机器学习篇-day03-线性回归-正规方程与梯度下降-模型评估-正则化解决模型拟合问题
一. 线性回归简介
定义
线性回归(Linear regression)是利用 回归方程(函数) 对 一个或多个自变量(特征值)和因变量(目标值)之间 关系进行建模的一种分析方式。
回归方程(函数)
一元线性回归: y = kx + b => wx + b k: 斜率, 在机器学习中叫 权重(weight), 简称: w b: 截距, 在机器学习中叫 偏差/偏置(bios), 简称: b
多元线性回归: y = w1x1 + w2x2 + w3x3... + b => w转置 * x + b

★线性回归的分类
一元线性回归
目标值只与一个因变量有关系
1个特征, 1个标签
多元线性回归
目标值只与多个因变量有关系
多个特征, 1个标签

★应用场景
有特征, 有标签, 且标签是 连续的

二. 线性回归问题求解
线性回归API
线性回归API介绍

代码演示
# 导包
from sklearn.linear_model import LinearRegression
# 1. 准备数据
# 训练集数据
x_train = [[160], [166], [172], [174], [180]]
y_train = [56.3, 60.6, 65.1, 68.5, 75]
# 2. 创建 线性回归 模型对象
estimator = LinearRegression()
# 3. 模型训练
estimator.fit(x_train, y_train)
# 4. 模型评估(暂时略过)
# 5. 模型预测
# 查看模型参数, 即: 斜率(权重) 和 截距(偏置)
print(f'斜率k(w): {estimator.coef_}') # [0.92942177]
print(f'截距b: {estimator.intercept_}') # -93.27346938775514
# 模型预测
x_test = [[176]]
y_predict = estimator.predict(x_test)
print(f'预测结果:{y_predict}') # [70.3047619]
★损失函数
求解最优 斜率 和 截距(拟合结果)

误差概念
用预测值y – 真实值y 就是 误差
损失函数
衡量每个样本预测值与真实值效果的函数
公式推导

损失函数分类
损失函数: 用来衡量 预测值 和 真实值关系的, 分类如下:
-
最小二乘法:
每个样本的 预估值 - 真实值 的平方和
-
均方误差(Mean Square Error => MSE):
每个样本的 预估值 - 真实值 的平方和 / 样本数
-
平均绝对误差(Mean Absolute Error => MAE)
每个样本的 预估值 - 真实值 的绝对值的 和 / 样本数

线性回归求解步骤
损失函数优化方向, 即: 让损失函数值最小 方式1: 梯度下降法. 方式2: 正规方程(求导, 求偏导)

复习-导数和矩阵
数据表述

导数
函数上某一个点的切线就是导数, 瞬时速度变化率
基本公式

四则运算

复合函数求导:
g(h)是外函数h(x)是内函数。先对外函数求导,再对内函数求导
偏导

向量

向量范数

矩阵




正规方程法
只适用于线性回归
一元线性回归推导

多元线性回归推导



★梯度下降算法
思想原理
输入:初始化位置S;每步距离为a 。输出:从位置S到达山底
步骤1:令初始化位置为山的任意位置S
步骤2:在当前位置环顾四周,如果四周都比S高返回S;否则执行步骤3
步骤3: 在当前位置环顾四周,寻找坡度最陡的方向,令其为x方向
步骤4:沿着x方向往下走,长度为a,到达新的位置S'
步骤5:在S'位置环顾四周,如果四周都比S^‘高,则返回S^‘。否则转到步骤3
梯度下降过程就和下山场景类似, 可微分的损失函数,代表着一座山, 寻找的函数的最小值,也就是山底.
梯度 gradient grad
单变量函数中,梯度就是某一点切线斜率(某一点的导数);有方向为函数增长最快的方向
多变量函数中,梯度就是某一个点的偏导数;有方向:偏导数分量的向量方向
梯度下降公式

