深度学习项目----用LSTM模型预测股价(包含LSTM网络简介,代码数据均可下载)
前言
- 前几天在看论文,打算复现,论文用到了LSTM,故这一篇文章是小编学LSTM模型的学习笔记;
- LSTM感觉很复杂,但是结合代码构建神经网络,又感觉还行;
- 本次学习的案例数据来源于GitHub,在本文案例前有数据和本人代码文件的网盘链接,想学习的可以下载,当然也希望大家能够批评指针,一起学习。
文章目录
- 1、LSTM讲解
- 1、网络结构
- 2、解释
- 3、前言
- 2、案例
- 1、数据分析
- 1、导入库
- 2、导入数据
- 3、数据预处理
- 4、特征选择
- 5、数据归一化
- 6、构建目标值
- 7、将数据转化为时间序列数据
- 8、训练集和测试集的构建
- 9、动态加载数据
- 2、构建LSTM网络
- 3、模型训练
- 1、设置超参数
- 2、训练集训构建
- 3、测试集构建
- 4、正式训练
- 4、结果展示
- 1、损失结果展示
- 2、训练集中原始值和预测值展示(反归一化)
- 3、误差检验
1、LSTM讲解
由于本人现在没有学RNN模型,故学习LSTM只聚焦于两个模块:
LSTM的三种类型门:输入门、遗忘门、输出门;LSTM的隐藏层包含“隐状态”和“记忆元”,只有隐状态会传递到输出层,而记忆元完全属于内部信息;至于LSTM可以缓解梯度消失和梯度爆炸,就等后面学到RNN之后在详细学习。
1、网络结构
LSTM神经网络简图(用ppt太难画了)

