使用Pytorch构建自定义层并在模型中使用
使用Pytorch构建自定义层并在模型中使用
继承自nn.Module类,自定义名称为NoisyLinear的线性层,并在新模型定义过程中使用该自定义层。完整代码可以在jupyter nbviewer中在线访问。
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoaderimport numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from mlxtend.plotting import plot_decision_regions
print(torch.__version__)
print(np.__version__)
2.0.1+cu118
1.24.4
创建一个包含有噪声的线性层
class NoisyLinear(nn.Module):def __init__(self, input_size, output_size, noise_stddev=0.1):super().__init__()w = torch.Tensor(input_size, output_size)self.w = nn.Parameter(w)nn.init.xavier_uniform_(self.w)b = torch.Tensor(output_size).fill_(0)self.b = nn.Parameter(b)self.noise_stddev = noise_stddevdef forward(self, x, training=False):if training:noise = torch.normal(0.0, self.noise_stddev, x.shape)x_new = torch.add(x, noise)else:x_new = xreturn torch.add(torch.mm(x_new, self.w), self.b)
这段代码定义了一个名为 NoisyLinear 的类,它继承自 nn.Module,表示一个包含噪声的线性层。
class NoisyLinear(nn.Module):
定义一个名为 NoisyLinear 的类,它继承自 PyTorch 的 nn.Module 类。这意味着它可以被用作一种神经网络层。
def __init__(self, input_size, output_size, noise_stddev=0.1):
初始化方法 __init__ 接受三个参数:输入大小 input_size,输出大小 output_size,以及噪声的标准差 noise_stddev(默认值为 0.1)。
super().__init__()
调用父类 nn.Module 的初始化方法,以确保父类的相关属性和方法被正确初始化。
w = torch.Tensor(input_size, output_size)
创建一个形状为 (input_size, output_size) 的张量 w,用于存储权重。
self.w = nn.Parameter(w)
将权重 w 包装为 nn.Parameter,这意味着在训练过程中,PyTorch 会自动将其视为可学习参数。
nn.init.xavier_uniform_(self.w)
使用 Xavier 均匀分布对权重 self.w 进行初始化。这是一种常用的初始化方法,有助于保持神经网络中信号的方差。
b = torch.Tensor(output_size).fill_(0)
创建一个形状为 (output_size,) 的张量 b,并将其填充为 0,用于存储偏置。
self.b = nn.Parameter(b)
将偏置 b 包装为 nn.Parameter,使其在训练过程中也是可学习的。
self.noise_stddev = noise_stddev
将噪声的标准差 noise_stddev 存储为类的一个属性,用于后续的噪声计算。
def forward(self, x, training=False):
定义前向传播方法 forward,接受输入 x 和一个布尔参数 training,指示当前是否在训练模式下。
if training:
检查当前是否处于训练模式。
noise = torch.normal(0.0, self.noise_stddev, x.shape)
如果是训练模式,则创建一个与输入 x 形状相同的噪声张量 noise,其服从均值为 0、标准差为 self.noise_stddev 的正态分布。
x_new = torch.add(x, noise)
将噪声添加到输入 x 上,得到新的输入 x_new。
else:
如果不是训练模式,则执行以下代码。
x_new = x
在非训练模式下,x_new 直接设置为输入 x,即没有添加噪声。
return torch.add(torch.mm(x_new, self.w), self.b)
计算输出:首先用 torch.mm 进行矩阵乘法(x_new 和权重 self.w),然后将偏置 self.b 添加到结果中。最后返回计算出的输出。
总结来说,这个类实现了一个带噪声的线性变换,在线性层中可以根据训练模式选择性地添加噪声。
# 上述层的使用示例.
# 1、实例化这个层,并调用三次.
torch.manual_seed(1)noisy_layer = NoisyLinear(4, 2)
x = torch.zeros((1, 4))
print(noisy_layer(x, training=True))print(noisy_layer(x, training=True))print(noisy_layer(x, training=False))
tensor([[ 0.1154, -0.0598]], grad_fn=<AddBackward0>)
tensor([[ 0.0432, -0.0375]], grad_fn=<AddBackward0>)
tensor([[0., 0.]], grad_fn=<AddBackward0>)
在一个示例数据上,构建一个包含该自定义层的模型
# 生成一个示例数据.
np.random.seed(1)
torch.manual_seed(1)
x = np.random.uniform(low=-1, high=1, size=(200, 2))
y = np.ones(len(x))
y[x[:, 0] * x[:, 1]<0] = 0n_train = 100
x_train = torch.tensor(x[:n_train, :], dtype=torch.float32)
y_train = torch.tensor(y[:n_train], dtype=torch.float32)
x_valid = torch.tensor(x[n_train:, :], dtype=torch.float32)
y_valid = torch.tensor(y[n_train:], dtype=torch.float32)fig = plt.figure(figsize=(6, 6))
plt.plot(x[y==0, 0], x[y==0, 1], 'o', alpha=0.75, markersize=10)
plt.plot(x[y==1, 0], x[y==1, 1], '<', alpha=0.75, markersize=10)
plt.xlabel(r'$x_1$', size=15)
plt.ylabel(r'$x_2$', size=15)
plt.tight_layout()
plt.show()