单变量

多变量

总结梯度下降

梯度下降案例-信贷

梯度下降算法分类
分类

优缺点

正规方程梯度下降对比

三. 回归模型的评估方法
★MAE-平均绝对误差

MSE-均方误差

★RMSE-均方根误差

MAE 和 RMSE 接近, 都表明模型的误差很低, MAE 或 RMSE 越小, 误差越小
RMSE的计算公式中有一个平方项, 因此大的误差将被平方, 因此会增加RMSE的值, 大多数情况下RMSE>MAE
RMSE会放大预测误差较大的样本对结果的影响,而MAE 只是给出了平均误差
结论:RMSE > MAE都能反应真实误差,但是RMSE会对异常点更加敏感
四. 线性回归API和案例
线性回归API
正规方程
sklearn.linear_model.LinearRegression(fit_intercept=True)
通过正规方程优化
参数:fit_intercept,是否计算偏置
属性:
LinearRegression.coef_ (回归系数)
LinearRegression.intercept_(偏置)
梯度下降
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='constant', eta0=0.01)
SGDRegressor类实现了随机梯度下降学习,它支持不同的损失函数和正则化惩罚项,来拟合线性回归模型。
参数
loss(损失函数类型)eg:loss=”squared_loss
fit_intercept(是否计算偏置)
learning_rate (学习率策略):string, optional ,可以配置学习率随着迭代次数不断减小, 比如:学习率不断变小策略: ‘invscaling’: eta = eta0 / pow(t, power_t=0.25)
eta0=0.01 (学习率的值)
属性
SGDRegressor.coef_ (回归系数)SGDRegressor.intercept_ (偏置)
★波士顿房价预测
正规方程
from sklearn.preprocessing import StandardScaler # 特征处理
from sklearn.model_selection import train_test_split # 数据集划分
from sklearn.linear_model import LinearRegression # 正规方程的回归模型
from sklearn.linear_model import SGDRegressor # 梯度下降的回归模型
from sklearn.metrics import mean_squared_error, mean_absolute_error, root_mean_squared_error # 均方误差评估
from sklearn.linear_model import Ridge, RidgeCV
import pandas as pd
import numpy as np
# 1. 加载数据
# 数据地址
data_url = "http://lib.stat.cmu.edu/datasets/boston"
# pandas读取数据
raw_df = pd.read_csv(data_url, sep="\\s+", skiprows=22, header=None)
# 获取特征数据集
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
# 获取标签数据集
target = raw_df.values[1::2, 2]
# 2. 数据预处理: 把总数据506条 按8:2划分
x_train, x_test, y_train, y_test = train_test_split(data, target,test_size=0.2,random_state=21
)
# 3. 特征工程: 特征预处理(标准化, 归一化)
# 创建标准化对象
transfer = StandardScaler()
# 标准化训练集
x_train = transfer.fit_transform(x_train)
# 标准化测试集
x_test = transfer.transform(x_test)
print(len(x_train), len(x_test))
# 4. 模型训练
# 创建线性回归模型对象 => 正规方程
estimator = LinearRegression(fit_intercept=True)
# 训练模型
estimator.fit(x_train, y_train)
# 打印模型的 权重和偏置
print('权重', estimator.coef_)
print('偏置', estimator.intercept_)
# 5. 模型预测
y_predict = estimator.predict(x_test)
print(y_predict)
# 6. 模型评估
# 基于 预测值 和 真实值 计算 模型的 均方误差
print(f'该模型的均方误差: {mean_squared_error(y_test, y_predict)}')
print(f'该模型的平均绝对误差: {mean_absolute_error(y_test, y_predict)}')
print(f'该模型的均方根误差: {root_mean_squared_error(y_test, y_predict)}')
梯度下降
from sklearn.preprocessing import StandardScaler # 特征处理
from sklearn.model_selection import train_test_split # 数据集划分
from sklearn.linear_model import LinearRegression # 正规方程的回归模型
from sklearn.linear_model import SGDRegressor # 梯度下降的回归模型
from sklearn.metrics import mean_squared_error, mean_absolute_error, root_mean_squared_error # 均方误差, 平均绝对误差, 均方根误差评估
from sklearn.linear_model import Ridge, RidgeCV
import pandas as pd
import numpy as np
# 1. 加载数据
# 数据地址
data_url = "http://lib.stat.cmu.edu/datasets/boston"
# pandas读取数据
raw_df = pd.read_csv(data_url, sep="\\s+", skiprows=22, header=None)
# 获取特征数据集
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
# 获取标签数据集
target = raw_df.values[1::2, 2]
# 2. 数据预处理: 把总数据506条 按8:2划分
x_train, x_test, y_train, y_test = train_test_split(data, target,test_size=0.2,random_state=21
)
# 3. 特征工程: 特征预处理(标准化, 归一化)
# 创建标准化对象
transfer = StandardScaler()
# 标准化训练集
x_train = transfer.fit_transform(x_train)
# 标准化测试集
x_test = transfer.transform(x_test)
print(len(x_train), len(x_test))
# 4. 模型训练
# 创建线性回归模型对象 => 梯度下降.
# 理解: 新的点 = 当前点 - 学习率 * 梯度(偏导)
# estimator = LinearRegression(fit_intercept=True) # 正规方程
# constant: 常量, 即: 学习率的值
# eta0: 学习率(梯度下降公式中的α)
# max_iter: 最大迭代次数
estimator = SGDRegressor(fit_intercept=True,learning_rate='constant',eta0=0.001,max_iter=1000000
)
# 训练模型
estimator.fit(x_train, y_train)
# 打印模型的 权重和偏置
print('权重', estimator.coef_)
print('偏置', estimator.intercept_)
# 5. 模型预测
y_predict = estimator.predict(x_test)
print(y_predict)
# 6. 模型评估
# 基于 预测值 和 真实值 计算 模型的 均方误差
print(f'该模型的均方误差: {mean_squared_error(y_test, y_predict)}')
print(f'该模型的平均绝对误差: {mean_absolute_error(y_test, y_predict)}')
print(f'该模型的均方根误差: {root_mean_squared_error(y_test, y_predict)}')
五. 模型拟合问题
复习欠拟合与过拟合

