Hadoop之——WordCount案例与执行本地jar包
目录
一、WordCount代码
(一)WordCount简介
1.wordcount.txt
(二)WordCount的java代码
1.WordCountMapper
2.WordCountReduce
3.WordCountDriver
(三)IDEA运行结果
(四)Hadoop运行wordcount
1.在HDFS上新建一个文件目录
2.新建一个文件,并上传至该目录下
3.执行wordcount命令
4.查看运行结果
5.第二次提交报错原因
6.进入NodeManager查看
7.启动历史服务器(如果已经启动可以忽略此步骤)
8.查看历史服务信息
三、执行本地代码
(一)项目代码
1.stuscore.csv
2.Student类
2.StudentMapper类
4.StudentReduce类
5.StudentDriver类
(二)java代码中指定路径
1.maven项目编译并打包
2.上传stuscore.csv到hdfs指定目录下
3.xftp上传target目录下的打包好的jar包上传到虚拟机
4.Hadoop运行hadoopstu-1.0-SNAPSHOT.jar
5.Hadoop运行结果
(三)java代码中不指定路径
1.StuudentDriver类
2.重新编译打包上传
3.HDFS命令执行该jar包
4.查看运行结果
一、WordCount代码
(一)WordCount简介
WordCount是大数据经典案例,其逻辑就是有一个文本文件,通过编写java代码与Hadoop核心组件的操作,查询每个单词出现的频率。
1.wordcount.txt
hello java hello hadoop hello java hadoop java hadoop java hadoop hadoop java hello java
(二)WordCount的java代码
1.WordCountMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;// Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
// <0,"hello world","hello",1>
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {Text text = new Text();IntWritable intWritable = new IntWritable();@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {System.out.println("WordCount stage Key:"+key+" Value:"+value);String[] words = value.toString().split(" ");// "hello world" -->[hello,world]for (String word :words) {text.set(word);intWritable.set(1);context.write(text,intWritable);// 输出键值对 <hello,1><world,1>}}
}2.WordCountReduce
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;// <KEYIN, VALUEIN, KEYOUT, VALUEOUT>
public class WordCountReduce extends Reducer<Text, IntWritable,Text, LongWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {System.out.println("Reduce stage Key:"+key+" Values:"+values.toString());int count = 0;for (IntWritable intWritable :values) {count += intWritable.get();}
// LongWritable longWritable = new LongWritable();
// longWritable.set(count);LongWritable longWritable = new LongWritable(count);System.out.println("Key:"+key+" ResultValue:"+longWritable.get());context.write(key,longWritable);}
}3.WordCountDriver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);job.setJarByClass(WordCountDriver.class);// 设置mapper类job.setMapperClass(WordCountMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 设置reduce类job.setReducerClass(WordCountReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 指定map输入的文件路径FileInputFormat.setInputPaths(job,new Path("D:\\javaseprojects\\hadoopstu\\input\\demo1\\wordcount.txt"));// 指定reduce结果输出的文件路径Path path = new Path("D:\\javaseprojects\\hadoopstu\\output");FileSystem fileSystem = FileSystem.get(path.toUri(),configuration);if(fileSystem.exists(path)){fileSystem.delete(path,true);}FileOutputFormat.setOutputPath(job,path);job.waitForCompletion(true);
// job.setJobName("");}
}
(三)IDEA运行结果
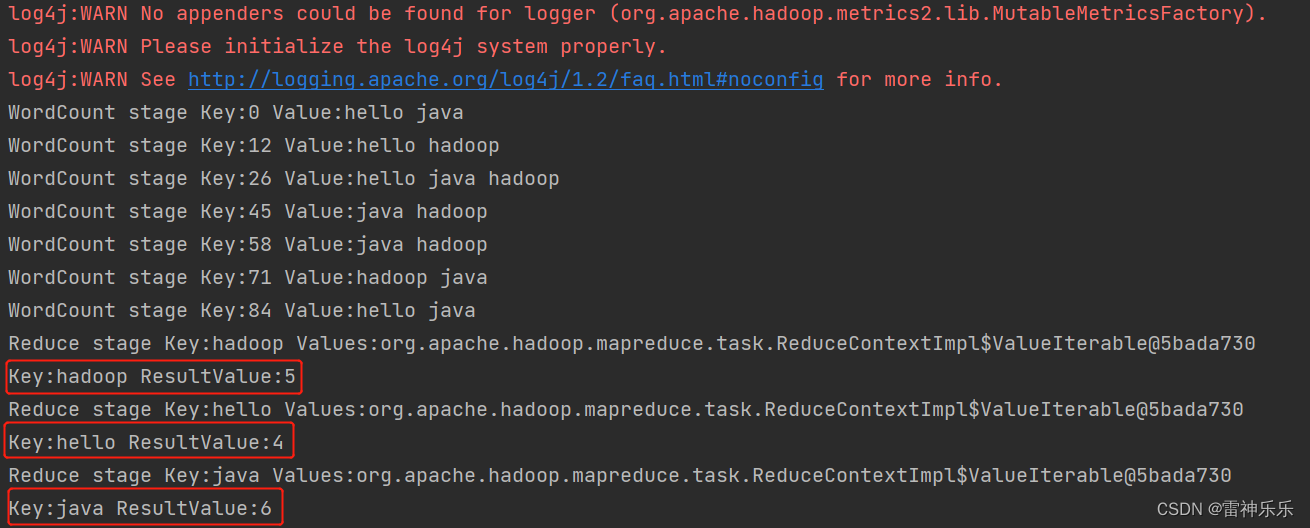
(四)Hadoop运行wordcount
1.在HDFS上新建一个文件目录
[root@lxm147 ~]# hdfs dfs -mkdir /inputpath
2023-02-10 23:05:40,098 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@lxm147 ~]# hdfs dfs -ls /
2023-02-10 23:05:52,217 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items
drwxr-xr-x - root supergroup 0 2023-02-08 08:06 /aa
drwxr-xr-x - root supergroup 0 2023-02-10 10:52 /bigdata
drwxr-xr-x - root supergroup 0 2023-02-10 23:05 /inputpath2.新建一个文件,并上传至该目录下
[root@lxm147 mapreduce]# vim ./test.csv
[root@lxm147 mapreduce]# hdfs dfs -put ./test.csv /inputpath
3.执行wordcount命令
[root@lxm147 mapreduce]# hadoop jar ./hadoop-mapreduce-examples-3.1.3.jar wordcount /inputpath /outputpath
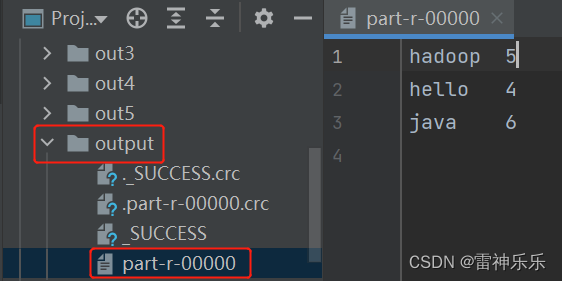
4.查看运行结果
(1)web端


