机器学习分类算法评价指标
一. 分类评价指标
对机器学习算法的性能进行评估时,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价指标,这就是算法评价指标。分类算法的评价指标一般有准确率,精确率,召回率,F1-score,PR曲线,ROC,AUC。
在介绍具体的评价指标前,需要先以二分类为例引入混淆矩阵。
混淆矩阵
针对一个二分类问题,即将实例分成正类(positive)或反类(negative),在实际分类中会出现以下四种情况:
(1)若一个样本是正类,并且被预测为正类,即为真正类TP(True Positive )
(2)若一个样本是正类,但是被预测为反类,即为假反类FN(False Negative )
(3)若一个样本是反类,但是被预测为正类,即为假正类FP(False Positive )
(4)若一个样本是反类,并且被预测为反类,即为真反类TN(True Negative )
混淆矩阵的每一行是样本的预测分类,每一列是样本的真实分类,如下图所示。

二. 准确率(accuracy),精确率(precision),召回率(recall),F1-score
1. 准确率(accuracy)
精确率是预测正确的样本占所有样本的百分比。
accuracy=TP+TNTP+FP+TN+FNaccuracy = \frac{TP + TN}{TP + FP +TN + FN}accuracy=TP+FP+TN+FNTP+TN
局限:当数据的正负样本不均衡,仅仅使用这个指标来评价模型的性能优劣是不合适的。
假如一个测试集有正样本99个,负样本1个。模型把所有的样本都预测为正样本,那么模型的Accuracy为99%,看评价指标,模型的效果很好,但实际上模型没有任何预测能力。
2. 精确率(precision)
又叫查准率,它是模型预测为正样本的结果中,真正为正样本的比例。
precision=TPTP+FPprecision=\frac{TP}{TP + FP}precision=TP+FPTP
3. 召回率(recall)
又叫查全率,它是实际为正的样本中,被预测为正样本的比例。
recall=TPTP+FNrecall=\frac{TP}{TP + FN}recall=TP+FNTP
4. F1-score
F1-score是precision和recall的调和平均值。
F1=2∗Precision∗RecallPrecision+RecallF1 =\frac{2 * Precision * Recall}{ Precision + Recall}F1=Precision+Recall2∗Precision∗Recall
5. 编码实现
import numpy as np
from sklearn import datasets
import warnings
warnings.filterwarnings("ignore")
digits = datasets.load_digits()
x = digits.data
y = digits.target.copy()
y[digits.target == 9] = 1
y[digits.target != 9] = 0
x.shape
(1797, 64)
y.shape
(1797,)
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x, y, random_state=666)
from sklearn.linear_model import LogisticRegressionlog_reg = LogisticRegression()
log_reg.fit(x_train, y_train)
y_log_predict = log_reg.predict(x_test)
log_reg.score(x_test, y_test)
0.9755555555555555
#### 手动计算混淆矩阵
def TN(y_true, y_predict):assert len(y_true) == len(y_predict)return np.sum((y_true ==0) & (y_predict == 0))
TN(y_test, y_log_predict)
403
def FP(y_true, y_predict):assert len(y_true) == len(y_predict)return np.sum((y_true ==0) & (y_predict == 1))
FP(y_test, y_log_predict)
2
def FN(y_true, y_predict):assert len(y_true) == len(y_predict)return np.sum((y_true ==1) & (y_predict == 0))
FN(y_test, y_log_predict)
9
def TP(y_true, y_predict):assert len(y_true) == len(y_predict)return np.sum((y_true ==1) & (y_predict == 1))
TP(y_test, y_log_predict)
36
def my_confusion_matrix(y_true, y_predict):return np.array([[TN(y_true, y_predict),FP(y_true, y_predict)],[FN(y_true, y_predict),TP(y_true, y_predict)]])
my_confusion_matrix(y_test, y_log_predict)
array([[403, 2],[ 9, 36]])
# 使用sklearn 提供的api计算混淆矩阵from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_log_predict)
array([[403, 2],[ 9, 36]])
#手动计算precision
def my_precision_score(y_true, y_predict):return TP(y_true, y_predict) / (TP(y_true, y_predict) + FP(y_true, y_predict))my_precision_score(y_test, y_log_predict)
0.9473684210526315
# 使用sklearn提供的api计算precision
from sklearn.metrics import precision_score
precision_score(y_test, y_log_predict)
0.9473684210526315
#手动计算recall
def my_recall_score(y_true, y_predict):return TP(y_true, y_predict) / (TP(y_true, y_predict) + FN(y_true, y_predict))my_recall_score(y_test,y_log_predict)
0.8
#使用sklearn 提供的api计算recall
from sklearn.metrics import recall_score
recall_score(y_test, y_log_predict)
0.8
# 手动计算F1-score
def my_f1_score(precision, recall):try:return 2 * precision * recall / (precision + recall)except:return 0.0
my_f1_score(precision_score(y_test, y_log_predict), recall_score(y_test, y_log_predict))
0.8674698795180723
# 使用sklearn 提供的api计算F1-score
from sklearn.metrics import f1_score
f1_score(y_test, y_log_predict)
0.8674698795180723
三. PR曲线
1. PR曲线
P-R曲线是描述精确率和召回率变化的曲线。对于所有的正样本,设置不同的阈值,模型预测所有的正样本,再根据对应的精准率和召回率绘制相应的曲线。
一般情况下一个分类模型不可能同时获得高的精准率与召回率,当精准率较高时,召回率会降低;当召回率较高时,精准率会降低。

