4个顶级的大模型推理引擎
LLM 在文本生成应用中表现出色,例如具有高理解度和流畅度的聊天和代码完成模型。然而,它们的庞大规模也给推理带来了挑战。基本推理速度很慢,因为 LLM 会逐个生成文本标记,需要对每个下一个标记进行重复调用。随着输入序列的增长,处理时间也会增加。此外,LLM 有数十亿个参数,很难在内存中存储和管理所有这些权重。
为了优化 LLM 推理和服务,有多个框架和软件包,在本博客中,我将使用和比较以下推理引擎:TensorRT-LLM、vLLM、LMDeploy 和 MLC-LLM。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、TensorRT-LLM
TensorRT-LLM 是另一个推理引擎,可加速和优化 NVIDIA GPU 上最新 LLM 的推理性能。 LLM 被编译到 TensorRT Engine 中,然后与 triton 服务器一起部署,以利用推理优化,例如 In-Flight Batching(减少等待时间并允许更高的 GPU 利用率)、分页 KV 缓存、MultiGPU-MultiNode 推理和 FP8 支持。
我们将比较 HF 模型、TensorRT 模型和 TensorRT-INT8 模型(量化)的执行时间、ROUGE 分数、延迟和吞吐量。
你需要为你的 Linux 系统安装 Nvidia-container-toolkit,初始化 Git LFS(以下载 HF 模型),并下载必要的软件包,如下所示:
!curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
!apt-get update
!git clone https://github.com/NVIDIA/TensorRT-LLM/
!apt-get update && apt-get -y install python3.10 python3-pip openmpi-bin libopenmpi-dev
!pip3 install tensorrt_llm -U --pre --extra-index-url https://pypi.nvidia.com
!pip install -r TensorRT-LLM/examples/phi/requirements.txt
!pip install flash_attn pytest
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
!apt-get install git-lfs现在检索模型权重:
PHI_PATH="TensorRT-LLM/examples/phi"
!rm -rf $PHI_PATH/7B
!mkdir -p $PHI_PATH/7B && git clone https://huggingface.co/microsoft/Phi-3-small-128k-instruct $PHI_PATH/7B将模型转换为 TensorRT-LLM 检查点格式并从检查点构建 TensorRT-LLM。
!python3 $PHI_PATH/convert_checkpoint.py --model_dir $PHI_PATH/7B/ \--dtype bfloat16 \--output_dir $PHI_PATH/7B/trt_ckpt/bf16/1-gpu/
# Build TensorRT-LLM model from checkpoint
!trtllm-build --checkpoint_dir $PHI_PATH/7B/trt_ckpt/bf16/1-gpu/ \--gemm_plugin bfloat16 \--output_dir $PHI_PATH/7B/trt_engines/bf16/1-gpu/类似地,现在将 INT8 仅权重量化应用于 HF 模型并将检查点转换为 TensorRT-LLM。
!python3 $PHI_PATH/convert_checkpoint.py --model_dir $PHI_PATH/7B \--dtype bfloat16 \--use_weight_only \--output_dir $PHI_PATH/7B/trt_ckpt/int8_weight_only/1-gpu/
!trtllm-build --checkpoint_dir $PHI_PATH/7B/trt_ckpt/int8_weight_only/1-gpu/ \--gemm_plugin bfloat16 \--output_dir $PHI_PATH/7B/trt_engines/int8_weight_only/1-gpu/现在在总结任务上测试基础 phi3 和两个 TensorRT 模型:
%%capture phi_hf_results
# Huggingface
!time python3 $PHI_PATH/../summarize.py --test_hf \--hf_model_dir $PHI_PATH/7B/ \--data_type bf16 \--engine_dir $PHI_PATH/7B/trt_engines/bf16/1-gpu/
%%capture phi_trt_results
# TensorRT-LLM
!time python3 $PHI_PATH/../summarize.py --test_trt_llm \--hf_model_dir $PHI_PATH/7B/ \--data_type bf16 \--engine_dir $PHI_PATH/7B/trt_engines/bf16/1-gpu/
%%capture phi_int8_results
# TensorRT-LLM (INT8)
!time python3 $PHI_PATH/../summarize.py --test_trt_llm \--hf_model_dir $PHI_PATH/7B/ \--data_type bf16 \--engine_dir $PHI_PATH/7B/trt_engines/int8_weight_only/1-gpu/现在,在捕获结果后,你可以解析输出并绘制它以比较所有模型的执行时间、ROUGE 分数、延迟和吞吐量。

