【在Python中爬取网页信息并存储】
在Python中爬取网页信息并存储的过程通常涉及几个关键步骤:发送HTTP请求、解析HTML内容、提取所需数据,以及将数据存储到适当的格式中(如文本文件、CSV文件、数据库等)。以下是一个更详细的指南,包括示例代码,演示如何完成这些步骤。
步骤1:安装必要的库
首先,你需要安装requests和BeautifulSoup库(如果还没有安装的话)。requests用于发送HTTP请求,而BeautifulSoup用于解析HTML内容。
pip install requests beautifulsoup4
步骤2:发送HTTP请求
使用requests库发送HTTP请求到目标网页。
import requestsurl = 'https://example.com' # 替换为你要爬取的网页URL
response = requests.get(url)# 检查请求是否成功
if response.status_code == 200:page_content = response.text
else:print(f"Failed to retrieve the webpage. Status code: {response.status_code}")page_content = None
步骤3:解析HTML内容
使用BeautifulSoup解析HTML内容。
from bs4 import BeautifulSoupif page_content:soup = BeautifulSoup(page_content, 'html.parser')# 现在你可以使用soup对象来提取所需的数据了
步骤4:提取所需数据
根据你的需求提取数据。例如,提取所有文章标题或链接。
# 提取所有标题(假设标题都在<h2>标签内)
titles = [h2.get_text(strip=True) for h2 in soup.find_all('h2')]# 提取所有链接(假设链接都在<a>标签内)
links = [a.get('href') for a in soup.find_all('a', href=True)]
步骤5:存储数据
将提取的数据存储到适当的格式中。例如,存储到CSV文件中。
import csv# 假设我们要存储标题和链接
data = list(zip(titles, links)) # 创建一个包含标题和链接的元组列表# 写入CSV文件
with open('webpage_data.csv', 'w', newline='', encoding='utf-8') as file:writer = csv.writer(file)writer.writerow(['Title', 'Link']) # 写入表头writer.writerows(data) # 写入数据行print("Data saved to webpage_data.csv")
完整示例代码
将上述步骤整合成一个完整的示例代码:
import requests
from bs4 import BeautifulSoup
import csvurl = 'https://example.com' # 替换为你要爬取的网页URL
response = requests.get(url)# 检查请求是否成功
if response.status_code == 200:page_content = response.textsoup = BeautifulSoup(page_content, 'html.parser')# 提取所有标题(假设标题都在<h2>标签内)titles = [h2.get_text(strip=True) for h2 in soup.find_all('h2')]# 提取所有链接(假设链接都在<a>标签内)links = [a.get('href') for a in soup.find_all('a', href=True)]# 假设我们要存储标题和链接data = list(zip(titles, links)) # 创建一个包含标题和链接的元组列表# 写入CSV文件with open('webpage_data.csv', 'w', newline='', encoding='utf-8') as file:writer = csv.writer(file)writer.writerow(['Title', 'Link']) # 写入表头writer.writerows(data) # 写入数据行print("Data saved to webpage_data.csv")
else:print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
注意事项
- 在实际使用中,你可能需要根据目标网页的具体结构来调整提取数据的方式。
- 遵守目标网站的
robots.txt文件和使用条款,不要进行恶意爬取。 - 考虑使用异常处理来捕获和处理可能发生的错误,如网络问题、解析错误等。
- 如果需要爬取大量数据,考虑使用异步请求库(如
aiohttp)或分布式爬虫框架来提高效率。
相关文章:

【在Python中爬取网页信息并存储】
在Python中爬取网页信息并存储的过程通常涉及几个关键步骤:发送HTTP请求、解析HTML内容、提取所需数据,以及将数据存储到适当的格式中(如文本文件、CSV文件、数据库等)。以下是一个更详细的指南,包括示例代码ÿ…...

ESP32 Bluedroid 篇(1)—— ibeacon 广播
前言 前面我们已经了解了 ESP32 的 BLE 整体架构,现在我们开始实际学习一下Bluedroid 从机篇的广播和扫描。本文将会以 ble_ibeacon demo 为例子进行讲解,需要注意的一点是。ibeacon 分为两个部分,一个是作为广播者,一个是作为观…...