# 创建一个DataLoader.
train_ds = TensorDataset(x_train, y_train)
batch_size = 2
torch.manual_seed(1)# 使用DataLoader加载数据,batchsize为2.
train_dl = DataLoader(train_ds, batch_size, shuffle=True)
# 创建一个新的模型,并且调用上述的自定义层.
class MyNoiseModule(nn.Module):def __init__(self):super().__init__()self.l1 = NoisyLinear(2, 4, 0.07)self.a1 = nn.ReLU()self.l2 = nn.Linear(4, 4)self.a2 = nn.ReLU()self.l3 = nn.Linear(4, 1)self.a3 = nn.Sigmoid()def forward(self, x, training=False):x = self.l1(x, training)x = self.a1(x)x = self.l2(x)x = self.a2(x)x = self.l3(x)x = self.a3(x)return xdef predict(self, x):self.eval()with torch.no_grad():x = torch.tensor(x, dtype=torch.float32)pred = self.forward(x)[:, 0]return (pred>=0.5).float()
# 模型实例化.
torch.manual_seed(1)
model = MyNoiseModule()
model
MyNoiseModule((l1): NoisyLinear()(a1): ReLU()(l2): Linear(in_features=4, out_features=4, bias=True)(a2): ReLU()(l3): Linear(in_features=4, out_features=1, bias=True)(a3): Sigmoid()
)
# 3.在训练training batch上计算预测结果.
loss_fn = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.015)
# 模型训练,设置epochs=200
torch.manual_seed(1)
num_epochs = 200def train(model, num_epochs, train_dl, x_valid, y_valid):loss_hist_train = [0] * num_epochsacc_hist_train = [0] * num_epochsloss_hist_valid = [0] * num_epochsacc_hist_valid = [0] * num_epochsfor epoch in range(num_epochs):for x_batch, y_batch in train_dl:pred = model(x_batch, True)[:, 0]loss = loss_fn(pred, y_batch)loss.backward()optimizer.step()optimizer.zero_grad()loss_hist_train[epoch] += loss.item()is_correct = ((pred>=0.5).float() == y_batch).float()acc_hist_train[epoch] += is_correct.mean()loss_hist_train[epoch] /= n_train/batch_sizeacc_hist_train[epoch] /= n_train/batch_sizepred = model(x_valid)[:, 0]loss = loss_fn(pred, y_valid)loss_hist_valid[epoch] = loss.item()is_correct = ((pred>=0.5).float() == y_valid).float()acc_hist_valid[epoch] += is_correct.mean()return loss_hist_train, loss_hist_valid, \acc_hist_train, acc_hist_validhistory = train(model, num_epochs, train_dl, x_valid, y_valid)
# 绘制决策边界.
fig = plt.figure(figsize=(16, 4))
ax = fig.add_subplot(1, 3, 1)
plt.plot(history[0], lw=4)
plt.plot(history[1], lw=4)
plt.legend(['Train loss', 'Validation loss'], fontsize=15)
ax.set_xlabel('Epochs', size=15)ax = fig.add_subplot(1, 3, 2)
plt.plot(history[2], lw=4)
plt.plot(history[3], lw=4)
plt.legend(['Train acc.', 'Validation acc.'], fontsize=15)
ax.set_xlabel('Epochs', size=15)ax = fig.add_subplot(1, 3, 3)
plot_decision_regions(X=x_valid.numpy(), y=y_valid.numpy().astype(np.int64),clf=model)
ax.set_xlabel(r'$x_1$', size=15)
ax.xaxis.set_label_coords(1, -0.025)
ax.set_ylabel(r'$x_2$', size=15)
ax.yaxis.set_label_coords(-0.025, 1)
plt.show()

