【万字长文】Word2Vec计算详解(三)分层Softmax与负采样
【万字长文】Word2Vec计算详解(三)分层Softmax与负采样
写在前面
第三部分介绍Word2Vec模型的两种优化方案。
【万字长文】Word2Vec计算详解(一)CBOW模型 markdown行 9000+
【万字长文】Word2Vec计算详解(二)Skip-gram模型 markdown行 12000+
【万字长文】Word2Vec计算详解(三)分层Softmax与负采样 markdown行 18000+
优化
在原本的Word2Vec模型的 Softmax 层中,对于每一次预测,我们都要计算所有 V V V个单词出现的概率,这在数量级为很大的语料库中,计算的消耗是十分巨大的。下面将介绍两种优化方式,它们均以此为切入点,优化Softmax的计算。
在分层 Softmax中,由于使用了 Huffman 树,我们最多计算 V V V个单词的概率,平均计算为 l o g V logV logV次,相比与原来的 V V V次计算,在数量级巨大时,优化计算十分明显。例如当 V = 1000000 V=1000000 V=1000000 时,在 Softmax 层中,我们将计算 1000000 1000000 1000000 次 e x e^x ex运算,而 l o g ( 1000000 ) ≈ 14 log(1000000) \approx 14 log(1000000)≈14 次(Sigmoid运算), V l o g V = 1000000 14 ≈ 72382 \frac{V}{logV} = \frac{1000000}{14} \approx 72382 logVV=141000000≈72382倍,这个优化十分巨大,我们接下来进入 H-Softmax 的介绍。
分层 Softmax
Hierachical Softmax(分层Softmax)的基本思想就是首先将词典中的每个词按照词频大小构建出一棵 Huffman 树,保证词频较大的词处于相对比较浅的层,词频较低的词相应的处于 Huffman 树较深层的叶子节点,每一个词都处于这棵 Huffman 树上的某个叶子节点。然后我们根据我们所生成的 Huffman 树,我们将从根节点出发,计算并判断结果单词是在左子树的得分大还是在右子树的得分大,进入得分较大的分支所在的下一个节点。递归执行当前节点到达叶子节点时,代表我们找到了预测结果单词。将路径上的得分进行 Sigmoid 转换成概率,我们就可以得到这个概率(得分越高代表概率越大)。
我们本节以 CBOW 模型为例讲述分层 Softmax ,使用了分层 Softmax 进行优化的 CBOW 模型如图下所示。与 CBOW 模型优化前进行对比,可以发现加权平均层以及其之前的层与原来的 CBOW 模型一致。主要的变化是在是在权重输出层和Softmax层,我们将其优化成 H-Softmax 层。我们将在 H-Softmax 层中详细介绍。现在我们回顾一下 CBOW 模型加权平均层及其之前层的处理。