模型与坐标轴围成的面积越大,则模型的性能越好。但一般来说,曲线下的面积是很难进行估算的,所以衍生出了“平衡点”(Break-Event Point,简称BEP),即当P=R时的取值,平衡点的取值越高,性能更优。
2. 编码实现
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
digits = datasets.load_digits()
x = digits.data
y = digits.target.copy()
y[digits.target == 9] = 1
y[digits.target != 9] = 0
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x, y, random_state=666)
from sklearn.linear_model import LogisticRegressionlog_reg = LogisticRegression()
log_reg.fit(x_train, y_train)
y_log_predict = log_reg.predict(x_test)
log_reg.score(x_test, y_test)
0.9755555555555555
# 获取分类算法的分类阈值
decision_scores = log_reg.decision_function(x_test)
手动绘制PR曲线
from sklearn.metrics import precision_score
from sklearn.metrics import recall_scoreprecisions = []
recalls = []
thresholds = np.arange(np.min(decision_scores), np.max(decision_scores), 0.1)
for threshold in thresholds:y_predict = np.array(decision_scores >= threshold, dtype = 'int')precisions.append(precision_score(y_test, y_predict))recalls.append(recall_score(y_test, y_predict))
plt.plot(precisions, recalls)

使用sklearn API绘制PR曲线
from sklearn.metrics import precision_recall_curveprecisions1, recalls1, thresholds1 = precision_recall_curve(y_test, decision_scores)
plt.plot(precisions1, recalls1)

四. ROC和AUC
1. ROC曲线
ROC(Receiver Operating Characteristic)曲线,又称接受者操作特征曲线。曲线对应的纵坐标是TPR,横坐标是FPR。下面先介绍下TPR和FPR。
-
TPR(true positive rate):真正类率,也称为灵敏度(sensitivity),等同于召回率。表示被正确分类的正实例占所有正实例的比例。
TPR=TPTP+FNTPR=\frac{TP}{TP + FN}TPR=TP+FNTP -
FPR(false positive rate):负正类率,表示被错误分类的负实例占所有负实例的比例。
FPR=FPFP+TNFPR=\frac{FP}{FP + TN}FPR=FP+TNFP

设置不同的阈值,会得到不同的TPR和FPR,而随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着负类,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。理想目标: TPR=1, FPR=0,即图中(0,1)点。故ROC曲线越靠拢(0,1)点,即,越偏离45度对角线越好。对应的就是TPR越大越好,FPR越小越好。
2. AUC
AUC(Area Under Curve)是处于ROC曲线下方的那部分面积的大小。AUC越大,代表模型的性能越好。
一个分类模型的AUC值越大,则认为算法表现的越好。
3. 编码实现
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
digits = datasets.load_digits()
x = digits.data
y = digits.target.copy()
y[digits.target == 9] = 1
y[digits.target != 9] = 0
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x, y, random_state=666)
from sklearn.linear_model import LogisticRegressionlog_reg = LogisticRegression()
log_reg.fit(x_train, y_train)
y_log_predict = log_reg.predict(x_test)
log_reg.score(x_test, y_test)
0.9755555555555555
# 获取分类算法的分类阈值
decision_scores = log_reg.decision_function(x_test)
使用sklearn API绘制ROC曲线
from sklearn.metrics import roc_curvefprs1, tprs1, thresholds = roc_curve(y_test, decision_scores)
plt.plot(fprs1, tprs1)

使用sklearn API计算auc的值
from sklearn.metrics import roc_auc_scoreroc_auc_score(y_test, decision_scores)
0.9824417009602195
相关文章:
机器学习分类算法评价指标
一. 分类评价指标 对机器学习算法的性能进行评估时,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价指标,这就是算法评价指标。分类算法的评价指标一般有准确率,精确率,召回率,F1-score&a…...