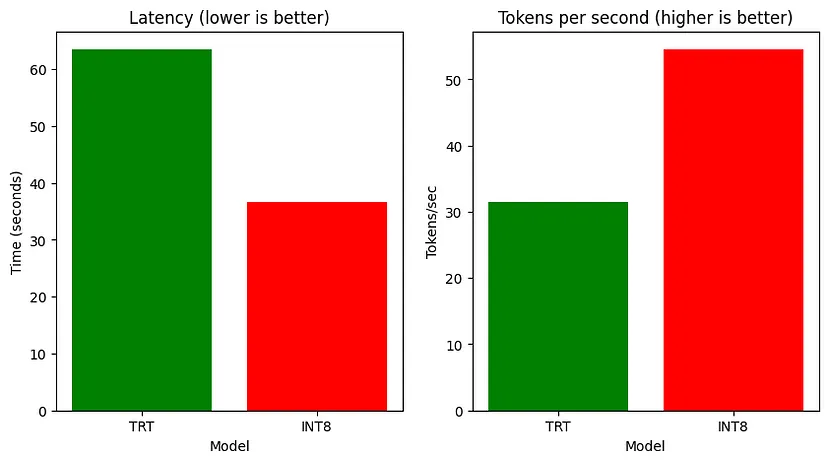
延迟和吞吐量的比较
2、vLLM
vLLM 提供 LLM 推理和服务,具有 SOTA 吞吐量、分页注意、连续批处理、量化(GPTQ、AWQ、FP8)和优化的 CUDA 内核。
让我们评估 microsoft/Phi3-mini-4k-instruct 的吞吐量和延迟。首先设置依赖项并导入库。
!pip install -q vllm
!git clone https://github.com/vllm-project/vllm.git
!pip install -q datasets
!pip install transformers scipy
from vllm import LLM, SamplingParams
from datasets import load_dataset
import time
from tqdm import tqdm
from transformers import AutoTokenizer现在让我们加载模型并在数据集的一小部分上生成其输出。
dataset = load_dataset("akemiH/MedQA-Reason", split="train").select(range(10))
prompts = []
for sample in dataset:prompts.append(sample)
sampling_params = SamplingParams(max_tokens=524)
llm = LLM(model="microsoft/Phi-3-mini-4k-instruct", trust_remote_code=True)
def generate_with_time(prompt):start = time.time()outputs = llm.generate(prompt, sampling_params)taken = time.time() - startgenerated_text = outputs[0].outputs[0].textreturn generated_text, taken
generated_text = []
time_taken = 0
for sample in tqdm(prompts):text, taken = generate_with_time(sample)time_taken += takengenerated_text.append(text)# Tokenize the outputs and calculate the throughput
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
token = 1
for sample in generated_text:tokens = tokenizer(sample)tok = len(tokens.input_ids)token += tok
print(token)
print("tok/s", token // time_taken)![]()
我们还通过 ShareGPT 数据集上的 vLLM 对模型的性能进行基准测试
!wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
%cd vllm
!python benchmarks/benchmark_throughput.py --backend vllm --dataset ../ShareGPT_V3_unfiltered_cleaned_split.json --model microsoft/Phi-3-mini-4k-instruct --tokenizer microsoft/Phi-3-mini-4k-instruct --num-prompts=1000
3、LMDeploy
此软件包还允许压缩、部署和服务 LLM,同时提供高效推理(持久批处理、块 KV 缓存、动态拆分和融合、张量并行、高性能 CUDA 内核)、有效量化(4 位推理性能比 FP16 高 2.4 倍)、轻松的分发服务器(跨多台机器和卡部署多模型服务)和交互式推理模式(记住对话历史并避免重复处理历史会话)。此外,它还允许分析令牌延迟和吞吐量、请求吞吐量、API 服务器和 triton 推理服务器性能。
安装依赖项并导入包:
!pip install -q lmdeploy
!pip install nest_asyncio
import nest_asyncio
nest_asyncio.apply()!git clone --depth=1 https://github.com/InternLM/lmdeploy
%cd lmdeploy/benchmarkLMdeploy 开发了两个推理引擎 TurboMind 和 PyTorch。
让我们在 microsoft/Phi3-mini-128k-instruct 上分析一下 PyTorch 引擎。
!python3 profile_generation.py microsoft/Phi-3-mini-128k-instruct --backend pytorch它在多轮中对引擎进行分析,并报告每轮的令牌延迟和吞吐量。

