强化学习:通过试错学习最优策略---示例:使用Q-Learning解决迷宫问题
强化学习(Reinforcement Learning, RL)是一种让智能体(agent)在与环境交互的过程中,通过最大化某种累积奖励来学习如何采取行动的学习方法。它适用于那些需要连续决策的问题,比如游戏、自动驾驶和机器人控制等。
强化学习的关键概念
- 代理 (Agent): 学习并作出决策的实体。
- 环境 (Environment): 代理与其交互的世界。
- 状态 (State): 描述环境中当前情况的信息。
- 动作 (Action): 代理可以执行的行为。
- 奖励 (Reward): 环境对代理行为的反馈,用于指导学习过程。
- 策略 (Policy): 决定给定状态下应采取何种动作的规则。
- 价值函数 (Value Function): 预期未来奖励的估计。
示例:使用Q-Learning解决迷宫问题
将通过一个简单的迷宫问题来展示如何实现一个基本的强化学习算法——Q-Learning。在这个例子中目标是让代理找到从起点到终点的最短路径。
环境设置 我们首先定义迷宫的结构。假设迷宫是一个4x4的网格,其中包含墙壁、空地以及起始点和终点。
import numpy as np# 定义迷宫布局
maze = np.array([[0, 1, 0, 0],[0, 1, 0, 0],[0, 0, 0, 1],[0, 0, 0, 0]
])# 定义起始点和终点
start = (0, 0)
end = (3, 3)# 动作空间
actions = ['up', 'down', 'left', 'right']Q-Learning算法实现
# 初始化Q表
q_table = np.zeros((maze.shape[0], maze.shape[1], len(actions)))# 参数设置
alpha = 0.1 # 学习率
gamma = 0.95 # 折扣因子
epsilon = 0.1 # 探索概率
num_episodes = 1000 # 训练回合数def choose_action(state, q_table, epsilon):if np.random.uniform(0, 1) < epsilon:action = np.random.choice(actions) # 探索else:action_idx = np.argmax(q_table[state])action = actions[action_idx] # 利用return actiondef get_next_state(state, action):row, col = stateif action == 'up' and row > 0 and maze[row - 1, col] == 0:next_state = (row - 1, col)elif action == 'down' and row < maze.shape[0] - 1 and maze[row + 1, col] == 0:next_state = (row + 1, col)elif action == 'left' and col > 0 and maze[row, col - 1] == 0:next_state = (row, col - 1)elif action == 'right' and col < maze.shape[1] - 1 and maze[row, col + 1] == 0:next_state = (row, col + 1)else:next_state = statereturn next_statedef update_q_table(q_table, state, action, reward, next_state, alpha, gamma):action_idx = actions.index(action)best_next_action_value = np.max(q_table[next_state])q_table[state][action_idx] += alpha * (reward + gamma * best_next_action_value - q_table[state][action_idx])# 训练过程
for episode in range(num_episodes):state = startwhile state != end:action = choose_action(state, q_table, epsilon)next_state = get_next_state(state, action)# 假设到达终点时获得正奖励,否则无奖励reward = 1 if next_state == end else 0update_q_table(q_table, state, action, reward, next_state, alpha, gamma)state = next_state# 测试最优策略
state = start
path = [state]
while state != end:action_idx = np.argmax(q_table[state])action = actions[action_idx]state = get_next_state(state, action)path.append(state)print("Path from start to end:", path)maze数组表示迷宫的布局,其中0代表空地,1代表墙。q_table是一个三维数组,用来存储每个状态-动作对的价值。choose_action函数根据ε-greedy策略选择动作,允许一定程度的探索。get_next_state函数根据当前状态和动作返回下一个状态。update_q_table函数更新Q表中的值,采用贝尔曼方程进行迭代更新。- 在训练过程中,代理会不断尝试不同的动作,并通过接收奖励来调整其行为策略。
- 最后测试经过训练后的策略,输出从起点到终点的最佳路径。
在实际问题中,可能还需要考虑更多复杂的因素,如更大的状态空间、连续的动作空间以及更复杂的奖励机制等。还有许多其他类型的强化学习算法,如Deep Q-Network (DQN)、Policy Gradients、Actor-Critic方法等,可以处理更加复杂的问题。
相关文章:

强化学习:通过试错学习最优策略---示例:使用Q-Learning解决迷宫问题
强化学习(Reinforcement Learning, RL)是一种让智能体(agent)在与环境交互的过程中,通过最大化某种累积奖励来学习如何采取行动的学习方法。它适用于那些需要连续决策的问题,比如游戏、自动驾驶和机器人控制…...

