大模型微调技术之 LoRA:开启高效微调新时代

一、LoRA 简介
LoRA,即低秩适应(Low-Rank Adaptation),是一种用于微调大型语言模型的技术,旨在以较小的计算资源和数据量实现模型的快速适应特定任务或领域。
LoRA 方法通过引入低秩近似的思想,对大型预训练语言模型的部分权重进行高效且轻量级的调整。在大型语言模型中,权重矩阵通常是高维且密集的,包含大量参数。LoRA 引入低秩矩阵,这些矩阵更小、更简单,但仍然能够捕获新任务所需的基本变化。例如,假设模型有一个 100 行 100 列的矩阵,需要存储 10000 个数字,而 LoRA 将矩阵分解成一个 1000x2 矩阵和一个 2x100 矩阵,只有 400 个数字需要存储,大大减少了参数量。
LoRA 主要对 Stable Diffusion 模型中最关键的交叉注意力层进行小的修改。研究人员发现,微调这部分模型就足以实现良好的训练。通过在交叉注意力层的权重矩阵中引入低秩矩阵,LoRA 可以在不显著影响模型性能的前提下,降低模型的存储需求和计算成本。
LoRA 的优势在于其高效性和灵活性。通过使用更少的参数,LoRA 显著降低了模型训练过程中的计算复杂性和显存使用量,使得在消费级 GPU 上训练大模型成为可能。同时,LoRA 可以提升模型的泛化性,防止在训练数据有限场景下的过拟合现象。此外,LoRA 可以无缝地集成到现有的神经网络架构中,以最小的额外训练成本对预训练模型进行微调和调整,非常适合迁移学习应用。
二、工作原理与关键技术要点