Socks5代理服务器示例详解
Go语言中变量的声明和JavaScript很像,使用var关键字,变量的声明、定义有好几种形式 变量和常量 // 声明并初始化一个变量 var m int 10 // 声明初始化多个变量 var i, j, k 1, 2, 3 // 多个变量的声明(注意小括号的使用) var(no intname string ) //…...

使用 Docker 和 Nginx 反向代理访问 ChatGPT API
在许多应用程序中,我们需要从一个外部服务中获取数据。然而,由于种种原因(例如跨域问题、API 访问限制等),我们可能无法直接从客户端访问这些服务。这时,反向代理可以成为我们的救星。在这篇文章中…...

[前端笔记038]vue2之vueRouter、elementUI
前言 本笔记参考视频,尚硅谷:BV1Zy4y1K7SH p117 - p135 相关理解 vue 的一个插件库,专门用来实现SPA 应用单页 Web 应用(single page web application,SPA),整个应用只有一个完整的页面点击页面中的导航…...

ChatGPT使用案例之操作Excel
ChatGPT使用案例之操作Excel 微软已经通过其官网宣布,正在将其基于GPT-4的人工智能(AI)技术植入到其Office办公软件当中,该功能名为“Microsoft 365 Copilot”。微软称其是基于大语言模型的下一代AI生产力技术,目前已经向部分商业用户开放。 Microsoft 365 负责人Jared …...

【算法基础】(二)数据结构 --- 单链表
✨个人主页:bit me ✨当前专栏:算法基础 🔥专栏简介:该专栏主要更新一些基础算法题,有参加蓝桥杯等算法题竞赛或者正在刷题的铁汁们可以关注一下,互相监督打卡学习 🌹 🌹 dz…...

STL容器之<multiset>
文章目录测试环境multiset介绍头文件模块类定义对象构造初始化元素访问元素插入和删除元素查找容器大小迭代器其他函数测试环境 系统:ubuntu 22.04.2 LTS 64位 gcc版本:11.3.0 编辑器:vsCode 1.76.2 multiset介绍 关联式容器。元素是唯一的…...
(附python示例代码))
python实战应用讲解-【numpy专题篇】numpy常见函数使用示例(三)(附python示例代码)
目录 Python numpy.finfo()函数 Python Numpy MaskedArray.masked_less()函数 Python Numpy MaskedArray.masked_less_equal()函数 Python Numpy MaskedArray.masked_not_equal()函数 Python Numpy MaskedArray masked_outside()函数 Python Numpy MaskedArray.masked_wh…...

【Android笔记89】Android之全局加载框Gloading的使用
这篇文章,主要介绍Android之全局加载框Gloading的使用。 目录 一、Gloading全局加载框 1.1、Gloading介绍 1.2、Gloading运行效果 1.3、Gloading的使用...
php微信小程序java+Vue高校课程课后辅导在线教育系统nodejs+python
目 录 1绪论 1 1.1项目研究的背景 1 1.2开发意义 1 1.3项目研究现状及内容 5 1.4论文结构 5 2开发技术介绍 7 2.1 B/S架构 7 2.2 MySQL 介绍 7 2.3 MySQL环境配置 7 2.5微信小程序技术 8 3系统分析 9 3.1可行性分析 9 3.1.1技术可行性 9 3.1.2经济可行性 9 3.1.3操作可行性 10 …...

公司刚来的00后真卷,上班还没2年,跳到我们公司起薪20k....
都说00后躺平了,但是有一说一,该卷的还是卷。 这不,前段时间我们公司来了个00后,工作都没两年,跳槽到我们公司起薪18K,都快接近我了。后来才知道人家是个卷王,从早干到晚就差搬张床到工位睡觉了…...
Intel 处理器 macOS降级到Big Sur
1 创建可引导的 macOS 安装器 将移动硬盘作安装 Mac 操作系统的启动磁盘。 创建可引导安装器需要满足的条件 移动硬盘(格式化为 Mac OS 扩展格式),至少有 14GB 可用空间已下载 macOS Big Sur的安装器 2 下载 macOS macOS Big Sur安装器会…...
【网络安全】记一次红队渗透实战项目
一、信息收集 信息收集非常重要,有了信息才能知道下一步该如何进行,接下来将用 nmap 来演示信息收集 1、nmap 扫描存活 IP 由于本项目环境是 nat 模式需要项目 IP 地址,扫描挖掘本地的 IP 地址信息: 本机 IP 为:192…...

