力扣SQL仅数据库(1098~1132)
1098 小众书籍
需求
编写解决方案,筛选出过去一年中订单总量 少于 10 本 的 书籍,并且 不考虑 上架距今销售 不满一个月 的书籍 。假设今天是 2019-06-23 。
返回结果表 无顺序要求 。
数据准备
Create table If Not Exists Books (book_id int, name varchar(50), available_from date)
Create table If Not Exists Orders (order_id int, book_id int, quantity int, dispatch_date date)
Truncate table Books
insert into Books (book_id, name, available_from) values ('1', 'Kalila And Demna', '2010-01-01')
insert into Books (book_id, name, available_from) values ('2', '28 Letters', '2012-05-12')
insert into Books (book_id, name, available_from) values ('3', 'The Hobbit', '2019-06-10')
insert into Books (book_id, name, available_from) values ('4', '13 Reasons Why', '2019-06-01')
insert into Books (book_id, name, available_from) values ('5', 'The Hunger Games', '2008-09-21')
Truncate table Orders
insert into Orders (order_id, book_id, quantity, dispatch_date) values ('1', '1', '2', '2018-07-26')
insert into Orders (order_id, book_id, quantity, dispatch_date) values ('2', '1', '1', '2018-11-05')
insert into Orders (order_id, book_id, quantity, dispatch_date) values ('3', '3', '8', '2019-06-11')
insert into Orders (order_id, book_id, quantity, dispatch_date) values ('4', '4', '6', '2019-06-05')
insert into Orders (order_id, book_id, quantity, dispatch_date) values ('5', '4', '5', '2019-06-20')
insert into Orders (order_id, book_id, quantity, dispatch_date) values ('6', '5', '9', '2009-02-02')
insert into Orders (order_id, book_id, quantity, dispatch_date) values ('7', '5', '8', '2010-04-13')代码实现
with b as (select * from books where available_from <'2019-05-23')
, o as (select * from orders where dispatch_date > '2018-06-23')
,su as (select b.book_id,name,sum(ifnull(quantity,0))suu from b left join o on o.book_id=b.book_id
group by b.book_id,name)
select book_id,name from su where suu<10;1107. 每日新用户统计
需求:
编写解决方案,找出从今天起最多 90 天内,每个日期该日期首次登录的用户数。假设今天是 2019-06-30 。
以 任意顺序 返回结果表
数据准备:
Create table If Not Exists Traffic (user_id int, activity ENUM('login', 'logout', 'jobs', 'groups', 'homepage'), activity_date date)
Truncate table Traffic
insert into Traffic (user_id, activity, activity_date) values ('1', 'login', '2019-05-01')
insert into Traffic (user_id, activity, activity_date) values ('1', 'homepage', '2019-05-01')
insert into Traffic (user_id, activity, activity_date) values ('1', 'logout', '2019-05-01')
insert into Traffic (user_id, activity, activity_date) values ('2', 'login', '2019-06-21')
insert into Traffic (user_id, activity, activity_date) values ('2', 'logout', '2019-06-21')
insert into Traffic (user_id, activity, activity_date) values ('3', 'login', '2019-01-01')
insert into Traffic (user_id, activity, activity_date) values ('3', 'jobs', '2019-01-01')
insert into Traffic (user_id, activity, activity_date) values ('3', 'logout', '2019-01-01')
insert into Traffic (user_id, activity, activity_date) values ('4', 'login', '2019-06-21')
insert into Traffic (user_id, activity, activity_date) values ('4', 'groups', '2019-06-21')
insert into Traffic (user_id, activity, activity_date) values ('4', 'logout', '2019-06-21')
insert into Traffic (user_id, activity, activity_date) values ('5', 'login', '2019-03-01')
insert into Traffic (user_id, activity, activity_date) values ('5', 'logout', '2019-03-01')
insert into Traffic (user_id, activity, activity_date) values ('5', 'login', '2019-06-21')
insert into Traffic (user_id, activity, activity_date) values ('5', 'logout', '2019-06-21')代码实现:
#select date_sub('2019-06-30',interval 90 day);
with t1 as (select distinct user_id,min(activity_date) mindate from traffic where activity='login'group by user_id having mindate>=(date_sub('2019-06-30',interval 90 day)))
select mindate login_date,count(user_id) user_count from t1 group by login_date;1112. 每位学生的最高成绩
需求:
编写解决方案,找出每位学生获得的最高成绩和它所对应的科目,若科目成绩并列,取 course_id 最小的一门。查询结果需按 student_id 增序进行排序。
数据准备:
Create table If Not Exists Enrollments (student_id int, course_id int, grade int)
Truncate table Enrollments