欠拟合:模型在训练集和测试集上表现都不好。模型过于简单
正好拟合(泛化程度较高): 模型在训练集, 测试集上表现效果都比较好.
过拟合:模型在训练集上表现好,在测试集上表现不好。模型过于复杂
欠拟合在训练集和测试集上的误差都较大
过拟合在训练集上误差较小,而测试集上误差较大
欠拟合
代码
# 导包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error # 计算均方误差
from sklearn.linear_model import Ridge, Lasso
# 1. 定义函数, 表示: 欠拟合.
def dm01_欠拟合():# 1. 准备数据.# 准备噪声(可以简单理解为就是: 随机种子), 噪声相同, 每次生成的随机数(点)相同.np.random.seed(21)# x: 表示特征, -3 ~ 3之间 随机的小数, 生成: 100个.x = np.random.uniform(-3, 3, size=100)# y: 表示标签(目标值), 线性关系: y = 0.5x² + x + 2 + 正态分布 + 噪声.# np.random.normal(0, 1, size=100) 意思是: 均值为0, 标准差为1, 生成100个.y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 模型训练.# 2. 创建 线性回归-正规方程 模型对象.estimator = LinearRegression(fit_intercept=True) # 计算: 偏置.# 3. 对数据集做处理.X = x.reshape(-1, 1)# print(f'处理前 x => {x}') # 假设: x = [1, 2, 3]# print(f'处理后 X => {X}') # 处理后: X = [[1], [2], [3]]# 4. 模型训练.estimator.fit(X, y) # 这里传的是, 处理后的x的值, 即: 二维数组.# 5. 模型预测.y_predict = estimator.predict(X)print(f'预测值为: {y_predict}')# 6. 模型评估.print(f'均方误差: {mean_squared_error(y, y_predict)}') # 2.0683653437315512# 7. 数据可视化, 绘制图像.plt.scatter(x, y) # 基于: 原始的x(特征), y值(真实值)绘制 散点图.plt.plot(x, y_predict, c='r') # 基于: 原值的x(特征), y值(预测值)绘制 折线图(就是我们的 拟合回归线)plt.show()
结果

数据是抛物线=> 非线性, 用线性模型拟合, 模型过于简单, 欠拟合
产生原因
学习到数据的特征过少
解决办法
1)添加其他特征项,有时出现欠拟合是因为特征项不够导致的,可以添加其他特征项来解决, 例如: “组合”、“泛化”、“相关性”三类特征是特征添加的重要手段
2)添加多项式特征,模型过于简单时的常用套路,例如将线性模型通过添加二次项或三次项使模型泛化能力更强
正拟合
代码
def dm02_正好拟合():# 1. 准备数据.# 准备噪声(可以简单理解为就是: 随机种子), 噪声相同, 每次生成的随机数(点)相同.np.random.seed(21)# x: 表示特征, -3 ~ 3之间 随机的小数, 生成: 100个.x = np.random.uniform(-3, 3, size=100)# y: 表示标签(目标值), 线性关系: y = 0.5x² + x + 2 + 正态分布 + 噪声.# np.random.normal(0, 1, size=100) 意思是: 均值为0, 标准差为1, 生成100个.y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 模型训练.# 2. 创建 线性回归-正规方程 模型对象.estimator = LinearRegression(fit_intercept=True) # 计算: 偏置.# 3. 对数据集做处理.# 3.1 把数据从 一维数组 => 二维数组, 即: 从 [1, 2, 3] => [[1], [2], [3]]X = x.reshape(-1, 1)# 3.2 拼接: x 和 x的平方, 把数据从 [[1], [2], [3]] => [[1, 1], [2, 4], [3, 9]] 一元线性回归 => 二元线性回归X2 = np.hstack([X, X ** 2]) #print(f'处理前 x => {x}') # 假设: x = [1, 2, 3]print(f'处理后 X => {X}') # 处理后: X = [[1], [2], [3]]print(f'处理后 X2 => {X2}') # 处理后: X2 = [[1, 1], [2, 4], [3, 9]]
# 4. 模型训练.estimator.fit(X2, y) # 这里传的是, 处理后的x的值, 即: 二维数组 => 二元线性回归# 5. 模型预测.y_predict = estimator.predict(X2)print(f'预测值为: {y_predict}')# 6. 模型评估.print(f'均方误差: {mean_squared_error(y, y_predict)}') # 均方误差: 1.0009503498374301# 7. 数据可视化, 绘制图像.plt.scatter(x, y) # 基于: 原始的x(特征), y值(真实值)绘制 散点图.
# 细节: 要对x的值进行升序排列, 然后再绘制, 否则会出现: 散点没有连贯性.# plt.plot(x, y_predict, c='r') # 基于: 原值的x(特征), y值(预测值)绘制 折线图(就是我们的 拟合回归线)# np.sort(x): 按照x的值 升序排列.# np.argsort(x): 按照x的值 升序排列, 返回(x对应的)索引值.plt.plot(np.sort(x), y_predict[np.argsort(x)], c='r') # 基于: 原值的x(特征), y值(预测值)绘制 折线图(就是我们的 拟合回归线)plt.show()
结果