Pytorch 引擎配置文件,用于标记延迟和吞吐量
4、MLC-LLM
MLC-LLM 提供高性能部署和推理引擎,称为 MLCEngine。
让我们安装依赖项,包括使用 conda 设置依赖项和创建 conda 环境。然后克隆 git 存储库并进行配置。
conda activate your-environment
python -m pip install --pre -U -f https://mlc.ai/wheels mlc-llm-nightly-cu121 mlc-ai-nightly-cu121
conda env remove -n mlc-chat-venv
conda create -n mlc-chat-venv -c conda-forge \"cmake>=3.24" \rust \git \python=3.11
conda activate mlc-chat-venv
git clone --recursive https://github.com/mlc-ai/mlc-llm.git && cd mlc-llm/
mkdir -p build && cd build
python ../cmake/gen_cmake_config.py
cmake .. && cmake --build . --parallel $(nproc) && cd ..
set(USE_FLASHINFER ON)
conda activate your-own-env
cd mlc-llm/python
pip install -e .要使用 MLC LLM 运行模型,我们需要将模型权重转换为 MLC 格式。通过 Git LFS 下载 HF 模型,然后转换权重。
mlc_llm convert_weight ./dist/models/Phi-3-small-128k-instruct/ \--quantization q0f16 \--model-type "phi3" \-o ./dist/Phi-3-small-128k-instruct-q0f16-MLC现在将你的 MLC 格式模型加载到 MLC 引擎中:
from mlc_llm import MLCEngine
# Create engine
model = "HF://mlc-ai/Phi-3-mini-128k-instruct-q0f16-MLC"
engine = MLCEngine(model)# Now let’s calculate throughput
import time
from transformers import AutoTokenizer
start = time.time()
response = engine.chat.completions.create(messages=[{"role": "user", "content": "What is the Machine Learning?"}],model=model,stream=False,
)
taken = time.time() - start
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-128k-instruct")
print("tok/s", 82 // taken)![]()
5、结束语
TensorRT INT8 模型在推理速度方面优于 HF 模型和常规 TensorRT,而常规 TensorRT 模型在总结任务上表现更好,在三个模型中 ROUGE 得分最高。LMDeploy 在 A100 上提供的请求吞吐量比 vLLM 高出 1.8 倍。
原文链接:4个顶级LLM推理引擎 - BimAnt
相关文章:

4个顶级的大模型推理引擎
LLM 在文本生成应用中表现出色,例如具有高理解度和流畅度的聊天和代码完成模型。然而,它们的庞大规模也给推理带来了挑战。基本推理速度很慢,因为 LLM 会逐个生成文本标记,需要对每个下一个标记进行重复调用。随着输入序列的增长&…...

Oracle中ADD_MONTHS()函数详解
文章目录 前言一、ADD_MONTHS()的语法二、主要用途三、测试用例总结 前言 在Oracle数据库中,ADD_MONTHS()函数用于在日期中添加指定的月数。 一、ADD_MONTHS()的语法 ADD_MONTHS(date, n) 其中,date是一个日期值,n是一个整数值,…...