insert into Enrollments (student_id, course_id, grade) values ('2', '2', '95')
insert into Enrollments (student_id, course_id, grade) values ('2', '3', '95')
insert into Enrollments (student_id, course_id, grade) values ('1', '1', '90')
insert into Enrollments (student_id, course_id, grade) values ('1', '2', '99')
insert into Enrollments (student_id, course_id, grade) values ('3', '1', '80')
insert into Enrollments (student_id, course_id, grade) values ('3', '2', '75')
insert into Enrollments (student_id, course_id, grade) values ('3', '3', '82')代码实现:
select * from enrollments;
with t1 as (select *,row_number() over(partition by student_id order by grade desc ,course_id) ran from enrollments)
select student_id,course_id,grade from t1 where ran=1;1113. 报告的记录
需求:
编写解决方案,针对每个举报原因统计昨天的举报帖子数量。假设今天是 2019-07-05 。
返回结果表 无顺序要求
数据准备:
Create table If Not Exists Actions (user_id int, post_id int, action_date date, action ENUM('view', 'like', 'reaction', 'comment', 'report', 'share'), extra varchar(10))
Truncate table Actions
insert into Actions (user_id, post_id, action_date, action, extra) values ('1', '1', '2019-07-01', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('1', '1', '2019-07-01', 'like', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('1', '1', '2019-07-01', 'share', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('2', '4', '2019-07-04', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('2', '4', '2019-07-04', 'report', 'spam')
insert into Actions (user_id, post_id, action_date, action, extra) values ('3', '4', '2019-07-04', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('3', '4', '2019-07-04', 'report', 'spam')
insert into Actions (user_id, post_id, action_date, action, extra) values ('4', '3', '2019-07-02', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('4', '3', '2019-07-02', 'report', 'spam')
insert into Actions (user_id, post_id, action_date, action, extra) values ('5', '2', '2019-07-04', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('5', '2', '2019-07-04', 'report', 'racism')
insert into Actions (user_id, post_id, action_date, action, extra) values ('5', '5', '2019-07-04', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('5', '5', '2019-07-04', 'report', 'racism')代码实现:
#select date_sub('2019-07-05',interval 1 day);
with t1 as (select distinct post_id,extra from actions where action_date=date_sub('2019-07-05',interval 1 day) and extra is not null and action in ('report'))
select extra report_reason,count(post_id) report_count from t1 group by extra;1126. 查询活跃业务
需求:
平均活动 是指有特定 event_type 的具有该事件的所有公司的 occurrences 的均值。
活跃业务 是指具有 多个 event_type 的业务,它们的 occurrences 严格大于 该事件的平均活动次数。
写一个解决方案,找到所有 活跃业务。
以 任意顺序 返回结果表。
数据准备:
Create table If Not Exists Events (business_id int, event_type varchar(10), occurrences int)
Truncate table Events
insert into Events (business_id, event_type, occurrences) values ('1', 'reviews', '7')
insert into Events (business_id, event_type, occurrences) values ('3', 'reviews', '3')
insert into Events (business_id, event_type, occurrences) values ('1', 'ads', '11')
insert into Events (business_id, event_type, occurrences) values ('2', 'ads', '7')
insert into Events (business_id, event_type, occurrences) values ('3', 'ads', '6')
insert into Events (business_id, event_type, occurrences) values ('1', 'page views', '3')
insert into Events (business_id, event_type, occurrences) values ('2', 'page views', '12')代码实现:
with t1 as (select *,avg(occurrences)over(partition by event_type)avgg from events)
select business_id from t1 where occurrences>avgg group by business_id having count(event_type)>=2;1127. 用户购买平台
需求:
编写解决方案找出每天 仅 使用手机端用户、仅 使用桌面端用户和 同时 使用桌面端和手机端的用户人数和总支出金额。
以 任意顺序 返回结果表。
数据准备:
Create table If Not Exists Spending (user_id int, spend_date date, platform ENUM('desktop', 'mobile'), amount int)
Truncate table Spending
insert into Spending (user_id, spend_date, platform, amount) values ('1', '2019-07-01', 'mobile', '100')