(一)低秩矩阵注入
在大型语言模型中,通常会在 Transformer 的注意力层等特定层引入一对低秩矩阵。以一个大型语言模型为例,假设其权重矩阵原本具有极高的维度,比如一个 的矩阵,直接微调整个模型所需的参数量巨大。而 LoRA 引入的低秩矩阵,矩阵 为 ,矩阵 为 ,其中秩 远小于基本矩阵维度 和 。这样一来,构建的参数量就大大减少了。比如,当原权重 的参数量为 时,若选择 LoRA 的秩 为 4,那么 和 的参数量均为 ,二者之和为 ,仅需训练 的参数就可以更新参数矩阵。
(二)微调过程
在微调阶段,LoRA 只训练低秩矩阵的参数,原模型的其他部分权重保持不变。通过在特定任务的数据集上对这些少量额外参数进行训练,可以引导模型有针对性地学习任务相关的语言模式和知识。比如在绘画应用 stable diffusion 中,LoRA 以插件的形式嵌入模型中,使得用户可以下载相对于原模型(GB 量级)更小的 LoRA 模型(MB 量级),从而达到调整生成图像风格的效果。在语言大模型 ChatGPT - 3 中,LoRA 可以优化它在特定领域的表现,如代码调试、法律咨询等领域。
(三)内存效率与计算效率
由于只需要训练一小部分参数,LoRA 在微调过程中显著降低了内存需求和计算成本。以 GPT - 3 175B 模型为例,原先需要 1.2TB 的显存才可以训练,使用 LoRA 后只需要 350GB 即可。当 设置为 4,且只调整 query 和 value 矩阵时,需要的显存进一步从 350GB 降至 35MB。在推理阶段,这些低秩矩阵可以在运行时动态地与原模型权重相加或相乘,无需改变模型结构或重新存储整个模型,进一步节省了资源。
三、应用与扩展
(一)NLP 任务应用
在自然语言处理任务中,LoRA 表现出了强大的适应性和高效性。例如,在文本分类任务中,使用 LoRA 微调的模型能够快速适应不同的分类需求,同时在减少大量参数的情况下,性能仅下降了极小的幅度。研究表明,在某些大规模文本分类数据集上,LoRA 微调后的模型在减少 90% 参数的情况下,性能仅下降了不到 1%。
在问答任务中,LoRA 可以通过微调预训练模型,使其更好地理解特定领域的问题,并给出更准确的答案。比如在医疗领域的问答系统中,通过对预训练语言模型进行 LoRA 微调,可以让模型更好地理解医学术语和病症描述,从而提高回答的准确性和专业性。
此外,LoRA 还可以与其他 NLP 技术结合,进一步提升模型性能。例如,与知识图谱结合,利用知识图谱中的实体和关系信息,引导 LoRA 微调过程,使模型在回答问题时能够更好地利用外部知识。
(二)插件式微调策略
LoRA 的插件式微调策略为用户提供了极大的便利。用户可以根据不同的任务需求,选择合适的预训练模型,并通过 LoRA 快速进行定制化调整。
这种插件式的设计使得模型的定制化过程更加灵活和高效。例如,当用户需要针对特定的文学作品进行分析时,可以选择一个通用的语言模型,然后使用 LoRA 对其进行微调,使其更好地理解该作品的风格和主题。
同时,LoRA 的插件式策略也使得模型的更新和维护更加容易。当新的任务出现或者数据发生变化时,用户可以只对 LoRA 部分进行调整,而无需重新训练整个模型。
总之,LoRA 的插件式微调策略为大型语言模型的应用提供了一种高效、灵活的解决方案,使得更多的用户能够在有限的资源下利用大型语言模型的强大能力。
四、微调实践
(一)环境配置
StarCoder 的微调实践需要特定的环境配置。例如,采用 A800 显卡,搭配 python3.8、torch2.0 和 CUDA11.6。在 python 环境中,transforemrs 和 peft 这两个包建议使用 "Development Mode" 安装。环境中主要包的版本也有明确要求,如 tqdm==4.65.0、transformers=4.31.0.dev0、peft=0.4.0.dev0、datasets==2.11.0、huggingface-hub==0.13.4、accelerate==0.18.0。这样的环境配置为后续的模型加载和微调提供了稳定的基础。
(二)模型加载
模型加载过程整合了 alpaca-lora 项目和 StarCoder 的 finetune 项目。首先,使用 AutoModelForCausalLM.from_pretrained 加载预训练模型,设置参数如 use_auth_token=True、use_cache=True、load_in_8bit=True 等,并通过 device_map 指定显卡索引。接着,使用 prepare_model_for_int8_training 对模型进行处理,然后设置 LoraConfig,指定参数如 r=16、lora_alpha=32、lora_dropout=0.05 等,并通过 get_peft_model 将原模型作为 base 模型,在各个 self-attention 层加入 LoRA 层,同时改写模型 forward 的计算方式。在模型加载时,load_in_8bit=True 的 8bit 量化优化了静态显存,是 bitsandbytes 库赋予的能力,会把加载模型转化成混合 8bit 的量化模型。模型量化本质是对浮点参数进行压缩的同时,降低压缩带来的误差,将原始 fp32(4 字节)压缩到 int8(1 字节),也就是实现了 1/4 的显存占用。
(三)参数选取
- Rank 的选取:作者对比了 1 - 64 的取值,在一般效果上,Rank 在 4 - 8 之间最好,再高并没有效果提升。不过论文的实验是面向下游单一监督任务的,因此在指令微调上,根据指令分布的广度,Rank 选择还是需要在 8 以上的取值进行测试。
- alpha 参数选取:alpha 其实是个缩放参数,训练后权重 merge 时的比例为 alpha/r。
- 初始化:矩阵 A 是 Uniform 初始化,B 是零初始化,这样最初的 lora 权重为 0,所以 lora 参数是从头学起,并没有那么容易收敛。对于哪些参数进行微调,基于 Transformer 结构,LoRA 只对每层的 Self-Attention 的部分进行微调,有四个映射层参数可以进行微调。像 StarCoder 模型 Multi - query 结构的 attention 层对应的参数名称是 attn.c_attn、attn.c_proj。
