代码随想录算法训练营第十四天|递归 226.翻转二叉树 101. 对称二叉树 104.二叉树的最大深度 111.二叉树的最小深度
226.翻转二叉树
翻转一棵二叉树。
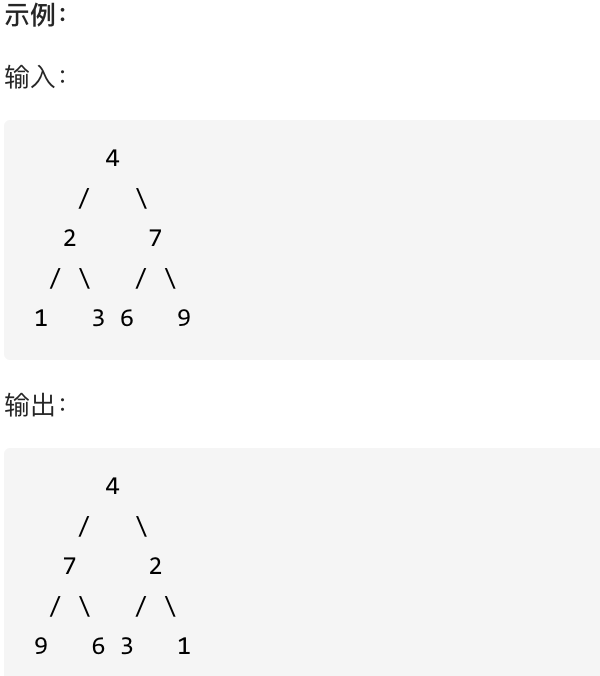
思路:
在这里需要注意的是,在递归的时候唯独中序遍历是不可用的,这是因为先对左子树进行了反转,又对自身进行了反转,对自身反转后原本的左子树变成了右子树,如果此时又轮到对右子树进行翻转,相当于原本的右子树没操作而对原来的左子树进行了两次翻转。
所以我们选择前序遍历,根据递归三部曲:
1.确定参数和返回值:参数是节点,而返回值可以是返回根节点,但我个人在一开始做的时候人为自定义了一个新的函数来专门对二叉树进行反转,是直接对二叉树进行操作的,所以认为不需要返回值,选择void或者->None
2.确定终止条件:当左孩子和右孩子都不存在的时候说明此时翻转无意义,此时return。(但规范写法的思路是当节点为空的时候return,我想这是因为如果只有一个左(右)孩子的时候依然会调用函数,这个时候有一个孩子节点是为空的,所以此时在定义递归函数的时候肯定还是需要定义一个条件:当节点为空时return,自然就不需要我一开始设置的这个条件了)
3.单层递归的逻辑:我选择最好理解的前序遍历,逻辑就是先对本节点进行操作,即对本节点的左右孩子进行互换,然后对左子树(左孩子节点)进行反转操作(调用递归),再对右子树进行反转操作。
根据以上思路,实现代码如下:
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution:def reverseTree(self, node: Optional[TreeNode]) -> None:if not node:returnif not node.left and not node.right:returnnode.left, node.right = node.right, node.leftself.reverseTree(node.left)self.reverseTree(node.right)def invertTree(self, root: Optional[TreeNode]) -> Optional[TreeNode]:if not root:return rootself.reverseTree(root)return root附上规范写法,更简洁和有效,应该学习:
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution:def invertTree(self, root: TreeNode) -> TreeNode:if not root:return Noneroot.left, root.right = root.right, root.leftself.invertTree(root.left)self.invertTree(root.right)return root以上是递归写法,自然还能用迭代的方法,个人更喜欢使用广度优先(层序遍历),非常好理解,思路就是层序遍历压入队列中,然后依次进行反转,代码实现如下:
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution:def invertTree(self, root: TreeNode) -> TreeNode:if not root:return rootqueue = deque([root])while(queue):for _ in range(len(queue)):cur = queue.popleft()if cur.left:queue.append(cur.left)if cur.right:queue.append(cur.right)cur.left, cur.right = cur.right, cur.leftreturn root101. 对称二叉树
给定一个二叉树,检查它是否是镜像对称的。

