c++ atomic
文章目录
- why atomic?
- sequentially consistent atomic
- Relaxed memory models
why atomic?
当我们有一片内存空间S,线程A正在往S里写数据,这个时候线程B突然往S中做了++操作,导致线程A的操作结果变得不可预知(对线程A来说),这种情况换句话说叫做data race,我们一般的操作时上锁,在c++中有多种类型的锁比如std::mutex,std::shared_mutex(c++ 17),
std::mutex的性能要比std::shared_mutex低,因为std::shared_mutex上锁后其他线程可以照样可以访问被lock住的空间(只可以读原数据),而一旦线程对一块内存区域上std::mutex锁后,其他的线程无论读还是写都不会成功
mutext使用如下
#include <iostream>
#include <mutex>
#include <thread>class A{public:A() = default;~A() = default;void add_element(int num);static int element;
private:std::mutex m;};int A::element = 0;void A::add_element(int num){m.lock();std::cout << "thread " << std::this_thread::get_id() << " add " << num << std::endl;element = element + num;m.unlock();
}int main(){A a;std::thread worker[5];for(int i = 0; i < 5; i++){worker[i] = std::thread(&A::add_element, std::addressof(a), i);worker[i].join();}}
注意!
如果std::thread()添加的函数对象在class外部,且调用std::thread()的函数也不属于任何一个class,那么就直接调用,std::thread()第二个参数佳被调用函数的第一个参数
如果std::thread()添加的函数对象在class内部(class 内部非静态函数如我们上面的例子所示),他要除了要将函数的全部名称(包含class名字)写上去,还要指定我们这个class对象的位子,这样才能寻址到指定的函数,std::thread()第三个就是该被注册函数的第一个参数
如果std::thread()位于某个class内部,且注册的函数也位于这个class内部我们和上面一样需要指定这个class的起使位子(this在std::thread()的第二个参数中)
shared_mutext使用如下
#include <iostream>
#include <shared_mutex>
#include <thread>class A{public:A() = default;~A() = default;void add_element(int num);void get_element();static int element;
private:std::shared_mutex m;};int A::element = 0;void A::add_element(int num){//for set lockm.lock();element = element + num;m.unlock();
}void A::get_element(){//for read lockm.lock_shared();std::cout << "thread " << std::this_thread::get_id() << " get element "<< element << std::endl;m.unlock_shared();
}int main(){A a;std::thread worker[5];for(int i = 0; i < 5; i++){worker[i] = std::thread(&A::add_element, std::addressof(a), i);worker[i].join();worker[i] = std::thread(&A::get_element, std::addressof(a));worker[i].join();}}
现在回归正题,为什么我们要使用atomic而不是锁?首先我们在用atomic的时候发现系统明显的慢,并且我们的锁颗粒已经小到极致,那么为了再进一步的提升性能我们只能使用atomic
首先锁的一些操作都是操作系统提供,比如win,linux,但是atomic是我们处理器提供的,锁机制其实是将被lock住的线程挂起,空出cpu资源给其他的线程,但是这有明显的inter pross的线程上下文切换(被锁住的线程在不断地尝试直到成功强到锁(也叫做busy wait))我们使用锁的时候还要考虑死锁等情况发生(当然c++中有lock_guardclass将一个锁包住当lock_guardclass对象被销毁自动的unlock)
而我们的atomic就简单的多,只需要将容易发生race的那个变量置为atomic即可
#include <iostream>
#include <shared_mutex>
#include <thread>
#include <chrono>
#include <atomic>class A{public:A() = default;~A() = default;void add_element(int num);void get_element();static std::atomic<int> element;
private://std::shared_mutex m;};std::atomic<int> A::element{0};void A::add_element(int num){//for set lock//m.lock();element = element + num;//m.unlock();
}void A::get_element(){//for read lock//m.lock_shared();std::cout << "thread " << std::this_thread::get_id() << " get element "<< element << std::endl;//m.unlock_shared();
}int main(){A a;std::vector<std::thread> worker;for(int i = 0; i < 5; i++){worker.push_back(std::thread(&A::add_element, std::addressof(a), i));}for(int i = 5; i < 10; i++){worker.push_back(std::thread(&A::get_element, std::addressof(a)));}for(auto& currth : worker){currth.join();}return 0;
}
atomic 在C++标准中并没有说明他是lock-free的,有的平台他是lock-free,有的平台他是用mutex实现,所以C++提供了一个method去验证你的这个平台上atomic 是否是lock-free
bool std::atomic::is_lock_free()
