pdf处理1
处理PDF文件以构建数据索引是一个复杂但关键的步骤,尤其是因为PDF格式的文件通常包含多种元素,如文本、图片、表格、标题等。以下是一个通俗易懂的详细解释,帮助你理解PDF文件是如何被处理和解析的:
1. PDF文件的基本结构
PDF(Portable Document Format)是一种页面描述语言,用于呈现文档的布局和内容。一个PDF文件可能包含以下元素:
- 文本:段落、标题、脚注等。
- 图片:插图、照片、图表等。
- 表格:结构化的数据展示。
- 图形元素:线条、形状、图标等。
- 多媒体:视频、音频(较少见)。
2. 处理步骤
步骤一:文件加载与解析
首先,需要将PDF文件加载到处理系统中。解析PDF文件的工具(如PDFBox、PyMuPDF等)会读取文件的内容流,将其转化为可处理的格式。
步骤二:版面分析
版面分析的目的是识别PDF页面上的不同区域和元素类型。这包括:
- 文本块:识别段落、标题、页眉页脚等。
- 图像块:检测并提取图片的位置和内容。
- 表格块:识别表格的行列结构。
难点:PDF文件中元素的位置和布局可能非常复杂,特别是包含多列、嵌入式图表或混合内容的页面。
解决方法:使用先进的版面分析模型,如百度的PP StructureV2,这类模型能够高效地检测和分类不同类型的区域(如文本、标题、图片、表格等),并准确识别它们的边界和属性。
步骤三:文本提取与处理
一旦识别了文本块,接下来是提取其中的文字内容。这包括:
- OCR(光学字符识别):对于扫描的PDF或图片中的文字,需要使用OCR技术将图像中的文字转换为可编辑的文本。
- 文本解析:将提取的文字根据其属性(如字体大小、加粗、斜体)进行分类,以保留原始文档的结构和格式。
难点:文本可能存在旋转、扭曲或模糊,影响识别准确性。
解决方法:使用高精度的OCR工具,并结合版面分析结果,确保文本的准确提取和分类。
步骤四:图像和表格的提取与重构
- 图像提取:将检测到的图像区域单独提取出来,并保存其位置信息和相关描述(如图像标题)。
- 表格提取:识别表格的行列结构,提取单元格中的数据,并重构为结构化的表格格式(如CSV或数据库表)。
难点:复杂的表格结构、合并单元格或嵌套表格会增加提取难度。
解决方法:利用专业的表格识别算法,结合版面分析,确保表格的准确重构。
步骤五:数据统一与存储
将提取的文本、图像、表格等内容按照统一的范式进行存储。这包括:
- 数据向量化(Embedding):将文本内容转换为向量表示,以便后续的索引和搜索。
- 索引创建:基于向量化的数据创建高效的索引结构(如向量数据库),以支持快速检索。
3. 综合应用
在实际应用中,处理PDF文件通常需要结合多个工具和模型,协同工作。例如:
- PDF解析工具:如PDFBox、PyMuPDF,用于基础的文件解析。
- 版面分析模型:如PP StructureV2,用于复杂布局的识别。
- OCR工具:如Tesseract、百度OCR,用于图像中文字的识别。
- 表格识别工具:如Tabula、Camelot,用于表格的提取和重构。
4. 实例说明
假设你有一个包含多个章节、图片和表格的PDF报告。处理流程如下:
- 加载PDF:使用PDF解析工具读取文件内容。
- 版面分析:识别每一页上的章节标题、正文段落、图片和表格的位置。
- 提取文本:将每个章节的文字内容提取出来,并保留其结构(如章节编号、标题层级)。
- 提取图片:保存所有图片,并记录它们在文档中的位置和相关描述。
- 提取表格:将表格内容转换为结构化数据,方便后续的数据分析。
- 数据存储与索引:将所有提取的数据进行向量化,存入数据库,并创建索引,确保后续的快速检索和查询。
5. 总结
处理PDF文件以构建数据索引涉及多个步骤和技术,关键在于准确地识别和提取不同类型的内容,并将其结构化存储。通过使用先进的工具和模型,可以有效地解决PDF处理中的各种难点,确保数据索引的准确性和高效性。
希望这个解释能帮助你更好地理解PDF文件在数据索引构建中的处理过程!
5.2 如何对数据进行检索(Retrieval)?
在数据索引完成后,如何高效、准确地从大量数据中检索出所需的信息是一个关键环节。以下是对数据检索过程的详细解释,包括其动机、主要思路和常用技术。
1. 动机:检索环节的重要性
- 获取有效信息:在海量数据中,检索环节决定了能否快速找到相关且准确的信息,直接影响用户体验和业务效率。
- 提升效率和相关性:通过优化检索方法,可以减少不相关的信息干扰,提高检索结果的相关性和准确性。
2. 检索的主要思路
2.1 元数据过滤
- 概念:当数据被分割成许多“chunks”(小块)时,直接在所有chunks中进行检索会降低效率。元数据过滤通过预先筛选出符合条件的chunks,缩小检索范围。
- 举例:假设你有一个包含多个文档的数据库,每个文档都有标签(如日期、作者、主题等)。在检索时,先根据标签筛选出相关的文档,再在这些文档中进行具体内容的检索。
- 优势:大幅提升检索速度和结果的相关性,减少计算资源的消耗。
2.2 图关系检索
- 概念:利用知识图谱(Knowledge Graph)将数据中的实体(如人物、地点、事件)表示为节点(Node),它们之间的关系表示为边(Relation)。
- 应用:
- 多跳问题:例如,查询“某位科学家影响了哪些领域”,需要通过多个关系链条来得到答案。