思路:
第一反应还是层序遍历,只需要将包括None的每一层节点数组都压入数组中,如果将数组的每一层数组反序输出与原数组都相同,那么说明是对称的。
但还是以学习递归为主,先优先实现递归的方法,思路是在每一个递归过程中,判断【左孩子的左孩子】和【右孩子的右孩子】是否相等,以及判断【左孩子的右孩子】和【右孩子的左孩子】是否相等。代码随想录将其分别称为外侧和里侧,可能更好理解一点。除了以上还需要确保根节点的左右孩子相等才行。
递归三部曲:
- 参数和返回值:参数为两个,是左右孩子两个节点,即要进行比较的两个子树根节点。返回值应该是bool,当出现任意一个false都应该返回false。
- 终止条件:①左空右不空->false ②左不空右空->false ③左右为空->True ④左右不空但数值不等->false
- 递归逻辑:当左右不空且数值相等时(这里其实是⑤,所以上面④的时候不能用else,只能用else if或者elif),才进入递归逻辑:判断【左孩子的右孩子】和【右孩子的左孩子】是否相等,只有当两个条件都符合时返回True,否则返回false。
代码实现如下:
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution:def compare(self, node1: Optional[TreeNode], node2: Optional[TreeNode]) -> bool:if node1 and not node2:return Falseelif not node1 and node2:return Falseelif not node1 and not node2:return Trueelif node1.val != node2.val:return Falsebool1 = self.compare(node1.left, node2.right)bool2 = self.compare(node1.right, node2.left)return bool1 and bool2def isSymmetric(self, root: Optional[TreeNode]) -> bool:if not root:return Trueif not root.left and not root.right:return Truereturn self.compare(root.left, root.right)规范代码:
class Solution:def isSymmetric(self, root: TreeNode) -> bool:if not root:return Truereturn self.compare(root.left, root.right)def compare(self, left, right):#首先排除空节点的情况if left == None and right != None: return Falseelif left != None and right == None: return Falseelif left == None and right == None: return True#排除了空节点,再排除数值不相同的情况elif left.val != right.val: return False#此时就是:左右节点都不为空,且数值相同的情况#此时才做递归,做下一层的判断outside = self.compare(left.left, right.right) #左子树:左、 右子树:右inside = self.compare(left.right, right.left) #左子树:右、 右子树:左isSame = outside and inside #左子树:中、 右子树:中 (逻辑处理)return isSame层序遍历:
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution:def isSymmetric(self, root: Optional[TreeNode]) -> bool:if not root:return Trueres = []queue = deque([root])while queue:arr = []for _ in range(len(queue)):cur = queue.popleft()if not cur:arr.append(None)continuearr.append(cur.val)queue.append(cur.left)queue.append(cur.right)res.append(arr)for arr in res:if arr != arr[::-1]:return Falsereturn True规范代码(层序遍历):
class Solution:def isSymmetric(self, root: TreeNode) -> bool:if not root:return Truequeue = collections.deque([root.left, root.right])while queue:level_size = len(queue)if level_size % 2 != 0:return Falselevel_vals = []for i in range(level_size):node = queue.popleft()if node:level_vals.append(node.val)queue.append(node.left)queue.append(node.right)else:level_vals.append(None)if level_vals != level_vals[::-1]:return Falsereturn True104.二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例: 给定二叉树 [3,9,20,null,null,15,7],

返回它的最大深度 3 。
思路:
依然第一反应是层序遍历:每到新一层就更新最大值,最后返回最大值即可。
还是以学习递归为主,递归思路:
节点的深度是孩子节点的深度+1,那么只需要递归计算孩子节点的深度然后+1即可。
递归三部曲:
- 参数和返回值:参数应该是传入一个节点。返回值是传入节点的两个孩子节点的深度的最大值,应该是int类型。
- 终止条件:当左右孩子都不存在的时候,说明是叶子节点,此时返回深度1。当本节点不存在的时候,这时候为了区别于叶子节点,返回深度0
- 递归逻辑:对两个左右孩子进行递归调用,得到两个数值中的最大值然后再+1就可以得到当前节点的深度。
代码实现如下:
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution:def getdepth(self, node: Optional[TreeNode]) -> int:if not node:return 0if not node.left and not node.right:return 1return max(self.getdepth(node.left), self.getdepth(node.right)) + 1def maxDepth(self, root: Optional[TreeNode]) -> int:if not root:return 0return self.getdepth(root)层序遍历:
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution:def maxDepth(self, root: Optional[TreeNode]) -> int:if not root:return 0queue = deque([root])res = 0while queue:for _ in range(len(queue)):cur = queue.popleft() if cur.left:queue.append(cur.left)if cur.right:queue.append(cur.right)res += 1return res
111.二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],