Lock-free usually applies to data structures shared between multiple threads, where the synchronisation mechanism is not mutual exclusion; the intention is that all threads should keep making some kind of progress instead of sleeping on a mutex.
sequentially consistent atomic
首先如果使用了atomic<T>,那么C++是可以保证sequentially consistent atomic特性的
什么是sequentially consistent atomic?他所保证的特性如下
- 所有线程的operation中load和store操作是对所有其他线程可见的
- 必须要遵从(源码)顺序执行
比如我们有2个thread,A和B,其中A执行如下2个操作
thread A
x.store(1);
reg1 = y.load();
线程B执行以下2个操作
thread B
y.store(2);
reg2 = x.load();
假设上述的2个线程的操作遵循sequentially consistent atomic,那么他们的load和store指令是相互可见的(满足条件1),并且每个线程执行atomic operate的顺序严格按照上述伪代码(满足条件2,对于线程A x.store在前y.load在后,对于线程B y.store在前,x.load在这些顺序不能变),那么他们的执行顺序有6种可能
A:x.store(1)--->B:y.store(2)--->A:reg1=y.load()--->B:reg2=x.load()
A:x.store(1)--->B:y.store(2) -->B:reg2=x.load() -->A:reg1=y.load()
A:x.store(1)--->A:reg1=y.load()-->B:y.store(2)-->B:reg2=x.load()
B:y.store(2)--->A:x.store(1)-->A:reg1=y.load()--->B:reg2=x.load()
B:y.store(2)--->A:x.store(1)-->B:reg2=x.load()-->A:reg1=y.load()
B:y.store(2)--->B:reg2=x.load()--->A:x.store(1)-->A:reg1=y.load()
再比如我们2个线程1和2执行下面的指令
线程1指令
x.store(2)
x.load()
线程2指令
x.store(3)
因为load指令是对所有其他线程可见,所以线程1可以看到自己的load指令也可以看到线程2的load指令(限制1),那么执行顺序有3种如下(假设x初始化为1)
1:x.store(2)--->2:x.store(3)--->1:x.load() 结果X=5
2:x.store(3)--->1:x.store(2)--->1:x.load() 结果X=5
1:x.store(2)--->1:x.load()--->2:x.store(3) 结果X=2
2:x.store(3)--->1:x.load()--->1:x.store(2) 结果X=3
上述的顺序永远不会出现,因为1:x.load()不能出现在1:x.store(2)之前,否则违反规则2(代码中规定了执行顺序)
此时你也许会问这有啥用,要知道c++原子操作只会在操作atomic< T > A 的时候是原子的,如下代码
#include <iostream>
#include <thread>
#include <atomic>class A{public:A() = default;~A() = default;void for_thread_1();void for_thread_2();void for_thread_3();static std::atomic<int> element;
private:};std::atomic<int> A::element{0};void A::for_thread_1(){element = element + 2;std::cout << "for thread 1 element is " << element << std::endl;
}void A::for_thread_2(){element = element + 3;//std::cout << "for thread 2 element is " << element << std::endl;
}int main(){A a;std::thread worker[3];worker[0] = std::thread(&A::for_thread_1, std::addressof(a));worker[1] = std::thread(&A::for_thread_2, std::addressof(a));worker[0].join();worker[1].join();如果说我们想要线程1强制在线程2之后执行(结果为5),也就是下面这个顺序
2:x.store(3)--->1:x.store(2)--->1:x.load() 结果X=5
可以这样写
#include <iostream>
#include <thread>
#include <atomic>class A{public:A() = default;~A() = default;void for_thread_1();void for_thread_2();void for_thread_3();static std::atomic<int> element;
private:};std::atomic<int> A::element{0};void A::for_thread_1(){while(element == 0) continue;element = element + 2;std::cout << "for thread 1 element is " << element << std::endl;
}void A::for_thread_2(){element = element + 3;//std::cout << "for thread 2 element is " << element << std::endl;
}int main(){A a;std::thread worker[3];worker[0] = std::thread(&A::for_thread_1, std::addressof(a));worker[1] = std::thread(&A::for_thread_2, std::addressof(a));worker[0].join();worker[1].join();return 0;
}
注意c++原子操作一定是在对原子对象操作一瞬间是原子的,比如上述例子中线程1和线程2中每一个对原子对象
element操作的句子
也许你还会疑问,以为线程1对element操作的2个语句是一个原子操作,其实这是2个原子操作分别是store和load,我们c++ atomic如果不做特殊的设置默认Sequential consistency
Sequential consistency也是分布式领域大牛2013年图灵奖获得者,强分布式一致性协议paxos的发明者 Leslie Lamport发明的
Relaxed memory models
TODO
相关文章:

c++ atomic
文章目录why atomic?sequentially consistent atomicRelaxed memory modelswhy atomic? 当我们有一片内存空间S,线程A正在往S里写数据,这个时候线程B突然往S中做了操作,导致线程A的操作结果变得不可预知(对线程A来说),这种情况换句话说叫做data race,我们一般的操作时上锁,在…...
要想孩子写作文没烦恼?建议家长这样做
说起语文学习,就不得不提作文。作为语文学习中的重中之重,作文写作一直是压在学生和家长身上的一块“心头大石”。发现很多孩子在写作文时,往往存在四大问题:写不出、不生动、流水账、太空洞。如今,孩子怕写作文&#…...
基于Python的高光谱图像分析教程
1、前言超光谱图像 (HSI) 分析因其在从农业到监控的各个领域的应用而成为人工智能 (AI) 研究的前沿领域之一。 该领域正在发表许多研究论文,这使它变得更加有趣! 和“对于初学者来说,在 HSI 上开始模式识别和机器学习是相当麻烦的”ÿ…...

【图神经网络】从0到1使用PyG手把手创建异构图
从0到1用PyG创建异构图异构图创建异构图电影评分数据集MovieLens建立二分图数据集转换为可训练的数据集建立异构图神经网络以OGB数据集为例HeteroData中常用的函数将简单图神经网络转换为异质图神经网络GraphGym的使用PyG中常用的卷积层参考资料在现实中需要对 多种类型的节点以…...
2023美赛春季赛思路分析汇总
将在本帖更新汇总2023美赛春季赛两个赛题思路,大家可以点赞收藏! 2023美赛春季赛各赛题全部解题参考思路资料模型代码等全部实时更新!第一时间获取全部美赛春季赛相关资料! 目前思路整理仅为部分,请大家耐心等待&…...
GPT4国内镜像站
GPT-4介绍GPT-4是OpenAI发布的最先进的大型语言模型,是ChatGPT模型的超级进化版本。与ChatGPT相比,GPT-4的推理能力、复杂问题的理解能力、写代码能力得到了极大的强化,是当前人工智能领域,最有希望实现通用人工智能的大模型。但G…...