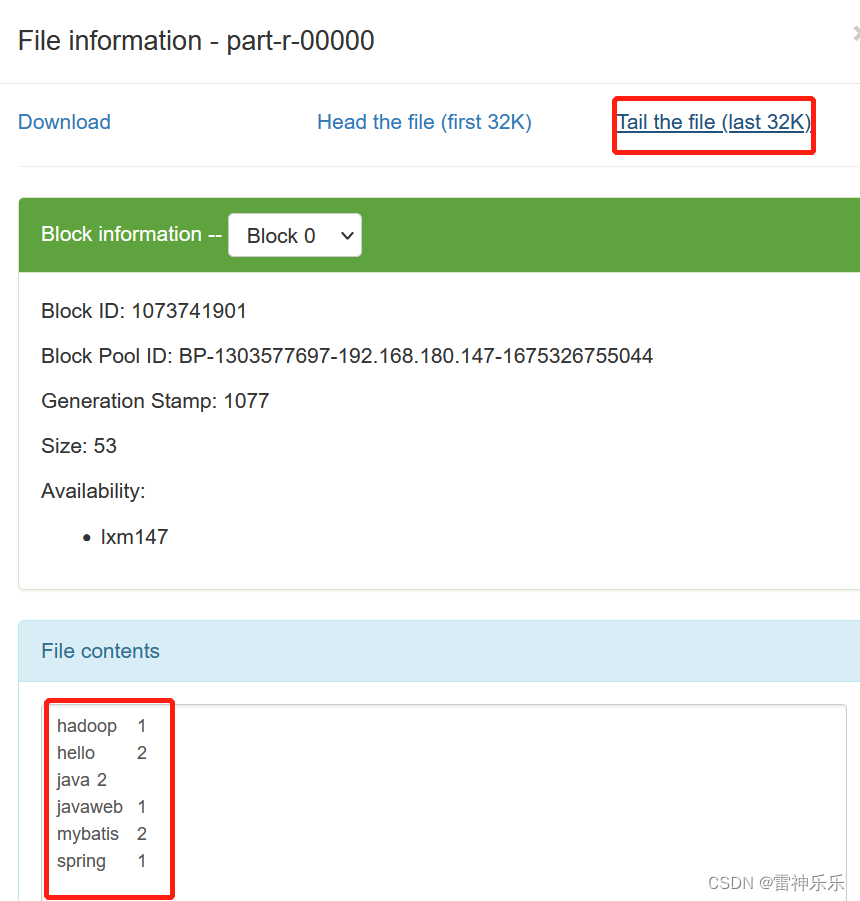
(2)命令行
[root@lxm147 mapreduce]# hdfs dfs -cat /outputpath/part-r-00000
2023-02-10 23:26:06,276 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-02-10 23:26:07,793 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
hadoop 1
hello 2
java 2
javaweb 1
mybatis 2
spring 15.第二次提交报错原因
执行wordcount命令前删除/outpath目录下的文件再执行即可
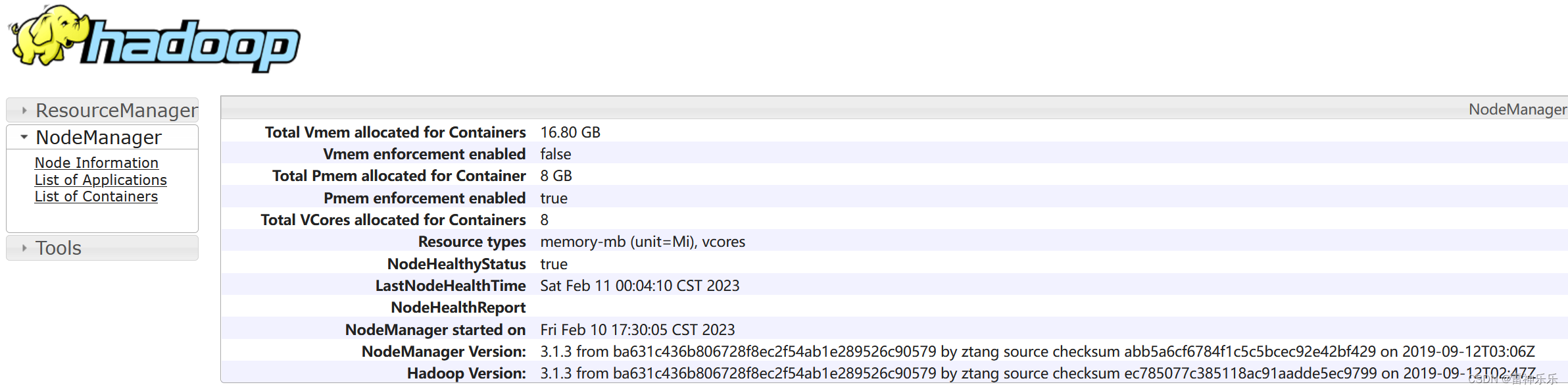
6.进入NodeManager查看
http://lxm147:8088/cluster
7.启动历史服务器(如果已经启动可以忽略此步骤)
[root@lxm148 ~]# mr-jobhistory-daemon.sh start historyserver
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
[root@lxm148 ~]# jps
4546 SecondaryNameNode
6370 JobHistoryServer
4164 NameNode
4804 ResourceManager
4937 NodeManager
6393 Jps
4302 DataNode
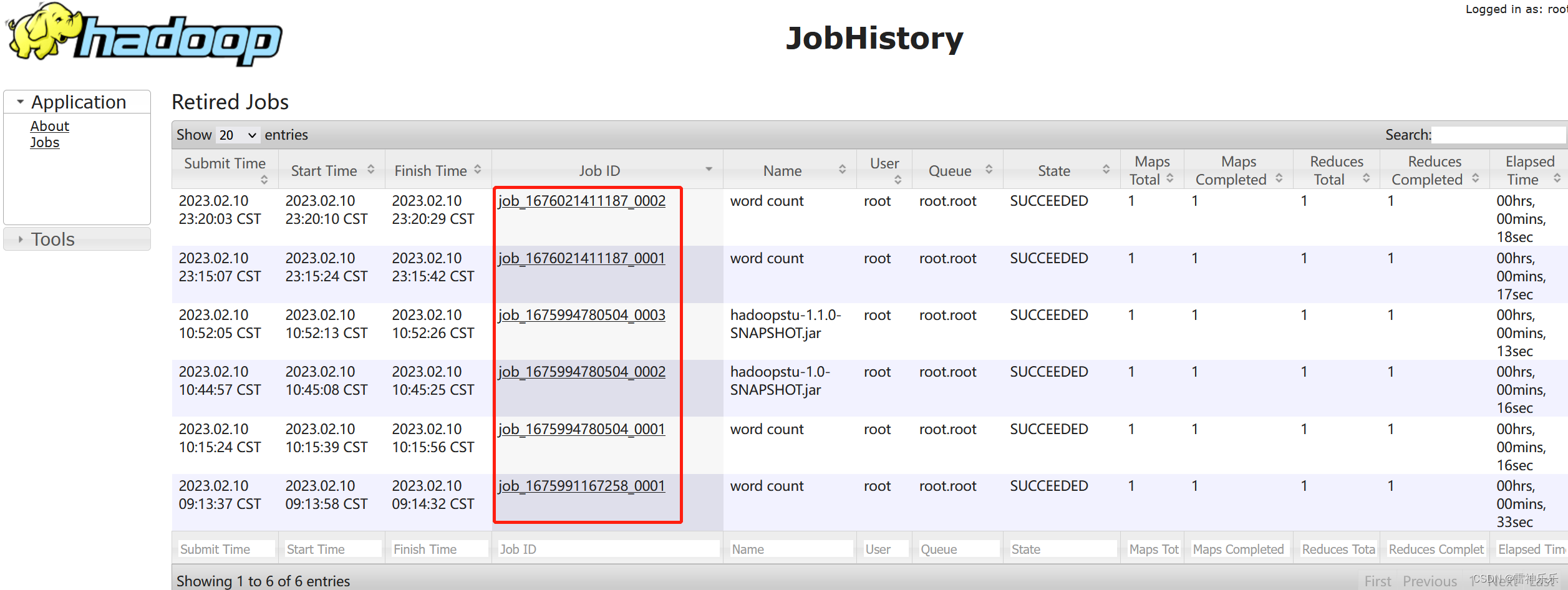
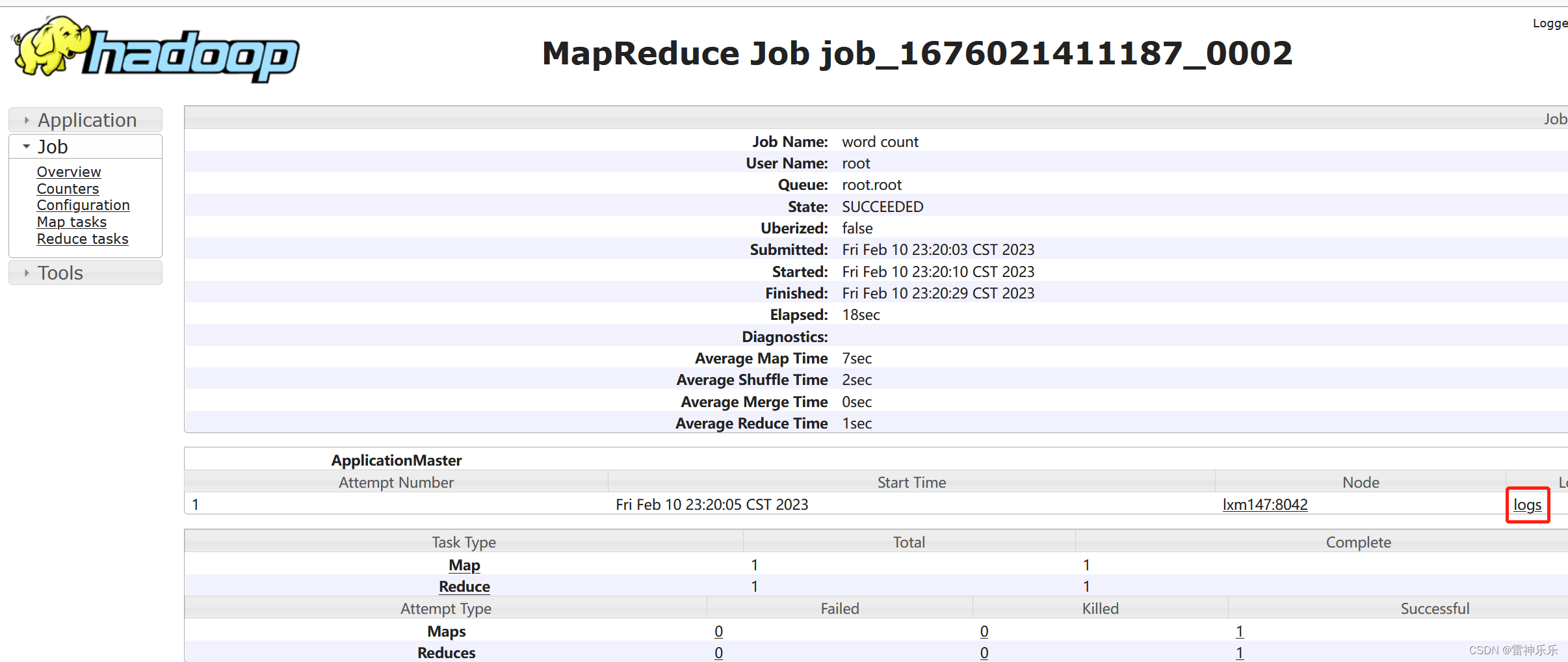
8.查看历史服务信息
http://lxm147:19888/