insert into Spending (user_id, spend_date, platform, amount) values ('1', '2019-07-01', 'desktop', '100')
insert into Spending (user_id, spend_date, platform, amount) values ('2', '2019-07-01', 'mobile', '100')
insert into Spending (user_id, spend_date, platform, amount) values ('2', '2019-07-02', 'mobile', '100')
insert into Spending (user_id, spend_date, platform, amount) values ('3', '2019-07-01', 'desktop', '100')
insert into Spending (user_id, spend_date, platform, amount) values ('3', '2019-07-02', 'desktop', '100')代码实现:
with t1 as (select spend_date,user_id,platform, sum(amount)sum1from spending group by spend_date,user_id,platform)
# t1排除掉一天中同一个用户购买相同的物品多次的情况
# select * from t1;
,t2 as (select *,count(user_id) over(partition by spend_date,user_id) confrom t1)
# t2统计 去group by 后的数据,数据中只会出现同一个用户一天最多两次的情况,筛选出用户一天中有两条记录的情况,说明此时的用户购买了两类产品
# select * from t2;
,t3 as (select spend_date,sum(sum1) total_amount ,count(distinct user_id) total_users,case when con=1 then platform when con=2 then 'both' end platform1from t2 group by spend_date,platform1)
# t3统计 每天,每个商品的金额总数及不同用户数(排除掉both中用户有2的情况),此时已有both作为商品类别
# select * from t3;
,t4 as (
# select * from (select distinct spend_date from spending)a1 join (select distinct platform1 platform from t3)a2 会报错,不知道为什么select spend_date, 'mobile' as platform from spendingunionselect spend_date, 'desktop' as platform from spendingunionselect spend_date, 'both' as platform from spending
)
# t5作为一个全面表
# select * from t5;selectt4.spend_date, t4.platform ,coalesce(t3.total_amount,t3.total_amount,0) total_amount ,coalesce(t3.total_users,t3.total_users,0) total_usersfrom t4 left join t3 on t4.spend_date=t3.spend_date and t4.platform=t3.platform1;1132. 报告的记录2
需求:
编写解决方案,统计在被报告为垃圾广告的帖子中,被移除的帖子的每日平均占比,四舍五入到小数点后 2 位。
数据准备:
Create table If Not Exists Actions (user_id int, post_id int, action_date date, action ENUM('view', 'like', 'reaction', 'comment', 'report', 'share'), extra varchar(10))
create table if not exists Removals (post_id int, remove_date date)
Truncate table Actions
insert into Actions (user_id, post_id, action_date, action, extra) values ('1', '1', '2019-07-01', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('1', '1', '2019-07-01', 'like', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('1', '1', '2019-07-01', 'share', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('2', '2', '2019-07-04', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('2', '2', '2019-07-04', 'report', 'spam')
insert into Actions (user_id, post_id, action_date, action, extra) values ('3', '4', '2019-07-04', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('3', '4', '2019-07-04', 'report', 'spam')
insert into Actions (user_id, post_id, action_date, action, extra) values ('4', '3', '2019-07-02', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('4', '3', '2019-07-02', 'report', 'spam')
insert into Actions (user_id, post_id, action_date, action, extra) values ('5', '2', '2019-07-03', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('5', '2', '2019-07-03', 'report', 'racism')
insert into Actions (user_id, post_id, action_date, action, extra) values ('5', '5', '2019-07-03', 'view', NULL)
insert into Actions (user_id, post_id, action_date, action, extra) values ('5', '5', '2019-07-03', 'report', 'racism')
Truncate table Removals
insert into Removals (post_id, remove_date) values ('2', '2019-07-20')
insert into Removals (post_id, remove_date) values ('3', '2019-07-18')代码实现:
with t1 as (select post_id po1,action_date,extra from actions where extra='spam')
,t2 as (select * from t1 left join removals on t1.po1=Removals.post_id)
,t3 as (select action_date,count(distinct post_id)/count(distinct po1) con from t2 group by action_date)
select round((sum(con)/count(con))*100,2) average_daily_percent from t3
;相关文章:
)
力扣SQL仅数据库(1098~1132)
1098 小众书籍 需求 编写解决方案,筛选出过去一年中订单总量 少于 10 本 的 书籍,并且 不考虑 上架距今销售 不满一个月 的书籍 。假设今天是 2019-06-23 。 返回结果表 无顺序要求 。 数据准备 Create table If Not Exists Books (book_id int, nam…...