五、在大模型微调中的作用
(一)高效微调
大语言模型通常拥有海量的参数,全参数微调不仅计算成本高昂,而且耗时漫长。LoRA 以其独特的低秩矩阵注入方式,为大语言模型的微调带来了高效的解决方案。
以 GPT-3 175B 模型为例,全参数微调需要 1.2TB 的显存,而使用 LoRA 后,显存需求大幅降低。例如,当 设置为 4,且只调整 query 和 value 矩阵时,显存需求可从 1.2TB 降至 35MB,这为资源受限的环境提供了可行性。
在微调过程中,LoRA 只训练低秩矩阵的参数,原模型的其他部分权重保持不变。这种方式使得训练过程更加高效,能够在较短的时间内达到较好的效果。同时,由于参数量的大幅减少,训练过程中的计算复杂性也大大降低,避免了过拟合的风险,保持了模型的稳定性和可靠性。
(二)应用场景广泛
1. 智能客服领域
在智能客服领域,LoRA 微调后的大语言模型能够更加准确地理解客户的问题,并给出更加恰当的回答。一家企业使用经过 LoRA 微调的大语言模型来回答客户的问题,通过对大量客户咨询数据的学习和微调,模型能够快速适应不同类型的问题和客户需求。据统计,使用 LoRA 微调后的模型,客户满意度提高了 [X]%,同时大大降低了人工客服的成本。
2. 文本生成领域
对于文本生成任务,LoRA 微调也发挥了重要作用。一位作家利用经过 LoRA 微调的语言模型来辅助创作。这个模型可以根据作家提供的主题和关键词,生成富有创意和感染力的文本内容。作家可以在此基础上进行进一步的修改和完善,从而提高创作效率和质量。例如,在某些文学创作项目中,使用 LoRA 微调后的模型,创作效率提高了 [X]%。
3. 机器翻译领域
在机器翻译领域,LoRA 微调同样有着出色的表现。一个翻译团队使用经过 LoRA 微调的大语言模型来进行多语种翻译。通过对特定领域的翻译数据进行微调,这个模型能够更加准确地翻译专业术语和特定语境下的语句,提高了翻译的准确性和流畅性。实验表明,在特定领域的翻译任务中,LoRA 微调后的模型翻译准确率提高了 [X]%。
六、技术优势
(一)低秩矩阵近似高效
大语言模型往往拥有庞大的参数数量,这使得全参数微调面临着巨大的计算资源压力和时间成本。LoRA 巧妙地运用低秩矩阵近似的方法,对高维参数矩阵进行分解。例如,在一个拥有数十亿参数的大语言模型中,全参数微调可能需要数 TB 的显存空间以及漫长的训练时间。而 LoRA 可以将参数矩阵分解为低秩矩阵,假设原模型参数矩阵为 ,LoRA 可能将其分解为 和 的两个低秩矩阵,极大地减少了参数量。实验数据表明,这种低秩矩阵近似的方法可以将训练显存开销降低至全参数微调的约 1/3。在实际应用中,对于资源有限的环境,如消费级 GPU,LoRA 使得大模型的微调成为可能,大大提高了模型训练的效率和可行性。
(二)灵活插件式应用
LoRA 的插件式应用为不同任务的微调提供了极大的灵活性。在不同的应用场景中,可以针对特定任务训练出独立的 LoRA 参数,然后与预训练参数快速结合。以 Stable Diffusion(SD)与 LoRA 的结合为例,在图像生成领域,用户可以根据不同的风格需求下载相对较小的 LoRA 模型(通常为几十到几百 MB),与原有的 SD 模型(可能为几个 GB)结合使用。比如,当用户想要生成特定风格的图像时,只需要加载对应的 LoRA 模型,即可轻松实现风格的调整。这种插件式的设计方便快捷,使得用户可以在不改变原模型结构的情况下,快速适应不同的任务需求。同时,插件式应用也使得模型的更新和扩展更加容易,当新的任务或风格出现时,只需训练新的 LoRA 参数,而无需重新训练整个模型。
(三)不改变原模型
LoRA 微调的一个重要优势是不改变原有的预训练参数。在微调过程中,新的 LoRA 参数与原参数配合使用,不会增加推理时间。这意味着在实际应用中,可以在不影响模型性能的前提下,实现高效的任务微调。例如,在智能客服系统中,使用 LoRA 微调后的大语言模型可以在不改变原有的响应时间的情况下,更加准确地回答客户的问题。对于一些对实时性要求较高的应用场景,这一优势尤为重要。同时,不改变原模型也使得模型的稳定性得到了保障,避免了因大规模参数调整而可能导致的模型性能不稳定问题。在不同的任务中,LoRA 可以根据具体需求进行灵活的微调,而不会对原模型的整体性能产生负面影响。
结语
LoRA作为大模型微调技术中的一项创新成果,在多个方面展现出了卓越的性能和巨大的潜力。 从技术角度来看,其低秩矩阵注入的工作原理,为大模型微调在内存效率和计算效率方面提供了一种高效的解决方案。这种在特定层引入少量参数进行训练的方式,在不破坏原模型结构的基础上,实现了模型对特定任务的快速适应,这是传统微调方法难以企及的。 在应用层面,无论是自然语言处理领域的各种任务,还是扩展到其他如与图像生成模型结合的跨领域应用,LoRA都发挥着不可忽视的作用。它的插件式微调策略,使得不同领域、不同需求的用户能够方便地定制大型语言模型,满足多样化的实际需求。 随着人工智能技术的不断发展,大模型在各个行业的应用将越来越广泛。LoRA技术凭借其独特的优势,有望在未来的研究和实际应用中继续发挥重要的作用,进一步推动大模型在各个特定领域的优化和应用拓展,为实现更加精准、高效的人工智能服务奠定坚实的基础。同时,研究人员也将继续探索LoRA技术的更多可能性,例如如何进一步优化低秩矩阵的选择和训练,以及如何更好地与其他新兴技术相结合等,以适应不断变化的人工智能发展需求。
相关文章:
大模型微调技术之 LoRA:开启高效微调新时代
一、LoRA 简介 LoRA,即低秩适应(Low-Rank Adaptation),是一种用于微调大型语言模型的技术,旨在以较小的计算资源和数据量实现模型的快速适应特定任务或领域。 LoRA 方法通过引入低秩近似的思想,对大型预训…...
)
【Vue】Vue2(2)
文章目录 1 数据代理1.1 回顾Object.defineproperty方法1.2 何为数据代理1.3 Vue中的数据代理 2 事件处理2.1 事件的基本使用2.2 事件修饰符2.3 键盘事件 1 数据代理 1.1 回顾Object.defineproperty方法 <!DOCTYPE html> <html><head><meta charset&quo…...

