快速实现AI搜索!Fivetran 支持 Milvus 作为数据迁移目标


Fivetran 现已支持 Milvus 向量数据库作为数据迁移的目标,能够有效简化 RAG 应用和 AI 搜索中数据源接入的流程。
数据是 AI 应用的支柱,无缝连接数据是充分释放数据潜力的关键。非结构化数据对于企业搜索和检索增强生成(RAG)聊天机器人等 AI 应用有着巨大价值。随着数据量的增长,像 Milvus 这样的可扩展向量数据库对于高效搜索组织信息至关重要。
用于搜索的数据通常存储在各种地方,如云存储、商业应用和关系型数据库中。常见的方法是将这些不同来源的数据合并到同一个存储库中,将非结构化数据(如文本)转换为 Embedding 向量,同时将元数据也一同存储在向量数据库中。这样一来,AI 应用能够访问多种数据集并适应数据源的变化。
Fivetran 现已支持 Milvus 向量数据库作为数据迁移的目标,有效简化了上述流程,用户无需构建、维护和监控复杂的数据管道(Data Pipeline)。数据工程师只需轻击几下鼠标,便可以创建快速、高效且可扩展的 AI 搜索解决方案,更专注于创造业务价值,而不是管理复杂的基础设施。
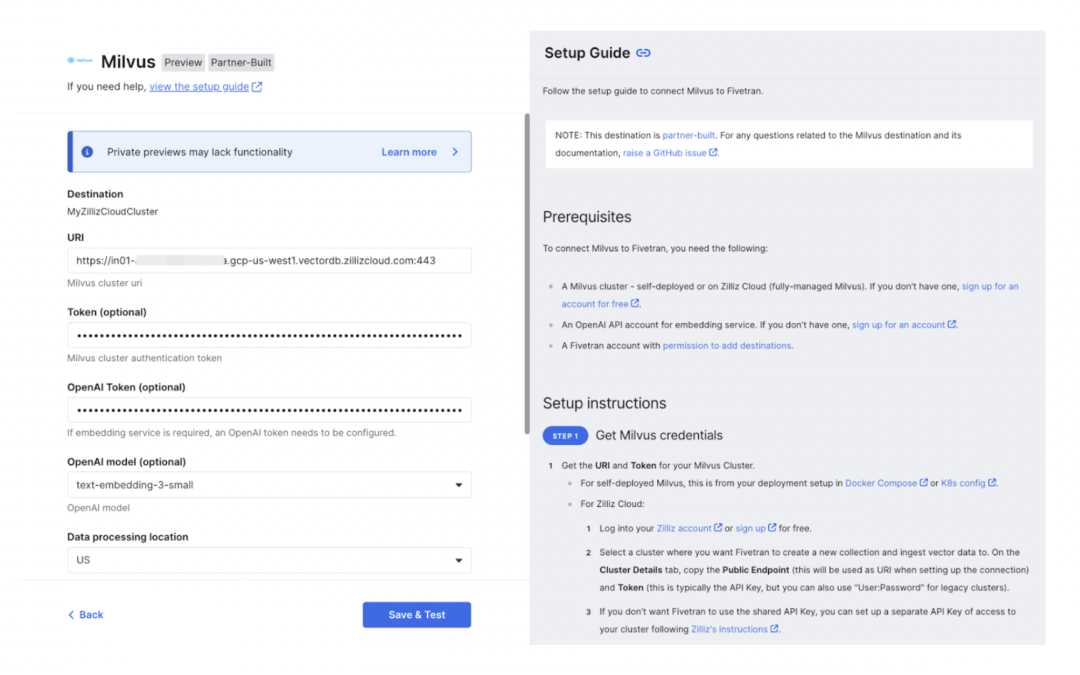
01.
Milvus 和 Fivetran 如何为 AI 构建基础
Milvus 是一款高性能、高度可扩展的开源向量数据库。在 Kubernetes 上部署的单个 Milvus 集群可以处理数十亿向量数据。Zilliz Cloud 是全托管的 Milvus 服务,增加了企业级特性(如 RBAC 和 SOC2 安全合规认证),并且自带专有的 Cardinal 向量搜索引擎,性能更出色。Milvus 和 Zilliz Cloud 被广泛应用于语义搜索、RAG 和多模态搜索等应用中。构建 AI 搜索解决方案的一个挑战是如何将来自各种来源的数据 Ingest 到 Milvus 中,以实现实时搜索。Fivetran 支持 Milvus 向量数据库作为数据迁移的目标,简化了将任何来源的数据 Ingest 到 Milvus 的流程,帮助企业免去管理传输的麻烦,更高效地分析数据。通过利用 Milvus 的高级向量搜索功能和简化的数据传输流程,开发者可以快速构建AI 应用,充分利用其组织来自多样数据源的数据 。
使用 Fivetran 的 Milvus 目标,您可以:
通过 Fivetran 连接器(Connector)将超过 500 个数据来源的数据 Ingest 到 Milvus/Zilliz Cloud 中。
使用 OpenAI Embedding 模型简化非结构化数据的提取、加载和向量化流程。