【通配符】粗浅学习
1 背景说明 首先要注意,通配符中的符号和正则表达式中的特殊符号具备不同的匹配意义,例如:*在正则表达式中表示里面是指匹配前面的子表达式0次或者多次,而在通配符领域则是表示代表0个到无穷个任意字符。 此外,要注意…...

Spring MVC 常用注解
目录 基础概念 常用注解介绍 基础概念 1、MVC :代表一种软件架构设计思想,通俗的理解:客户端发送请求到后台服务器的Controller(C),控制器调用Model(M)来处理业务逻辑,处理完成后,返回处理后的数据到Vie…...

水泵模块(5V STM32)
目录 一、介绍 二、传感器原理 1.尺寸介绍 2.继电器控制水泵电路原理图 三、程序设计 main.c文件 bump.h文件 bump.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 水泵模块(bump)通常是指用于液体输送系统的组件,它负责将水或其他流体从低处提…...

需求6:如何写一个后端接口?
这两天一直在对之前做的工作做梳理总结,不过前两天我都是在总结一些bug的问题。尽管有些bug问题我还没写文章,但是,我今天不得不先停下对bug的总结了。因为在国庆之后,我需要自己开发一个IT资产管理的功能,这个功能需要…...
:文件权限控制及文件操作相关的命令)
《Linux从小白到高手》理论篇(五):文件权限控制及文件操作相关的命令
本篇介绍Linux文件权限控制及文件操作相关的命令,看完本文,有关Linux文件权限控制及文件操作相关的常用命令你就掌握了99%了。 文件权限 在介绍文件权限之前先来复习下Linux的文件类型,始终记住那句话:Linux系统下,一…...
异常场景分析
优质博文:IT-BLOG-CN 为了防止黑客从前台异常信息,对系统进行攻击。同时,为了提高用户体验,我们都会都抛出的异常进行拦截处理。 一、异常处理类 Java把异常当做是破坏正常流程的一个事件,当事件发生后,…...

