 Hive 支持。最后,使用 Spark SQL 查询语句查询了一个名为 mytable 的 Hive 表,并将结果打印出来。最后,停止了 SparkSession 对象。
需要注意的是,Spark SQL 语法与 Hive SQL 语法略有不同,可以参考 Spark SQL 官方文档。
2 ThiriftServer使用
javaedge@JavaEdgedeMac-mini sbin % pwd
/Users/javaedge/Downloads/soft/spark-2.4.3-bin-2.6.0-cdh5.15.1/sbinjavaedge@JavaEdgedeMac-mini sbin % ./start-thriftserver.sh --master local --jars /Users/javaedge/.m2/repository/mysql/mysql-connector-java/8.0.15/mysql-connector-java-8.0.15.jarstarting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /Users/javaedge/Downloads/soft/spark-2.4.3-bin-2.6.0-cdh5.15.1/logs/spark-javaedge-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-JavaEdgedeMac-mini.local.out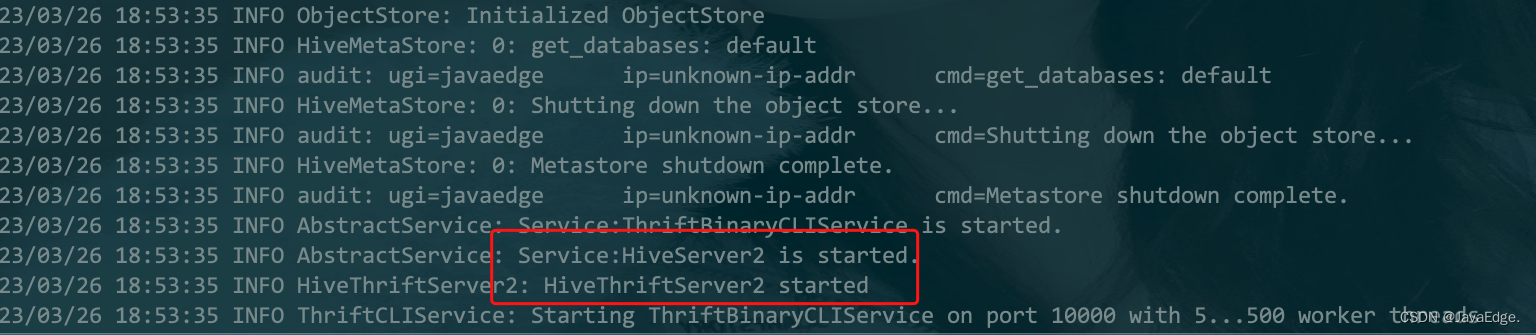
beeline
内置了一个客户端工具:
javaedge@JavaEdgedeMac-mini bin % ./beeline -u jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Connected to: Spark SQL (version 2.4.3)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1.spark2 by Apache Hive
0: jdbc:hive2://localhost:10000>
当你执行一条命令后:
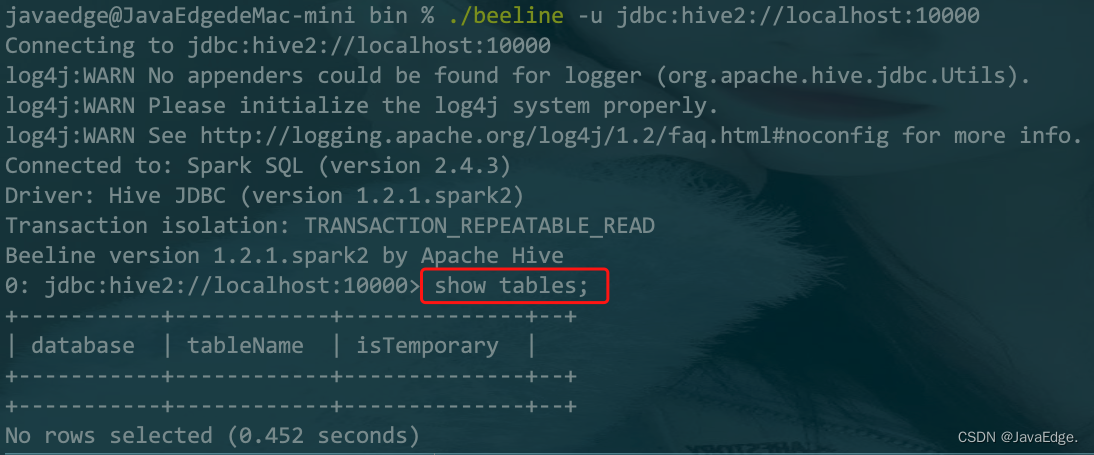
就能在 Web UI 看到该命令记录:

3 通过代码访问数据
总是手敲命令行肯定太慢了,我们更多是代码访问:
package com.javaedge.bigdata.chapter06import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}object JDBCClientApp {def main(args: Array[String]): Unit = {Class.forName("org.apache.hive.jdbc.HiveDriver")val conn: Connection = DriverManager.getConnection("jdbc:hive2://localhost:10000")val pstmt: PreparedStatement = conn.prepareStatement("show tables")val rs: ResultSet = pstmt.executeQuery()while (rs.next()) {println(rs.getObject(1) + " : " + rs.getObject(2))}}
}
最后打成 jar 包,扔到服务器定时运行即可执行作业啦。
ThiriftServer V.S Spark Application 例行作业
Thrift Server 独立的服务器应用程序,它允许多个客户端通过网络协议访问其上运行的 Thrift 服务。Thrift 服务通常是由一组 Thrift 定义文件定义的,这些文件描述了可以从客户端发送到服务器的请求和响应消息的数据结构和协议。Thrift Server 可以使用各种编程语言进行开发,包括 Java、C++、Python 等,并支持多种传输和序列化格式,例如 TSocket、TFramedTransport、TBinaryProtocol 等。使用 Thrift Server,您可以轻松地创建高性能、可伸缩和跨平台的分布式应用程序。
Spark Application,基于 Apache Spark 的应用程序,它使用 Spark 编写的 API 和库来处理大规模数据集。Spark Application 可以部署在本地计算机或云环境中,并且支持各种数据源和格式,如 Hadoop 分布式文件系统(HDFS)、Apache Cassandra、Apache Kafka 等。Spark Application 可以并行处理数据集,以加快数据处理速度,并提供了广泛的机器学习算法和图形处理功能。使用 Spark Application,您可以轻松地处理海量数据,提取有价值的信息和洞察,并帮助您做出更明智的业务决策。
因此,Thrift Server 和 Spark Application 适用不同的场景和应用程序:
- 需要创建一个分布式服务并为多个客户端提供接口,使用 Thrift Server
- 需要处理大规模数据集并使用分布式计算和机器学习算法来分析数据,使用 Spark Application
4 Spark 代码访问 Hive 数据
5 Spark SQL 函数实战
parallelize
SparkContext 一个方法,将一个本地数据集转为RDD。parallelize` 方法接受一个集合作为输入参数,并根据指定的并行度创建一个新的 RDD。
语法:
// data表示要转换为 RDD 的本地集合
// numSlices表示 RDD 的分区数,通常等于集群中可用的 CPU 核心数量。
val rdd =
sc.parallelize(data, numSlices)
将一个包含整数值的本地数组转换为RDD:
import org.apache.spark.{SparkConf, SparkContext}// 创建 SparkConf 对象
val conf = new SparkConf().setAppName("ParallelizeExample").setMaster("local[*]")// 创建 SparkContext 对象
val sc = new SparkContext(conf)// 定义本地序列
val data = Seq(1, 2, 3, 4, 5)// 使用 parallelize 方法创建 RDD
val rdd = sc.parallelize(data)// 执行转换操作
val result = rdd.map(_ * 2)// 显示输出结果
result.foreach(println)
创建了一个包含整数值的本地序列 data,然后使用 parallelize 方法将其转换为一个 RDD。接下来,我们对 RDD 进行转换操作,并打印输出结果。
使用 parallelize 方法时,请确保正确配置 Spark 应用程序,并设置正确 CPU 核心数量和内存大小。否则,可能会导致应用程序性能下降或崩溃。
5.1 内置函数
都在这:
统计 PV、UV 实例
package com.javaedge.bigdata.chapter06import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}/*** 内置函数*/
object BuiltFunctionApp {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().master("local").appName("HiveSourceApp").getOrCreate()// day useridval userAccessLog = Array("2016-10-01,1122","2016-10-01,1122","2016-10-01,1123","2016-10-01,1124","2016-10-01,1124","2016-10-02,1122","2016-10-02,1121","2016-10-02,1123","2016-10-02,1123")import spark.implicits._// Array ==> RDDval userAccessRDD: RDD[String] = spark.sparkContext.parallelize(userAccessLog)val userAccessDF: DataFrame = userAccessRDD.map(x => {val splits: Array[String] = x.split(",")Log(splits(0), splits(1).toInt)}).toDFuserAccessDF.show()import org.apache.spark.sql.functions._// select day, count(user_id) from xxx group by day;userAccessDF.groupBy("day").agg(count("userId").as("pv")).show()userAccessDF.groupBy("day").agg(countDistinct("userId").as("uv")).show()spark.stop()}private case class Log(day: String, userId: Int)
}
5.2 自定义函数
package com.javaedge.bigdata.chapter06import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}/*** 统计每个人爱好的个数* pk:3* jepson: 2*** 1)定义函数* 2)注册函数* 3)使用函数*/
object UDFFunctionApp {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().master("local").appName("HiveSourceApp").getOrCreate()import spark.implicits._val infoRDD: RDD[String] = spark.sparkContext.textFile("/Users/javaedge/Downloads/sparksql-train/data/hobbies.txt")val infoDF: DataFrame = infoRDD.map(_.split("###")).map(x => {Hobbies(x(0), x(1))}).toDFinfoDF.show(false)// TODO... 定义函数 和 注册函数spark.udf.register("hobby_num", (s: String) => s.split(",").size)infoDF.createOrReplaceTempView("hobbies")//TODO... 函数的使用spark.sql("select name, hobbies, hobby_num(hobbies) as hobby_count from hobbies").show(false)// select name, hobby_num(hobbies) from xxxspark.stop()}private case class Hobbies(name: String, hobbies: String)
}output:
+------+----------------------+
|name |hobbies |
+------+----------------------+
|pk |jogging,Coding,cooking|
|jepson|travel,dance |
+------+----------------------++------+----------------------+-----------+
|name |hobbies |hobby_count|
+------+----------------------+-----------+
|pk |jogging,Coding,cooking|3 |
|jepson|travel,dance |2 |
+------+----------------------+-----------+
6 总结
通过上述示例代码,可以看到如何在 Java 中使用 Spark 整合 Hive。通过使用 Hive 的数据存储和查询功能,可以在 Spark 中高效地处理和分析数据。当然,还有许多其他功能和配置可以使用,例如设置 Spark 应用程序的资源分配、数据分区、数据格式转换等等。
相关文章:
Spark SQL实战(08)-整合Hive
1 整合原理及使用 Apache Spark 是一个快速、可扩展的分布式计算引擎,而 Hive 则是一个数据仓库工具,它提供了数据存储和查询功能。在 Spark 中使用 Hive 可以提高数据处理和查询的效率。 场景 历史原因积累下来的,很多数据原先是采用Hive…...
堆(数据结构系列11)
目录 前言: 1.优先级队列概念 2.堆的概念 3.堆的存储方式 4.堆的创建 5.创建堆的时间复杂度 6.堆的插入和删除 6.1堆的插入 6.2堆的删除 结束语: 前言: 上一次博客中小编主要与大家分享了 二叉树一些相关的知识点和一些练习题&…...
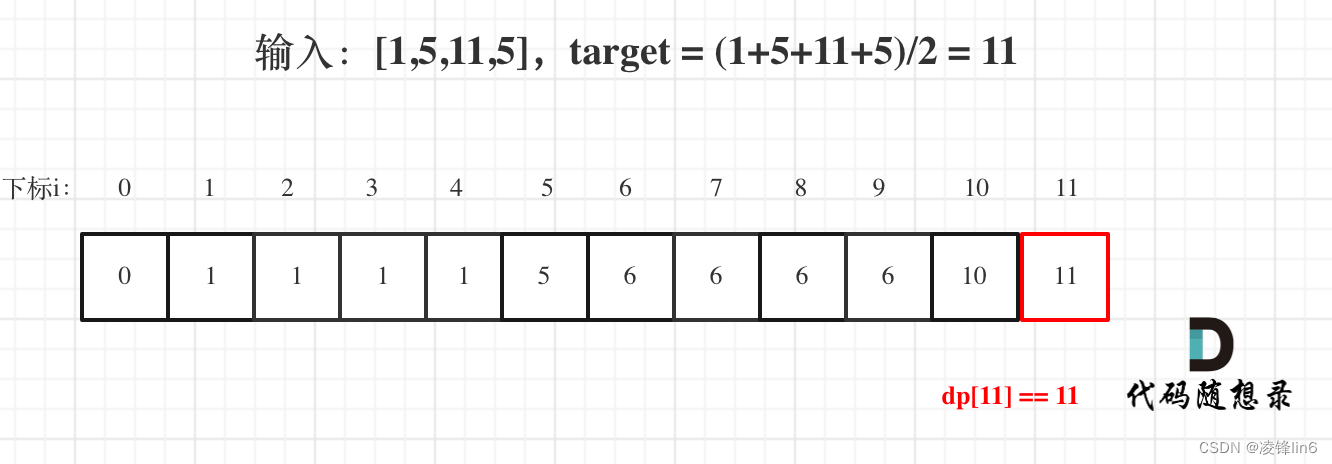
算法训练第四十二天|01背包问题 二维 、01背包问题 一维、416. 分割等和子集
动态规划part0401背包问题 二维01 背包二维dp数组01背包完整c测试代码总结01背包问题 一维一维dp数组(滚动数组)一维dp01背包完整C测试代码416. 分割等和子集题目描述思路01背包问题总结01背包问题 二维 视频链接:https://www.bilibili.com/…...
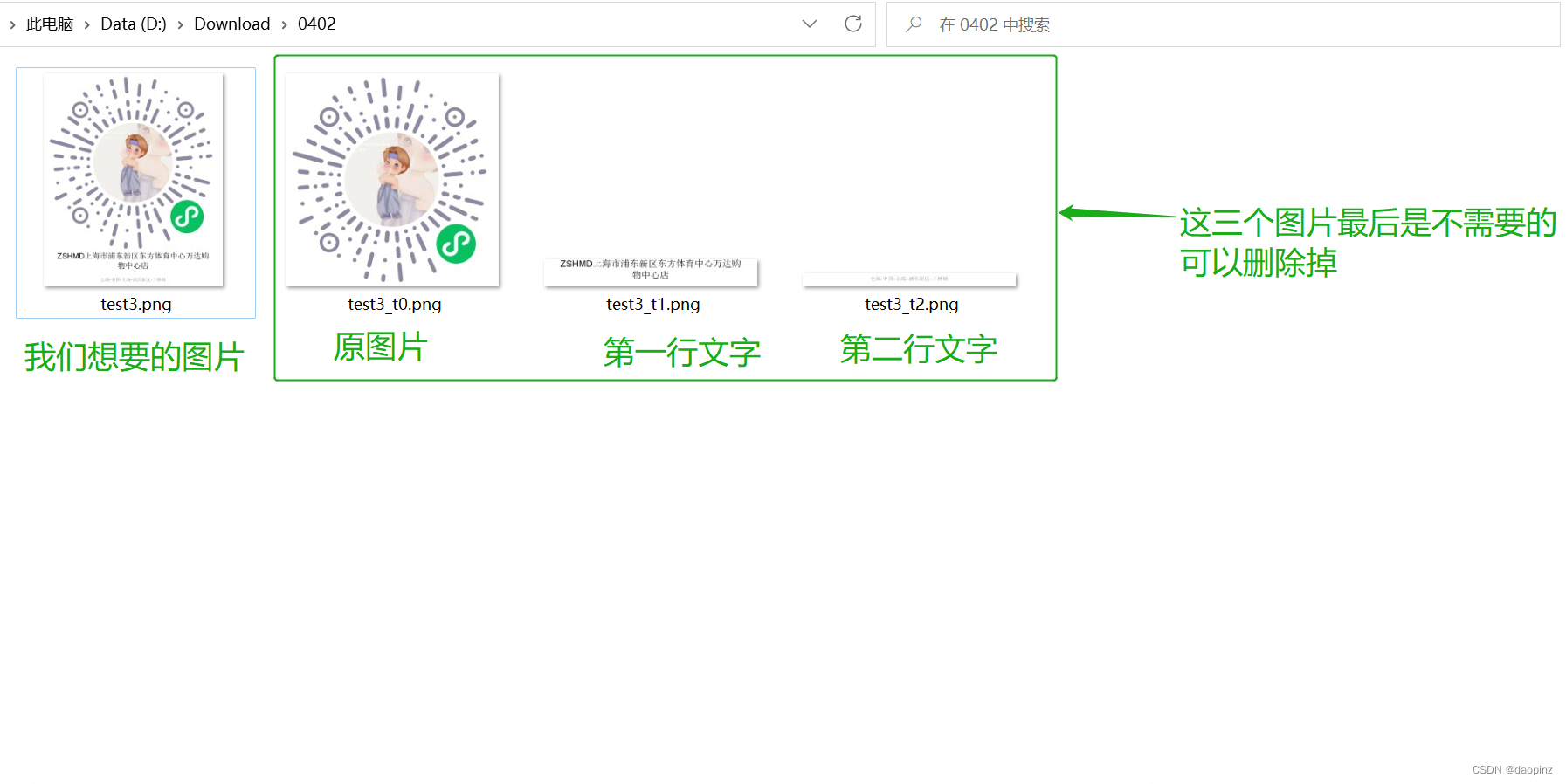
Java-如何使用Java将图片和文字拼接在一起(并非是给图片加水印)
之前有遇到一个问题 问题背景:项目中,有一个功能,管理端可以将客户创建的小程序码下载到本地,方便客户将对应门店的小程序码打印出来并张贴到门店,做门店的引流和会员入会。 具体问题:当小程序码的数量较少…...