代码随想录算法训练营第四十八天| 198 打家劫舍 213 打家劫舍II 337 打家劫舍III
代码随想录算法训练营第四十八天| 198 打家劫舍 213 打家劫舍II 337 打家劫舍III LeetCode 198 打家劫舍 题目: 198.打家劫舍 动规五部曲: 确定dp数组以及下标的含义 dp[i]:考虑下标i(包括i)以内的房屋,最多可以偷…...
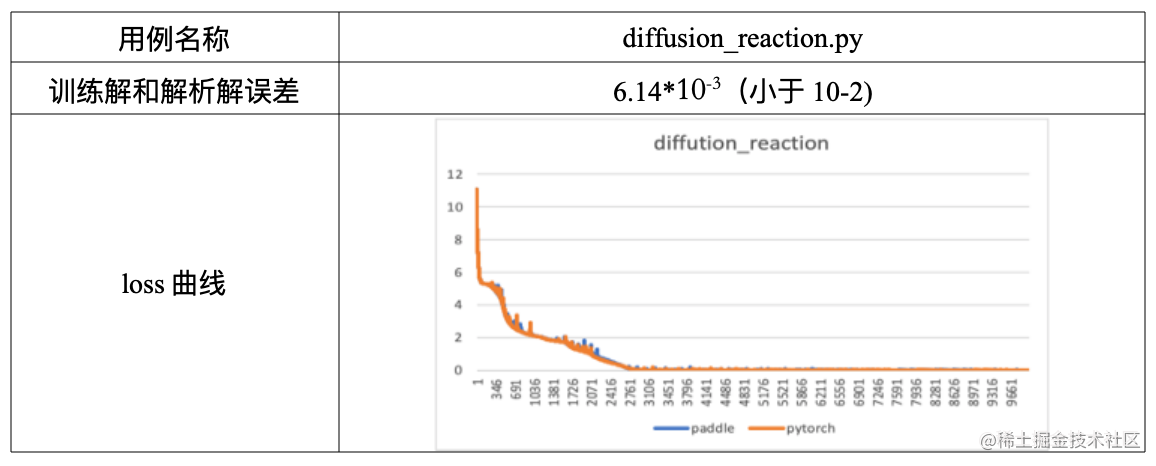
飞桨DeepXDE用例验证及评估
在之前发布的文章中,我们介绍了飞桨全量支持业内优秀科学计算深度学习工具 DeepXDE。本期主要介绍基于飞桨动态图模式对 DeepXDE 中 PINN 方法用例实现、验证及评估的具体流程,同时提供典型环节的代码,旨在帮助大家更加高效地基于飞桨框架进行…...

