基于ResNet50模型的船型识别与分类系统研究
关于深度实战社区
我们是一个深度学习领域的独立工作室。团队成员有:中科大硕士、纽约大学硕士、浙江大学硕士、华东理工博士等,曾在腾讯、百度、德勤等担任算法工程师/产品经理。全网20多万+粉丝,拥有2篇国家级人工智能发明专利。
社区特色:深度实战算法创新
获取全部完整项目数据集、代码、视频教程,请进入官网:zzgcz.com。竞赛/论文/毕设项目辅导答疑,v:zzgcz_com
1. 项目简介
本项目旨在实现基于深度学习的船型识别系统,主要针对不同类型船只的图像进行自动分类。该项目的背景是随着海洋监控、海事安全和船只管理需求的不断增长,快速准确地识别海上船只的类型成为一项重要的技术挑战。传统的船只识别方法主要依赖人工特征提取和规则匹配,但由于海上环境复杂多变,如光照、船体角度、海况等因素影响,这种方法的表现较为有限。因此,本项目采用深度学习模型,充分利用卷积神经网络(CNN)的强大特征提取能力,通过学习大规模的船只图像数据集来提升识别精度。
项目中选用的模型是基于经典的ResNet-50结构,并结合迁移学习策略来提高模型的收敛速度和泛化能力。具体应用场景包括:海上交通管控、海事安全预警、无人机巡航系统等。通过对输入图像的自动分类,本项目能够识别如货船、渔船、帆船、军舰等多种常见船型,为海洋管理提供准确、可靠的技术支持。最终目标是开发一个能够高效处理和识别多种船型的系统,并通过不断优化模型性能来满足实际应用需求。

2.作业要求
本次作业的目标是让您熟悉使用 PyTorch 框架构建和训练深度学习模型的过程。您将使用预训练的 ResNet50 模型,对船型图片数据集进行分类。通过完成本作业,您将掌握以下内容:
- 数据集的加载与预处理
- 使用 PyTorch 定义和训练深度学习模型
- 训练过程的可视化
- 模型的评估与保存
任务一:数据集加载与预处理
- 实现一个函数
load_datasets,用于加载和预处理数据集,增加参数is_test,默认值为True。 - 当
is_test=True时,从每个类别中随机选取固定数量的图片(例如,50 张)用于训练和验证。 - 将选取的图片按照指定的验证集比例(例如,20%)划分为训练集和验证集。
任务二:模型定义与训练
- 使用
torchvision.models加载预训练的 ResNet50 模型,并修改全连接层以匹配数据集的类别数量。 - 实现训练函数
train_model,包括训练过程、验证过程和模型保存。 - 在训练过程中,记录每个 epoch 的训练和验证损失、准确率。
任务三:结果分析与可视化
- 实现函数
plot_training_history,绘制训练和验证的损失曲线、准确率曲线。 - 实现函数
generate_report,在验证集上生成分类报告和绘制混淆矩阵。 - 分析模型的性能,讨论可能的改进方向。
任务四:模型保存与加载
- 在训练过程中,保存验证准确率最高的模型权重到文件
best_model.pth。 - 训练结束后,保存最终的模型权重到文件
final_model.pth。 - 提供加载模型权重的代码示例,说明如何在后续使用中加载和评估模型
3. 结果展示:

- 使用了预训练权重,已经具备较强的特征提取能力。这意味着,即使全连接层(分类器)未经过训练,模型依然能够提取有意义的特征,从而在验证集上可能表现出较高的准确率。