数据是一元二次方程抛物线, 给模型的数据, 增加x²项特征, 再用线性模型拟合, 模型结果正拟合
过拟合
代码
def dm03_过拟合():# 1. 准备数据.# 准备噪声(可以简单理解为就是: 随机种子), 噪声相同, 每次生成的随机数(点)相同.np.random.seed(21)# x: 表示特征, -3 ~ 3之间 随机的小数, 生成: 100个.x = np.random.uniform(-3, 3, size=100)# y: 表示标签(目标值), 线性关系: y = 0.5x² + x + 2 + 正态分布 + 噪声.# np.random.normal(0, 1, size=100) 意思是: 均值为0, 标准差为1, 生成100个.y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 模型训练.# 2. 创建 线性回归-正规方程 模型对象.estimator = LinearRegression(fit_intercept=True) # 计算: 偏置.# 3. 对数据集做处理.# 3.1 把数据从 一维数组 => 二维数组, 即: 从 [1, 2, 3] => [[1], [2], [3]]X = x.reshape(-1, 1)# 3.2 拼接: x, x的平方, x的立方, x的四次方..., 把数据从 [[1], [2], [3]] => [[1, 1....], [2, 4, 8, 16, 32, 64...], [3, 9, 27...]] 一元线性回归 => 二元线性回归X3 = np.hstack([X, X ** 2, X ** 3, X ** 4, X ** 5, X ** 6, X ** 7, X ** 8, X ** 9, X ** 10]) # 继续增加 最高次项print(f'处理前 x => {x}') # 假设: x = [1, 2, 3]print(f'处理后 X => {X}') # 处理后: X = [[1], [2], [3]]print(f'处理后 X2 => {X3}') # 处理后: X = [[1], [2], [3]]
# 4. 模型训练.estimator.fit(X3, y) # 这里传的是, 处理后的x的值, 即: 二维数组 => 多元线性回归# 5. 模型预测.y_predict = estimator.predict(X3)print(f'预测值为: {y_predict}')# 6. 模型评估.print(f'均方误差: {mean_squared_error(y, y_predict)}') # 均方误差: 0.9646255969834893# 7. 数据可视化, 绘制图像.plt.scatter(x, y) # 基于: 原始的x(特征), y值(真实值)绘制 散点图.
# 细节: 要对x的值进行升序排列, 然后再绘制, 否则会出现: 散点没有连贯性.# plt.plot(x, y_predict, c='r') # 基于: 原值的x(特征), y值(预测值)绘制 折线图(就是我们的 拟合回归线)# np.sort(x): 按照x的值 升序排列.# np.argsort(x): 按照x的值 升序排列, 返回(x对应的)索引值.plt.plot(np.sort(x), y_predict[np.argsort(x)], c='r') # 基于: 原值的x(特征), y值(预测值)绘制 折线图(就是我们的 拟合回归线)plt.show()
结果

数据是一元二次的, 特征值含有多个高次项, 模型过于复杂, 学习到脏数据, 过拟合
产生原因
原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾所有测试样本
解决办法
1)重新清洗数据
导致过拟合的一个原因有可能是数据不纯,如果出现了过拟合就需要重新清洗数据。
2)增大数据的训练量
还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。
3)正则化
4)减少特征维度
正则化
解释正则化
在解决回归过拟合中,我们选择正则化。但是对于其他机器学习算法如分类算法来说也会出现这样的问题,除了一些算法本身作用之外(决策树、神经网络),我们更多的也是去自己做特征选择,包括之前说的删除、合并一些特征


在学习的时候,数据提供的特征有些影响模型复杂度或者这个特征的数据点异常较多,所以算法在学习的时候尽量减少这个特征的影响(甚至删除某个特征的影响),这就是正则化
注:调整时候,算法并不知道某个特征影响,而是去调整参数得出优化的结
★L1正则化
概念原理
L1正则化,在损失函数中添加L1正则化项
![]()
α 叫做惩罚系数,该值越大则权重调整的幅度就越大,即:表示对特征权重惩罚力度就越大
L1 正则化会使得权重趋向于 0,甚至等于 0,使得某些特征失效,达到特征筛选的目的