- C:记忆细胞,Ct-1,上一个记忆状态,Ct当下记忆状态
- H:隐藏状态
2、解释
-
遗忘门(Forget Gate):
- 对输入信息x,进行遗忘,选择需要记忆的东西,假如:我们考完了高数,选择需要备考线性代数,这个时候当我们进入这个门时候,需要选择遗忘高数内容(虽然现实不可能)。
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f\cdot[h_{t-1},x_t]+b_f) ft=σ(Wf⋅[ht−1,xt]+bf)
- 其中,Wf是权重矩阵,bf是偏置项,σ是 Sigmoid 激活函数,用于决定丢弃多少前一个单元状态的信息。
-
输入门(Input Gate):
- It,选择记忆,假如:我们复习线性代数的时候,可能有些知识是不需要记忆的,而这门的作用就是这个,过滤掉没有用的知识。
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) c ~ t = tanh ( W c ⋅ [ h t − 1 , x t ] + b c ) i_t=\sigma(W_i\cdot[h_{t-1},x_t]+b_i)\\\tilde{c}_t=\tanh(W_c\cdot[h_{t-1},x_t]+b_c) it=σ(Wi⋅[ht−1,xt]+bi)c~t=tanh(Wc⋅[ht−1,xt]+bc)
- 其中,Wi和 Wc是权重矩阵,bi和 bc*是偏置项,σ 是 Sigmoid 激活函数,tanh是双曲正切激活函数,用于生成候选单元状态。
-
单元状态(Cell State):
- 这个时候,我们记忆力多少呢?这个门相当于我们复习完一次在脑子里还剩下多少知识。
c t = f t ⊙ c t − 1 + i t ⊙ c ~ t c_t=f_t\odot c_{t-1}+i_t\odot\tilde{c}_t ct=ft⊙ct−1+it⊙c~t
- 其中,⊙是逐元素乘法(Hadamard product),用于更新单元状态。
-
输出门(Output Gate):
- 输出隐藏维度,相当于我们考试成绩,在神经网络中,它相当于输出多少维度特征
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) h t = o t ⊙ tanh ( c t ) o_t=\sigma(W_o\cdot[h_{t-1},x_t]+b_o)\\h_t=o_t\odot\tanh(c_t) ot=σ(Wo⋅[ht−1,xt]+bo)ht=ot⊙tanh(ct)
- 其中,Wo 是权重矩阵,bo 是偏置项,σ 是 Sigmoid 激活函数,tanh是双曲正切激活函数,用于生成当前时间步的隐藏状态。
3、前言
当然,结合案例实战,看代码是如何构建神经网络的才是最重要的,下面就是一个股价预测案例,核心是在于怎么构建LSTM网络结构,怎么进行前向传播
2、案例
数据来源于GitHub,数据和本人代码的文件网盘下载如下:
通过网盘分享的文件:基于LSTM的股价预测(入门).zip
链接: https://pan.baidu.com/s/1ZXFLl_TrhReexyvb5Gp8Xg?pwd=v7t2 提取码: v7t2
1、数据分析
1、导入库
# 导入常用的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
# 显示中文
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
2、导入数据
dates = pd.date_range('2008-08-25', '2017-10-11', freq='B')
df_main = pd.DataFrame(index=dates)
df_aaxj = pd.read_csv("./data_stock/ETFs/aaxj.us.txt", parse_dates=True, index_col=0) # 索引列为 0
df_main = df_main.join(df_aaxj) # 按照索引列规定数据范围
df_main
| Open | High | Low | Close | Volume | OpenInt | |
|---|---|---|---|---|---|---|
| 2008-08-25 | 44.044 | 44.044 | 43.248 | 43.248 | 18975.0 | 0.0 |
| 2008-08-26 | 43.802 | 43.802 | 43.471 | 43.660 | 5507.0 | 0.0 |
| 2008-08-27 | 44.564 | 44.564 | 44.457 | 44.457 | 1675.0 | 0.0 |
| 2008-08-28 | 44.421 | 44.475 | 44.421 | 44.475 | 6687.0 | 0.0 |
| 2008-08-29 | 44.224 | 44.224 | 44.171 | 44.171 | 446.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 2017-10-05 | 73.500 | 74.030 | 73.500 | 73.970 | 2134323.0 | 0.0 |
| 2017-10-06 | 73.470 | 73.650 | 73.220 | 73.579 | 2092100.0 | 0.0 |
| 2017-10-09 | 73.500 | 73.795 | 73.480 | 73.770 | 879600.0 | 0.0 |
| 2017-10-10 | 74.150 | 74.490 | 74.150 | 74.480 | 1878845.0 | 0.0 |
| 2017-10-11 | 74.290 | 74.645 | 74.210 | 74.610 | 1168511.0 | 0.0 |
2383 rows × 6 columns
3、数据预处理
# 查看数据类型
df_main.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2383 entries, 2008-08-25 to 2017-10-11
Freq: B
Data columns (total 6 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Open 2298 non-null float641 High 2298 non-null float642 Low 2298 non-null float643 Close 2298 non-null float644 Volume 2298 non-null float645 OpenInt 2298 non-null float64
dtypes: float64(6)
memory usage: 194.9 KB
- 总数量:2383,no_null数量:2298,存在缺失值
- 数据类型:float64
# 查看缺失值数量
df_main.isnull().sum()
输出:
Open 85
High 85
Low 85
Close 85
Volume 85
OpenInt 85
dtype: int64
- 85 / 2385 大概为3.5%,缺失值有点多;
- 缺失值类型为随机丢失值,是收集缺失的;
- 由于该数据是时间序列,且股票价格和前后关系很大,故采用插值方法填充。
# 插值方法填充缺失值
df_main = df_main.interpolate(method='linear')
# 再次查看缺失值的情况
df_main.isnull().sum()
输出:
Open 0
High 0
Low 0
Close 0
Volume 0
OpenInt 0
dtype: int64
# 统计量分析
df_main.describe()
输出:
| Open | High | Low | Close | Volume | OpenInt | |
|---|---|---|---|---|---|---|
| count | 2383.000000 | 2383.000000 | 2383.000000 | 2383.000000 | 2.383000e+03 | 2383.0 |
| mean | 52.559695 | 52.835654 | 52.216654 | 52.552454 | 7.177284e+05 | 0.0 |
| std | 8.773809 | 8.687520 | 8.930144 | 8.805241 | 7.704731e+05 | 0.0 |
| min | 23.790000 | 24.605000 | 19.699000 | 22.726000 | 1.120000e+02 | 0.0 |
| 25% | 48.988500 | 49.313000 | 48.552500 | 48.981500 | 2.789905e+05 | 0.0 |
| 50% | 53.653000 | 53.932000 | 53.432000 | 53.653000 | 5.040570e+05 | 0.0 |
| 75% | 57.270500 | 57.484000 | 56.983500 | 57.214500 | 8.812500e+05 | 0.0 |
| max | 74.290000 | 74.645000 | 74.210000 | 74.610000 | 1.048028e+07 | 0.0 |
# 相关性分析
df_main.corr()
输出:
| Open | High | Low | Close | Volume | OpenInt | |
|---|---|---|---|---|---|---|
| Open | 1.000000 | 0.999256 | 0.997143 | 0.998608 | 0.265971 | NaN |
| High | 0.999256 | 1.000000 | 0.996543 | 0.999276 | 0.268923 | NaN |
| Low | 0.997143 | 0.996543 | 1.000000 | 0.997468 | 0.261464 | NaN |
| Close | 0.998608 | 0.999276 | 0.997468 | 1.000000 | 0.264884 | NaN |
| Volume | 0.265971 | 0.268923 | 0.261464 | 0.264884 | 1.000000 | NaN |
| OpenInt | NaN | NaN | NaN | NaN | NaN | NaN |
- 结合生活情况,选取特征:open、high、low、close
4、特征选择
# 选取特征:open、high、low、close
sel_features = ['Open', 'High', 'Low', 'Close']
df_main = df_main[sel_features] # 列索引
# 查看前几条数据
df_main.head(3)
输出:
| Open | High | Low | Close | |
|---|---|---|---|---|
| 2008-08-25 | 44.044 | 44.044 | 43.248 | 43.248 |
| 2008-08-26 | 43.802 | 43.802 | 43.471 | 43.660 |
| 2008-08-27 | 44.564 | 44.564 | 44.457 | 44.457 |
# 股价收盘价展示
df_main[['Close']].plot()
plt.title('股价收盘价走势')
plt.ylabel('股票价格')
plt.xlabel('时间')
plt.show()