三、执行本地代码
(一)项目代码
1.stuscore.csv
1,zs,10,语文 2,ls,98,语文 3,ww,80,语文 1,zs,20,数学 2,ls,87,数学 3,ww,58,数学 1,zs,44,英语 2,ls,66,英语 3,ww,40,英语 1,zs,55,政治 2,ls,60,政治 3,ww,80,政治 1,zs,10,化学 2,ls,28,化学 3,ww,78,化学 1,zs,87,生物 2,ls,9,生物 3,ww,10,生物
2.Student类
import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class Student implements WritableComparable<Student> {private long stuid;private String stuname;private int score;private String lession;@Overridepublic int compareTo(Student o) {return this.score > o.score ? 1 : 0;}@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeLong(stuid);dataOutput.writeUTF(stuname);dataOutput.writeUTF(lession);dataOutput.writeInt(score);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.stuid = dataInput.readLong();this.stuname = dataInput.readUTF();this.lession = dataInput.readUTF();this.score = dataInput.readInt();}@Overridepublic String toString() {return "Student{" +"stuid=" + stuid +", stuname='" + stuname + '\'' +", score=" + score +", lession='" + lession + '\'' +'}';}public long getStuid() {return stuid;}public void setStuid(long stuid) {this.stuid = stuid;}public String getStuname() {return stuname;}public void setStuname(String stuname) {this.stuname = stuname;}public int getScore() {return score;}public void setScore(int score) {this.score = score;}public String getLession() {return lession;}public void setLession(String lession) {this.lession = lession;}public Student(long stuid, String stuname, int score, String lession) {this.stuid = stuid;this.stuname = stuname;this.score = score;this.lession = lession;}public Student() {}
}
2.StudentMapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;// K=id,V=student
// Mapper<进来的K,进来的V,出去的K,出去的V>
public class StudentMapper extends Mapper<LongWritable, Text, LongWritable, Student> {@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, Student>.Context context) throws IOException, InterruptedException {System.out.println(key+" "+value.toString());String[] split = value.toString().split(",");LongWritable stuidKey = new LongWritable(Long.parseLong(split[2]));Student studentValue = new Student(Long.parseLong(split[0]), split[1], Integer.parseInt(split[2]),split[3]);context.write(stuidKey,studentValue);}
}4.StudentReduce类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class StudentReduce extends Reducer<LongWritable, Student, Student, NullWritable> {@Overrideprotected void reduce(LongWritable key, Iterable<Student> values, Reducer<LongWritable, Student, Student, NullWritable>.Context context) throws IOException,InterruptedException {Student stu = new Student();// 相同key相加
// int sum = 0;int max = 0;String name ="";String lession = "";
// for (Student student:
// values) {
// sum += student.getScore();
// name = student.getStuname();
// }// 求每门科目的最高分for (Student student :values) {if(max<=student.getScore()){max = student.getScore();name = student.getStuname();lession = student.getLession();}}stu.setStuid(key.get());stu.setScore(max);stu.setStuname(name);stu.setLession(lession);System.out.println(stu.toString());context.write(stu,NullWritable.get());}
}
5.StudentDriver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class StudentDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);job.setJarByClass(StudentDriver.class);job.setMapperClass(StudentMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Student.class);job.setReducerClass(StudentReduce.class);job.setOutputKeyClass(Student.class);job.setOutputValueClass(NullWritable.class);// 指定路径FileInputFormat.setInputPaths(job,new Path("hdfs://lxm147:9000/bigdata/in/demo2/stuscore.csv"));Path path = new Path("hdfs://lxm147:9000/bigdata/out2");// 不指定路径/* Path inpath = new Path(args[0]);FileInputFormat.setInputPaths(job, inpath);Path path = new Path(args[1]);*/FileSystem fs = FileSystem.get(path.toUri(), configuration);if (fs.exists(path)) {fs.delete(path, true);}FileOutputFormat.setOutputPath(job, path);job.waitForCompletion(true);}
}(二)java代码中指定路径
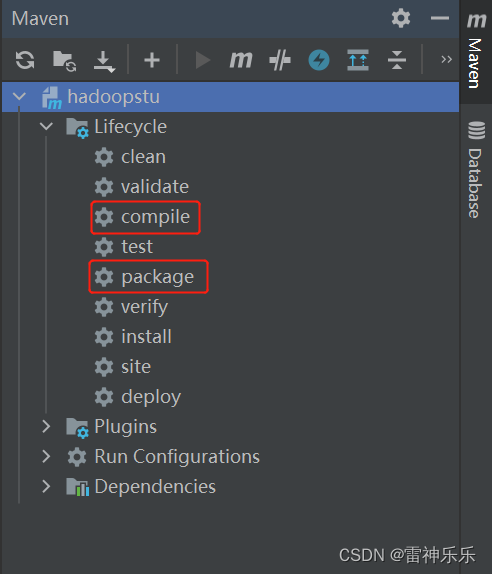
1.maven项目编译并打包
分别双击compile和package
2.上传stuscore.csv到hdfs指定目录下
hdfs dfs -put /opt/stuscore.csv /bigdata/in/demo23.xftp上传target目录下的打包好的jar包上传到虚拟机
4.Hadoop运行hadoopstu-1.0-SNAPSHOT.jar
[root@lxm147 opt]# hadoop jar ./hadoopstu-1.1.0-SNAPSHOT.jar nj.zb.kb21.demo2.StudentDriver /bigdata/in/demo2/stuscore.csv /bigdata/out2
5.Hadoop运行结果