4. 模型架构
本项目基于ResNet-50结构进行船型识别任务,并在预训练的ResNet-50模型基础上进行修改,添加了自定义的全连接层以实现特定的分类任务。模型的每一层逻辑和功能如下:
第一个线性层(全连接层) :
- 功能:将ResNet50输出的高维特征(例如2048维)映射到较低的维度(512维)。
- 优点:通过减少特征维度,模型能够更高效地处理数据,同时保留关键信息。这有助于减少计算资源的消耗,并可能提升模型的泛化能力。
激活函数(ReLU) :
- 功能:应用ReLU(线性整流单元)激活函数,引入非线性。
- 优点:非线性激活函数使模型能够学习和表示更复杂的模式和特征,提升模型的表达能力。
Dropout层:
- 功能:随机丢弃50%的神经元,防止过拟合。
- 优点:通过随机屏蔽部分神经元,Dropout层有助于防止模型对训练数据的过度拟合,提高模型在未见过数据上的泛化性能。
批归一化层(Batch Normalization) :
- 功能:对512维的特征进行归一化处理。
- 优点:批归一化加速了训练过程,稳定了模型的学习过程,减少了对初始权重的敏感性,从而提高了模型的收敛速度和稳定性。
第二个线性层:
- 功能:将特征维度从512进一步减少到16。
- 优点:逐步降维的设计能够更细致地提取和压缩特征,进一步提升模型的表达能力,并减少参数数量,降低计算复杂度。
再次应用激活函数(ReLU) :
- 功能:在第二个线性层之后再次应用ReLU激活函数。
- 优点:继续引入非线性,增强模型的表达能力,使其能够捕捉更复杂的特征关系。
再次添加Dropout层:
- 功能:再次丢弃50%的神经元,继续防止过拟合。
- 优点:进一步增强正则化效果,提高模型的泛化能力。
再次添加批归一化层:
- 功能:对16维的特征进行归一化。
- 优点:进一步稳定模型的训练过程,提高训练效率,确保模型在不同训练批次间保持一致的分布。
最终线性层:
- 功能:将16维的特征映射到最终的类别数量
num_classes。 - 优点:这一层的输出对应于每个类别的得分或概率,用于最终的分类决策。通过映射到具体的类别数,模型能够根据任务需求灵活调整输出维度。
5. 核心代码详细讲解
在深度学习项目中,数据加载和预处理是至关重要的步骤。PyTorch 提供了强大的数据处理工具,其中 torch.utils.data.Dataset 是一个抽象类,用户可以通过继承它来自定义数据集。下面,我们将深入讲解你提供的 CustomDataset 类,理解其每个部分的功能和实现细节。
完整代码片段
暂时无法在飞书文档外展示此内容
-
Dataset类简介:Dataset是 PyTorch 提供的一个抽象类,定义了数据集的基本接口。- 任何继承自