- 提高相关度:通过理解实体之间的关系,可以提供更准确和有深度的检索结果。
- 优势:适用于复杂查询,能够捕捉数据中的深层次关系,提升检索的准确性和智能化水平。
3. 常用的检索技术
3.1 向量化(Embedding)相似度检索
- 概念:将文本或其他数据转化为高维向量(数值表示),通过计算向量之间的相似度来进行检索。
- 相似度计算方式:
- 欧氏距离(Euclidean Distance):测量两个向量之间的直线距离。
- 曼哈顿距离(Manhattan Distance):测量两个向量在各维度上的绝对差值之和。
- 余弦相似度(Cosine Similarity):测量两个向量之间的夹角,反映方向上的相似性。
- 应用:适用于语义检索,可以识别出意义相近但表达不同的内容。
3.2 关键词检索
- 概念:基于用户输入的关键词在数据中查找匹配的内容,是最传统和广泛使用的检索方式。
- 方法:
- 直接匹配:查找包含特定关键词的文档或内容块。
- 元数据过滤:结合元数据(如标签、分类)进行初步筛选。
- 摘要匹配:先对内容块进行摘要提取,再通过摘要中的关键词进行检索。
- 优势:简单高效,适用于结构化和半结构化数据。
3.3 全文检索
- 概念:在整个文本中搜索关键词或短语,而不仅仅是标题或特定字段。
- 特点:
- 全面覆盖:能够在文档的任何部分找到匹配内容。
- 支持复杂查询:如布尔查询、短语匹配、模糊查询等。
- 应用:适用于需要深入文本内容的场景,如文献检索、法律文件查找等。
3.4 SQL检索
- 概念:使用结构化查询语言(SQL)在关系数据库中执行检索操作。
- 特点:
- 结构化数据:适用于有明确表结构和关系的数据。
- 复杂查询:支持多表联结、聚合、排序等高级查询功能。
- 应用:广泛应用于企业数据管理、事务处理等场景。
4. 其他关键技术
4.1 重排序(Rerank)
- 概念:在初步检索后,根据相关度、匹配度等因素对检索结果进行重新排序,使其更符合实际需求。
- 方法:
- 相关度评分:基于内容相关性重新评分。
- 业务规则:结合具体业务需求进行调整,如优先显示最新内容、权威来源等。
- 优势:提高最终用户看到的结果质量,提升满意度。
4.2 查询轮换
- 概念:采用多种查询策略和方法,动态调整检索过程以获得更好的结果。
- 方式:
- 子查询(Subquery):将复杂查询分解为多个简单查询,逐步获取和合并结果。
- 树查询(Tree Query):采用树状结构,从叶子节点一步步向上查询和合并。
- 向量查询:结合向量化技术进行语义检索。
- 顺序查询(Sequential Query):按照预定顺序依次查询各个内容块。
- 工具:如LlamaIndex等框架提供的查询器,可以灵活选择和组合不同的查询策略。
- 优势:增强检索的灵活性和适应性,适应不同的检索需求和场景。
4.3 HyDE
- 概念:Hybrid Dynamic Execution(混合动态执行),是一种生成相似或更标准的提示模板(Prompt Template)的方法。
- 作用:
- 生成标准化提示:通过自动生成和优化提示模板,提高检索和生成内容的质量。
- 适应不同场景:根据具体需求生成适应不同业务场景的提示,提高系统的智能化水平。
- 优势:提高检索和生成过程的效率和准确性,适应多变的业务需求。
5. 实际应用示例
假设你有一个包含大量技术文档的数据库,用户需要检索关于“机器学习算法优化”的信息。以下是检索流程:
- 元数据过滤:
- 根据文档的标签(如“机器学习”、“算法优化”)筛选出相关文档。
- 关键词检索:
- 在筛选出的文档中搜索关键词“优化”、“算法”、“性能”等。
- 向量化相似度检索:
- 将用户查询转换为向量,与文档内容向量进行相似度计算,找到语义上最匹配的内容块。
- 图关系检索:
- 利用知识图谱,查找“机器学习”相关的实体及其关系,提供更深入的关联信息。
- 重排序:
- 根据相关度评分和业务需求,对初步结果进行排序,确保最相关的信息优先展示。
- 查询轮换:
- 根据用户反馈和具体需求,动态调整查询策略,进一步优化检索结果。
- HyDE:
- 生成优化后的提示模板,提高检索过程的智能化和自动化水平。
总结
数据检索是数据处理流程中至关重要的一环,通过多种技术和方法的结合,可以实现高效、准确的信息获取。元数据过滤、图关系检索、向量化相似度检索、关键词检索、全文检索和SQL检索等技术各有优势,适用于不同的场景和需求。重排序和查询轮换等方法则进一步优化检索结果的质量和相关性。掌握和应用这些技术,能够显著提升数据检索的效率和用户体验。
希望以上解释能帮助你更好地理解数据检索的各个方面!
深入理解数据检索中的重排序、查询轮换和HyDE
在前面的内容中,我们介绍了数据检索的基本概念和主要技术。接下来,我们将深入探讨三个关键环节:重排序(Rerank)、查询轮换(Query Rotation)以及HyDE。我们将以通俗易懂的方式解释这些概念,并详细介绍其中的一些专有名词。
1. 重排序(Rerank)
重排序是指在初步检索出一组候选结果后,根据特定的标准或规则,对这些结果的顺序进行重新调整,以确保最相关和最重要的信息排在前面。这一过程有助于提升用户体验,使用户更快地找到他们真正需要的信息。
为何需要重排序?
- 初步检索的局限性:初步检索(如关键词匹配或向量相似度检索)可能会返回一系列相关但不完全符合用户需求的结果。
