like 模糊查询的底层算法
like 模糊查询的底层算法
全文搜索算法、模糊查询、n-gram分隔算法
功能介绍
百度搜索,文心一言给出的结果:
SQL模糊查询底层通常使用全文搜索算法,如LIKE操作符和全文索引通常使用的n-gram分割算法。
n-gram是一种将文本分割成固定大小的词组的算法,通常用于文本搜索和自然语言处理。在SQL中,全文索引通常以n-gram的方式工作,其中n取决于索引的granularity设置。
再次搜索,找到一篇博客,部分内容是这么说的:
ngram是全文解析器能够对文本进行分词,中文分词用 ngram_token_size 设定分词的大小,ngram_token_size 的值就是连续n个字的序列。
示例:使用ngram对于‘全文索引进行分词’:
ngram_token_size =1,分词为 ‘全‘,’文‘,’索‘,’引‘
ngram_token_size =2,分词为 ‘全文‘,’文索‘,’索引‘
ngram_token_size =3,分词为 ‘全文索‘,’文索引‘
ngram_token_size =4,分词为 ‘全文索引‘
查看配置ngram_token_size:
#查看默认分词大小 ngram_token_size=2
show variables like '%token%';
innodb_ft_min_token_size
默认3,表示最小3个字符作为一个关键词,增大该值可减少全文索引的大小
innodb_ft_max_token_size
默认84,表示最大84个字符作为一个关键词,限制该值可减少全文索引的大小
ngram_token_size
默认2,表示2个字符作为内置分词解析器的一个关键词,如对“abcd”建立全文索引,关键词为’ab’,‘bc’,‘cd’
当使用ngram分词解析器时,innodb_ft_min_token_size和innodb_ft_max_token_size 无效
创建全文索引的方法移步刚才的博客。
全文搜索算法 原理简介
起由
关于全文搜索算法,我找到了这样一篇厉害的博客,
09年的,非常好,可惜没有作者13 14年后文章了。
以下内容源于我对这篇博客的理解,恭疏短引:
全文搜索算法出现的原因:对于大量 不定长或无固定格式 的非结构化数据,顺序扫描法效率很低。
优化思路:由于结构化数据有一定的结构可以采取一定的搜索算法加快速度,
所以,我们将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,这个重新组织的 有一定结构的信息
称为索引,然后对索引搜索,从而实现加速目的。
这个先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
原理
索引中的内容
从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引。
建立一个词典,词典中每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表(Posting List)。
全文搜索相对于顺序扫描的优势之一:一次索引,多次使用。
如何创建索引
1. 为了方便说明索引创建过程,这里特意用两个文件为例:
文件一:Students should be allowed to go out with their friends, but not allowed to drink beer.
文件二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
2. 分词(Tokenizer)
- 将文档分成一个一个单独的单词。
- 去除标点符号。
- 去除停词(Stop word)。
经过分词(Tokenizer)后得到的结果称为词元(Token):
“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“allowed”。
3. 词元(Token)传给语言处理组件(Linguistic Processor)
- 变为小写(Lowercase)。
- 将单词缩减为词根形式,如“cars”到“car”等。这种操作称为:stemming。
- 将单词转变为词根形式,如“drove”到“drive”等。这种操作称为:lemmatization。
语言处理组件(linguistic processor)的结果称为词(Term):
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
4. 词(Term)传给索引组件(Indexer)
(示例见原文)
- 利用得到的词(Term)创建一个字典,包含字符串和文档id
- 对字典按字母顺序进行排序
- 合并相同的词(Term)成为文档倒排(Posting List)链表
表中,有几个定义:
Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
Frequency 即词频率,表示此文件中包含了几个此词(Term)。
如果搜索“driving”,查询语句经过这里的一到三步,变为“drive”,从而可以搜索到想要的文档。
如何搜索索引
经过上面的处理,搜索到的结果可能非常多,我们可能找不到最想看的文章。
1. 输入查询语句
2. 对查询语句进行词法分析,语法分析,及语言处理
3. 搜索索引,得到符合语法树的文档
搜索索引分几小步:
- 首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
- 其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
- 然后,将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,从而得到既包含lucene又包含learn而且不包含hadoop的文档链表。
- 此文档链表就是我们要找的文档。
4. 根据得到的文档和查询语句的相关性,对结果进行排序
- 首先,一个文档有很多词(Term)
- 对于文档之间的关系,不同的Term重要性不同。
- 找出词(Term)对文档的重要性的过程称为计算词的权重(Term weight)的过程。
- 影响权重的因素:
Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。 - 权重 w = tf x log (n / df) 其中,n为该词在所有文档中出现的总次数
- 判断Term之间的关系从而得到文档相关性,使用向量空间模型的算法(VSM)
- 把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
- 把此文档中各个词(term)的权重(term weight) 看作一个向量。
- Document = {term1, term2, …… ,term N}
- Document Vector = {weight1, weight2, …… ,weight N}
- 把查询语句看作一个简单的文档,也用向量来表示。
- Query = {term1, term 2, …… , term N}
- Query Vector = {weight1, weight2, …… , weight N}
- 把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。
- 维数不同时,取二者的并集,如果不含某个词(Term),则权重(Term Weight)为0。
- 计算夹角的余弦值作为相关性的打分,夹角越小,余弦值越大,打分越高,相关性越大。
通读一遍,感觉还是原文写得好,我缩减的不够深入浅出,要点连成片反而抓不到要点了。。。
文末,另附Lucene原理与代码分析完整版
声明:本文使用八爪鱼rpa工具从gitee自动搬运本人原创(或摘录,会备注出处)博客,如版式错乱请评论私信,如情况紧急或久未回复请致邮 xkm.0jiejie0@qq.com 并备注原委;引用本人笔记的链接正常情况下均可访问,如打不开请查看该链接末尾的笔记标题(右击链接文本,点击 复制链接地址,在文本编辑工具粘贴查看,也可在搜索框粘贴后直接编辑然后搜索),在本人博客手动搜索该标题即可;如遇任何问题,或有更佳方案,欢迎与我沟通!
相关文章:

like 模糊查询的底层算法
like 模糊查询的底层算法 全文搜索算法、模糊查询、n-gram分隔算法功能介绍 百度搜索,文心一言给出的结果: SQL模糊查询底层通常使用全文搜索算法,如LIKE操作符和全文索引通常使用的n-gram分割算法。 n-gram是一种将文本分割成固定大小的词…...
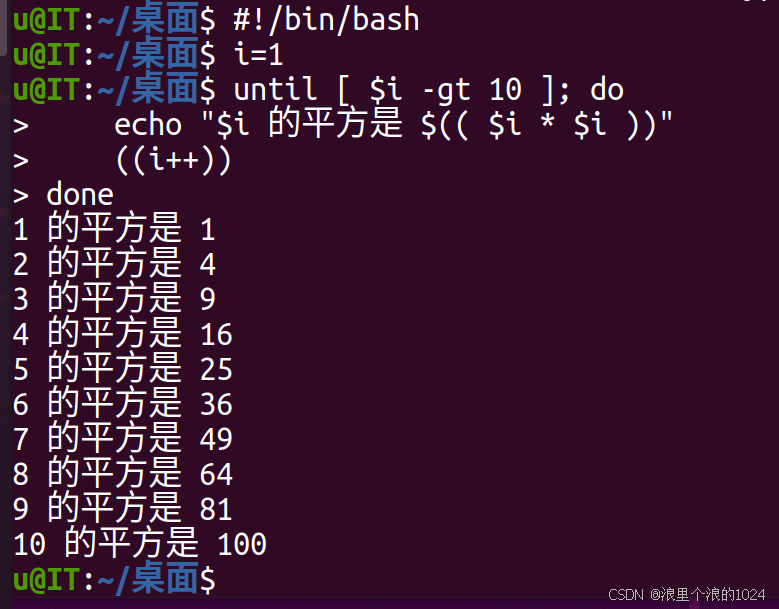
【Linux实践】实验九:Shell流程控制语句
文章目录 实验九:Shell流程控制语句实验目的:实验内容:操作步骤:1. 复制*.c文件并排序2. 计算1-10的平方 实验九:Shell流程控制语句 实验目的: 掌握条件判断语句,如if语句、case语句。掌握循环…...
YOLOv8实战TT100K中国交通标志检测【数据集+YOLOv8模型+源码+PyQt5界面】
YOLOv8实战TT100k交通标志识别 文章目录 研究背景资源获取1.前言1.1 YOLO 系列:中国交通标志检测领域的璀璨明星1.2 Transformer与注意力机制:为中国交通标志检测注入新活力1.3 中国交通标志检测技术:迎接挑战,砥砺前行1.4 YOLOv8…...

SQLite3
文章目录 SQLite3 C/CAPI介绍SQLite3 C/C API 使⽤ SQLite3 C/CAPI介绍 C/C API是SQLite3数据库的⼀个客⼾端,提供⼀种⽤C/C操作数据库的⽅法。 SQLite3 C/C API 使⽤ 下⾯我们将这⼏个接⼝封装成⼀个类,快速上⼿这⼏个接口 创建/打开数据库文件针对打开…...