OpenGL ES 纹理(7)
OpenGL ES 纹理(7) 简述 通过前面几章的学习,我们已经可以绘制渲染我们想要的逻辑图形了,但是如果我们想要渲染一张本地图片,这就需要纹理了。 纹理其实是一个可以用于采样的数据集,比较典型的就是图片了,我们知道我…...

【C#】CacheManager:高效的 .NET 缓存管理库
在现代应用开发中,缓存是提升性能和降低数据库负载的重要技术手段。无论是 Web 应用、桌面应用还是移动应用,缓存都能够帮助减少重复的数据查询和处理,从而提高系统的响应速度。然而,管理缓存并不简单,尤其是当你需要处…...

【数学分析笔记】第4章第2节 导数的意义和性质(2)
4. 微分 4.2 导数的意义与性质 4.2.3 单侧导数 f ′ ( x ) lim Δ x → 0 f ( x Δ x ) − f ( x ) Δ x lim x → x 0 f ( x ) − f ( x 0 ) x − x 0 f(x)\lim\limits_{\Delta x\to 0}\frac{f(x\Delta x)-f(x)}{\Delta x}\lim\limits_{x\to x_0}\frac{f(x)-f(x_0)…...

深度学习:迁移学习
目录 一、迁移学习 1.什么是迁移学习 2.迁移学习的步骤 1、选择预训练的模型和适当的层 2、冻结预训练模型的参数 3、在新数据集上训练新增加的层 4、微调预训练模型的层 5、评估和测试 二、迁移学习实例 1.导入模型 2.冻结模型参数 3.修改参数 4.创建类ÿ…...

Footprint Growthly Quest 工具:赋能 Telegram 社区实现 Web3 飞速增长
作者:Stella L (stellafootprint.network) 在 Web3 的快节奏世界里,社区互动是关键。而众多 Web3 社区之所以能够蓬勃发展,很大程度上得益于 Telegram 平台。正因如此,Footprint Analytics 精心打造了 Growthly —— 一款专为 Tel…...

进入xwindows后挂起键盘鼠标没有响应@FreeBSD
问题: 在升级pkg包后,系统无法进入xfce等xwindows,表现为黑屏和看见鼠标,左上角有一个白字符块,键盘鼠标没有反应,整个系统卡住。但是可以ssh登录,内部的服务一切正常。 表现 处理过程…...

CentOS7.9 snmptrapd更改162端口
端口更改前: 命令: netstat -an |grep 162 [root@kibana snmp]# netstat -an | grep 162 udp 0 0 0.0.0.0:162 0.0.0.0:* unix 3 [ ] STREAM CONNECTED 45162 /run/systemd/journal/stdout u…...

模糊测试SFuzz亮相第32届中国国际信息通信展览会
9月25日,被誉为“中国ICT市场的创新基地和风向标”的第32届中国国际信息通信展在北京盛大开幕,本次展会将在为期三天的时间内,为信息通信领域创新成果、尖端技术和产品提供国家级交流平台。开源网安携模糊测试产品及相关解决方案精彩亮相&…...

CMake学习
向大佬lyf学习,先把其8服务器中所授fine 文章目录 前言一、CMakeList.txt 命令1. 最外层CMakeLists1.1 cmake_minimum_required()1.2 project()1.3 set()1.4 add_subdirectory(&…...

书生·浦语大模型全链路开源开放体系
书生浦语大模型全链路开源开放体系 大模型应用生态的发展和繁荣是建立在模型基座强大的通用基础能力之上的。上海AI实验室联合团队研究认为,大模型各项性能提升的基础在于语言建模能力的增强,对于大模型的研究应回归语言建模本质,通过更高质量…...

