爬虫——XPath基本用法
第一章XML
一、xml简介
1.什么是XML?
1,XML指可扩展标记语言
2,XML是一种标记语言,类似于HTML
3,XML的设计宗旨是传输数据,而非显示数据
4,XML标签需要我们自己自定义
5,XML被设计为具有自我描述性
2.XML和HTML的区别?
1,XML被设计为传输和存储数据,其焦点是数据的内容
2,HTML是显示数据以及如何更好的显示数据
3.XML文档示例
<?xml version="1.0" encoding="utf-8"?><bookstore><book category="cooking"><title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price></book> <book category="children"><title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price></book> <book category="web"><title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price></book><book category="web" cover="paperback"><title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price></book></bookstore>注意:这上面的标签都是自定义的
二、XML的节点关系
1.父(parent)
每个元素及属性都有一个父
下面这个XML例子中,book元是title,author,year,price元素的父
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
2.子(children)
元素节点可能有零个,一个或者多个子
在下面的例子中 title,author,year,price都是book元素的子
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
3.同胞(sibling)
拥有相同的父的节点
在下面例子中 title,author,year,price元素都是同胞
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
4.先辈(ancestor)
某节点的父,父的父,等等
下面例子中,title元素的先辈是book和bookstore
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book></bookstore>
5.后代
某节点的子,子的子,等等
下面例子中,bookstore后代是book,title,author,year,price元素
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
第二章 xpath
XPath原理:先将HTML文档转为XML文档,再用XPath查找HTML节点或元素
一、xpath简介
xpth解析
(1)本地文件 etree.parse
(2)服务器响应的数据 response.read().decode('utf-8') etree.HTML()
示例1:
1.本地文件解析
解析_xpath的基本使用.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><ul><li id="l1" class="c1">北京</li><li id="l2">上海</li><li class="c3">深圳</li><li id="c3">武汉</li><li id="c4">广州</li></ul><ul><li>大连</li><li>锦州</li><li>沈阳</li></ul>
</body>
</html> #解析'解析——xpath的基本使用.html‘本地文件
tree=etree.parse('解析_xpath的基本使用.html')
print(tree)#<lxml.etree._ElementTree object at 0x000001FC65813F88>

二、节点选取
1.选取节点
XPath使用路径表达式来选取XML文档中的节点或者节点集,这些路径表达式和我们在常规的电脑文件系统里看到的表达式非常相似。
最常用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
例如:
| bookstore | 选取 bookstore 元素的所有子节点。 | |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 | |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 | |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 | |
| //@lang | 选取名为 lang 的所有属性。 |
2.选取未知节点
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
比如:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| html/node()/meta/@* | 选择html下面任意节点下的meta节点的所有属性 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
3.选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
比如:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
三、路径查询
tree.xpath('xpath路径')
1 //:查找所有的子孙节点,不考虑层级关系
2 /:找直接子节点
1.查找ul下面的li
li_list=tree.xpath('//body/ul/li')
# #判断列表的长度
print(li_list)
print(len(li_list))

2.谓词查询
如:
//div[@id]
//div[@id='属性值']
#查找所有有id属性的li标签
#text()获取标签中的内容
li_list=tree.xpath('//ul/li[@id]')
li_list1=tree.xpath('//ul/li[@id]/text()')#['北京', '上海']
#查找id=l1的li标签 注意引号问题
li_list2=tree.xpath('//ul/li[@id="l1"]/text()')
print(li_list)
print(li_list1)
print(li_list2)

3.属性查询
如://@class
#查找id为l1的li标签的class的属性值
li_list=tree.xpath('//ul/li[@id="l1"]/@class')#c1
print(li_list)

4.模糊查询
如:
//div[contains(@id,"he")]
//div[starts-with(@id,"he")]
#查找id中包含l的li标签
li_list=tree.xpath('//ul/li[contains(@id,"l")]/text()')#['北京', '上海']
print(li_list)

5.内容查询
如://div/h1/text()
#查询id的值以c开头的标签
li_list=tree.xpath('//ul/li[starts-with(@id,"c")]/text()')#['武汉', '广州']
print(li_list)