Leetcode: 0001-0010题速览
Leetcode: 0001-0010题速览 本文材料来自于LeetCode solutions in any programming language | 多种编程语言实现 LeetCode、《剑指 Offer(第 2 版)》、《程序员面试金典(第 6 版)》题解 遵从开源协议为知识共享 版权归属-相同方式…...
计算机的错误计算(一百一十二)
摘要 计算机的错误计算(六十三)与(六十八)以及(六十九)分别探讨了大数与 附近数以及 附近数 的余切函数的计算精度问题。本节讨论余切序列(即迭代 )的计算精度问题。 余切序列是指…...
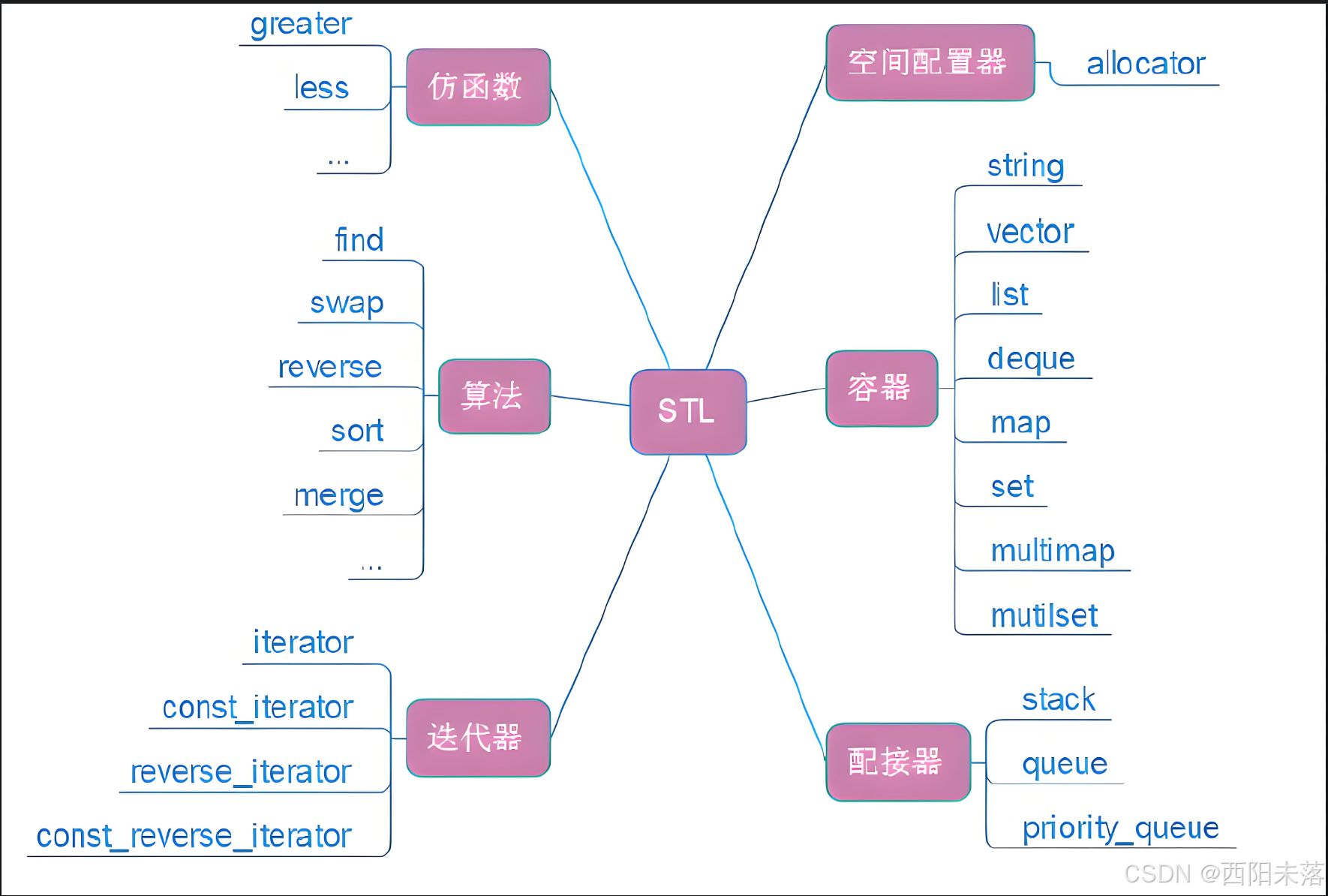
C++基础(7)——STL简介及string类
目录 1.STL简介 1.1什么是 1.2STL的历史版本 1.3STL的六大组件 编辑 1.4有用的网址 2.string类 2.1string的多种定义方式 2.2string的插入 2.2.1尾插(push_back) 2.2.2insert插入 2.3拼接(append) 2.4删除 2.4.1尾…...