如何实现一个基于 HTML+CSS+JS 的任务进度条
如何实现一个基于 HTMLCSSJS 的任务进度条 在网页开发中,任务进度条是一种常见的 UI 组件,它可以直观地展示任务的完成情况。本文将向你展示如何使用 HTML CSS JavaScript 来创建一个简单的、交互式的任务进度条。用户可以通过点击进度条的任意位置来…...
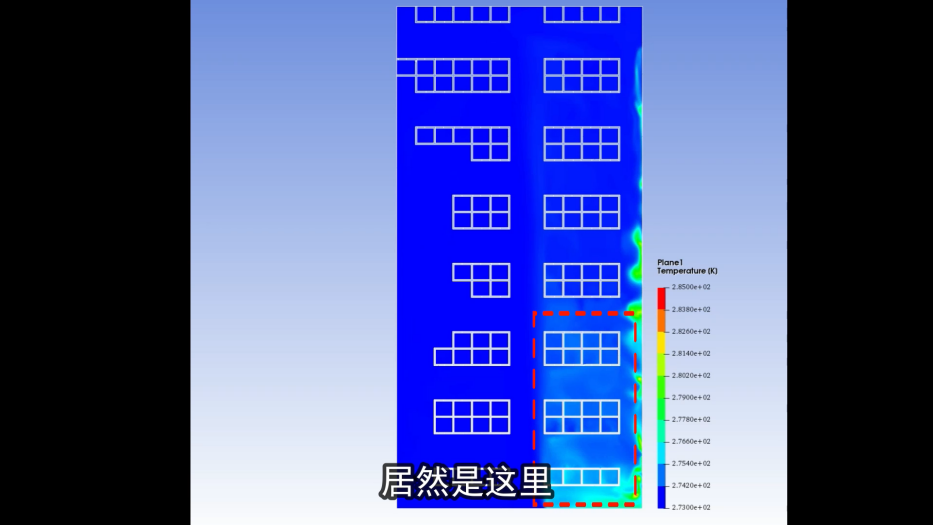
学会流体力学,冬天洗澡再也不冷啦
前些日子收到一位网友“究极理性怪物”的私信,说最近在学校的公共浴室洗澡时,快被冻死了,希望我从流体力学角度帮他分析一下浴室的温度分布,以便找到相对温暖的洗澡位置。 我看到后觉得很有意思,就与他展开了关于澡堂…...

