◇【code】PPO: Proximal Policy Optimization
整理的代码库:https://github.com/Gaoshu-root/Code-related-courses/tree/main/RL2024/PPO
OpenAI 文档 —— PPO-Clip
OpenAI 文档 界面链接
PPO: on-policy 算法、适用于 离散 或 连续动作空间。可能局部最优
PPO 的动机与 TRPO 一样:如何利用现有的数据在策略上采取最大可能的改进 step,而不会改动过大而意外导致性能崩溃?
- TRPO 试图用一种复杂的二阶方法来解决这个问题,PPO 则是一种一阶方法,它使用了一些其他技巧来保持 新策略接近旧策略。
- PPO 方法的实现要简单得多,而且从经验上看,其执行效果至少与 TRPO 一样好。
PPO 有两种主要的变体:PPO-Penalty 和 PPO-Clip。
- PPO-Penalty 近似地解决了像 TRPO 这样的 KL 约束更新,但在目标函数中惩罚了 KL-divergence,而不是使其成为硬约束,并在训练过程中自动调整惩罚系数,使其适当缩放。
- PPO-Clip 在目标函数中没有 KL-divergence 项,也没有约束。而是依靠对目标函数的特定裁剪来去除 新策略远离旧策略 的激励。
PPO-Clip (OpenAl 使用的主要变体)。
关键公式
PPO-clip 更新策略: θ k + 1 = arg max θ E s , a ∼ π θ k [ L ( s , a , θ k , θ ) ] \theta_{k+1}=\arg\max\limits_{\theta}\underset{s,a\sim {\pi_{\theta_k}}}{\mathbb E}[L(s,a,\theta_k,\theta)] θk+1=argθmaxs,a∼πθkE[L(s,a,θk,θ)]
通常采取多步(通常是小批量) SGD 来最大化目标。
L ( s , a , θ k , θ ) = min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A π θ k ( s , a ) , clip ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A π θ k ( s , a ) ) L(s,a,\theta_k,\theta)=\min\bigg(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}A^{\pi_{\theta_k}}(s,a),\text{clip}\Big(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)},1-\epsilon,1+\epsilon\Big)A^{\pi_{\theta_k}}(s,a)\bigg) L(s,a,θk,θ)=min(πθk(a∣s)πθ(a∣s)Aπθk(s,a),clip(πθk(a∣s)πθ(a∣s),1−ϵ,1+ϵ)Aπθk(s,a))
- 其中 ϵ \epsilon ϵ 是一个(小)超参数,它大致表示新策略 与 旧策略之间的距离。
这是一个相当复杂的表达式,乍一看很难看出它在做什么,或者它如何帮助保持新策略接近旧策略。事实证明,这个目标有一个相当简化的版本[1],更容易处理(也是我们在代码中实现的版本):
L ( s , a , θ k , θ ) = min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A π θ k ( s , a ) , g ( ϵ , A π θ k ( s , a ) ) ) L(s,a,\theta_k,\theta)=\min\bigg(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}A^{\pi_{\theta_k}}(s, a), g\Big(\epsilon, A^{\pi_{\theta_k}}(s,a)\Big)\bigg) L(s,a,θk,θ)=min(πθk(a∣s)πθ(a∣s)Aπθk(s,a),g(ϵ,Aπθk(s,a)))
- 其中 g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) A A < 0 g(\epsilon,A)=\left\{\begin{aligned}(1+\epsilon)A&~~~~~~~A\geq0\\ (1-\epsilon)A&~~~~~~~A<0\end{aligned}\right. g(ϵ,A)={(1+ϵ)A(1−ϵ)A A≥0 A<0
————————————————
简化版本的 PPO-Clip 目标 推导
整理自 链接 (20180730)
命题 1: PPO-Clip 目标可简化成
L θ k C L I P ( θ ) = E s , a ∼ θ k [ min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A θ k ( s , a ) , g ( ϵ , A θ k ( s , a ) ) ) ] L^{\rm CLIP}_{\theta_k}(\theta)=\underset{s, a\sim\theta_k}{\mathbb E}\bigg[\min\bigg(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}A^{\theta_k}(s, a), g\Big(\epsilon, A^{\theta_k}(s,a)\Big)\bigg)\bigg] LθkCLIP(θ)=s,a∼θkE[min(πθk(a∣s)πθ(a∣s)Aθk(s,a),g(ϵ,Aθk(s,a)))]
- 其中 g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) A otherwise g(\epsilon,A)=\left\{\begin{aligned}(1+\epsilon)A&~~~~~~~A\geq0\\ (1-\epsilon)A&~~~~~~~\text{otherwise}\end{aligned}\right. g(ϵ,A)={(1+ϵ)A(1−ϵ)A A≥0 otherwise