Dataset的子类都需要实现三个基本方法:__init__、__len__和__getitem__。
-
为什么需要自定义数据集:
- 默认的数据集类(如
torchvision.datasets中的类)适用于常见的数据集格式。 - 对于特定任务或自定义数据存储方式,用户需要通过继承
Dataset类来创建适合自己需求的数据集类。
- 默认的数据集类(如
- 初始化方法
init
暂时无法在飞书文档外展示此内容
-
方法签名:
__init__是类的构造函数,用于初始化类的实例。
-
参数解释:
image_paths:一个列表,包含所有图像文件的路径。每个元素是一个字符串,指向一张图片的位置。labels:一个列表,包含每张图像对应的标签。通常是整数或类别名称的索引。transform:可选参数,用于对图像进行预处理的转换操作。通常使用torchvision.transforms定义的数据增强或标准化操作。
-
成员变量:
self.image_paths:存储图像路径列表,供后续访问。self.labels:存储标签列表,与图像路径一一对应。self.transform:存储转换方法,在获取图像时应用于图像数据。
示例:
假设有以下图像路径和标签:
暂时无法在飞书文档外展示此内容
初始化 CustomDataset:
dataset = CustomDataset(image_paths, labels, transform=your_transforms)
- 方法
len
暂时无法在飞书文档外展示此内容
-
功能:
- 返回数据集的大小,即图像的总数量。
-
重要性:
- 让 PyTorch 知道数据集有多少样本,以便在训练过程中进行迭代。
-
实现细节:
- 使用内置的
len函数获取self.image_paths列表的长度。
- 使用内置的
示例:
暂时无法在飞书文档外展示此内容
- 方法
getitem
暂时无法在飞书文档外展示此内容
-
功能:
- 根据给定的索引
idx,返回对应的图像及其标签。
- 根据给定的索引
-
参数解释:
idx:整数,表示要获取的数据样本的索引。
- 与
DataLoader的集成
CustomDataset 通常与 torch.utils.data.DataLoader 一起使用,以便高效地批量加载数据。
示例:
暂时无法在飞书文档外展示此内容
-
参数解释:
batch_size:每个批次加载的样本数量,这里设置为16。shuffle:是否在每个 epoch 开始时打乱数据顺序,这有助于提高模型的泛化能力。num_workers:加载数据的子进程数量,增加可以加快数据加载速度,特别是在 I/O 密集型任务中。