PHP安装swoole扩展无效,如何将文件上传至Docker容器
目录 过程 操作方式 过程 在没有使用过云服务器以前,Docker这个平台一直都很神秘。在我申请了华为云服务器,并使用WordPress镜像去搭建自己的网站以后,我不得不去把Docker平台弄清楚,原因是我使用的一个主题需要安装swoole扩展,才能够正常启用。而要将swoole.so这个扩展…...

Web3.0 应用项目
Web3.0 是下一代互联网的概念,旨在去中心化、用户拥有数据控制权和通过区块链技术实现信任的网络。Web3.0的应用项目主要集中在区块链、加密货币、去中心化应用 (DApps)、去中心化金融 (DeFi)、NFT(非同质化代币)等领域。以下是一些典型的 We…...
—— 重定向与缓冲区)
Linux 学习笔记(十六)—— 重定向与缓冲区
一、文件重定向 矩阵的下标,也就是文件描述符的分配规则,是从0开始空的最小的文件描述符分配给进程新打开的文件;文件输出重定向的原理是,关掉1(输出),然后打开文件,这个新打开的文…...

828华为云征文|WordPress部署
目录 前言 一、环境准备 二、远程连接 三、WordPress简介 四、WordPress安装 1. 基础环境安装 编辑 2. WordPress下载与解压 3. 创建站点 4. 数据库配置 总结 前言 WordPress 是一个非常流行的开源内容管理系统(Content Management System, CMS…...
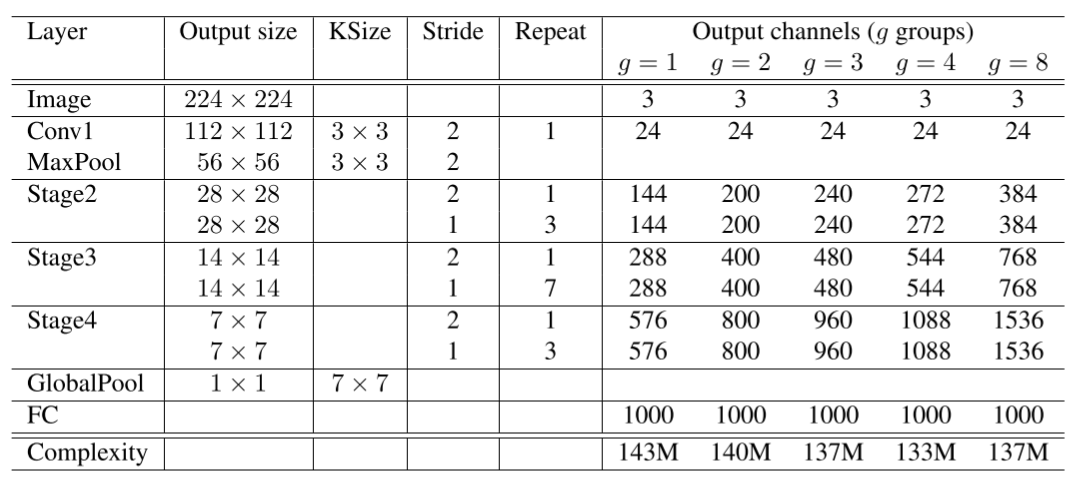
华为开源自研AI框架昇思MindSpore应用案例:计算高效的卷积模型ShuffleNet
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区 ShuffleNet ShuffleNet网络介绍 ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到…...