telegram连接本地Proxy连接不上
1.ClashX开启允许局域网连接。 2.重启ClashX和Telegram...
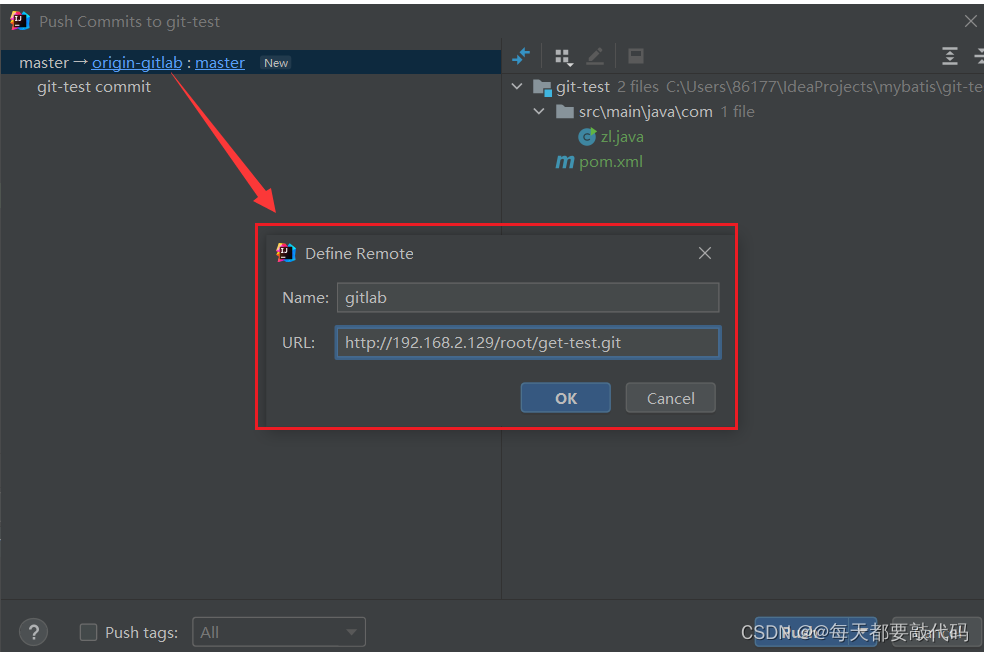
【分布式版本控制系统Git】| 国内代码托管中心-Gitee、自建代码托管平台-GitLab
目录 一:国内代码托管中心-码云 1. 码云创建远程库 2. IDEA 集成码云 3. 码云复制 GitHub 项目 二:自建代码托管平台-GitLab 1. GitLab 安装 2. IDEA 集成 GitLab 一:国内代码托管中心-码云 众所周知,GitHub 服务器在国外&…...
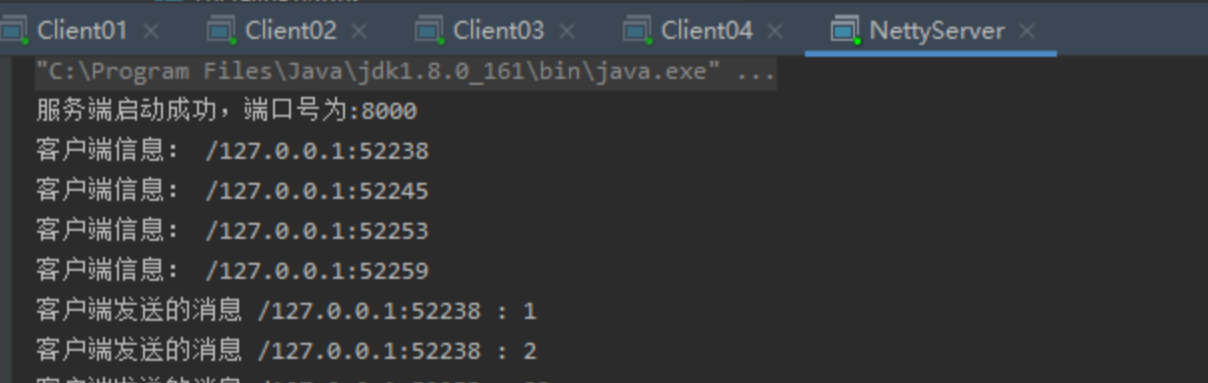
【面试】BIO、NIO、AIO面试题
文章目录什么是IO在了解不同的IO之前先了解:同步与异步,阻塞与非阻塞的区别什么是BIO什么是NIO什么是AIO什么NettyBIO和NIO、AIO的区别IO流的分类按照读写的单位大小来分:按照实际IO操作来分:按照读写时是否直接与硬盘,…...

C语言实现拼图求解
题目: 有如下的八种拼图块,每块都是由八块小正方块构成, 这些拼图块刚好可以某种方式拼合放入给定的目标形状, 请以C或C++编程,自动求解 一种拼图方式 目标拼图: 本栏目适合想要深入了解无向图、深度优先算法、编程语句如何实现算法、想要去接拼图算法的小伙伴。...