6. 模型 改进:类别不均衡
- 数据重采样(Resampling):
-
过采样(Oversampling)少数类:
- 随机过采样(Random Oversampling): 从少数类中随机复制样本,增加少数类的样本数量。
- SMOTE(Synthetic Minority Over-sampling Technique): 通过插值生成新的少数类样本,而不是简单地复制。
- ADASYN(Adaptive Synthetic Sampling): 基于 SMOTE 的改进,更多地合成难以学习的少数类样本。
-
欠采样(Undersampling)多数类:
- 随机欠采样(Random Undersampling): 从多数类中随机删除样本,减少多数类的样本数量。
- 集成欠采样(Ensemble Undersampling): 结合多个欠采样子集,构建更稳定的模型。
- 调整模型权重(Class Weights):
-
修改损失函数: 在损失函数中对少数类赋予更高的权重,使模型在训练时更加关注少数类。
- PyTorch 示例:
- 暂时无法在飞书文档外展示此内容
- 自动计算权重: 使用 sklearn 的
compute_class_weight函数。 - 暂时无法在飞书文档外展示此内容
↓↓↓更多热门推荐:
LSTM模型实现电力数据预测
基于YOLOv8-deepsort算法的智能车辆目标检测车辆跟踪和车辆计数
全部项目数据集、代码、教程进入官网zzgcz.com
相关文章:
基于ResNet50模型的船型识别与分类系统研究
关于深度实战社区 我们是一个深度学习领域的独立工作室。团队成员有:中科大硕士、纽约大学硕士、浙江大学硕士、华东理工博士等,曾在腾讯、百度、德勤等担任算法工程师/产品经理。全网20多万粉丝,拥有2篇国家级人工智能发明专利。 社区特色…...
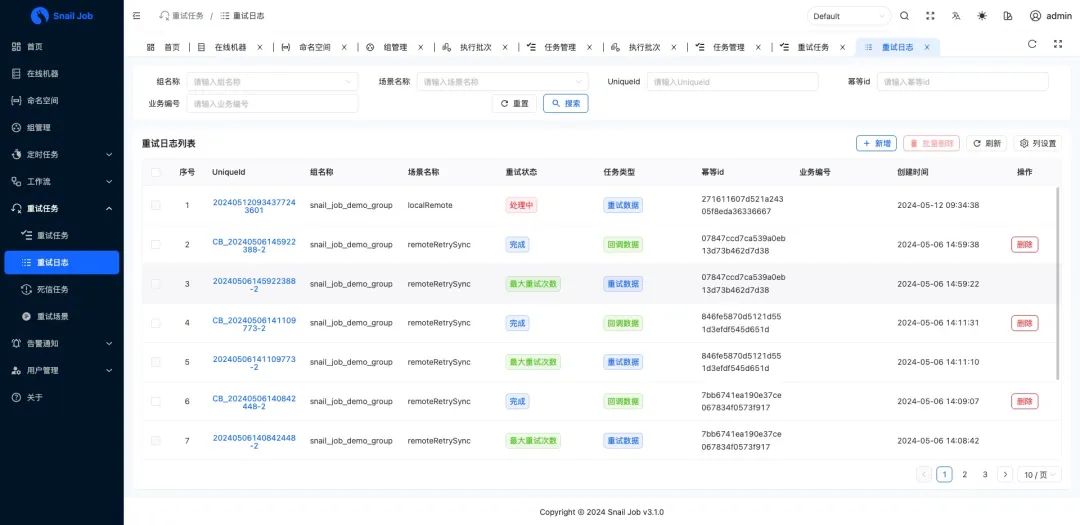
一个为分布式环境设计的任务调度与重试平台,高灵活高效率,系统安全便捷,分布式重试杀器!(附源码)
背景 近日挖掘到一款名为“SnailJob”的分布式重试开源项目,它旨在解决微服务架构中常见的重试问题。在微服务大行其道的今天,我们经常需要对某个数据请求进行多次尝试。然而,当遇到网络不稳定、外部服务更新或下游服务负载过高等情况时,请求…...
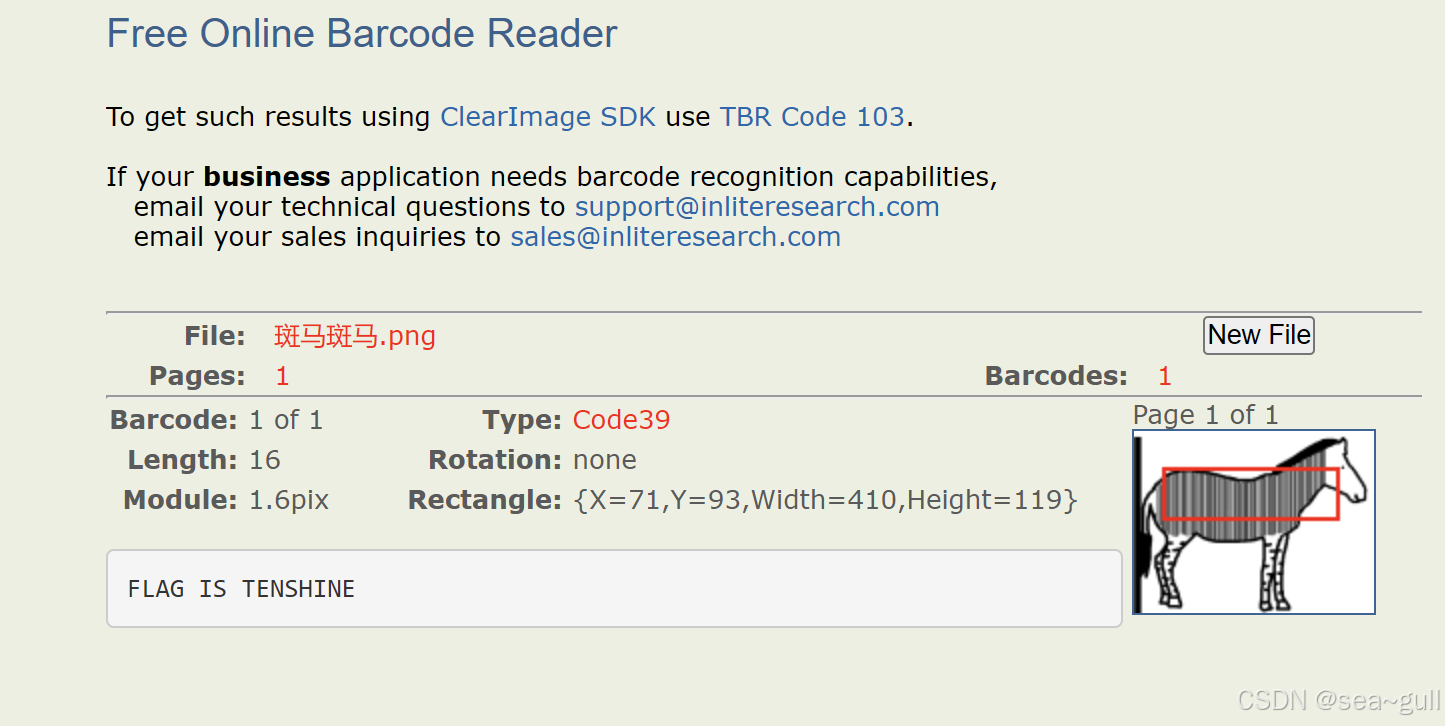
攻防世界(CTF)~Misc-Banmabanma
题目介绍 附件下载后得到一张图片类,似一只斑马,仔细观看发现像条形码 用条形码在线阅读查看一下 条形码在线识别 flag{TENSHINE}...