5、数据归一化
from sklearn.preprocessing import MinMaxScaler
# 创建归一化
scaler = MinMaxScaler(feature_range=(-1, 1))
# 归一化
for col in sel_features:df_main[col] = scaler.fit_transform(df_main[col].values.reshape(-1, 1)) # -1:自动推断长度,列数量
# 数据展示
df_main.head(3)
输出:
| Open | High | Low | Close | |
|---|---|---|---|---|
| 2008-08-25 | -0.197861 | -0.223062 | -0.135991 | -0.208928 |
| 2008-08-26 | -0.207446 | -0.232734 | -0.127809 | -0.193046 |
| 2008-08-27 | -0.177267 | -0.202278 | -0.091633 | -0.162324 |
6、构建目标值
由于没有目标值,故需要新建,目标值为下一次收盘价格
# 创建目标值
df_main['target'] = df_main['Close'].shift(-1) # 选取下一个目标值
# 向前移动一位,故最后缺一行
df_main = df_main.dropna()
# 统一数据类型
df_main = df_main.astype(np.float32)
import seaborn as sns
# 计算相关性
corr_matrix = df_main.corr()
# 绘图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', linewidths=0.5)
plt.title('相关性分析')
plt.show()

- 突然感觉这一步很多余,因为股价么,开盘,涨幅,收盘相关性就应该是极强的
7、将数据转化为时间序列数据
由于股价是数据金融数据,不属于时间序列数据,故为了更好预测,需要将数据转化为金融数据。
def create_time_data(data, seq): # seq时间序列窗口长度# 创建存储特征数据、目标检测容器data_feat, data_target = [], []# index开始,构建长度seq长度数据for index in range(len(data) - seq):data_feat.append(data[['Open', 'High', 'Low', 'Close']][index: index + seq].values)data_target.append(data['target'][index: index + seq])# 将数据转化为numpy数组data_feat = np.array(data_feat)data_target = np.array(data_target)return data_feat, data_target
# 查看转化为时间序列格式
df_main[['Open', 'High', 'Low', 'Close']][0: 20].values输出:
array([[-0.19786139, -0.22306155, -0.1359909 , -0.2089276 ],[-0.20744555, -0.23273382, -0.12780906, -0.19304602],[-0.17726733, -0.20227818, -0.09163288, -0.16232364],[-0.1829307 , -0.20583533, -0.09295372, -0.1616298 ],[-0.19073267, -0.21586731, -0.10212617, -0.17334823],[-0.19764356, -0.22284172, -0.10755628, -0.17905328],[-0.20455445, -0.22981615, -0.11298637, -0.1847583 ],[-0.26768318, -0.28892887, -0.17543249, -0.24797626],[-0.28574258, -0.3117506 , -0.21487406, -0.28968468],[-0.33833665, -0.33721024, -0.2418044 , -0.28833553],[-0.27168316, -0.29316548, -0.1908789 , -0.24585614],[-0.28011882, -0.30607513, -0.21553448, -0.29249865],[-0.3281584 , -0.34580335, -0.24672085, -0.31716907],[-0.37619802, -0.38553157, -0.27790722, -0.3418395 ],[-0.3779802 , -0.4044764 , -0.2841445 , -0.36458254],[-0.40669307, -0.43381295, -0.33151108, -0.41153342],[-0.45421782, -0.4803757 , -0.37579572, -0.44086808],[-0.472 , -0.49972022, -0.400488 , -0.48681673],[-0.47366336, -0.43888888, -0.375172 , -0.38705572],[-0.36376238, -0.32893685, -0.26047954, -0.28174388]],dtype=float32)
8、训练集和测试集的构建
# 定义划分函数
def train_test(data_feat, data_target, test_size, seq):# 训练集大小train_size = data_feat.shape[0] - test_size # 划分训练集和测试集,并将数据转化为 张量 格式train_x = torch.from_numpy(data_feat[: train_size].reshape(-1, seq, 4)).type(torch.Tensor)test_x = torch.from_numpy(data_feat[train_size:].reshape(-1, seq, 4)).type(torch.Tensor)train_y = torch.from_numpy(data_target[:train_size].reshape(-1, seq, 1)).type(torch.Tensor)test_y = torch.from_numpy(data_target[train_size:].reshape(-1, seq, 1)).type(torch.Tensor)# 返回return train_x, train_y, test_x, test_y# 数据定义
data = df_main
seq = 6 # 窗口大小:这里设置为6,原因:: 股价数据中6天为一周
test_size = int(len(data) * 0.2)# 创建时间序列数据
feat, target = create_time_data(data, seq)# 创建划分数据
train_x, train_y, test_x, test_y = train_test(feat, target, test_size, seq)
# 输出维度
train_x.shape, train_y.shape, test_x.shape, test_y.shape
输出:
(torch.Size([1900, 6, 4]),torch.Size([1900, 6, 1]),torch.Size([476, 6, 4]),torch.Size([476, 6, 1]))
9、动态加载数据
from torchvision import transforms, datasetsbatch_size = 6 # 每一次那6天数据进行训练# 加载数据
train_data = torch.utils.data.TensorDataset(train_x, train_y)
test_data = torch.utils.data.TensorDataset(test_x, test_y)# 动态加载数据
train_dl = torch.utils.data.DataLoader(dataset=train_data,batch_size=batch_size,shuffle=True)test_dl = torch.utils.data.DataLoader(dataset=test_data,batch_size=batch_size,shuffle=True)
2、构建LSTM网络
class LSTM(nn.Module):def __init__(self, input_dim, hidden_dim, num_layers,output_dim):super(LSTM, self).__init__()# 定义隐藏层维度self.hidden_dim = hidden_dim# 定义lstm层的数量self.num_layers = num_layers# 构建lstm模型self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)# 构建全连接层self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):# 初始化隐藏状态和细胞状态h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()# 前向传播lstmout, (hn, cn) = self.lstm(x, (h0.detach(), c0.detach()))# 分类out = self.fc(out)# 返回结果return out
# 创建并且打印模型参数
# 输入特征:4,输出特征:1
model = LSTM(input_dim=4, hidden_dim=32, num_layers=2, output_dim=1)
model
输出:
LSTM((lstm): LSTM(4, 32, num_layers=2, batch_first=True)(fc): Linear(in_features=32, out_features=1, bias=True)
)
3、模型训练
1、设置超参数
# 创建损失函数
loss_fn = torch.nn.MSELoss()
# 学习率
learn_rate = 0.01
# 创建优化器
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
2、训练集训构建
def train(dataloader, model, loss_fn, optimizer):# 获取批次大小batch_size = len(dataloader) # 总数 / 32# 准确率和损失率train_loss = 0for X, y in dataloader: # 每一批次的规格请看上面:动态加载数据哪里# 预测pred = model(X)# 计算损失loss = loss_fn(pred, y)# 梯度清零optimizer.zero_grad()# 求导loss.backward()# 梯度下降法更新optimizer.step()# 误差train_loss += loss.item() # .item 获取数据项# 计算损失函数和梯度train_loss /= batch_sizereturn train_loss3、测试集构建
def test(dataloader, model, loss_fn):batch_size = len(dataloader)# 准确率和损失率test_loss = 0with torch.no_grad():for X, y in dataloader:# 预测和计算损失pred = model(X)loss = loss_fn(pred, y)test_loss += loss.item()# 计算损失率 test_loss /= batch_sizereturn test_loss
4、正式训练
train_loss = []
test_loss = []epochs = 15for epoch in range(epochs):model.train()epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_loss = test(test_dl, model, loss_fn)train_loss.append(epoch_train_loss)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_mse:{:.10f}, Test_mse:{:.10f}')print(template.format(epoch+1, epoch_train_loss, epoch_test_loss))
Epoch: 1, Train_mse:0.0055270789, Test_mse:0.0028169709
Epoch: 2, Train_mse:0.0014304496, Test_mse:0.0032940961
Epoch: 3, Train_mse:0.0016769003, Test_mse:0.0014444893
Epoch: 4, Train_mse:0.0013827066, Test_mse:0.0023709078
Epoch: 5, Train_mse:0.0013644575, Test_mse:0.0005126200
Epoch: 6, Train_mse:0.0011645519, Test_mse:0.0009766717
Epoch: 7, Train_mse:0.0010370992, Test_mse:0.0026354755
Epoch: 8, Train_mse:0.0011004983, Test_mse:0.0005752990
Epoch: 9, Train_mse:0.0011330271, Test_mse:0.0013168041
Epoch:10, Train_mse:0.0011555004, Test_mse:0.0016195212
Epoch:11, Train_mse:0.0015111874, Test_mse:0.0010681283
Epoch:12, Train_mse:0.0010495648, Test_mse:0.0008801822
Epoch:13, Train_mse:0.0009528522, Test_mse:0.0006430979
Epoch:14, Train_mse:0.0010829600, Test_mse:0.0006819312
Epoch:15, Train_mse:0.0011495422, Test_mse:0.0013490517
4、结果展示
1、损失结果展示
# 绘制损失函数
epoch_range = range(epochs)plt.plot(epoch_range, train_loss, label='Training Mse')
plt.plot(epoch_range, test_loss, label='Test Mse')
plt.legend(loc='upper right')
plt.title('Mse')
plt.show()