(三)java代码中不指定路径
1.StuudentDriver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class StudentDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);job.setJarByClass(StudentDriver.class);job.setMapperClass(StudentMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Student.class);job.setReducerClass(StudentReduce.class);job.setOutputKeyClass(Student.class);job.setOutputValueClass(NullWritable.class);// 指定路径/*FileInputFormat.setInputPaths(job,new Path("hdfs://lxm147:9000/bigdata/in/demo2/stuscore.csv"));Path path = new Path("hdfs://lxm147:9000/bigdata/out2");*/// 不指定路径Path inpath = new Path(args[0]);FileInputFormat.setInputPaths(job, inpath);Path path = new Path(args[1]);FileSystem fs = FileSystem.get(path.toUri(), configuration);if (fs.exists(path)) {fs.delete(path, true);}FileOutputFormat.setOutputPath(job, path);job.waitForCompletion(true);}
}2.重新编译打包上传
为了方便区分,这里修改版本号再重新编译打包
3.HDFS命令执行该jar包
[root@lxm147 opt]# hadoop jar ./hadoopstu-1.1.0-SNAPSHOT.jar nj.zb.kb21.demo2.StudentDriver /bigdata/in/demo2/stuscore.csv /bigdata/out
4.查看运行结果
[root@lxm147 opt]# hdfs dfs -cat /bigdata/out/part-r-00000
Student{stuid=1, stuname='zs', score=226}
Student{stuid=2, stuname='ls', score=348}
Student{stuid=3, stuname='ww', score=346}
相关文章:
Hadoop之——WordCount案例与执行本地jar包
目录 一、WordCount代码 (一)WordCount简介 1.wordcount.txt (二)WordCount的java代码 1.WordCountMapper 2.WordCountReduce 3.WordCountDriver (三)IDEA运行结果 (四)Hadoop运行wordcount 1.在HDFS上新建一个文件目录 2.新建一个文件,并上传至该目录下…...
利用git reflog 命令来查看历史提交记录,并使用提交记录恢复已经被删除掉的分支
一.问题描述 当我们在操作中手误删除了某个分支,那该分支中提交的内容也没有了,我们可以利用git reflog这个命令来查看历史提交的记录从而恢复被删除的分支和提交的内容 二.模拟问题 1.创建git仓库,并提交一个文件 [rootcentos7-temp /da…...
【软件测试】大厂测试开发你真的了解吗?测试开发养成记......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 在一些大公司里&…...