预处理
简单介绍模型输入前的处理。给定一个语料库 text,我们要将其处理成能够用于模型输入的 one-hot 向量。首先去重,然后将单词与标点符号按读入顺序放入集合corpus,并另外存储一份单词与索引直接查询的字典,word_to_id 和 id_to_word。
随后是将单词集合corpus也就是词汇表Vocabulary转换为 one-hot 表示
模型输入
在模型中,将一个词的上下文词表示为独热编码(one-hot encoding)向量然后并作为模型的一个输入。上下文的词的多少取决于窗口大小 C C C,于是我们的输入 X = ( x i − c , x i − c + 1 , … , x i − 1 ∈ R V × 2 C , x i + 1 , … , x i + c ) X = (x_{i-c}, x_{i-c + 1}, \dots, x_{i - 1} \in \mathbb{R}^{V \times 2C}, x_{i + 1}, \dots, x_{i + c}) X=(xi−c,xi−c+1,…,xi−1∈RV×2C,xi+1,…,xi+c), x i x_i xi为目标单词,其中 x i ∈ R V × 1 x_i \in \mathbb{R}^{V \times 1} xi∈RV×1。
权重输入层
在这一层,我们将目标单词 x i x_i xi的上下文的 one-hot 编码与隐藏层的权重输入矩阵 W W W 相乘再加上置偏值 b ∈ R D × 1 b \in \mathbb{R}^{D \times 1} b∈RD×1 得到 x j ′ x_j' xj′,即 X j ′ = W X j + b X_j' = W X_j + b Xj′=WXj+b, 其中 x j ′ ∈ R D × 1 x_j' \in \mathbb{R}^{D \times 1} xj′∈RD×1, j = ( i − C , i − C + 1 , … , i − 1 , i + 1 , … , i + C ) j = (i-C,i-C+1,\dots,i-1,i+1,\dots,i+C) j=(i−C,i−C+1,…,i−1,i+1,…,i+C)。写成矩阵的形式为
X ′ = W X + b X' = WX+b X′=WX+b
加权平均层
我们将输入层得到的所有 x j ′ x_j' xj′ 进行加权平均得到 h h h。
h = ∑ j = i − C , j ≠ i i + C x j ′ = 1 2 C ( x i − C ′ + … x i − 1 ′ + x i + 1 ′ + ⋯ + x i + C ′ ) h = \sum\limits^{i+C}_{j = i-C,j \ne i} x_j'= \frac{1}{2C}(x_{i-C}' + \dots x_{i - 1}' + x_{i + 1}' + \dots + x_{i + C}') h=j=i−C,j=i∑i+Cxj′=2C1(xi−C′+…xi−1′+xi+1′+⋯+xi+C′)
其中 C C C 是窗口大小, h ∈ R D × 1 h \in \mathbb{R}^{D \times 1} h∈RD×1。写成矩阵的形式为
h = 1 2 C X ′ j ⃗ h = \frac{1}{2C} X'\vec{j} h=2C1X′j
其中 j ⃗ = [ 1 , 1 , … , 1 , 1 ] ∈ R 2 C × 1 \vec{j}=\left[1,1,\dots,1,1\right] \in \mathbb{R}^{2C \times 1} j=[1,1,…,1,1]∈R2C×1。
接下来我们开始进入真正的分层 Softmax 模块,即 分层Softmax 层。分层 Softmax 层 的输入是隐藏层的向量 h h h,输入是预测的单词。
分层 Softmax 预处理
在正式进入 分层Softmax层 前我们还有一些预处理操作,即为词汇表构建 Huffman 树。Huffman 树的基础是词汇表中的词频,于是我们简单修改 preprocess函数,统计出词汇表中的每个单词的词频,并加入到返回值中,具体代码见附录优化中的分层Softmax预处理。
我们的目标是通过数组下标为单词索引,值为词频的数组word_count(由preprocess函数生成,在返回值中),来构建 Huffman 树,并生成每个单词对应的路径序列。Huffman 树的构建和路径序列生成的过程步骤如下。
1.初始化优先队列
给定单词集合 { w 1 , w 2 , … , w n } \{w_1, w_2, \ldots, w_n\} {w1,w2,…,wn} 与它们的词频 { f ( w 1 ) , f ( w 2 ) , … , f ( w n ) } \{f(w_1), f(w_2), \ldots, f(w_n)\} {f(w1),f(w2),…,f(wn)},初始化优先队列 Q Q Q,使所有节点按词频从小到大排序。每个节点 N i N_i Ni 表示单词 w i w_i wi 和其词频 f ( w i ) f(w_i) f(wi)。
定义节点 N i N_i Ni如下:
N i = ( w i , f ( w i ) ) N_i = (w_i, f(w_i)) Ni=(wi,f(wi))
初始化优先队列 Q Q Q:
Q = min-heap ( { ( w 1 , f ( w 1 ) ) , ( w 2 , f ( w 2 ) ) , … , ( w n , f ( w n ) ) } ) Q = \text{min-heap}(\{ (w_1, f(w_1)), (w_2, f(w_2)), \ldots, (w_n, f(w_n)) \}) Q=min-heap({(w1,f(w1)),(w2,f(w2)),…,(wn,f(wn))})
2.构建Huffman树
重复以下步骤直到 Q Q Q 中只剩一个节点:
(1) 从 Q Q Q 中取出两个词频最小的节点 N min1 N_{\text{min1}} Nmin1 和 N min2 N_{\text{min2}} Nmin2。(通常情况下,存在两个节点值相同的情况,这时我们按照队列Q的入队顺序进行提取即可)
(2) 创建一个新的内部节点 N new N_{\text{new}} Nnew,其词频为两子节点词频之和:
N new = ( N min1 , N min2 , f ( N min1 ) + f ( N min2 ) ) N_{\text{new}} = (N_{\text{min1}}, N_{\text{min2}}, f(N_{\text{min1}}) + f(N_{\text{min2}})) Nnew=(Nmin1,Nmin2,f(Nmin1)+f(Nmin2))
(3) 将 N new N_{\text{new}} Nnew 添加到 Q Q Q,移除 N min1 N_{\text{min1}} Nmin1 和 N min2 N_{\text{min2}} Nmin2。
3.生成路径序列
为每个单词 w i w_i wi 生成从根节点到叶子节点的路径序列 P ( w i ) P(w_i) P(wi)。路径中向左用“0”表示,向右用“1”表示:
P ( w i ) = { d 1 , d 2 , … , d k } P(w_i) = \{d_1, d_2, \ldots, d_k\} P(wi)={d1,d2,…,dk}
其中 d j d_j dj 表示第 j j j 次向左或向右的决策(“0”表示左,“1”表示右)。
根据上面的步骤,Python的代码实现见附录优化中的构建Huffman树程序代码。
至此我们完成了分层 Softmax 层的预处理,即得到了我们的Huffman树以及对应的路径信息,下面正式进入 分层Softmax 层的介绍。
分层 Softmax 层
对于预处理得到的 Huffman 树,我们为每一个非叶子节点设置一个参数向量 θ ∈ R D × 1 \theta \in \mathbb{R}^{D \times 1} θ∈RD×1 。对于每个节点的输入均是隐藏层的 h h h,将对应的 θ \theta θ 与 h T h^T hT 相乘,加上置偏值 b ′ b' b′,然后取 Sigmoid 得到正向的概率 P i 1 P_i^1 Pi1。那么负向的概率就是 P i 0 = 1 − P i 1 P_i^0 = 1 - P_i^1 Pi0=1−Pi1。
正向概率: P i 1 = σ ( h T θ i + b i ′ ) = 1 1 + e − h T θ i + b i ′ 正向概率: P_i^1 = \sigma(h^T\theta_i + b_i') = \frac{1}{1 + e^{-h^T\theta_i + b_i'}} 正向概率:Pi1=σ(hTθi+bi′)=1+e−hTθi+bi′1
负向概率: P i 0 = 1 − σ ( h T θ i + b i ′ ) 负向概率: P_i^0 = 1 - \sigma(h^T\theta_i + b_i') 负向概率:Pi0=1−σ(hTθi+bi′)
我们依据计算的正向概率和负向概率,按 Huffman 树从根节点到叶子节点单词的路径上的概率 P i d P_i^{d} Pid进行连乘可以得到每个叶子节点单词的概率,即
P ( w o r d i ) = ∏ i = 1 l P i d P(word_i) = \prod_{i = 1}^{l} P_i^{d} P(wordi)=i=1∏lPid
其中 l l l 为路径长度, d d d 只能从0或1中选,即 d ∈ { 0 , 1 } d \in \{0,1\} d∈{0,1}。
然后我们取最大概率的单词作为预测的单词结果。
简单的分层Softmax例子
下面按照原来 CBOW 模型中的例子继续详细介绍下优化后分层 Softmax层 模型预测部分的计算过程。