返回它的最小深度 2.
思路:
层序遍历思路:每层遍历记录层数,当第一次遍历到叶子节点的时候直接返回深度即可。
递归思路:与前面计算最大深度相似,但是需要注意的是,有一种情况不一样,也就是只有一个孩子的情况,因为没有孩子的情况有可能会返回0,但此时本节点并非叶子节点,此时如果空节点返回了深度0,那么此时计算到的最小深度是错误的。所以该题应该在遇到空孩子的时候直接跳过。
递归三部曲:
- 参数和返回值:参数是进入递归调用的节点。返回值应该是int类型的深度值。
- 终止条件:当左右孩子都不存在时(为叶子节点),返回深度1
- 递归逻辑:当左右孩子均存在时,计算两个孩子节点的深度的最小值,得到后+1作为返回值。如果只存在一个孩子,则计算存在的孩子节点的深度,然后+1作为返回值。、
代码实现如下:
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution:def minDepth(self, root: Optional[TreeNode]) -> int:return self.getdepth(root)def getdepth(self, node: Optional[TreeNode]) -> int:if not node:return 0if not node.left and not node.right:return 1if node.left and node.right:return min(self.getdepth(node.left), self.getdepth(node.right)) + 1elif not node.left and node.right:return self.getdepth(node.right) + 1elif node.left and not node.right:return self.getdepth(node.left) + 1规范代码:
class Solution:def getDepth(self, node):if node is None:return 0leftDepth = self.getDepth(node.left) # 左rightDepth = self.getDepth(node.right) # 右# 当一个左子树为空,右不为空,这时并不是最低点if node.left is None and node.right is not None:return 1 + rightDepth# 当一个右子树为空,左不为空,这时并不是最低点if node.left is not None and node.right is None:return 1 + leftDepthresult = 1 + min(leftDepth, rightDepth)return resultdef minDepth(self, root):return self.getDepth(root)层序遍历:
# Definition for a binary tree node.# class TreeNode:# def __init__(self, val=0, left=None, right=None):# self.val = val# self.left = left# self.right = rightclass Solution:def minDepth(self, root: Optional[TreeNode]) -> int:if not root:return 0queue = deque([root])res = 0while queue:for _ in range(len(queue)):cur = queue.popleft() if cur.left:queue.append(cur.left)if cur.right:queue.append(cur.right)if not cur.left and not cur.right:return res+1res += 1return res相关文章:
代码随想录算法训练营第十四天|递归 226.翻转二叉树 101. 对称二叉树 104.二叉树的最大深度 111.二叉树的最小深度
226.翻转二叉树 翻转一棵二叉树。 思路: 在这里需要注意的是,在递归的时候唯独中序遍历是不可用的,这是因为先对左子树进行了反转,又对自身进行了反转,对自身反转后原本的左子树变成了右子树,如果此时又轮…...

Spark 任务与 Spark Streaming 任务的差异详解
Spark 任务与 Spark Streaming 任务的主要差异源自于两者的应用场景不同:Spark 主要处理静态的大数据集,而 Spark Streaming 处理的是实时流数据。这些差异体现在任务的调度、执行、容错、数据处理模式等方面。 接下来,我们将从底层原理和源…...

Git提示信息 Pulling is not possible because you have unmerged files.
git [fatal] hint: Pulling is not possible because you have unmerged files.hint: Fix them up in the … error: Pulling is not possible because you have unmerged files. 错误:无法提取,因为您有未合并的文件。 hint: Fix them up in the work tree, and t…...

python编程开发“人机猜拳”游戏
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...
丹摩智算平台部署 Llama 3.1:实践与体验
文章目录 前言部署前的准备创建实例 部署与配置 Llama 3.1使用心得总结 前言 在最近的开发工作中,我有机会体验了丹摩智算平台,部署并使用了 Llama 3.1 模型。在人工智能和大模型领域,Meta 推出的 Llama 3.1 已经成为了目前最受瞩目的开源模…...