《C++ 小游戏:简易飞机大战游戏的实现》
文章目录 《C 游戏代码解析:简易飞机大战游戏的实现》一、游戏整体结构与功能概述二、各个类和函数的功能分析(一)BK类 - 背景类(二)hero_plane类 - 玩家飞机类(三)plane_bullet类 - 玩家飞机发…...
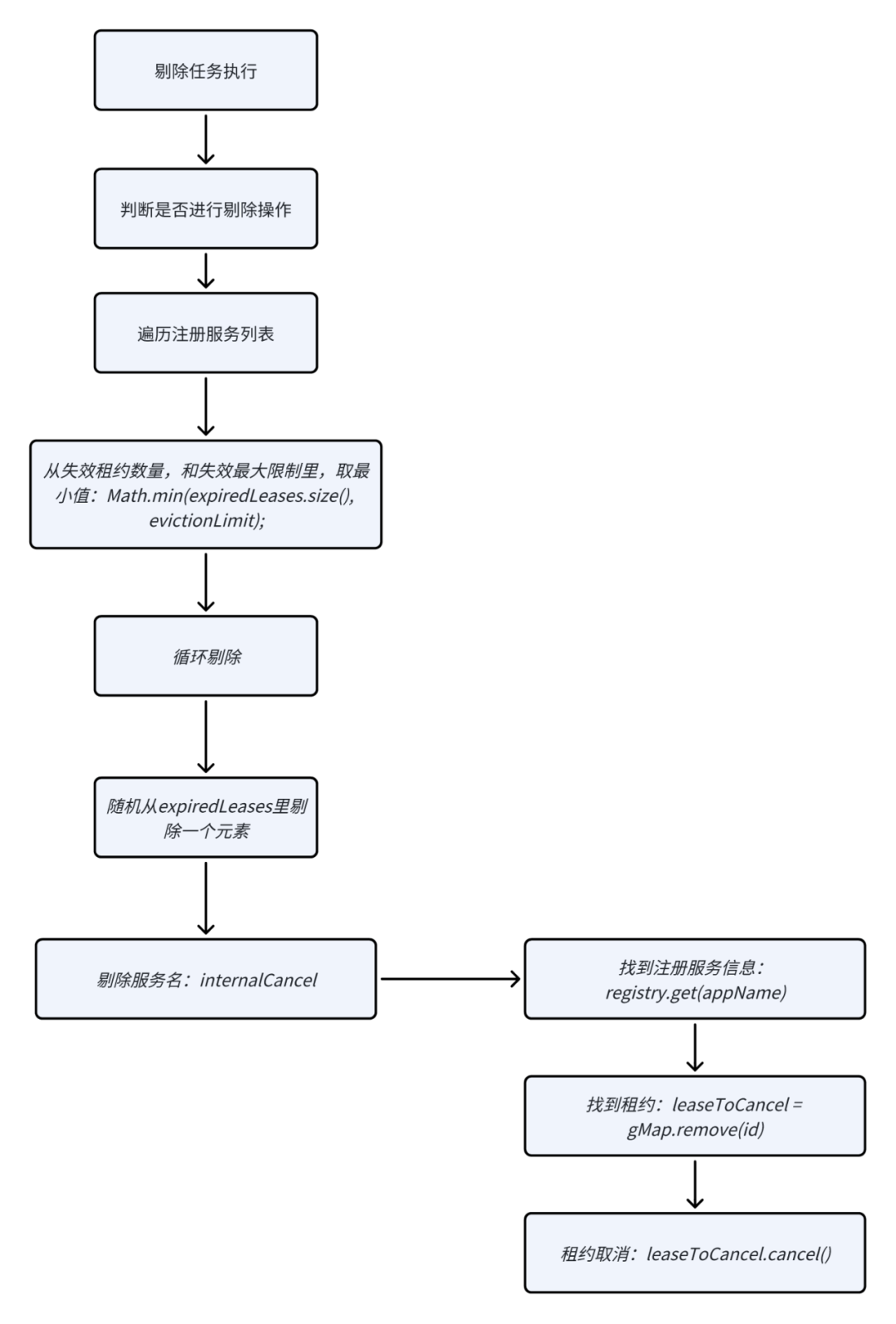
SpringCloud源码:服务端分析(二)- EurekaServer分析
背景 从昨日的两篇文章:SpringCloud源码:客户端分析(一)- SpringBootApplication注解类加载流程、SpringCloud源码:客户端分析(二)- 客户端源码分析。 我们理解了客户端的初始化,其实…...