相关文章:
使用Pytorch构建自定义层并在模型中使用
使用Pytorch构建自定义层并在模型中使用 继承自nn.Module类,自定义名称为NoisyLinear的线性层,并在新模型定义过程中使用该自定义层。完整代码可以在jupyter nbviewer中在线访问。 import torch import torch.nn as nn from torch.utils.data import T…...
:从前序与中序遍历序列构造二叉树)
学习记录:js算法(五十六):从前序与中序遍历序列构造二叉树
文章目录 从前序与中序遍历序列构造二叉树我的思路网上思路 总结 从前序与中序遍历序列构造二叉树 给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示…...

qt使用QDomDocument读写xml文件
在使用QDomDocument读写xml之前需要在工程文件添加: QT xml 1.生成xml文件 void createXml(QString xmlName) {QFile file(xmlName);if (!file.open(QIODevice::WriteOnly | QIODevice::Truncate |QIODevice::Text))return false;QDomDocument doc;QDomProcessin…...

Oracle架构之表空间详解
文章目录 1 表空间介绍1.1 简介1.2 表空间分类1.2.1 SYSTEM 表空间1.2.2 SYSAUX 表空间1.2.3 UNDO 表空间1.2.4 USERS 表空间 1.3 表空间字典与本地管理1.3.1 字典管理表空间(Dictionary Management Tablespace,DMT)1.3.2 本地管理方式的表空…...

springboot整合seata
一、准备 docker部署seata-server 1.5.2参考:docker安装各个组件的命令 二、springboot集成seata 2.1 引入依赖 <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId>&…...
【二次向用户申请授权】程序访问控制)
鸿蒙开发(NEXT/API 12)【二次向用户申请授权】程序访问控制
当应用通过[requestPermissionsFromUser()]拉起弹框[请求用户授权]时,用户拒绝授权。应用将无法再次通过requestPermissionsFromUser拉起弹框,需要用户在系统应用“设置”的界面中,手动授予权限。 在“设置”应用中的路径: 路径…...

docker export/import 和 docker save/load 的区别
Docker export/import 和 docker save/load 都是用于容器和镜像的备份和迁移,但它们有一些关键的区别: docker export/import: export 作用于容器,import 创建镜像导出的是容器的文件系统,不包含镜像的元数据丢失了镜像的层级结构…...

明星周边销售网站开发:SpringBoot技术全解析
1系统概述 1.1 研究背景 如今互联网高速发展,网络遍布全球,通过互联网发布的消息能快而方便的传播到世界每个角落,并且互联网上能传播的信息也很广,比如文字、图片、声音、视频等。从而,这种种好处使得互联网成了信息传…...

STM32+ADC+扫描模式
1 ADC简介 1 ADC(模拟到数字量的桥梁) 2 DAC(数字量到模拟的桥梁),例如:PWM(只有完全导通和断开的状态,无功率损耗的状态) DAC主要用于波形生成(信号发生器和音频解码器) 3 模拟看门狗自动监…...