分析
- 模型在归一化后的预测效果中,训练集和测试集的mse,均小于1%,说明了该模型对这个数据的预测有效性;
- 下面将进行反归一化,将预测数据进行可视化展示,可以更直观观测效果。
2、训练集中原始值和预测值展示(反归一化)
y_train_pred = model(train_x)
y_test_pred = model(test_x)y_train_pred = scaler.inverse_transform(y_train_pred.detach().numpy()[:,-1,0].reshape(-1,1))
y_train = scaler.inverse_transform(train_y.detach().numpy()[:,-1,0].reshape(-1,1))
y_test_pred = scaler.inverse_transform(y_test_pred.detach().numpy()[:,-1,0].reshape(-1,1))
y_test = scaler.inverse_transform(test_y.detach().numpy()[:,-1,0].reshape(-1,1))
# 训练绘图展示
plt.plot(y_train_pred, label="pred_data")
plt.plot(y_train, label="true_data")
plt.legend()
plt.show()

# 测试绘图展示
plt.plot(y_test_pred, label="pred_data")
plt.plot(y_test, label="true_data")
plt.legend()
plt.show()

3、误差检验
from sklearn.metrics import mean_squared_errortrainScore = mean_squared_error(y_train, y_train_pred)
testScore = mean_squared_error(y_test, y_test_pred)print("Trian mse: ", trainScore)
print("Test mse: ", testScore)
Trian mse: 0.60466486
Test mse: 0.8240372
分析
- Trian mse: 0.61244047,Test mse: 0.8975438,结合原始数据大小,进一步验证了模型的有效性
相关文章:
深度学习项目----用LSTM模型预测股价(包含LSTM网络简介,代码数据均可下载)
前言 前几天在看论文,打算复现,论文用到了LSTM,故这一篇文章是小编学LSTM模型的学习笔记;LSTM感觉很复杂,但是结合代码构建神经网络,又感觉还行;本次学习的案例数据来源于GitHub,在…...

