Kafka学习笔记(一)Kafka基准测试、幂等性和事务、Java编程操作Kafka
文章目录
- 前言
- 4 Kafka基准测试
- 4.1 基于1个分区1个副本的基准测试
- 4.2 基于3个分区1个副本的基准测试
- 4.3 基于1个分区3个副本的基准测试
- 5 Java编程操作Kafka
- 5.1 引入依赖
- 5.2 向Kafka发送消息
- 5.3 从Kafka消费消息
- 5.4 异步使用带有回调函数的生产消息
- 6 幂等性
- 6.1 幂等性介绍
- 6.2 Kafka幂等性实现原理
- 7 Kafka事务
- 7.1 Kafka事务介绍
- 7.2 事务操作API
- 7.3 Kafka事务编程
- 7.3.1 需求
- 7.3.2 创建Topic
- 7.3.3 编写生产者
- 7.3.4 创建消费者
- 7.3.5 消费旧Topic数据并生产到新Topic
- 7.3.6 测试
- 7.3.7 模拟异常测试事务
前言
Kafka学习笔记(一)Linux环境基于Zookeeper搭建Kafka集群、Kafka的架构
4 Kafka基准测试
基准测试(benchmark testing)是一种测量和评估软件性能指标的活动。 我们可以通过基准测试,了解到软件、硬件的性能水平,主要测试负载的执行时间、传输速度、吞吐量、资源占用率等。
4.1 基于1个分区1个副本的基准测试
- 1)创建1个分区1个副本的Topic
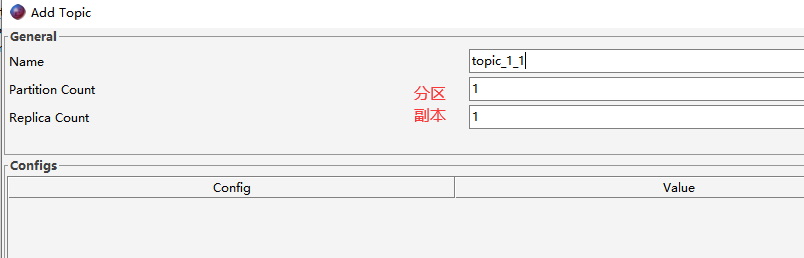
- 2)生产消息基准测试
bin/kafka-producer-perf-test.sh --topic topic_1_1 --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 acks=1
命令解释:
- bin/kafka-producer-perf-test.sh 性能测试脚本
- –topic Topic的名称
- –num-records 指定生产数据量(默认5000W)
- –throughput 指定吞吐量,即限流(-1不指定)
- –record-size record数据大小(字节)
- –producer-props bootstrap.servers 指定Kafka集群地址
- acks=1 ACK模式
执行以上命令,结果如下:

- 3)消费消息基准测试
bin/kafka-consumer-perf-test.sh --broker-list 192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 --topic topic_1_1 --fetch-size 1048576 --messages 5000000 --timeout 100000
命令解释:
- bin/kafka-consumer-perf-test.sh 消费消息基准测试脚本
- –broker-list 集群Broker列表
- –topic Topic的名称
- –fetch-size 每次拉取的数据大小
- –messages 总共要消费的消息个数
- –timeout 超时时间
执行以上命令,结果如下:

4.2 基于3个分区1个副本的基准测试
- 1)创建3个分区1个副本的Topic

- 2)生产消息基准测试
bin/kafka-producer-perf-test.sh --topic topic_3_1 --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 acks=1
| 指标 | 3分区1副本 | 1分区1副本 | 性能(对比1分区1副本) |
|---|---|---|---|
| 吞吐量 | 10900.822140 records/sec | 8994.536718 records/sec | 提升↑ |
| 吞吐速率 | 10.40 MB/sec | 8.58 MB/sec | 提升↑ |
| 平均延迟时间 | 2508.37 ms avg latency | 3418.50 ms avg latency | 提升↑ |
| 最大延迟时间 | 47436.00 ms max latency | 50592.00 ms max latency |
- 3)消费消息基准测试
bin/kafka-consumer-perf-test.sh --broker-list 192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 --topic topic_3_1 --fetch-size 1048576 --messages 5000000 --timeout 100000
| 指标 | 3分区1副本 | 1分区1副本 | 性能(对比1分区1副本) |
|---|---|---|---|
| data.consumed.in.MB 共计消费数据量 | 4768.4021 | 4768.3716 | |
| MB.sec 每秒消费数据量 | 28.5637 | 21.1589 | 提升↑ |
| data.consumed.in.nMsg 共计消费消息数量 | 5000032 | 5000000 | |
| nMsg.sec 每秒消费消息数量 | 29951.2517 | 22186.7235 | 提升↑ |
4.3 基于1个分区3个副本的基准测试
- 1)创建1个分区3个副本的Topic
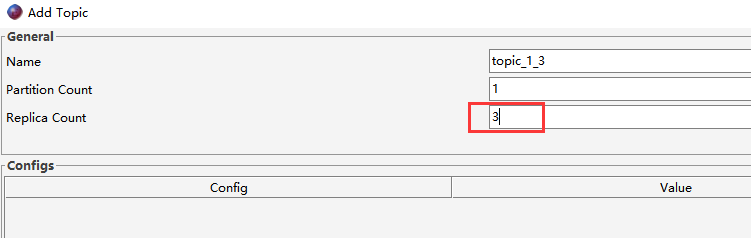
- 2)生产消息基准测试
bin/kafka-producer-perf-test.sh --topic topic_1_3 --num-records 5000000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 acks=1
| 指标 | 1分区3副本 | 1分区1副本 | 性能(对比1分区1副本) |
|---|---|---|---|
| 吞吐量 | 4323.273652 records/sec | 8994.536718 records/sec | 下降↓ |
| 吞吐速率 | 4.12 MB/sec | 8.58 MB/sec | 下降↓ |
| 平均延迟时间 | 7533.70 ms avg latency | 3418.50 ms avg latency | 下降↓ |
| 最大延迟时间 | 32871.00 ms max latency | 50592.00 ms max latency |
可见,副本越多,生产消息的性能反而下降。
- 3)消费消息基准测试
bin/kafka-consumer-perf-test.sh --broker-list 192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092 --topic topic_1_3 --fetch-size 1048576 --messages 5000000 --timeout 100000
| 指标 | 1分区3副本 | 1分区1副本 | 性能(对比1分区1副本) |
|---|---|---|---|
| data.consumed.in.MB 共计消费数据量 | 4768.3716 | 4768.3716 | |
| MB.sec 每秒消费数据量 | 46.9504 | 21.1589 | 下降↓ |
| data.consumed.in.nMsg 共计消费消息数量 | 5000000 | 5000000 | |
| nMsg.sec 每秒消费消息数量 | 49231.0116 | 22186.7235 | 下降↓ |
同样,副本越多,消费消息的性能也下降。
5 Java编程操作Kafka
创建一个Maven项目,测试Java变成操作Kafka。
5.1 引入依赖
<!-- kafka_demo\pom.xml --><!-- kafka客户端工具 -->
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.4.1</version>
</dependency>
5.2 向Kafka发送消息
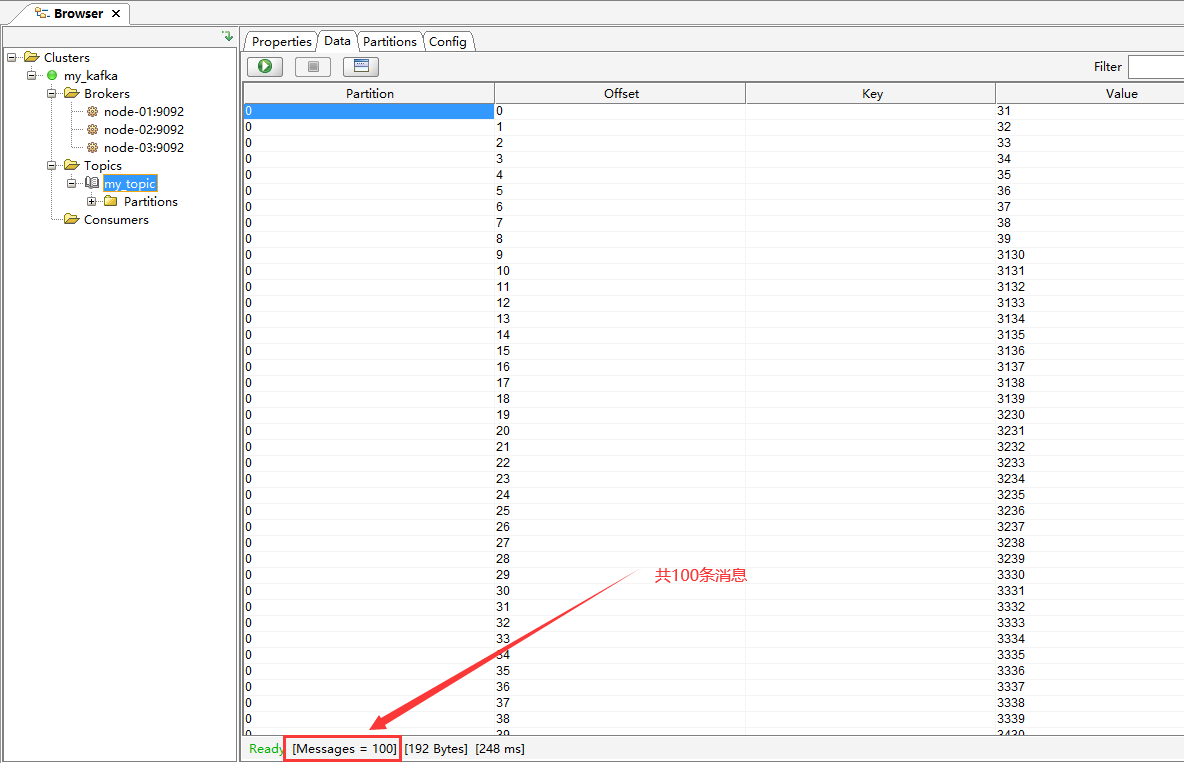
public class KafkaProducerTest {public static void main(String[] args) {// 1.创建用于连接Kafka的Properties配置Properties props = new Properties();props.put("bootstrap.servers", "192.168.245.130:9092");props.put("acks", "all");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 2.创建一个生产者对象KafkaProducerKafkaProducer<String, String> producer = new KafkaProducer<>(props);// 3.调用send发送1-100消息到`my_topic`主题for(int i = 0; i < 100; ++i) {try {// 获取返回值Future,该对象封装了返回值Future<RecordMetadata> future = producer.send(new ProducerRecord<>("my_topic", null, i + ""));// 调用一个Future.get()方法等待响应future.get();} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}}// 4. 关闭生产者producer.close();}}