SpringCloud 2023各依赖版本选择、核心功能与组件、创建项目(注意事项、依赖)
目录 1. 各依赖版本选择2. 核心功能与组件3. 创建项目3.1 注意事项3.2 依赖 1. 各依赖版本选择 SpringCloud: 2023.0.1SpringBoot: 3.2.4。参考Spring Cloud Train Reference Documentation选择版本 SpringCloud Alibaba: 2023.0.1.0*: 参考Spring Cloud Alibaba选择版本。同时…...

串行化执行、并行化执行
文章目录 1、串行化执行2、并行化测试(多线程环境)3、任务的执行是异步的,但主程序的继续执行是同步的 可以将多个任务编排为并行和串行化执行。 也可以处理编排的多个任务的异常,也可以返回兜底数据。 1、串行化执行 顺序执行、…...
)
二叉搜索树(c++版)
前言 在前面我们介绍过二叉树这个数据结构,今天我们更进一步来介绍二叉树的一种在实现中运用的场景——二叉搜索树。二叉搜索树顾名思义其在“搜索”这个场景下有不俗的表现,之所以会这样是因为它在二叉树的基础上添加了一些属性。下面我们就来简单的介…...

每日1题-7
...

简单实现log记录保存到文本和数据库
简单保存记录到txt,sqlite数据库,以及console监控记录 using System; using System.Collections.Generic; using System.ComponentModel; using System.Text; using System.Data.SQLite; using System.IO;namespace NlogFrame {public enum LogType{Tr…...

敏感字段加密 - 华为OD统一考试(E卷)
2024华为OD机试(E卷+D卷+C卷)最新题库【超值优惠】Java/Python/C++合集 题目描述 【敏感字段加密】给定一个由多个命令字组成的命令字符串: 1、字符串长度小于等于127字节,只包含大小写字母,数字,下划线和偶数个双引号; 2、命令字之间以一个或多个下划线 进行分割; 3、可…...

go 安装三方库
go版本 go versiongo version go1.23.1 darwin/arm64安装 redis 库 cd $GOPATH说明: 这里可以改 GOPATH的值 将如下 export 语句写入 ~/.bash_profile 文件中 export GOPATH/Users/goproject然后使其生效 source ~/.bash_profile初始化生成 go.mod 文件 go mod…...

Java 中的 volatile和synchronized和 ReentrantLock区别讲解和案例示范
在 Java 的并发编程中,volatile、synchronized 和 ReentrantLock 是三种常用的同步机制。每种机制都有其独特的特性、优缺点和适用场景。理解它们之间的区别以及在何种情况下使用哪种机制,对提高程序的性能和可靠性至关重要。本文将详细探讨这三种机制的…...

从GDAL中 读取遥感影像的信息
从GDAL提供的实用程序来看,很多程序的后缀都是 .py ,这充分地说明了Python语言在GDAL的开发中得到了广泛的应用。 1. 打开已有的GeoTIF文件 下面我们试着读取一个GeoTiff文件的信息。第一步就是打开一个数据集。 >>> from osgeo import gdal…...

算法闭关修炼百题计划(一)
多看优秀的代码一定没有错,此篇博客属于个人学习记录 1.两数之和2.前k个高频元素3.只出现一次的数字4.数组的度5.最佳观光组合6.整数反转7.缺失的第一个正数8.字符串中最多数目的子序列9.k个一组翻转链表10.反转链表II11. 公司命名12.合并区间13.快速排序14.数字中的…...

vue3实现打字机的效果,可以换行
之前看了很多文章,效果是实现了,就是没有自动换行的效果,参考了文章写了一个,先上个效果图,卡顿是因为模仿了卡顿的效果,还是很丝滑的 目录 效果图:代码如下 效果图: 
【如何学习操作系统】——学会学习的艺术
🐟作者简介:一名大三在校生,喜欢编程🪴 🐡🐙个人主页🥇:Aic山鱼 🐠WeChat:z7010cyy 🦈系列专栏:🏞️ 前端-JS基础专栏✨前…...

stm32 flash无法擦除
通过bushound调试代码发现,当上位机发送命令到模组后flash将不能擦除,通过 HAL_FLASH_GetError()函数查找原因是FLASH Programming Sequence error(编程顺序错误),解决办法是在解锁后清零标志位…...