python --获取本机屏幕分辨率
pywin32 方法一 使用 win32api.GetDeviceCaps() 方法来获取显示器的分辨率。 使用 win32api.GetDC() 方法获取整个屏幕的设备上下文句柄,然后使用 win32api.GetDeviceCaps() 方法获取水平和垂直方向的分辨率。最后需要调用 win32api.ReleaseDC() 方法释放设备上下…...
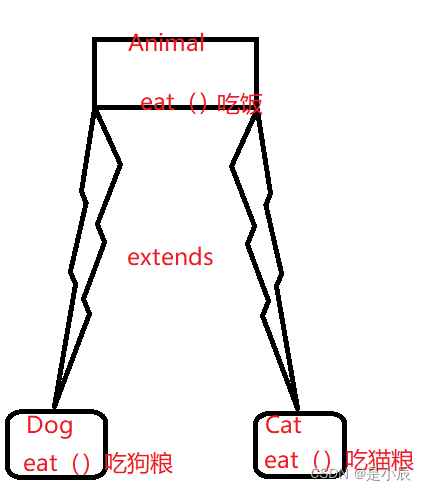
Java多态
目录 1.多态是什么? 2.多态的条件 3.重写 3.1重写的概念 3.2重写的作用 3.3重写的规则 4.向上转型与向下转型 4.1向上转型 4.2向下转型 5.多态的优缺点 5.1 优点 5.2 缺点 面向对象程序三大特性:封装、继承、多态。 1.多态是什么࿱…...

绝对路径和相对路径
1.绝对路径:从根目录为起点到某一个目录的路径 使用计算机时要找到需要的文件就必须知道文件的位置,表示文件的位置的方式就是路径,例如只要看到这个路径:c:/website/img/photo.jpg我们就知道photo.jpg文件是在c盘的website目录下…...

Linux第二次总结
Linux阶段总结 OSI模型:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层 路由器的工作原理:最佳路径选择 三次握手四次挥手:... shell是翻译官把人类语言翻译成二进制语言 Tab作用:自动补齐、确认输入是否有误 …...
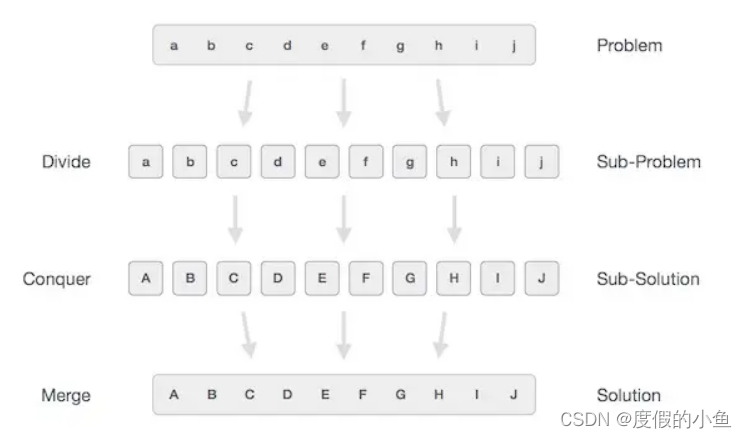
算法:贪婪算法、分而治之
算法:贪婪算法、分而治之 文章目录1.贪婪算法计数硬币实例12.分而治之分割/歇征服/解决合并/合并实例23.动态规划对照实例34.基本概念算法数据定义数据对象内置数据类型派生数据类型基本操作1.贪婪算法 设计算法以实现给定问题的最佳解决方案。在贪婪算法方法中&am…...

462. 最小操作次数使数组元素相等 II——【Leetcode每日一题】
462. 最小操作次数使数组元素相等 II 给你一个长度为 n 的整数数组 nums ,返回使所有数组元素相等需要的最小操作数。 在一次操作中,你可以使数组中的一个元素加 1 或者减 1 。 示例 1: 输入:nums [1,2,3] 输出:2 …...