首先我们的语料库为 text = ‘The cat plays in the garden, and the cat chases the mouse in the garden.’。窗口大小 C = 2 C = 2 C=2,隐藏层的维数 D = 4 D = 4 D=4 ,并且要给定 plays 的上下文进行预测。我们可以得到模型输入是 x 0 x_0 x0 , x 1 x_1 x1 , x 3 x_3 x3 , x 0 x_0 x0,对应单词分别为 the、cat、in、the。则 X = ( x 0 , x 1 , x 3 , x 0 ) X = (x_0, x_1, x_3, x_0) X=(x0,x1,x3,x0),在下方展示。 我们对输入权重权重矩阵 W W W 进行初始化, W W W初始值与原来的CBOW模型中的一致,我们有如下的信息。
X = ( x 0 , x 1 , x 3 , x 0 ) = [ 1 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ] , b = [ 0.0513 − 1.1577 0.8167 0.4336 ] X = (x_0, x_1, x_3, x_0) = \begin{bmatrix} 1&0&0&1\\ 0&1&0&0\\ 0&0&0&0\\ 0&0&1&0\\ 0&0&0&0\\ 0&0&0&0\\ 0&0&0&0\\ 0&0&0&0\\ 0&0&0&0\\ 0&0&0&0 \end{bmatrix} , b = \begin{bmatrix} 0.0513 \\ -1.1577\\ 0.8167 \\ 0.4336 \end{bmatrix} X=(x0,x1,x3,x0)= 1000000000010000000000010000001000000000 ,b= 0.0513−1.15770.81670.4336
W = [ − 0.2047 0.4789 − 0.5194 − 0.5557 1.9657 1.3934 0.0929 0.2817 0.769 1.2464 1.0071 − 1.2962 0.2749 0.2289 1.3529 0.8864 − 2.0016 − 0.3718 1.669 − 0.4385 − 0.5397 0.4769 3.2489 − 1.0212 − 0.577 0.1241 0.3026 0.5237 0.0009 1.3438 − 0.7135 − 0.8311 − 2.3702 − 1.8607 − 0.8607 0.5601 − 1.2659 0.1198 − 1.0635 0.3328 ] W = \begin{bmatrix} -0.2047 & 0.4789 & -0.5194 & -0.5557 & 1.9657 & 1.3934 & 0.0929 & 0.2817 & 0.769 & 1.2464\\ 1.0071 & -1.2962 & 0.2749 & 0.2289 & 1.3529 & 0.8864 & -2.0016 & -0.3718 & 1.669 & -0.4385\\ -0.5397 & 0.4769 & 3.2489 & -1.0212 & -0.577 & 0.1241 & 0.3026 & 0.5237 & 0.0009 & 1.3438\\ -0.7135 & -0.8311 & -2.3702 & -1.8607 & -0.8607 & 0.5601 & -1.2659 & 0.1198 & -1.0635 & 0.3328 \end{bmatrix} W= −0.20471.0071−0.5397−0.71350.4789−1.29620.4769−0.8311−0.51940.27493.2489−2.3702−0.55570.2289−1.0212−1.86071.96571.3529−0.577−0.86071.39340.88640.12410.56010.0929−2.00160.3026−1.26590.2817−0.37180.52370.11980.7691.6690.0009−1.06351.2464−0.43851.34380.3328
接下来是权重输入层的运算。我们将 W W W 与 X X X 进行矩阵乘法运算再加上置偏值 b b b,计算得到 X ′ X' X′。
X ′ = W X + b = [ − 0.1533 0.5302 − 0.5043 − 0.1533 − 0.1506 − 2.4539 − 0.9288 − 0.1506 0.277 1.2936 − 0.2044 0.277 − 0.2798 − 0.3974 − 1.427 − 0.2798 ] X' = WX + b = \begin{bmatrix} -0.1533 & 0.5302 & -0.5043 & -0.1533\\ -0.1506& -2.4539 & -0.9288& -0.1506\\ 0.277 & 1.2936 & -0.2044 & 0.277 \\ -0.2798 & -0.3974 & -1.427 & -0.2798 \end{bmatrix} X′=WX+b= −0.1533−0.15060.277−0.27980.5302−2.45391.2936−0.3974−0.5043−0.9288−0.2044−1.427−0.1533−0.15060.277−0.2798
接下来进行加权平均层的计算,也就是将 X ′ X' X′每行中的 4 4 4个值进行相加,得到 4 × 1 4 \times 1 4×1 的向量 h h h 。
h = 1 4 X ′ = 1 4 [ − 0.1533 + 0.5302 − 0.5043 − 0.1533 − 0.1506 − 2.4539 − 0.9288 − 0.1506 0.277 + 1.2936 − 0.2044 + 0.277 − 0.2798 − 0.3974 − 1.427 − 0.2798 ] = [ − 0.0701 − 0.9209 0.4108 − 0.596 ] h = \frac{1}{4} X' = \frac{1}{4} \begin{bmatrix} -0.1533 + 0.5302 - 0.5043 - 0.1533\\ -0.1506 - 2.4539 -0.9288 -0.1506 \\ 0.277 + 1.2936 - 0.2044 + 0.277\\ -0.2798 -0.3974 -1.427 -0.2798 \end{bmatrix} = \begin{bmatrix} -0.0701\\ -0.9209\\ 0.4108\\ -0.596 \end{bmatrix} h=41X′=41 −0.1533+0.5302−0.5043−0.1533−0.1506−2.4539−0.9288−0.15060.277+1.2936−0.2044+0.277−0.2798−0.3974−1.427−0.2798 = −0.0701−0.92090.4108−0.596
至此,分层Softmax层 前的准备运算工作已经完成,下面详细介绍 分层Softmax 层的计算。
首先是分层 Softmax 的预处理,我们通过对语料库使用改进的 preprocess 函数处理(参考分层 Softmax 预处理中的preprocess函数代码),我们可以得到词频信息如下表所示。
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| x i x_i xi | x 0 x_0 x0 | x 1 x_1 x1 | x 2 x_2 x2 | x 3 x_3 x3 | x 4 x_4 x4 | x 5 x_5 x5 | x 6 x_6 x6 | x 7 x_7 x7 | x 8 x_8 x8 | x 9 x_9 x9 |
| word | the | cat | plays | in | garden | , | and | chases | mouse | . |
| frequency | 5 | 2 | 1 | 2 | 2 | 1 | 1 | 1 | 1 | 1 |
preprocess 函数得到后的结果(词汇表、词频信息)
简单介绍下 Huffman 树的生成的过程,首先将所有节点放入到优先队列中,每次取出两个最小频次的两个索引,例如2、6,我们组成新的节点node1,该节点的频次(权重)为2。同理我们用7、8和5、9组合成node2(权重2)和node3(权重2)节点,此时队列中最小的频次(权重)为2。我们继续取出节点进行合并,过程依次为将1、3合并为node4(权重4),node2、4合并为node5(权重4),node1、node3合并为node6(权重4),node4、node5合并成node7(权重8),然后将node6和1合并成node8(权重9),最后将node7和node8合并为node9(权重17)得到Huffman树,如下图所示。

我们规定,对应于每一个非叶子节点,向左子树方向的编码为 0 ,向右子树方向的编码为 1 。根据路径我们可以得到每个单词的路径,如下图。根据下图我们可以的得到路径信息,如下表所示。

| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| word | the | cat | plays | in | garden | , | and | chases | mouse | . |
| path | 11 | 000 | 1011 | 001 | 011 | 1000 | 1010 | 0101 | 0100 | 1001 |
词汇表经过Huffman树处理后对应单词的索引以及的路径信息
由于一共有十个单词,生成对应的 Huffman 树时,有 9 个非叶子节点,我们按顺序将这 9 个非叶子节点标记为 θ 1 ∼ 9 \theta_{1 \sim 9} θ1∼9,并对其以及对应的置偏值 b ′ b' b′进行初始化,如下图所示。

