什么是词嵌入(Word Embedding)
1. 什么是词嵌入(Word Embedding)
⾃然语⾔是⼀套⽤来表达含义的复杂系统。在这套系统中,词是表义的基本单元。顾名思义,词向量是⽤来表⽰词的向量,也可被认为是词的特征向量或表征。把词映射为实数域向量的技术也叫词嵌⼊(word embedding)。近年来,词嵌⼊已逐渐成为⾃然语⾔处理的基础知识。
在NLP(自然语言处理)领域,文本表示是第一步,也是很重要的一步,通俗来说就是把人类的语言符号转化为机器能够进行计算的数字,因为普通的文本语言机器是看不懂的,必须通过转化来表征对应文本。早期是基于规则的方法进行转化,而现代的方法是基于统计机器学习的方法。
数据决定了机器学习的上限,而算法只是尽可能逼近这个上限,在本文中数据指的就是文本表示,所以,弄懂文本表示的发展历程,对于NLP学习者来说是必不可少的。接下来开始我们的发展历程。文本表示分为离散表示和分布式表示:
2.离散表示
2.1 One-hot表示
One-hot简称读热向量编码,也是特征工程中最常用的方法。其步骤如下:
-
构造文本分词后的字典,每个分词是一个比特值,比特值为0或者1。 -
每个分词的文本表示为该分词的比特位为1,其余位为0的矩阵表示。
例如:John likes to watch movies. Mary likes too
John also likes to watch football games.
以上两句可以构造一个词典,**{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9, "too": 10} **
每个词典索引对应着比特位。那么利用One-hot表示为:
**John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] **
likes: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0] .......等等,以此类推。
One-hot表示文本信息的缺点:
-
随着语料库的增加,数据特征的维度会越来越大,产生一个维度很高,又很稀疏的矩阵。 -
这种表示方法的分词顺序和在句子中的顺序是无关的,不能保留词与词之间的关系信息。
2.2 词袋模型
词袋模型(Bag-of-words model),像是句子或是文件这样的文字可以用一个袋子装着这些词的方式表现,这种表现方式不考虑文法以及词的顺序。
文档的向量表示可以直接将各词的词向量表示加和。例如:
John likes to watch movies. Mary likes too
John also likes to watch football games.
以上两句可以构造一个词典,**{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9, "too": 10} **
那么第一句的向量表示为:**[1,2,1,1,1,0,0,0,1,1],其中的2表示likes**在该句中出现了2次,依次类推。
词袋模型同样有一下缺点:
-
词向量化后,词与词之间是有大小关系的,不一定词出现的越多,权重越大。 -
词与词之间是没有顺序关系的。
2.3 TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆文本频率指数(Inverse Document Frequency)。
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。