R语言绘制散点图
散点图是一种在直角坐标系中用数据点直观呈现两个变量之间关系、可检测异常值并探索数据分布的可视化图表。它是一种常用的数据可视化工具,我们通过不同的参数调整和包的使用,可以创建出满足各种需求的散点图。 常用绘制散点图的函数有plot()函数和ggpl…...

安装最新 MySQL 8.0 数据库(教学用)
安装 MySQL 8.0 数据库(教学用) 文章目录 安装 MySQL 8.0 数据库(教学用)前言MySQL历史一、第一步二、下载三、安装四、使用五、语法总结 前言 根据 DB-Engines 网站的数据库流行度排名(2024年)࿰…...
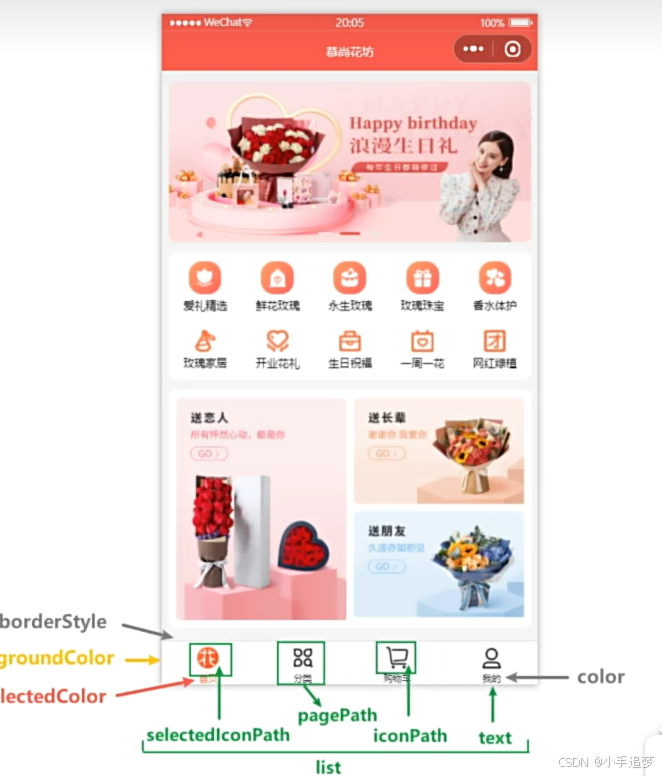
微信小程序开发-配置文件详解
文章目录 一,小程序创建的配置文件介绍二,配置文件-全局配置-pages 配置作用:注意事项:示例: 三,配置文件-全局配置-window 配置示例: 四,配置文件-全局配置-tabbar 配置核心作用&am…...

TCP/UDP初识
TCP是面向连接的、可靠的、基于字节流的传输层协议。 面向连接:一定是一对一连接,不能像 UDP 协议可以一个主机同时向多个主机发送消息 可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端…...

【大数据】在线分析、近线分析与离线分析
文章目录 1. 在线分析(Online Analytics)定义特点应用场景技术栈 2. 近线分析(Nearline Analytics)定义特点应用场景技术栈 3. 离线分析(Offline Analytics)定义特点应用场景技术栈 总结 在线分析ÿ…...

【unity进阶知识9】序列化字典,场景,vector,color,Quaternion
文章目录 前言一、可序列化字典类普通字典简单的使用可序列化字典简单的使用 二、序列化场景三、序列化vector四、序列化color五、序列化旋转Quaternion完结 前言 自定义序列化的主要原因: 可读性:使数据结构更清晰,便于理解和维护。优化 I…...

传奇GOM引擎架设好进游戏后提示请关闭非法外挂,重新登录,如何处理?
今天在架设一个GOM引擎的版本时,进游戏之后刚开始是弹出一个对话框,提示请关闭非法外挂,重新登录,我用的是绿盟登陆器,同时用的也是绿盟插件,刚开始我以为是绿盟登录器的问题,于是就换成原版gom…...
视频写入类VideoWriter之标识视频编解码器函数fourcc()的使用)
OpenCV视频I/O(15)视频写入类VideoWriter之标识视频编解码器函数fourcc()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将 4 个字符拼接成一个 FourCC 代码。 在 OpenCV 中,fourcc() 函数用于生成 FourCC 代码,这是一种用于标识视频编解码器的…...

rust log选型
考察了最火的tracing。但是该模块不支持compact,仅支持根据时间进行rotate。 daily Creates a daily-rotating file appender. hourly Creates an hourly-rotating file appender. minutely Creates a minutely-rotating file appender. This will rotate the log…...