- 业务需求差异:不同的业务场景可能对结果的相关性有不同的要求。例如,电商网站可能更关注最新的产品信息,而法律数据库则更注重法律条文的准确性和权威性。
重排序的关键因素
- 相关度(Relevance):结果与用户查询的匹配程度。
- 匹配度(Match Degree):具体的匹配细节,如关键词出现的频率和位置。
- 业务规则(Business Rules):特定业务场景下的优先级规则,例如优先展示高评价产品或最新发布的文章。
如何实现重排序?
- 评分机制:为每个检索结果计算一个相关度分数,基于内容匹配、用户行为等因素。
- 结合业务规则:根据业务需求调整分数,例如给某些类别的内容加权。
- 重新排序:按照最终得分从高到低排列检索结果。
举例说明: 假设用户在搜索“智能手机”,初步检索返回了50个相关产品。通过重排序,可以将评价高、价格适中、最新发布的手机排在前面,从而提高用户的满意度和购买转化率。
2. 查询轮换(Query Rotation)
查询轮换是一种动态调整检索策略的方法,通过采用多种查询策略和技术,以获得更准确和全面的检索结果。查询轮换可以根据不同的场景和需求,灵活选择最合适的查询方式。
查询轮换的主要方式
- 子查询(Subquery)
- 树查询(Tree Query)
- 向量查询(Vector Query)
- 顺序查询(Sequential Query)
详细解释各方式
2.1 子查询(Subquery)
子查询是将一个复杂的查询分解为多个简单的小查询,逐步获取和合并结果。这种方法适用于需要分阶段筛选数据的场景。
举例: 用户查询“过去一年内销售额超过100万的智能手机”。首先,可以通过子查询筛选出过去一年的销售数据,再从中筛选出销售额超过100万的产品。
2.2 树查询(Tree Query)
树查询采用树状结构,从叶子节点一步步向上查询和合并结果。适用于层级结构的数据,如分类目录或知识图谱。
举例: 在一个企业内部知识库中,用户查询“市场部的最新营销策略”。树查询可以从具体的策略文档开始,逐步向上找到相关的部门和整体营销计划。
2.3 向量查询(Vector Query)
向量查询利用向量化技术,将查询和数据转换为向量,通过计算向量之间的相似度进行检索。适用于语义检索,即理解查询的语义而不仅仅是关键词匹配。
举例: 用户查询“如何优化机器学习模型”,向量查询可以理解用户意图,检索出关于模型优化、参数调整、性能提升等相关内容,即使这些内容使用了不同的表述方式。
2.4 顺序查询(Sequential Query)
顺序查询按照预定顺序依次查询各个内容块。这是最原始和简单的查询方式,适用于数据量较小或查询逻辑简单的场景。
举例: 在一个小型文档库中,用户查询“年度报告”,顺序查询可以从第一个文档开始,依次查找包含“年度报告”的内容块。
使用框架和工具
LlamaIndex等框架提供了灵活的查询器,允许开发者根据具体需求选择和组合不同的查询策略。例如,可以结合树查询和向量查询,实现复杂的数据检索需求。
举例: 在一个混合型数据库中,用户查询“最新的市场分析报告”,系统可以先使用树查询定位市场部门的报告目录,再通过向量查询找到最相关的分析内容。
3. HyDE
HyDE(Hybrid Dynamic Execution)是一种生成相似或更标准的提示模板(Prompt Template)的方法。尽管这个名字听起来技术性较强,实际上它的作用是优化和标准化用户与系统之间的交互方式,以提升检索和生成内容的质量。
HyDE的作用
- 生成标准化提示:通过自动生成和优化提示模板,使得系统能够更准确地理解用户意图和需求。
- 适应不同场景:根据具体的业务需求,生成适应不同场景的提示,提高系统的智能化水平。
为何需要HyDE?
- 提高准确性:标准化的提示模板有助于系统更准确地解析用户查询,减少误解和错误。
- 提升效率:自动生成提示模板减少了手动编写的工作量,加快了系统响应速度。
- 增强灵活性:能够根据不同的业务需求动态调整提示模板,适应多变的应用场景。
如何实现HyDE?
- 收集和分析用户查询:通过分析大量用户查询,识别常见的查询模式和需求。
- 生成提示模板:基于分析结果,自动生成标准化的提示模板,涵盖不同的查询类型和业务场景。
- 优化和调整:根据用户反馈和系统表现,持续优化提示模板,确保其适应性和准确性。
举例说明: 在一个客户服务系统中,用户可能会提出各种问题,如“如何重置密码”、“订单状态查询”等。HyDE可以根据这些常见问题生成标准化的提示模板,使得系统能够快速理解并提供准确的回答。例如,对于“如何重置密码”,生成的提示模板可能包括步骤说明、常见问题解答等内容,提高了回答的质量和一致性。
总结
重排序(Rerank)、查询轮换(Query Rotation)和HyDE是提升数据检索效果的重要技术手段:
- 重排序通过重新调整检索结果的顺序,确保最相关的信息优先展示,提升用户满意度。
- 查询轮换通过采用多种查询策略和技术,灵活应对不同的检索需求和场景,增强检索的准确性和全面性。
- HyDE通过生成和优化标准化提示模板,提升系统对用户意图的理解能力,提高检索和生成内容的质量。
掌握并合理应用这些技术,可以显著提升数据检索系统的性能和用户体验,满足不同业务场景下的多样化需求。
希望以上解释能帮助你更好地理解重排序、查询轮换和HyDE在数据检索中的作用和实现方式
相关文章:

pdf处理1
处理PDF文件以构建数据索引是一个复杂但关键的步骤,尤其是因为PDF格式的文件通常包含多种元素,如文本、图片、表格、标题等。以下是一个通俗易懂的详细解释,帮助你理解PDF文件是如何被处理和解析的: 1. PDF文件的基本结构 PDF&a…...
)
区间覆盖(贪心)
给定 NN 个闭区间 [ai,bi][ai,bi] 以及一个线段区间 [s,t][s,t],请你选择尽量少的区间,将指定线段区间完全覆盖。 输出最少区间数,如果无法完全覆盖则输出 −1−1。 输入格式 第一行包含两个整数 ss 和 tt,表示给定线段区间的两…...

[rk3588 debain]cpu死锁问题解决
1 问题 rk3588机器上运行客户如下程序程序发生“BUG: spinlock recursion on CPU#0” ./rtsp RtspWrapper.xml 应用程序功能是:ip摄像头推流,通过rtsp协议拉流,对视频流做裁剪,缩放工作。首先,根据视频帧率每秒钟处理…...

CMU 10423 Generative AI:lec18(大模型的分布式训练)
这个文档主要讲解了分布式训练(Distributed Training),特别是如何在多GPU上训练大规模的语言模型。以下是主要内容的概述: 1. 问题背景 训练大规模语言模型的主要挑战是内存消耗。 训练过程中,内存消耗主要来源于两个…...

