如何用python抓取豆瓣电影TOP250
1.如何获取网站信息?
(1)调用requests库、bs4库
#检查库是否下载好的方法:打开终端界面(terminal)输入pip install bs4,
如果返回的信息里有Successfully installed bs4 说明安装成功(requests同理)
from bs4 import BeautifulSoup
import requests(2)访问网站
import requests
response = requests.get("https://movie.douban.com/top250")
print(response.status_code) #HTTP状态响应码
if response.ok:print(response.text)
else:print("请求失败")输出结果:
418
请求失败
无法访问原因:
有些网站会检查请求的 User-Agent,如果没有提供合适的 User-Agent,可能会拒绝访问。
(3)添加 User-Agent 头部
打开网站->右键->检查->network

刷新网页—>点击任意一个模块—>在headers一栏找到"User-Agent"—>复制冒号后面的内容

headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 SE 2.X MetaSr 1.0"
}
response = requests.get("https://movie.douban.com/top250",headers=headers)(4)判断网站是否响应
如果状态码为200说明访问成功
import requests
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 SE 2.X MetaSr 1.0"
}
response = requests.get("https://movie.douban.com/top250",headers=headers)
print(response.status_code) #HTTP状态响应码
if response.ok:print(response.text)
else:print("请求失败")2.如何筛选出标题?
(1)分析网站的html文本
找出标题所在html文本的特点:

使用findAll函数筛选
response = requests.get("https://movie.douban.com/top250",headers=headers)
content = response.text
soup = BeautifulSoup(content, "html.parser")
all_titles = soup.findAll("span", attrs={"class": "title"})
for t in all_titles:print(t.string)输出结果:此时输出的标题不仅有中文标题还有原版标题
肖申克的救赎
/ The Shawshank Redemption
霸王别姬
阿甘正传
/ Forrest Gump
泰坦尼克号
/ Titanic
千与千寻
/ 千と千尋の神隠し
这个杀手不太冷
/ Léon
美丽人生
/ La vita è bella
星际穿越
/ Interstellar
盗梦空间
/ Inception
楚门的世界
/ The Truman Show
辛德勒的名单
/ Schindler's List
忠犬八公的故事
/ Hachi: A Dog's Tale
海上钢琴师
/ La leggenda del pianista sull'oceano
三傻大闹宝莱坞
/ 3 Idiots
放牛班的春天
/ Les choristes
机器人总动员
/ WALL·E
疯狂动物城
/ Zootopia
无间道
/ 無間道
控方证人
/ Witness for the Prosecution
大话西游之大圣娶亲
/ 西遊記大結局之仙履奇緣
熔炉
/ 도가니
教父
/ The Godfather
触不可及
/ Intouchables
当幸福来敲门
/ The Pursuit of Happyness
寻梦环游记
/ CocoProcess finished with exit code 0
如何筛选出中文标题:
all_titles = soup.findAll("span", attrs={"class": "title"})for t in all_titles:str = t.stringif "/" not in str: #筛选出中文标题print(str)
运行结果:
肖申克的救赎
霸王别姬
阿甘正传
泰坦尼克号
千与千寻
这个杀手不太冷
美丽人生
星际穿越
盗梦空间
楚门的世界
辛德勒的名单
忠犬八公的故事
海上钢琴师
三傻大闹宝莱坞
放牛班的春天
机器人总动员
疯狂动物城
无间道
控方证人
大话西游之大圣娶亲
熔炉
教父
触不可及
当幸福来敲门
寻梦环游记
3.如何爬取250个电影标题?
首先观察网址链接,找出不同点:
“https://movie.douban.com/top250?start=0&filter=”
“https://movie.douban.com/top250?start=25&filter=”
“https://movie.douban.com/top250?start=50&filter=”
......
“https://movie.douban.com/top250?start=175&filter=”
“https://movie.douban.com/top250?start=200&filter=”
“https://movie.douban.com/top250?start=225&filter=”
特点:网站总共有十页,每一页网址链接只有"start="后面的数字不一样
而数字正是每一页网页的第一个电影的索引,而每一页一共25个电影,因此可以才用for循环来访问这十个不同的网址:
for start_num in range(0,250,25): #第一个电影索引是0,第二个电影索引是249,每页网页有25个电影response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers)最终代码:
from bs4 import BeautifulSoup
import requests
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 SE 2.X MetaSr 1.0"
}
for start_num in range(0,250,25): #第一个电影索引是0,第二个电影索引是249,每页网页有25个电影response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers)content = response.textsoup = BeautifulSoup(content, "html.parser")all_titles = soup.findAll("span", attrs={"class": "title"})for t in all_titles:str = t.stringif "/" not in str: #筛选出中文标题print(str)
response.close() #关掉response相关文章:
如何用python抓取豆瓣电影TOP250
1.如何获取网站信息? (1)调用requests库、bs4库 #检查库是否下载好的方法:打开终端界面(terminal)输入pip install bs4, 如果返回的信息里有Successfully installed bs4 说明安装成功(request…...