执行以上代码,查看此时my_topic主题中的消息:
5.3 从Kafka消费消息
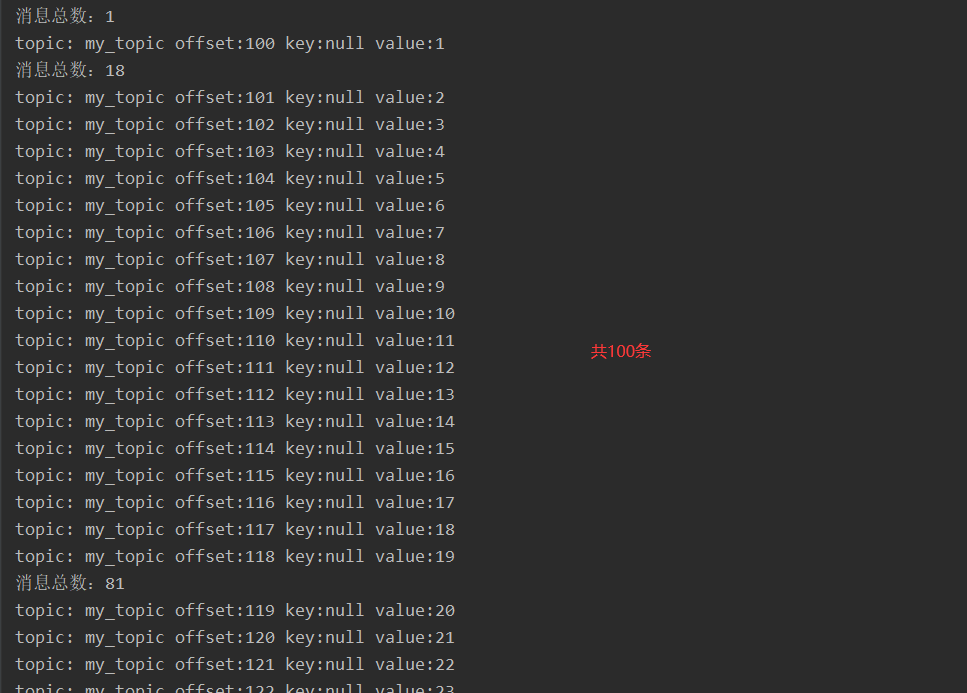
public class KafkaConsumerTest {public static void main(String[] args) throws InterruptedException {// 1.创建Kafka消费者配置Properties props = new Properties();props.setProperty("bootstrap.servers", "node-01:9092,node-02:9092,node-03:9092");// 消费者组(可以使用消费者组将若干个消费者组织到一起),共同消费Kafka中topic的数据// 每一个消费者需要指定一个消费者组,如果消费者的组名是一样的,表示这几个消费者是一个组中的props.setProperty("group.id", "my_group");// 自动提交offsetprops.setProperty("enable.auto.commit", "true");// 自动提交offset的时间间隔props.setProperty("auto.commit.interval.ms", "1000");// 拉取的key、value数据的props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 2.创建Kafka消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(props);// 3. 订阅要消费的主题// 指定消费者从哪个topic中拉取数据kafkaConsumer.subscribe(Arrays.asList("my_topic"));// 4.使用一个while循环,不断从Kafka的topic中拉取消息while(true) {// Kafka的消费者一次拉取一批的数据ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(5));System.out.println("消息总数:" + consumerRecords.count());// 5.将将记录(record)的offset、key、value都打印出来for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {// 主题String topic = consumerRecord.topic();// offset:这条消息处于Kafka分区中的哪个位置long offset = consumerRecord.offset();// key\valueString key = consumerRecord.key();String value = consumerRecord.value();System.out.println("topic: " + topic + " offset:" + offset + " key:" + key + " value:" + value);}Thread.sleep(1000);}}
}
执行以上代码,查看打印日志:
5.4 异步使用带有回调函数的生产消息
如果想知道消息是否成功发送到Kafka,或者成功发送消息到Kafka后执行一些其他动作,就可以使用带有回调函数的发送方法来发送消息。
public static void main(String[] args) {// 1. 创建用于连接Kafka的Properties配置Properties props = new Properties();props.put("bootstrap.servers", "node-01:9092");props.put("acks", "all");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 2. 创建一个生产者对象KafkaProducerKafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);// 3. 调用send发送1-100消息到指定Topic testfor(int i = 1; i <= 100; i++) {// 一、同步方式// 获取返回值Future,该对象封装了返回值// Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>("my_topic", null, i + ""));// 调用一个Future.get()方法等待响应// future.get();// 二、带回调函数异步方式producer.send(new ProducerRecord<String, String>("my_topic", null, i + ""), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if(exception != null) {System.out.println("发送消息出现异常!");}else {String topic = metadata.topic();int partition = metadata.partition();long offset = metadata.offset();System.out.println("发送消息到Kafka中的名字为" + topic + "的主题,第" + partition + "分区,第" + offset + "条数据成功!");}}});}// 4. 关闭生产者producer.close();
}
执行以上代码,查看打印日志:

6 幂等性
6.1 幂等性介绍
在HTTP/1.1中对幂等性的定义是:一次和多次请求某一个资源,对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,任意多次请求执行,对资源本身所产生的影响均与一次请求执行的影响相同。
实现幂等性的关键就是服务端可以区分请求是否重复,过滤掉重复的请求。要区分请求是否重复有两个要素:
- 唯一标识:要想区分请求是否重复,请求中就得有唯一标识。例如支付请求中,订单号就是唯一标识。
- 记录下已处理过的请求标识:光有唯一标识还不够,还需要记录下哪些请求是已经处理过的,这样当收到新的请求时,用新请求中的标识和处理记录进行比较,如果处理记录中有相同的标识,说明是重复交易,拒绝掉。
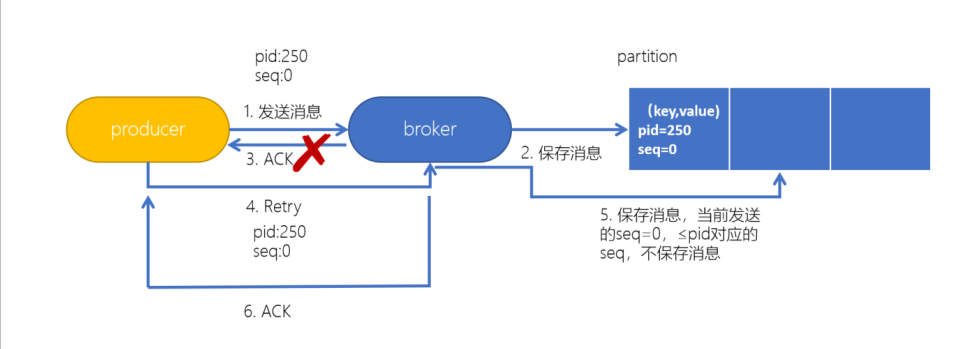
如上图所示,当再次发送的消息(seq=0)和上次发送的消息(seq=0)重复时,不保存新的消息。
6.2 Kafka幂等性实现原理
为了实现生产者的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。
- PID:每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是不可见的。
- Sequence Numbler:针对每个生产者(对应PID)发送到指定的<Topic, Partition>的消息都对应一个从0开始单调递增的Sequence Number。
而生产者想要实现幂等性,只需要添加以下配置:
// 实现幂等性
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
7 Kafka事务
7.1 Kafka事务介绍
通过事务机制,Kafka可以实现对多个Topic的多个Partition的原子性的写入,即处于同一个事务内的所有消息,不管最终需要落地到哪个Topic 的哪个Partition,最终结果都是要么全部写成功,要么全部写失败。
开启事务,必须开启幂等性,Kafka的事务机制,在底层依赖于幂等生产者。
7.2 事务操作API
要开启Kafka事务,生产者需要添加以下配置:
// 配置事务的id,开启了事务会默认开启幂等性
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-transactional");
消费者则需要添加以下配置:
// 设置隔离级别
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
// 关闭自动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
Producer接口中定义了以下5个事务相关方法:
- 1.
initTransactions(初始化事务):要使用Kafka事务,必须先进行初始化操作 - 2.
beginTransaction(开始事务):启动一个Kafka事务 - 3.
sendOffsetsToTransaction(提交偏移量):批量地将分区对应的offset发送到事务中,方便后续一块提交 - 4.
commitTransaction(提交事务):提交事务 - 5.
abortTransaction(放弃事务):取消事务
7.3 Kafka事务编程
7.3.1 需求
在Kafka的Topic[ods_user]中有一些用户数据,数据格式如下:
姓名,性别,出生日期
张三,1,1980-10-09
李四,0,1985-11-01
现在要编写程序,将用户的性别转换为男、女(1-男,0-女),转换后将数据写入到Topic[dwd_user]中。要求使用事务保障,要么消费了数据的同时写入数据到新Topic,提交offset;要么全部失败。
7.3.2 创建Topic
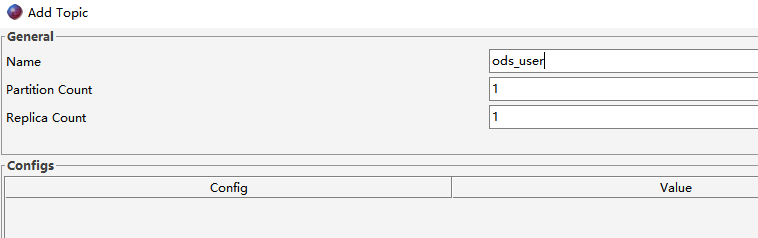
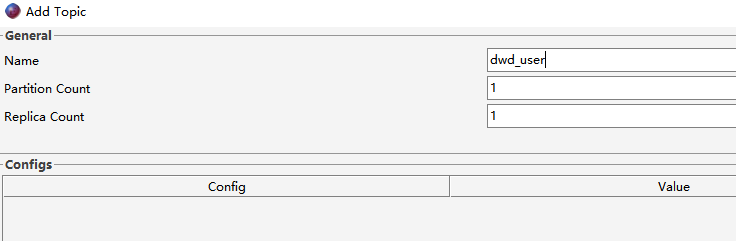
启动生产者控制台程序,准备发送消息到Topic[ods_user]:
[root@node-01 kafka01]$ bin/kafka-console-producer.sh --broker-list 192.168.245.130:9092 --topic ods_user
>
启动消费者控制台程序,准备从新Topic[dwd_user]消费消息:
[root@node-01 kafka01]$ bin/kafka-console-consumer.sh --bootstrap-server 192.168.245.130:9092 --topic dwd_user --from-beginning --isolation-level read_committed
7.3.3 编写生产者