对数据库的库及表的操作
全篇在MySQL操作下完成 在此之前,先介绍一下,字段、列类型及属性。 一、什么是字段、列类型、属性 (1)字段,一张表中列的名称;列类型,该列存储数据的类型;属性,描述列类型的特征。 …...

final类又没实现接口应该用哪一种代理, jdk动态代理还是cglib代理
jdk动态代理还是cglib代理🧙jdk动态代理和cglib代理的示例JDK动态代理原理CGLIB代理final类又没实现接口应该用哪一种代理, jdk动态代理还是cglib代理滚滚长江东逝水,浪花淘尽英雄。——唐代杨炯《临江仙》 jdk动态代理和cglib代理的示例 以下是一个使用…...
)
乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓)
更多请点击: https://intelliparadigm.com 第一章:乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓) ElevenLabs 官方文档中仅标注 ur 为乌尔…...

AI编程助手安全规则实战:从SQL注入防御到团队安全基线构建
1. 项目概述:当AI编程助手遇上安全红线最近在GitHub上看到一个挺有意思的项目,叫“cursor-security-rules”。光看名字,你大概能猜到它和Cursor这个AI编程工具有关,而且重点是“安全规则”。没错,这个项目本质上是一个…...

ComfyUI-Manager终极指南:3步掌握AI绘画插件管理技巧
ComfyUI-Manager终极指南:3步掌握AI绘画插件管理技巧 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custom…...

数据质量保证:确保数据准确性和可靠性
数据质量保证:确保数据准确性和可靠性 一、数据质量保证概述 1.1 数据质量保证的定义 数据质量保证是指通过一系列技术和流程,确保数据的准确性、完整性、一致性和及时性的过程。它涉及数据采集、存储、处理和使用的各个环节,确保数据符合业务…...

桌面CNC木质游戏手柄外壳制作:从Fusion 360设计到实战加工全流程
1. 项目概述:从数字模型到木质手柄的旅程如果你和我一样,既痴迷于复古游戏的怀旧情怀,又享受亲手将数字设计变为实体物件的成就感,那么这个项目绝对能点燃你的热情。我们这次要做的,不是一个简单的3D打印外壳ÿ…...

AI Agent无障碍审查:自动化集成WCAG标准与axe-core实践
1. 项目概述:一个为AI助手打造的“无障碍”审查官最近在折腾AI应用开发,特别是那些能自动处理任务的智能体(AI Agent),发现一个挺有意思但容易被忽略的问题:我们费尽心思让AI能写代码、分析数据、生成报告&…...
:为什么它突然支持Nastaliq音素映射?)
ElevenLabs乌尔都语语音合成精度实测报告(WER 8.2% vs 行业均值19.6%):为什么它突然支持Nastaliq音素映射?
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs乌尔都语语音合成精度实测报告(WER 8.2% vs 行业均值19.6%):为什么它突然支持Nastaliq音素映射? ElevenLabs于2024年Q2悄然上线乌尔都语&#…...
)
【实用小程序】超轻量级文件上传下载中心 (File Download Server)
站内源码及jar包下载 一、项目概述 文件下载中心一个基于 Java 内置 HTTP 服务器(com.sun.net.httpserver)构建的轻量级文件管理服务。它零第三方依赖,单 JAR 包即可运行,适合在内网环境或临时场景中快速搭建文件共享站点。 你的团队需要临时共享一批日志文件或交付物,…...

手工打造柔性LED眼罩:从SMD焊接入门到可穿戴电路实践
1. 项目概述:从零打造你的赛博格之眼如果你和我一样,对《银翼杀手》里那些闪烁着冷光的义眼,或是赛博朋克美学中标志性的发光装饰着迷,那么亲手制作一个属于自己的LED眼罩,绝对是一次令人兴奋的旅程。这不仅仅是一个酷…...

SuperMap Objects开发避坑指南:从COM引用到内存释放的实战经验总结
SuperMap Objects开发避坑指南:从COM引用到内存释放的实战经验总结 在GIS二次开发领域,SuperMap Objects以其强大的空间数据处理能力备受开发者青睐。然而,当我们将这个COM组件集成到C# WinForms项目中时,往往会遇到一些官方文档…...