深度学习模型
1. 引言
在过去的十年间,深度学习的崛起引发了人工智能领域的革命,深刻影响了多个行业。深度学习是一种模仿人脑神经元的工作方式,通过多层神经网络进行数据处理与特征学习。其应用范围从简单的图像识别到复杂的自然语言处理、自动驾驶和医疗诊断等领域,深度学习已经证明了其强大的学习能力。
深度学习的成功离不开大量的数据、强大的计算能力以及先进的算法。随着研究的深入和技术的进步,深度学习不断发展,涌现出多种新模型和应用。本文将全面探讨深度学习模型的基本概念、不同类型的模型、训练过程、最新进展及其应用领域,并深入分析其面临的挑战和未来的发展方向。
2. 深度学习的基本概念
2.1 神经网络结构
深度学习的核心是神经网络。神经网络模拟人脑神经元的连接结构,通常由多个层组成:
- 输入层:接收外部输入的数据,每个节点对应一个特征。
- 隐藏层:由多个神经元组成,负责特征提取和非线性变换。隐藏层的数量和每层的神经元数量直接影响模型的复杂性和表达能力。
- 输出层:根据隐藏层提取的特征生成最终预测结果。输出层的结构根据具体任务而变化,例如在分类任务中通常采用softmax函数来计算每个类别的概率。
2.2 激活函数
激活函数为神经网络引入非线性因素,使得网络能够学习和拟合复杂的函数。常用的激活函数包括:
-
ReLU(Rectified Linear Unit):在输入大于零时,输出与输入相等;输入小于零时,输出为零。ReLU加速了网络的训练,减少了梯度消失的问题。公式为:
f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x) -
Sigmoid:将输入压缩到0到1之间,适合二分类问题,但在深层网络中容易出现梯度消失。公式为:
f(x)=11+e−xf(x) = \frac{1}{1 + e^{-x}}f(x)=1+e−x1 -
Tanh:将输入映射到-1到1之间,能够提供更强的输出信号,适合处理对称数据。公式为:
f(x)=tanh(x)=ex−e−xex+e−xf(x) = \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}f(x)=tanh(x)=ex+e−xex−e−x
2.3 损失函数
损失函数用于衡量模型预测值与真实值之间的差距,指导模型的优化过程。常见的损失函数包括:
-
均方误差(MSE):用于回归任务,计算预测值与真实值之间的平方差。公式为:
MSE=1n∑i=1n(yi−y^i)2\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2MSE=n1i=1∑n(yi−y^i)2 -
交叉熵损失:常用于分类任务,衡量真实标签与预测概率分布之间的差异,公式为:
Cross-Entropy=−∑i=1Cyilog(y^i)\text{Cross-Entropy} = - \sum_{i=1}^{C} y_i \log(\hat{y}_i)Cross-Entropy=−i=1∑Cyilog(y^i)其中 yiy_iyi 是真实标签,y^i\hat{y}_iy^i 是模型预测的概率。
2.4 正则化
为了防止模型过拟合,通常会使用正则化技术。常见的正则化方法包括:
-
L1正则化:在损失函数中添加权重的绝对值之和,促进稀疏性。
Loss=Loss+λ∑∣wi∣\text{Loss} = \text{Loss} + \lambda \sum |w_i|Loss=Loss+λ∑∣wi∣ -
L2正则化:在损失函数中添加权重的平方和,平滑权重值。
Loss=Loss+λ∑wi2\text{Loss} = \text{Loss} + \lambda \sum w_i^2Loss=Loss+λ∑wi2
3. 深度学习模型的类型
深度学习模型可根据不同任务的需求分为多种类型,每种模型都有其独特的结构和应用场景。
3.1 前馈神经网络(FNN)
前馈神经网络是最简单的神经网络结构。信息在网络中单向流动,没有环路。适合处理静态数据的分类与回归任务。FNN的优点是结构简单,易于实现,但在处理复杂数据时可能表现不足。
3.2 卷积神经网络(CNN)
卷积神经网络专为图像处理设计,通过局部感知、共享权重和池化操作来有效提取图像特征。CNN的核心组件包括:
- 卷积层:通过卷积运算提取特征,通常使用多个卷积核对输入图像进行处理。
- 激活层:通常在卷积层后应用ReLU激活函数,以增加非线性。
- 池化层:用于下采样,减少特征图的维度,防止过拟合。常用的池化方法有最大池化和平均池化。
- 全连接层:在网络的最后阶段,将提取的特征进行整合,输出分类结果。
CNN在图像识别、目标检测和图像生成等领域取得了显著成功。