private static KafkaProducer<String, String> createProducer() {// 1.创建用于连接Kafka的Properties配置Properties props = new Properties();// 配置事务的id,开启了事务会默认开启幂等性props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "my-transactional");props.put("bootstrap.servers", "192.168.245.130:9092");props.put("acks", "all");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 2.创建一个生产者对象KafkaProducerKafkaProducer<String, String> producer = new KafkaProducer<>(props);return producer;
}
7.3.4 创建消费者
private static KafkaConsumer<String, String> createConsumer() {// 1.创建Kafka消费者配置Properties props = new Properties();props.setProperty("bootstrap.servers", "192.168.245.130:9092,192.168.245.131:9092,192.168.245.132:9092");props.setProperty("group.id", "my_group");// 关闭自动提交offsetprops.setProperty("enable.auto.commit", "false");// 事务隔离级别props.put("isolation.level", "read_committed");props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 2.创建Kafka消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 3.订阅要消费的主题consumer.subscribe(Arrays.asList("ods_user"));return consumer;
}
7.3.5 消费旧Topic数据并生产到新Topic
public static void main(String[] args) {KafkaProducer<String, String> producer = createProducer();KafkaConsumer<String, String> consumer = createConsumer();// 1.初始化事务producer.initTransactions();while (true) {try {// 2.开启事务producer.beginTransaction();// 定义Map结构,用于保存分区对应的offsetMap<TopicPartition, OffsetAndMetadata> offsetCommits = new HashMap<>();// 3.拉取ods_user的消息ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(2));for (ConsumerRecord<String, String> record : records) {System.out.println("原始消息:" + record.value());// 4.保存偏移量offsetCommits.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1));// 5.进行转换处理String[] fields = record.value().split(",");fields[1] = fields[1].equalsIgnoreCase("1") ? "男" : "女";String newMsg = fields[0] + "," + fields[1] + "," + fields[2];// 6.将新消息生产到dwd_userproducer.send(new ProducerRecord<>("dwd_user", newMsg));System.out.println("新消息:" + newMsg);}// 7.提交偏移量到事务producer.sendOffsetsToTransaction(offsetCommits, "my_group");// 8.提交事务producer.commitTransaction();} catch (ProducerFencedException e) {// 9.放弃事务producer.abortTransaction();}}
}
7.3.6 测试
执行上述main()方法,然后向Topic[ods_user]发送消息:

main()方法日志打印:
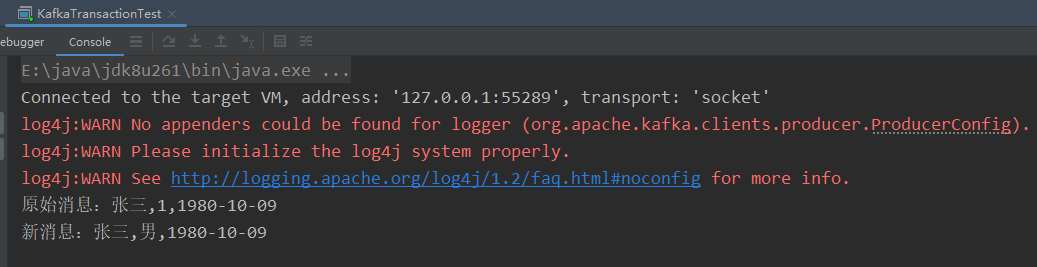
从新Topic[dwd_user]消费消息:

7.3.7 模拟异常测试事务
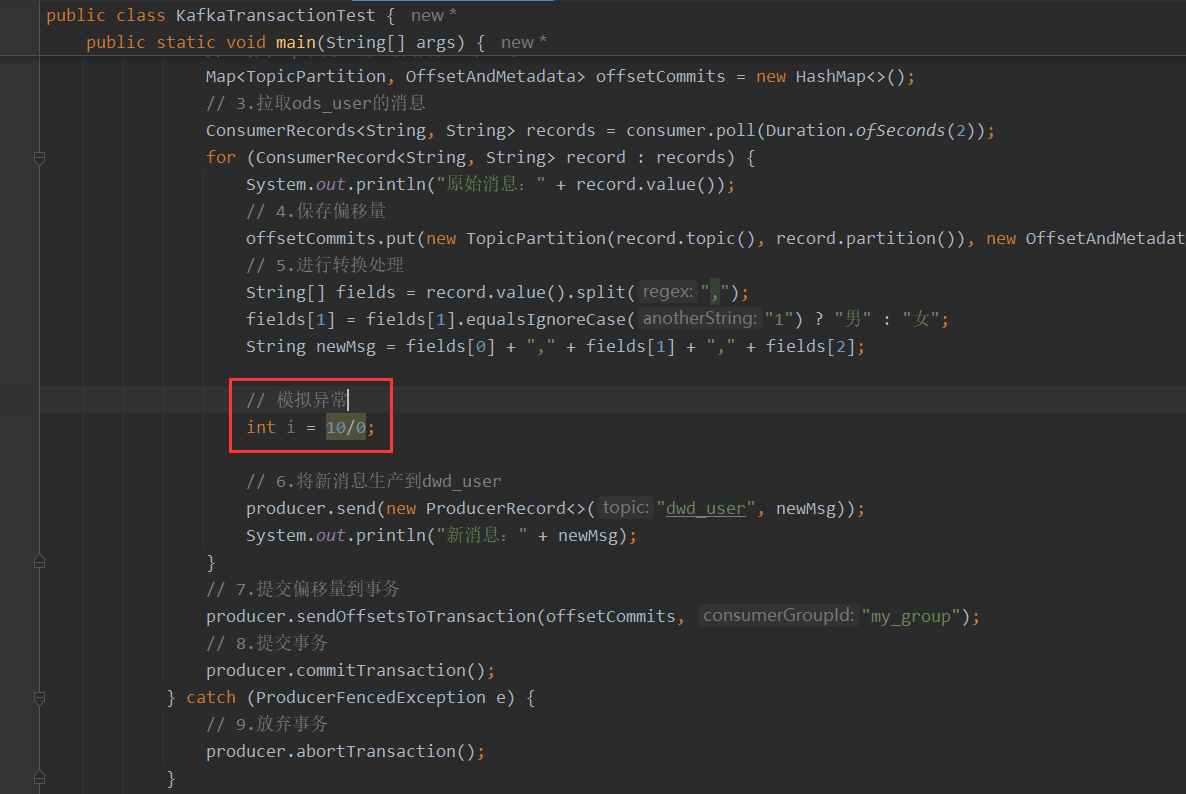
假设在进行转换处理的时候出现异常。再次向Topic[ods_user]发送消息,程序会读取到消息,但转换报错:
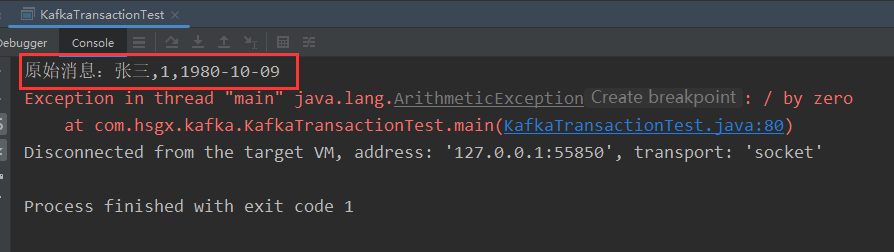
再次重启main()方法,还是可以读取到消息,但转换报错。说明消息一直都没有被消费成功,offset没有被提交,Kafka事务生效了。
…
本节完,更多内容请查阅分类专栏:微服务学习笔记
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析
- MyBatis3源码深度解析
- Redis从入门到精通
- MyBatisPlus详解
- SpringCloud学习笔记
相关文章:
Kafka学习笔记(一)Kafka基准测试、幂等性和事务、Java编程操作Kafka
文章目录 前言4 Kafka基准测试4.1 基于1个分区1个副本的基准测试4.2 基于3个分区1个副本的基准测试4.3 基于1个分区3个副本的基准测试 5 Java编程操作Kafka5.1 引入依赖5.2 向Kafka发送消息5.3 从Kafka消费消息5.4 异步使用带有回调函数的生产消息 6 幂等性6.1 幂等性介绍6.2 K…...