WPF下使用FreeRedis操作RedisStream实现简单的消息队列
Redis Stream简介 Redis Stream是随着5.0版本发布的一种新的Redis数据类型: 高效消费者组:允许多个消费者组从同一数据流的不同部分消费数据,每个消费者组都能独立地处理消息,这样可以并行处理和提高效率。 阻塞操作:消费者可以设置阻塞操作,这样它们会在流中有新数据…...

踩坑NVTX
最开始在 【简说】NVTX Nsight Nvidia性能分析利器 看到NVTX的时候,我觉得这是一个好东西啊,可以详细说明每一段时间对应的是哪一段程序。 看了一下github,他的文章已经过时,现在已经不需要链接动态库了,直接includ…...

Ubuntu修改IP方法
方法一:通过图形化界面修改IP 打开网络设置: 点击桌面右上角的网络图标,然后选择“设置”或“网络设置”。 选择网络接口: 在网络设置窗口中,选择你正在使用的网络接口(有线或无线网络)。 进…...

C++——STL简介
目录 一、什么是STL 二、STL的版本 三、STL的六大组件 没用的话..... 不知不觉两个月没写博客了,暑假后期因为学校的事情在忙,开学又在准备学校的java免修,再然后才继续开始学C,然后最近打算继续写博客沉淀一下最近学到的几周…...

[linux] 磁盘清理相关
在 CentOS 7 中清理磁盘空间可以通过多种方法实现,以下是一些常用的步骤和命令: 1. 查找和删除大文件 你可以使用 find 命令查找占用大量空间的文件: find / -type f -size 100M 2>/dev/null这条命令会查找大于 100 MB 的文件。你可以根…...