简化过程:
PPO-Clip 的目标函数为:
~
L θ k C L I P ( θ ) ≐ E s , a ∼ θ k [ min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A θ k ( s , a ) , c l i p ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A θ k ( s , a ) ) ] L^{\rm CLIP}_{\theta_k}(\theta)\doteq\underset{s, a\sim\theta_k}{\mathbb E}\bigg[\min\bigg(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}A^{\theta_k}(s, a), {\rm clip}\Big(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)},1-\epsilon, 1+\epsilon\Big)A^{\theta_k}(s, a)\bigg)\bigg] LθkCLIP(θ)≐s,a∼θkE[min(πθk(a∣s)πθ(a∣s)Aθk(s,a),clip(πθk(a∣s)πθ(a∣s),1−ϵ,1+ϵ)Aθk(s,a))]
~
$\underset{s, a\sim\theta_k}{\mathbb E}$E s , a ∼ θ k ~~~\underset{s, a\sim\theta_k}{\mathbb E} s,a∼θkE
- 其中 θ k \theta_k θk 为第 k k k 次迭代 的策略的参数 , ϵ \epsilon ϵ 为 小的超参数。
~
设 ϵ ∈ ( 0 , 1 ) \epsilon\in(0,1) ϵ∈(0,1), 定义
F ( r , A , ϵ ) ≐ min ( r A , c l i p ( r , 1 − ϵ , 1 + ϵ ) A ) F(r,A,\epsilon)\doteq\min\bigg(rA,{\rm clip}(r,1-\epsilon,1+\epsilon)A\bigg) F(r,A,ϵ)≐min(rA,clip(r,1−ϵ,1+ϵ)A)
当 A ≥ 0 A\geq0 A≥0
F ( r , A , ϵ ) = min ( r A , c l i p ( r , 1 − ϵ , 1 + ϵ ) A ) = A min ( r , c l i p ( r , 1 − ϵ , 1 + ϵ ) ) = A min ( r , { 1 + ϵ r ≥ 1 + ϵ r r ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { min ( r , 1 + ϵ ) r ≥ 1 + ϵ min ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) min ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { 1 + ϵ r ≥ 1 + ϵ r r ∈ ( 1 − ϵ , 1 + ϵ ) r r ≤ 1 − ϵ } 根据右侧的范围 = A min ( r , 1 + ϵ ) = min ( r A , ( 1 + ϵ ) A ) \begin{aligned}F(r,A,\epsilon)&=\min\bigg(rA,{\rm clip}(r,1-\epsilon,1+\epsilon)A\bigg)\\ &=A\min\bigg(r,{\rm clip}(r,1-\epsilon,1+\epsilon)\bigg)\\ &=A\min\bigg(r,\left\{\begin{aligned}&1+\epsilon~~&r\geq1+\epsilon\\ &r &r\in(1-\epsilon,1+\epsilon)\\ &1-\epsilon &r\leq1-\epsilon\\ \end{aligned}\right\}\bigg)\\ &=A\left\{\begin{aligned}&\min(r,1+\epsilon)~~&r\geq1+\epsilon\\ &\min(r,r) &r\in(1-\epsilon,1+\epsilon)\\ &\min(r,1-\epsilon) &r\leq1-\epsilon\\ \end{aligned}\right\}\\ &=A\left\{\begin{aligned}&1+\epsilon~~&r\geq1+\epsilon\\ &r &r\in(1-\epsilon,1+\epsilon)\\ &r &r\leq1-\epsilon\\ \end{aligned}\right\}~~~~~\textcolor{blue}{根据右侧的范围}\\ &=A\min(r, 1+\epsilon)\\ &=\min\bigg(rA, (1+\epsilon)A\bigg) \end{aligned} F(r,A,ϵ)=min(rA,clip(r,1−ϵ,1+ϵ)A)=Amin(r,clip(r,1−ϵ,1+ϵ))=Amin(r,⎩ ⎨ ⎧1+ϵ r1−ϵr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧min(r,1+ϵ) min(r,r)min(r,1−ϵ)r≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧1+ϵ rrr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫ 根据右侧的范围=Amin(r,1+ϵ)=min(rA,(1+ϵ)A)
~
当 A < 0 A<0 A<0