优惠点餐api接口对接的具体步骤是什么?
优惠点餐API接口对接的具体步骤通常包括以下几个阶段: 需求分析:明确对接的目标和需求,例如实现在线点餐、订单管理、支付集成等 。选择API服务提供商:根据业务需求选择合适的点餐API服务提供商 。注册和获取API密钥:…...

【韩顺平Java笔记】第8章:面向对象编程(中级部分)【297-313】
文章目录 297. super基本语法297.1 基本介绍297.2 基本语法 298. super使用细节1299. super使用细节2300. super使用细节3301. 方法重写介绍302. 方法重写细节303. 重写课堂练习1304. 重写课堂练习2输出结果: 姓名:田所浩二 年龄:24305. 养宠物引出多态3…...

快递批量查询物流追踪只揽收无物流信息的单号
在电子商务和物流领域,快递单号的追踪是确保货物顺利送达的关键环节。然而,在实际操作中,经常会遇到一些只显示揽收信息而没有后续物流更新的单号,这给商家和买家都带来了不小的困扰。本文将介绍如何通过快递批量查询物流的方法&a…...

【动态网站资源保存下载】
文章目录 概要解决思路技术细节小结 概要 我们在网上浏览网站时,经常有这样的需求:将浏览的网页保存下来,即使无网的情况下也可以继续浏览。比如一些教育类网站的PPT,内容为HTML格式的,无法作为PPT格式下载下来&#…...

Selenium自动化测试中如何处理数据驱动?
在自动化测试中,数据驱动(Data-Driven Testing)是指通过外部数据源(如Excel、CSV、数据库等)来控制测试用例的执行,而不是直接在代码中硬编码数据。这种方式可以提高测试的灵活性和可维护性,使得…...

淘宝API接口系列有哪些内容?
淘宝API(Application Programming Interface)接口系列是一套允许开发者与淘宝平台进行数据交互的接口集合,涵盖了商品信息、订单信息、物流信息、用户信息以及营销等多个方面的数据接口。以下是对淘宝API接口系列内容的详细归纳: …...

华为OD机试 - 冠亚军排名(Java 2024 E卷 100分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(E卷D卷A卷B卷C卷)》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加…...
VmWare中安装CenterOs(内网服务器)
VmWare中安装CenterOs(内网服务器) 文章目录 VmWare中安装CenterOs(内网服务器)[toc] 一 、CentOS 7的下载与安装1、下载2、安装(1)前期准备(2)正式安装 开始等待!!! 二、软件仓库更换1、root用…...

JS 数组去重 — 各类场景适合方法大全
JS 数组去重 — 各类场景适合方法大全 本文介绍各种场景 JS 去重 方法使用 性能最好、用的最多、场景大全 文章目录 JS 数组去重 — 各类场景适合方法大全 一、基础篇:简单直观的去重方法1. 使用Set数据结构2. 利用filter和indexOf方法3. reduce方法的应用 二、进阶…...

【Java 问题】集合——List
List 1.说说有哪些常见集合?2.ArrayList和LinkedList有什么区别?3.ArrayList的扩容机制了解吗?4.ArrayList怎么序列化的知道吗? 为什么用transient修饰数组?5.快速失败(fail-fast)和安全失败(fail-safe)了解吗…...

xss 跨站脚本攻击
XSS 的全称是 Cross-Site Scripting(跨站脚本攻击)。是一种常见的web安全漏洞。 1. XSS 的定义 XSS 是一种注入类型的攻击,攻击者将恶意脚本注入到受信任的网站中。当其他用户访问该网站时,这些脚本会在用户的浏览器中执行。 2…...