《精通开关电源设计》笔记一
重点 效率 纹波 环路响应 尺寸,从静态到动态的研究方法,假设开关电源稳态运行,以电感为中心,根据半导体器件(mos管或二极管)分段分析电路的状态,工具有电路原理和能量守恒 影响效率的主要是开关损耗,所以…...

QLoRA代码实战
QLoRA原理参考: BiliBili:4bit量化与QLoRA模型训练 zhihu:QLoRA(Quantized LoRA)详解 下载llama3-8b模型 from modelscope import snapshot_download model_dir snapshot_download(LLM-Research/Meta-Llama-3-8B-In…...

pyqt QGraphicsView 以鼠标为中心进行缩放
注意几个关键点: 1. 初始化 class CustomGraphicsView(QGraphicsView):def __init__(self, parentNone):super(CustomGraphicsView, self).__init__(parent)self.scene QGraphicsScene()self.setScene(self.scene)self.setGeometry(0, 0, 1024, 600)# 以下初始化…...

FPGA-Vivado-IP核-逻辑分析仪(ILA)
ILA IP核 背景介绍 在用FPGA做工程项目时,当Verilog代码写好,我们需要对代码里面的一些关键信号进行上板验证查看。首先,我们可以把需要查看的这些关键信号引出来,接好线通过示波器进行实时监测,但这会用到大量的线材…...
基于webComponents的纯原生前端框架
我本人的个人开发web前端前框架xui,正在开发中,业已完成50%的核心开发工作,并且在开发过程中逐渐完善. 目前框架未采用任何和市面上框架模式,没有打包过程,实现真实的开箱即用。 当然在开发过程中也会发现没有打包工…...

OpenCV-背景建模
文章目录 一、背景建模的目的二、背景建模的方法及原理三、背景建模实现四、总结 OpenCV中的背景建模是一种在计算机视觉中从视频序列中提取出静态背景的技术。以下是对OpenCV背景建模的详细解释: 一、背景建模的目的 背景建模的主要目标是将动态的前景对象与静态的…...

一个简单的摄像头应用程序6
主要改进点: 使用 ThreadPoolExecutor 管理多线程: 使用 concurrent.futures.ThreadPoolExecutor 来管理多线程,这样可以更高效地处理图像。 在 main 函数中创建一个 ThreadPoolExecutor,并在每个循环中提交图像处理任务。 减少…...

Pikachu-目录遍历
目录遍历,跟不安全文件上传下载有差不多; 访问 jarheads.php 、truman.php 都是通过 get 请求,往title 参数传参; 在后台,可以看到 jarheads.php 、truman.php所在目录: /var/www/html/vul/dir/soup 图片…...

用Python实现基于Flask的简单Web应用:从零开始构建个人博客
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 前言 在现代Web开发中,Python因其简洁、易用以及丰富的库生态系统,成为了许多开发者的首选编程语言。Flask作为一个轻量级的Python Web框架,以其简洁和灵活性深受开…...

IDEA的lombok插件不生效了?!!
记录一下,防止找不到解决方案,已经遇到好几次了 前面啰嗦的多,可以直接跳到末尾的解决方法,点击一下 问题现场情况 排查过程 确认引入的依赖正常 —》🆗 idea 是否安装了lombok插件 --》🆗 貌似没有问题…...

CSP-S 2022 T1假期计划
CSP-S 2022 T1假期计划 先思考暴力做法,题目需要找到四个不相同的景点,那我们就枚举这四个景点,判断它们之间的距离是否符合条件,条件是任意两个点之间的距离是否大于 k k k,所以我们需要求出任意两点之间的距离。常用…...