异想天开!没有CPU的操作系统
【引子】“The Last CPU”(https://doi.org/10.1145/3458336.3465291),ACM上的这一篇论文非常有趣,核心思想是如果计算机的体系结构中没有了CPU,那么,操作系统又会是怎样的呢?......不敢私藏&am…...

ChatGPT背后的指令学习是什么?PSU最新首篇《指令学习》技术全面综述,详述指令学习关键问题
来源: 专知 任务语义可以用一组输入到输出的例子或一条文本指令来表示。传统的自然语言处理(NLP)机器学习方法主要依赖于大规模特定任务样本集的可用性。出现了两个问题: 首先,收集特定于任务的标记示例,不适用于任务可能太复杂或太昂贵而无法注释&#…...

【Python】《我的世界》简简单单就可以完成?OMG~(附教学)
文章目录前言一、准备二、运行及操作三.代码解读与自定义总结前言 《我的世界 Minecraft》大家应该都听说过,但你有没有想过自己写一个这样的游戏呢?太难、太复杂了?也许吧,但是不试一试你怎么知道能不能成呢? 国外有…...
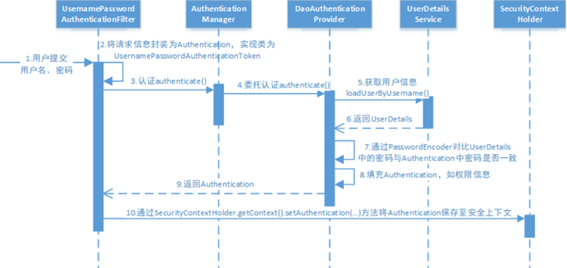
【SpringSecurity】认证授权框架——SpringSecurity使用方法
【SpringSecurity】认证授权框架——SpringSecurity使用方法 文章目录【SpringSecurity】认证授权框架——SpringSecurity使用方法1. 概述2. 准备工作2.1 引依赖2.2 测试3. 认证3.1 认证流程3.2 登录校验问题3.3 实现3.3.1 实现UserDetailsService接口3.3.2 密码存储和校验3.3.…...

java的Lambda表达式与方法引用详解
1. 定义 Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。 Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。 使用 Lambda 表达式可以使代码变的更加简洁紧凑。 1.1 通用定义 lambda 表达…...
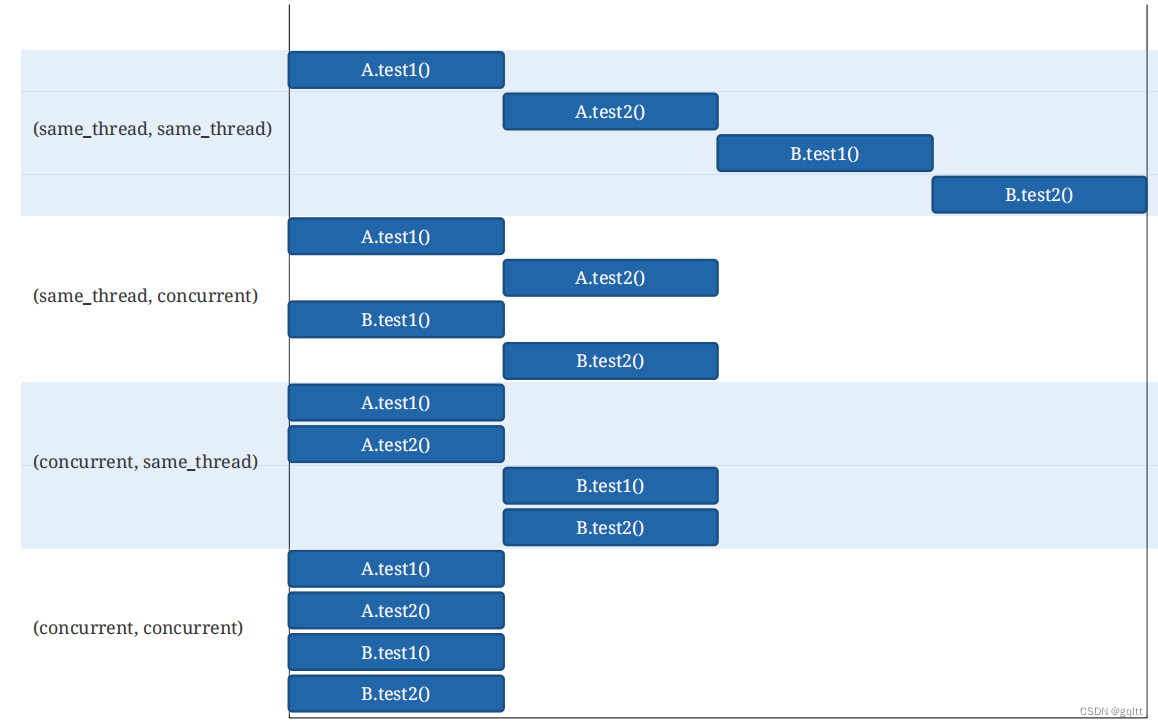
JUnit5用户手册~并行执行
两种运行模式 SAME_THREAD:默认的,测试方法在同一个线程CONCURRENT:并行执行,除非有资源锁junit-platform.properties配置参数配置所有测试方法都并行 junit.jupiter.execution.parallel.enabled true junit.jupiter.execution.…...