Redis中的hash结构和扩容机制
1.rehash原理 hash包含两个数据结构为字典数组ht[0]和ht[1]。其中ht[0]用来存放数据,ht[1]在rehash时使用。 扩容时,ht[1]的大小为第一个大于等于ht[0].used*2的2的幂次方的数; 收缩时,ht[1]的大小为第一个大于等于ht[0].used的…...
【2023.02.08】)
【C++奇技淫巧】前置自增与后置自增的区别(++i,i++)【2023.02.08】
简介 先说i和i的区别,判断语句中if(i)是拿i的值先判断,而后自增;if(i)是先自增i再进行判断。涉及到左值与右值也有点区别,i返回的是右值,i返回的是左值。也就是下面的代码要解释的东西。 #include <iostream>i…...
实战打靶集锦-005-HL
**写在前面:**记录一次曲折的打靶经历。 目录1. 主机发现2. 端口扫描3. 服务枚举4. 服务探查4.1 浏览器访问4.2 目录枚举4.3 探查admin4.4 探查index4.5 探查login5 公共EXP搜索6. 再次目录枚举6.1 探查superadmin.php6.2 查看页面源代码6.3 base64绕过6.4 构建反弹…...
)
铁路系统各专业介绍(车机工电辆)
目录 1 车务段 1.1 职能简介 1.2 路段名单 1.3 岗位级别 2 机务段 2.1 职能简介 2.2 路段名单 2.3 岗位级别 3 工务段 3.1 职能简介 3.2 路段名单 3.3 岗位级别 4 电务段 4.1 职能简介 4.2 路段名单 4.3 岗位级别 5 车辆段 5.1 职能简介 5.2 路段名单 5.3 …...

2/11考试总结
时间安排 7:30–7:50 读题,T1貌似是个 dp ,T2 数据结构,T3 可能是数据结构。 7:50–9:45 T1,点规模非常大,可以达到 1e18 级别,感觉应该没法直接做,考虑每条新增的边的贡献,想到用 …...