【SQL】掌握SQL查询技巧:高效数据整合与查询优化
目录 1. SQL 的基本构成2. SQL 联接(JOIN)2.1 内联接(INNER JOIN)2.2 外联接(OUTER JOIN)2.2.1 左外联接(LEFT JOIN)2.2.2 右外联接(RIGHT JOIN)2.2.3 全外联…...

一个月学会Java 第5天 控制结构
Day5 控制结构 这么叫可能有些就算有基础的人也看不懂,其实就是if-else、switch-case、for、while、do-while这几个,没基础的听到了这个也不要慌张,这几个是程序的基础,多多训练就好 第一章 顺序结构 这章其实没有什么好讲的&…...
参赛项目介绍内容模拟示例参考)
世界职业院校技能大赛(大数据技术与应用)参赛项目介绍内容模拟示例参考
最近关注世界职业院校技能大赛的同学应该都知道了,比赛已经正式改为”世界职业院校技能大赛“了,不仅仅是名称变化,而且比赛的形式也发生了巨大的改革,2024年世界职业院校技能大赛设置42个赛道,要求各比赛项目提交项目…...

【Python】文件及目录
文章目录 概要一、文件对象的函数1.1 open()函数1.2 文件对象的函数1.3 with语句 二、基于os和os.path模块的目录操作三、基于Pandas的文件处理3.1 Pandas读写各种类型文件 其他章节的内容 概要 本文主要将了打开文件的函数open()的参数,以及文件对象的函数&#x…...

OpenHarmony(鸿蒙南向开发)——标准系统方案之瑞芯微RK3566移植案例(下)
往期知识点记录: 鸿蒙(HarmonyOS)应用层开发(北向)知识点汇总 鸿蒙(OpenHarmony)南向开发保姆级知识点汇总~ 持续更新中…… 概述 OpenHarmony Camera驱动模型结构 HDI Implementation&#x…...

霓虹灯数字时钟(可复制源代码)
文章目录 一、效果演示二、CodeHTMLCSSJavaScript 三、实现思路拆分CSS 部分JavaScript 部分 四、源代码 一、效果演示 文末可一键复制完整代码 二、Code HTML <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><…...

大模型微调技术之 LoRA:开启高效微调新时代
一、LoRA 简介 LoRA,即低秩适应(Low-Rank Adaptation),是一种用于微调大型语言模型的技术,旨在以较小的计算资源和数据量实现模型的快速适应特定任务或领域。 LoRA 方法通过引入低秩近似的思想,对大型预训…...
)
【Vue】Vue2(2)
文章目录 1 数据代理1.1 回顾Object.defineproperty方法1.2 何为数据代理1.3 Vue中的数据代理 2 事件处理2.1 事件的基本使用2.2 事件修饰符2.3 键盘事件 1 数据代理 1.1 回顾Object.defineproperty方法 <!DOCTYPE html> <html><head><meta charset&quo…...