Android—ANR日志分析
获取ANR日志: ANR路径:/data/anrADB指令:adb bugreport D:\bugrep.zip ANR日志分析步骤: “main” prio:主线程状态beginning of crash:搜索 crash 相关信息CPU usage from:搜索 cpu 使用信息…...

9.29 LeetCode 3304、3300、3301
思路: ⭐进行无限次操作,但是 k 的取值小于 500 ,所以当 word 的长度大于 500 时就可以停止操作进行取值了 如果字符为 ‘z’ ,单独处理使其变为 ‘a’ 得到得到操作后的新字符串,和原字符串拼接 class Solution { …...

从手忙脚乱到智能掌控:League-Toolkit如何解决你的英雄联盟痛点
从手忙脚乱到智能掌控:League-Toolkit如何解决你的英雄联盟痛点 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾经在极地大…...

为什么92%的数据分析师还没用上Gemini Sheets功能?—— 一份被谷歌官方忽略的AI分析落地清单
更多请点击: https://intelliparadigm.com 第一章:Gemini Sheets数据分析的现状与认知断层 Gemini Sheets 作为 Google Workspace 生态中新兴的 AI 增强型电子表格工具,正逐步替代传统 Sheets 的部分分析场景。然而,当前用户实践…...

优化ESP32 ADF 音频问题
可以,现在已经进入音质调试阶段了,不是“能不能播放”的阶段。 你现在的问题大概率不是一个单点问题,而是下面几类之一: 1. 音量 / 增益太大,导致 ES8388 或 MD8002A 功放削顶失真 2. I2S 时钟不准,导致声音…...

基于Vue的纯前端的库存销售系统
🚀【开源】 基于Vue的纯前端的库存销售系统 项目地址:https://github.com/cuiyunhao-2026/warhouse-sales-management-system 这是基于art design pro模板的二次开发 模板地址:https://github.com/Daymychen/art-design-pro 你是否&#x…...

实战解析:用高斯过程回归搞定不确定性预测
1. 高斯过程回归能解决什么问题 我第一次接触高斯过程回归是在一个金融风控项目里。当时我们需要预测未来三个月的用户违约概率,但传统机器学习模型只能给出一个冰冷的数字预测,完全无法体现预测的可信程度。这就像天气预报只告诉你"明天会下雨&quo…...

航模电调XXD2212的“坑”与“宝”:从欠压报警到堵转丢步的实战避坑指南
XXD2212电调实战指南:从欠压保护到电机匹配的深度解析 1. 揭开XXD2212电调的神秘面纱 XXD2212作为航模圈内广为人知的入门级电调,以其极高的性价比吸引了大量无人机和机器人爱好者。这款电调采用新唐科技MS51FB9AE作为主控芯片,搭配六MOS管组…...

时间序列预测总翻车?试试用Python实现嵌套交叉验证来守住‘未来’数据
时间序列预测中的嵌套交叉验证:用Python守住数据的时间壁垒 当你在预测下周的销售额、下个月的电力负荷或明天的股价时,最可怕的不是模型不够复杂,而是它偷偷"作弊"了——通过窥探未来的数据来假装自己很聪明。这种时间序列预测中的…...

边缘计算实战:基于 Linux Netns 与标准海事网关抵御局域网横向攻击的物理隔离架构
摘要:扁平化局域网极易遭受 ARP 欺骗与黑客横向攻击。本文记录了在标准工业级海事网关上基于 Linux netns 构建网络物理与逻辑隔离防线的实操复盘。 导语:在实操一个远洋船载网络的安全重构项目时,我们面临一个极其严峻的威胁模型࿱…...

Windows 11终极优化指南:一键清理系统臃肿,免费提升51%性能
Windows 11终极优化指南:一键清理系统臃肿,免费提升51%性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to …...

【AI原生多任务学习实战白皮书】:SITS 2026官方未公开的5大优化范式与3类典型失效场景复盘
更多请点击: https://intelliparadigm.com 第一章:AI原生多任务学习:SITS 2026多目标优化实战技巧 在 SITS 2026 挑战赛中,AI 原生多任务学习(MTL)不再仅依赖共享特征表示,而是通过任务感知梯…...