配置Nginx以支持通过HTTPS回源到CDN
要配置Nginx以支持通过HTTPS回源到CDN,你需要确保Nginx已正确配置SSL,并且能够处理来自CDN的HTTPS请求。以下是一个简化的Nginx配置示例,它配置了SSL并设置了代理服务器参数以回源到CDN: server {listen 443 ssl;server_name you…...
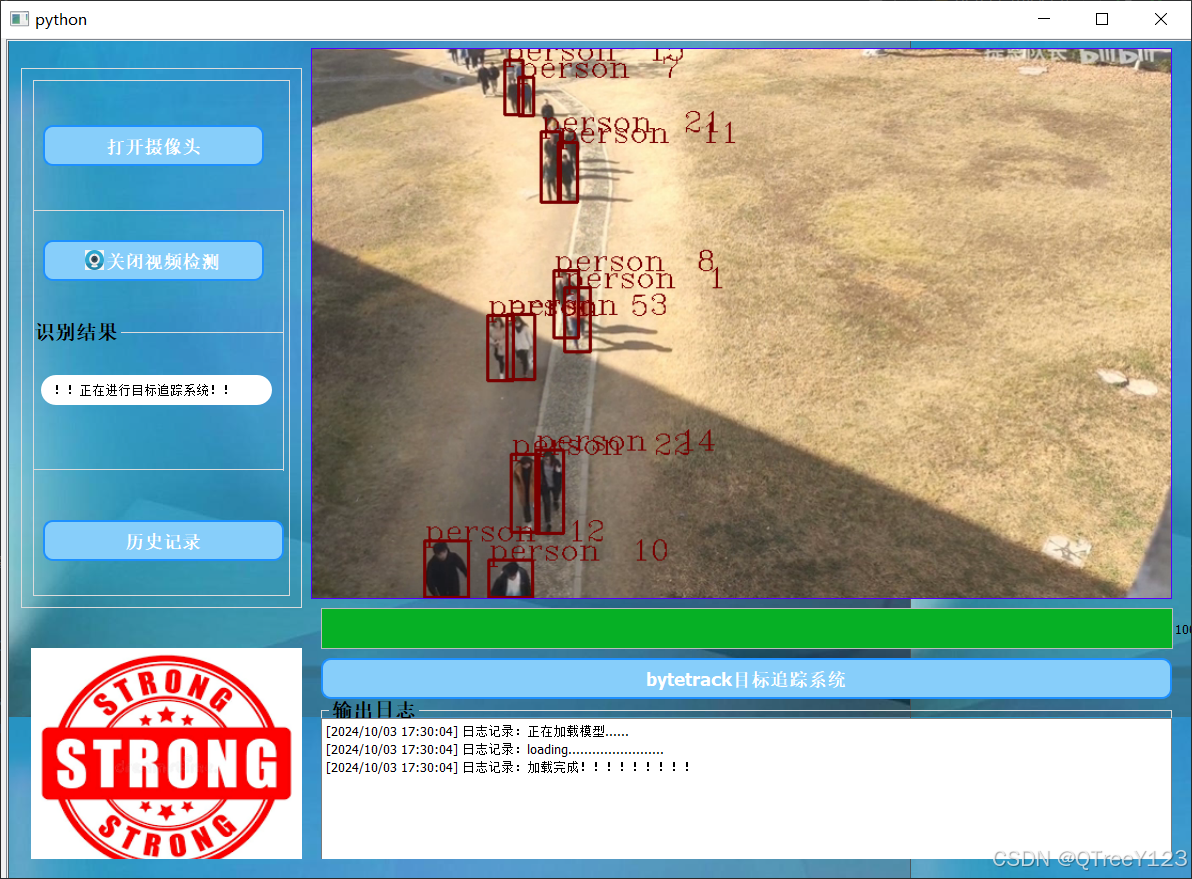
yolov10+strongsort的目标跟踪实现
此次yolov10deepsort不论是准确率还是稳定性,再次超越了之前的yolodeepsort系列。 yolov10介绍——实时端到端物体检测 YOLOv10 是清华大学研究人员在 UltralyticsPython 清华大学的研究人员在 YOLOv10软件包的基础上,引入了一种新的实时目标检测…...
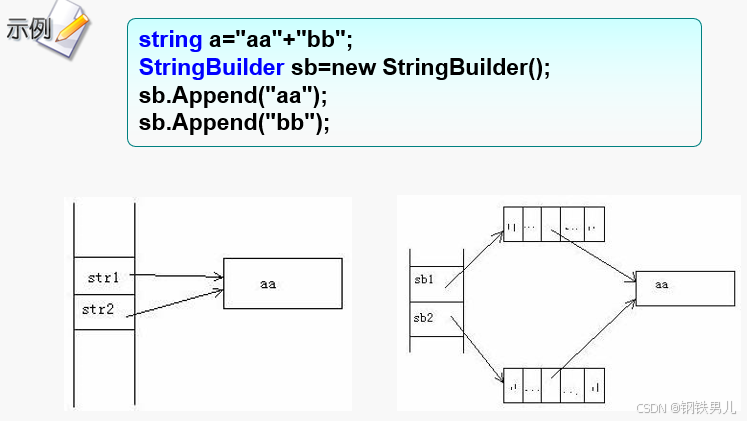
C# 字符与字符串
本课要点: 1、字符类Char的使用 2、字符串类String的使用 3、可变字符串****StringBuilder 4、常见错误 一 何时用到字符与字符串 问题: 输出C#**课考试最高分:**98.5 输出最高分学生姓名:张三 输出最高分学生性别&#x…...

在Ubuntu 16.04上使用LEMP安装WordPress的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 WordPress 是互联网上最流行的 CMS(内容管理系统)。它允许您在 MySQL 后端和 PHP 处理的基础上轻松设置灵…...