6.逻辑运算
如:
//div[@id="head" and @class="s_down"]
//title|//price
#查询id为l1和class为c1的标签
li_list=tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')#['北京']
li_list1=tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')#['北京', '上海']
print(li_list)
print(len(li_list))
print(li_list1)
print(len(li_list1))

四、代码示例
html = '''
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></div>
'''# 1,使用lxml的etree类
from lxml import etree#,2,利用etree.HTML()构造一个xpath解析对象(转为xml文档)
xml_doc=etree.HTML(html)
print(xml_doc)
print('-----'*10)# etree.tostring()输出转换后的html代码,
html_doc = etree.tostring(xml_doc)
print(html_doc) #自动补全了body,html标签
print(type(html_doc)) # bytes类型
# print('-----'*10)
print(html_doc.decode()) # 利用decode()方法将其转成str类型,
print(type(html_doc.decode()))
注意:
1,只要涉及到条件,加 []
2,只要获取属性值,加 @
3,通过text()取内容
相关文章:
爬虫——XPath基本用法
第一章XML 一、xml简介 1.什么是XML? 1,XML指可扩展标记语言 2,XML是一种标记语言,类似于HTML 3,XML的设计宗旨是传输数据,而非显示数据 4,XML标签需要我们自己自定义 5,XML被…...

常见排序算法汇总
排序算法汇总 这篇文章说明下排序算法,直接开始。 1.冒泡排序 最简单直观的排序算法了,新手入门的第一个排序算法,也非常直观,最大的数字像泡泡一样一个个的“冒”到数组的最后面。 算法思想:反复遍历要排序的序列…...

Golang | Leetcode Golang题解之第459题重复的子字符串
题目: 题解: func repeatedSubstringPattern(s string) bool {return kmp(s s, s) }func kmp(query, pattern string) bool {n, m : len(query), len(pattern)fail : make([]int, m)for i : 0; i < m; i {fail[i] -1}for i : 1; i < m; i {j : …...

0.计网和操作系统
0.计网和操作系统 熟悉计算机网络和操作系统知识,包括 TCP/IP、UDP、HTTP、DNS 协议等。 常见的页面置换算法: 先进先出(FIFO)算法:将最早进入内存的页面替换出去。最近最少使用(LRU)算法&am…...

探索Prompt Engineering:开启大型语言模型潜力的钥匙
前言 什么是Prompt?Prompt Engineering? Prompt可以理解为向语言模型提出的问题或者指令,它是激发模型产生特定类型响应的“触发器”。 Prompt Engineering,即提示工程,是近年来随着大型语言模型(LLM,Larg…...
)
滚雪球学Oracle[3.3讲]:数据定义语言(DDL)
全文目录: 前言一、约束的高级使用1.1 主键(Primary Key)案例演示:定义主键 1.2 唯一性约束(Unique)案例演示:定义唯一性约束 1.3 外键(Foreign Key)案例演示:…...

ssrf学习(ctfhub靶场)
ssrf练习 目录 ssrf类型 漏洞形成原理(来自网络) 靶场题目 第一题(url探测网站下文件) 第二关(使用伪协议) 关于http和file协议的理解 file协议 http协议 第三关(端口扫描)…...

ElasticSearch之网络配置
对官方文档Networking的阅读笔记。 ES集群中的节点,支持处理两类通信平面 集群内节点之间的通信,官方文档称之为transport layer。集群外的通信,处理客户端下发的请求,比如数据的CRUD,检索等,官方文档称之…...

【C语言进阶】系统测试与调试
1. 引言 在开始本教程的深度学习之前,我们需要了解整个教程的目标及其结构,以及为何进阶学习是提升C语言技能的关键。 目标和结构: 教程目标:本教程旨在通过系统化的学习,从单元测试、系统集成测试到调试技巧…...

多个单链表的合成
建立两个非递减有序单链表,然后合并成一个非递增有序的单链表。 注意:建立非递减有序的单链表,需要采用创建单链表的算法 输入格式: 1 9 5 7 3 0 2 8 4 6 0 输出格式: 9 8 7 6 5 4 3 2 1 输入样例: 在这里给出一组输入。例如…...

『建议收藏』ChatGPT Canvas功能进阶使用指南!
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工…...