通过结构化数据列,实现在向量搜索过程中进行元数据过滤。
构建近实时的搜索功能,支持增量数据同步。
02.
Fivetran 的 Partner SDK:构建自定义连接器和目标
Fivetran 的 Partner SDK 使技术供应商能够为其服务创建源或目标连接器,并与 Fivetran 的自动化数据移动平台无缝集成。Partner SDK 的关键优势包括:
灵活的开发语言:基于 gRPC 的 SDK 允许使用任何支持的编程语言编写源和目标连接器,为开发者提供灵活性,以便在他们选择的语言中重用或编写新代码。
降低复杂性:通过模板和本地测试环境,第三方供应商可以轻松测试和部署连接器。
数据平台的新机遇:SDK 为产品开辟了新渠道,允许数据仓库、数据湖和存储平台轻松访问 Fivetran 的 500 多个连接器。
Zilliz 是 Milvus 背后的原厂,通过将其向量数据库操作紧密映射到 Fivetran 的关系型更新模型,构建了与 Fivetran 的集成。他们还简化了第三方解决方案的使用流程,例如通过 OpenAI Embedding 服务,在 Ingestion 过程中生成向量。
03.
AI 搜索演示
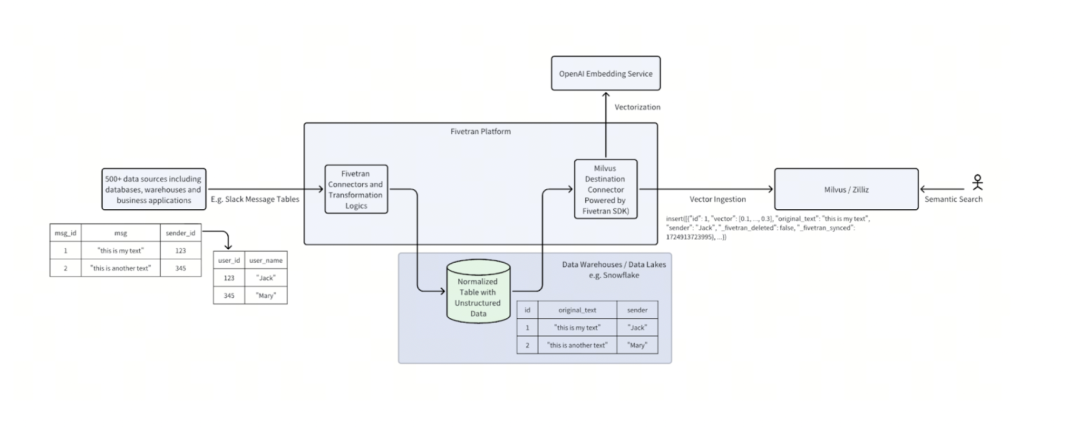
非结构化数据虽然通常最有价值,但也是最具挑战性的数据类型。借助 Fivetran 和 Milvus,企业可以快速且轻松地构建 AI 驱动的搜索工具,从丰富的数据集中获取洞察。
Fivetran 的全托管连接器可以自动、可靠且安全从主要的商业应用中传输数据,且支持 Schema 迁移。例如,一家公司想要为其 Slack 消息构建一个内部搜索工具。使用 Fivetran 的 Slack 连接器,数据首先被复制并以规范化格式存储在数仓或 data lakehouse(如 Snowflake)中。然后,可以反范式化、连接、分块和转换这些数据,之后可以通过 Fivetran 的 Snowflake 源连接器连接到 Milvus。只需将文本块存储在名为 original_text 的列中,Milvus 目标就会自动调用 OpenAI Embedding 服务为文本生成向量。向量与所有其他标签一起作为标量字段存储在 Milvus 中,随后通过向量相似性搜索和元数据过滤实现高效的语义搜索。
04.
总结
新推出的 Fivetran 的 Milvus 目标连接器进一步扩展了 AI 领域中的数据范围,实现了对多种数据源数据进行语义搜索。通过将来自多种数据库/数仓和商业应用的源数据 Ingest 到 Milvus 向量数据库,这种集成使得 AI 工作流变得更加轻松高效。欢迎根据设置说明使用 Fivetran 的 Milvus 目标连接器。
作者介绍