结合vueuse实现图片懒加载
介绍 为什么要有懒加载? 在一个网页中如果有很多张图片,那么用户初进这个页面的时候不必一次性把所有图片都加载出来,否则容易造成卡顿和浪费。应该是,用户的视图页面滑到该图片的位置,然后再把该图片加载出来。 前置…...

Mysql数据库--聚合查询、分组查询、联合查询(不同的连接方式)
文章目录 1.查询的进阶版1.1查询搭配插入进行使用1.2聚合查询1.3group by分组查询1.4联合查询之笛卡尔积1.5左外连接,右外连接介绍join on1.6自连表 1.查询的进阶版 1.1查询搭配插入进行使用 我们首先创建两张表,一个叫做student,一个叫做student2,两个…...
计算机视觉——图像修复综述篇
目录 1. Deterministic Image Inpainting 判别器图像修复 1.1. sigle-shot framework (1) Generators (2) training objects / Loss Functions 1.2. two-stage framework 2. Stochastic Image Inpainting 随机图像修复 2.1. VAE-based methods 2.2. GAN-based methods …...

集中式架构和分布式架构
数据是企业的核心资产和战略资源。面对爆炸性的数据增长,如何有效地组织、管理和利用数据成为企业的重大挑战。数据架构作为企业数据管理的蓝图和框架,发挥重要作用。本文就来详细说下当下主流的两种数据架构的类型。 首先明确数据架构定义:…...

Redis: 集群高可用之故障转移和集群迁移
故障转移 故障转移,包括自动故障转移和手动故障转移 1 )自动故障转移 Redis 集群,主节点挂了,从节点可以顶上来继续提供服务常用制造故障的两种方式 第一,对其中一个节点进行 SHUTDOWN 操作第二,kill 掉…...

记账软件在线、会计记账网站、财务记账官网、记账云、云记账、在线免费做账以及易舟云财务软件
记账软件在线、会计记账网站、财务记账官网、记账云、云记账、在线免费做账以及易舟云财务软件,以下是一些详细的介绍和推荐: 一、记账软件在线与会计记账网站 记账软件和会计记账网站是现代财务管理中不可或缺的工具,它们能够帮助企业或个人…...

Elasticsearch基础_3.基础操作
文章目录 一、索引操作1.1、创建索引1.2、删除索引 二、映射操作2.1、查看映射2.2、扩展映射 三、文档操作3.1、单条写入文档3.2、更新单条文档3.3、查看单条文档3.4、删除单条文档3.5、根据条件删除文档 一、索引操作 1.1、创建索引 PUT /${index_name} {"settings&quo…...

PHP永久性Cookie的含义
PHP中的永久性Cookie(也称为持久性Cookie)是指在用户的计算机上存储的一种持久性的HTTP Cookie。与常规的临时Cookie不同,永久性Cookie在浏览器关闭后依然保留,并且可以在用户下次访问该网站时被读取和使用。 主要特点 持久存储…...

瑜伽培训行业为何要搭建自己的专属知识付费小程序平台?集师知识付费系统 集师知识付费小程序 集师知识服务系统 集师线上培训系统
在当今快节奏的生活中,瑜伽作为一种舒缓压力、增强体质的生活方式,受到了越来越多人的青睐。瑜伽培训行业也随之蓬勃发展,但如何在激烈的市场竞争中脱颖而出,成为众多瑜伽培训机构面临的一大挑战。搭建自己的专属知识付费小程序平…...

FFT 分析进阶-笔记
FFT 分析进阶 边界不连续与泄漏效应解决方法增加窗函数海宁窗与哈布什窗混叠效应频率高到什么程度会出现混叠现象呢?那我们有办法去应对这个混叠吗?经典平均指数平均关于结果的显示模式FFT计算的三个常见的范例计算FFT图谱中某一段的总值,图中…...
毕业设计_基于springboot+layui+mybatisPlus的中小型仓库物流管理系统源码+SQL+教程+可运行】41004
毕业设计_基于springbootlayuimybatisPlus的中小型仓库物流管理系统源码SQL教程可运行】41004 下载地址: https://download.csdn.net/download/qq_24428851/89843203 技术栈 后端:springboot、mybatis-plus、shiro 前端:layUI 存储&…...

ROS基础入门——实操教程
ROS基础入门——实操教程 前言 本教程实操为主,少说书。可供参考的文档中详细的记录了ROS的实操和理论,只是过于详细繁杂了,看得脑壳疼,于是做了这个笔记。 Ruby Rose,放在这里相当合理 本文初编辑于2024年10月4日 C…...

etcd 快速入门
简介 随着go与kubernetes的大热,etcd作为一个基于go编写的分布式键值存储,逐渐为开发者所熟知,尤其是其还作为kubernetes的数据存储仓库,更是引起广泛专注。 本文我们就来聊一聊etcd到底是什么及其工作机制。 首先,…...

Spring MVC__HttpMessageConverter、拦截器、异常处理器、注解配置SpringMVC、SpringMVC执行流程
目录 一、HttpMessageConverter1、RequestBody2、RequestEntity3、ResponseBody4、SpringMVC处理json5、SpringMVC处理ajax6、RestController注解7、ResponseEntity7.1、文件下载7.2、文件上传 二、拦截器1、拦截器的配置2、拦截器的三个抽象方法3、多个拦截器的执行顺序 三、异…...