分母之所以加1,是为了避免分母为0。
那么,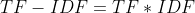 ,从这个公式可以看出,当w在文档中出现的次数增大时,而TF-IDF的值是减小的,所以也就体现了以上所说的了。
,从这个公式可以看出,当w在文档中出现的次数增大时,而TF-IDF的值是减小的,所以也就体现了以上所说的了。
缺点:还是没有把词与词之间的关系顺序表达出来。
2.4 n-gram模型
n-gram模型为了保持词的顺序,做了一个滑窗的操作,这里的n表示的就是滑窗的大小,例如2-gram模型,也就是把2个词当做一组来处理,然后向后移动一个词的长度,再次组成另一组词,把这些生成一个字典,按照词袋模型的方式进行编码得到结果。改模型考虑了词的顺序。
例如:
John likes to watch movies. Mary likes too
John also likes to watch football games.
以上两句可以构造一个词典,**{"John likes”: 1, "likes to”: 2, "to watch”: 3, "watch movies”: 4, "Mary likes”: 5, "likes too”: 6, "John also”: 7, "also likes”: 8, “watch football”: 9, "football games": 10}**
那么第一句的向量表示为:**[1, 1, 1, 1, 1, 1, 0, 0, 0, 0],其中第一个1表示John likes**在该句中出现了1次,依次类推。
缺点:随着n的大小增加,词表会成指数型膨胀,会越来越大。
2.5 离散表示存在的问题
由于存在以下的问题,对于一般的NLP问题,是可以使用离散表示文本信息来解决问题的,但对于要求精度较高的场景就不适合了。
-
无法衡量词向量之间的关系。 -
词表的维度随着语料库的增长而膨胀。 -
n-gram词序列随语料库增长呈指数型膨胀,更加快。 -
离散数据来表示文本会带来数据稀疏问题,导致丢失了信息,与我们生活中理解的信息是不一样的。
3. 分布式表示
科学家们为了提高模型的精度,又发明出了分布式的表示文本信息的方法,这就是这一节需要介绍的。
用一个词附近的其它词来表示该词,这是现代统计自然语言处理中最有创见的想法之一。当初科学家发明这种方法是基于人的语言表达,认为一个词是由这个词的周边词汇一起来构成精确的语义信息。就好比,物以类聚人以群分,如果你想了解一个人,可以通过他周围的人进行了解,因为周围人都有一些共同点才能聚集起来。
3.1 共现矩阵
共现矩阵顾名思义就是共同出现的意思,词文档的共现矩阵主要用于发现主题(topic),用于主题模型,如LSA。
局域窗中的word-word共现矩阵可以挖掘语法和语义信息,例如:
-
I like deep learning. -
I like NLP. -
I enjoy flying
有以上三句话,设置滑窗为2,可以得到一个词典:**{"I like","like deep","deep learning","like NLP","I enjoy","enjoy flying","I like"}**。
我们可以得到一个共现矩阵(对称矩阵):
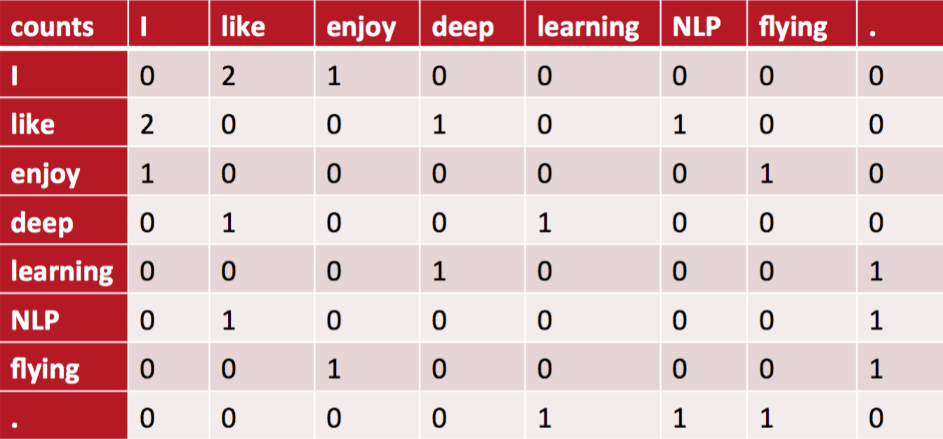
中间的每个格子表示的是行和列组成的词组在词典中共同出现的次数,也就体现了共现的特性。
存在的问题:
-
向量维数随着词典大小线性增长。 -
存储整个词典的空间消耗非常大。 -
一些模型如文本分类模型会面临稀疏性问题。 -
模型会欠稳定,每新增一份语料进来,稳定性就会变化。
4.神经网络表示
4.1 NNLM
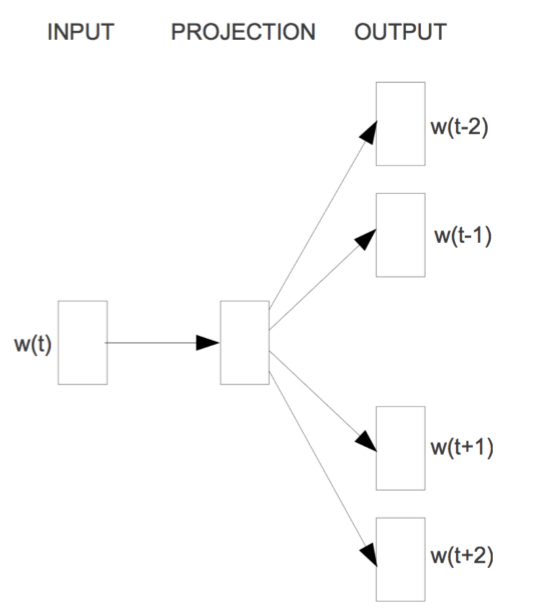
NNLM (Neural Network Language model),神经网络语言模型是03年提出来的,通过训练得到中间产物--词向量矩阵,这就是我们要得到的文本表示向量矩阵。
NNLM说的是定义一个前向窗口大小,其实和上面提到的窗口是一个意思。把这个窗口中最后一个词当做y,把之前的词当做输入x,通俗来说就是预测这个窗口中最后一个词出现概率的模型。