如何实现一个基于 HTML+CSS+JS 的任务进度条
如何实现一个基于 HTMLCSSJS 的任务进度条 在网页开发中,任务进度条是一种常见的 UI 组件,它可以直观地展示任务的完成情况。本文将向你展示如何使用 HTML CSS JavaScript 来创建一个简单的、交互式的任务进度条。用户可以通过点击进度条的任意位置来…...
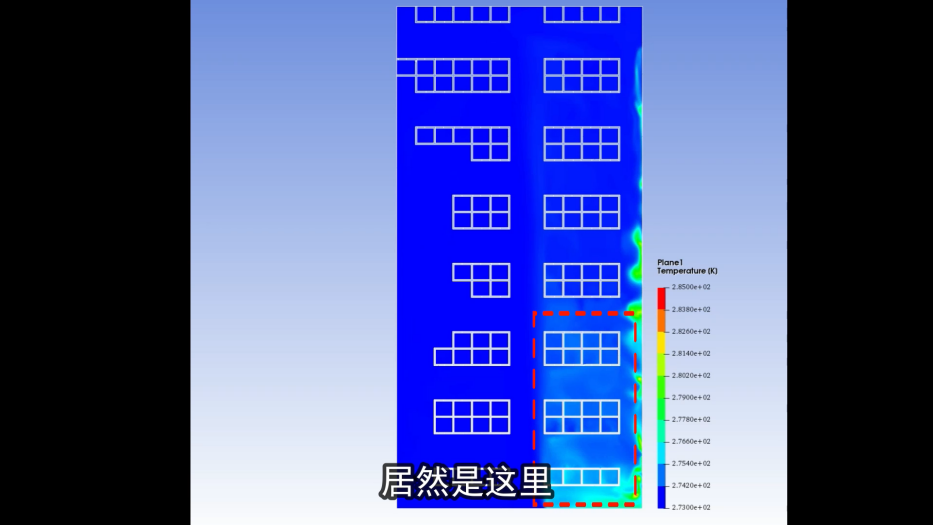
学会流体力学,冬天洗澡再也不冷啦
前些日子收到一位网友“究极理性怪物”的私信,说最近在学校的公共浴室洗澡时,快被冻死了,希望我从流体力学角度帮他分析一下浴室的温度分布,以便找到相对温暖的洗澡位置。 我看到后觉得很有意思,就与他展开了关于澡堂…...

WPF下使用FreeRedis操作RedisStream实现简单的消息队列
Redis Stream简介 Redis Stream是随着5.0版本发布的一种新的Redis数据类型: 高效消费者组:允许多个消费者组从同一数据流的不同部分消费数据,每个消费者组都能独立地处理消息,这样可以并行处理和提高效率。 阻塞操作:消费者可以设置阻塞操作,这样它们会在流中有新数据…...

踩坑NVTX
最开始在 【简说】NVTX Nsight Nvidia性能分析利器 看到NVTX的时候,我觉得这是一个好东西啊,可以详细说明每一段时间对应的是哪一段程序。 看了一下github,他的文章已经过时,现在已经不需要链接动态库了,直接includ…...

Ubuntu修改IP方法
方法一:通过图形化界面修改IP 打开网络设置: 点击桌面右上角的网络图标,然后选择“设置”或“网络设置”。 选择网络接口: 在网络设置窗口中,选择你正在使用的网络接口(有线或无线网络)。 进…...

C++——STL简介
目录 一、什么是STL 二、STL的版本 三、STL的六大组件 没用的话..... 不知不觉两个月没写博客了,暑假后期因为学校的事情在忙,开学又在准备学校的java免修,再然后才继续开始学C,然后最近打算继续写博客沉淀一下最近学到的几周…...

[linux] 磁盘清理相关
在 CentOS 7 中清理磁盘空间可以通过多种方法实现,以下是一些常用的步骤和命令: 1. 查找和删除大文件 你可以使用 find 命令查找占用大量空间的文件: find / -type f -size 100M 2>/dev/null这条命令会查找大于 100 MB 的文件。你可以根…...