显示器放大后,大漠识图识色坐标偏移解决方法
原因分析: 显示器分辨率较高,DPI设置放大125% or 150% or 200%,游戏打开时也会默认会根据显示器的放大比例自行放大,但是大漠综合管理工具抓图不会放大; 解决方法: 1、大漠综合管理…...

C++容器之list基本使用
目录 前言 一、list的介绍? 二、使用 1.list的构造 2.list iterator的使用 3.list capacity 🥇 empty 🥇size 4.list element access 🥇 front 🥇 back 5.list modifiers 🥇 push_front 🥇 po…...
Redis-哨兵
概念 Redis Sentinel 相关名词解释 注意: 哨兵机制不负责存储数据,只是对其它的redis-server进程起到监控的作用哨兵节点,也会搞一个集合,防止一个挂了 ⼈⼯恢复主节点故障 用户监控: 实际开发中,对于服务器后端开发,监控程序,是很重要的 服务器长期运行,总会有一些意外,…...
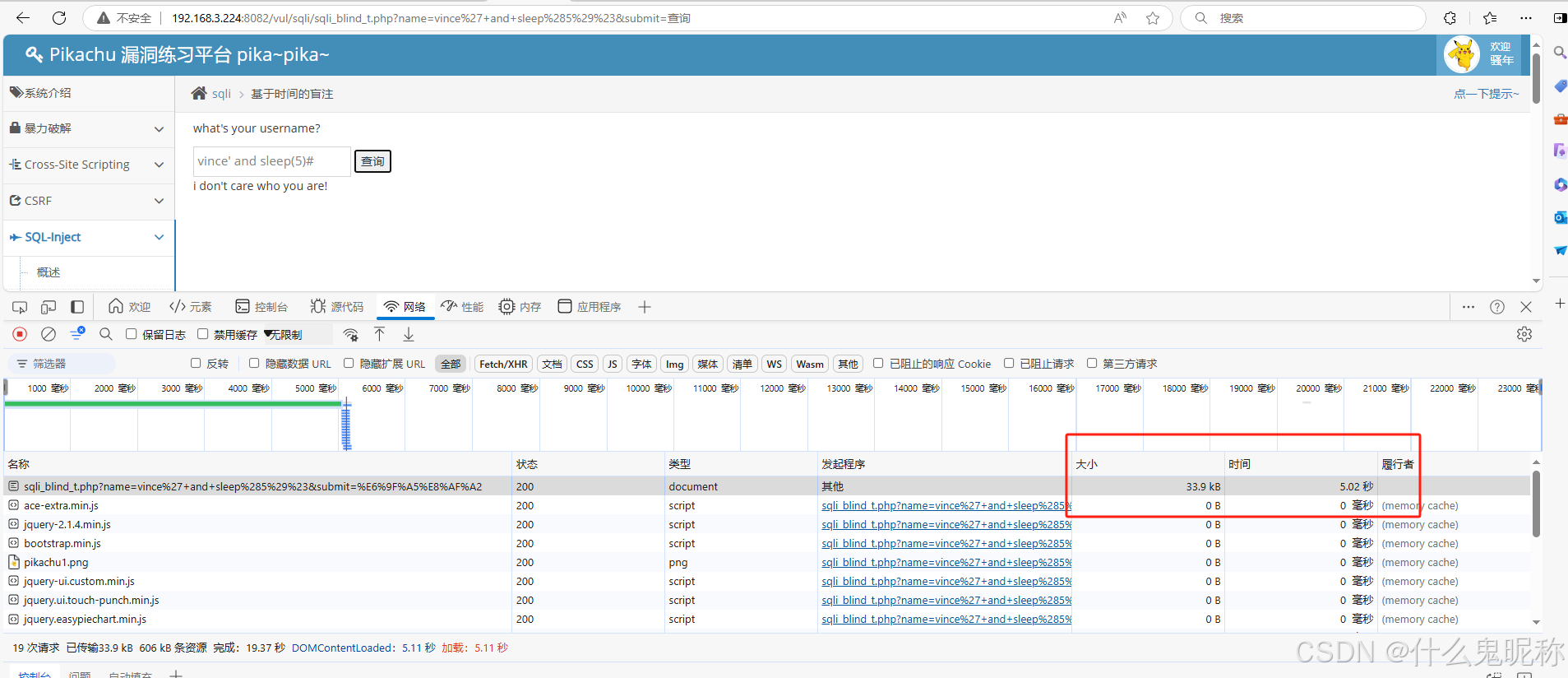
Pikachu-Sql-Inject - 基于时间的盲注
基于时间的盲注: 就是前端的基于time 的盲注,什么错误信息都看不到,但是还可以通过特定的输入,判断后台的执行时间,从而确定注入。 mysql 里函数sleep() 是延时的意思,sleep(10)就是数据库延时10 秒返回内…...