以下是NNLM的网络结构图:
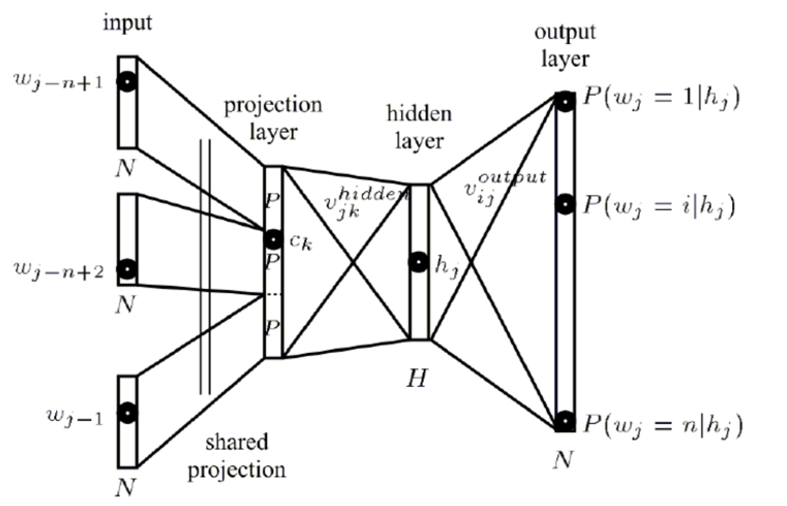
-
input层是一个前向词的输入,是经过one-hot编码的词向量表示形式,具有V*1的矩阵。
-
C矩阵是投影矩阵,也就是稠密词向量表示,在神经网络中是w参数矩阵,该矩阵的大小为D*V,正好与input层进行全连接(相乘)得到D*1的矩阵,采用线性映射将one-hot表示投影到稠密D维表示。

image -
output层(softmax)自然是前向窗中需要预测的词。
-
通过BP+SGD得到最优的C投影矩阵,这就是NNLM的中间产物,也是我们所求的文本表示矩阵,通过NNLM将稀疏矩阵投影到稠密向量矩阵中。
4.2 Word2Vec
谷歌2013年提出的Word2Vec是目前最常用的词嵌入模型之一。Word2Vec实际是一种浅层的神经网络模型,它有两种网络结构,分别是CBOW(Continues Bag of Words)连续词袋和Skip-gram。Word2Vec和上面的NNLM很类似,但比NNLM简单。
CBOW
CBOW获得中间词两边的的上下文,然后用周围的词去预测中间的词,把中间词当做y,把窗口中的其它词当做x输入,x输入是经过one-hot编码过的,然后通过一个隐层进行求和操作,最后通过激活函数softmax,可以计算出每个单词的生成概率,接下来的任务就是训练神经网络的权重,使得语料库中所有单词的整体生成概率最大化,而求得的权重矩阵就是文本表示词向量的结果。