鸽笼原理与递归 - 离散数学系列(四)
目录 1. 鸽笼原理 鸽笼原理的定义 鸽笼原理的示例 鸽笼原理的应用 2. 递归的定义与应用 什么是递归? 递归的示例 递归与迭代的对比 3. 实际应用 鸽笼原理的实际应用 递归的实际应用 4. 例题与练习 例题1:鸽笼原理应用 例题2:递归…...

Ubuntu 20.04常见配置(含yum源替换、桌面安装、防火墙设置、ntp配置)
Ubuntu 20.04常见配置 1. yum源配置2. 安装桌面及图形化2.1 安装图形化桌面2.1.1 选择安装gnome桌面2.1.2 选择安装xface桌面 2.2 安装VNC-Server 3. ufw防火墙策略4. 时区设置及NTP时间同步4.1 时区设置4.2 NTP安装及时间同步4.2.1 服务端(例:172.16.32…...

AI学习指南深度学习篇-生成对抗网络的基本原理
AI学习指南深度学习篇-生成对抗网络的基本原理 引言 生成对抗网络(Generative Adversarial Networks, GANs)是近年来深度学习领域的一个重要研究方向。GANs通过一种创新的对抗训练机制,能够生成高质量的样本,其应用范围广泛&…...

什么是网络安全
网络安全是指通过采取必要措施,防范对网络的攻击、侵入、干扰、破坏和非法使用以及意外事故,使网络处于稳定可靠运行的状态,以及保障网络数据的完整性、保密性、可用性的能力。 网络安全涉及多个层面,包括硬件、软件及其系统中数…...

Redis list 类型
list类型 类型介绍 列表类型 list 相当于 数组或者顺序表 list内部的编码方式更接近于 双端队列 ,支持头插 头删 尾插 尾删。 需要注意的是,Redis的下标支持负数下标。 比如数组大小为5,那么要访问下标为 -2 的值可以理解为访问 5 - 2 3 …...

Linux更改固定IP地址
1.VMware里更改虚拟网络 一: 二: 三:确定就好了 2.修改Linux系统的固定IP 一:进入此文件 效果如下: 执行以下命令: 此时IP已更改 3.远程连接 这个是前提!!! 更改网络编辑器后网络适配器可能会修改,我就是遇着这个,困住我了一会 一:可以以主机IP对应连接 连接成功 二:主机名连…...

Qt+大恒相机回调图片刷新使用方式
一、前言 上篇文章介绍了如何调用大恒SDK获得回调图片,这篇介绍如何使用这些图片并刷新到界面上。考虑到相机的帧率很高,比如200fps是很高的回调频率。那么我们的刷新频率是做不到这么快,也没必要这么快。一般刷新在60帧左右就够了。 二、思路…...