陈将
Zilliz 生态和 AI 平台负责人
推荐阅读


相关文章:
快速实现AI搜索!Fivetran 支持 Milvus 作为数据迁移目标
Fivetran 现已支持 Milvus 向量数据库作为数据迁移的目标,能够有效简化 RAG 应用和 AI 搜索中数据源接入的流程。 数据是 AI 应用的支柱,无缝连接数据是充分释放数据潜力的关键。非结构化数据对于企业搜索和检索增强生成(RAG)聊天…...

css的页面布局属性
CSS Flexbox(Flexible Box Layout)是一种用于页面布局的CSS3规范,它提供了一种更加高效的方式来布置、对齐和分配容器内元素的空间,即使它们的大小是未知或者动态变化的。Flexbox很容易处理一维布局,即在一个方向上&am…...

RTE 大会报名丨AI 时代新基建:云边端架构和 AI Infra ,RTE2024 技术专场第二弹!
所有 AI Infra 都在探寻规格和性能的最佳平衡,如何构建高可用的云边端协同架构? 语音 AI 实现 human-like 的最后一步是什么? AI 视频的爆炸增长,给新一代编解码技术提出了什么新挑战? 当大模型进化到实时多模态&am…...

【React】入门Day01 —— 从基础概念到实战应用
目录 一、React 概述 二、开发环境创建 三、JSX 基础 四、React 的事件绑定 五、React 组件基础使用 六、组件状态管理 - useState 七、组件的基础样式处理 快速入门 – React 中文文档 一、React 概述 React 是什么 由 Meta 公司开发,是用于构建 Web 和原生…...

<<机器学习实战>>10-11节笔记:生成器与线性回归手动实现
10生成器与python实现 如果是曲线规律的数据集,则需要把模型变复杂。如果是噪音较大,则需要做特征工程。 随机种子的知识点补充: 根据不同库中的随机过程,需要用对应的随机种子: 比如 llist(range(5)) random.shuf…...

链表OJ经典题目及思路总结(一)
目录 前言1.移除元素1.1 链表1.2 数组 2.双指针2.1 找链表的中间结点2.2 找倒数第k个结点 总结 前言 解代码题 先整体:首先数据结构链表的题一定要多画图,捋清问题的解决思路; 后局部:接着考虑每一步具体如何实现,框架…...

初识chatgpt
GPT到底是什么 首先,我们需要了解GPT的全称:Generative Pre-trained Transformer,即三个关键词:生成式 预训练 变换模型。 (1)什么是生成式? 即能够生成新的文本序列。 (2&#…...

【60天备战2024年11月软考高级系统架构设计师——第33天:云计算与大数据架构——大数据处理框架的应用场景】
随着大数据技术的发展,越来越多的企业开始采用大数据处理框架来解决实际问题。理解这些框架的应用场景对于架构师来说至关重要。 大数据处理框架的应用场景 实时数据分析:使用Apache Kafka与Apache Spark结合,可以实现对实时数据流的处理与…...