数据库-分库分表
什么是分库分表 分库分表是一种数据库优化策略。 目的:为了解决由于单一的库表数据量过大而导致数据库性能降低的问题 分库:将原来独立的数据库拆分成若干数据库组成 分表:将原来的大表(存储近千万数据的表)拆分成若干个小表 什么时候考虑分…...

基于SSM的校园社团管理系统的设计 社团信息管理 智慧社团管理社团预约系统 社团活动管理 社团人员管理 在线社团管理社团资源管理(源码+定制+文档)
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...

mRNA疫苗序列生物信息学分析:从密码子优化到免疫原性预测
1. 项目概述:解码两大mRNA疫苗的“核心蓝图”作为一名在生物信息学和基因组学领域摸爬滚打了十多年的“老码农”,我见过太多令人兴奋的数据集,但当我第一次在GitHub上看到这个名为“Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-se…...

对比直接使用厂商 API 体验 Taotoken 在路由容灾上的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在路由容灾上的价值 在开发依赖大模型能力的应用时,服务的连续性与稳定性是保障用…...

基于AI智能体的渗透测试框架:从自动化到智能协同的范式转变
1. 项目概述:一个面向渗透测试的智能体框架最近在整理自己的工具链时,发现了一个挺有意思的项目,叫GH05TCREW/pentestagent。乍一看这个名字,你可能会觉得这又是一个“缝合怪”式的自动化渗透工具,把Nmap、SQLmap之类的…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

Qdrant Python客户端全解析:从向量数据库连接到AI应用开发实战
1. 项目概述:从向量数据库到客户端,现代AI应用落地的关键拼图如果你最近在折腾大语言模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率已经听过“向量数据库”这个词了。简单来说,它就像一个专门为AI模型设…...

PCL2启动器离线登录按钮消失?5分钟快速修复指南
PCL2启动器离线登录按钮消失?5分钟快速修复指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否遇到过PCL2启动器离线登录按钮突然消失的困扰࿱…...

基于Claude API构建AI代码生成工具:从API封装到工程化实践
1. 项目概述与核心价值最近在开发者社区里,一个名为ashish200729/claude-code-source-code的项目标题引起了不小的讨论。乍一看,这个标题很容易让人产生误解,以为这是某个知名AI模型的源代码被公开了。但作为一名在软件开发和开源领域摸爬滚打…...

构建轻量级应用沙盒:Microverse原理与实践指南
1. 项目概述:一个轻量级、可移植的“微宇宙”开发沙盒最近在折腾一些边缘计算和嵌入式AI应用的原型验证,经常遇到一个头疼的问题:开发环境和部署环境不一致。在本地笔记本上跑得好好的Python脚本,放到树莓派或者Jetson Nano上&…...

【STC8H】GPIO模式深度解析:从准双向到推挽,如何精准控制外设
1. STC8H的GPIO模式全景解析 第一次接触STC8H的GPIO配置时,我被那个神秘的PxM0和PxM1寄存器搞得晕头转向。直到有一次调试I2C通讯失败,才发现是开漏模式配置错误。这次教训让我明白,理解GPIO的四种工作模式,就像掌握不同武器的使用…...

AI编码工具选型指南:从原理到实践的全方位解析
1. 项目概述:为什么我们需要一份AI编码工具的“藏宝图”如果你是一名开发者,过去一年里,你的工作流可能已经被AI工具彻底重塑了。从最初用ChatGPT写几行注释,到后来用GitHub Copilot自动补全整段代码,再到如今各种能直…...