F ( r , A , ϵ ) = min ( r A , c l i p ( r , 1 − ϵ , 1 + ϵ ) A ) = A max ( r , c l i p ( r , 1 − ϵ , 1 + ϵ ) ) = A max ( r , { 1 + ϵ r ≥ 1 + ϵ r r ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { max ( r , 1 + ϵ ) r ≥ 1 + ϵ max ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) max ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { r r ≥ 1 + ϵ r r ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } 根据右侧的范围 = A max ( r , 1 − ϵ ) = min ( r A , ( 1 − ϵ ) A ) \begin{aligned}F(r,A,\epsilon)&=\min\bigg(rA,{\rm clip}(r,1-\epsilon,1+\epsilon)A\bigg)\\ &=A\textcolor{blue}{\max}\bigg(r,{\rm clip}(r,1-\epsilon,1+\epsilon)\bigg)\\ &=A\max\bigg(r,\left\{\begin{aligned}&1+\epsilon~~&r\geq1+\epsilon\\ &r &r\in(1-\epsilon,1+\epsilon)\\ &1-\epsilon &r\leq1-\epsilon\\ \end{aligned}\right\}\bigg)\\ &=A\left\{\begin{aligned}&\max(r,1+\epsilon)~~&r\geq1+\epsilon\\ &\max(r,r) &r\in(1-\epsilon,1+\epsilon)\\ &\max(r,1-\epsilon) &r\leq1-\epsilon\\ \end{aligned}\right\}\\ &=A\left\{\begin{aligned}&r~~&r\geq1+\epsilon\\ &r &r\in(1-\epsilon,1+\epsilon)\\ &1-\epsilon &r\leq1-\epsilon\\ \end{aligned}\right\}~~~~~\textcolor{blue}{根据右侧的范围}\\ &=A\max(r, 1-\epsilon)\\ &=\textcolor{blue}{\min}\bigg(rA,(1-\epsilon)A\bigg) \end{aligned} F(r,A,ϵ)=min(rA,clip(r,1−ϵ,1+ϵ)A)=Amax(r,clip(r,1−ϵ,1+ϵ))=Amax(r,⎩ ⎨ ⎧1+ϵ r1−ϵr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧max(r,1+ϵ) max(r,r)max(r,1−ϵ)r≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧r r1−ϵr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫ 根据右侧的范围=Amax(r,1−ϵ)=min(rA,(1−ϵ)A)
~
综上:可定义 g ( ϵ , A ) g(\epsilon,A) g(ϵ,A)
~
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) A A < 0 g(\epsilon,A)=\left\{\begin{aligned}&(1+\epsilon)A ~~~~&A\geq0\\ &(1-\epsilon)A&A<0\end{aligned}\right. g(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0
动机: 如果给定的 状态-动作 对 具有负的优势 A A A,优化想要让 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 更小,但让 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 比 ( 1 − ϵ ) π θ ( a ∣ s ) (1-\epsilon)\pi_\theta(a|s) (1−ϵ)πθ(a∣s) 小对目标函数并没有额外的益处。
如果给定的 状态-动作 对 具有正的优势 A A A,优化想要让 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 更大,但让 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 比 ( 1 + ϵ ) π θ ( a ∣ s ) (1+\epsilon)\pi_\theta(a|s) (1+ϵ)πθ(a∣s) 大对目标函数并没有额外的益处。

————————————————
1、当 advantage优势 为正
L ( s , a , θ k , θ ) = min ( π θ ( a ∣ s ) ↑ π θ k ( a ∣ s ) , 1 + ϵ ) A π θ k ( s , a ) L(s,a,\theta_k, \theta)=\min\bigg(\frac{\pi_\theta(a|s)~\textcolor{blue}{↑}}{\pi_{\theta_k}(a|s)}, 1+\epsilon\bigg)A^{\pi_{\theta_k}}(s, a) L(s,a,θk,θ)=min(πθk(a∣s)πθ(a∣s) ↑,1+ϵ)Aπθk(s,a)
当 状态-动作对 的优势是正的,希望拟习得的策略增大动作 a a a 被执行的概率,即增大 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) ,这将会使得目标增大。
但该项中的 min 限制了 目标函数只能增大到某个值
一旦 π θ ( a ∣ s ) > ( 1 + ϵ ) π θ k ( a ∣ s ) \pi_\theta(a|s)>(1+\epsilon)\pi_{\theta_k}(a|s) πθ(a∣s)>(1+ϵ)πθk(a∣s), min 触发,限制该项值为 ( 1 + ϵ ) π θ k ( a ∣ s ) (1+\epsilon)\pi_{\theta_k}(a|s) (1+ϵ)πθk(a∣s)。
the new policy does not benefit by going far away from the old policy.