5.toString()、构造方法、垃圾回收、静态变量与静态方法、单例设计模式、内部类
文章目录 一、toString()1. 优缺点2. 使用方法举例① Dos类里更省事的方法 ② Application里 二、构造方法1. 导入2. 什么是构造方法3. 怎么写构造方法① 无参的构造方法(无参构造器)② 有参的构造方法(有参构造器)③ 注意 4. 构造方法的重载 三、再探this1. 给成员变量用2. 给…...
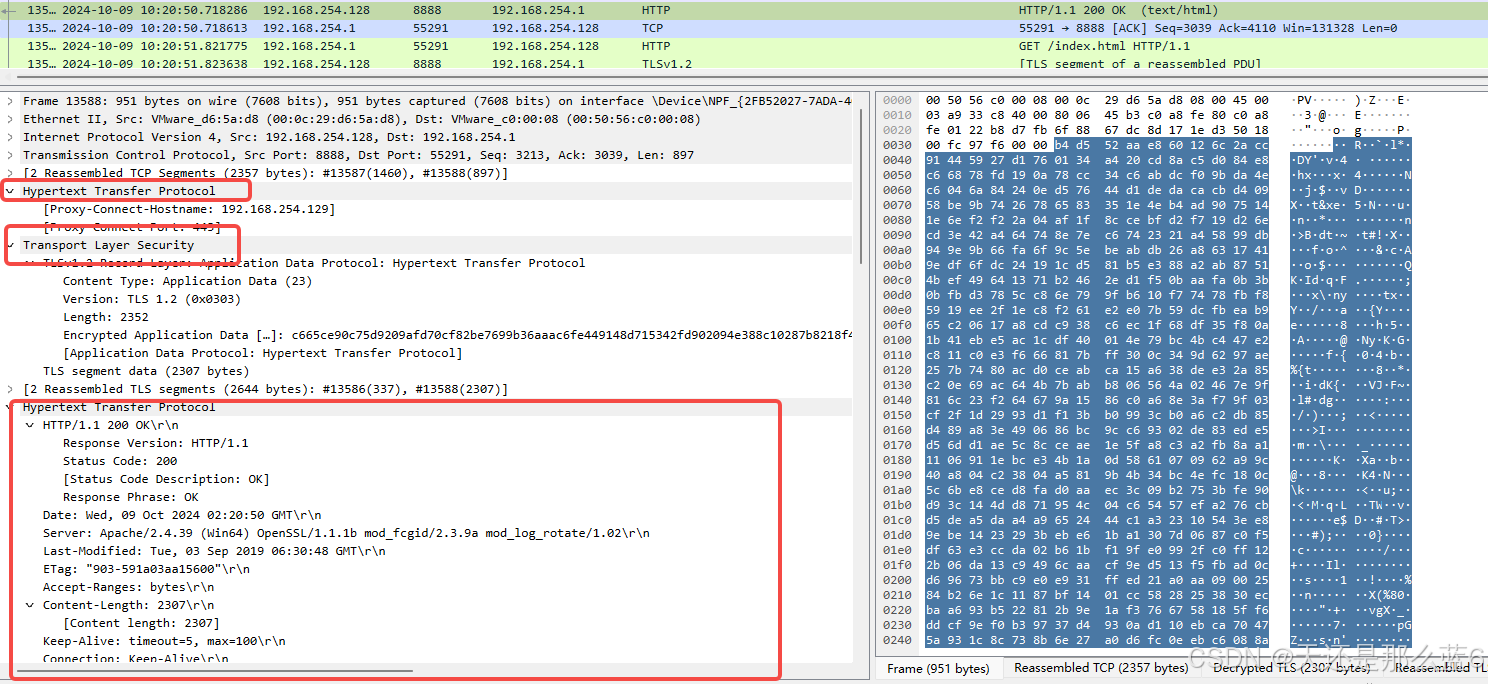
Fiddler配合wireshark解密ssl
环境: win11(wireshark)--虚拟机win7(Fiddler)---虚拟机win7(HTTPS站点) 软件安装问题: 需要.net环境,NDP461-KB3102436-x86-x64-AllOS-ENU.exe。 安装fiddler后安装下…...

【UI】将 naive ui 的 message 封装进axios 中,关于naiveui的message相关的用法
文章目录 前言在setup外进行使用直接包裹使用vue 单文件中使用 参考文章: 关于naiveui的message相关的用法 前言 最近新建了一个vite vu3 的项目,完全是从0 到1 ,封装到request 的时候 想对axios 请求做一个全局的处理,但发现…...

IC卡批量加密快速写入
我们常用的非接触式IC卡,简称M1卡,他有16个扇区,每个扇区有A密码和B密码 对数据的读写是要验证密码的,因此卡片正式使用前,需要把卡片密码改成需要的密码,系统才可以识别 由于一次加密卡片数量比较大&#…...

软件测试学习笔记丨tcpdump 与 wireshark
本文转自测试人社区,原文链接:https://ceshiren.com/t/topic/32333 一、抓包分析TCP协议 1.1 简介 TCP协议是在传输层中,一种面向连接的、可靠的、基于字节流的传输层通信协议。 1.2 环境准备 对接口测试工具进行分类: 网络嗅…...