Docker 环境下 PostgreSQL 监控实战:从 Exporter 到 Prometheus 的部署详解
Docker 环境下 PostgreSQL 监控实战:从 Exporter 到 Prometheus 的部署详解 文章目录 Docker 环境下 PostgreSQL 监控实战:从 Exporter 到 Prometheus 的部署详解一 节点简述二 节点监控部署1)创建 PostgreSQL 的 exporter 账号2)…...

构建带有调试符号的srsRAN 4G
### 构建带有调试符号 首先确保已下载srsRAN 4G,并已创建并导航至构建文件夹: bash git clone https://github.com/srsran/srsran_4g.git cd srsRAN_4G mkdir build cd build 若srsRAN 4G已构建完成,应清除原有构建文件夹后继续。 可以使…...
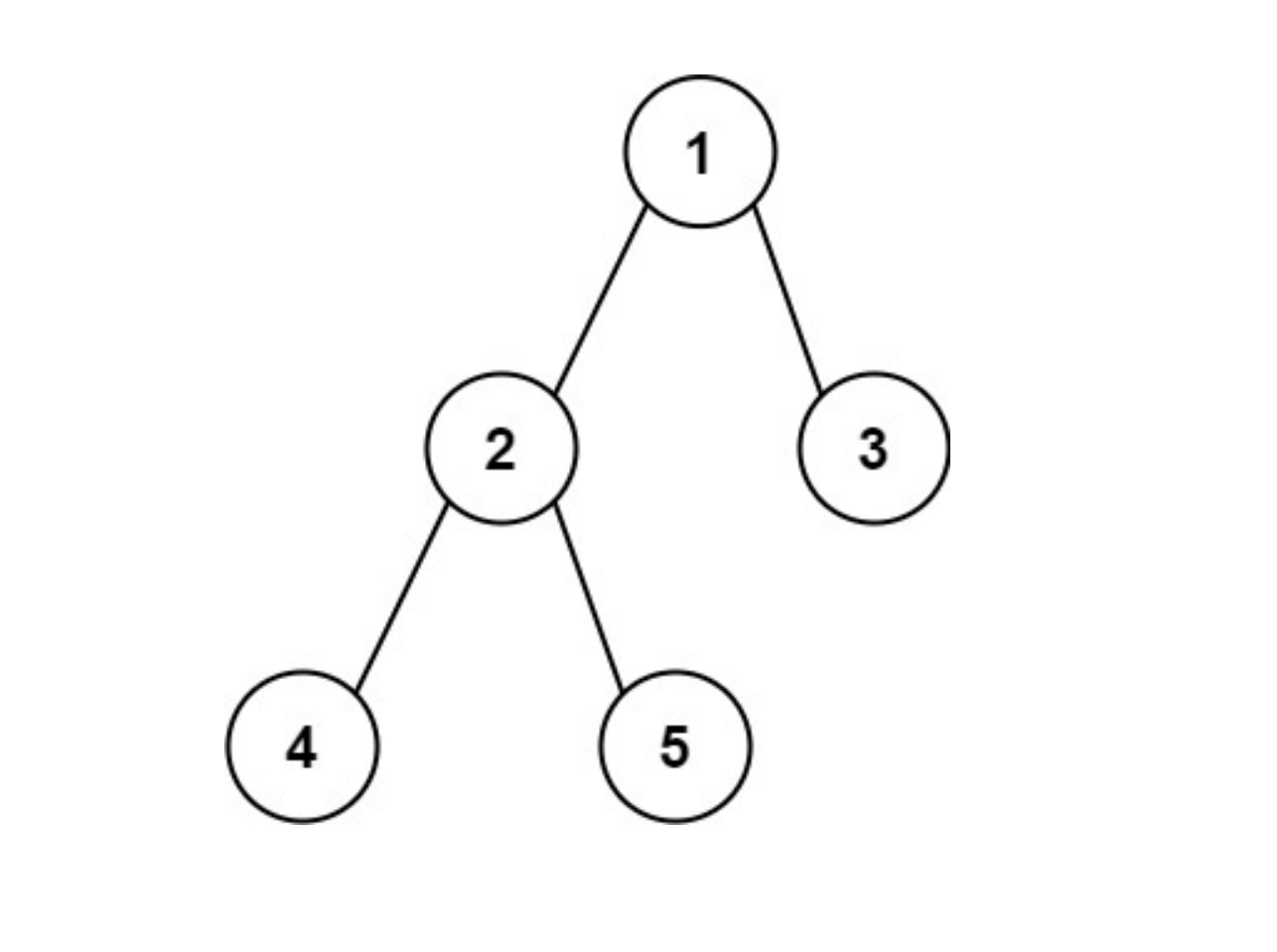
算法题总结(十)——二叉树上
#二叉树的递归遍历 // 前序遍历递归LC144_二叉树的前序遍历 class Solution {public List<Integer> preorderTraversal(TreeNode root) {List<Integer> result new ArrayList<Integer>(); //也可以把result 作为全局变量,只需要一个函数即可。…...