( θ 1 , … , θ 9 ) = [ 0.0296 0.7952 0.1181 − 0.7485 0.5849 0.1526 − 1.5656 − 0.5625 − 0.0326 − 0.929 − 0.4825 − 0.0362 1.0953 0.9809 − 0.5894 1.5817 − 0.5287 0.457 0.9299 − 1.5692 − 1.0224 − 0.4028 0.2204 − 0.1934 0.6691 − 1.6489 − 2.2527 − 1.1668 0.3536 0.7021 − 0.2745 − 0.1391 0.1076 − 0.6065 − 0.417 − 0.017 ] (\theta_1, \dots, \theta_9) = \begin{bmatrix} 0.0296 & 0.7952 & 0.1181 & -0.7485 & 0.5849 & 0.1526 & -1.5656 & -0.5625 & -0.0326 \\ -0.929 & -0.4825 & -0.0362 & 1.0953 & 0.9809 & -0.5894 & 1.5817 & -0.5287 & 0.457 \\ 0.9299 & -1.5692 & -1.0224 & -0.4028 & 0.2204 & -0.1934 & 0.6691 & -1.6489 & -2.2527 \\ -1.1668 & 0.3536 & 0.7021 & -0.2745 & -0.1391 & 0.1076 & -0.6065 & -0.417 & -0.017 \end{bmatrix} (θ1,…,θ9)= 0.0296−0.9290.9299−1.16680.7952−0.4825−1.56920.35360.1181−0.0362−1.02240.7021−0.74851.0953−0.4028−0.27450.58490.98090.2204−0.13910.1526−0.5894−0.19340.1076−1.56561.58170.6691−0.6065−0.5625−0.5287−1.6489−0.417−0.03260.457−2.2527−0.017
初始化 θ i \theta_i θi 对应位置上的置偏值 b ′ = ( b 1 ′ , b 2 ′ , … , b 9 ′ ) b' = (b_1', b_2', \dots, b_9') b′=(b1′,b2′,…,b9′)
b ′ = [ − 1.2241 − 1.8008 1.6347 0.989 0.4579 0.5551 1.3067 − 0.4405 − 0.3013 ] b' = \begin{bmatrix} -1.2241 & -1.8008 & 1.6347 & 0.989 & 0.4579 & 0.5551 & 1.3067 & -0.4405 & -0.3013 \end{bmatrix} b′=[−1.2241−1.80081.63470.9890.45790.55511.3067−0.4405−0.3013]
我们计算对应路径上的 h T h^T hT 与 θ i \theta_i θi 的乘积的结果加上置偏 b i ′ b_i' bi′ 最后再取 Sigmoid 得到一个概率值 P P P,我们将其标记为正向概率,即 P i 1 = σ ( h T × θ i + b i ′ ) P_i^1 = \sigma(h^T \times \theta_i + b_i') Pi1=σ(hT×θi+bi′)。我们依据正向概率计算负向概率 P i 0 P_i^0 Pi0,即 P i 0 = 1 − P i 1 P_i^0 = 1 - P_i^1 Pi0=1−Pi1,然后我们按 Huffman 树路径对路径上的概率进行连乘可以得到每个叶子节点的概率,然后我们取最大概率的单词作为预测的单词结果。具体计算例子如下,我们从根节点开始,计算所有的 P i 1 = σ ( h T × θ i + b i ′ ) P_i^1 = \sigma (h^T \times \theta_i + b_i') Pi1=σ(hT×θi+bi′) 和 P i 1 = 1 − P i 1 P_i^1 = 1 - P_i^1 Pi1=1−Pi1
P 1 1 = σ ( h T × θ 1 + b 1 ′ ) = 0.6696 , P 1 1 = 1 − P 1 1 = 0.3304 P 2 1 = σ ( h T × θ 2 + b 2 ′ ) = 0.0938 , P 2 1 = 1 − P 2 1 = 0.9062 P 3 1 = σ ( h T × θ 3 + b 3 ′ ) = 0.6945 , P 3 1 = 1 − P 3 1 = 0.3055 P 4 1 = σ ( h T × θ 4 + b 4 ′ ) = 0.5077 , P 4 1 = 1 − P 4 1 = 0.4923 P 5 1 = σ ( h T × θ 4 + b 5 ′ ) = 0.4223 , P 5 1 = 1 − P 5 1 = 0.5777 P 6 1 = σ ( h T × θ 6 + b 6 ′ ) = 0.7198 , P 6 1 = 1 − P 6 1 = 0.2802 P 7 1 = σ ( h T × θ 7 + b 7 ′ ) = 0.6447 , P 7 1 = 1 − P 7 1 = 0.3553 P 8 1 = σ ( h T × θ 8 + b 8 ′ ) = 0.4150 , P 8 1 = 1 − P 8 1 = 0.5850 P 9 1 = σ ( h T × θ 9 + b 9 ′ ) = 0.1631 , P 9 1 = 1 − P 9 1 = 0.8369 P_1^1 = \sigma (h^T \times \theta_1 + b_1') = 0.6696, P_1^1 = 1 - P_1^1 = 0.3304\\ P_2^1 = \sigma (h^T \times \theta_2 + b_2') = 0.0938, P_2^1 = 1 - P_2^1 = 0.9062\\ P_3^1 = \sigma (h^T \times \theta_3 + b_3') = 0.6945, P_3^1 = 1 - P_3^1 = 0.3055\\ P_4^1 = \sigma (h^T \times \theta_4 + b_4') = 0.5077, P_4^1 = 1 - P_4^1 = 0.4923 \\ P_5^1 = \sigma (h^T \times \theta_4 + b_5') = 0.4223, P_5^1 = 1 - P_5^1 = 0.5777\\ P_6^1 = \sigma (h^T \times \theta_6 + b_6') = 0.7198, P_6^1 = 1 - P_6^1 = 0.2802\\ P_7^1 = \sigma (h^T \times \theta_7 + b_7') = 0.6447, P_7^1 = 1 - P_7^1 = 0.3553\\ P_8^1 = \sigma (h^T \times \theta_8 + b_8') = 0.4150, P_8^1 = 1 - P_8^1 = 0.5850\\ P_9^1 = \sigma (h^T \times \theta_9 + b_9') = 0.1631, P_9^1 = 1 - P_9^1 = 0.8369 P11=σ(hT×θ1+b1′)=0.6696,P11=1−P11=0.3304P21=σ(hT×θ2+b2′)=0.0938,P21=1−P21=0.9062P31=σ(hT×θ3+b3′)=0.6945,P31=1−P31=0.3055P41=σ(hT×θ4+b4′)=0.5077,P41=1−P41=0.4923P51=σ(hT×θ4+b5′)=0.4223,P51=1−P51=0.5777P61=σ(hT×θ6+b6′)=0.7198,P61=1−P61=0.2802P71=σ(hT×θ7+b7′)=0.6447,P71=1−P71=0.3553P81=σ(hT×θ8+b8′)=0.4150,P81=1−P81=0.5850P91=σ(hT×θ9+b9′)=0.1631,P91=1−P91=0.8369
接下来计算每个单词的概率,对路径上的 P i d P_i^d Pid进行连乘,即 P ( w o r d i ) = ∏ i = 1 l P i d P(word_i) = \prod_{i = 1}^{l} P_i^{d} P(wordi)=∏i=1lPid,具体计算过程为
P ( t h e ) = ∏ i = 1 2 P i d = P 1 1 × P 2 1 = 0.4650 P ( c a t ) = ∏ i = 1 3 P i d = P 1 0 × P 2 0 × P 3 0 = 0.1473 P ( p l a y s ) = ∏ i = 1 4 P i d = P 1 1 × P 2 0 × P 3 1 × P 4 1 = 0.02401 P ( i n ) = ∏ i = 1 3 P i d = P 1 0 × P 2 0 × P 3 1 = 0.1520 P ( g a r d e n ) = ∏ i = 1 3 P i d = P 1 0 × P 2 1 × P 3 1 = 0.0130 P ( , ) = ∏ i = 1 4 P i d = P 1 1 × P 2 0 × P 3 0 × P 4 0 = 0.0335 P ( a n d ) = ∏ i = 1 4 P i d = P 1 1 × P 2 0 × P 3 1 × P 4 0 = 0.1232 P ( c h a s e s ) = ∏ i = 1 4 P i d = P 1 0 × P 2 1 × P 3 0 × P 4 1 = 0.0115 P ( m o u s e ) = ∏ i = 1 4 P i d = P 1 0 × P 2 1 × P 3 0 × P 4 0 = 0.0063 P ( . ) = ∏ i = 1 4 P i d = P 1 1 × P 2 0 × P 3 0 × P 4 1 = 0.0237 P(the) = \prod_{i = 1}^{2} P_i^{d} = P_1^{1} \times P_2^{1} = 0.4650\\ P(cat) = \prod_{i = 1}^{3} P_i^{d} = P_1^{0} \times P_2^{0} \times P_3^{0} = 0.1473\\ P(plays) = \prod_{i = 1}^{4} P_i^{d} = P_1^{1} \times P_2^{0} \times P_3^{1} \times P_4^{1} = 0.02401\\ P(in) = \prod_{i = 1}^{3} P_i^{d} = P_1^{0} \times P_2^{0} \times P_3^{1} = 0.1520\\ P(garden) = \prod_{i = 1}^{3} P_i^{d} = P_1^{0} \times P_2^{1} \times P_3^{1} = 0.0130\\ P(,) = \prod_{i = 1}^{4} P_i^{d} = P_1^{1} \times P_2^{0} \times P_3^{0} \times P_4^{0} = 0.0335\\ P(and) = \prod_{i = 1}^{4} P_i^{d} = P_1^{1} \times P_2^{0} \times P_3^{1} \times P_4^{0} = 0.1232\\ P(chases) = \prod_{i = 1}^{4} P_i^{d} = P_1^{0} \times P_2^{1} \times P_3^{0} \times P_4^{1} = 0.0115\\ P(mouse) = \prod_{i = 1}^{4} P_i^{d} = P_1^{0} \times P_2^{1} \times P_3^{0} \times P_4^{0} = 0.0063\\ P(.) = \prod_{i = 1}^{4} P_i^{d} = P_1^{1} \times P_2^{0} \times P_3^{0} \times P_4^{1} = 0.0237\\ P(the)=i=1∏2Pid=P11×P21=0.4650P(cat)=i=1∏3Pid=P10×P20×P30=0.1473P(plays)=i=1∏4Pid=P11×P20×P31×P41=0.02401P(in)=i=1∏3Pid=P10×P20×P31=0.1520P(garden)=i=1∏3Pid=P10×P21×P31=0.0130P(,)=i=1∏4Pid=P11×P20×P30×P40=0.0335P(and)=i=1∏4Pid=P11×P20×P31×P40=0.1232P(chases)=i=1∏4Pid=P10×P21×P30×P41=0.0115P(mouse)=i=1∏4Pid=P10×P21×P30×P40=0.0063P(.)=i=1∏4Pid=P11×P20×P30×P41=0.0237
其中概率最大的值为 0.4650,代表的单词为the,所以预测的结果过单词为the。
下面按照原来模型中的例子继续详细介绍下优化后 分层Softmax 层之后的损失函数计算过程。
损失函数
在层次 Softmax 中使用的损失函数通常是二元交叉熵损失(Binary Cross-Entropy, BCE)。每个非叶节点上的决策可以被视作一个二分类问题——决定是向左还是向右,使用二元交叉熵损失可以衡量事件(向左或向右)的预测概率与实际结果之间的差异。通过计算对应路径上的 h T h^T hT 与 θ i \theta_i θi 的乘积加上置偏值 b i b_i bi 最后再取 Sigmoid 得到概率 p i p_i pi,用 p i p_i pi 与标签来计算二元交叉熵损失。
L i = − [ t i log ( p i ) + ( 1 − t i ) log ( 1 − p i ) ] \text{L}_i = -[t_i\log(p_i) + (1 - t_i)\log(1 - p_i)] Li=−[tilog(pi)+(1−ti)log(1−pi)]
其中, t i t_i ti 是实际的标签,可以理解为相应节点正确的决策路径。 T = ( t 1 , … , t n ) T = (t_1,\dots, t_n) T=(t1,…,tn) 可以表示正确单词在 Huffman 树上对应的路径。 p i p_i pi 是模型预测的概率,当 p i > 0.5 p_i > 0.5 pi>0.5 是表示向右走(编码为 1), p i < 0.5 p_i < 0.5 pi<0.5 是表示向左走(编码为0)。
每个二分类过程都可以得到一个损失 L i L_i Li,我们对其求和得到总的损失Loss。
Loss = ∑ i = 1 n L i \text{Loss} = \sum\limits^{n}_{i = 1} L_i Loss=i=1∑nLi
其中 n n n 为路径的长度,通过计算路径上每次决策的损失并累加得到最终的损失。
分层 Softmax 小结
1.H-Softmax层的输入是 h ∈ R D × 1 h \in \mathbb{R}^{D \times 1} h∈RD×1,输出是对应的预测的单词的路径
T ∈ R k × 1 T \in \mathbb{R}^{k \times 1} T∈Rk×1
和对应路径上的概率序列
P = ( p 1 , p 2 , … , p k ) P = (p_1, p_2, \dots, p_k) P=(p1,p2,…,pk)
其中 k k k 为所预测单词的路径长度。
2.预测结果单词为Huffman树路径到叶子节点之间经过的 P i d P_i^d Pid连乘结果得到的概率所概率最大的位置所对应的单词,即
P ( w o r d i ) = ∏ i = 1 l P i d P(word_i) = \prod_{i = 1}^{l} P_i^{d} P(wordi)=i=1∏lPid
值最大对应索引的单词,其中 l l l 为路径长度, d d d 只能从0或1中选,即 d ∈ { 0 , 1 } d \in \{0,1\} d∈{0,1}。损失函数使用概率序列 P P P和路径(标签)来计算交叉熵损失。
通过上面的解释,我们知道了分层Softmax以修改原来Word2Vec模型中的多分类Softmax的拓扑结构为多个二分类Huffuman树结构的形式减少了计算量,下面我们将介绍另一种形式的优化----负采样。负采样以训练技巧(trick)的方式对Softmax进行优化,它不再使用(复杂的)Huffman 树,而是利用随机取特定数量的负样例,从而减少计算量,下面正式进行介绍。
负采样
负采样(Negative Sampling)的基本思想是从一个概率分布中选择少数几个负样本来参与每次的训练,而不是使用全体负样本。在原本的Word2Vec模型中,在Softmax层中,我们会进行 V V V次 e x e^x ex运算,这个计算量在 V V V较大时,计算的时间复杂度特别高,而当我们使用少数几个样本作为负样本,例如我们令负样本数 k = 5 k = 5 k=5(通常 k k k为 5 ∼ 20 5 \sim 20 5∼20),这将把计算时间复杂度将为常数级。例如当 V = 1000000 V=1000000 V=1000000,传统的Word2Vec模型在Softmax层会进行 1000000 1000000 1000000次运算,而在优化后的负采样中只会进行 5 5 5次(假设 k = 5 k = 5 k=5),这将提升 1000000 / 2 = 500000 1000000 / 2 = 500000 1000000/2=500000倍的运算效率!
在负采样中,我们通常不使用Softmax多分类,而是使用Sigmoid函数进行二分类。我们通常将这 k k k个负例分别与正例使用 Sigmoid函数做二分类计算获得每个样例的得分并组合成得分向量,最后使用Softmax归一化得分得到样例的概率值。
通过这种方式,负采样帮助模型专注于最重要的信息,避免了在大量不相关数据上浪费计算资源。分层Softmax和负采样是可以相互替代的作为Word2Vec的一种加速计算的方式。
我们本节以 CBOW 模型为例讲述负采样 ,使用了负采样进行优化的 CBOW 模型如下图所示。与 CBOW 模型优化前进行对比,可以发现加权平均层以及其之前的层与原来的 CBOW 模型一致。主要的变化是在是在权重输出层和Softmax层,我们将其优化成 负采样层。我们将在 负采样 层中详细介绍。现在我们回顾一下 CBOW 模型加权平均层及其之前层的处理。