【笔记】DDD领域驱动设计
同名读书笔记,对于一些自觉重要的点进行记录。 扩展资源:github.com/evancyz/ddd-learning UML中类图的一些基本知识 - jack_Meng - 博客园 最后的第四部分暂时没看 Part Two 模型驱动设计的构造块 Chapter 5 软件中所表示的模型 5.2 模式:…...
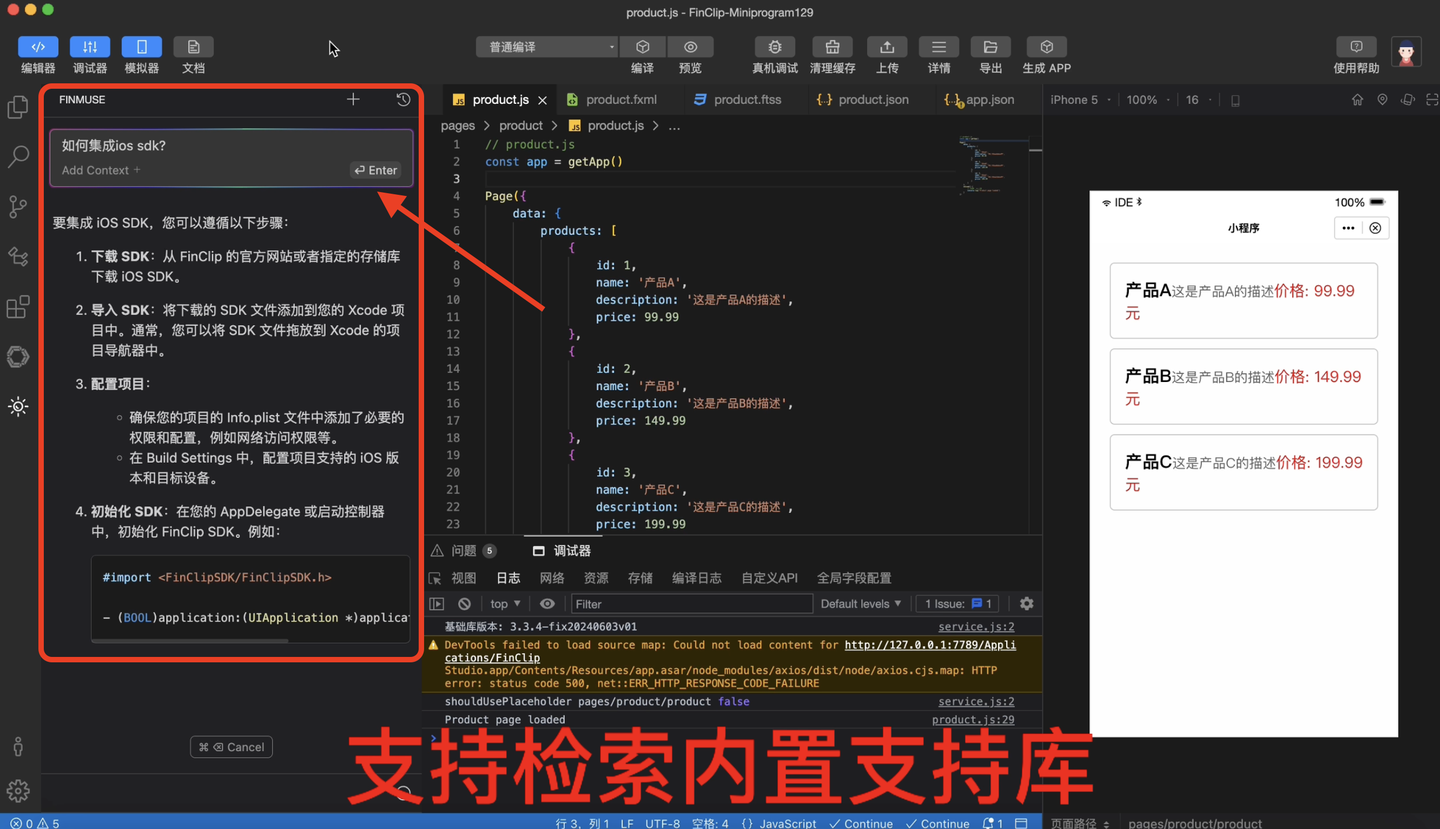
用AI构建小程序需要多久?效果如何?
随着移动互联网的快速发展,多端应用的需求日益增长。为了提高开发效率、降低成本并保证用户体验的一致性,前端跨端技术在如今的开发界使用已经非常普遍了,技术界较为常用的跨端技术有小程序技术、HTML5技术两大类。 2023年以来,伴…...