Ollama 运行视觉语言模型LLaVA
Ollama的LLaVA(大型语言和视觉助手)模型集已更新至 1.6 版,支持: 更高的图像分辨率:支持高达 4 倍的像素,使模型能够掌握更多细节。改进的文本识别和推理能力:在附加文档、图表和图表数据集上进…...

gdb 调试 linux 应用程序的技巧介绍
使用 gdb 来调试 Linux 应用程序时,可以显著提高开发和调试的效率。gdb(GNU 调试器)是一款功能强大的调试工具,适用于调试各类 C、C 程序。它允许我们在运行程序时检查其状态,设置断点,跟踪变量值的变化&am…...

Java项目实战II基于Java+Spring Boot+MySQL的房产销售系统(源码+数据库+文档)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者 一、前言 随着房地产市场的蓬勃发展,房产销售业务日益复杂,传统的手工管理方式已难以满…...

aws(学习笔记第一课) AWS CLI,创建ec2 server以及drawio进行aws画图
aws(学习笔记第一课) 使用AWS CLI 学习内容: 使用AWS CLI配置密钥对创建ec2 server使用drawio(vscode插件)进行AWS的画图 1. 使用AWS CLI 注册AWS账号 AWS是通用的云计算平台,可以提供ec2,vpc,SNS以及clo…...

【Python】Eventlet 异步网络库简介
Eventlet 是一个 Python 的异步网络库,它使用协程(green threads)来简化并发编程。通过非阻塞的 I/O 操作,Eventlet 使得你可以轻松编写高性能的网络应用程序,而无需处理复杂的回调逻辑或编写多线程代码。它广泛应用于…...
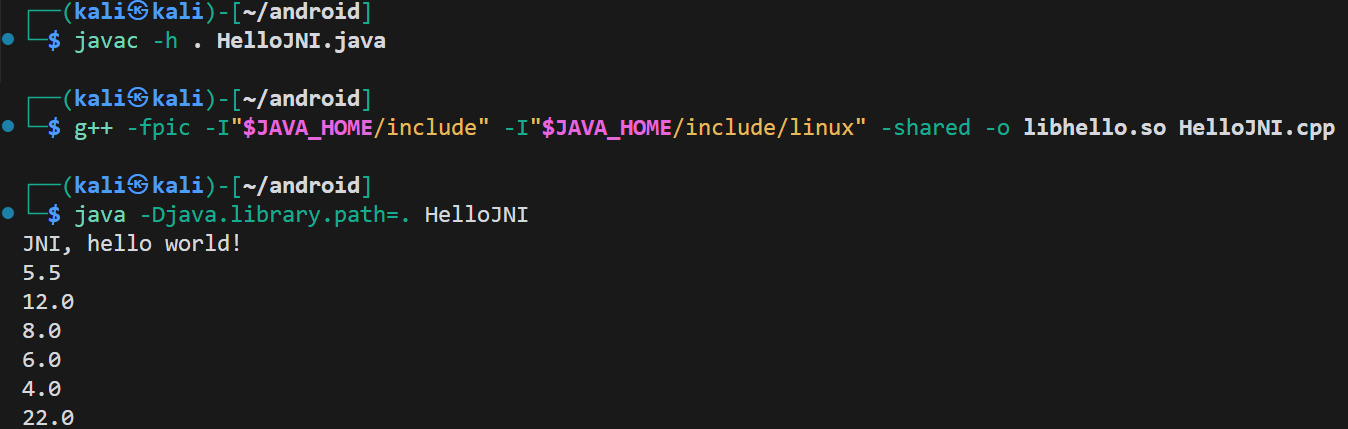
【JNI】数组的基本使用
在上一期讲了基本类型的基本使用,这期来说一说数组的基本使用 HelloJNI.java:实现myArray函数,把一个整型数组转换为双精度型数组 public class HelloJNI { static {System.loadLibrary("hello"); }private native String HelloW…...

React跨平台
React的跨平台应用开发详解如下: 一、跨平台能力 React本身是一个用于构建用户界面的JavaScript库,但它通过React Native等框架实现了跨平台应用开发的能力。React Native允许开发者使用JavaScript和React来编写原生应用,这些应用可以在iOS和…...