获取淘宝直播间弹幕数据的技术探索实践方法
在数字时代,直播已成为电商营销的重要渠道之一,而弹幕作为直播互动的核心元素,蕴含着丰富的用户行为和情感数据。本文将详细介绍如何获取淘宝直播间弹幕数据的技术方法和步骤,同时分析不同工具和方法的优缺点,并提供实…...

Python 卸载所有的包
Python 卸载所有的包 引言正文 引言 可能很少有小伙伴会遇到这个问题,当我们错误安装了一些包后,由于包之间有相互关联,导致一些已经安装的包无法使用,而由于我们已经安装了很多包,它们的名字我们并不完全知道&#x…...
、Token、Session和Cookie)
JWT(JSON Web Token)、Token、Session和Cookie
JWT(JSON Web Token)、Token、Session和Cookie都是Web开发中常用的概念,它们各自在不同的场景下发挥着重要的作用。以下是对这四个概念的详细解释和比较: 一、JWT(JSON Web Token) 定义:JWT是一…...

国内知名人工智能AI大模型专家培训讲师唐兴通讲授AI办公应用人工智能在营销与销售过程中如何应用数字化赋能
AI如火如荼,对商业与社会影响很大。 目前企业广泛应用主要是在营销、销售方向,提升办公效率等方向。 从喧嚣的AI导入营销与销售初步阶段,那么当下,领先的组织与个人现在正在做什么呢? 如何让人性注入冷冰冰的AI&…...

Android常用C++特性之std::swap
声明:本文内容生成自ChatGPT,目的是为方便大家了解学习作为引用到作者的其他文章中。 std::swap 是 C 标准库中提供的一个函数,位于 <utility> 头文件中。它用于交换两个变量的值。 语法: #include <utility>std::s…...

MongoDB数据库详解:特点、架构与应用场景
目录 MongoDB 简介MongoDB 的核心特点 2.1 面向文档的存储2.2 动态架构2.3 水平扩展能力2.4 强大的查询能力 MongoDB 的架构设计 3.1 存储引擎3.2 集群架构3.3 副本集(Replica Set)3.4 分片(Sharding) MongoDB 常见应用场景 4.1 …...

【C语言刷力扣】1678.设计Goal解析器
题目: 解题思路: 遍历分析每一个字符,对不同情况分别讨论。 若是字符 G ,则 res 中添加字符 G若是字符 ( ,则再分别讨论。 若下一个字符是 ), 则在 res 末尾添加字符 o若下一个字符…...

RK3568平台开发系列讲解(I2C篇)i2c 总线驱动介绍
🚀返回专栏总目录 文章目录 一、i2c 总线定义二、i2c 总线注册三、i2c 设备和 i2c 驱动匹配规则沉淀、分享、成长,让自己和他人都能有所收获!😄 i2c 总线驱动由芯片厂商提供,如果我们使用 ST 官方提供的 Linux 内核, i2c 总线驱动已经保存在内核中,并且默认情况下已经…...

xilinx中bufgce
在Xilinx的FPGA设计中,BUFGCE是一种重要的全局时钟缓冲器原语,它基于BUFGCTRL并以一些引脚连接逻辑高电位和低电位。以下是对BUFGCE的详细解析: 一、BUFGCE的功能与特点 功能:BUFGCE是带有时钟使能信号的全局缓冲器。它接收一个时…...
雷池+frp 批量设置proxy_protocol实现真实IP透传
需求 内网部署safeline,通过frp让外网访问内部web网站服务,让safeline记录真实外网攻击IP safeline 跟 frp都部署在同一台服务器:192.168.2.103 frp client 配置 frpc只需要在https上添加transport.proxyProtocolVersion "v2"即…...

DAY27||回溯算法基础 | 77.组合| 216.组合总和Ⅲ | 17.电话号码的字母组合
回溯算法基础知识 一种效率不高的暴力搜索法。本质是穷举。有些问题能穷举出来就不错了。 回溯算法解决的问题有: 组合问题:N个数里面按一定规则找出k个数的集合切割问题:一个字符串按一定规则有几种切割方式子集问题:一个N个数…...

js基础速成12-正则表达式
正则表达式 正则表达式(Regular Expression)或 RegExp 是一种小型编程语言,有助于在数据中查找模式。RegExp 可以用来检查某种模式是否存在于不同的数据类型中。在 JavaScript 中使用 RegExp,可以使用 RegExp 构造函数࿰…...

使用Selenium自动化测试定位iframe以及修改img标签的display属性值
在使用 Selenium 进行自动化测试时,处理 iframe 是一个常见问题。当页面中出现 iframe 时,需要先切换到该 iframe 内部,才能正常定位和操作其中的元素。以下是处理 iframe 的步骤和示例代码: 步骤 切换到 iframe:使用…...

DAY13
面试遇到的新知识点 char str[10],只有10个字符的空间,但是只能存储9个字符,最后一个字符用来存储终止符\0 strlen只会计算\n,不会计算\0 值传递: void test2(char * str) {str "hello\n"; }int main() {char * str;test2(str);…...
)
WPF 自定义用户控件(Content根据加减按钮改变值)
前端代码: <UserControl.Resources><Style x:Key"Num_Button_Style" TargetType"Button"><Setter Property"MinWidth" Value"30" /><Setter Property"Height" Value"35" />&l…...