深度学习的应用综述
文章目录 引言深度学习的基本概念深度学习的主要应用领域计算机视觉自然语言处理语音识别强化学习医疗保健金融分析 深度学习应用案例公式1.损失函数(Loss Function) 结论 引言 深度学习是机器学习的一个子领域,通过模拟人脑的神经元结构来处理复杂的数据。近年来&…...

whereis命令:查找命令的路径
一、命令简介 whereis 命令用于查找命令的:可执行文件、帮助文件和源代码文件。 例如 $ whereis ls ls: /usr/bin/ls /usr/share/man/man1/ls.1.gz找到了 ls 命令的可执行文件、帮助文件的位置。 二、命令参数 命令格式 whereis [选项] [命令名称]选项…...
)
【ECMAScript 从入门到进阶教程】第四部分:项目实践(项目结构与管理,单元测试,最佳实践与开发规范,附录)
第四部分:项目实践 第十四章 项目结构与管理 在构建现代 Web 应用程序时,良好的项目结构和管理是确保代码可维护性、高效开发和部署成功的关键因素。这一章将深入讨论项目初始化与配置,以及如何使用构建工具来简化和优化项目建设过程。 14…...
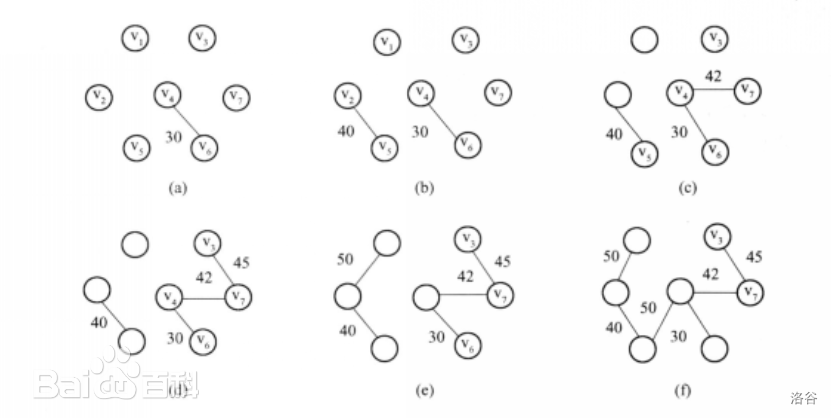
算法讲解—最小生成树(Kruskal 算法)
算法讲解—最小生成树(Kruskal 算法) 简介 根据度娘的解释我们可以知道,最小生成树(Minimum Spanning Tree, MST)就是:一个有 n n n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n n n 个结点…...

掌握 C# 多线程与异步编程
现代应用程序通常需要执行复杂的计算或处理 I/O 操作,这些操作可能会导致主线程阻塞,从而降低用户体验。C# 提供了多线程与异步编程的多种工具,让我们能够高效地并发处理任务。本文将介绍 C# 中的多线程与异步编程,包括 Thread 类…...

Angular 2 用户输入
Angular 2 用户输入 Angular 2 是一个由 Google 维护的开源前端 web 框架,用于构建单页应用程序(SPA)。它以其高效的双向数据绑定、模块化架构和强大的依赖注入系统而闻名。在 Angular 2 应用程序中,处理用户输入是核心功能之一,因为它允许应用程序响应用户的操作。 Ang…...

线程安全的单例模式 | 可重入 | 线程安全 |死锁(理论)
🌈个人主页: 南桥几晴秋 🌈C专栏: 南桥谈C 🌈C语言专栏: C语言学习系列 🌈Linux学习专栏: 南桥谈Linux 🌈数据结构学习专栏: 数据结构杂谈 🌈数据…...
跟GBDT(Gradient Boosting Decision Trees)有什么区别)
解决方案:梯度提升树(Gradient Boosting Trees)跟GBDT(Gradient Boosting Decision Trees)有什么区别
文章目录 一、现象二、解决方案梯度提升树(GBT)GBDT相同点区别 一、现象 在工作中,在机器学习中,时而会听到梯度提升树(Gradient Boosting Trees)跟GBDT(Gradient Boosting Decision Trees&…...

