【DataLoom】智能问数 - 自然语言与数据库交互
探索DataLoom的智能问数功能:简化数据库查询
在数据驱动的决策制定中,数据库查询是获取洞察的关键步骤。但是,传统的数据库查询方法往往复杂且技术性强,这限制了非技术用户的使用。DataLoom的智能问数功能正是为了解决这一问题而设计的。本文将详细介绍这一功能,并展示其背后的代码实现。
DataLoom简介
DataLoom是一个创新的数据管理平台,旨在通过提供直观的界面和强大的后端处理能力,简化数据查询和分析过程。我们的目标是让数据查询变得简单,让每个人都能轻松地从数据中获取洞察。
智能问数功能


智能问数是DataLoom的核心功能之一,它允许用户通过自然语言输入查询请求,系统会自动将其转换为SQL语句并执行。这一功能极大地降低了技术门槛,使得即使是没有数据库背景的用户也能快速获取所需数据。
核心流程图

核心代码
ChatForSQLRequest类
@Data
public class ChatForSQLRequest {/*** 模型Id*/private Long chatId;/*** 询问的数据*/private String question;
}
这是一个简单的Java Bean类,用于封装用户请求智能问数时发送的数据。它包含两个属性:chatId(模型Id)和question(询问的数据)。
userChatForSQL方法
public void userChatForSQL(ChatForSQLRequest chatForSQLRequest, User loginUser) {Long chatId = chatForSQLRequest.getChatId();String question = chatForSQLRequest.getQuestion();// 1. 获取模型IDChat chat = chatService.getById(chatId);ThrowUtils.throwIf(chat == null, ErrorCode.PARAMS_ERROR, "不存在该助手");// 2. 获取数据源所有的元数据Long datasourceId = chat.getDatasourceId();List<AskAIWithDataTablesAndFieldsRequest> dataTablesAndFieldsRequests = getAskAIWithDataTablesAndFieldsRequests(loginUser, datasourceId);// 3. 构造请求AI的输入String input = buildAskAISQLInput(dataTablesAndFieldsRequests, question);// 4. 持久化消息ChatHistory user_q = new ChatHistory();user_q.setChatRole(ChatHistoryRoleEnum.USER.getValue());user_q.setChatId(chatId);user_q.setModelId(chat.getModelId());user_q.setContent(question);chatHistoryService.save(user_q);// 5. 利用webSocket发送消息通知开始AskSQLWebSocketMsgVO askSQLWebSocketMsgVO = new AskSQLWebSocketMsgVO();askSQLWebSocketMsgVO.setType("start");askSQLWebSocket.sendOneMessage(loginUser.getId(), askSQLWebSocketMsgVO);// 6. 询问AI,获取返回的SQLString sql = aiManager.doAskSQLWithKimi(input, LIMIT_RECORDS);// 7. 执行SQL,并得到返回的结果QueryAICustomSQLVO queryAICustomSQLVO = null;try {queryAICustomSQLVO = buildUserChatForSqlVO(datasourceId, sql);} catch (Exception e) { // 防止异常发生,前端还继续等待接收数据if (e instanceof SQLException) { // 记录异常queryAICustomSQLVO = new QueryAICustomSQLVO();queryAICustomSQLVO.setSql(sql);ChatHistory chatHistory = ChatHistory.builder().chatRole(ChatHistoryRoleEnum.MODEL.getValue()).chatId(chatId).modelId(chat.getModelId()).status(ChatHistoryStatusEnum.FAIL.getValue()).execMessage("查询异常").content(JSONUtil.toJsonStr(queryAICustomSQLVO)).build();chatHistoryService.updateById(chatHistory);}notifyMessageEnd(loginUser.getId());return;}// 8. 将查询的结果存放在数据库中ChatHistory chatHistory = new ChatHistory();chatHistory.setChatRole(ChatHistoryRoleEnum.MODEL.getValue());chatHistory.setChatId(chatId);chatHistory.setModelId(chat.getModelId());// 9. 存储结果类JSON字符串chatHistory.setContent(JSONUtil.toJsonStr(queryAICustomSQLVO));try {chatHistoryService.save(chatHistory);} catch (Exception e) {notifyMessageEnd(loginUser.getId());return;}// 10. 利用webSocket发送消息通知AskSQLWebSocketMsgVO res = AskSQLWebSocketMsgVO.builder().res(queryAICustomSQLVO.getRes()).columns(queryAICustomSQLVO.getColumns()).type("running").sql(sql).build();askSQLWebSocket.sendOneMessage(loginUser.getId(), res);// 11. 通知结束notifyMessageEnd(loginUser.getId());