插槽slot在vue中的使用
介绍 在 Vue.js 中,插槽(slot)是一种用于实现组件内容分发的功能。通过插槽,可以让父组件在使用子组件时自定义子组件内部的内容。插槽提供了一种灵活的方式来组合和复用组件。 项目中有很多地方需要调用一个组件,比…...

针对考研的C语言学习(定制化快速掌握重点2)
1.C语言中字符与字符串的比较方法 在C语言中,单字符可以用进行比较也可以用 > , < ,但是字符串却不能用直接比较,需要用strcmp函数。 strcmp 函数的原型定义在 <string.h> 头文件中,其定义如下: int strcmp(const …...
)
告别Keil!用VSCode+OpenOCD+STLink一键下载STM32程序(保姆级教程)
用VSCodeOpenOCDSTLink打造高效STM32开发环境 在嵌入式开发领域,Keil和IAR等传统IDE长期占据主导地位,但它们臃肿的安装包、昂贵的授权费用和略显陈旧的用户界面让许多开发者开始寻找更现代化的替代方案。Visual Studio Code(VSCodeÿ…...

基于Python与aiogram构建多模型AI助手:集成GPT-4、Claude与Gemini的Telegram机器人开发实践
1. 项目概述:一个多模型AI助手的自研之路 最近在折腾一个挺有意思的玩意儿,我把它叫做“AIAssistantBot”。简单来说,这是一个跑在Telegram上的机器人,但它不是那种只会回复固定指令的“傻”机器人。它的核心是整合了市面上几家主…...

Active Record Doctor与多数据库支持:MySQL、PostgreSQL、SQLite兼容性详解
Active Record Doctor与多数据库支持:MySQL、PostgreSQL、SQLite兼容性详解 【免费下载链接】active_record_doctor Identify database issues before they hit production. 项目地址: https://gitcode.com/gh_mirrors/ac/active_record_doctor Active Recor…...

终极魔兽争霸3优化指南:5分钟让你的经典游戏焕发新生
终极魔兽争霸3优化指南:5分钟让你的经典游戏焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸3》的老旧限制…...

掌握AI专著撰写技巧,借助工具3天完成20万字专著创作!
学术专著的生命力在于逻辑的严谨性,而逻辑论证正是写作中最容易出现问题的地方。专著的撰写必须围绕核心观点展开系统的论证,既需要对每一个论点进行详细的阐述,还要面对不同学派的争议观点,同时保证理论框架的自洽,避…...

STM32高效驱动WS2812:SPI+DMA时序精解与实战避坑
1. WS2812驱动原理与SPIDMA方案优势 第一次接触WS2812灯带时,我被它的单线控制方式惊艳到了——只需要一根信号线就能控制数百个RGB灯珠。但真正动手实现时才发现,这个看似简单的协议背后藏着不少玄机。WS2812采用归零码(RZ)编码方…...

图像理解的底层逻辑:从像素到语义的三层跃迁
1. 这不是“看图说话”,而是让机器学会“看见”的底层逻辑 你有没有想过,当手机相册自动给你把“猫”和“狗”的照片分到不同相册里,或者修图App能一键抠出人像边缘、连发丝都清晰分明,背后到底发生了什么?很多人以为A…...
)
工控人必备技能:VMware虚拟机+Win10+博途V15完整开发环境搭建实录(从镜像下载到PLC在线)
工控工程师的移动工作站:VMwareWin10博途V15全栈开发环境实战指南 在工业自动化领域,能够随时随地进行PLC程序开发和调试的能力已经成为工程师的核心竞争力。想象这样一个场景:深夜接到产线紧急故障通知,而你的开发环境却锁在办公…...

Windows和Office激活难题终结者:KMS智能激活脚本全攻略
Windows和Office激活难题终结者:KMS智能激活脚本全攻略 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾为Windows系统那恼人的激活提醒而烦恼?是否因为Office突然…...

NVIDIA Profile Inspector完整指南:解锁显卡隐藏性能的终极方案
NVIDIA Profile Inspector完整指南:解锁显卡隐藏性能的终极方案 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾经感觉自己的NVIDIA显卡性能没有完全发挥?明明配置不差&…...