代码演示
# 4. 定义函数, 表示: L1正则化 => 解决 过拟合问题的, 降低模型复杂度, 可能会使得权重变为0 => 特征选取.
def dm04_L1正则化():# 1. 准备数据.# 准备噪声(可以简单理解为就是: 随机种子), 噪声相同, 每次生成的随机数(点)相同.np.random.seed(21)# x: 表示特征, -3 ~ 3之间 随机的小数, 生成: 100个.x = np.random.uniform(-3, 3, size=100)# y: 表示标签(目标值), 线性关系: y = 0.5x² + x + 2 + 正态分布 + 噪声.# np.random.normal(0, 1, size=100) 意思是: 均值为0, 标准差为1, 生成100个.y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 模型训练.# 2. 创建 线性回归-正规方程 模型对象.# estimator = LinearRegression(fit_intercept=True) # 计算: 偏置.# 2. 创建 线性回归-L1正则化 模型对象.estimator = Lasso(alpha=0.1) # alpha: 正则化参数, 其值越大, 则正则化程度越高, 即: 权重值越小, 则越容易被截断为0.
# 3. 对数据集做处理.# 3.1 把数据从 一维数组 => 二维数组, 即: 从 [1, 2, 3] => [[1], [2], [3]]X = x.reshape(-1, 1)# 3.2 拼接: x, x的平方, x的立方, x的四次方..., 把数据从 [[1], [2], [3]] => [[1, 1....], [2, 4, 8, 16, 32, 64...], [3, 9, 27...]] 一元线性回归 => 二元线性回归X3 = np.hstack([X, X ** 2, X ** 3, X ** 4, X ** 5, X ** 6, X ** 7, X ** 8, X ** 9, X ** 10]) # 继续增加 最高次项print(f'处理前 x => {x}') # 假设: x = [1, 2, 3]print(f'处理后 X => {X}') # 处理后: X = [[1], [2], [3]]print(f'处理后 X2 => {X3}') # 处理后: X = [[1], [2], [3]]
# 4. 模型训练.estimator.fit(X3, y) # 这里传的是, 处理后的x的值, 即: 二维数组 => 多元线性回归# 5. 模型预测.y_predict = estimator.predict(X3)print(f'预测值为: {y_predict}')# 6. 模型评估.print(f'均方误差: {mean_squared_error(y, y_predict)}') # 均方误差: 1.026270345364126# 7. 数据可视化, 绘制图像.plt.scatter(x, y) # 基于: 原始的x(特征), y值(真实值)绘制 散点图.
# 细节: 要对x的值进行升序排列, 然后再绘制, 否则会出现: 散点没有连贯性.# plt.plot(x, y_predict, c='r') # 基于: 原值的x(特征), y值(预测值)绘制 折线图(就是我们的 拟合回归线)# np.sort(x): 按照x的值 升序排列.# np.argsort(x): 按照x的值 升序排列, 返回(x对应的)索引值.plt.plot(np.sort(x), y_predict[np.argsort(x)], c='r') # 基于: 原值的x(特征), y值(预测值)绘制 折线图(就是我们的 拟合回归线)plt.show()
结果图

Lasso回归L1正则 会将高次方项系数变为0
★L2正则化
概念原理
L2正则化,在损失函数中添加L2正则化项

α 叫做惩罚系数,该值越大则权重调整的幅度就越大,即:表示对特征权重惩罚力度就越大
L2 正则化会使得权重趋向于 0,一般不等于 0

代码演示
# 5. 定义函数, 表示: L2正则化 => 解决 过拟合问题的, 降低模型复杂度. 会使得权重趋向于0, 不会变为0.
def dm05_L2正则化():# 1. 准备数据.# 准备噪声(可以简单理解为就是: 随机种子), 噪声相同, 每次生成的随机数(点)相同.np.random.seed(21)# x: 表示特征, -3 ~ 3之间 随机的小数, 生成: 100个.x = np.random.uniform(-3, 3, size=100)# y: 表示标签(目标值), 线性关系: y = 0.5x² + x + 2 + 正态分布 + 噪声.# np.random.normal(0, 1, size=100) 意思是: 均值为0, 标准差为1, 生成100个.y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 模型训练.# 2. 创建 线性回归-正规方程 模型对象.# estimator = LinearRegression(fit_intercept=True) # 计算: 偏置.# 2. 创建 线性回归-L2正则化 模型对象.estimator = Ridge(alpha=0.1) # alpha: 正则化参数, 其值越大, 则正则化程度越高, 即: 权重值越小, 则越容易被截断为0.
# 3. 对数据集做处理.# 3.1 把数据从 一维数组 => 二维数组, 即: 从 [1, 2, 3] => [[1], [2], [3]]X = x.reshape(-1, 1)# 3.2 拼接: x, x的平方, x的立方, x的四次方..., 把数据从 [[1], [2], [3]] => [[1, 1....], [2, 4, 8, 16, 32, 64...], [3, 9, 27...]] 一元线性回归 => 二元线性回归X3 = np.hstack([X, X ** 2, X ** 3, X ** 4, X ** 5, X ** 6, X ** 7, X ** 8, X ** 9, X ** 10]) # 继续增加 最高次项print(f'处理前 x => {x}') # 假设: x = [1, 2, 3]print(f'处理后 X => {X}') # 处理后: X = [[1], [2], [3]]print(f'处理后 X2 => {X3}') # 处理后: X = [[1], [2], [3]]
# 4. 模型训练.estimator.fit(X3, y) # 这里传的是, 处理后的x的值, 即: 二维数组 => 多元线性回归# 5. 模型预测.y_predict = estimator.predict(X3)print(f'预测值为: {y_predict}')# 6. 模型评估.print(f'均方误差: {mean_squared_error(y, y_predict)}') # 均方误差: 0.964988964298911# 7. 数据可视化, 绘制图像.plt.scatter(x, y) # 基于: 原始的x(特征), y值(真实值)绘制 散点图.
# 细节: 要对x的值进行升序排列, 然后再绘制, 否则会出现: 散点没有连贯性.# plt.plot(x, y_predict, c='r') # 基于: 原值的x(特征), y值(预测值)绘制 折线图(就是我们的 拟合回归线)# np.sort(x): 按照x的值 升序排列.# np.argsort(x): 按照x的值 升序排列, 返回(x对应的)索引值.plt.plot(np.sort(x), y_predict[np.argsort(x)], c='r') # 基于: 原值的x(特征), y值(预测值)绘制 折线图(就是我们的 拟合回归线)plt.show()
结果图