预处理
简单介绍模型输入前的处理。给定一个语料库 text,我们要将其处理成能够用于模型输入的 one-hot 向量。首先去重,然后将单词与标点符号按读入顺序放入集合corpus,并另外存储一份单词与索引直接查询的字典,word_to_id 和 id_to_word。
随后是将单词集合corpus也就是词汇表Vocabulary转换为 one-hot 表示
模型输入
在模型中,将一个词的上下文词表示为独热编码(one-hot encoding)向量然后并作为模型的一个输入。上下文的词的多少取决于窗口大小 C C C,于是我们的输入 X = ( x i − c , x i − c + 1 , … , x i − 1 ∈ R V × 2 C , x i + 1 , … , x i + c ) X = (x_{i-c}, x_{i-c + 1}, \dots, x_{i - 1} \in \mathbb{R}^{V \times 2C}, x_{i + 1}, \dots, x_{i + c}) X=(xi−c,xi−c+1,…,xi−1∈RV×2C,xi+1,…,xi+c), x i x_i xi为目标单词,其中 x i ∈ R V × 1 x_i \in \mathbb{R}^{V \times 1} xi∈RV×1。
权重输入层
在这一层,我们将目标单词 x i x_i xi的上下文的 one-hot 编码与隐藏层的权重输入矩阵 W W W 相乘再加上置偏值 b ∈ R D × 1 b \in \mathbb{R}^{D \times 1} b∈RD×1 得到 x j ′ x_j' xj′,即 X j ′ = W X j + b X_j' = W X_j + b Xj′=WXj+b, 其中 x j ′ ∈ R D × 1 x_j' \in \mathbb{R}^{D \times 1} xj′∈RD×1, j = ( i − C , i − C + 1 , … , i − 1 , i + 1 , … , i + C ) j = (i-C,i-C+1,\dots,i-1,i+1,\dots,i+C) j=(i−C,i−C+1,…,i−1,i+1,…,i+C)。写成矩阵的形式为
X ′ = W X + b X' = WX+b X′=WX+b
加权平均层
我们将输入层得到的所有 x j ′ x_j' xj′ 进行加权平均得到 h h h。
h = ∑ j = i − C , j ≠ i i + C x j ′ = 1 2 C ( x i − C ′ + … x i − 1 ′ + x i + 1 ′ + ⋯ + x i + C ′ ) h = \sum\limits^{i+C}_{j = i-C,j \ne i} x_j'= \frac{1}{2C}(x_{i-C}' + \dots x_{i - 1}' + x_{i + 1}' + \dots + x_{i + C}') h=j=i−C,j=i∑i+Cxj′=2C1(xi−C′+…xi−1′+xi+1′+⋯+xi+C′)
其中 C C C 是窗口大小, h ∈ R D × 1 h \in \mathbb{R}^{D \times 1} h∈RD×1。写成矩阵的形式为
h = 1 2 C X ′ j ⃗ h = \frac{1}{2C} X'\vec{j} h=2C1X′j
其中 j ⃗ = [ 1 , 1 , … , 1 , 1 ] ∈ R 2 C × 1 \vec{j}=\left[1,1,\dots,1,1\right] \in \mathbb{R}^{2C \times 1} j=[1,1,…,1,1]∈R2C×1。
接下来我们开始进入真正的负采样 模块,即 “负采样” 层。“负采样” 层 的输入是隐藏层的向量 h h h。
负采样层
Word2Vec中使用负采样,只是通过优化计算改善了词向量的质量,而并没有改变预测的方法,在预测过程中,我们通常将 Word2Vec 模型中隐藏层的向量 h h h 乘成正例的权重输出矩阵 θ 1 \theta_1 θ1,即 S 1 = θ 1 × h + b 1 ′ S_1 = \theta_1 \times h + b_1' S1=θ1×h+b1′,得到我们需要预测单词的得分向量 S 1 S_1 S1,然后使用Softmax将得分向量转换为概率,即 P = S o f t m a x ( S 1 ) P = Softmax(S_1) P=Softmax(S1)最后将最大概率位置的值设为1,其他位置设为0,得到对应的单词的one-hot表示,最后得到one-hot向量的相应的单词。
简单的负采样例子
以Word2Vec中,前面的CBOW模型为例子进行解释。
首先我们的语料库为 text = ‘The cat plays in the garden, and the cat chases the mouse in the garden.’。窗口大小 C = 2 C = 2 C=2,隐藏层的维数 D = 4 D = 4 D=4 ,并且要给定 plays 的上下文进行预测。我们可以得到模型输入是 x 0 x_0 x0 , x 1 x_1 x1 , x 3 x_3 x3 , x 0 x_0 x0,对应单词分别为 the、cat、in、the。则 X = ( x 0 , x 1 , x 3 , x 0 ) X = (x_0, x_1, x_3, x_0) X=(x0,x1,x3,x0),在下方展示。 我们对输入权重权重矩阵 W W W 进行初始化, W W W初始值与原来的CBOW模型中的一致,我们有如下的信息。
X = ( x 0 , x 1 , x 3 , x 0 ) = [ 1 0 0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ] , b = [ 0.0513 − 1.1577 0.8167 0.4336 ] X = (x_0, x_1, x_3, x_0) = \begin{bmatrix} 1&0&0&1\\ 0&1&0&0\\ 0&0&0&0\\ 0&0&1&0\\ 0&0&0&0\\ 0&0&0&0\\ 0&0&0&0\\ 0&0&0&0\\ 0&0&0&0\\ 0&0&0&0 \end{bmatrix} , b = \begin{bmatrix} 0.0513 \\ -1.1577\\ 0.8167 \\ 0.4336 \end{bmatrix} X=(x0,x1,x3,x0)= 1000000000010000000000010000001000000000 ,b= 0.0513−1.15770.81670.4336
W = [ − 0.2047 0.4789 − 0.5194 − 0.5557 1.9657 1.3934 0.0929 0.2817 0.769 1.2464 1.0071 − 1.2962 0.2749 0.2289 1.3529 0.8864 − 2.0016 − 0.3718 1.669 − 0.4385 − 0.5397 0.4769 3.2489 − 1.0212 − 0.577 0.1241 0.3026 0.5237 0.0009 1.3438 − 0.7135 − 0.8311 − 2.3702 − 1.8607 − 0.8607 0.5601 − 1.2659 0.1198 − 1.0635 0.3328 ] W = \begin{bmatrix} -0.2047 & 0.4789 & -0.5194 & -0.5557 & 1.9657 & 1.3934 & 0.0929 & 0.2817 & 0.769 & 1.2464\\ 1.0071 & -1.2962 & 0.2749 & 0.2289 & 1.3529 & 0.8864 & -2.0016 & -0.3718 & 1.669 & -0.4385\\ -0.5397 & 0.4769 & 3.2489 & -1.0212 & -0.577 & 0.1241 & 0.3026 & 0.5237 & 0.0009 & 1.3438\\ -0.7135 & -0.8311 & -2.3702 & -1.8607 & -0.8607 & 0.5601 & -1.2659 & 0.1198 & -1.0635 & 0.3328 \end{bmatrix} W= −0.20471.0071−0.5397−0.71350.4789−1.29620.4769−0.8311−0.51940.27493.2489−2.3702−0.55570.2289−1.0212−1.86071.96571.3529−0.577−0.86071.39340.88640.12410.56010.0929−2.00160.3026−1.26590.2817−0.37180.52370.11980.7691.6690.0009−1.06351.2464−0.43851.34380.3328
接下来是权重输入层的运算。我们将 W W W 与 X X X 进行矩阵乘法运算再加上置偏值 b b b,计算得到 X ′ X' X′。
X ′ = W X + b = [ − 0.1533 0.5302 − 0.5043 − 0.1533 − 0.1506 − 2.4539 − 0.9288 − 0.1506 0.277 1.2936 − 0.2044 0.277 − 0.2798 − 0.3974 − 1.427 − 0.2798 ] X' = WX + b = \begin{bmatrix} -0.1533 & 0.5302 & -0.5043 & -0.1533\\ -0.1506& -2.4539 & -0.9288& -0.1506\\ 0.277 & 1.2936 & -0.2044 & 0.277 \\ -0.2798 & -0.3974 & -1.427 & -0.2798 \end{bmatrix} X′=WX+b= −0.1533−0.15060.277−0.27980.5302−2.45391.2936−0.3974−0.5043−0.9288−0.2044−1.427−0.1533−0.15060.277−0.2798
接下来进行加权平均层的计算,也就是将 X ′ X' X′每行中的 4 4 4个值进行相加,得到 4 × 1 4 \times 1 4×1 的向量 h h h 。
h = 1 4 X ′ = 1 4 [ − 0.1533 + 0.5302 − 0.5043 − 0.1533 − 0.1506 − 2.4539 − 0.9288 − 0.1506 0.277 + 1.2936 − 0.2044 + 0.277 − 0.2798 − 0.3974 − 1.427 − 0.2798 ] = [ − 0.0701 − 0.9209 0.4108 − 0.596 ] h = \frac{1}{4} X' = \frac{1}{4} \begin{bmatrix} -0.1533 + 0.5302 - 0.5043 - 0.1533\\ -0.1506 - 2.4539 -0.9288 -0.1506 \\ 0.277 + 1.2936 - 0.2044 + 0.277\\ -0.2798 -0.3974 -1.427 -0.2798 \end{bmatrix} = \begin{bmatrix} -0.0701\\ -0.9209\\ 0.4108\\ -0.596 \end{bmatrix} h=41X′=41 −0.1533+0.5302−0.5043−0.1533−0.1506−2.4539−0.9288−0.15060.277+1.2936−0.2044+0.277−0.2798−0.3974−1.427−0.2798 = −0.0701−0.92090.4108−0.596
至此,我们正式进入负采样,并将介绍是如何计算出预测单词的。
我们初始化正例的权重 θ 1 \theta_1 θ1,然后进行运算 S c o r e = θ 1 × h Score = \theta_1 \times h Score=θ1×h。
S c o r e = θ 1 × h = [ 0.0296 0.7952 0.1181 − 0.7485 0.5849 0.1526 − 1.5656 − 0.5625 − 0.0326 − 0.929 − 0.4825 − 0.0362 1.0953 0.9809 − 0.5894 1.5817 − 0.5287 0.457 0.9299 − 1.5692 − 1.0224 − 0.4028 0.2204 − 0.1934 0.6691 − 1.6489 − 2.2527 − 1.1668 0.3536 0.7021 − 0.2745 − 0.1391 0.1076 − 0.6065 − 0.417 − 0.017 − 1.2241 − 1.8008 1.6347 0.989 ] × [ − 0.0701 − 0.9209 0.4108 − 0.596 ] = [ − 0.2397 − 0.4894 0.6811 − 2.1649 0.9334 0.6484 1.2415 − 0.7012 0.3898 1.8262 ] Score = \theta_1 \times h = \begin{bmatrix} 0.0296 & 0.7952 & 0.1181 & -0.7485 \\ 0.5849 & 0.1526 & -1.5656 & -0.5625 \\ -0.0326 & -0.929 & -0.4825 & -0.0362 \\ 1.0953 & 0.9809 & -0.5894 & 1.5817 \\ -0.5287 & 0.457 & 0.9299 & -1.5692 \\ -1.0224 & -0.4028 & 0.2204 & -0.1934 \\ 0.6691 & -1.6489 & -2.2527 & -1.1668 \\ 0.3536 & 0.7021 & -0.2745 & -0.1391 \\ 0.1076 & -0.6065 & -0.417 & -0.017 \\ -1.2241 & -1.8008 & 1.6347 & 0.989 \end{bmatrix} \times \begin{bmatrix} -0.0701\\ -0.9209\\ 0.4108\\ -0.596 \end{bmatrix}= \begin{bmatrix} -0.2397 \\ -0.4894 \\ 0.6811 \\ -2.1649 \\ 0.9334 \\ 0.6484 \\ 1.2415 \\ -0.7012 \\ 0.3898 \\ 1.8262 \end{bmatrix} Score=θ1×h= 0.02960.5849−0.03261.0953−0.5287−1.02240.66910.35360.1076−1.22410.79520.1526−0.9290.98090.457−0.4028−1.64890.7021−0.6065−1.80080.1181−1.5656−0.4825−0.58940.92990.2204−2.2527−0.2745−0.4171.6347−0.7485−0.5625−0.03621.5817−1.5692−0.1934−1.1668−0.1391−0.0170.989 × −0.0701−0.92090.4108−0.596 = −0.2397−0.48940.6811−2.16490.93340.64841.2415−0.70120.38981.8262
得分最高的值为 1.8262 1.8262 1.8262,也就是索引为 9 9 9 的单词 ‘.’。