【笔记】DDD领域驱动设计
同名读书笔记,对于一些自觉重要的点进行记录。 扩展资源:github.com/evancyz/ddd-learning UML中类图的一些基本知识 - jack_Meng - 博客园 最后的第四部分暂时没看 Part Two 模型驱动设计的构造块 Chapter 5 软件中所表示的模型 5.2 模式:…...
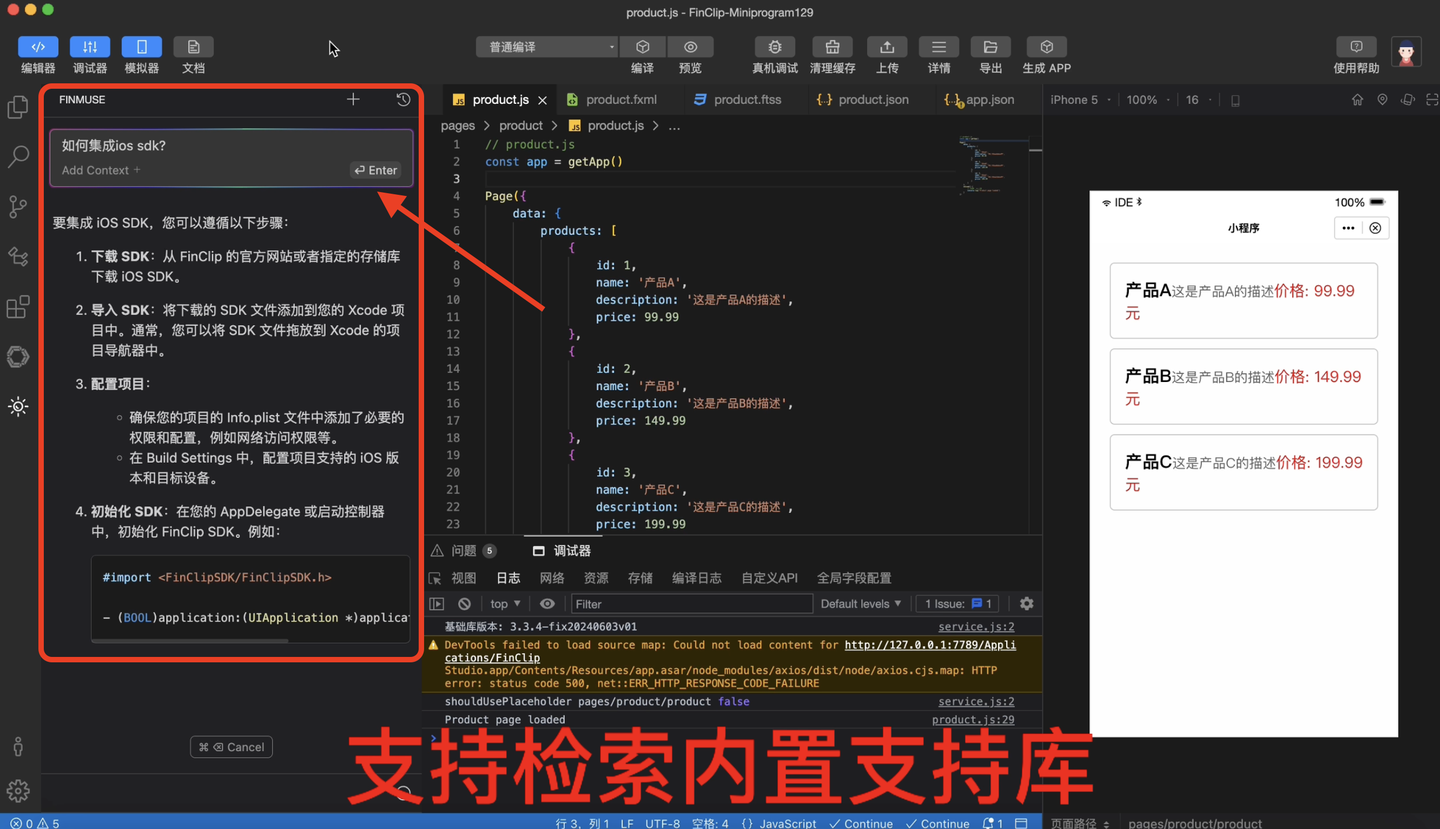
用AI构建小程序需要多久?效果如何?
随着移动互联网的快速发展,多端应用的需求日益增长。为了提高开发效率、降低成本并保证用户体验的一致性,前端跨端技术在如今的开发界使用已经非常普遍了,技术界较为常用的跨端技术有小程序技术、HTML5技术两大类。 2023年以来,伴…...

深度学习的应用综述
文章目录 引言深度学习的基本概念深度学习的主要应用领域计算机视觉自然语言处理语音识别强化学习医疗保健金融分析 深度学习应用案例公式1.损失函数(Loss Function) 结论 引言 深度学习是机器学习的一个子领域,通过模拟人脑的神经元结构来处理复杂的数据。近年来&…...