Ridge线性回归l2正则不会将系数变为0 但是对高次方项系数影响较大
L1与L2的区别
工程开发中L1、L2使用建议:一般倾向使用L2正则。
相同点
都可以降低模型的复杂度, 都可以解决: 过拟合问题.
不同点
L1正则化会使得特征的权重变为0, 一般适用于: 特征选取.L2正则化会使得特征的权重趋向于0, 不会变为零. 可以解决 过拟合问题, 一般首选用 它.
相关文章:
机器学习篇-day03-线性回归-正规方程与梯度下降-模型评估-正则化解决模型拟合问题
一. 线性回归简介 定义 线性回归(Linear regression)是利用 回归方程(函数) 对 一个或多个自变量(特征值)和因变量(目标值)之间 关系进行建模的一种分析方式。 回归方程(函数) 一元线性回归: y kx b > wx b k: 斜率, 在机器学习中叫 权重(weight), 简称: w b: 截距, 在机…...

图像人脸与视频人脸匹配度检测
import cv2 import dlib import numpy as np import os from pathlib import Path# 加载预训练模型 face_recognition_model "dlib_face_recognition_resnet_model_v1.dat" face_recognition_net dlib.face_recognition_model_v1(face_recognition_model)detector …...

【AI绘画】Midjourney进阶:对称构图详解
博客主页: [小ᶻZ࿆] 本文专栏: AI绘画 | Midjourney 文章目录 💯前言💯什么是构图为什么Midjourney要使用构图 💯对称构图特点使用场景提示词书写技巧测试 💯小结 💯前言 通常来学习AI绘画的人可以分为…...

道路积水检测数据集 1450张 路面积水 带分割 voc yolo
道路积水检测数据集 1450张 路面积水 带分割 voc yolo 分类名: (图片张数, 标注个数) puddle:(1468,1994) 总数:(1468,1994) 总类(nc): 1类 道路积水检测数据集介绍 项目名称 道路积水检测数据集 项目概述 本数据集包含1450张带有标注的图像&#x…...

上门安装维修系统小程序开发详解及源码示例
随着智能家居和设备的普及,消费者对上门安装和维修服务的需求日益增加。为了满足这一市场需求,开发一款上门安装维修系统小程序成为了一种有效的解决方案。本文将详细介绍上门安装维修系统小程序的开发过程,并提供一个简单的源码示例…...

03_23 种设计模式之《原型模式》
文章目录 一、原型模式基础知识原型模式的结构应用场景 实例拷贝构造函数被调用场景如下:典型的应用场景: 一、原型模式基础知识 原型模式是一种创建型设计模式,其功能为复制一个运行时的对象,包括对象各个成员当前的值。而代码又…...
-三语言题解)
【秋招笔试】10.08华为荣耀秋招(已改编)-三语言题解
🍭 大家好这里是 春秋招笔试突围,一起备战大厂笔试 💻 ACM金牌团队🏅️ | 多次AK大厂笔试 | 大厂实习经历 ✨ 本系列打算持续跟新 春秋招笔试题 👏 感谢大家的订阅➕ 和 喜欢💗 和 手里的小花花🌸 ✨ 笔试合集传送们 -> 🧷春秋招笔试合集 本次的三题全部上线…...