3.3 循环神经网络(RNN)
循环神经网络适合处理序列数据,具有记忆能力,能够捕捉数据中的时间依赖性。RNN通过隐状态传递信息,使得网络能够利用先前的信息。其变体包括:
-
长短期记忆网络(LSTM):解决了标准RNN在处理长序列时的梯度消失问题。LSTM通过引入记忆单元和门控机制来控制信息流动,决定哪些信息保留、更新或遗忘。
-
门控循环单元(GRU):与LSTM相似,但结构更简单,使用更新门和重置门来控制信息流动。
RNN广泛应用于自然语言处理、语音识别和时间序列预测等任务。
3.4 生成对抗网络(GAN)
生成对抗网络由生成器和判别器组成,通过对抗训练生成高质量样本。生成器负责生成样本,而判别器负责判断样本的真实性。两者通过博弈过程相互提升性能,最终生成器能够生成与真实数据几乎无法区分的样本。
GAN在图像生成、图像修复和风格迁移等领域表现突出。
3.5 Transformer模型
Transformer模型是近年来兴起的一种新型网络架构,尤其在自然语言处理领域表现卓越。其核心思想是自注意力机制,使得模型能够有效捕捉输入序列中各个位置之间的关系。Transformer消除了传统RNN在处理长序列时的限制,显著提升了训练效率和效果。
4. 深度学习模型的训练
深度学习模型的训练过程涉及多个关键步骤,每一步都对模型的性能产生重要影响。以下是详细的训练过程。
4.1 数据准备
4.1.1 数据收集
在训练深度学习模型之前,首先需要收集大量的高质量数据。这些数据可以来自多种渠道:
- 公开数据集:许多领域都有公开的数据集,如ImageNet、COCO、MNIST等,这些数据集已经过标注并适合用于训练模型。
- 自定义数据集:在特定应用场景下,可能需要收集自定义数据。这通常涉及数据爬取、问卷调查等手段。
- 合成数据:在某些情况下,可以通过模拟或生成算法创建合成数据来扩充训练集。
4.1.2 数据清洗
数据清洗是确保数据质量的重要步骤,通常包括:
- 去重:删除重复的样本,以避免对模型造成偏见。
- 处理缺失值:使用均值填充、插值或删除缺失值样本的方法处理缺失数据。
- 异常值检测:识别并处理数据中的异常值,以避免影响模型训练。
4.1.3 数据增强
数据增强是通过对训练数据进行变换,增加数据的多样性,从而提升模型的泛化能力。常见的数据增强方法包括:
- 图像增强:对图像进行旋转、翻转、裁剪、缩放和颜色变换等处理。
- 文本增强:使用同义词替换、随机删除和数据扩充等方法增强文本数据。
4.2 模型选择
选择合适的模型架构是成功的关键。根据任务需求,可以选择以下几种常见模型:
- 分类任务:适合使用CNN,尤其是在图像分类和文本分类任务中表现优异。
- 序列任务:RNN、LSTM或GRU适合处理时间序列或自然语言处理任务。
- 生成任务:GAN和VAE(变分自编码器)常用于生成新样本。
4.3 损失计算
在每次训练迭代中,使用损失函数计算预测值与真实值之间的误差。这个过程通常包括以下步骤:
- 前向传播:将输入数据通过神经网络,计算出预测值。
- 损失计算:利用损失函数计算损失值,以评估模型的表现。
4.4 参数更新
深度学习模型的优化主要依赖于参数更新。优化算法决定了如何根据损失值调整网络参数。常用的优化算法包括:
- 随机梯度下降(SGD):通过计算一个小批量(mini-batch)的梯度来更新参数,适用于大规模数据集。
- Adam优化器:结合了动量和自适应学习率,适用于各种任务,具有更快的收敛速度和更好的效果。
更新参数的过程通常为:
θ=θ−α∇J(θ)\theta = \theta - \alpha \nabla J(\theta)θ=θ−α∇J(θ)
其中,α\alphaα 是学习率,∇J(θ)\nabla J(\theta)∇J(θ) 是损失函数相对于参数的梯度。
4.5 模型评估
模型评估是判断模型性能的关键环节。通常使用验证集进行评估,主要指标包括:
- 准确率:分类任务中正确分类的样本占总样本的比例。
- 精确率和召回率:精确率衡量模型预测为正类的样本中实际为正类的比例,召回率衡量实际正类样本中被正确预测为正类的比例。
Precision=TPTP+FP,Recall=TPTP+FN\text{Precision} = \frac{TP}{TP + FP}, \quad \text{Recall} = \frac{TP}{TP + FN}Precision=TP+FPTP,Recall=TP+FNTP
- F1 Score:精确率和召回率的调和平均,综合考虑模型的准确性和召回率。
4.6 超参数调优
超参数是指在训练开始前需要手动设置的参数,例如学习率、批量大小、网络深度等。超参数调优通常采用以下方法:
- 网格搜索:通过穷举法遍历所有可能的超参数组合。
- 随机搜索:随机选取超参数组合进行训练,效率较高。
- 贝叶斯优化:通过构建模型对超参数空间进行建模,逐步寻找最优解。
5. 深度学习的最新进展
近年来,深度学习领域取得了显著进展,推动了多个技术的快速发展。
5.1 自监督学习
自监督学习是一种新兴的学习范式,利用未标注的数据进行特征学习。在自监督学习中,模型通过生成代理任务(如预测图像的某部分、填补文本中的空白)来学习数据的潜在结构。该方法在数据稀缺的情况下表现优越,已经在图像和文本处理领域取得了突破。
5.2 迁移学习
迁移学习旨在将已训练好的模型应用于新任务,尤其是在目标任务的数据有限的情况下。通过在大规模数据集上预训练模型,并在目标数据集上进行微调,可以显著提高模型的性能。迁移学习已被广泛应用于计算机视觉和自然语言处理任务。
5.3 联邦学习
联邦学习是一种分布式学习方法,允许模型在多个设备上训练而不需要将数据集中到一起。这种方法保护了用户隐私,同时利用了边缘设备的计算能力,适用于医疗、金融等数据隐私要求高的场景。
5.4 图神经网络(GNN)
图神经网络是一种针对图数据的深度学习模型,适用于处理社交网络、知识图谱和分子结构等类型的数据。GNN通过节点之间的关系建模,能够有效学习图的结构特征,广泛应用于推荐系统、药物发现等领域。
5.5 大模型
近年来,模型规模的不断扩大使得大模型(如GPT-3、BERT等)成为热门研究方向。这些模型通过大规模的数据集训练,能够进行更复杂的语言理解和生成任务。大模型的成功引发了对计算资源和能效的关注,推动了模型压缩和高效训练算法的发展。
6. 深度学习模型的应用领域
深度学习技术的广泛应用已深入多个行业和领域,以下是一些主要的应用场景:
6.1 计算机视觉
计算机视觉是深度学习最重要的应用领域之一。深度学习模型,尤其是卷积神经网络(CNN),在图像分类、物体检测和图像分割等任务中表现出色。
-
图像分类:利用CNN模型,可以对图像进行分类。例如,ImageNet挑战赛中,许多基于深度学习的模型在图像分类任务上获得了前所未有的高准确率。
-
物体检测:YOLO(You Only Look Once)和Faster R-CNN等模型可以实时识别图像中的多个物体,并标记其位置,广泛应用于视频监控、无人驾驶等领域。
-
图像分割:U-Net和Mask R-CNN等模型能够将图像分割成不同的区域,实现语义分割和实例分割,广泛应用于医学影像分析。
6.2 自然语言处理
自然语言处理(NLP)是深度学习的另一个重要领域。利用RNN、LSTM、GRU和Transformer模型,深度学习在语言理解和生成方面取得了显著进展。
-
文本分类:如情感分析和垃圾邮件检测,通过深度学习模型对文本进行分类。
-
机器翻译:基于Transformer的模型如BERT和GPT已被广泛应用于机器翻译任务,实现了高质量的翻译效果。
-
对话系统:深度学习技术使得构建智能对话系统成为可能,例如基于GPT的聊天机器人,能够理解用户的问题并进行智能回应。
6.3 语音识别
深度学习在语音识别领域同样取得了显著成就。模型如端到端的深度神经网络(DNN)和卷积神经网络(CNN)被用于语音到文本的转换。
-
自动语音识别(ASR):通过深度学习模型,可以将语音信号转化为文字,应用于语音助手、电话客服等场景。
-
声纹识别:利用深度学习模型进行个体声纹的识别与验证,广泛应用于安全认证领域。
6.4 医疗健康
深度学习在医疗健康领域的应用日益广泛,帮助医生提高诊断准确率,改善患者治疗效果。
-
医学影像分析:通过深度学习模型对X光、CT和MRI等医学影像进行分析,实现自动病灶检测与分类。
-
基因组学:利用深度学习分析基因组数据,预测疾病风险,辅助个性化医疗。
6.5 自动驾驶
自动驾驶技术的实现离不开深度学习的支持。深度学习模型被用于感知、决策和控制等多个方面。
-
环境感知:通过卷积神经网络和传感器数据融合,实现对周围环境的理解,包括道路识别、行人检测和障碍物识别。
-
路径规划:基于深度学习的算法用于预测最佳行驶路径,提高行车安全性。
7. 深度学习面临的挑战
尽管深度学习技术取得了显著进展,但在实际应用中仍面临一些挑战。
7.1 数据依赖
深度学习模型通常需要大量的标注数据进行训练,而高质量标注数据的获取往往成本高昂且耗时。此外,数据的偏差也可能导致模型的偏见。
7.2 过拟合
深度学习模型易于在训练数据上表现良好,但在未见过的数据上可能出现过拟合。为解决这一问题,通常需要采用正则化、数据增强等方法。
7.3 可解释性
深度学习模型通常被视为“黑箱”,其内部决策过程不易理解。这给在医疗、金融等关键领域的应用带来了挑战,如何提高模型的可解释性仍是一个重要研究方向。