项目级别的配置文件 `.git/config`||全局配置文件 `~/.gitconfig`
Git 项目级别的配置文件 .git/config,该文件包含了当前项目(仓库)的特定配置。 与全局配置文件 ~/.gitconfig 不同,这里的设置仅对当前项目生效。 配置内容解释 [core]repositoryformatversion 0filemode truebare falselog…...

【Docker】配置文件
问题 学习Docker期间会涉及到docker的很多配置文件,可能会涉及到的会有: /usr/lib/systemd/system/docker.service 【docker用于被systemd管理的配置文件】 /etc/systemd/system/docker.service.d【覆盖配置文件的存放处】 /etc/systemd/system/mul…...

坐标系变换总结
二维情况下的转换 1 缩放变换 形象理解就是图像在x方向和y方向上放大或者缩小。 代数形式: { x ′ k x x y ′ k y y \begin{cases} x k_x x \\ y k_y y \end{cases} {x′kxxy′kyy 矩阵形式: ( x ′ y ′ ) ( k x 0 0 k y ) ( x y ) \be…...

数据在内存中的存储【上】
一.整型在内存中的存储 在讲解操作符的时候,我们就讲过了下面的内容: 整数的2进制表示方法有三种,即 原码、反码和补码 有符号的整数,三种表示方法均有符号位和数值位两部分,符号位都是用0表示"正"ÿ…...

Prometheus之Pushgateway使用
Pushgateway属于整个架构图的这一部分 The Pushgateway is an intermediary service which allows you to push metrics from jobs which cannot be scraped. The Prometheus Pushgateway exists to allow ephemeral and batch jobs to expose their metrics to Prometheus. S…...

Rust Web开发常用库
本集合中所有库都是在开源项目中广泛使用且在2024年积极维护的库,排名靠前的库是当前使用比较广泛的,不全面但够用 Rust异步运行时 tokio:异步运行时 async_std:与标准库兼容性较强的运行时 monoio:字节开源 smol…...

ios内购支付-支付宝APP支付提现
文章目录 前言一、IOS内购支付(ios订单生成自己写逻辑即可)1.支付回调票据校验controller1.支付回调票据校验server 二、安卓APP支付宝支付1.生成订单返回支付宝字符串(用于app拉起支付宝,这里用的是证书模式)2.生成订…...

新课发布|鸿蒙HarmonyOS Next商城APP应用开发实战
2024年年初,鸿蒙HarmonyOS Next星河版强势发布,随着鸿蒙系统的普及和应用场景的拓展,市场需求将持续增加。鸿蒙系统已经应用于华为的智能手机、平板电脑、智能家居等多个领域,并有望在未来拓展到智能汽车、物联网等更多领域。这为…...