以上就是使用了负采样的CBOW模型的预测过程的计算,预测的过程比较简单,而训练,即损失函数的计算过程会复杂一些,我们接着上面CBOW模型的例子介绍损失函数的计算过程。
损失函数
使用了负采样的Word2Vec模型的损失函数的计算包括两个部分,一是正例损失的计算,二是负例损失的计算。在使用负采样的Word2Vec模型中,预测单词时,只用到了正例的权重输出矩阵 θ 1 \theta_1 θ1,但在计算损失时,我们需要同时考虑正例和负例的的损失。
正例损失的计算:在预测过程中,我们计算了单词的得分向量,也就是 S 1 = θ 1 h + b 1 ′ S_1 = \theta_1h + b_1' S1=θ1h+b1′。我们使用交叉熵损失计算损失,即
L o s s = − [ t 1 × l o g ( P 1 ) + t 2 × l o g ( P 2 ) + ⋯ + t V − 1 × l o g ( P V − 1 ) + t V × l o g ( P V ) ] \begin{split} Loss & = -\left[t_1 \times log(P_1) + t_2 \times log(P_2) + \dots + t_{V-1} \times log(P_{V-1}) + t_V \times log(P_V) \right] \end{split} Loss=−[t1×log(P1)+t2×log(P2)+⋯+tV−1×log(PV−1)+tV×log(PV)]
其中 T 1 T_1 T1是正确的标签,即 T 1 = ( t 1 , t 2 , … , t V ) T T_1 = (t_1, t_2, \dots, t_V)^T T1=(t1,t2,…,tV)T, P P P是每个单词对应的概率,即 P = ( P 1 , P 2 , … , P V ) P = (P_1,P_2, \dots, P_V) P=(P1,P2,…,PV),此处我们进行优化。在 T T T中,由于只有正确索引位置为为 1 1 1,在进行交叉熵损失运算时,只会保留正确索引位置单词的得分概率,于是我们将得分向量中正确的得分直接取出,记为 S 1 = ( θ 1 h ) T T 1 S_1 = (\theta_1h)^TT_1 S1=(θ1h)TT1。
随后我们将得分转换为概率,由于此处均为二分类问题(即预测单词是否为目标单词),我们使用 S i g m o i d Sigmoid Sigmoid函数将得分转换正例的概率 P 1 ∈ R P_1 \in R P1∈R,最后应用于交叉熵损失函数,即
P 1 = σ ( S 1 ) = σ ( ( θ 1 h + b 1 ′ ) T T 1 ) = 1 1 + e − ( ( θ 1 h + b 1 ′ ) T T 1 ) P_1 = \sigma(S_1) = \sigma((\theta_1h + b_1')^TT_1) = \frac{1}{1 + e^{-((\theta_1h + b_1')^TT_1)}} P1=σ(S1)=σ((θ1h+b1′)TT1)=1+e−((θ1h+b1′)TT1)1
L o s s + = − l o g ( P 1 ) = − l o g ( 1 1 + e − ( ( θ 1 h + b 1 ′ ) T T 1 ) ) Loss_+ = - log(P_1) = -log(\frac{1}{1 + e^{-((\theta_1h+ b_1')^TT_1)}}) Loss+=−log(P1)=−log(1+e−((θ1h+b1′)TT1)1)
负例的计算:负例的计算与正例类似,不过我们先需要进行采样,下面先介绍如何对负例进行采样。
从预料库中选取负例的集合,要求词频高的词容易被随机到,而词频低的词不容易被随机到。Word2Vec负采样方法如下:
- 我们根据词汇表中的单词,按照词频给出每个单词的概率分布,公式如下为
f ( w ) = [ c o u n t ( w ) ] 3 4 ∑ i = 1 V [ c o u n t ( i ) ] 3 4 f(w) = \frac{[count(w)]^{\frac{3}{4}}}{\sum_{i = 1}^{V} [count(i)]^{\frac{3}{4}}} f(w)=∑i=1V[count(i)]43[count(w)]43 其中函数 c o u n t ( i n d e x ) count(index) count(index)计算索引位置为 i n d e x index index位置单词的词频, w w w表示目标单词的索引, V V V为词汇表的大小。 l e n len len函数分母计算了所有单词的一个权重和, f ( w ) f(w) f(w)函数求得索引位置为 w w w位置的单词按照词频在词汇表中概率分布。 - 我们根据概率分布进行抽样,若抽到正例则重新抽样,于是我们得到了若干负例。
在Word2Vec原文中,数据量较大时,我们通常使用的负例个数 k k k 通常为5,当数据量较小时,则通常为 5 ∼ 20 5 \sim 20 5∼20个。
通过采样后,我们得到了负样本,下面介绍负例的计算。对于采样出的负例,我们计算对应的得分之后将其取负号再使用 S i g m o i d Sigmoid Sigmoid 函数,然后使用原来计算正例的方式进行计算。考虑负例的权重输出函数 ,我们将负例的权重矩阵 θ 0 \theta_0 θ0与隐藏层向量 h h h相乘得到单词的得分向量,取出分别出采样单词对应的得分,即 S 0 , i = ( θ 0 h + b 0 ′ ) T T 0 , i S_{0,i} = (\theta_0h + b_0')^TT_{0,i} S0,i=(θ0h+b0′)TT0,i,其中 T 0 , i T_{0,i} T0,i是取出的负样例中,对应负样例的标签(one-hot向量), i i i是负样例标签的索引,即负采样采样出负样例中的第几个,且 i ∈ 1 , 2 , … , k i \in {1,2,\dots, k} i∈1,2,…,k, k k k为负样例个数。随后对 S 0 , i S_{0,i} S0,i 取负号后使用 S i g m o i d Sigmoid Sigmoid 函数得到负样例概率 P 0 , i P_{0,i} P0,i,即 P 0 , i = σ ( − S 0 , i ) P_{0,i} = \sigma(-S_{0,i}) P0,i=σ(−S0,i),然后将所有的概率取使用交叉熵损失计算方法得到负样例的损失。
P 0 , i = σ ( S 0 , i ) = σ ( ( θ 0 h + b 0 ′ ) T T 0 , i ) = 1 1 + e − ( ( θ 0 h + b 0 ′ ) T T 0 , i ) P_{0,i} = \sigma(S_{0,i}) = \sigma((\theta_0h + b_0')^TT_{0,i}) = \frac{1}{1 + e^{-((\theta_0h + b_0')^TT_{0,i})}} P0,i=σ(S0,i)=σ((θ0h+b0′)TT0,i)=1+e−((θ0h+b0′)TT0,i)1
Loss − = − ∑ i = 1 k Loss − , i = − ∑ i = 1 k log ( P 0 , i ) = − ∑ i = 1 k log ( 1 1 + e − ( ( θ 0 h + b 0 ′ ) T T 0 , i ) ) \text{Loss}_-= -\sum_{i = 1}^{k} \text{Loss}_{-,i} = -\sum_{i = 1}^{k} \log(P_{0,i}) = -\sum_{i = 1}^{k}\log(\frac{1}{1 + e^{-((\theta_0h + b_0')^TT_{0,i})}}) Loss−=−i=1∑kLoss−,i=−i=1∑klog(P0,i)=−i=1∑klog(1+e−((θ0h+b0′)TT0,i)1)
最后我们将正例损失与负例损失相加得到总的损失。
Loss = Loss + + Loss − \text{Loss} = \text{Loss}_+ + \text{Loss}_{-} Loss=Loss++Loss−
负采样小结
1.负采样层的输入是隐藏层的向量 h ∈ R D × 1 h \in \mathbb{R}^{D \times 1} h∈RD×1(隐藏层通常有Word2Vec模型的输入进行词嵌入获得), D D D为隐藏层层数,输出是对应的预测的单词。负采样层通过正例的权重输出矩阵 θ 1 ∈ V × D \theta_1 \in V \times D θ1∈V×D 与隐藏层向量 h h h进行相乘直接得到了单词的得分向量, V V V 为词汇表大小,取得分向量中最大得分位置索引的单词作为预测结果单词。
2.负采样损失函数的计算包括两个部分,正例损失的计算和负例损失的计算。对于正例损失,我们将正例权重输出矩阵 θ 1 \theta_1 θ1与隐藏层的向量 h h h相乘得到单词得分向量,随后取出正例对于索引位置单词的得分,即
S 1 = ( θ 1 h + b 1 ′ ) T T 1 S_1 = (\theta_1h + b_1')^TT_1 S1=(θ1h+b1′)TT1
其中 T 1 T_1 T1为正例对应的标签。然后我们使用 S i g m o i d Sigmoid Sigmoid函数将得分转换为概率,即
P 1 = σ ( S 1 ) P_1= \sigma(S_1) P1=σ(S1)
然后我们使用交叉熵计算损失,即
Loss + = − log ( P 1 ) \text{Loss}_+ = -\log(P_1) Loss+=−log(P1)
对于负例损失的计算,我们首先通过词频加权处理得到每个单词的概率分布,依据概率分布进行抽样,抽取出 k k k个负例,随后我们进行负例计算。我们将负例权重输出矩阵 θ 0 \theta_0 θ0与隐藏层的向量 h h h相乘得到单词得分向量,随后依次取出每个负例对于索引位置单词的得分然后取负号,即
S 0 , i = − ( θ 0 h + b 0 ′ ) T T 0 , i S_{0,i} = -(\theta_0h + b_0')^TT_{0,i} S0,i=−(θ0h+b0′)TT0,i
其中 T 0 , i T_{0,i} T0,i为负例对应的标签。然后我们使用 S i g m o i d Sigmoid Sigmoid函数将得分转换为概率,即
P 1 = σ ( S 0 , i ) P_1= \sigma(S_{0,i}) P1=σ(S0,i)
然后我们使用交叉熵计算损失,即
Loss − = − ∑ i = 1 k log ( P 0 , i ) \text{Loss}_- = -\sum_{i = 1}^{k}\log(P_{0,i}) Loss−=−i=1∑klog(P0,i)
最后我们将 L o s s + Loss_+ Loss+ 与 L o s s − Loss_- Loss−相加得到总的损失Loss,即
Loss = Loss + + Loss − \text{Loss} = \text{Loss}_+ + \text{Loss}_- Loss=Loss++Loss−
到此,负采样算法的损失函数已经介绍完毕!
以上我们介绍了Word2Vec以及两种优化方法,Word2Vec的内容到此结束。
附录
分层Softmax预处理程序代码
def preprocess(text):text = text.lower()text = text.replace('.', ' .')text = text.replace(',', ' ,')text = text.replace('!', ' !')words = text.split(' ')word_to_id = {}id_to_word = {}word_count = {}for word in words:if word not in word_to_id:new_id = len(word_to_id)word_to_id[word] = new_idid_to_word[new_id] = wordword_count[new_id] = 1else:word_count[word_to_id[word]] += 1corpus = np.array([word_to_id[w] for w in words])return corpus, word_to_id, id_to_word, word_count
构建Huffman数程序代码
import heapq class HuffmanNode:def __init__(self, char, freq):self.char = charself.freq = freqself.left = Noneself.right = None# 使节点成为可比较的,基于频率def __lt__(self, other):return self.freq < other.freqdef build_huffman_tree(frequencies):# 初始化优先队列priority_queue = [HuffmanNode(char, freq) for char, freq in enumerate(frequencies)]heapq.heapify(priority_queue)# 当只剩下一个节点时停止while len(priority_queue) > 1:# 取出两个最小的节点left = heapq.heappop(priority_queue)right = heapq.heappop(priority_queue)# 创建新的内部节点merged = HuffmanNode(None, left.freq + right.freq)merged.left = leftmerged.right = right# 将新节点添加回优先队列heapq.heappush(priority_queue, merged)# 返回根节点return priority_queue[0]def get_huffman_codes(node, current_code="", codes={}):# 如果是叶子节点,记录路径if node.char is not None:codes[node.char] = current_codereturn codes# 向左递归if node.left:get_huffman_codes(node.left, current_code + "0", codes)# 向右递归if node.right:get_huffman_codes(node.right, current_code + "1", codes)return codes# 示例
frequencies = [5, 2, 1, 2, 2, 1, 1, 1, 1, 1] # 词频数组
root = build_huffman_tree(frequencies)
codes = get_huffman_codes(root)print(codes)
# {1: '000', 3: '001', 8: '0100', 7: '0101', 4: '011', 5: '1000', 9: '1001', 6: '1010', 2: '1011', 0: '11'}
相关文章:
【万字长文】Word2Vec计算详解(三)分层Softmax与负采样
【万字长文】Word2Vec计算详解(三)分层Softmax与负采样 写在前面 第三部分介绍Word2Vec模型的两种优化方案。 【万字长文】Word2Vec计算详解(一)CBOW模型 markdown行 9000 【万字长文】Word2Vec计算详解(二࿰…...