7.4 计算资源
深度学习模型的训练和推理通常需要大量的计算资源,这限制了其在资源受限环境中的应用。如何降低计算需求,提高模型效率是当前研究的热点之一。
8. 未来发展方向
深度学习技术的发展仍在持续,未来的研究方向包括:
8.1 轻量化模型
为了适应移动设备和边缘计算的需求,研究人员正在致力于开发轻量化模型,如MobileNet和EfficientNet。这些模型通过减少参数量和计算量,在保证准确率的同时,提高了运行效率。
8.2 增强学习
增强学习结合深度学习技术,使得智能体能够通过与环境的交互不断学习与优化。该方法在游戏、机器人和自动驾驶等领域表现突出。
8.3 跨模态学习
跨模态学习旨在通过不同模态(如图像、文本、声音)之间的相互理解,提升模型的智能水平。这种方法在多媒体内容理解和生成方面有广阔的前景。
8.4 伦理和安全
随着深度学习在各领域的应用不断扩大,如何处理伦理和安全问题成为重要议题。研究人员需要确保深度学习模型的公正性、隐私保护和安全性,防止其滥用。
9. 深度学习模型的工具与框架
随着深度学习技术的发展,众多工具和框架应运而生,为研究人员和开发者提供了便利。这些工具和框架大大降低了深度学习的入门门槛,推动了技术的普及与应用。
9.1 TensorFlow
TensorFlow 是由 Google 开发的开源深度学习框架。它提供了灵活的计算图机制,支持各种规模的深度学习模型。TensorFlow 的主要特点包括:
- 高效性:通过 XLA(加速线性代数)编译器进行优化,提升模型训练和推理的速度。
- 分布式计算:支持在多种硬件上进行分布式训练,适合大规模数据集。
- 丰富的社区和文档:拥有庞大的用户社区,提供了丰富的教程和模型库。
9.2 PyTorch
PyTorch 是 Facebook 开发的深度学习框架,以其动态计算图的特性而受到广泛欢迎。PyTorch 的优势在于:
- 易用性:其 API 设计简洁,适合快速原型开发和实验。
- 动态图机制:允许在运行时修改计算图,提供了更大的灵活性。
- 强大的社区支持:PyTorch 在研究界得到广泛应用,许多前沿研究成果都基于此框架。
9.3 Keras
Keras 是一个高级深度学习 API,最初是为了简化深度学习模型的构建而设计。Keras 可以作为 TensorFlow 的一部分使用,具有以下优点:
- 用户友好:API 设计简洁易懂,适合初学者。
- 模块化:允许用户方便地组合不同层和模型,快速构建深度学习应用。
- 支持多种后端:Keras 可以与 TensorFlow、Theano 和 CNTK 等深度学习后端一起使用。
9.4 MXNet
MXNet 是一个高性能的深度学习框架,支持多种编程语言。它的特点包括:
- 灵活性:支持动态图和静态图,适合不同需求的应用场景。
- 分布式训练:提供了高效的分布式计算能力,适合处理大规模数据。
- 社区支持:虽然相对较小,但随着亚马逊对其的支持,社区正在逐步扩大。
9.5 ONNX
ONNX(开放神经网络交换格式)是一个开放格式,旨在促进深度学习模型的互操作性。ONNX 的优势在于:
- 模型转化:允许用户将模型从一个框架转移到另一个框架,例如从 PyTorch 转移到 TensorFlow。
- 跨平台支持:支持多种深度学习框架和硬件,加速模型的推理过程。
10. 深度学习的未来展望
深度学习的未来充满希望,随着技术的不断进步和创新,预计将会出现以下趋势:
10.1 更强的通用性
未来的深度学习模型将朝着通用人工智能的方向发展,能够处理多种任务,而不仅仅是专注于特定领域。这将要求模型具有更强的自学习和适应能力。
10.2 跨学科的融合
深度学习与其他学科(如生物学、化学、社会科学等)的结合将创造新的研究和应用机会。例如,在生物医学领域,深度学习可以帮助发现新的药物和治疗方法。
10.3 更高的能效
随着深度学习模型规模的不断扩大,能耗问题逐渐受到重视。未来将更加关注模型的能效优化,开发低功耗、高性能的深度学习算法。
10.4 伦理与社会责任
随着深度学习技术的广泛应用,伦理和社会责任的问题将愈发重要。研究者和开发者需要确保技术的公正性和透明度,避免造成潜在的社会影响。
10.5 开源与共享
开源社区在推动深度学习技术发展方面发挥了重要作用,未来将更加注重开源模型和数据集的共享,促进合作与创新。
11. 结论
深度学习作为人工智能领域的重要分支,已经在多个领域取得了显著的成果。虽然面临许多挑战,但随着技术的不断进步和创新,深度学习的应用前景广阔。未来,我们期待深度学习能够在更广泛的领域发挥其巨大潜力,为人类社会带来更多的便利和福祉。
相关文章:

深度学习模型
1. 引言 在过去的十年间,深度学习的崛起引发了人工智能领域的革命,深刻影响了多个行业。深度学习是一种模仿人脑神经元的工作方式,通过多层神经网络进行数据处理与特征学习。其应用范围从简单的图像识别到复杂的自然语言处理、自动驾驶和医疗…...
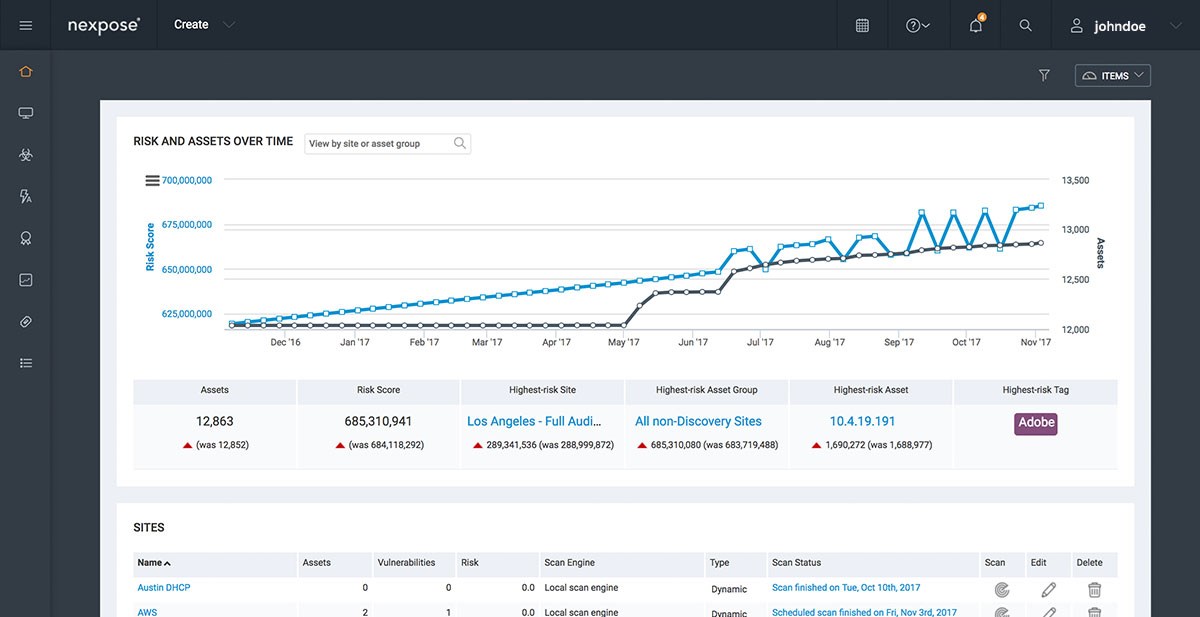
Nexpose 6.6.271 发布下载,新增功能概览
Nexpose 6.6.271 for Linux & Windows - 漏洞扫描 Rapid7 Vulnerability Management, release Sep 26, 2024 请访问原文链接:https://sysin.org/blog/nexpose-6/,查看最新版。原创作品,转载请保留出处。 作者主页:sysin.or…...
SimpleRAG-v1.0.3:增加文件对话功能
Kimi上有一个功能,就是增加文件之后对话,比如我有如下一个私有文档: 会议主题:《如何使用C#提升工作效率》 参会人员:张三、李四、王五 时间:2024.9.26 14:00-16:00 会议内容: 1. 自动化日常任…...