为什么要学习大模型?AI在把传统软件当早餐吃掉?
前言 上周末在推特平台上有一篇写在谷歌文档里的短文,在国外的科技/投资圈得到了非常广泛的浏览,叫做 The End of Software(软件的终结), 作者 Chris Paik 是位于纽约市的风险投资基金 Pace Capital 的创始合伙人&…...

全流程Python编程、机器学习与深度学习实践技术应用
近年来,人工智能领域的飞速发展极大地改变了各个行业的面貌。当前最新的技术动态,如大型语言模型和深度学习技术的发展,展示了深度学习和机器学习技术的强大潜力,成为推动创新和提升竞争力的关键。特别是PyTorch,凭借其…...

pWnos1.0 靶机渗透 (Perl CGI 的反弹 shell 利用)
靶机介绍 来自 vulnhub 主机发现 ┌──(kali㉿kali)-[~/testPwnos1.0] …...
 函数绑定无效)
jquery on() 函数绑定无效
on 前面的元素必须在页面加载的时候就存在于 dom 里面。动态的元素或者样式等,可以放在 on 的第二个参数里面。jQuery on() 方法是官方推荐的绑定事件的一个方法。使用 on() 方法可以给将来动态创建的动态元素绑定指定的事件,例如 append 等。 <div …...

数字化转型与企业创新的双向驱动
数字化转型与企业创新的双向驱动 在全球化的竞争环境中,数字化转型已成为企业保持竞争力的重要手段。未来几年,随着信息技术的进一步发展,数字化转型将不仅限于IT部门,而是深入到企业的各个业务层面,推动创新和效率的…...
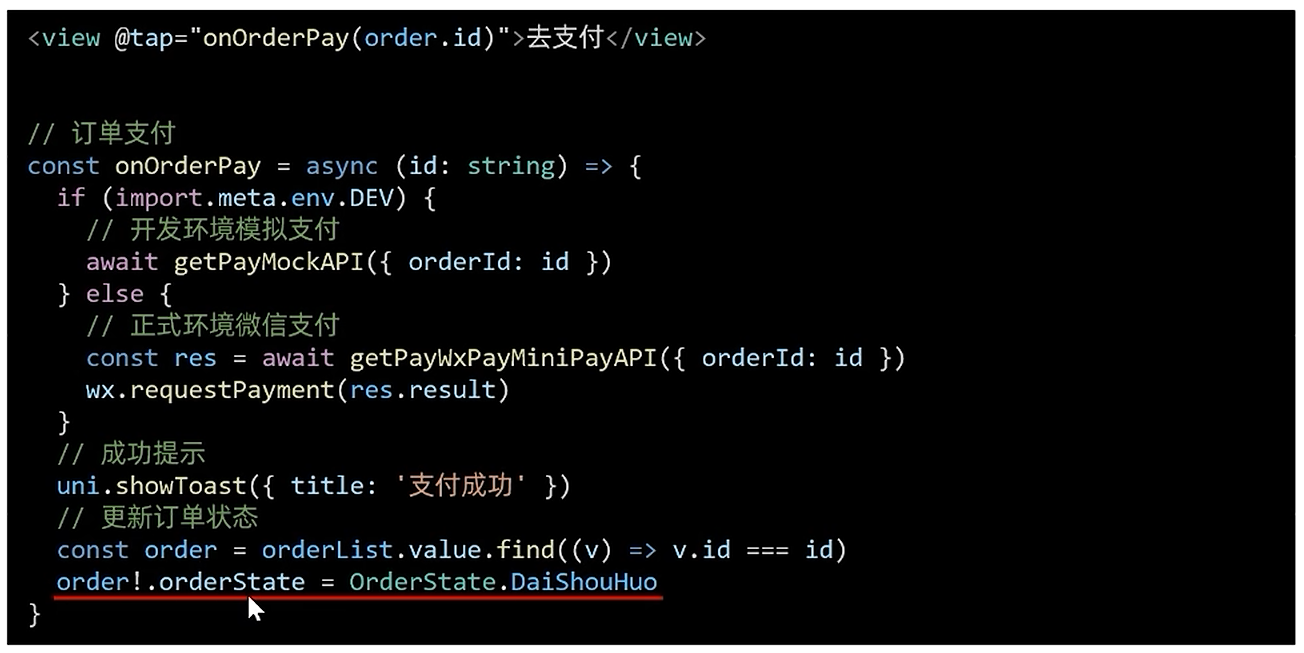
[uni-app]小兔鲜-07订单+支付
订单模块 基本信息渲染 import type { OrderState } from /services/constants import type { AddressItem } from ./address import type { PageParams } from /types/global/** 获取预付订单 返回信息 */ export type OrderPreResult {/** 商品集合 [ 商品信息 ] */goods: …...