Skip-gram:
Skip-gram是通过当前词来预测窗口中上下文词出现的概率模型,把当前词当做x,把窗口中其它词当做y,依然是通过一个隐层接一个Softmax激活函数来预测其它词的概率。如下图所示:
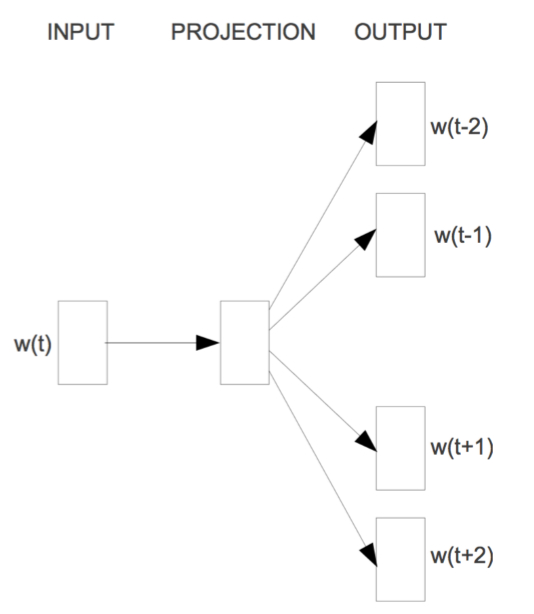
优化方法:
-
层次Softmax:至此还没有结束,因为如果单单只是接一个softmax激活函数,计算量还是很大的,有多少词就会有多少维的权重矩阵,所以这里就提出 层次Softmax(Hierarchical Softmax),使用Huffman Tree来编码输出层的词典,相当于平铺到各个叶子节点上,瞬间把维度降低到了树的深度,可以看如下图所示。这课Tree把出现频率高的词放到靠近根节点的叶子节点处,每一次只要做二分类计算,计算路径上所有非叶子节点词向量的贡献即可。
**哈夫曼树(Huffman Tree)**:给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
-
负例采样(Negative Sampling):这种优化方式做的事情是,在正确单词以外的负样本中进行采样,最终目的是为了减少负样本的数量,达到减少计算量效果。将词典中的每一个词对应一条线段,所有词组成了[0,1]间的剖分,如下图所示,然后每次随机生成一个[1, M-1]间的整数,看落在哪个词对应的剖分上就选择哪个词,最后会得到一个负样本集合。
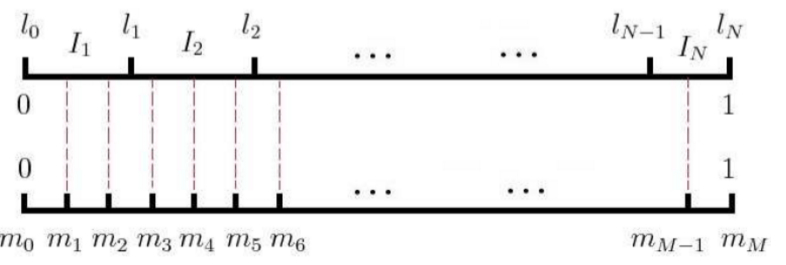
image
Word2Vec存在的问题
-
对每个local context window单独训练,没有利用包 含在global co-currence矩阵中的统计信息。 -
对多义词无法很好的表示和处理,因为使用了唯一的词向量
4.3 sense2vec
word2vec模型的问题在于词语的多义性。比如duck这个单词常见的含义有水禽或者下蹲,但对于 word2vec 模型来说,它倾向于将所有概念做归一化平滑处理,得到一个最终的表现形式。
5. 词嵌入为何不采用one-hot向量
虽然one-hot词向量构造起来很容易,但通常并不是⼀个好选择。⼀个主要的原因是,one-hot词向量⽆法准确表达不同词之间的相似度,如我们常常使⽤的余弦相似度。由于任何两个不同词的one-hot向量的余弦相似度都为0,多个不同词之间的相似度难以通过onehot向量准确地体现出来。
word2vec⼯具的提出正是为了解决上⾯这个问题。它将每个词表⽰成⼀个定⻓的向量,并使得这些向量能较好地表达不同词之间的相似和类⽐关系。
获取更多干货内容,记得关注我哦。
本文由 mdnice 多平台发布
相关文章:
什么是词嵌入(Word Embedding)
1. 什么是词嵌入(Word Embedding) ⾃然语⾔是⼀套⽤来表达含义的复杂系统。在这套系统中,词是表义的基本单元。顾名思义,词向量是⽤来表⽰词的向量,也可被认为是词的特征向量或表征。把词映射为实数域向量的技术也叫词嵌⼊(word e…...