GAMES101(19节,相机)
相机 synthesis合成成像:比如光栅化,光线追踪,相机是capture捕捉成像, 但是在合成渲染时,有时也会模拟捕捉成像方式(包括一些技术 动态模糊 / 景深等),这时会有涉及很多专有名词&a…...

Django Nginx+uwsgi 安装配置
Django Nginx+uwsgi 安装配置 本文将详细介绍如何在Linux环境下安装和配置Django应用程序,使用Nginx作为Web服务器和uwsgi作为应用程序服务器。我们将覆盖以下主题: 安装Python和相关库安装和配置Django安装Nginx安装和配置uwsgi配置Nginx以使用uwsgi测试和调试1. 安装Pytho…...

oracle数据备份和导入
一、数据导出 创建目录对象: CREATE DIRECTORY dpump_dir AS /path/to/your/directory;授予权限: GRANT READ, WRITE ON DIRECTORY dpump_dir TO test_user; #导出的用户导出全库数据 expdp your_user/your_password DIRECTORYdpump_dir DUMPFILEfu…...

C++ | Leetcode C++题解之第452题用最少数量的箭引爆气球
题目: 题解: class Solution { public:int findMinArrowShots(vector<vector<int>>& points) {if (points.empty()) {return 0;}sort(points.begin(), points.end(), [](const vector<int>& u, const vector<int>&…...

react-问卷星项目(3)
项目实战 React Hooks 缓存,性能优化,提升时间效率,但是不要为了技术而优化,应该是为了业务而进行优化 内置Hooks保证基础功能,灵活配合实现业务功能,抽离公共部分,自定义Hooks或者第三方&am…...

解析日本工程塑料厂家代理新日铁住金产品的核心价值与
在众多日本工程塑料供应商中,新日铁住金凭借其在特种工程塑料领域的技术积累和稳定品质,成为众多制造企业的优选合作伙伴。对于寻求高性价比、稳定供应的塑胶制品厂、精密注塑厂及汽车零部件厂商而言,选择专业代理商是平衡品质与成本的关键。…...

别再傻傻分不清!用打电话、对讲机、广播这些生活例子,5分钟搞懂串行通信里的单工、半双工和全双工
从生活场景秒懂通信模式:广播、对讲机与电话的硬核技术解读 刚接触嵌入式开发时,看到UART、I2C这些协议文档里蹦出的"全双工"、"半双工"术语,是不是感觉像在读天书?别急着翻教科书,其实这些抽象概…...

3分钟学会B站缓存视频转换:m4s转MP4完整指南
3分钟学会B站缓存视频转换:m4s转MP4完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过这样的困扰?在B…...

构建内容生成应用时借助Taotoken灵活选用不同风格模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 构建内容生成应用时借助Taotoken灵活选用不同风格模型 在内容创作与营销文案生成的实际应用中,单一模型往往难以满足多…...

C# 零基础到精通教程 - 第六章:方法——让代码“模块化“
6.1 为什么需要方法?6.1.1 没有方法的问题csharp// 没有方法:代码重复、臃肿、难以维护 static void Main() {// 第一次计算两个数的和int a1 10, b1 20;int sum1 a1 b1;Console.WriteLine($"{a1} {b1} {sum1}");// 第二次计算两个数的和…...

5.20 明天见!拿好这份参会指南|AIGC2026峰会
组委会 发自 凹非寺量子位|公众号 QbitAI明天5月20日,09:30,中国AIGC产业峰会准时开场。提前查好路况,定好闹钟,我们现场见。所有人,马上AI起来。明天聊什么?议程帮你划重点上午场:A…...

别再说国产模型不行了!DeepSeek V4 + Claude Code,编程体验直接起飞
别再说国产模型不行了!DeepSeek V4 Claude Code,编程体验直接起飞 还在觉得 DeepSeek V4 不如国外模型? 醒醒,2026 年了。DeepSeek V4 系列在代码能力上已经卷到让人窒息——而且价格只有 Claude 官方的零头。 但问题来了&…...

PIC24F Curiosity开发板实战:从MCC配置到低功耗设计
1. 项目概述与核心价值最近在做一个需要兼顾低功耗和实时控制的小型嵌入式项目,选型时又一次把目光投向了Microchip的PIC24F系列MCU。说实话,对于很多从8位机过渡过来的工程师,或者在校学生、创客爱好者来说,直接上手一款16位单片…...
)
ArcGIS Pro 3.x 批量处理遥感栅格:用Python脚本实现自动化转点、计算与导出(附完整代码)
ArcGIS Pro 3.x 遥感栅格自动化处理实战:从数据清洗到生产级流水线构建 遥感数据分析师常常需要处理TB级的时序栅格数据,比如月度NDVI指数、地表温度或降水分布。传统手动操作不仅效率低下,还容易因人为失误导致数据不一致。本文将分享如何基…...

Taotoken的用量分析与账单追溯功能让财务对账更轻松
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的用量分析与账单追溯功能让财务对账更轻松 对于依赖大模型API进行开发的企业或项目团队而言,成本核算与费用分…...