新策略 不会因远离 旧策略而受益。
——> 策略将会习得 不要与原策略相差过大。
2、当 advantage优势为负
L ( s , a , θ k , θ ) = max ( π θ ( a ∣ s ) ↓ π θ k ( a ∣ s ) , 1 − ϵ ) A π θ k ( s , a ) L(s,a,\theta_k, \theta)=\max\bigg(\frac{\pi_\theta(a|s) ~\textcolor{blue}{↓}}{\pi_{\theta_k}(a|s)}, 1-\epsilon\bigg)A^{\pi_{\theta_k}}(s, a) L(s,a,θk,θ)=max(πθk(a∣s)πθ(a∣s) ↓,1−ϵ)Aπθk(s,a)
当 某个状态-动作对 的优势是负的,希望拟习得的策略减小该动作 a a a 被执行的概率 ,即 减小 π θ ( a ∣ s ) π_\theta(a|s) πθ(a∣s) ,此时目标函数就会增大。但是该项中的 max 限制了目标函数可以增大到多少。
一旦 π θ ( a ∣ s ) < ( 1 − ϵ ) π θ k ( a ∣ s ) \pi_\theta(a|s)<(1-\epsilon)\pi_{\theta_k}(a|s) πθ(a∣s)<(1−ϵ)πθk(a∣s), max 触发,限制该项值为 ( 1 − ϵ ) π θ k ( a ∣ s ) (1-\epsilon)\pi_{\theta_k}(a|s) (1−ϵ)πθk(a∣s)。
再次说明:the new policy does not benefit by going far away from the old policy.
新策略 不会因远离 旧策略而受益。
注意: 这种 clipping 最终仍有可能得到一个与旧策略相去甚远的新策略,在这里的实现中,我们使用了一个特别简单的方法:提前停止。如果新策略与旧策略的平均 KL -散度超过一个阈值,我们就停止执行梯度步骤。
探索 vs. 利用
PPO 以一种 on-policy 的方式训练随机策略。
这意味着它根据随机策略的最新版本通过抽样动作进行探索。
动作选择的随机性取决于初始条件和训练过程。
在训练过程中,策略通常会逐渐变得不那么随机,因为更新规则会鼓励它利用已经找到的奖励。这可能导致策略陷入局部最优状态。
PPO-Clip 算法伪码

算法: PPO-Clip
1:输入:策略的初始参数 θ 0 \theta_0 θ0,价值函数的初始参数 ϕ 0 \phi_0 ϕ0
2: f o r k = 0 , 1 , 2 , … d o {\bf for} ~ k=0,1,2,\dots~ {\bf do} for k=0,1,2,… do:每个epoch轮次 ~~~~ 未过拟合的前提下,轮次越多越好
3: ~~~~~~ 通过在环境中运行策略 π k = π ( θ k ) \pi_k=\pi(\theta_k) πk=π(θk) 收集轨迹集 D k = { τ i } {\cal D}_k=\{\tau_i\}~~~~~ Dk={τi} ∣ D k ∣ |{\cal D}_k| ∣Dk∣ 个并行 actors,每个 actor 收集 长度为 T T T 个时间步 的数据
4: ~~~~~~ 计算奖励 (rewards-to-go) R ^ t \hat R_t~~~~~ R^t 有些实现用的 td_target R ^ t = ∑ t ′ = t T R ( s t ′ , a t ′ , s t ′ + 1 ) ~~~~~~~~\hat R_t=\sum\limits_{t^\prime=t}^TR(s_{t^\prime},a_{t^\prime},s_{t^\prime +1}) R^t=t′=t∑TR(st′,at′,st′+1) 【参考链接】 ~~~~~ R ( τ ) = ∑ t = 0 ∞ γ t r t R(\tau)=\sum\limits_{t=0}^\infty \gamma^tr_t R(τ)=t=0∑∞γtrt 【参考链接】
5: ~~~~~~ 计算优势估计,基于当前价值函数 V ϕ k V_{\phi_k} Vϕk 的 A ^ t \hat A_t A^t (使用任何优势估计方法) ~~~~~ GAE
6: ~~~~~~ 通过最大化 PPO-Clip 目标 更新策略:
~~~~~~~~~~~