Metasploit入门到高级【第三章】
来自公粽号:Kali与编程预计更新第一章:Metasploit 简介 Metasploit 是什么Metasploit 的历史和发展Metasploit 的组成部分 第二章:Kali Linux 入门 Kali Linux 简介Kali Linux 安装和配置常用命令和工具介绍 第三章:Metasploi…...
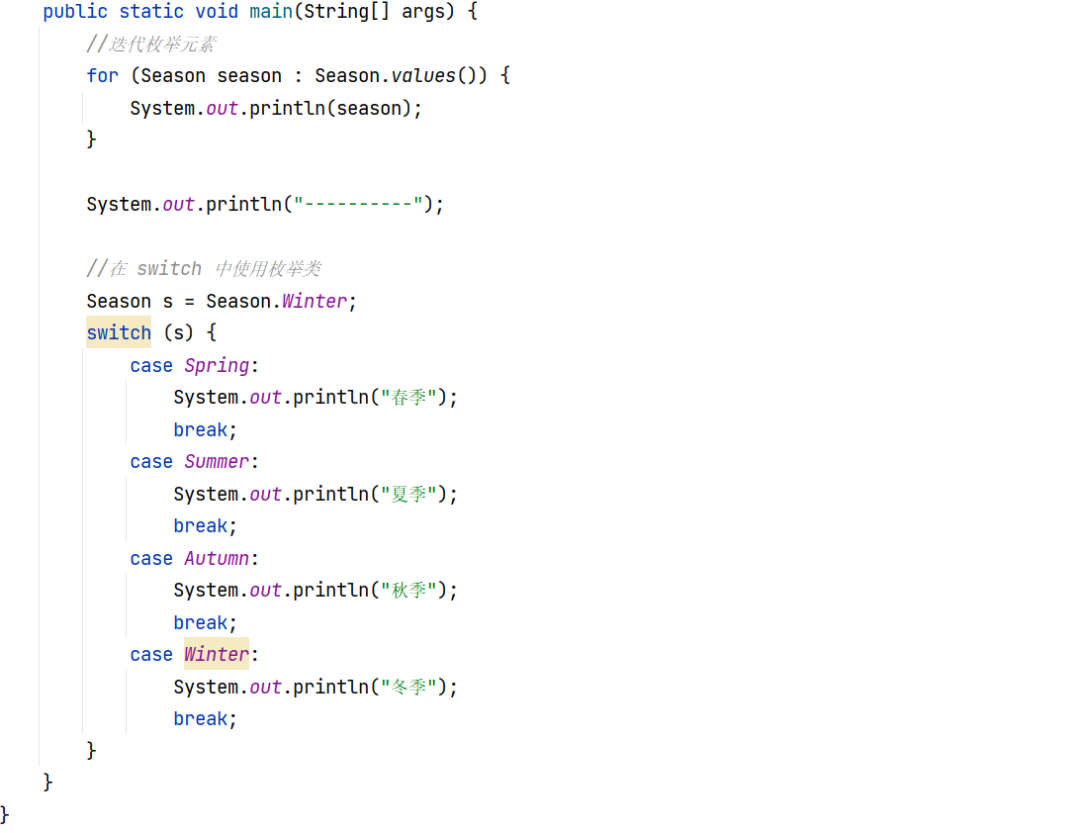
枚举的使用
Java 枚举是一个特殊的类,一般表示一组常量,比如一年的 4 个季节,一个年的 12 个月份,一个星期的 7 天,方向有东南西北等。1 问题如何在类中使用枚举,例如枚举出一年的四个季度,并且通过迭代枚举…...