【分布式微服务云原生】探索Dubbo:接口定义语言的多样性与选择
目录 探索Dubbo:接口定义语言的多样性与选择引言Dubbo的接口定义语言(IDL)1. Java接口2. XML配置3. 注解4. Protobuf IDL 流程图:Dubbo服务定义流程表格:Dubbo IDL方式比较结论呼吁行动Excel表格:Dubbo IDL…...

SAP将假脱机(Spool requests)内容转换为PDF文档[RSTXPDFT4]
将假脱机(Spool requests)内容转换为PDF文档[RSTXPDFT4] 有时需要将Spool中的内容导出成PDF文件,sap提供了一个标准程序RSTXPDFT4可以实现此功能。 1, Tcode:SP01, 进入spool requests list 2, SE38 运行程序RSTXPDFT4 输入spool reqeust号码18680,然后…...

DNS能加速游戏吗?
在游戏玩家追求极致游戏体验的今天,任何可能提升游戏性能的因素都备受关注,DNS(域名系统)便是其中一个被探讨的对象。那么,DNS能加速游戏吗? 首先,我们需要了解DNS的基本功能。DNS就像是互联网…...

Raspberry Pi3B+之C/C++开发环境搭建
Raspberry Pi3B之C/C开发环境搭建 1. 源由2. 环境搭建2.1 搭建C语言开发环境2.2 工程目录结构2.3 Makefile2.4 Demo (main.c) 3. 测试工程3.1 编译3.2 运行 4. 总结5. 参考资料 1. 源由 为了配合《Ardupilot开源飞控之FollowMe验证平台搭建》,以及VINS-Fusion对于图…...

[笔记] 仿射变换性质的代数证明
Title: [笔记] 仿射变换性质的代数证明 文章目录 I. 仿射变换的代数表示II. 仿射变换的性质III. 同素性的代数证明1. 点变换为点2. 直线变换为直线 IV. 结合性的代数证明1. 直线上一点映射为直线上一点2. 直线外一点映射为直线外一点 V. 保持单比的代数证明VI. 平行性的代数证明…...

遥感影像-语义分割数据集:sar水体数据集详细介绍及训练样本处理流程
原始数据集详情 简介:该数据集由WHU-OPT-SAR数据集整理而来,覆盖面积51448.56公里,分辨率为5米。据我们所知,WHU-OPT-SAR是第一个也是最大的土地利用分类数据集,它融合了高分辨率光学和SAR图像,并进行了充…...

极狐GitLab 发布安全补丁版本 17.4.1、17.3.4、17.2.8
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

汽车管理系统中使用函数
目录 setupUisetEnabledcurrentText()setTextsetFocus()query.exec(...)addWidgetconnect setupUi setupUi() 是 ui 对象的一个成员函数,它的作用是根据 .ui 文件中的设计,将设计好的组件(如按钮、文本框、布局等)添加到当前的窗…...

大数据分析入门概述
大数据分析入门概述 本文旨在为有意向学习数据分析、数据开发等大数据方向的初学者提供一个学习指南,当然如果你希望通过视频课程的方式快速入门,B站UP主戴戴戴师兄的课程质量很高,并且适合初学者快速入门。本文的目的旨在为想要了解大数据但…...
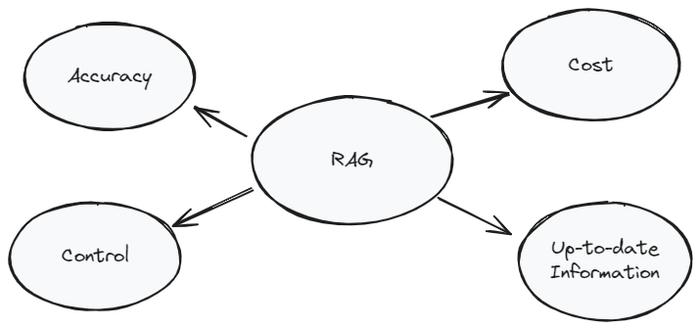
提示工程、微调和 RAG
自众多大型语言模型(LLM)和高级对话模型发布以来,人们已经运用了各种技术来从这些 AI 系统中提取所需的输出。其中一些方法会改变模型的行为来更好地贴近我们的期望,而另一些方法则侧重于增强我们查询 LLM 的方式,以提…...

自动化测试中如何高效进行元素定位!
前言 在自动化测试中,元素定位是一项非常重要的工作。良好的元素定位可以帮助测试人员处理大量的测试用例,加快测试进度,降低工作负担。但是在实际的测试工作中,我们常常遇到各种各样的定位问题,比如元素定位失败、元…...

UE5数字人制作平台使用及3D模型生成
第10章 数字人制作平台使用及3D模型生成 在数字娱乐、虚拟现实(VR)、增强现实(AR)等领域,高质量的3D模型是数字内容创作的核心。本章将引导你了解如何使用UE5(Unreal Engine 5)虚幻引擎这一强大…...

Linux进程被占用如何杀死进程
文章目录 前言一、根据名称进行查找程序所占用的端口号二、杀死进程总结 前言 由于Linux中,校园网登录的时候容易出现端口被占用,如何快速查找程序所占用的端口号。 提示:以下是本篇文章正文内容,下面案例可供参考 一、根据名称…...

详解Xilinx JESD204B PHY层端口信号含义及动态切换线速率(JESD204B五)
点击进入高速收发器系列文章导航界面 Xilinx官方提供了两个用于开发JESD204B的IP,其中一个完成PHY层设计,另一个完成传输层的逻辑,两个IP必须一起使用才能正常工作。 7系列FPGA只能使用最多12通道的JESD204B协议,线速率为1.0至12.…...