GHelper:华硕笔记本终极性能优化解决方案
GHelper:华硕笔记本终极性能优化解决方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertbook, RO…...

Deskreen:如何将任何浏览器设备变成你的第二屏幕?
Deskreen:如何将任何浏览器设备变成你的第二屏幕? 【免费下载链接】deskreen Deskreen turns any device with a web browser into a secondary screen for your computer. ⭐️ Star to support our work! 项目地址: https://gitcode.com/gh_mirrors/…...

2036年的病榻前,陪伴我的是“贾维斯”还是我的两个儿子?
《跨越银色浪潮:中国智慧养老的破局与重构》 9/10 老陈的“完美”养老局,在病床上破防了 老陈是以前一位年长的同事,搞了一辈子软件 。退休后,他给自己设计了一套堪称“完美”的养老方案 。 他老伴走得早,两个儿子又都在海外。于是,他的客厅里摆着最新款的陪伴机器人,…...

架构解密:如何通过FastExcel流式处理引擎重塑Java Excel操作效率标准
架构解密:如何通过FastExcel流式处理引擎重塑Java Excel操作效率标准 【免费下载链接】fastexcel Generate and read big Excel files quickly 项目地址: https://gitcode.com/gh_mirrors/fas/fastexcel 在当今数据驱动的企业环境中,Excel文件处理…...

113、MPC:非线性MPC与实时优化
113、MPC:非线性MPC与实时优化 从一次电机堵转说起 去年调试一个四足机器人单腿的力控,用的线性MPC,模型是简单的质量-弹簧-阻尼。空载跑得挺好,一上负载,电机堵转,电流直接爆表。查了半天,发现是关节摩擦力矩的非线性项在MPC的线性化模型里被忽略了——线性MPC把摩擦…...

一款多功能显示控制器芯片,FHD 120/144Hz,支持最高1920x1080@120Hz.
主要特性特性类别具体规格输入接口1VGA (模拟RGB)、1HDMI 1.4 (带HDCP1.4/2.2)、1DP1.2 组合接口 (兼容HDMI 1.4,带HDCP1.4/2.2)输出接口2 Port LVDS,支持8bit/10bit最大分辨率1920x1200100Hz 或 1920x1080120Hz (带ODC)色彩深度输入:6/8/10b…...

VBA添加超链接:Hyperlinks.Add 方法 完整参数解析
Worksheet.Hyperlinks.Add Cells(j 1, 11), ar(2, j), "", "单击打开:" & ar(1, j), ar(1, j) 每个参数解析、 VBA Hyperlinks.Add 方法 完整参数解析 你这句代码是Excel VBA 给单元格添加超链接的核心语句,我把 Hyperlinks.…...
)
RWKV vs Llama2:在论文审稿任务上,我们为什么第一版选了它?(附长上下文模型选型避坑指南)
RWKV与Llama2在论文审稿任务中的技术选型思考 当面对论文审稿这一知识密集型任务时,模型选型往往成为项目成败的关键。2023年第三季度,我们在构建首个论文审稿GPT系统时,曾在RWKV与Llama2之间面临艰难抉择。本文将深入剖析两种架构的核心差异…...

[全网首发]百万短剧CMS系统_支持全网网盘转存拉新
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 爱搜索正版管理系统安装教程 --------------------------------- 搭建要求环境如下 --------------------------------- 宝塔 --------------------------------- PHP7.2 Nginx 1.26.3 M…...

别再只写CRUD了!用SpringBoot+MySQL设计一个高并发预约挂号系统,这些架构细节你得知道
高并发预约挂号系统架构实战:SpringBootMySQL核心技术解析 1. 系统架构设计挑战与解决方案 在医疗信息化高速发展的今天,预约挂号系统作为医院服务的"第一窗口",其稳定性与性能直接影响患者就医体验。传统CRUD架构在面对挂号早高峰…...