亚马逊国际商品详情API返回值:电商精准营销的关键
亚马逊国际商品详情API(Amazon Product Advertising API)为开发者提供了一种获取商品信息的方式,这些信息对于电商精准营销至关重要。通过分析API返回的详细数据,商家可以制定更精准的营销策略,提高用户购买转化率。 …...

Claude Code 架构深度解析:一文搞懂 Sub-Agent、Skill 与底层模型之间的协同机制
Claude Code 架构深度解析:一文搞懂 Sub-Agent、Skill 与底层模型之间的协同机制 Claude Code 凭什么成为 AI 编程工具市场占有率第一?本文深入拆解其内部四层架构——Skill 拦截层、Claude Code 编排器、Sub-Agent 执行层、底层大模型推理层——带你彻底…...

深度解析AI游戏瞄准辅助:从YOLOv10模型到实时视觉识别的完整技术架构
深度解析AI游戏瞄准辅助:从YOLOv10模型到实时视觉识别的完整技术架构 【免费下载链接】yolov8_aimbot Aim-bot based on AI for all FPS games 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_aimbot 在当今FPS游戏竞技领域,AI瞄准辅助技术…...
)
别再傻等!解决conda install nb_conda卡在solving environment的3个高效方法(附清华源配置)
彻底解决conda install卡在solving environment的终极指南 当你满怀期待地在终端输入conda install nb_conda准备为Jupyter Notebook添加环境管理功能时,却发现进度条永远卡在"solving environment"这一步,这种体验就像在高速公路上遇到无休止…...

图文实操|飞书联动 OpenClaw,搭建智能电脑操控体系
OpenClaw 飞书机器人配置教程|一键对接飞书,聊天下达 AI 指令 适配版本:OpenClaw(小龙虾)前置要求:已部署 OpenClaw Windows 端(Win10/Win11 均可),未部署可先下载一键部…...

终极指南:如何用WinDiskWriter快速制作Windows启动盘并绕过硬件限制
终极指南:如何用WinDiskWriter快速制作Windows启动盘并绕过硬件限制 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UEFI &…...

3步找回密码:如何用ArchivePasswordTestTool解锁加密压缩包
3步找回密码:如何用ArchivePasswordTestTool解锁加密压缩包 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经面对一个…...

不用命令行!OpenClaw 2.7.5 Win11 专属部署,双击直达本地 AI 助手
前言 本教程专为Windows用户设计,提供可视化部署方案。通过专用部署包实现全程图形化操作,彻底告别命令行和手动配置环境。即使是零基础用户也能轻松完成部署,快速搭建专属数字员工系统,显著提升工作效率。教程完美适配Windows 1…...

CANNBot Triton-Ascend Amin归约原子操作优化案例
【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills name: triton-ascend-case-reduction-amin-atomic description: "…...

Chrome密码恢复终极指南:3分钟快速找回所有浏览器密码
Chrome密码恢复终极指南:3分钟快速找回所有浏览器密码 【免费下载链接】chromepass Get all passwords stored by Chrome on WINDOWS. 项目地址: https://gitcode.com/gh_mirrors/chr/chromepass 你是否曾经忘记过保存在Chrome浏览器中的重要密码?…...

拟态设计革命来了,你还在用老版MJ?2024Q2官方未披露的3类新拟态纹理权重算法首度解密
更多请点击: https://kaifayun.com 第一章:拟态设计革命的底层逻辑与时代必然性 拟态设计并非视觉层面的风格迁移,而是一场由安全范式迁移、计算环境异构化与攻击面指数级扩张共同驱动的系统性重构。其底层逻辑根植于“动态异构冗余”&…...