数学建模算法与应用 第7章 数理统计与方法
目录 7.1 参数估计与假设检验 Matlab代码示例:均值的假设检验 7.2 Bootstrap方法 Matlab代码示例:Bootstrap估计均值的置信区间 7.3 方差分析 Matlab代码示例:单因素方差分析 7.4 回归分析 Matlab代码示例:线性回归 7.5 基…...

【网络】洪水攻击防御指南
洪水攻击防御指南 摘要: 本文深入探讨了洪水攻击的概念、危害以及防御策略。通过Java技术实现,我们将学习如何通过编程手段来增强服务器的安全性。文章不仅提供了详细的技术解读,还包含了实用的代码示例和流程图,帮助读者构建一个…...

应对Redis大Key挑战:从原理到实现
在使用Redis作为缓存或数据存储时,开发者可能会遇到大Key(Big Key)问题。大Key是指在Redis中存储的单个键值对,其值的大小非常大,可能包含大量数据或占用大量内存。大Key问题会导致性能下降、内存消耗过多以及其他潜在…...

网络安全的全面指南
目录 网络安全的全面指南1. 引言2. 网络安全的基本概念3. 网络安全框架4. 常见网络安全攻击及案例4.1 病毒与恶意软件攻击案例4.2 钓鱼攻击案例4.3 DDoS 攻击案例 5. 网络安全最佳实践5.1 强密码策略5.2 定期更新和补丁管理5.3 数据备份与恢复策略 6. 企业网络安全策略6.1 安全…...