LSTM时间序列模型实战——预测上证指数走势
LSTM时间序列模型实战——预测上证指数走势 关于作者 作者:小白熊 作者简介:精通python、matlab、c#语言,擅长机器学习,深度学习,机器视觉,目标检测,图像分类,姿态识别,…...

基于 STM32F407 的 SPI Flash下载算法
目录 一、概述二、自制 FLM 文件1、修改使用的芯片2、修改输出算法的名称3、其它设置4、修改配置文件 FlashDev.c5、文件 FlashPrg.c 的实现 三、验证算法 一、概述 本文将介绍如何使用 MDK 创建 STM32F407 的 SPI Flash 下载算法。 其中,SPI Flash 芯片使用的是 W…...

力扣之1355.活动参与者
题目: Sql 测试用例: Create table If Not Exists Friends (id int, name varchar(30), activity varchar(30)); Create table If Not Exists Activities (id int, name varchar(30)); Truncate table Friends; insert into Friends (id, name, acti…...

数据资产治理:构建敏捷与安全的数据管理体系
在当今数字化的盛况下,作为核心资产的数据已经越发受到企业的重视。但是随着公司的逐步壮大,如何分析这些数据以及如何有效治理数据资产,以确保安全性、合规性以及易用性,是企业面临的重大挑战。数聚股份将从多年从业经验深度探讨…...

Nodejs连接Mysql笔记
框架搭建 安装Node.js 首先,确保你已经在系统上安装了Node.js和npm(Node Packaged Modules)。你可以通过以下命令检查是否已经安装:shell 或者 node -v 或者 npm -v 数据库连接代码 1.导入MySQL2库 npm install mysql2 2.在文件…...

Canvas:AI协作的新维度
在人工智能的浪潮中,OpenAI的最新力作Canvas,不仅是一款新工具,它标志着人工智能协作方式的一次革命性飞跃。Canvas为写作和编程提供了一个全新的交互界面,让用户能够与ChatGPT进行更紧密、更直观的协作。 Canvas的…...

【深度学习】— softmax回归、网络架构、softmax 运算、小批量样本的向量化、交叉熵
【深度学习】— softmax回归、网络架构、softmax 运算、小批量样本的向量化、交叉熵 3.4 Softmax 回归3.4.1 分类问题3.4.2 网络架构 3.4.3 全连接层的参数开销3.4.4 softmax 运算3.4.5 小批量样本的向量化3.4.6 损失函数对数似然softmax 的导数 3.4.7 信息论基础熵信息量重新审…...

C# Wpf 图片按照鼠标中心缩放和平移
C# Wpf 图片按照鼠标中心缩放和平移 1、缩放事件 MouseWheel(object sender, MouseWheelEventArgs e)2、平移相关的事件 MouseMove(object sender, MouseEventArgs e) MouseDown(object sender, MouseButtonEventArgs e) MouseUp(object sender, MouseButtonEventArgs e)3、…...