【MySQL】MySQL 数据库主从复制详解
目录 1. 基本概念1.1 主从架构1.2 复制类型 2. 工作原理2.1 复制过程2.2 主要组件 3. 配置步骤3.1 准备工作3.2 在主服务器上配置3.3 在从服务器上配置 4. 监控和维护4.1 监控复制状态4.2 处理复制延迟4.3 故障恢复 5. 备份策略5.1 逻辑备份与物理备份5.2 增量备份 6. 使用场景…...

一种格式化printf hex 数据的方法
格式化输出HEX数据 调试过程中通常需要个格式化输出16进制数据,为了方便美观可以参考如下方法。 #define __is_print(ch) ((unsigned int)((ch) - ) < 127u - )/*** dump_hex* * brief hex打印* * param buf: 需要打印的原始数据* param size: 原始数据类型*…...
在LabVIEW中如何读取EXCEL
在LabVIEW中读取Excel文件通常使用“报告生成工具包”(Report Generation Toolkit)。以下是详细步骤: 安装工具包:确保已安装“报告生成工具包”。这通常随LabVIEW一起提供,但需要单独安装。 创建VI: 打…...

布匹瑕疵检测数据集 4类 2800张 布料缺陷 带标注 voc yolo
布匹瑕疵检测数据集 4类 2800张 布料缺陷 带标注 voc yolo 对应标注,格式VOC (XML),选配Y0L0(TXT) label| pic_ num| box_ _num hole: (425, 481) suspension_ wire: (1739, 1782) topbasi: (46, 46) dirty: (613&…...

灵动微高集成度电机MCU单片机
由于锂电技术的持续进步、消费者需求的演变、工具种类的革新以及应用领域的扩展,电动工具行业正呈现出无绳化、锂电化、大功率化、小型化、智能化和一机多能化的发展趋势。无绳化和锂电化的电动工具因其便携性和高效能的特性,已成为市场增长的重要驱动力…...

陪护小程序|护理陪护系统|陪护小程序成品
智能化,作为智慧医疗宏伟蓝图的基石,正引领着一场医疗服务的深刻变革。在这场变革的浪潮中,智慧医院小程序犹如璀璨新星,迅速崛起,而陪护小程序的诞生,更是如春风化雨,细腻地触及了老年病患、家…...

【JVM】基础篇
1 初识JVM 1.1 什么是JVM JVM 全称是 Java Virtual Machine,中文译名 Java虚拟机。JVM 本质上是一个运行在计算机上的程序,他的职责是运行Java字节码文件。 Java源代码执行流程如下: 分为三个步骤: 1、编写Java源代码文件。 …...

软件测试工程师 朝哪里进阶?
软件测试工程师 朝哪里进阶? 这里浅谈一下我的看法。 软件测试工程师 朝哪里进阶呢? 当我们测试工程师工作了2-3年后,就需要往前走往高走,就像一句名言说的:我们需要像ceo一样工作。 将自己的边界扩大一点࿰…...