Java Set集合
7 Set集合 7.1 Set集合的概述和特点 Set集合的特点 不包含重复元素的集合没有带索引的方法,所以不能使用普通for循环 Set集合是接口通过实现类实例化(多态的形式) HashSet:添加的元素是无序,不重复,无索引…...
【手写 Vuex 源码】第七篇 - Vuex 的模块安装
一,前言 上一篇,主要介绍了 Vuex 模块收集的实现,主要涉及以下几个点: Vuex 模块的概念;Vuex 模块和命名空间的使用;Vuex 模块收集的实现-构建“模块树”; 本篇,继续介绍 Vuex 模…...
EOC第六章《块与中枢派发》
文章目录第37条:理解block这一概念第38条:为常用的块类型创建typedef第39条:用handler块降低代码分散程度第41条:多用派发队列,少用同步锁方案一:使用串行同步队列来将读写操作都安排到同一个队列里&#x…...
八、Git远程仓库操作——跨团队成员的协作
前言 前面一篇博文介绍了git团队成员之间的协作,现在在介绍下如果是跨团队成员的话,如何协作? 跨团队成员协作,其实就是你不属于那个项目的成员,你没有权限向那个仓库提交代码。但是github还有另一种 pull request&a…...

算法刷题打卡第88天:字母板上的路径
字母板上的路径 难度:中等 我们从一块字母板上的位置 (0, 0) 出发,该坐标对应的字符为 board[0][0]。 在本题里,字母板为board ["abcde", "fghij", "klmno", "pqrst", "uvwxy", "…...

UVa The Morning after Halloween 万圣节后的早晨 双向BFS
题目链接:The Morning after Halloween 题目描述: 给定一个二维矩阵,图中有障碍物和字母,你需要把小写字母移动到对应的大写字母位置,不同的小写字母可以同时移动(上下左右四个方向或者保持不动 ࿰…...
)
Connext DDS属性配置参考大全(3)
Transport传输dds.participant.logging.time_based_logging.process_received_messagedds.participant.logging.time_based_logging.process_received_message.timeout...
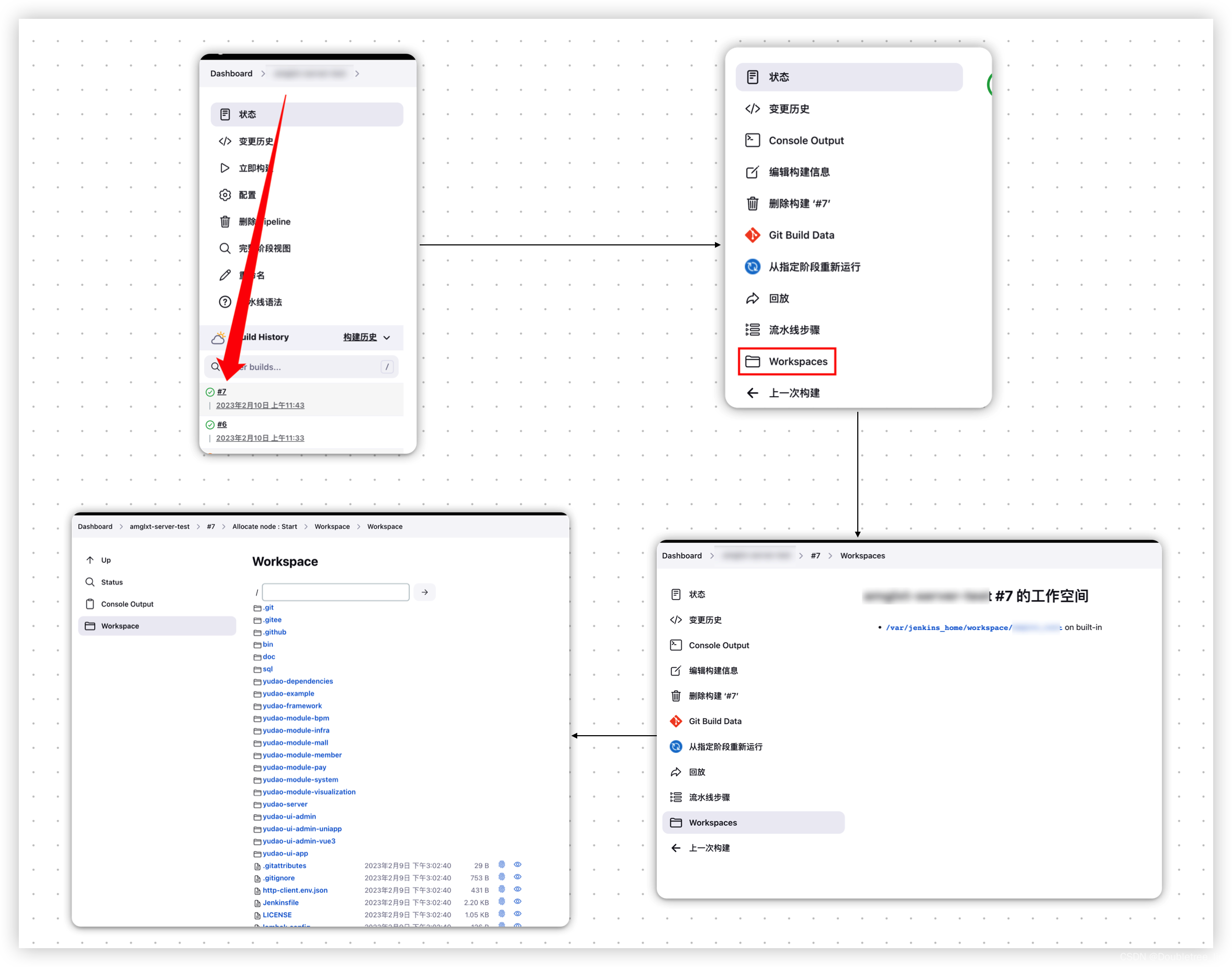
Docker-安装Jenkins-使用jenkins发版Java项目
文章目录0.前言环境背景1.操作流程1.1前期准备工作1.1.1环境变量的配置1.2使用流水线的方式进行发版1.2.1新建流水线任务1.2.2流水线操作工具tools步骤stages步骤1:拉取代码编译步骤2:发送文件并启动0.前言 学海无涯,旅“途”漫漫,“途”中小记ÿ…...