Oracle数据库中表压缩的实现方式和特点
Oracle数据库中表压缩的实现方式和特点 在 Oracle 数据库中,表压缩是一项重要的功能,旨在优化存储空间和提高性能。Oracle 提供了多种表压缩技术,以适应不同的应用场景和需求。以下是 Oracle 数据库中表压缩的实现方式和特点: 1…...

【C语言】基础篇
简单输出“helloword” #include<stdio.h> int main(){printf("hello world!");return 0; } 和与商 #include<stdio.h> int main(){int a,b,sum,quotient;printf("Enter two numbers:");scanf("%d %d",&a,&b);sum a b…...

番茄小说下载器:终极解决方案,轻松构建个人数字图书馆
番茄小说下载器:终极解决方案,轻松构建个人数字图书馆 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 还在为网络小说资源分散、广告干扰、无法离线阅读…...

IL-4诱导的M2INF巨噬细胞在二型免疫疾病及感染防御中的机制研究
摘要郑世进课题组通过深入研究IL-4诱导的M2INF巨噬细胞,揭示了其产生机制主要涉及糖代谢途径的重编程和组蛋白H3K4位点甲基化修饰的改变。这一发现为理解二型免疫疾病的发生发展提供了新的视角,并为相关疾病的治疗策略提供了理论依据。通过在小鼠模型&am…...

告别DETR训练慢!手把手教你用Deformable Attention加速目标检测模型收敛
突破DETR训练瓶颈:Deformable Attention加速目标检测实战指南 当你在深夜盯着屏幕,看着DETR模型训练到第50个epoch时验证集指标仍在波动,是否曾怀疑自己的显卡在空转?Transformer架构在目标检测领域的革命性突破有目共睹ÿ…...

CMOS概率计算芯片设计与工程实践
1. CMOS概率计算芯片的核心设计理念概率计算作为一种新兴的计算范式,正在突破传统冯诺依曼架构的局限。我们团队开发的这款440节点CMOS芯片,其核心创新点在于将物理启发的随机性与标准CMOS工艺完美结合。不同于传统计算机的确定性计算方式,每…...

ARM架构ADD/AND指令详解与应用优化
1. ARM指令集基础与ADD/AND指令概述在嵌入式系统和移动计算领域,ARM架构凭借其高效能低功耗的特性占据主导地位。作为RISC(精简指令集计算机)架构的代表,ARM指令集的设计哲学是通过精简而高效的指令完成复杂任务。其中,…...

Windows HEIC缩略图插件:为什么你的iPhone照片在Windows上无法预览?
Windows HEIC缩略图插件:为什么你的iPhone照片在Windows上无法预览? 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumb…...

Analog Discovery 2:口袋实验室如何用FPGA重塑硬件调试体验
1. 口袋里的实验室:为什么我们需要Analog Discovery 2?作为一名在硬件开发一线摸爬滚打了十多年的工程师,我太熟悉那种面对复杂项目时,被实验室设备“卡脖子”的窘迫感了。你想验证一个想法,或者排查一个棘手的信号问题…...

CefFlashBrowser终极指南:三步实现完美Flash浏览器与SOL存档管理
CefFlashBrowser终极指南:三步实现完美Flash浏览器与SOL存档管理 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 在Adobe正式停止Flash支持后,你是否还在为无法访问…...

2026年小程序多少钱:8款高口碑产品排行榜解锁最优选择
导读:2026年,小程序开发已成为企业数字化运营的核心工具,其成本结构受功能复杂度、平台选择及服务商专业度等多因素影响。市场调研显示,基础展示型小程序报价集中在5000-15000元,而定制化多功能方案可达5万元以上。行业…...

5分钟终极指南:用HunterPie轻松提升《怪物猎人:世界》狩猎效率
5分钟终极指南:用HunterPie轻松提升《怪物猎人:世界》狩猎效率 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirr…...