Redis:分布式 - 哨兵
Redis:分布式 - 哨兵 概念哨兵 Docker 搭建哨兵分布式选举流程 概念 Redis 的主从复制模式下,一旦主节点由于故障不能提供服务,需要人工进行主从切换,同时大量的客户端需要被通知切换到新的主节点上,对于上了一定规模…...
开源城市运动预约的工具类小程序源码
运动场馆预约小程序是一款主要针对城市运动预约的工具类程序, 产品主要服务人群为20-45岁运动爱好者, 程序前后端完整代码,包括场馆动态,运动常识,羽毛球场地预约,足球场地预约,篮球场地预约&a…...
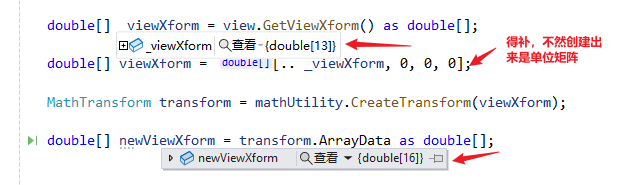
SldWorks问题 2. 矩阵相关接口使用上的失误
问题 在计算三维点在图纸(DrawingDoc)中的位置时,就是算不对,明明就4、5行代码,怎么看都是很“哇塞”的,毫无问题的。 但结果就是不对。 那就调试一下吧,调试后发现生成的矩阵很不对劲&#…...

【Nginx】Nginx index 指令全解:从首页加载失败到高性能目录服务的生产实践
Nginx index 指令全解:从首页加载失败到高性能目录服务的生产实践 本文面向已部署过简单 Nginx 服务、了解反向代理概念,但尚未系统掌握其静态文件目录索引与默认首页机制的中高级工程师。我们将彻底拆解 index 指令的工作原理、继承规则、与 try_files 的协作边界,揭示为何…...

处理智能体的不确定性:重试、回退与人工介入
一个让AI“不任性”的实战手册——该认错时认错,该求助时求助先讲一个让我至今心有余悸的事。 去年做的一个金融Agent,任务是每天自动从十几家券商网站抓取研报,提取关键的投资评级和目标价,然后汇总成一张表发给基金经理。上线跑…...

别再只会点Run了!深度解读Calibre DRC/LVS/PEX那些容易被忽略的配置项
别再只会点Run了!深度解读Calibre DRC/LVS/PEX那些容易被忽略的配置项 在芯片设计验证领域,Calibre工具链早已成为行业标准,但许多工程师对其功能的理解仍停留在"Run DRC/LVS/PEX"的基础操作层面。当面对复杂设计时,这种…...

告别无声直播!OBS实时字幕插件终极指南:5分钟让直播无障碍
告别无声直播!OBS实时字幕插件终极指南:5分钟让直播无障碍 【免费下载链接】OBS-captions-plugin Closed Captioning OBS plugin using Google Speech Recognition 项目地址: https://gitcode.com/gh_mirrors/ob/OBS-captions-plugin 还在为直播观…...

多智能体协同控制未来的前景和方向如何?
在AI技术快速演进的今天,单一智能体已难以满足企业复杂业务场景的需求,多智能体协同正成为行业关注的焦点,它通过多个智能体分工协作、动态交互,形成更强大、更灵活的数字员工团队,有望重塑企业运营模式,推…...

基础知识丨JAVA序列化与反序列化漏洞
今天在学习的时候又接触到了JAVA反序列化漏洞。一直只知道JAVA反序列化就是利用反序列化工具进行攻击,在目标系统中执行命令,利用的就是传输对象时采用JAVA序列化。但是也只知道这么多了。所以,就想着今天再了解一下反序列化漏洞。顺便&#…...

FreeRTOS SMP多核调试踩坑记:在TC397上如何确认你的任务真的跑在了对的CPU核心?
TC397多核调试实战:如何验证FreeRTOS任务真的跑在指定核心? 调试多核系统就像在迷宫中寻找出口——即使代码看起来正确,任务也可能悄悄溜到错误的核心上执行。当LED闪烁频率异常、任务响应延迟或系统出现难以解释的锁死时,开发者首…...
)
宠物领养平台(10052)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

现代Web全栈技术栈实践:从Next.js到PostgreSQL的标准化开发方案
1. 项目概述:一个现代Web应用的技术栈实践最近在技术社区里看到一个挺有意思的项目,叫stack-wuh/x.wuh.site。光看这个名字,可能有点摸不着头脑,但拆解一下就能明白,这本质上是一个关于“技术栈”的实践项目。stack-wu…...

【开源】基于 ASP.NET Core Blazor Server 10.0 构建的学生信息查询系统
学生查询系统基于 ASP.NET Core Blazor Server 10.0 构建的学生信息查询系统,使用 Excel 文件作为数据源,支持动态列适配和响应式布局。功能特性灵活查询:支持按姓名、学号进行模糊查询,可单独或组合使用动态列适配:不…...