基于ResNet50模型的船型识别与分类系统研究
关于深度实战社区 我们是一个深度学习领域的独立工作室。团队成员有:中科大硕士、纽约大学硕士、浙江大学硕士、华东理工博士等,曾在腾讯、百度、德勤等担任算法工程师/产品经理。全网20多万粉丝,拥有2篇国家级人工智能发明专利。 社区特色…...
一个为分布式环境设计的任务调度与重试平台,高灵活高效率,系统安全便捷,分布式重试杀器!(附源码)
背景 近日挖掘到一款名为“SnailJob”的分布式重试开源项目,它旨在解决微服务架构中常见的重试问题。在微服务大行其道的今天,我们经常需要对某个数据请求进行多次尝试。然而,当遇到网络不稳定、外部服务更新或下游服务负载过高等情况时,请求…...
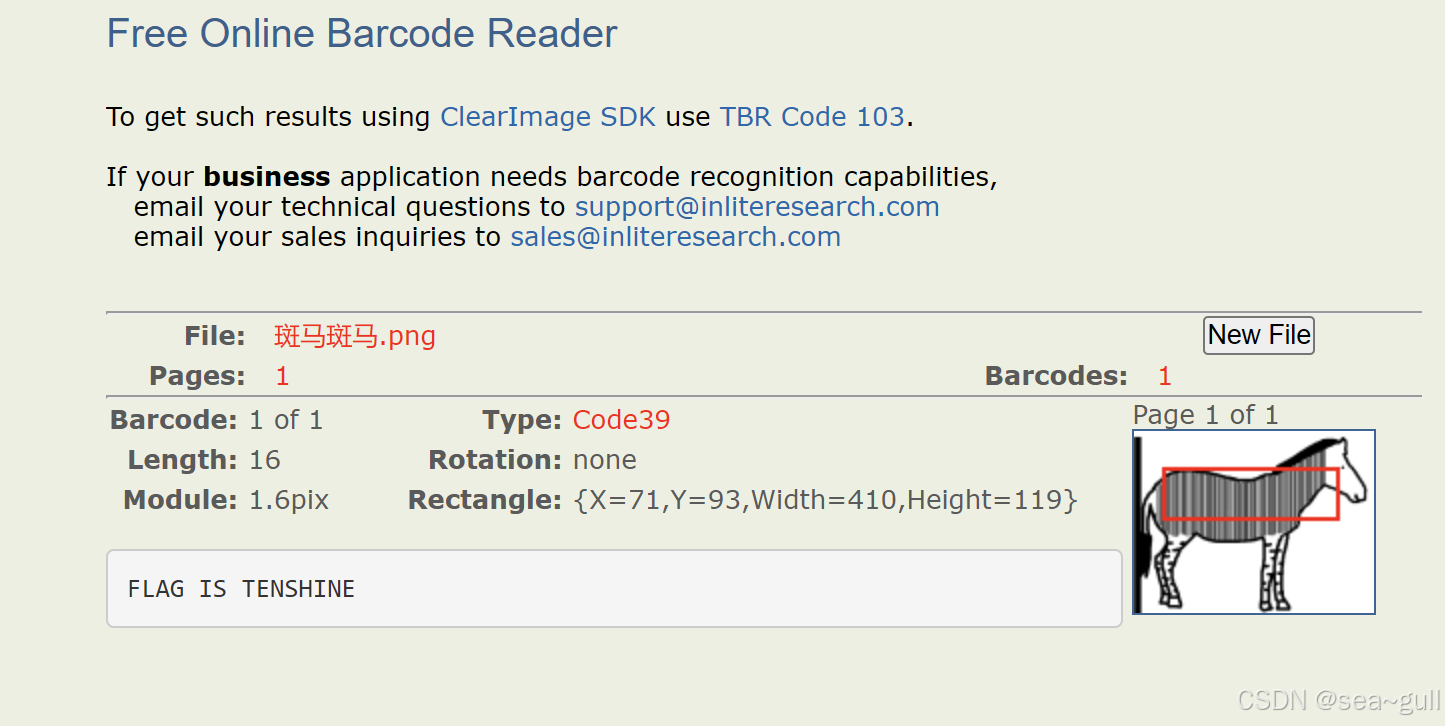
攻防世界(CTF)~Misc-Banmabanma
题目介绍 附件下载后得到一张图片类,似一只斑马,仔细观看发现像条形码 用条形码在线阅读查看一下 条形码在线识别 flag{TENSHINE}...

获取淘宝直播间弹幕数据的技术探索实践方法
在数字时代,直播已成为电商营销的重要渠道之一,而弹幕作为直播互动的核心元素,蕴含着丰富的用户行为和情感数据。本文将详细介绍如何获取淘宝直播间弹幕数据的技术方法和步骤,同时分析不同工具和方法的优缺点,并提供实…...

Python 卸载所有的包
Python 卸载所有的包 引言正文 引言 可能很少有小伙伴会遇到这个问题,当我们错误安装了一些包后,由于包之间有相互关联,导致一些已经安装的包无法使用,而由于我们已经安装了很多包,它们的名字我们并不完全知道&#x…...
、Token、Session和Cookie)
JWT(JSON Web Token)、Token、Session和Cookie
JWT(JSON Web Token)、Token、Session和Cookie都是Web开发中常用的概念,它们各自在不同的场景下发挥着重要的作用。以下是对这四个概念的详细解释和比较: 一、JWT(JSON Web Token) 定义:JWT是一…...

国内知名人工智能AI大模型专家培训讲师唐兴通讲授AI办公应用人工智能在营销与销售过程中如何应用数字化赋能
AI如火如荼,对商业与社会影响很大。 目前企业广泛应用主要是在营销、销售方向,提升办公效率等方向。 从喧嚣的AI导入营销与销售初步阶段,那么当下,领先的组织与个人现在正在做什么呢? 如何让人性注入冷冰冰的AI&…...

Android常用C++特性之std::swap
声明:本文内容生成自ChatGPT,目的是为方便大家了解学习作为引用到作者的其他文章中。 std::swap 是 C 标准库中提供的一个函数,位于 <utility> 头文件中。它用于交换两个变量的值。 语法: #include <utility>std::s…...