Obsidian Plugin Release Pre-check
- [ ] 修改代码 - [ ] 修改README.md - [ ] 修改manifest.json - [ ] --将上述修改push到GitHub-- - [ ] 修改release版本 git tag git tag -a 1.0.6 -m "1.0.6" git push origin 1.0.6 ------------------------------------------- 备忘https://semver.org/lang/…...
怎么选,告别‘卖家秀’惨案)
从LED灯珠到手机屏幕:一文搞懂色温、显色指数(CRI)怎么选,告别‘卖家秀’惨案
从LED灯珠到手机屏幕:色温与显色指数的科学选购指南 深夜伏案工作时,你是否总觉得眼睛干涩疲劳?网购衣物到手后颜色总与屏幕显示相差甚远?餐厅美食拍出来总是暗淡无光?这些困扰的根源往往在于——光源质量。当我们面对…...

texgen.js扩展开发终极指南:如何自定义纹理生成器和滤镜
texgen.js扩展开发终极指南:如何自定义纹理生成器和滤镜 【免费下载链接】texgen.js JavaScript Texture Generator 项目地址: https://gitcode.com/gh_mirrors/te/texgen.js texgen.js 是一个功能强大的JavaScript纹理生成器库,它让开发者能够通…...

基于大语言模型的智能购物助手:从架构设计到工程实现
1. 项目概述:当AI遇上电商,一个“懂你”的购物助手如何炼成最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“KudoAI/amazongpt”。光看名字,你大概能猜到它和亚马逊(Amazon)以及GPT有关。没…...

Ollama客户端开发指南:构建本地大模型交互工具的核心原理与实践
1. 项目概述:一个与Ollama对话的客户端工具如果你正在本地运行像Llama 3、Mistral或者Qwen这类开源大语言模型,那么Ollama这个名字对你来说一定不陌生。它让部署和管理这些模型变得像在命令行里敲几个单词一样简单。但Ollama本身主要是一个服务端工具&am…...

城通网盘直连解析终极指南:告别龟速下载的完整解决方案
城通网盘直连解析终极指南:告别龟速下载的完整解决方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘缓慢的下载速度而烦恼吗?ctfileGet是你的完美解决方案&…...

音频处理中的头部空间标准化:原理、工具与工程实践
1. 项目概述:一个为音频处理而生的“头部空间”工具如果你经常处理音频,尤其是人声干音,那你一定对“头部空间”这个概念不陌生。简单来说,它指的是人声录音中,人声峰值电平与数字满刻度(0 dBFS)…...

气体放电管实战指南:从关键参数到电路防护的精准匹配
1. 气体放电管:电路防护的"安全气囊" 第一次接触气体放电管时,我就被它简单却巧妙的设计所吸引。这玩意儿就像汽车的安全气囊——平时默默无闻,关键时刻却能救你一命。气体放电管(GDT)本质上是个陶瓷或玻璃…...

基于RAG的Obsidian智能知识库:本地部署与优化实战
1. 项目概述:当知识管理遇上大语言模型 如果你和我一样,是 Obsidian 的深度用户,同时又对大语言模型(LLM)的智能涌现能力感到着迷,那么你肯定也想过一个问题:能不能让我的知识库“活”起来&…...

GeoJSON世界地图数据实战指南:从数据获取到高级可视化
GeoJSON世界地图数据实战指南:从数据获取到高级可视化 【免费下载链接】world.geo.json Annotated geo-json geometry files for the world 项目地址: https://gitcode.com/gh_mirrors/wo/world.geo.json 想要构建专业级的地理信息可视化应用却苦于找不到高质…...

轨道交通条形屏电源技术分析:超薄化与高可靠性的工程平衡
一、行业背景与技术挑战在智慧城轨建设中,地铁站内条形屏是乘客信息显示系统的核心终端设备。该应用场景对配套电源提出以下技术要求:技术需求具体指标工程挑战超薄化整机厚度3-8mm传统变压器/散热器高度难以压缩高可靠性MTBF≥50000小时轨道交通振动、温…...