Python进阶语法
1.1 Python进阶语法 1.1.1 交换变量 一行代码快速交换两个变量,无需创建临时变量。 from icecream import ica 2 b 4 a, b b, a ic(a, b)ic| a: 4, b: 2 1.1.2 链式比较 from icecream import ica 97 if 90 < a < 100:ic(a)ic| a: 97 1.1.3 初始化列表…...

Pyspark_结构化流4
Pyspark 注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hi…...

Linux cmp 命令
Linux cmp 命令用于比较两个文件是否有差异。 当相互比较的两个文件完全一样时,则该指令不会显示任何信息。若发现有所差异,预设会标示出第一个不同之处的字符和列数编号。若不指定任何文件名称或是所给予的文件名为"-",则cmp指令…...

Python入门到高级【第五章】
预计更新第一章. Python 简介 Python 简介和历史Python 特点和优势安装 Python 第二章. 变量和数据类型 变量和标识符基本数据类型:数字、字符串、布尔值等字符串操作列表、元组和字典 第三章. 控制语句和函数 分支结构:if/else 语句循环结构&#…...

C语言中(i++)+ (i++)真的每次都等于3吗?
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言结论证明首先,登场的是我们的VC6.0(还有Linux)最后一位,我使用了小熊猫C(还有Clion)请添加…...