θ k + 1 = arg max θ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T min ( π θ ( a t ∣ s t ) π θ k ( a t ∣ s t ) A π θ k ( s t , a t ) , g ( ϵ , A π θ k ( s t , a t ) ) ) ~~~~~~~~~~~\theta_{k+1}=\arg\max\limits_\theta\frac{1}{|{\cal D}_k|T}\sum\limits_{\tau\in{\cal D}_k}\sum\limits_{t=0}^T\min\Big(\frac{\pi_{\theta} (a_t|s_t)}{\pi_{\theta_k}(a_t|s_t)}A^{\pi_{\theta_k}}(s_t,a_t),g(\epsilon,A^{\pi_{\theta_k}}(s_t,a_t))\Big) θk+1=argθmax∣Dk∣T1τ∈Dk∑t=0∑Tmin(πθk(at∣st)πθ(at∣st)Aπθk(st,at),g(ϵ,Aπθk(st,at)))
~~~~~~~~~~~
~~~~~~~~~~~
~~~~~~~~~~~ 一般 随机梯度上升 + Adam
7: ~~~~~~ 均方误差回归 拟合 价值函数:
~~~~~~~~~~~
ϕ k + 1 = arg min ϕ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T ( V ϕ ( s t ) − R ^ t ) 2 ~~~~~~~~~~~\phi_{k+1}=\arg \min\limits_\phi\frac{1}{|{\cal D}_k|T}\sum\limits_{\tau\in{\cal D}_k}\sum\limits_{t=0}^T\Big(V_\phi(s_t)-\hat R_t\Big)^2 ϕk+1=argϕmin∣Dk∣T1τ∈Dk∑t=0∑T(Vϕ(st)−R^t)2
~~~~~~~~~~~
~~~~~~~~~~~ 一般 梯度下降
8: e n d f o r \bf end ~for end for



$\dots$ … ~~~\dots …
spinup 关于 R ^ t \hat R_t R^t 的计算
# the next two lines implement GAE-Lambda advantage calculationdeltas = rews[:-1] + self.gamma * vals[1:] - vals[:-1]self.adv_buf[path_slice] = core.discount_cumsum(deltas, self.gamma * self.lam)# the next line computes rewards-to-go, to be targets for the value functionself.ret_buf[path_slice] = core.discount_cumsum(rews, self.gamma)[:-1]
def discount_cumsum(x, discount):"""magic from rllab for computing discounted cumulative sums of vectors.input: vector x, [x0, x1, x2]output:[x0 + discount * x1 + discount^2 * x2, x1 + discount * x2,x2]"""return scipy.signal.lfilter([1], [1, float(-discount)], x[::-1], axis=0)[::-1]- spinup/algos/pytorch/ppo
- rllib/algorithms/ppo/torch
第 12 章 PPO 算法 【上交】
整理自 链接
TRPO : 计算过程复杂,每一步更新的运算量非常大。
paperswithcode 页面相关整理
paperswithcode 页面 链接

相关文章:
◇【code】PPO: Proximal Policy Optimization
整理的代码库:https://github.com/Gaoshu-root/Code-related-courses/tree/main/RL2024/PPO OpenAI 文档 —— PPO-Clip OpenAI 文档 界面链接 PPO: on-policy 算法、适用于 离散 或 连续动作空间。可能局部最优 PPO 的动机与 TRPO 一样:…...

Spring Boot 进阶-浅析SpringBoot中如何完成数据校验
在实际开发中,我们经常会遇到接口数据校验的问题。例如在用户输入手机号、或者是身份证号的时候,我们就需要校验手机号或者身份证号是否输入正确。当然这样的校验在前端页面输入的时候就可以完成。 但是对于直接调用接口的情况则不能通过调用方来进行判断,这就需要我们在Spr…...