}
这个方法是处理用户SQL查询请求的核心逻辑。它执行以下步骤:
- 验证模型ID是否存在。
- 获取数据源的所有元数据。
- 构造请求AI的输入。
- 持久化用户的消息。
- 通过WebSocket通知前端开始处理。
- 询问AI,获取返回的SQL语句。
- 执行SQL并获取结果。
- 将查询结果持久化。
- 存储结果类为JSON字符串。
- 通过WebSocket发送查询结果。
- 通知查询结束。
getAskAIWithDataTablesAndFieldsRequests方法
/*** 查询对应数据源所有元数据(表信息、表字段)* @param loginUser* @param datasourceId* @return*/
private List<AskAIWithDataTablesAndFieldsRequest> getAskAIWithDataTablesAndFieldsRequests(User loginUser, Long datasourceId) {List<CoreDatasetTable> tables = coreDatasourceService.getTablesByDatasourceId(datasourceId, loginUser);ThrowUtils.throwIf(tables.isEmpty(), ErrorCode.PARAMS_ERROR, "数据源暂无数据");List<AskAIWithDataTablesAndFieldsRequest> dataTablesAndFieldsRequests = new ArrayList<>();tables.forEach(table -> {// 查询所有字段LambdaQueryWrapper<CoreDatasetTableField> wrapper = new LambdaQueryWrapper<>();wrapper.eq(CoreDatasetTableField::getDatasetTableId, table.getId());List<CoreDatasetTableField> tableFields = coreDatasetTableFieldService.list(wrapper);AskAIWithDataTablesAndFieldsRequest askAIWithDataTablesAndFieldsRequest = AskAIWithDataTablesAndFieldsRequest.builder().tableId(table.getId()).tableComment(table.getName()).tableName(table.getTableName()).coreDatasetTableFieldList(tableFields).build();dataTablesAndFieldsRequests.add(askAIWithDataTablesAndFieldsRequest);});return dataTablesAndFieldsRequests;
}
这个方法用于查询给定数据源的所有表信息和表字段。它遍历所有表,为每个表查询字段信息,并构建一个包含这些信息的请求列表。
buildAskAISQLInput方法
/*** 构造智能问数的问题* @param dataTablesAndFieldsRequests 数据源元数据* @param question* @return* 示例:* 分析需求:%s,* [* {表名: %s, 表注释: %s, 字段列表:[{%s}、{%s}]}* {表名: %s, 表注释: %s, 字段列表:[{%s}、{%s}]}* ]*/
private String buildAskAISQLInput(List<AskAIWithDataTablesAndFieldsRequest> dataTablesAndFieldsRequests, String question) {StringBuilder res = new StringBuilder();// 1. 构造需求res.append(String.format(ANALYSIS_QUESTION, question));res.append(SPLIT);// 2. 构造表与字段信息StringBuilder tablesAndFields = new StringBuilder();dataTablesAndFieldsRequests.forEach(tableAndFields -> {// 构造当前表字段列表StringBuilder tableFieldsInfo = new StringBuilder();List<CoreDatasetTableField> fieldList = tableAndFields.getCoreDatasetTableFieldList();fieldList.forEach(field -> {tableFieldsInfo.append(String.format(FIELDS_INFO, field.getOriginName(), field.getName(), field.getType()));tableFieldsInfo.append(SPLIT);});// 构造当前表信息String tableFieldsInfoList = String.format(LIST_INFO, tableFieldsInfo);tablesAndFields.append(String.format(TABLE_INFO, tableAndFields.getTableName(), tableAndFields.getTableComment(), tableFieldsInfoList));tableFieldsInfo.append(SPLIT);});res.append(String.format(TABLES_AND_FIELDS_PART, tablesAndFields));return res.toString();
}
这个方法用于构造智能问数的问题。它将用户的问题和数据源的元数据结合起来,形成一个格式化的字符串,该字符串将作为AI的输入。
doAskSQLWithKimi方法
/*** 执行智能问数* @param message 构造的输入* @param limitSize select 结果限制的行数* @return*/