我的创作纪念日一年
目录 机缘 收获 日常 成就 憧憬 机缘 我之所以开始写CSDN博客,源于一段特殊的时光。去年此时,我独自待在实验室,周围的世界仿佛与我无关。没有旅游,没有与朋友的欢聚,情感的挫折和学业的压力如潮水般袭来。在这样的…...

Docker基本操作命令(一)
Docker 是一个开源的应用容器引擎,允许开发者打包应用以及其依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。主要功能是为开发者提供一个简单…...

PGMP-02项目集管理绩效域
目录 1.概要 2.defintions定义 3.Program Management Performance Domain interactions 交互 4. Organizational Strategy, Portfolio Management, and Program Management Linkage 5. Portfolio and Program Distinctions 区别 6. Program and Project Distinctions区别 …...
总线的仲裁机制)
CAN(Controller Area Network)总线的仲裁机制
CAN(Controller Area Network)总线的仲裁机制是其核心特性之一,它确保了在多节点环境中数据能够高效、公正地传输。以下是对CAN仲裁机制的详细解释和介绍: 一、仲裁机制概述 在CAN总线网络中,各个节点地位平等&#…...

计算机毕业设计 | SpringBoot 房屋租赁网 租房买房卖房平台(附源码)
1,绪论 1.1 背景调研 在房地产行业持续火热的当今环境下,房地产行业和互联网行业协同发展,互相促进融合已经成为一种趋势和潮流。本项目实现了在线房产平台的功能,多种技术的灵活运用使得项目具备很好的用户体验感。 这个项目的…...

OJ在线评测系统 微服务高级 Gateway网关接口路由和聚合文档 引入knife4j库集中查看管理并且调试网关项目
Gateway微服务网关接口路由 各个服务之间已经能相互调用了 为什么需要网关 因为我们的不同服务是放在不同的端口上面的 如果前端调用服务 需要不同的端口 8101 8102 8103 8104 我们最好提供一个唯一的 给前端去调用的路径 我们学习技术的时候必须要去思考 1.为什么要用&am…...

腾讯云上传pushdocker镜像到镜像仓库
文章目录 腾讯云上传docker镜像 腾讯云上传docker镜像 >docker login ccr.ccs.tencentyun.com --usernameXXXXXX用户名>sudo docker tag mynginx:1.0 ccr.ccs.tencentyun.com/crfkitty/mynginx:1.0>docker push ccr.ccs.tencentyun.com/crfkitty/mynginx:1.0 The pu…...

sqli-labs靶场第二关less-2
sqli-labs靶场第二关less-2 本次测试在虚拟机搭建靶场,从主机测试 1、输入?id1和?id2发现有不同的页面回显 2、判断注入类型 http://192.168.128.3/sq/Less-2/?id1’ 从回显判断多一个‘ ,预测可能是数字型注入 输入 http://192.168.128.3/sq/Less…...

Ruby XML, XSLT 和 XPath 教程
Ruby XML, XSLT 和 XPath 教程 1. 引言 Ruby 是一种动态、开放源代码的编程语言,广泛用于网页开发、数据分析和各种自动化任务。在处理 XML(可扩展标记语言)时,Ruby 提供了强大的库和工具,使得解析、转换和提取 XML 数据变得简单高效。本教程将介绍如何使用 Ruby 来处理…...

attain和obtain区别
一、语法问题解答 attain:主要用作及物动词,表示“达到,得到,实现”,通常用于指经过努力达到某种目标、水平或状态,其宾语多为抽象名词,如目标、理想、成就等。它强调通过不懈努力实现某种…...

◇【code】PPO: Proximal Policy Optimization
整理的代码库:https://github.com/Gaoshu-root/Code-related-courses/tree/main/RL2024/PPO OpenAI 文档 —— PPO-Clip OpenAI 文档 界面链接 PPO: on-policy 算法、适用于 离散 或 连续动作空间。可能局部最优 PPO 的动机与 TRPO 一样:…...

Spring Boot 进阶-浅析SpringBoot中如何完成数据校验
在实际开发中,我们经常会遇到接口数据校验的问题。例如在用户输入手机号、或者是身份证号的时候,我们就需要校验手机号或者身份证号是否输入正确。当然这样的校验在前端页面输入的时候就可以完成。 但是对于直接调用接口的情况则不能通过调用方来进行判断,这就需要我们在Spr…...

◇【论文_20181020 v6】广义优势估计器 (generalized advantage estimator, GAE)
https://arxiv.org/abs/1506.02438 ICLR 2016 加州伯克利 电子工程与计算机科学系 High-Dimensional Continuous Control Using Generalized Advantage Estimation 文章目录 摘要1 引言2 预备知识3 优势函数估计4 解释为 奖励设计reward shaping5 价值函数估计6 实验6.1 策略优…...