MongoDB数据库详解:特点、架构与应用场景
目录 MongoDB 简介MongoDB 的核心特点 2.1 面向文档的存储2.2 动态架构2.3 水平扩展能力2.4 强大的查询能力 MongoDB 的架构设计 3.1 存储引擎3.2 集群架构3.3 副本集(Replica Set)3.4 分片(Sharding) MongoDB 常见应用场景 4.1 …...

【C语言刷力扣】1678.设计Goal解析器
题目: 解题思路: 遍历分析每一个字符,对不同情况分别讨论。 若是字符 G ,则 res 中添加字符 G若是字符 ( ,则再分别讨论。 若下一个字符是 ), 则在 res 末尾添加字符 o若下一个字符…...

RK3568平台开发系列讲解(I2C篇)i2c 总线驱动介绍
🚀返回专栏总目录 文章目录 一、i2c 总线定义二、i2c 总线注册三、i2c 设备和 i2c 驱动匹配规则沉淀、分享、成长,让自己和他人都能有所收获!😄 i2c 总线驱动由芯片厂商提供,如果我们使用 ST 官方提供的 Linux 内核, i2c 总线驱动已经保存在内核中,并且默认情况下已经…...

xilinx中bufgce
在Xilinx的FPGA设计中,BUFGCE是一种重要的全局时钟缓冲器原语,它基于BUFGCTRL并以一些引脚连接逻辑高电位和低电位。以下是对BUFGCE的详细解析: 一、BUFGCE的功能与特点 功能:BUFGCE是带有时钟使能信号的全局缓冲器。它接收一个时…...
雷池+frp 批量设置proxy_protocol实现真实IP透传
需求 内网部署safeline,通过frp让外网访问内部web网站服务,让safeline记录真实外网攻击IP safeline 跟 frp都部署在同一台服务器:192.168.2.103 frp client 配置 frpc只需要在https上添加transport.proxyProtocolVersion "v2"即…...

Gofile下载神器:5分钟快速上手的高效命令行工具
Gofile下载神器:5分钟快速上手的高效命令行工具 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 你是否经常需要从Gofile.io下载大量文件,却厌倦了手…...

为什么你的Perplexity返回过时新闻?环境时区、缓存策略与源权重配置三重校准指南
更多请点击: https://intelliparadigm.com 第一章:为什么你的Perplexity返回过时新闻?环境时区、缓存策略与源权重配置三重校准指南 Perplexity 的实时新闻响应延迟,常被误认为模型能力缺陷,实则源于底层检索链路中三…...

如何用OpenCATS免费开源招聘系统3天搭建企业级人才库
如何用OpenCATS免费开源招聘系统3天搭建企业级人才库 【免费下载链接】OpenCATS Open-source applicant tracking system (ATS) and recruitment CRM for staffing agencies and hiring teams. 项目地址: https://gitcode.com/gh_mirrors/op/OpenCATS 还在为招聘流程混乱…...

5分钟搭建Sunshine游戏串流:免费开源让全家共享游戏乐趣
5分钟搭建Sunshine游戏串流:免费开源让全家共享游戏乐趣 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在客厅沙发上畅玩书房电脑里的3A大作࿱…...
)
手把手教你用STM32F103C8T6驱动NRF24L01模块(附完整代码与避坑指南)
STM32F103C8T6与NRF24L01无线通信实战:从硬件对接到代码调试全解析 在物联网和智能硬件快速发展的今天,无线通信技术已成为嵌入式系统设计中不可或缺的一环。NRF24L01作为一款性价比极高的2.4GHz无线收发模块,配合STM32F103C8T6这类主流微控制…...

别再让PCIe性能打折扣!手把手教你用lspci和setpci调优MaxPayloadSize
PCIe性能调优实战:用lspci和setpci精准优化MaxPayloadSize 当你的NVMe固态硬盘突然降速,或者10G网卡吞吐量不及预期时,可能正遭遇PCIe链路层的隐形性能杀手。本文将带你用Linux系统自带的lspci和setpci工具,像专业工程师一样诊断和…...

GB/T14710有源设备环境及运输经验总结及怎样避免被的发补
近期有朋友询问:有源设备在检验所做了GB/T 14710里面的振动、碰撞、实车跑提交注册的时候却被审核老师发补重做,14710和运输都要再来一遍,理由是要加上包装运输试验。在我看来是一个不太明智的决定,也是在赌运气,既然花…...

GTA5终极防护与增强指南:YimMenu完整使用教程
GTA5终极防护与增强指南:YimMenu完整使用教程 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu …...

Tunasync调度器工作原理:智能任务分配与并发控制完全指南
Tunasync调度器工作原理:智能任务分配与并发控制完全指南 【免费下载链接】tunasync Mirror job management tool. 项目地址: https://gitcode.com/gh_mirrors/tu/tunasync Tunasync调度器是开源镜像同步工具的核心组件,负责智能任务分配与并发控…...

API 监控告警系统
LogMonitor - API监控告警系统 基于Python的智能API监控系统,集成Splunk日志分析和钉钉告警,支持多种API类型的实时监控和趋势分析。 代码地址 https://github.com/junbingliu007/log_monitor 功能特性 多API类型监控:支持多种API类型智…...