public String doAskSQLWithKimi(String message, int limitSize) {String SQLPrompt = "你是一个MySQL数据库专家,专门负责根据查询需求得出SQL查询语句,接下来我会按照以下固定格式给你提供内容: \n" +"分析需求:{分析需求或者目标} \n" +"所有的数据表元数据:[{数据库表名、表注释、数据库表的字段、注释以及类型}] \n" +"请根据这两部分内容,按照以下指定格式生成内容(此外不要输出任何多余的开头、结尾、注释),并且只生成Select语句!!!, 请严格按照数据表元数据中存在的数据表和字段,不要查询不存在的表和字段\n" +"要求select的结果不超过" + limitSize + "行";List<Message> messages = CollUtil.newArrayList(new Message(RoleEnum.system.name(), SQLPrompt),new Message(RoleEnum.user.name(), message));return moonshotAiClient.chat("moonshot-v1-32k",messages);
}
这个方法用于执行智能问数。它构造一个包含分析需求和数据表元数据的消息,然后通过调用AI客户端来获取SQL查询语句。
buildUserChatForSqlVO方法
/*** 执行SQL并封装智能问数返回类* @param datasourceId 数据源id* @param sql 执行sql* @return 智能问数返回类*/
private QueryAICustomSQLVO buildUserChatForSqlVO(Long datasourceId, String sql) throws SQLException {return datasourceEngine.execSelectSqlToQueryAICustomSQLVO(datasourceId, sql);
}
这个方法用于执行SQL语句并将结果封装到QueryAICustomSQLVO对象中。它调用execSelectSqlToQueryAICustomSQLVO方法,传入数据源ID和SQL语句,然后返回查询结果。
execSelectSqlToQueryAICustomSQLVO方法
/*** 执行SQL语句并将列集合和记录犯规* @param datasourceId 数据源id* @param sql sql语句* @param parameters 参数* @return*/
public QueryAICustomSQLVO execSelectSqlToQueryAICustomSQLVO(Long datasourceId, String sql, Object... parameters) throws SQLException {int dsIndex = (int) (datasourceId % (dataSourceMap.size()));// 获取对应连接池DataSource dataSource = dataSourceMap.get(dsIndex);QueryAICustomSQLVO queryAICustomSQLVO = new QueryAICustomSQLVO();// 所有列List<String> columns = new ArrayList<>();// 所有结果List<Map<String, Object>> res = new ArrayList<>();Connection connection = dataSource.getConnection();PreparedStatement preparedStatement = connection.prepareStatement(sql);// Set parameters to prevent SQL injectionfor (int i = 0; i < parameters.length; i++) {preparedStatement.setObject(i + 1, parameters[i]);}ResultSet rs = preparedStatement.executeQuery();// Execute the query or update// 处理查询结果ResultSetMetaData rsmd = rs.getMetaData();int columnCount = rsmd.getColumnCount();for (int i = 1; i <= columnCount; i++) {columns.add(rsmd.getColumnName(i));}while (rs.next()) {Map<String, Object> resMap = new HashMap<>();for (int i = 1; i <= columnCount; i++) {resMap.put(rsmd.getColumnName(i), rs.getString(i));}res.add(resMap);}queryAICustomSQLVO.setSql(sql);queryAICustomSQLVO.setColumns(columns);queryAICustomSQLVO.setRes(res);return queryAICustomSQLVO;
}
这个方法用于执行SQL查询并将结果集转换为一个包含列名和记录的QueryAICustomSQLVO对象。它使用PreparedStatement来设置参数,执行查询,并遍历结果集,将每一行的数据存储到一个Map中,然后将这些Map添加到结果列表中。
这些代码片段共同构成了DataLoom智能问数功能的核心实现。每个片段都扮演着处理用户请求、与数据库交互、以及与AI服务通信的重要角色。
未来展望
我们对DataLoom的未来充满期待。我们计划引入更多的智能功能,这些功能将在下面的几篇文章中介绍,例如智能仪表盘,智能图表分析报告等
项目快速启动
- 见GitHub:DataLoom 仓库
- 见Gitee地址:Gitee 仓库
如何贡献
如果你对 DataLoom 感兴趣并想做出贡献,欢迎提交 issue 或 Pull Request。我们非常欢迎开发者一起加入,共同改进这个项目。
- GitHub 地址:DataLoom 仓库
- Gitee地址:Gitee 仓库
- 你可以通过创建 Issue 来报告问题,或通过提交 PR 来贡献代码。
希望这篇文章能够激发你对 DataLoom 项目的兴趣!如果你喜欢这个项目,请给我们一个 Star ⭐️,这对我们来说意义重大!
请持续关注,后续文章也会发一些有关项目功能设计亮点介绍
项目地址:DataLoom GitHub 仓库
项目问题通过下面的联系方式进行沟通
邮箱:hardork@163.com
WX号: _hardork如果需要项目文档📄,可以联系WX号
相关文章:
【DataLoom】智能问数 - 自然语言与数据库交互
探索DataLoom的智能问数功能:简化数据库查询 在数据驱动的决策制定中,数据库查询是获取洞察的关键步骤。但是,传统的数据库查询方法往往复杂且技术性强,这限制了非技术用户的使用。DataLoom的智能问数功能正是为了解决这一问题而…...