网络安全产品类型
1. 防火墙(Firewall) 功能:防火墙是网络安全的第一道防线,通过检查进出网络的流量来阻止未经授权的访问。它可以基于预定义的安全规则,过滤数据包和阻止恶意通信。 类型: 硬件防火墙:以专用设备…...

【开源风云】从若依系列脚手架汲取编程之道(五)
📕开源风云系列 🍊本系列将从开源名将若依出发,探究优质开源项目脚手架汲取编程之道。 🍉从不分离版本开写到前后端分离版,再到微服务版本,乃至其中好玩的一系列增强Plus操作。 🍈希望你具备如下…...

金融市场的衍生品交易及其风险管理探讨
金融衍生品市场是现代金融体系的重要组成部分,其交易量和复杂性在过去几十年中迅速增长。衍生品,如期权、期货、掉期等,因其灵活性和杠杆效应,广泛应用于风险管理、投机和资产配置等多个领域。本文将探讨金融衍生品交易的关键特点…...
)
一、创建型(单例模式)
单例模式 概念 单例模式是一种创建型设计模式,确保一个类只有一个实例,并提供一个全局访问点。它控制类的实例化过程,防止外部代码创建新的实例。 应用场景 日志记录:确保只有一个日志记录器,以便于管理和避免重复记…...
毕业设计项目-古典舞在线交流平台的设计与实现(源码/论文)
项目简介 基于springboot实现的,主要功能如下: 技术栈 后端框框:springboot/mybatis 前端框架:html/JavaScript/Css/vue/elementui 运行环境:JDK1.8/MySQL5.7/idea(可选)/Maven3(…...
-三语言题解)
【秋招笔试】10.09华子秋招(已改编)-三语言题解
🍭 大家好这里是 春秋招笔试突围,一起备战大厂笔试 💻 ACM金牌团队🏅️ | 多次AK大厂笔试 | 大厂实习经历 ✨ 本系列打算持续跟新 春秋招笔试题 👏 感谢大家的订阅➕ 和 喜欢💗 和 手里的小花花🌸 ✨ 笔试合集传送们 -> 🧷春秋招笔试合集 本次的三题全部上线…...

【算法笔记】双指针算法深度剖析
【算法笔记】双指针算法深度剖析 🔥个人主页:大白的编程日记 🔥专栏:算法笔记 文章目录 【算法笔记】双指针算法深度剖析前言一.移动零1.1题目1.2思路分析1.3代码实现 二.复写零2.1题目2.2思路分析2.3代码实现 三.快乐数3.1题目…...

第二十二天|回溯算法| 理论基础,77. 组合(剪枝),216. 组合总和III,17. 电话号码的字母组合
目录 回溯算法理论基础 1.题目分类 2.理论基础 3.回溯法模板 补充一个JAVA基础知识 什么时候用ArrayList什么时候用LinkedList 77. 组合 未剪枝优化 剪枝优化 216. 组合总和III 17. 电话号码的字母组合 回溯法的一个重点理解:细细理解这句话!…...

关闭IDM自动更新
关闭IDM自动更新 1 打开注册表2 找到IDM注册表路径 1 打开注册表 winR regedit 2 找到IDM注册表路径 计算机\HKEY_CURRENT_USER\Software\DownloadManager 双击LstCheck,把数值数据改为0 完成 感谢阅读...

Go 性能剖析工具 pprof 与 Graphviz 教程
在 Golang 开发中,性能分析是确保应用高效运行的重要环节。本文介绍如何使用 gin-contrib/pprof 在 Gin 应用中集成性能剖析工具,并结合 Graphviz 生成图形化的性能分析结果,如火焰图。这套流程帮助开发者更好地理解和优化 Go 应用的性能。 目…...

【题目解析】蓝桥杯23国赛C++中高级组 - 斗鱼养殖场
【题目解析】蓝桥杯23国赛C中高级组 - 斗鱼养殖场 题目链接跳转:点击跳转 前置知识: 了解过基本的动态规划。熟练掌握二进制的位运算。 题解思路 这是一道典型的状压动态规划问题。设 d p i , j dp_{i, j} dpi,j 表示遍历到第 i i i 行的时候&a…...