JAVA后端项目须知
Eureka服务发现框架 Eureka是一个服务发现框架,由Netflix开发,主要用于定位运行在AWS域中的中间层服务,以达到负载均衡和中间层服务故障转移的目的。12 Eureka是Spring Cloud Netflix的一个子模块,也是核心模块之一…...

Java设计模式——适配器模式
目录 模式动机 模式定义 模式结构 代码分析 模式分析 实例 优点 缺点 适用环境 模式应用 模式扩展 总结 模式动机 在软件开发过程中,经常会遇到需要使用已有类的功能,但这些类的接口不符合当前系统的需求,或者需要将不同的类的接…...

docker compose入门6—如何挂载卷
在 Docker Compose 中,可以通过 volumes 字段将宿主机的文件或目录挂载到容器中。这样可以实现数据持久化、共享数据或配置等。以下是一些常见的挂载方式和示例。 1. 挂载单个文件 如果你想将宿主机上的一个特定文件挂载到容器中,可以使用以下格式&…...
)
ADAU1452/1467硬件设计避坑:手把手教你从原理图到SigmaStudio的通道映射(含AD1938实例)
ADAU1452/1467硬件设计实战:从原理图到SigmaStudio的通道映射全解析 在嵌入式音频系统设计中,ADAU1452和ADAU1467作为业界广泛使用的数字信号处理器,其硬件接口配置一直是工程师面临的典型挑战。特别是当系统需要连接多通道编解码器ÿ…...

统信UOS/麒麟KYLINOS用户看过来:除了Termius,这款开源免费的SSH工具electerm更香!
国产操作系统用户的SSH工具新选择:electerm深度体验报告 对于统信UOS和麒麟KYLINOS用户而言,远程服务器管理是日常工作中的高频需求。Termius作为老牌SSH工具确实表现不俗,但今天我们要探讨的electerm,或许能给你带来意想不到的惊…...
)
图吧工具箱下载安装和使用保姆级教程(2026实测)
图吧工具箱全名图拉丁吧硬件检测工具箱,简称 “图吧工具箱”,是国内硬件爱好者社区 “图拉丁吧” 开发维护的免费开源工具合集,2014 年首发,至今持续更新,是 DIY 玩家、装机员、普通用户公认的 “电脑硬件全能管家”。…...

代码随想录算法训练营第六十天|Bellman_ford 队列优化算法、Bellman_ford之判断负权回路、bellman_ford之单源有限最短路
参考文章均来自代码随想录 Bellman_ford 队列优化算法 参考文章链接 对第 59天中的题目进行优化 详细见参考文章推理步骤 还是用邻接表 #include <iostream> #include <vector> #include <queue> #include <list> #include <climits> using …...

《ROS 2机器人开发从入门到实践》 2.3 使用功能包组织C++节点
简介: 上一小节我们用功能包组织了python节点,这节我们把C节点也装进功能包。 参考资料: 参考资料均来自于鱼香ROS社区创始人小鱼,资源如下: ①:【《ROS 2机器人开发从入门到实践》 2.3 使用功能包组织…...

告别传统知识蒸馏:用CVPR2022的‘逆向蒸馏’在PyTorch里玩转工业异常检测
工业级异常检测实战:基于CVPR2022逆向蒸馏的PyTorch实现指南 当传统知识蒸馏在工业缺陷检测中遭遇瓶颈——学生网络对异常样本产生"幻觉响应"、模型对微小缺陷敏感度不足、复杂纹理场景下误报率飙升——CVPR2022提出的逆向蒸馏架构犹如一剂精准的手术刀。…...

从狼群狩猎到参数调优:GWO算法在机器学习超参数搜索中的保姆级指南
从狼群狩猎到参数调优:GWO算法在机器学习超参数搜索中的保姆级指南 在机器学习项目的最后阶段,我们常常会陷入超参数优化的泥潭。网格搜索耗时费力,随机搜索像买彩票,而贝叶斯优化又过于复杂。这时候,一群来自大自然的…...

周末短途游成新风尚,家门口也能遇见诗与远方
如今生活节奏不断加快,长时间的长途旅行对很多人来说成了一种奢望,周末短途游便顺势走进大众生活,成为越来越多人放松身心的选择。不必提前很久规划行程,不用纠结复杂的交通攻略,甚至不用打包厚重的行李,只…...

Windows上运行安卓应用:APK安装器完整指南
Windows上运行安卓应用:APK安装器完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行安卓应用,却不想安装笨重的…...

CANN Ascend C矩阵乘法特殊配置
GetSpecialMDLConfig 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gi…...