JAVA开源项目 旅游管理系统 计算机毕业设计
本文项目编号 T 063 ,文末自助获取源码 \color{red}{T063,文末自助获取源码} T063,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析5.4 用例设计 六、核…...

羽毛球每天必练的基本功:拉吊四方球战术、吊杀结合战术
文章目录 引言 I 羽毛球每天必练的基本功 1. 握拍练习 2. 挥拍动作 3. 步法训练 4. 球感练习 5. 发力技巧 II 发力 正确发力 握拍 反手发力 III 羽毛球单打战术 拉吊四方球战术 直线变斜线战术 重复落点战术 吊杀结合战术 追身球压制战术 防守反击战术 引言 打球前必须热身(活…...

AI Agent与DevOps融合:自动化开发与运维的智能体工具链
AI Agent与DevOps深度融合:打造全链路自动化开发运维的智能体工具链实践指南 摘要/引言 你有没有遇到过这些DevOps场景的痛点:凌晨3点收到线上告警,爬起来翻几百条日志排查根因花了40分钟,业务已经损失了几十万;团队100个开发每天提交200+MR,DevOps团队光做代码审查就要…...

LaTeX2Word-Equation:3分钟实现LaTeX公式到Word的无缝转换
LaTeX2Word-Equation:3分钟实现LaTeX公式到Word的无缝转换 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为学术论文中复杂的数…...

Helm 2到Helm 3迁移实战:深入解析helm-2to3插件原理与操作指南
1. 项目概述与背景 如果你和我一样,在Kubernetes生态里摸爬滚打了几年,那你一定对Helm这个“包管理器”又爱又恨。爱的是它用声明式的Chart把复杂的应用部署变得像 helm install 一样简单;恨的是版本升级带来的“阵痛”,尤其是从…...

VMware macOS虚拟机深度解锁指南:Unlocker 3.0架构剖析与实战应用
VMware macOS虚拟机深度解锁指南:Unlocker 3.0架构剖析与实战应用 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 在虚拟化技术领域,VMware Workstation和Player用户长期面临一个…...

RESTful API最佳实践:构建优雅的接口设计
RESTful API最佳实践:构建优雅的接口设计 前言 大家好,我是cannonmonster01!今天我们来聊聊RESTful API的最佳实践。 想象一下,你去一家餐厅吃饭。如果菜单混乱不堪,菜名不知所云,服务员态度恶劣&#x…...
)
自动化生产管理平台(Automatic)
1,自动化生产管理平台(Automatic) 1.1,重新定义Window样式 添加WindowChrome元素进行自定义定义 <Window x:Class"lzg.Automatic.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"…...

QMCDecode终极指南:3分钟解锁QQ音乐加密文件,让音乐自由播放
QMCDecode终极指南:3分钟解锁QQ音乐加密文件,让音乐自由播放 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录…...
)
LeetCode 1665.完成所有任务的最少初始能量:排序(贪心)
【LetMeFly】1665.完成所有任务的最少初始能量:排序(贪心) 力扣题目链接:https://leetcode.cn/problems/minimum-initial-energy-to-finish-tasks/ 给你一个任务数组 tasks ,其中 tasks[i] [actuali, minimumi] : actuali 是完…...

告别双系统!Win11下用WSL2直通NVIDIA显卡跑PyTorch,保姆级配置避坑指南
告别双系统!Win11下用WSL2直通NVIDIA显卡跑PyTorch,保姆级配置避坑指南 在深度学习开发中,Linux环境往往能提供更高效的GPU计算体验,但日常办公和娱乐又离不开Windows的便利。传统解决方案是安装双系统,频繁重启切换不…...