基于Java,SpringBoot,Vue智慧校园健康驿站体检论坛请假管理系统
摘要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让信息都可以通过网络传播,搭配信息管理工具可以很好地为人们提供服务。针对信息管理混乱,出错率高,信息安全性差…...
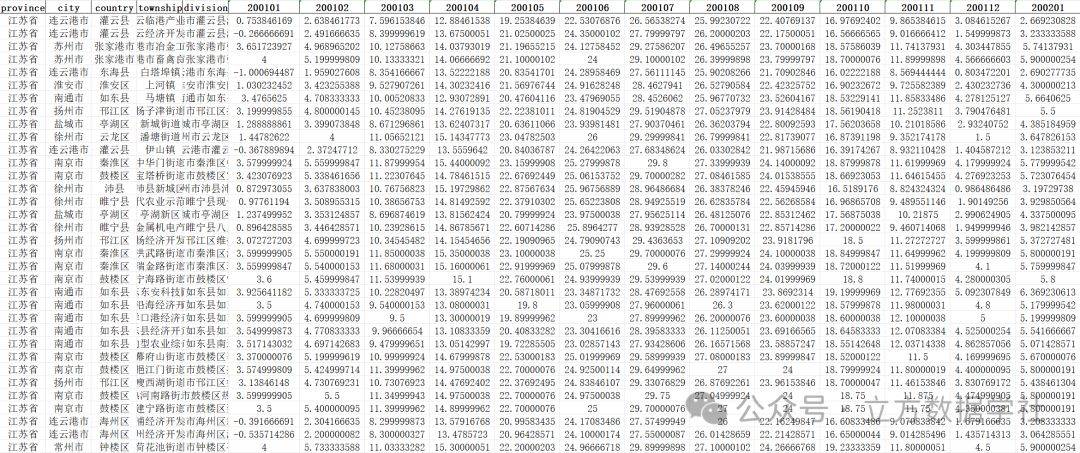
【数据分享】2001-2023年我国省市县镇四级的逐月平均气温数据(免费获取/Shp/Excel格式)
之前我们分享过1901-2023年1km分辨率逐月平均气温栅格数据,该数据来源于国家青藏高原科学数据中心。为方便大家使用,我们还基于上述平均气温栅格数据将数据处理为Shp和Excel格式的省市县三级逐月平均气温数据(可查看之前的文章获悉详情&#…...

c#代码介绍23种设计模式_16迭代器模式
目录 1、迭代器模式的介绍 2、迭代器模式的定义 3、迭代器模式的结构 4、代器模式角色组成 5、迭代器实现 6、迭代器模式的适用场景 7、迭代器模式的优缺点 8、.NET中迭代器模式的应用 9、实现思路 1、迭代器模式的介绍 迭代器是针对集合对象而生的,对于集合对象而言…...

408算法题leetcode--第23天
236. 二叉树的最近公共祖先 236. 二叉树的最近公共祖先\思路:递归,如注释时间和空间:O(n) /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode(int x) …...
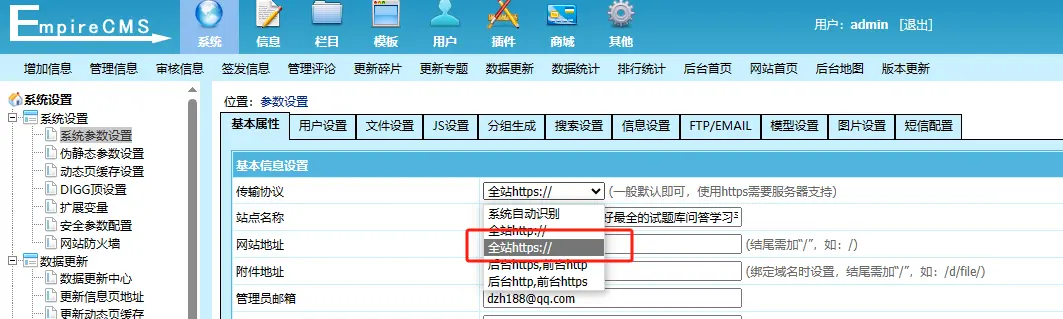
帝国CMS系统开启https后,无法登陆后台的原因和解决方法
今天本地配置好了帝国CMS7.5,传去服务器后,使用http访问一切正常。但是当开启了https(SSL)后,后台竟然无法登陆进去了。 输入账号密码后,点击登陆,跳转到/e/admin/ecmsadmin.php就变成页面一片…...

根据视频id查询播放量
声明:文章仅用于学习交流,如有侵权请联系删除 如何根据视频ID查询视频的播放数量 在数字化时代,视频内容的消费已成为人们日常生活的重要组成部分。无论是社交媒体平台上的短视频,还是视频分享网站上的长视频,了解视频的播放数量…...