如何设计具体项目的数据库管理
### 例三:足协的数据库管理算法 #### 角色: - **ESFP学生**:小明 - **ENTP老师**:张老师 #### 主题:足协的数据库管理算法 --- **张老师**:小明,今天我们来讨论一下足协的数据库管理算法。你…...

对于 Vue CLI 项目如何引入Echarts以及动态获取数据
🚀个人主页:一颗小谷粒 🚀所属专栏:Web前端开发 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 1、数据画卷—Echarts介绍 1.1 什么是Echarts? 1.2 Echarts官网地址 2、Vue CLI 项目…...

【Linux笔记】在VMware中,为基于NAT模式运行的CentOS虚拟机设置固定的网络IP地址
一、配置VMware虚拟网络 1、打开VMware虚拟网络编辑器: 点击VMware主界面上方的“编辑”菜单,选择“虚拟网络编辑器”。 2、选择NAT模式网络: 在虚拟网络编辑器中,选择VMnet8(或其他NAT模式的网络)。 取消勾…...

一文上手Kafka【中】
一、发送消息细节 在发送消息的特别注意: 在版本 3.0 中,以前返回 ListenableFuture 的方法已更改为返回 CompletableFuture。为了便于迁移,2.9 版本添加了一个方法 usingCompletableFuture(),该方法为 CompletableFu…...

Ubuntu如何如何安装tcpdump
在Ubuntu上安装tcpdump非常简单,可以通过以下步骤完成: 打开终端。 更新包列表: 首先,更新你的包管理器的包列表: sudo apt update 安装tcpdump: 使用以下命令安装tcpdump: sudo apt install …...

3-3 AUTOSAR RTE 对SR Port的作用
返回总目录->返回总目录<- 一、前言 RTE作为SWC和BSW之间的通信机构,支持Sender-Receiver方式实现ECU内及ECU间的通信。 对于Sender-Receiver Port支持三种模式: 显式访问:若运行实体采用显示模式的S/R通信方式,数据读写是即时的;隐式访问:当多个运行实体需要读取…...

hive/impala/mysql几种数据库的sql常用写法和函数说明
做大数据开发的时候,会在几种库中来回跳,同一个需求,不同库函数和写法会有出入,在此做汇总沉淀。 1. hive 1. 日期差 DATEDIFF(CURRENT_DATE(),wdjv.creation_date) < 30 30天内的数据 2.impala 3. spark 4. mysql 1.时间差…...

论文阅读:LM-Cocktail: Resilient Tuning of Language Models via Model Merging
论文链接 代码链接 Abstract 预训练的语言模型不断进行微调,以更好地支持下游应用。然而,此操作可能会导致目标领域之外的通用任务的性能显著下降。为了克服这个问题,我们提出了LM Cocktail,它使微调后的模型在总体上保持弹性。我们的方法以模型合并(Model Merging)的形…...

8640 希尔(shell)排序
### 思路 希尔排序是一种基于插入排序的排序算法,通过将待排序数组分割成多个子序列分别进行插入排序来提高效率。初始增量d为n/2,之后每次减半,直到d为1。 ### 伪代码 1. 读取输入的待排序关键字个数n。 2. 读取n个待排序关键字并存储在数组…...

Linux 安装redis主从模式+哨兵模式3台节点
下载 https://download.redis.io/releases/ 解压 tar -zxvf redis-7.2.4.tar.gz -C /opt chmod 777 -R /opt/redis-7.2.4/安装 # 编译 make # 安装, 一定是大写PREFIX make PREFIX/opt/redis-7.2.4/redis/ install配置为系统服务 cd /etc/systemd/system/主服务…...

[BCSP-X2024.小高3] 学习计划
题目描述 暑假共有 n 天,第 i 天的精力指数为 a[i],你想要利用假期依次(按 1,2,...,m 顺序)复习 m 门功课,第 i 门功课的重要程度为 b[i],且每门的复习时段必须连 续,并且不能有某天不干事。 …...
完全指南)
Android Debug Bridge(ADB)完全指南
文章目录 前言一、什么是ADB?二、ADB的工作原理ADB由三个部分组成: 三、如何安装ADBWindows系统:macOS和Linux系统: 四、ADB常用指令大全设备相关操作1. 查看连接的设备:2. 重启设备:3. 进入Bootloader模式…...