◇【论文_20181020 v6】广义优势估计器 (generalized advantage estimator, GAE)
https://arxiv.org/abs/1506.02438 ICLR 2016 加州伯克利 电子工程与计算机科学系 High-Dimensional Continuous Control Using Generalized Advantage Estimation 文章目录 摘要1 引言2 预备知识3 优势函数估计4 解释为 奖励设计reward shaping5 价值函数估计6 实验6.1 策略优…...

JAVA后端项目须知
Eureka服务发现框架 Eureka是一个服务发现框架,由Netflix开发,主要用于定位运行在AWS域中的中间层服务,以达到负载均衡和中间层服务故障转移的目的。12 Eureka是Spring Cloud Netflix的一个子模块,也是核心模块之一…...

Java设计模式——适配器模式
目录 模式动机 模式定义 模式结构 代码分析 模式分析 实例 优点 缺点 适用环境 模式应用 模式扩展 总结 模式动机 在软件开发过程中,经常会遇到需要使用已有类的功能,但这些类的接口不符合当前系统的需求,或者需要将不同的类的接…...

docker compose入门6—如何挂载卷
在 Docker Compose 中,可以通过 volumes 字段将宿主机的文件或目录挂载到容器中。这样可以实现数据持久化、共享数据或配置等。以下是一些常见的挂载方式和示例。 1. 挂载单个文件 如果你想将宿主机上的一个特定文件挂载到容器中,可以使用以下格式&…...

linux 环境下 docker 镜像获取失败, 重新设置docker镜像下载地址
1.查询镜像地址 https://hub.atomgit.com/repos/amd64/openjdk 2.docker file FROM hub.atomgit.com/amd64/openjdk:21-rc-jdk COPY xxxx.jar xxxx.jar EXPOSE xxxxx ENTRYPOINT ["java","-jar","-Xmx200M","-agentlib:jdwptransportdt_…...

【React】setState 是怎么记住上一个状态值的?
在 React 中,setState 通过 React 内部的状态管理机制来记住上一个状态值。即使每次组件重新渲染时,函数组件会被重新执行,React 仍能通过其内部的状态管理系统保持和追踪组件的状态变化。下面详细解释其工作原理: 1. setState 的…...

linux批量删文件
在 Linux 中,可以使用命令行工具来批量删除文件。以下是一些常用的方法: 使用 rm 命令 rm 是一个用于删除文件和目录的命令。使用此命令时应谨慎,因为删除操作是不可逆的。 删除特定类型的文件 例如,要删除当前目录下所有的 .tx…...

Kubernetes(K8s)的简介
一、Kubernetes的简介 1 应用部署方式演变 在部署应用程序的方式上,主要经历了三个阶段: 传统部署:互联网早期,会直接将应用程序部署在物理机上 优点:简单,不需要其它技术的参与 缺点:不能为应…...

线性查找法 ← Python实现
【线性查找法】 线性查找法顺序地将关键元素 key 和列表中的每一个元素进行比较。它连续这样做,直到这个关键字匹配列表中的某个元素,或者在没有找到匹配元素时已经查找完整个列表。如果找到一个匹配元素,那么线性查找将返回匹配在列表中的下…...

view deign 和 vue2 合并单元格的方法
1.vue版本和view design 版本 {"vue": "^2.6.11","view-design": "^4.7.0", }2.Data中定义数据 spanArr: [], // 某一列下需要合并的行数 pos: 0// 索引// 注意点: 在获取列表前,需要重置 this.spanArr [] 注…...

Arduino UNO R3自学笔记16 之 Arduino的定时器介绍及应用
注意:学习和写作过程中,部分资料搜集于互联网,如有侵权请联系删除。 前言:学习定时器的功能。 1.定时器介绍 定时器也是一种中断,属于软件中断。 它就像一个时钟,可以测量事件的时间间隔。 比如早…...

鸟类数据集,鸟数据集,目标检测class:bird,共一类13000+张图片yolo格式(txt)
鸟类数据集,鸟数据集,目标检测class:bird,共一类13000张图片yolo格式(txt) 鸟类数据集,鸟数据集,目标检测 class:bird,共一类 13000张图片 yolo格式(txt) 鸟…...

透明物体的投射和接收阴影
1、让透明度测试Shader投射阴影 (1)同样我们使用FallBack的形式投射阴影,但是需要注意的是,FallBack的内容为:Transparent / Cutout / VertexLit,该默认Shader中会把裁剪后的物体深度信息写入到 阴影映射纹…...