初始爬虫11
1.斗鱼selenium爬取 # -*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.common.by import By import timeclass Douyu(object):def __init__(self):self.url https://www.douyu.com/directory/allself.driver webdriver.Chrome()self.driver…...

SSY20241002提高组T4题解__纯数论
题面 题目描述 有一天 p e o p 1 e peop1e peop1e 学长梦到了一个丑陋的式子: ∑ i 1 n ( ∑ m 1 R F m ) ! i ! ∑ l 0 i ∑ j 0 ∑ t 1 R F t { K i − l } l ! { i ∑ w 1 R F w − j } j ! \sum_{i1}^n (\sum_{m1}^R F_m)!\times i!\times \sum_{l…...

别再用 STVP 了!用 IAR 3.11.1 调试 STM8S003 点灯程序,效率翻倍
告别STVP:用IAR 3.11.1高效调试STM8S003点灯程序全指南 在嵌入式开发领域,工具链的选择往往决定了开发效率的上限。对于STM8系列开发,许多工程师仍在使用STVP这种基础的烧录工具,却不知已经错过了IAR Embedded Workbench带来的效…...

避开这些坑!国产电池管理AFE芯片DVC1124的I2C驱动开发实战指南
避开这些坑!国产电池管理AFE芯片DVC1124的I2C驱动开发实战指南 在BMS(电池管理系统)开发中,AFE(模拟前端)芯片的稳定通信是确保电池数据准确采集的基础。DVC1124作为国产高性能电池监测芯片,其I…...

端到端关键词识别技术范式:WeKWS在边缘计算场景下的架构创新与实践
端到端关键词识别技术范式:WeKWS在边缘计算场景下的架构创新与实践 【免费下载链接】wekws Production First and Production Ready End-to-End Keyword Spotting Toolkit 项目地址: https://gitcode.com/gh_mirrors/we/wekws 在物联网设备普及的今天&#x…...

利用Taotoken为Claude Code配置稳定后备API解决封号与Token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken为Claude Code配置稳定后备API解决封号与Token不足问题 对于依赖Claude Code进行日常开发的工程师而言,服…...

硬件工程师效率翻倍:我是如何让Cadence OrCAD导出的PDF自动生成清晰书签目录的
硬件工程师效率革命:用OrCAD打造智能PDF文档工作流 在硬件设计领域,一份结构清晰的原理图PDF文档往往能大幅提升团队协作效率。想象一下这样的场景:当你将精心设计的电路方案交付给客户或跨部门同事时,对方打开的是一个带有智能书…...

2026年降AI技术进化深度解读:从换词替句到语义重构各代技术效果完整对比
2026年降AI技术进化深度解读:从换词替句到语义重构各代技术效果完整对比 跟同学聊起降AI技术进化解读,发现大家理解差距很大。理解浅的踩很多坑,理解深的很快解决了。 这篇文章把原理和实战方法都讲清楚。 理解降AI技术进化解读的核心逻辑 …...

六核国产CPU高性能显控方案:从自主可控到流畅体验的工程实践
1. 项目概述:从“能用”到“好用”的国产化显控之路 最近几年,但凡关注过信息技术领域的朋友,对“国产化”、“自主可控”这几个词一定不陌生。从芯片到操作系统,再到上层应用,一场深刻的产业变革正在发生。我作为一名…...

初次使用Taotoken模型广场进行选型与测试的直观感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken模型广场进行选型与测试的直观感受 作为一名需要接入大模型能力的开发者,面对市场上众多的模型提供商…...

从 LangChain 到 LangGraph:大语言模型应用开发框架极简史
大模型应用开发正经历一场静悄悄的革命——从“把LLM接进工作流”走向“为Agent构建操作系统”。作为这场革命的两大核心引擎,LangChain与LangGraph的故事,既是一部框架演进史,也是一部开发者认知升级史。 一、源起:一个框架的诞生与大模型开发的“蛮荒时代” 时间回到202…...

基于STM32的直流电机串级PID伺服控制系统设计与实现
摘要:本文设计并实现了一套基于STM32F103C8T6微控制器的直流电机串级PID伺服控制系统。该系统采用TB6612FNG驱动芯片控制带霍尔编码器的直流减速电机,通过位置-速度双闭环串级控制架构,实现了对电机位置和速度的高精度、快速响应控制。项目简…...