Java面试——场景题
1.如何分批处理数据? 1.使用LIMIT和OFFSET子句: 这是最常用的分批查询方法。例如,你可以使用以下SQL语句来分批查询数据: SELECT * FROM your_table LIMIT 1000 OFFSET 0; 分批查询到的数据在后端进行处理,达到分批…...

xss-labs靶场第一关测试报告
目录 一、测试环境 1、系统环境 2、使用工具/软件 二、测试目的 三、操作过程 1、注入点寻找 2、使用hackbar进行payload测试 3、绕过结果 四、源代码分析 五、结论 一、测试环境 1、系统环境 渗透机:本机(127.0.0.1) 靶 机:本机(127.0.0.…...
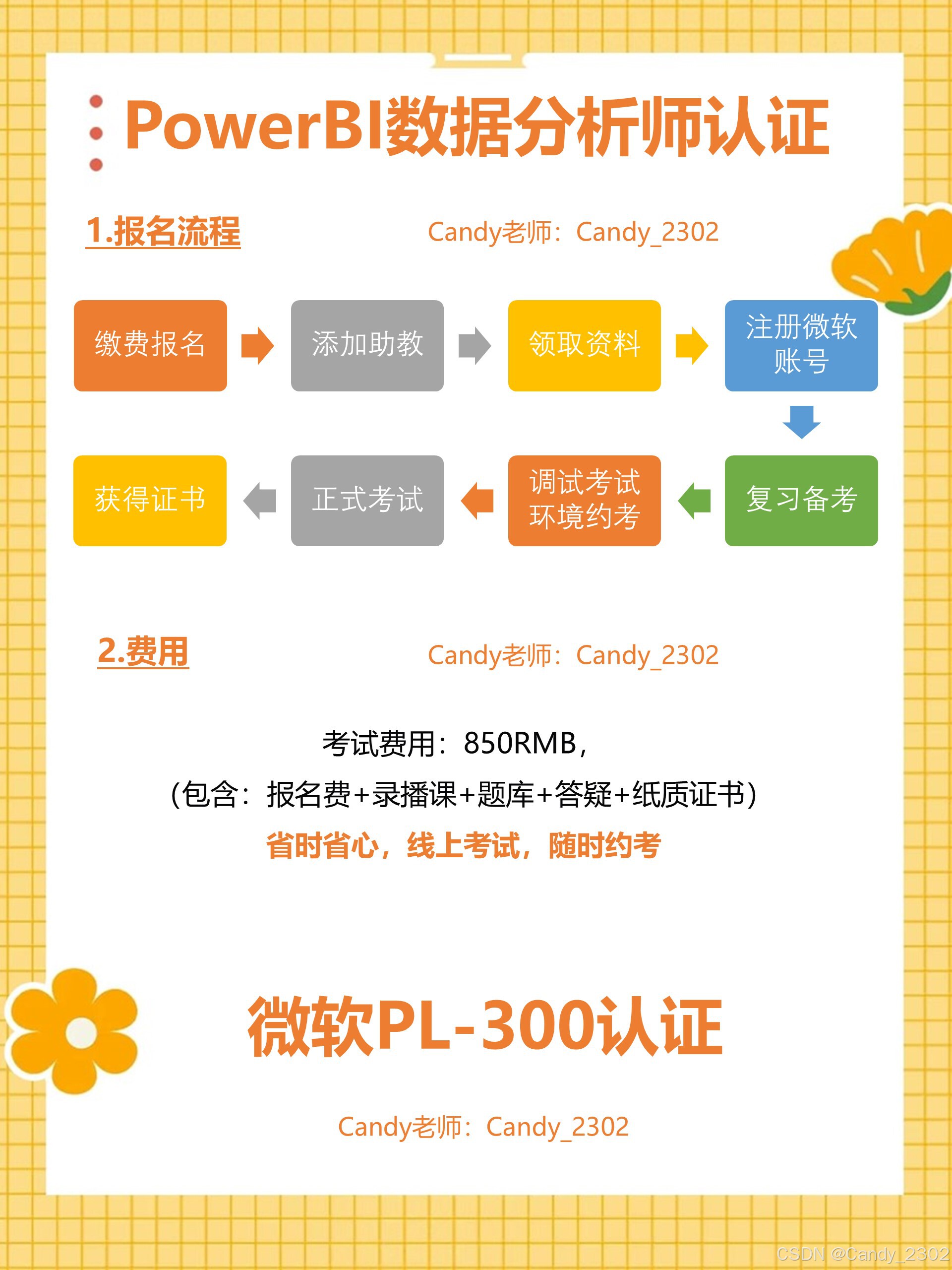
微软PowerBI认证!数据分析师入门级证书备考攻略来啦
#微软PowerBI认证!数据分析师入门级证书! 😃Power BI是一种强大的数据可视化和分析工具,学习Power BI,能提高数据的分析能力,将数据转化为有意义的见解,并支持数据驱动的决策制定。 ㅤ ✨微软P…...

上海AI Lab视频生成大模型书生.筑梦环境搭建推理测试
引子 最近视频生成大模型层出不穷,上海AI Lab推出新一代视频生成大模型 “书生・筑梦 2.0”(Vchitect 2.0)。根据官方介绍,书生・筑梦 2.0 是集文生视频、图生视频、插帧超分、训练系统一体化的视频生成大模型。OK,那就让我们开始吧。 一、模…...

3D看车如何实现?有哪些功能特点和优势?
3D看车是一种创新的汽车展示方式,它利用三维建模和虚拟现实技术,将汽车以更真实、更立体的形式呈现在消费者面前。 一、3D看车的实现方式 1、三维建模: 通过三维建模技术,按照1:1的比例还原汽车外观,包括车身线条、细…...

STM32H743+CubeMX配置FDCAN实战:如何利用TxFIFO优化FreeRTOS下的CAN通信性能?
STM32H743CubeMX配置FDCAN实战:如何利用TxFIFO优化FreeRTOS下的CAN通信性能? 在嵌入式系统开发中,CAN总线因其高可靠性和实时性被广泛应用于工业控制、汽车电子等领域。当我们将目光投向STM32H743这类高性能微控制器时,其内置的FD…...
)
面试官最爱问的哈希表实战:用C++手撕‘存在重复元素II’(附滑动窗口优化思路)
哈希表实战:从暴力解法到最优解法的完整思维路径 在技术面试中,哈希表相关题目几乎是必考内容,而"存在重复元素II"这类问题更是高频出现。这道看似简单的题目背后,隐藏着对候选人算法思维、编码能力和沟通表达的全面考察…...

Qwen3.5-2B部署案例:基于Docker+Supervisor的生产级多用户服务搭建
Qwen3.5-2B部署案例:基于DockerSupervisor的生产级多用户服务搭建 1. 项目背景与模型介绍 Qwen3.5-2B是阿里云推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这个模型专为低功耗、低门槛部署场景设计&…...

PhotoMaker性能基准测试终极指南:建立你的AI人像生成速度参考标准
PhotoMaker性能基准测试终极指南:建立你的AI人像生成速度参考标准 【免费下载链接】PhotoMaker 项目地址: https://ai.gitcode.com/hf_mirrors/TencentARC/PhotoMaker 想要了解PhotoMaker的实际性能表现吗?作为一款革命性的AI人像生成工具&#…...

CMake 导言
为什么选择 CMake 在掌握 Linux 基础后,我们知道一个项目通常由多个源文件组成。想要构建这个项目,就需要按照一定的规则对源文件进行编译和链接,而这些规则通常需要在 Makefile 中定义。 但随着项目体量增大,手写 Makefile 会变得…...

大疆诉影石创新专利侵权,FTO综合分析筑牢研发风控屏障
3月23日,全球无人机巨头大疆对同行影石创新提起专利权属纠纷诉讼,涉案6项专利聚焦无人机飞行控制、结构设计、影像处理等核心技术领域,这场行业龙头间的知识产权纠纷,成为近日行业关注焦点。职务发明权属成为争议关键本次纠纷由大…...

抖音批量下载终极指南:免费无水印,一键搞定视频、音乐、合集
抖音批量下载终极指南:免费无水印,一键搞定视频、音乐、合集 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and brows…...

社媒爆款流水线:手把手教你用Runway Gen-4.5的A/B测试功能,批量生产TikTok热门视频
社媒爆款流水线:用Runway Gen-4.5打造数据驱动的短视频生产引擎 在短视频内容爆炸式增长的今天,一个残酷的现实是:99%的内容在发布后的24小时内就会沉入算法深渊。那些能突破重围的爆款视频,往往不是偶然灵感的产物,而…...

火影AI绘画实战:用忍者绘卷Z-Image Turbo生成鸣人、佐助角色图教程
火影AI绘画实战:用忍者绘卷Z-Image Turbo生成鸣人、佐助角色图教程 1. 教程概述与准备工作 如果你是火影忍者的粉丝,现在可以通过AI技术轻松生成你最喜欢的角色图像。本教程将带你使用"忍者绘卷Z-Image Turbo"这个专门为火影风格优化的AI绘画…...

UI-TARS-desktop环境部署:Ubuntu+Docker下免配置运行Qwen3-4B多模态Agent
UI-TARS-desktop环境部署:UbuntuDocker下免配置运行Qwen3-4B多模态Agent 想体验一个能看懂屏幕、操作软件、帮你处理日常任务的多模态AI助手吗?今天,我们就来手把手教你,如何在Ubuntu系统上,通过Docker一键部署UI-TAR…...