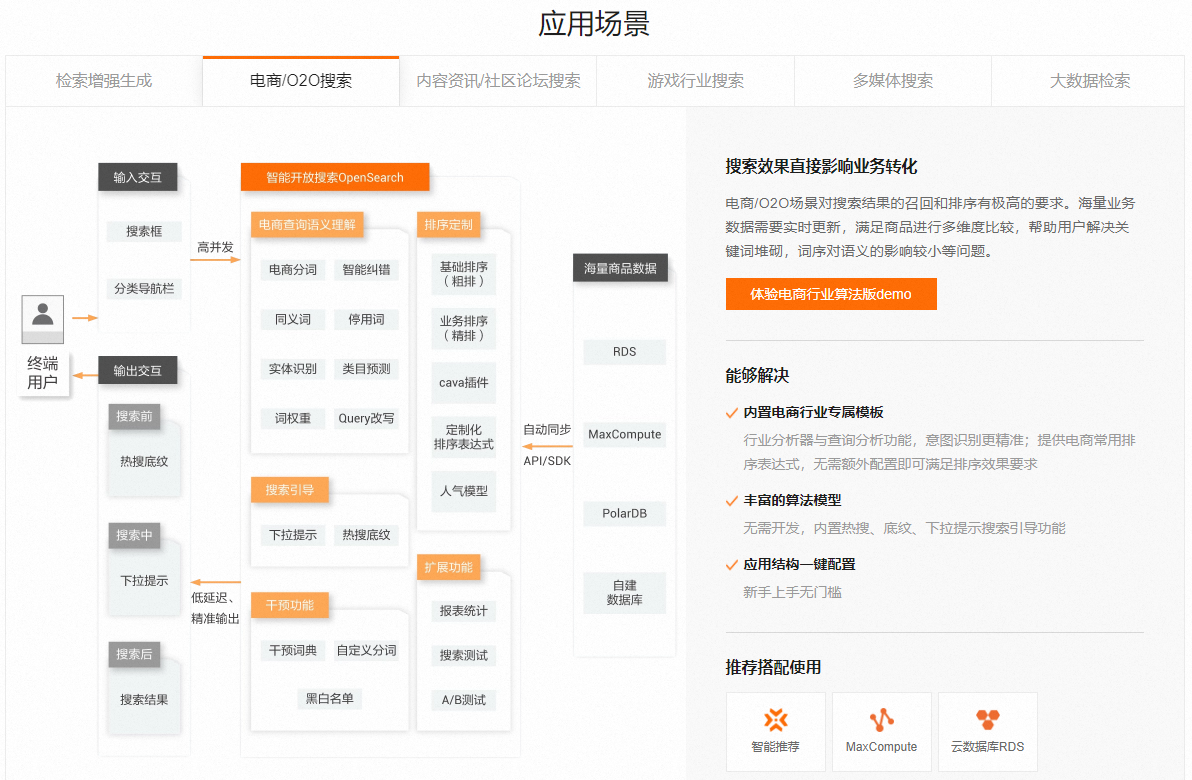
NL2SQL商业案例详解:AI智能开放搜索 OpenSearch
NL2SQL商业案例详解:AI智能开放搜索 OpenSearch 基于阿里巴巴自主研发的大规模分布式搜索引擎搭建的一站式智能搜索业务开发平台,目前为包括淘宝、天猫在内的阿里集团核心业务提供搜索服务支持。通过内置各行业的查询语义理解、机器学习排序算法等能力,以及充分开放的文本向…...

【万字长文】Word2Vec计算详解(一)
【万字长文】Word2Vec计算详解(一) 写在前面 本文用于记录本人学习NLP过程中,学习Word2Vec部分时的详细过程,本文与本人写的其他文章一样,旨在给出Word2Vec模型中的详细计算过程,包括每个模块的计算过程&a…...

【EXCEL数据处理】000022 案例 保姆级教程,附多个操作案例。EXCEL邮件合并工具
前言:哈喽,大家好,今天给大家分享一篇文章!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 【EXCEL数据处理】000022 案例 保姆级教程,附多个操作案例。…...

第十五周:机器学习笔记
第十五周周报 摘要Abstract一、机器学习1. 各式各样神奇的自注意力机制1.1 Local Attention/Truncated Attention(截断注意力机制)1.2 Stride Attention(跨步注意力机制)1.3 Global Attention(全局注意力机制ÿ…...