spring 中的 Bean 是否线程安全
文章目录结论1、spring中的Bean从哪里来?2、spring中什么样的Bean存在线程安全问题?3、如何处理spring Bean的线程安全问题?结论 其实,Spring 中的 Bean 是否线程安全,其实跟 Spring 容器本身无关。Spring框架中没有提…...
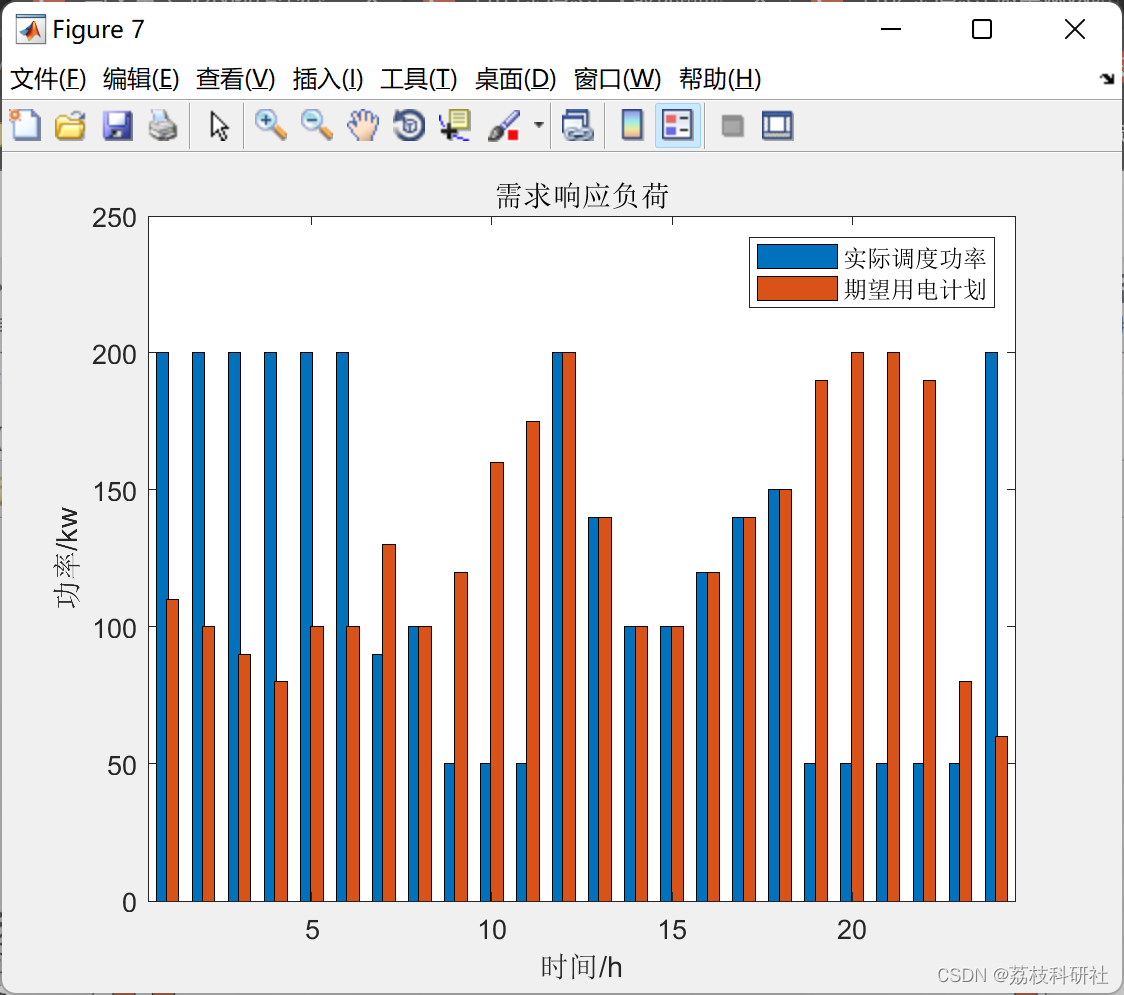
微电网两阶段鲁棒优化经济调度方法[3]【升级优化版本】(Matlab代码实现)
💥💥💥💞💞💞欢迎来到本博客❤️❤️❤️💥💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑…...