CPU、GPU、显卡
CPU VS GPUCPU(Central Processing Unit),中央处理器GPU(Graphics Processing Unit),图形处理单元GPU 的技术演变CUDA(Compute Unified Device Architecture) 显卡(Video…...

深入理解 Django 自定义用户模型
1. 引言 Django 作为一个强大的 Web 框架,内置了用户认证系统。然而,实际项目中我们通常需要扩展用户模型,以满足不同的业务需求。Django 提供了继承 AbstractUser 的方式,让我们能够轻松地定制用户模型。本文将通过一个自定义用…...

深入eDP协议栈:从PSR SDP发送到Main Link开关,一次搞懂屏幕自刷新的完整信令流程
深入eDP协议栈:从PSR SDP发送到Main Link开关,一次搞懂屏幕自刷新的完整信令流程 在显示技术的演进中,嵌入式DisplayPort(eDP)协议因其高效能和低功耗特性,已成为移动设备和高端显示器的首选接口。其中&am…...

【职场】职场里,“被喜欢“和“被重用“是两件完全不同的事
职场里,"被喜欢"和"被重用"是两件完全不同的事我见过太多这样的人。 在公司里人缘极好,谁都说他靠谱,谁都愿意跟他合作。 开会时第一个帮人倒水,群里消息第一个回复,同事生日永远记得,…...

解决Service broker not enable. Please activete it using ‘ALTER DATABASE My Database SET ENABLE BROKER
目录 1.问题 2.解决办法 3.说明 1.问题 网站运行报错:Service broker not enable. Please activete it using ALTER DATABASE My Database SET ENABLE BROKER 2.解决办法 服务代理(Service Broker)未启用。请使用 ALTER DATABASE [数据库…...

音乐学者紧急预警:Perplexity搜索结果偏差率高达47%?3步校验法立即挽救你的学术引用
更多请点击: https://intelliparadigm.com 第一章:音乐学者紧急预警:Perplexity搜索结果偏差率高达47%?3步校验法立即挽救你的学术引用 近期,由国际音乐学联合会(IMS)委托开展的交叉验证实验发…...

433MHz无线模块解码避坑指南:从示波器抓波形到STM32代码实现的完整流程
433MHz无线模块解码实战:从波形分析到STM32代码优化的全流程解析 1. 解码前的硬件准备与信号捕获 当你第一次拿到433MHz无线模块时,最令人困惑的往往是"为什么我的代码无法正确解码?"要解决这个问题,我们需要从最基础的…...

东山精密冲刺港股:第一季营收131亿 净利11亿 市值超4000亿
雷递网 雷建平 5月20日苏州东山精密制造股份有限公司(简称:“东山精密”)日前更新招股书,准备在港交所上市。截至目前,东山精密股价为219.33元,市值约4016亿元。一旦在港股上市,东山精密将形成“AH”的格局…...

Prodigal基因预测工具:3天快速掌握原核生物基因发现终极指南
Prodigal基因预测工具:3天快速掌握原核生物基因发现终极指南 【免费下载链接】Prodigal Prodigal Gene Prediction Software 项目地址: https://gitcode.com/gh_mirrors/pr/Prodigal 你是否正在寻找一款快速、准确的原核生物基因预测工具?Prodiga…...

AMD GPU本地AI模型部署终极指南:ollama-for-amd让你的Radeon显卡焕发新生
AMD GPU本地AI模型部署终极指南:ollama-for-amd让你的Radeon显卡焕发新生 【免费下载链接】ollama-for-amd Get up and running with Llama 3, Mistral, Gemma, and other large language models.by adding more amd gpu support. 项目地址: https://gitcode.com/…...

2026年5月19日:谷歌云误停账户致Railway全平台服务中断8小时
事件报告:2026年5月19日 - GCP账户暂停Chandrika Khanduri 与 Cody De Arkland于2026年5月20日发布此报告。据悉,本报告反映了发布时所掌握的信息,可能会根据谷歌云(Google Cloud)的内部审查结果进行更新。影响2026年5…...

注册培训师、咨询师——杨刚老师简介
注册培训师、咨询师——杨刚老师简介注册培训师、咨询师 MTP认证讲师——日本产业训练协会认证 世界500强管理目视化解决方案 版权持有人 杨老师具备10年生产管理经验、15年培训及咨询辅导经验。曾任某日资企业制作课课长、某上市企业精益经理、某民营企业绩效经理、某咨…...