Cursor,程序员的 AI 代码编辑助手
相信大家都或多或少地听说过、了解过 chatGPT ,半个月前发布的 GPT-4 ,可谓是 AI 赛道上的一个王炸 那么今天咸鱼给大家分享一个开源的 AI 代码编辑器——Cursor,让各位程序员在编程之路上一骑绝尘 😃 介绍 Cursor 是一个人工智…...
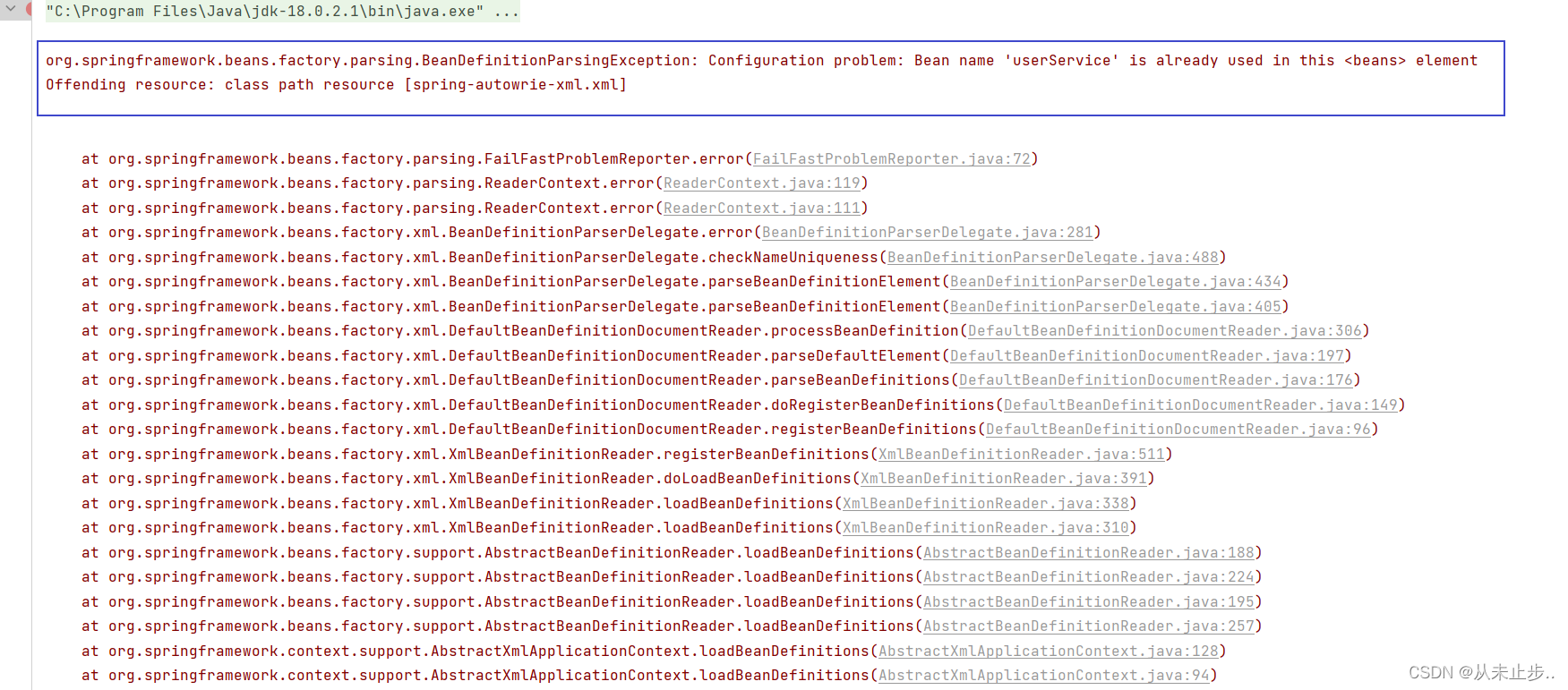
基于XML的自动装配~
基于XML的自动装配之场景模拟: 自动装配:根据指定的策略,在IOC容器中匹配某一个bean,自动为指定的bean中所依赖的类类型或者接口类型赋值 之前我们学过的依赖注入,我们在为不同属性赋值时,例如类类型的属性…...
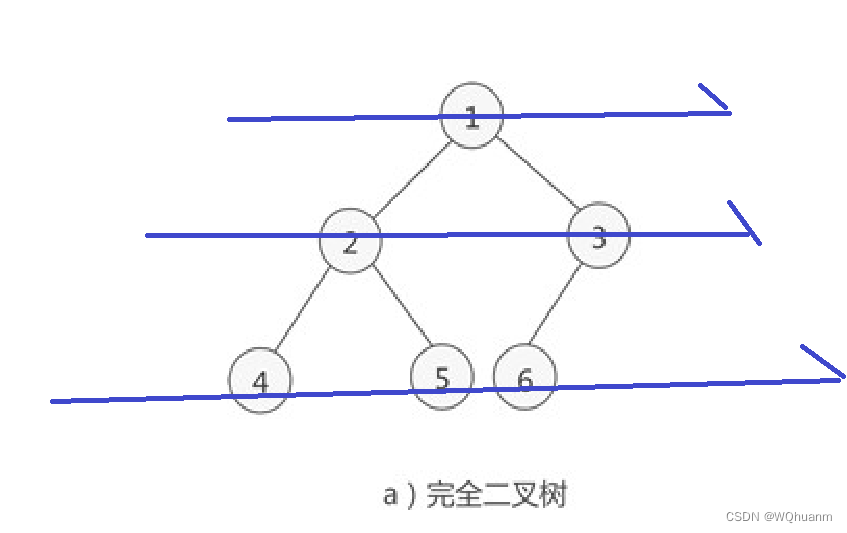
完全二叉树的4种遍历方式
一张二叉树的图 1,二叉树的特点 每个点p的左儿子是p*2,右儿子是p*21,可以分别表示为p<<1与p<<1|1节点的序号是从左到右,从上到下增加的每个点至多2个儿子(屁话(bushi)) 2ÿ…...
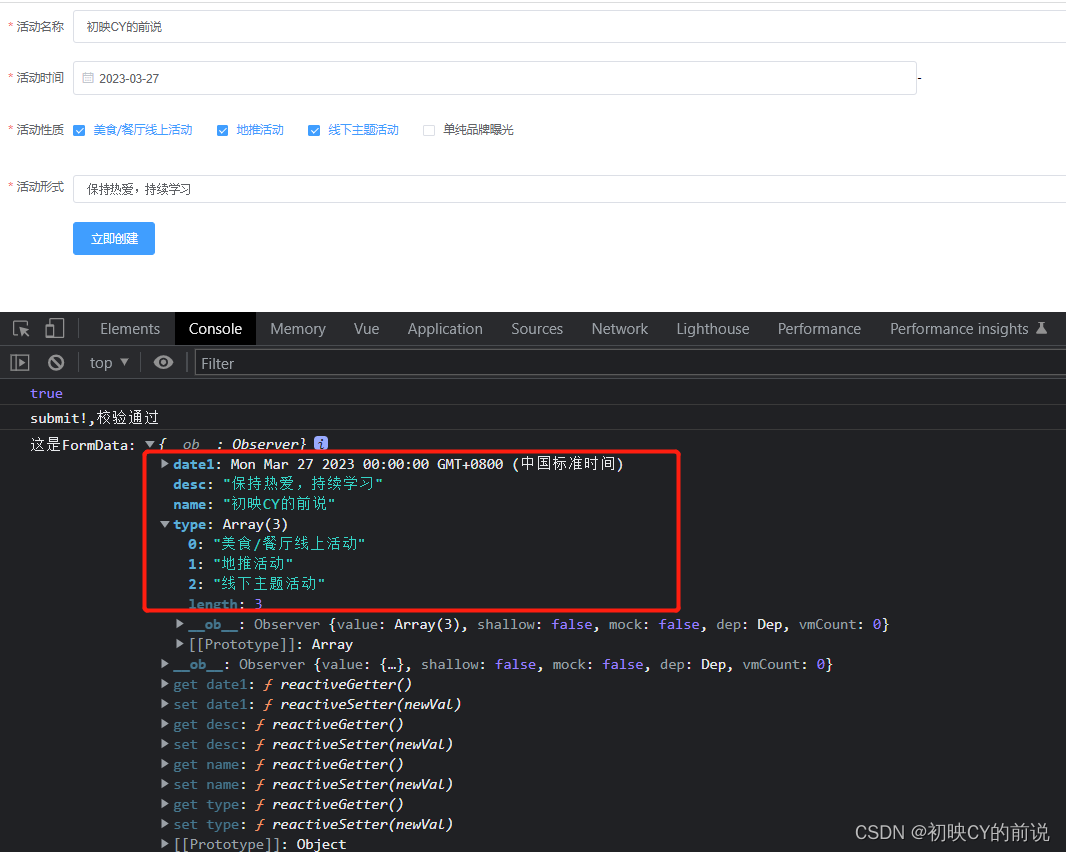
【vue2】使用elementUI进行表单验证实操(附源码)
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:vue使用elementUI进行表单验证实操(附源码) 【前言】我们在构建一…...