OpenCore Legacy Patcher终极指南:让老Mac焕发新生的4个简单步骤
OpenCore Legacy Patcher终极指南:让老Mac焕发新生的4个简单步骤 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为你的老Mac无法升级最新mac…...

Six Degrees of Wikipedia技术解析:广度优先搜索算法如何连接百万页面
Six Degrees of Wikipedia技术解析:广度优先搜索算法如何连接百万页面 【免费下载链接】sdow Six Degrees of Wikipedia 项目地址: https://gitcode.com/gh_mirrors/sd/sdow Six Degrees of Wikipedia(简称sdow)是一个基于维基百科页面…...

巨头转身难的地方,我们的星辰大海:开发版机巢,为千行百业而生
未来的低空经济图景是怎样的?它绝不仅仅是几架无人机在天上飞。 未来的城市与能源基础设施中,将隐藏着无数形态各异、能力专精的“机巢”。它们将像毛细血管一样渗透在城市的各个角落,定时自动穿梭,替代人力进行精细化巡检&#x…...

Nordic nRF52832蓝牙串口实战:手把手教你用SDK 15.3.0实现手机与设备双向通信
Nordic nRF52832蓝牙串口开发实战:从SDK配置到双向通信全解析 在嵌入式蓝牙开发领域,Nordic的nRF52832芯片凭借其优异的射频性能和丰富的外设资源,成为物联网设备开发的明星选择。但对于刚接触这款芯片的开发者来说,如何快速实现手…...

从零到一搭建 AI Agent 财务分析系统
一、核心目标拆解(先对齐业务) 你的系统要支撑 4 类核心场景: 财务报告自动生成 + 智能解读 智能问答 + 异常预警 财务预测、预算编制、风险识别 对接业务部门,推动需求落地 基于这个目标,我给你定了 **「轻量化 MVP → 企业级生产」两阶段架构 **,兼顾快速出 Demo 和长…...

别再瞎试了!用Python+正交设计,5分钟搞定你的多因素实验方案
用Python正交设计高效优化多因素实验方案 在数据科学和工程实践中,我们经常面临需要同时优化多个参数的挑战。无论是机器学习模型的超参数调优,还是化工生产中的工艺条件优化,传统的一一尝试方法不仅耗时耗力,而且难以捕捉因素间的…...

Arm Streamline性能分析工具在嵌入式Linux开发中的应用
1. Arm Streamline性能分析工具概述在嵌入式Linux开发领域,性能优化始终是开发者面临的核心挑战之一。Arm Streamline作为专为Arm架构设计的性能分析工具,提供了从应用层到内核层的全栈性能监控能力。与传统的perf工具相比,Streamline的最大优…...

GanttProject项目管理软件:完全免费的甘特图工具使用指南
GanttProject项目管理软件:完全免费的甘特图工具使用指南 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject GanttProject是一款功能强大的免费开源项目管理软件,专为…...

Unity 2D游戏开发:用Cinemachine 2D Camera实现平滑镜头跟随,告别手动写代码
Unity 2D游戏开发:用Cinemachine 2D Camera实现平滑镜头跟随,告别手动写代码 在2D游戏开发中,摄像机跟随是最基础却又最容易出问题的功能之一。很多开发者习惯用代码手动控制摄像机的位置更新,却常常陷入边界抖动、跟随延迟不自然…...

从‘一片黑’到重点突出:手把手教你用ArcGIS为乡镇规划图添加专业级影像蒙版
从‘一片黑’到重点突出:手把手教你用ArcGIS为乡镇规划图添加专业级影像蒙版 在乡镇规划汇报中,一张能清晰传达重点区域的地图往往比千言万语更有说服力。想象一下这样的场景:当决策者面对一张全区域亮度均一的遥感影像时,他们的视…...