【从零开始学习 UVM】3.3、UVM TestBench架构 —— UVM Environment [uvm_env]
文章目录 什么是UVM Environment?为什么验证组件不应该直接放置在test class中?创建UVM环境的步骤UVM环境示例Examples环境重用示例什么是UVM Environment? 一个UVM环境包含多个可重用的验证组件,并根据应用程序要求定义它们的默认配置。例如,一个UVM环境可能有多个agent…...

终极免费离线OCR解决方案:Umi-OCR完整使用指南
终极免费离线OCR解决方案:Umi-OCR完整使用指南 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 …...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...

从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧
从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧 在射频模块或高精度ADC供电设计中,电源的纯净度直接决定系统性能上限。当输出电压纹波超出ADC的LSB范围,或EMI噪声耦合到敏感信号链时,工程师往往需要重新审视D…...

从日志到环境变量:根治 Android Studio AVD 启动报错“The emulator process has terminated”
1. 从错误弹窗到日志分析:定位问题的第一步 当你兴冲冲地打开Android Studio准备启动AVD(Android Virtual Device)时,突然弹出一个冰冷的提示框:"The emulator process has terminated",这感觉就…...

Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案
Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费…...

从TPM到机密计算:远程证明技术原理与zap1项目实践指南
1. 项目概述与核心价值最近在整理一些零散的学习笔记时,发现了一个挺有意思的项目,叫Frontier-Compute/zap1-learning-attestation。乍一看这个标题,可能有点让人摸不着头脑,尤其是对于刚接触可信计算或者硬件安全领域的朋友来说。…...

自主智能体框架构建指南:从LLM工具调用到多任务规划系统
1. 项目概述:一个能“开疆拓土”的智能体框架最近在开源社区里,一个名为njbrake/agent-of-empires的项目引起了我的注意。光看这个名字,就充满了野心和想象力——“帝国的代理人”。这可不是一个简单的脚本工具,而是一个旨在构建能…...

探索下一代命令行界面:OpenCLI 架构设计与插件化实践
1. 项目概述:一个面向未来的命令行界面原型最近在开源社区里,我注意到一个名为sys-fairy-eve/nightly-mvp-2026-03-19-opencli的项目。这个标题信息量不小,它不像一个成熟的产品,更像是一个开发过程中的里程碑快照。sys-fairy-eve…...

工控一体机电脑核心性能特征解析:从选型到部署的实战指南
1. 项目概述:为什么我们需要重新审视工控一体机电脑?在工业自动化、智能制造、智慧零售乃至边缘计算这些听起来高大上的领域里,有一类设备常常是幕后的“无名英雄”,它不像机器人手臂那样引人注目,也不像云端服务器那样…...
)
告别闪烁屏!瑞芯微RK3399开发板Debian系统烧写保姆级教程(含DriverAssistant v5.1.1 + AndroidTool v2.69)
RK3399开发板Debian系统烧写实战:从屏幕闪烁到完美显示的终极解决方案 当你在RK3399开发板上成功烧写Debian系统后,最期待的莫过于看到系统稳定运行的画面。然而,不少开发者却遭遇了屏幕闪烁的困扰——这个问题看似简单,背后却隐藏…...