Highcharts 散点图
Highcharts 散点图 介绍 Highcharts 是一个流行的 JavaScript 图表库,广泛用于网页上展示动态和交互式的图表。散点图是 Highcharts 提供的一种图表类型,它通过在二维坐标系中展示数据点的分布,来揭示变量之间的关系。散点图特别适用于展示和比较大量的数据点,从而发现数…...

如何在5分钟内解锁所有Steam成就:Steam Achievement Manager完整使用指南
如何在5分钟内解锁所有Steam成就:Steam Achievement Manager完整使用指南 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 还在为Steam游戏中那…...

国产OK镜靠谱品牌怎么选?欧普康视硬核资质与全维度实力详解
导读:当下国民近视问题愈发普遍,大众对安全、高效的非手术视力矫正需求持续攀升。角膜塑形镜(OK镜)凭借非手术、可逆、日间高清裸眼视力的核心优势,成为青少年近视防控、成年人视力矫正的主流选择。但市面上OK镜品牌繁…...

14.3 异步协程开发铁律示例 与 标准示例代码核心:事件循环内严禁编写同步逻辑,协程业务务必全程异步
Python异步协程从原理到实战完整总结 一、协程底层核心 asyncio 基于单线程事件循环驱动运行,通过 await 主动让出执行权完成任务切换,切换开销远低于多线程,天生适配IO密集型业务场景; 单线程特性决定它无法直接利用多核处理CPU密…...

谷歌开发者大会2026:Gemini全面升级,重塑搜索与生活体验!
谷歌开发者大会2026开幕在品尝过「会前甜点」Android Show 之后,真正的重头戏谷歌开发者大会 Google I/O 2026 正式揭开了帷幕。不出所料,在时长接近两个小时的活动中,Gemini 占据了绝对的 C 位。除了更新基础模型和周边能力之外,…...

程序员职业生涯系列:关于技术能力的思考与总结
工作几十年,我面试过几百个程序员,带过十几个团队,自己也从一个写CRUD都费劲的菜鸟成长为架构师。回头看,最让我困惑过的一个问题是:什么才是真正的技术能力? 是LeetCode刷到300题?是把某个框架源码啃得烂熟?是写过多少个高并发项目?还是那张挂在墙上的高级职称证书?…...

ChipDNA PUF技术:从晶体管失配到硬件安全密钥的工程实践
1. 项目概述:当芯片拥有“DNA”,嵌入式安全进入新纪元在嵌入式系统设计领域,安全从来不是一个可以事后弥补的附加功能,而是必须从硬件层面开始构建的基石。随着物联网设备的爆炸式增长,从智能门锁到工业控制器…...

别死磕数据线!聊聊EMMC BGA布线里那些能删掉的‘废脚’
别死磕数据线!EMMC BGA布线中那些被忽略的"废脚"优化策略 在PCB layout工程师的日常工作中,EMMC存储器的BGA封装布线常常让人头疼不已。0.5mm的球间距、密集的数据线、严格的阻抗要求,这些因素叠加在一起,往往让设计者…...

日志分析 Elasticsearch 和 logstach.filebeat.
一、Elasticsearch 到底是啥?简单说,ES 就是一个能飞速搜索和分析海量数据的搜索引擎。类似百度、谷歌,但它是给你公司内部的数据用的。比如:淘宝搜商品,输入“手机 拍照好”,毫秒级给你结果——背后就是 E…...

CentOS 7服务器部署:NFS共享、Nginx-RTMP流媒体与Qt无GUI环境全攻略
1. 项目概述与核心思路最近在华为云的一台CentOS 7.4 64位服务器版ECS上,完整部署了一套用于音视频处理和后台服务的开发环境。这个环境的核心目标,是为一个需要处理视频流、提供Web服务,并能方便地进行跨机文件共享和Qt程序编译的后台系统打…...

别再说国产模型不行了!DeepSeek V4 + Claude Code,编程体验直接起飞
别再说国产模型不行了!DeepSeek V4 Claude Code,编程体验直接起飞 还在觉得 DeepSeek V4 不如国外模型? 醒醒,2026 年了。DeepSeek V4 系列在代码能力上已经卷到让人窒息——而且价格只有 Claude 官方的零头。 但问题来了&…...