前端性能优化全面指南
前端性能优化是提升用户体验的关键,页面加载速度、响应时间和交互流畅度直接影响用户的留存率和满意度。以下是常用的前端性能优化方法,从网络层、资源加载、JavaScript 执行、渲染性能等方面进行全方位优化。 减少 HTTP 请求 合并文件:将多…...
)
JavaScript-API(倒计时的实现)
基础知识 1.时间对象的使用 1.1 实例化 要获取一个时间首先需要一个关键词new了实例化 const time new Date() 如果是获取具体的具体的时间 const time new Date(2024-6-1 16:06:44) 1.2 日期对象方法 方法作用说明getFullYear()获得年份获得4…...

【C++】——继承【上】
P. S.:以下代码均在VS2019环境下测试,不代表所有编译器均可通过。 P. S.:测试代码均未展示头文件stdio.h的声明,使用时请自行添加。 博主主页:Yan. yan. …...

SpringBoot 整合 阿里云 OSS图片上传
一、OOS 简介 阿里云OSS(Object Storage Service)是一种基于云存储的产品,适用于存储和管理各种类型的文件,包括图片、视频、文档等。 阿里云OSS具有高可靠性、高可用性和低成本等优点,因此被广泛应用于各种场景&…...

内核编译 设备驱动 驱动程序
内核编译 一、内核编译的步骤 编译步骤: (linux 内核源码的顶层目录下操作 ) 1. 拷贝默认配置到 .config cp config_mini2440_td35 .config 2. make menuconfig 内核配置 make menuconfig 3. make uImage make u…...

自由学习记录
约束的泛型通配符? Java中的泛型 xiaomi和byd都继承了car,但是只是这两个类是car的子类而已,而arraylist<xiaomi> ,arraylist<byd> 两个没有半毛钱继承关系 所以传入的参数整体,是car的list变形,里面的确都能存car…...

在 C# 中使用 LINQ 查询文件列表并找出最大文件
文章目录 1. 环境准备2. 创建项目3. 引入命名空间4. 示例代码5. 运行代码6. 进阶:异常处理7. 总结 在现代 C# 开发中,LINQ (Language Integrated Query) 提供了一种强大而优雅的方式来处理集合数据。本文将详细介绍如何使用 LINQ 查询文件系统中的文件&a…...

数学建模算法与应用 第6章 微分方程建模及其求解方法
目录 6.1 微分方程建模概述 6.2 发射卫星与三阶火箭建模 Matlab代码示例:火箭发射模拟 6.3 微分方程数值解法 Matlab代码示例:欧拉法与龙格-库塔法 6.4 放射性废料的处理 Matlab代码示例:放射性衰变 6.5 初值问题的Matlab数值求解 习…...

数据库的相关知识
数据库的相关知识 1.数据库能够做什么? 存储大量数据,方便检索和访问保持数据信息的一致、完整共享和安全通过组合分析,产生新的有用信息 2.数据库作用? 存储数据、检索数据、生成新的数据 3.数据库要求? 统一、…...

Python cachetools常用缓存算法汇总
文章目录 cachetools介绍缓存操作设置数据生存时间(TTL)自定义缓存策略缓存装饰器缓存清理cachetools 超过缓存数量maxsize cachetools 使用示例 cachetools介绍 cachetools : 是一个Python第三方库,提供了多种缓存算法的实现。缓存是一种用于…...
java类和对象_成员变量方法修饰符局部变量this关键字-cnblog
java类和对象 成员变量 权限修饰符 变量类型 变量名; 成员变量可以是任意类型,整个类是成员变量的作用范围 成员变量 成员方法 权限修饰符 返回值类型 方法名() 成员方法可以有参数,也可以有返回值,用return声明 权限修饰符 private 只能在本类…...