【Linux】进程地址空间(初步了解)
文章目录 1. 奇怪的现象2. 虚拟地址空间3. 关于页表4. 为什么要有虚拟地址 1. 奇怪的现象 我们先看一个现象: 为什么父子进程从“同一块地址中”读取到的值不一样呢? 因为这个地址不是物理内存的地址 ,如果是物理内存的地址是绝对不可能出…...

hdu-6024
hdu-6024 struct node {int x, c;bool operator<(const node &a) const{return x < a.x;} }; // dp[i][0]为到第i个教室且第i个教室不建糖果店的花费前缀和,dp[i][1]为到第i个教室且第i个教室建糖果店的花费前缀和 int dp[N][2]; void solve() {int n;wh…...

jmeter操作数据库
jmeter操作数据库 一、打开数据库 二、jmeter下载驱动,安装jdbc驱动 1、下载好的驱动包 2、将驱动包复制粘贴 存放在包的路径下 (1)jdk下面 a、路径:jdk1\jre\lib b、jdk1\jre\lib\ext (2)jmeter下 a、…...

Stable Diffusion绘画 | 如何做到不同动作表情,人物角色保持一致性(上篇)
由于 SD 具有强大的可控性,在固定人物角色方面,SD 是远超 MJ 的, 其中最好用,也是最优先的方法就是训练一个自己专属的角色模型,例如之前使用秋叶训练器得到的 LoRA模型。 另外,如果不想自己训练模型的话…...

中国计量大学《2023年801+2023年819自动控制原理真题》 (完整版)
本文内容,全部选自自动化考研联盟的:《中国计量大学801819自控考研资料》的真题篇。后续会持续更新更多学校,更多年份的真题,记得关注哦~ 目录 2023年801真题 2023年819真题 Part1:2023年完整版真题 2023年801真题…...

本地运行LLama 3.2的三种方法
大型语言模型(LLMs)已经彻底改变了AI领域,小型模型也在崛起。因此,即使是在旧的PC和智能手机上运行先进的LLMs也成为了可能。为了给大家一个起点,我们将探索三种不同的方法来本地与LLama 3.2进行交互。 先决条件 在我…...
基于单片机的温度和烟雾检测
目录 一、主要功能 二、硬件资源 三、程序编程 四、实现现象 一、主要功能 基于51单片机,采用DS18B20读取温度,滑动变阻器链接ADC0832数模转换模拟烟雾, 通过lcd1602显示屏显示, 超过阈值则对应的led灯亮起,蜂鸣器…...

利士策分享,探寻中华民族的精神纽带
利士策分享,探寻中华民族的精神纽带 在历史的长河中,中华民族以其独特的文化魅力和坚韧不拔的民族精神,屹立于世界民族之林。 这份力量,源自何处?或许,正是那份纯真的情,如同纽带一般ÿ…...

JAVA思维提升案例3
需求: 某系统的数字密码是一个四位数,如1983,为了安全,需要加密后再传输,加密规则是:对密码中的每位数,都加5 ,再对10求余,最后将所有数字顺序反转,得到一串加密后的新数…...

vscode配置golang
1.安装golang解释器 从网址https://go.dev/dl/下载对应的golang解释器 2.配置环境 Extensions中搜索安装go 2.配置settings.json {"go.autocompleteUnimportedPackages": true,"go.gocodeAutoBuild": false,"explorer.confirmPasteNative"…...