JUC之阻塞队列解读(BlockingQueue)
目录 BlockingQueue 简介 BlockingQueue 核心方法 1.放入数据 2.获取数据 入门代码案例 常见的 BlockingQueue ArrayBlockingQueue(常用) LinkedBlockingQueue(常用) PriorityBlockingQueue SynchronousQueue LinkedTransferQueue LinkedBlockingDeque 小结 Bloc…...
LCHub:ChatGPT4和低代码来临,程序员面临下岗?
一个网友吐槽道: “ 建站出来了,你们说程序员会失业。 低代码出来了,你们说程序员会失业。 Copilot出来了,你们说程序员会失业。 Chatgpt出来了,你们说程序员会失业 虽然这只是网友的吐槽,但却引起了小编的好奇。为何程序员那么容易被新技术取代?今天小编打算跟大家…...
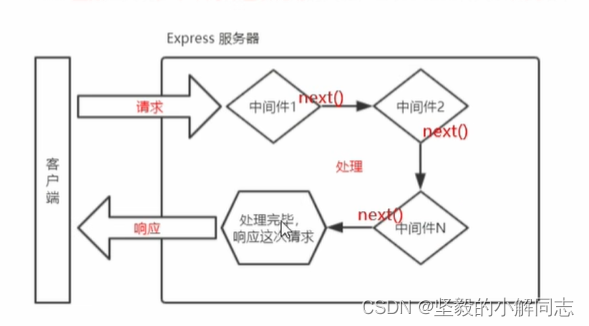
【Node.js】Express框架的基本使用
✍️ 作者简介: 前端新手学习中。 💂 作者主页: 作者主页查看更多前端教学 🎓 专栏分享:css重难点教学 Node.js教学 从头开始学习 目录 初识Express Express简介 什么是Express 进一步理解 Express Express能做什么 Express的基本使用 …...
使用docker 和 kubnernetes 部署单节点/多节点 kafka 环境
参考资料 https://kafka.apachecn.org/documentation.html#configuration kafka的broker有三个核心配置 broker.idlog.dirszookeeper.connect docker启动单节点kafka环境 启动zookeeper 可配置的环境变量,https://gallery.ecr.aws/bitnami/zookeeper $ docker …...
Linux使用:环境变量指南和CPU和GPU利用情况查看
Linux使用:环境变量指南和CPU和GPU利用情况查看Linux环境变量初始化与对应文件的生效顺序Linux的变量种类设置环境变量直接运行export命令定义变量修改系统环境变量修改用户环境变量修改环境变量配置文件环境配置文件的区别profile、 bashrc、.bash_profile、 .bash…...