Maintain Certificate Trust List,把 SAP 出站通信里的证书信任关口管清楚
做 SAP S/4HANA Cloud、SAP BTP ABAP environment 或者混合架构里的出站集成时,有一个问题很容易被业务侧低估,却经常成为接口上线前的最后一道卡点,SAP 系统到底信不信任通信伙伴的服务器证书。OAuth、Basic Authentication、Communication Arrangement、Destination、ODat…...

如何高效掌握LAMMPS:分子动力学模拟的完整实战指南
如何高效掌握LAMMPS:分子动力学模拟的完整实战指南 【免费下载链接】lammps Public development project of the LAMMPS MD software package 项目地址: https://gitcode.com/gh_mirrors/la/lammps 想要快速掌握强大的分子动力学模拟工具吗?LAMM…...

基于GAN的AI图像水印移除工具VeoWatermarkRemover实战指南
1. 项目概述:一个开源图像水印移除工具 最近在整理一些老照片和网上下载的素材时,经常被图片上那些碍眼的水印、Logo或者时间戳困扰。手动用PS处理,费时费力,而且对批量操作极不友好。直到我发现了GitHub上一个名为“VeoWatermar…...

互联网大厂 Java 求职面试全景:从音视频场景到微服务架构的深入探讨
互联网大厂 Java 求职面试全景:从音视频场景到微服务架构的深入探讨 在互联网大厂的招聘中,Java 开发者的面试不仅技术含量高,还充满了戏剧性。今天,我们将通过一位求职者燕双非与面试官的对话,带你走进这个复杂而有趣…...
)
为什么你的Perplexity薪资查询总返回403?3类Token权限陷阱+2种合法绕行路径(含Postman配置模板)
更多请点击: https://intelliparadigm.com 第一章:为什么你的Perplexity薪资查询总返回403?3类Token权限陷阱2种合法绕行路径(含Postman配置模板) 当你调用 Perplexity 提供的薪资数据 API(如 /v1/salari…...

MoocDownloader:三步轻松下载中国大学MOOC课程,实现离线学习自由
MoocDownloader:三步轻松下载中国大学MOOC课程,实现离线学习自由 【免费下载链接】MoocDownloader An MOOC downloader implemented by .NET. 一枚由 .NET 实现的 MOOC 下载器. 项目地址: https://gitcode.com/gh_mirrors/mo/MoocDownloader 你是…...

实用指南:5分钟搞定Minecraft MASA模组中文汉化
实用指南:5分钟搞定Minecraft MASA模组中文汉化 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese MASA全家桶汉化包是专为Minecraft 1.21版本设计的专业本地化解决方案&#x…...

拆解新客裂变与裂变率:诺云用户可直接套用的获客增长指南
在流量红利消退、公域获客成本高企的当下,“新客裂变”早已成为企业降低获客成本、实现指数级增长的核心抓手,而“裂变率”作为衡量裂变效果的核心指标,直接决定了这场获客动作的成败。今天,我们就聚焦“新客裂变”与“裂变率”这…...

性能优化必看:你的Unity粒子特效为什么这么卡?从ParticleSystem参数入手排查
Unity粒子特效性能优化实战指南:从参数调优到帧率提升 1. 粒子特效性能问题的根源剖析 在移动端和VR项目中,粒子特效往往是性能瓶颈的重灾区。一次性能审计中,某款手游的瀑布场景因未限制粒子最大数量,导致中端机型帧率骤降至18fp…...

Pandas 数据清洗与分析
第一部分:水果销售分析(入门篇)首先,我们有一个简单的水果销售列表。我们的任务是算出每种水果的总销量,以及每天的销售明细。1. 数据准备我们先造一点数据:import pandas as pd import numpy as npdata {…...