如何在 SQL 中更新表中的记录?
当你需要修改数据库中已存在的数据时,UPDATE 语句是你的首选工具。 这允许你更改表中一条或多条记录的特定字段值。 下面我将详细介绍如何使用 UPDATE 语句,并提供一些开发建议和注意事项。 基础用法 假设我们有一个名为 employees 的表,…...

宠物饮水机的水箱低液位提醒如何实现?
ICMAN液位检测芯片轻松实现宠物饮水机的水箱低液位提醒功能! 工作原理 : 基于双通道电容式单点液位检测原理 方案特点: 液位检测精度高达1mm,超强抗干扰,动态CS 10V 为家用电器水位提醒的应用提供了一种简单而又有…...

[笔记] 系统分析师 目录
文章目录系统分析师 第一章 绪论系统分析师 第二章 经济管理与应用数学系统分析师 第三章 操作系统基本原理系统分析师 第四章 数据通信与计算机网络系统分析师 第五章 数据库系统系统分析师 第六章 系统配置与性能评价系统分析师 第七章 企业信息化系统分析师 第八章 软件工程…...
)
STM32 ADC采样不准?别急着调代码,先检查VDDA和VREF+的供电(附实测波形)
STM32 ADC采样精度优化:从硬件设计到实测验证的完整指南 在嵌入式系统开发中,ADC采样精度问题往往让工程师陷入软件调试的泥潭。当发现采样值波动大、线性度差时,多数人的第一反应是检查代码配置——采样周期够不够?校准是否正确…...

3分钟搞定macOS OBS虚拟摄像头:专业直播与视频会议的终极指南
3分钟搞定macOS OBS虚拟摄像头:专业直播与视频会议的终极指南 【免费下载链接】obs-mac-virtualcam ARCHIVED! This plugin is officially a part of OBS as of version 26.1. See note below for info on upgrading. 🎉🎉🎉Creat…...

暖风机如何实现稳定高效的采暖输出?
一、核心结论NT‑5TS型暖风机可依托标准化结构与性能参数,满足常规工业空间采暖供热需求,整体运行能耗合理、散热效率稳定,适配多场景采暖工况。该设备经暖通设备性能检测标准核验,在额定工况下各项指标均达到行业通用使用要求&am…...

DNS 与 hosts 文件:Windows 11 中的名称解析配置
诸神缄默不语-个人技术博文与视频目录 一个域名会对应多个IP地址,当电脑访问域名时会默认指定访问其中一个IP地址(以下正文会介绍通过hosts文件和DNS服务器选择指定映射的IP的原理),总之有时我们可能会需要将域名对应的IP地址指定…...

MFAPC实战:如何为你的Arduino或树莓派项目添加智能自适应预测控制?
MFAPC实战:为嵌入式项目打造轻量级智能控制引擎 在创客空间和物联网实验室里,我们常看到这样的场景:一位开发者盯着反复震荡的智能小车摇头叹气,或是面对总也调不准的温室控制系统抓耳挠腮。传统PID控制在这些复杂动态系统中往往…...
)
从“消融”到“流动岩浆”:用Unity Shader的Tilling和Offset玩转动态纹理(URP/HDRP通用)
从“消融”到“流动岩浆”:用Unity Shader的Tilling和Offset玩转动态纹理(URP/HDRP通用) 想象一下:你的游戏场景中,炽热的岩浆在地表缓缓流动,水面泛起涟漪般的波纹,或是能量屏障表面流淌着神秘…...

VideoDownloadHelper:你的智能视频下载助手,轻松保存网页视频资源
VideoDownloadHelper:你的智能视频下载助手,轻松保存网页视频资源 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper Vid…...

WordPress Playground部署实战:从开发到生产的完整流程指南
WordPress Playground部署实战:从开发到生产的完整流程指南 【免费下载链接】wordpress-playground Run WordPress in the browser via WebAssembly PHP 项目地址: https://gitcode.com/gh_mirrors/wo/wordpress-playground WordPress Playground 是一个革命…...

3分钟解决Windows热键冲突:Hotkey Detective完全使用指南
3分钟解决Windows热键冲突:Hotkey Detective完全使用指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否…...