ChatGPT资源宝库:从提示工程到项目实践的完整指南
1. 项目概述:一份关于ChatGPT的“Awesome”清单意味着什么?如果你最近在GitHub上搜索过任何与ChatGPT、AI或提示工程相关的内容,那么你大概率见过一个以“awesome-”开头的仓库。而sindresorhus/awesome-chatgpt无疑是这个领域里最知名、最常…...

3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南
3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否厌倦了每次运行AutoHotkey脚本都需要安…...
)
保姆级教程:在Ubuntu 20.04上从源码编译aarch64-linux-gnu交叉工具链(GCC 9.2.0 + Glibc 2.30)
深度实践:从源码构建aarch64-linux-gnu交叉工具链全指南 在嵌入式开发领域,交叉编译工具链的构建能力是区分普通开发者与资深工程师的重要标志。当现成的预编译工具链无法满足特定需求时,从源码手动构建工具链不仅能解决兼容性问题࿰…...

技能工程化框架:从标准化定义到编排实战
1. 项目概述:从“技能”到“智能”的工程化桥梁在当今的软件开发领域,尤其是涉及复杂交互和自动化流程的场景,我们常常会听到“技能”这个词。它听起来很抽象,但如果你拆解过任何一款智能助手、自动化机器人或者一个大型的业务流程…...

5分钟掌握小红书无水印下载:让内容保存效率提升300%
5分钟掌握小红书无水印下载:让内容保存效率提升300% 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&#…...

Unity游戏开发集成MCP协议:AI助手自动化操作指南
1. 项目概述:Unity游戏开发中的MCP革命如果你是一名Unity开发者,最近可能已经注意到一个名为“CoderGamester/mcp-unity”的项目在GitHub上悄然走红。这不仅仅是一个普通的插件或工具包,它代表了一种全新的工作流范式,旨在将大型语…...

【C语言】printf格式化输出:你真的理解“四舍五入”的陷阱吗?
1. 从printf的"四舍五入"陷阱说起 那天我在调试一个财务计算程序时,发现金额显示总差那么几分钱。比如3.145元应该显示为3.15,但程序输出却是3.14。这让我想起刚学C语言时踩过的坑——printf的格式化输出并不像数学课教的四舍五入那样简单。 先…...

终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效
终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经因为ThinkPad风扇的"直升机起…...

Claw框架数据库迁移工具claw-migrate:原理、实践与团队协作指南
1. 项目概述:一个专为Claw设计的迁移工具最近在折腾一个叫Claw的开源项目,它本身是一个轻量级的Web框架,用起来挺顺手。但项目迭代过程中,难免会遇到数据库结构变更、数据迁移这类“脏活累活”。手动写SQL脚本?太原始&…...

开源大模型推理引擎Takeoff部署指南:从原理到生产实践
1. 项目概述:一个让大模型推理“起飞”的开源引擎 如果你正在为如何将那些动辄几十GB、几百亿参数的大语言模型(LLM)部署到生产环境而头疼,或者厌倦了为每一次API调用支付高昂的费用,那么今天聊的这个项目,…...