设计模式之原型模式(通俗易懂--代码辅助理解【Java版】)
文章目录 设计模式概述1、原型模式2、原型模式的使用场景3、优点4、缺点5、主要角色6、代码示例7、总结题外话关于使用序列化实现深拷贝 设计模式概述 创建型模式:工厂方法、抽象方法、建造者、原型、单例。 结构型模式有:适配器、桥接、组合、装饰器、…...

Study-Oracle-10-ORALCE19C-RAC集群维护
一路走来,所有遇到的人,帮助过我的、伤害过我的都是朋友,没有一个是敌人。 一、RAC的逻辑架构与进程 1、RAC 与单实例进程的对比 2、RAC相关进程功能 3、在主机查看RAC进程 其他的不列举了 4、RAC集群启停命令 检查集群状态 ORACLE 19C …...

【无题】夜入伊人笑愉,泪湿心夜难眠。
在这句诗中,意境描绘了一种深沉的情感体验,充满了温柔与哀愁。诗人通过“夜入伊人笑愉”开启了一段梦境之旅,其中“夜入”象征着进入梦境的状态。在这个梦幻的世界里,诗人与心爱的人欢笑嬉戏,那份快乐和亲昵如同真实的…...

docker下载mysql时出现Unable to pull mysql:latest (HTTP code 500) server error 问题
报错 Unable to pull mysql:latest (HTTP code 500) server error - Get “https://registry-1.docker.io/v2/”: EOF 解决方法 将VPN开到Global模式 解决啦...
厦门网站设计的用户体验优化策略
厦门网站设计的用户体验优化策略 在信息化快速发展的今天,网站作为企业与用户沟通的重要桥梁,用户体验(UX)的优化显得尤为重要。尤其是在交通便利、旅游资源丰富的厦门,吸引了大量企业进驻。在这样竞争激烈的环境中&am…...
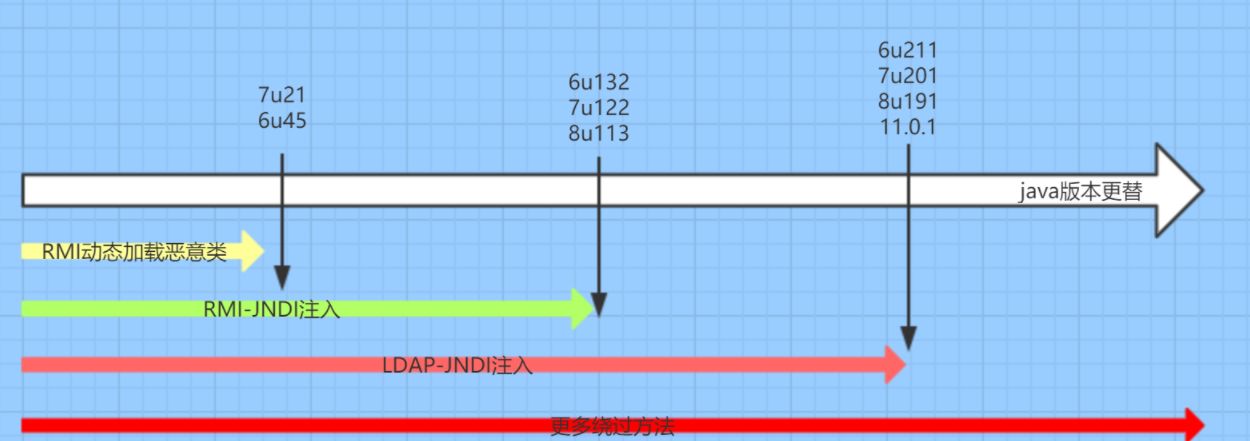
Fastjson反序列化
Fastjson反序列化一共有三条利用链 TempLatesImpl:实战中不适用JdbcRowSetImpl:实际运用中较为广泛BasicDataSource(BCEL) 反序列化核心 反序列化是通过字符串或字节流,利用Java的反射机制重构一个对象。主要有两种…...