C++入门教程||C++ 数据类型||C++ 变量类型
C 数据类型 使用编程语言进行编程时,需要用到各种变量来存储各种信息。变量保留的是它所存储的值的内存位置。这意味着,当您创建一个变量时,就会在内存中保留一些空间。 您可能需要存储各种数据类型(比如字符型、宽字符型、整型…...
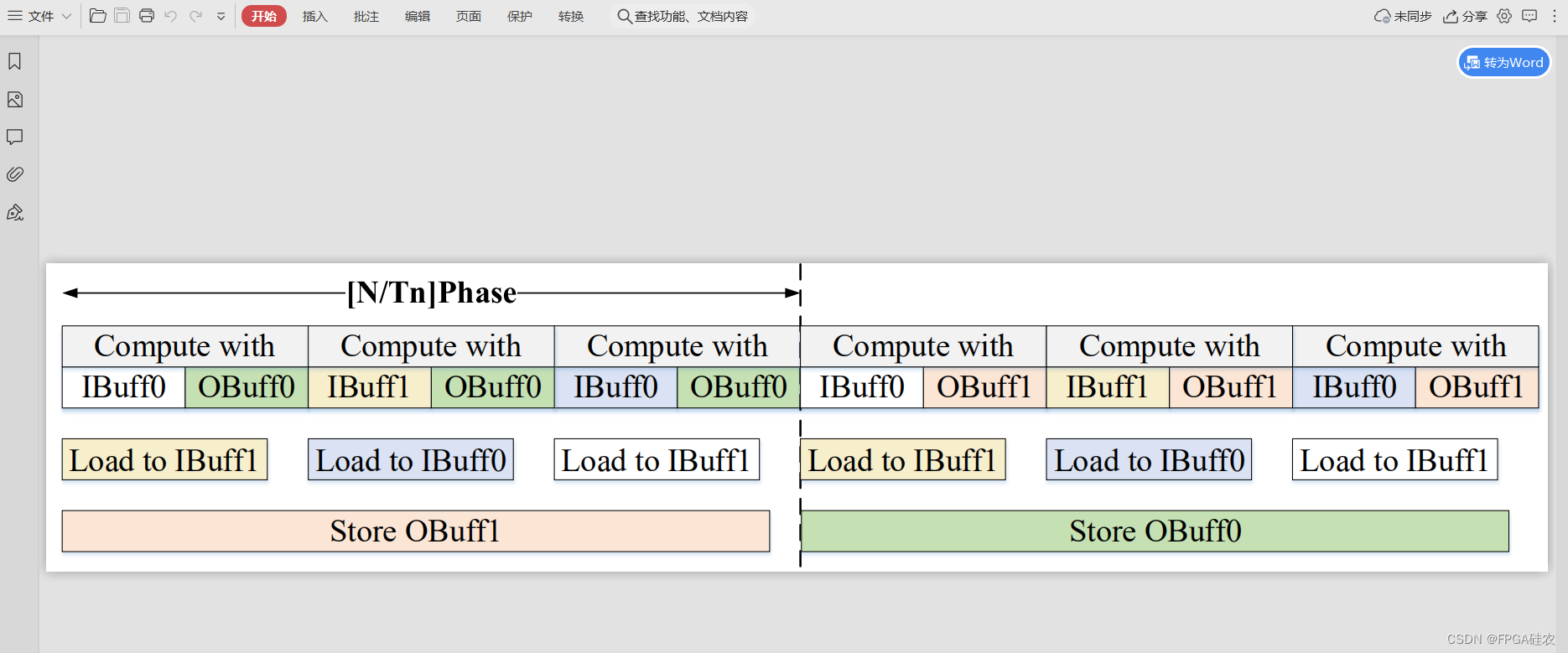
【visio使用技巧】图片导出pdf时去掉多余空白
问题 在visio导出pdf格式的图片时,往往会存在多余的白边,如下图所示: 解决方法 依次点击:菜单栏→文件→选项→自定义功能区→勾选“开发工具”→确定。 依次点击菜单栏→开发工具→显示ShapeSheet→页→Print Properties→将…...

【研报 A109】2026年脑机接口产业化专题报告:首个侵入式产品获批,医保完成赋码
摘要:脑机接口行业正迎来产业化应用的关键元年,2026年行业正式从实验室研究走向规模化商业化落地,当前行业处于导入期尾端、爆发前夜,非侵入式与半侵入式路径已率先打通商业化通道,侵入式则处于临床验证阶段。政策端&a…...

4sapi 企业级实战:统一模型网关与全生命周期管理解决方案
引言随着大模型技术在企业中的广泛应用,越来越多的企业开始面临 "模型碎片化" 的挑战。不同部门、不同业务线各自对接不同的大模型厂商,使用不同的 API 接口,导致企业内部出现了多个独立的 AI 孤岛,带来了一系列严重的问…...
下载分享)
上古卷轴5天际整合包下载最新全热门MOD整合(画质+人物+功能+场景全美化)下载分享
一、整合包基础概况 新手向懒人专属整合资源,适配电脑Windows系统。整合包集成多款热门优质MOD,无需玩家单独下载模组,整合包整体兼容性强,适配主流家用电脑,官方提前做好模组适配优化,规避多数模组冲突问…...

Qt 委托模式实战:QItemDelegate 赋能 QTableView 单元格交互控件
1. 为什么需要委托模式 在Qt开发中,表格视图(QTableView)是最常用的数据展示控件之一。但很多开发者都遇到过这样的困扰:当我们需要在表格单元格中嵌入交互控件时,直接调用setIndexWidget方法会导致控件始终显示,不仅影响界面美观…...

Specky:规范驱动开发平台,从AI氛围编程到确定性工程实践
1. Specky:一个重新定义AI辅助开发的确定性工程平台如果你和我一样,在过去几年里深度使用过GitHub Copilot、Claude Code这类AI编程助手,你肯定经历过那种又爱又恨的矛盾感。爱的是,它们确实能快速生成代码片段,把我们…...

Spring Boot + JWT 实现无状态认证
1. JWT JWT(JSON Web Token)是一种开放标准(RFC 7519),用于在网络应用环境间安全地将信息作为 JSON 对象传输。JWT 是目前最流行的跨域认证解决方案,特别适合前后端分离的架构。 1.1 JWT 的结构 JWT 由三…...

终极指南:如何用WarcraftHelper彻底解决魔兽争霸3的现代系统兼容性问题
终极指南:如何用WarcraftHelper彻底解决魔兽争霸3的现代系统兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争…...

通过AxisApi中转站使用国外API大模型教程
前言:所有的国外大模型想不通过中转站直接使用,其实是很麻烦的的事情,就拿codex来说,需要一个谷歌账号,没有谷歌账号需要注册,注册还必须要使用国外的手机号码和验证码校验审核,流程很繁琐&…...

Flutter Provider 状态管理完全指南
Flutter Provider 状态管理完全指南 引言 Provider 是 Flutter 中最流行的状态管理方案之一,它基于 InheritedWidget 实现,提供了简单而强大的状态管理方式。本文将深入探讨 Provider 的各种用法和高级技巧。 基础概念回顾 Provider 类型 Provider - 最基…...

你的oh-my-zsh插件列表还缺它吗?深度体验autojump:不止是目录跳转
深度探索autojump:oh-my-zsh终端导航的智能记忆系统 终端操作效率一直是开发者关注的焦点。当你的命令行环境从基础功能升级到oh-my-zsh这样的强大框架后,如何进一步挖掘工具潜力成为提升工作流的关键。在众多效率插件中,autojump以其独特的&…...