海信和TCL雷鸟及各大品牌智能电视测评
买了型号为32E2F(9008)的海信智能的电视有一段时间了,要使用这个智能电视还真能考验你的智商。海信电视有很多优点,它的屏幕比较靓丽,色彩好看,遥控器不用对着屏幕就能操作。但也有不少缺点。 1. 海信智能电视会强迫自动更新操作…...
)
Linux 基本系统命令及其使用详解手册(六)
指令:mesg 使用权限:所有使用者 使用方式:mesg [y|n] 说明 : 决定是否允许其他人传讯息到自己的终端机介面 把计 : y:允许讯息传到终端机介面上。 n:不允许讯息传到终端机介面上 。 如果没有设定,则讯息传递与否则由终端机界…...

全面掌握AMD Ryzen硬件调试:SMUDebugTool完整使用指南
全面掌握AMD Ryzen硬件调试:SMUDebugTool完整使用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gi…...

AdvancedLiterateMachinery的LORE-TSR:逻辑位置回归网络在表格结构识别中的突破
AdvancedLiterateMachinery的LORE-TSR:逻辑位置回归网络在表格结构识别中的突破 【免费下载链接】AdvancedLiterateMachinery A collection of original, innovative ideas and algorithms towards Advanced Literate Machinery. This project is maintained by the…...

如何用 OpenAPI Generator CLI 自动生成TypeScript Angular客户端
如何用 OpenAPI Generator CLI 自动生成TypeScript Angular客户端 【免费下载链接】openapi-generator-cli A node package wrapper for https://github.com/OpenAPITools/openapi-generator 项目地址: https://gitcode.com/gh_mirrors/op/openapi-generator-cli OpenAP…...
)
别再被AD值乱跳搞懵了!CS1237电子秤芯片的5个硬件设计避坑点(附电路图)
别再被AD值乱跳搞懵了!CS1237电子秤芯片的5个硬件设计避坑点(附电路图) 电子秤设计中最令人头疼的莫过于AD值不稳定问题。作为一款高精度Σ-Δ ADC芯片,CS1237在电子秤、压力测量等领域应用广泛,但硬件设计中的细微偏差…...

Windows Cleaner终极指南:3分钟解决C盘爆满,让电脑重获新生![特殊字符]
Windows Cleaner终极指南:3分钟解决C盘爆满,让电脑重获新生!🚀 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是…...

从零打造3D打印外壳:精准适配Adafruit Trellis控制器全流程
1. 项目概述与核心思路如果你手头有一块Adafruit Trellis按钮板,想把它变成一个握感扎实、外观专业的独立设备,比如一个迷你音乐控制器或者游戏手柄,那么为它设计并打印一个专属外壳,几乎是必经之路。这个项目远不止是把电路板塞进…...

FPGA静态侧信道攻击防御与传感器绕过技术解析
1. FPGA安全防御机制与静态侧信道攻击概述在现代数字安全领域,现场可编程门阵列(FPGA)因其可重构性和高性能特性,已成为加密加速、信号处理等关键应用的核心组件。然而,FPGA面临的物理安全威胁与日俱增,特别是针对硬件的侧信道攻击…...
详解:终于搞懂管道、消息队列、共享内存到底在干什么)
Linux 进程间通信(IPC)详解:终于搞懂管道、消息队列、共享内存到底在干什么
很多人第一次学 Linux 进程间通信(IPC)时,都会有一种感觉:概念很多 API 很杂 学完还是不知道到底什么时候该用什么最容易出现的问题是:管道和消息队列有什么区别?为什么共享内存最快?信号量到底…...

CST仿真入门实战:Dipole天线结果解读与关键参数分析
1. Dipole天线仿真结果初探 第一次打开CST仿真软件完成Dipole天线仿真后,面对密密麻麻的结果图表,相信很多人都会感到无从下手。我刚开始接触电磁仿真时也是这样,盯着那些S参数曲线和远场辐射图发愣。其实读懂这些结果并不难,关键…...

告别虚拟机卡顿:在VMware 17上为RHEL 9.2分配CPU和内存的黄金法则
告别虚拟机卡顿:在VMware 17上为RHEL 9.2分配CPU和内存的黄金法则 当你在VMware Workstation 17上运行RHEL 9.2时,是否经常遇到编译速度慢、桌面响应延迟甚至整个系统卡死的情况?这很可能是因为你没有根据宿主机的实际硬件情况科学分配虚拟资…...