Python Linux解压安装脚本
本脚本用于安装python3.x, 需要指定python版本,如12代表3.12 安装文件下载自 python-build-standalone 我下载的文件后缀是:-x86_64-unknown-linux-gnu-pgo-full.tar.zst,根据需要自行下载 注意:install_only或tar.gz包的目录没有…...

numpy 逻辑运算方法介绍
在 NumPy 中,逻辑运算方法用于对数组中的元素进行逻辑操作,通常用于布尔数组,也可用于数值数组,非零值视为 True,零值视为 False。常见的逻辑运算方法有: 1. numpy.logical_and 逐元素进行逻辑与运算&…...

怎么查看网站是否被谷歌收录,查看网站是否被谷歌收录的简便方法
查看网站是否被谷歌收录,有多种简便方法可供选择。以下是一些常用的简便方法: 一、使用“site:”指令 打开谷歌搜索引擎: 在浏览器中打开Google.com,确保使用的是谷歌的官方搜索引擎。 输入查询指令: 在搜索框中输…...

程序员职业生涯系列:关于技术能力的思考与总结
工作几十年,我面试过几百个程序员,带过十几个团队,自己也从一个写CRUD都费劲的菜鸟成长为架构师。回头看,最让我困惑过的一个问题是:什么才是真正的技术能力? 是LeetCode刷到300题?是把某个框架源码啃得烂熟?是写过多少个高并发项目?还是那张挂在墙上的高级职称证书?…...

CAD专业看图师手机版安装使用教程
CAD专业看图师是一款专注于DWG/DXF图纸快速查看、精准测量、现场标注的手机端工具,适配建筑、机械、工程等场景,支持天正图纸、图层管理、PDF导出,适合工地/外勤快速核对图纸。以下是完整安装与使用指南。 一、安装前准备 1. 系统与格式要求…...

独立开发者如何借助Taotoken管理多个AI侧项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken管理多个AI侧项目 作为一名独立开发者,同时维护多个使用大模型的小型项目是常态。你可能有…...

猫抓插件:浏览器资源嗅探与下载的完整手册
猫抓插件:浏览器资源嗅探与下载的完整手册 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-catch)是一…...

探索罗技鼠标宏:掌握PUBG压枪技术的完整路径
探索罗技鼠标宏:掌握PUBG压枪技术的完整路径 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在《绝地求生》这款竞技性极强的射击游戏…...

为什么你做的RAG总是翻车?三个坑让你怀疑人生
电梯里同事突然问:"你觉得RAG落地最难的地方在哪?"我愣了5秒,保安在旁边接话:“我以前干过,主要就文档预处理、召回质量、生成忠实度。” 一、真实场景里的RAG,和你想象的完全不一样 大模型的八…...
)
理光MP C2500扫描到共享文件夹保姆级教程(附Windows 10/11权限避坑指南)
理光MP C2500扫描到共享文件夹全流程解决方案与Windows权限深度优化 办公室里那台老当益壮的理光MP C2500复合机,至今仍是许多中小企业的生产力主力。但当IT管理员尝试配置"扫描到共享文件夹"功能时,往往会遭遇浏览网络空白、权限拒绝等"…...

联想笔记本BIOS隐藏设置终极解锁指南:3步开启高级功能
联想笔记本BIOS隐藏设置终极解锁指南:3步开启高级功能 【免费下载链接】LEGION_Y7000Series_Insyde_Advanced_Settings_Tools 支持一键修改 Insyde BIOS 隐藏选项的小工具,例如关闭CFG LOCK、修改DVMT等等 项目地址: https://gitcode.com/gh_mirrors/l…...
)
别再为Gurobi学术许可发愁了!手把手教你从申请到激活(附学信网报告攻略)
Gurobi学术许可全流程实战指南:从申请到Python集成 第一次接触Gurobi优化求解器时,我被它强大的性能所吸引,但随即陷入了学术许可申请的迷茫中。和许多研究生同学一样,我在学信网报告下载、邮件沟通、命令行激活等环节屡屡碰壁。本…...

告别VirtualBox的‘不是Host-Only适配器’错误:一个网络配置的深度修复指南
VirtualBox Host-Only网络故障全解析:从原理到实战修复 当你正准备启动VirtualBox中的开发环境虚拟机时,突然弹出的红色错误提示框让所有工作戛然而止——"Interface is not a Host-Only Adapter"。这个看似简单的网络适配器错误背后…...