【NIO基础】NIO(非阻塞 I/O)和 IO(传统 I/O)的区别,以及 NIO 的三大组件详解
目录
1、NIO
2、NIO 和 IO 的区别
1. 阻塞 vs 非阻塞
2. 一个线程 vs 多个连接
3. 面向流 vs 面向缓冲
4. 多路复用
3、Channel & Buffer
(1)Channel:双向通道
(2)Buffer:缓冲区
(3)ByteBuffer(通用的Buffer)
(一)ByteBuffer 正确使用方法
(二)ByteBuffer 结构
(三)ByteBuffer 分配空间
(四)ByteBuffer 中数据的读和写
4、Selector
(1)Selector 的工作原理
(2)register() 方法详解
(3)selectedKeys() 方法详解
(4)为什么 Channel 必须设置为非阻塞模式

1、NIO
NIO 是 New I/O 的缩写,意思就是“新型输入输出”,它是在 Java 1.4 版本里加进来的,中文可以叫“新 I/O”,也叫“非阻塞 I/O”。NIO 其实就是对传统的阻塞 IO 做了个加强版,专门为了解决以前处理大量数据或者很多并发连接时性能不够好的问题。
NIO 的牛掰之处在于,它提供了全新的一套操作数据的方式,比如:
- 非阻塞模式:你可以发起 IO 操作而不用等着它完成,干别的事也行。
- 多路复用(Selector):一个线程能管理好多个连接,不需要每个连接都分配一个线程。
- 缓冲区读写(Buffer):NIO 用缓冲区来存数据,读写的时候可以灵活处理,不用一次性读完或写完。
NIO 主要有三个核心组件:
- 缓冲区(Buffer):就像个数据临时仓库,所有读写数据的操作都要经过它来处理。
- 通道(Channel):有点像以前的输入输出流,但它可以非阻塞地传数据,不用傻等。
- 选择器(Selector):这玩意儿相当于一个“事件监听器”,可以监听多个连接的事件(比如有数据可读、可写等),然后让线程去处理,这样一个线程就能同时管好多连接。
NIO 让程序处理网络通信和文件操作更加高效,尤其是当你要处理很多并发连接的时候(比如高并发服务器),它表现得非常出色。说白了,NIO 就是让你写的程序跑得更快、更省资源,特别适合那些要处理大量网络连接或者数据传输的场景。
2、NIO 和 IO 的区别
在 Java 里,NIO(New I/O)和传统的 IO 最大的区别就在于如何处理数据和如何利用系统资源。
1. 阻塞 vs 非阻塞
-
传统 IO(阻塞 IO):如果你用传统的 IO 去读取数据,就像你打电话给外卖员问订单进展,直到对方告诉你信息之前,你只能一直举着电话不能干别的。也就是说,线程在等待 I/O 操作完成时,会被 卡住,要等到数据读完或写完才能继续干其他事。
-
NIO(非阻塞 IO):你打电话给外卖员后,他可能说"稍等,我还在路上",然后你就可以继续干别的事,比如刷个视频,再过一会儿再去看看外卖有没有到。这时,线程不会因为等待而停下来,你可以处理其他任务,再定期看看数据准备好了没有。不会因为没有数据而一直卡在那里。
2. 一个线程 vs 多个连接
-
传统 IO:每个网络连接都会单独给你开一个线程,线程就像一个专职服务员,每个客人(连接)都配一个服务员。问题来了:如果餐厅里客人太多,光请服务员就累死老板了。线程多了,系统的性能也会受到影响,因为线程多了之后管理它们、切换任务等会让系统变慢。
-
NIO:NIO 就聪明多了,它就像一个服务员可以同时服务很多桌子(连接),当某桌的客人喊服务时,服务员才会过去处理。这样,只用少量的线程就能服务大量的网络连接,减少了资源的浪费。
3. 面向流 vs 面向缓冲
-
传统 IO:数据是 按流(Stream)处理 的,意思就是你每次只能顺序处理数据,一点一点从头看到尾,就像看电视时从头开始看,不能快进。
-
NIO:NIO 用的是 缓冲区(Buffer),就像在看视频时你可以拖动进度条去看想看的片段。你可以先把数据放到缓冲区里,然后根据需要随时读写,不需要按照固定顺序来。
4. 多路复用
-
传统 IO:每个连接(比如一个客户端连接到服务器)都是一对一的,没法让一个线程同时处理多个连接。
-
NIO:NIO 有个“多路复用器”(Selector),它就像一个大屏幕显示所有的订单状态,服务员可以随时查看哪个订单状态有变化(比如哪个客户数据准备好了),然后再去处理,这样就不用每个订单派一个人盯着了。
3、Channel & Buffer
(1)Channel:双向通道
想象一下,Channel 就像一条双向的水管,水可以从管道里流进来,也可以流出去。在 NIO 中,Channel 也是这样,可以用来读数据(从 Channel 里往 Buffer 里流)和写数据(把 Buffer 里的数据流到 Channel 里)。和传统的输入输出流(Stream)相比,Channel 的功能更强大,因为 Stream 要么是读数据,要么是写数据,而 Channel 可以同时进行这两项操作。
常见的 Channel 类型:
- FileChannel:用来操作文件的通道,可以读写文件数据。
- DatagramChannel:用于 UDP 网络通信的通道,适合需要快速传输小数据包的场景。
- SocketChannel:用于 TCP 网络通信的通道,保证数据的可靠性,适合大多数网络应用。
- ServerSocketChannel:专门用于处理服务器端的 Socket 连接,能够接收来自客户端的连接请求。
这里有个简单的示意图,展示了 Channel 和 Buffer 之间的关系:

(2)Buffer:缓冲区
Buffer 就是用来临时存储数据的容器,可以理解为一个数据仓库。在读写数据的时候,数据首先会放到 Buffer 里,再从 Buffer 进行操作。Buffer 的好处是让数据处理变得更加高效,因为可以一次性读写一大块数据,而不是每次都一个字节一个字节地处理。
常见的 Buffer 类型:
- ByteBuffer:处理字节数据的缓冲区,可以直接用来读写文件和网络数据。
- MappedByteBuffer:将文件的某部分映射到内存,可以高效地读写大文件。
- DirectByteBuffer:直接在内存中分配,不会受 Java 堆的限制,适合高性能应用。
- HeapByteBuffer:在 Java 堆内存中分配,普通使用,性能稍逊色。
- ShortBuffer:处理短整型数据的缓冲区。
- IntBuffer:处理整型数据的缓冲区。
- LongBuffer:处理长整型数据的缓冲区。
- FloatBuffer:处理浮点型数据的缓冲区。
- DoubleBuffer:处理双精度浮点型数据的缓冲区。
- CharBuffer:处理字符数据的缓冲区。
其中,ByteBuffer 是一个通用且灵活的选择,适用于大多数应用场景。如果在特定场景下遇到性能瓶颈或有特殊需求,再考虑使用其他类型的 Buffer(如 MappedByteBuffer 或 DirectByteBuffer)。
(3)ByteBuffer(通用的Buffer)
(一)ByteBuffer 正确使用方法
当你在使用 NIO 里的 ByteBuffer 时,操作起来可能有些步骤需要特别注意,尤其是在读写数据的过程中。让我们用简单的步骤来介绍一下:
- 写数据到 buffer:首先,我们需要往
ByteBuffer里写数据,比如通过channel.read(buffer)。 - 切换为读模式:写完后要告诉
ByteBuffer,我们现在要读数据了。为此,需要调用flip(),这一步相当于把写好的内容准备好给我们读取。 - 从 buffer 读数据:我们可以用
buffer.get()来读取数据。 - 切换回写模式:当我们想再次写入新的数据时,要让
ByteBuffer回到写模式,可以调用clear()或compact(),重新开始写入新的数据。 - 重复以上步骤:通常我们会重复这几步来处理 I/O 操作。
(二)ByteBuffer 结构
为了更好地理解 ByteBuffer,我们需要了解它的三个核心属性:capacity、position 和 limit。这些属性是掌握 ByteBuffer 读写的关键。
- capacity:容量,表示这个 buffer 最多可以容纳多少数据。
- position:当前读写的位置。在写模式下,
position表示下一个写入数据的位置;在读模式下,position表示下一个要读取的位置。 - limit:写模式下,
limit通常等于capacity,表示可以写入的最大位置;读模式下,limit表示你可以读到的最后一个位置,防止越界读取。
1.初始阶段:当我们新建一个 ByteBuffer 时,position 从 0 开始,limit 等于 capacity。也就是说,缓冲区可以从头开始写入数据,最多写满整个容量。

2.写模式:我们可以往 ByteBuffer 中写入数据,比如我们写了 4 个字节,position 就会移动到第 4 个字节的位置,而 limit 依然是 capacity。

3.切换为读模式:调用 flip() 后,position 会切换为 0,表示准备从头开始读取数据,limit 切换到我们最后写入的位置,防止我们读到还没有写的数据。

4.读数据:当我们读取数据时,position 会随着我们读取的字节数移动,直到达到 limit 为止。

5.清空缓冲区:当我们调用 clear() 后,ByteBuffer 又回到最初的写模式状态,position 归零,limit 回到 capacity。

6.使用 compact():如果我们没有读完所有的数据,但又想往缓冲区写入新数据,可以用 compact()。它会把未读的数据移到缓冲区的开始位置,然后把 position 移到未读数据之后的位置,方便我们继续写入。

(三)ByteBuffer 分配空间
在 NIO 中,ByteBuffer 有两种常见的分配方式:一种是通过堆内存(Heap Buffer)分配,另一种是通过直接内存(Direct Buffer)分配,两种方式各有优缺点。
1. 堆内存分配(Heap Buffer)
这是最常用、最简单的一种方式,直接从 JVM 的堆中分配内存。通过 ByteBuffer.allocate() 方法实现。
ByteBuffer heapBuffer = ByteBuffer.allocate(16);这种方式创建的缓冲区是基于堆内存的,JVM 可以直接管理这些内存。堆缓冲区有以下特点:
- 读写性能:因为数据在堆中,访问速度较快,但是当进行 I/O 操作时,数据可能需要从堆内存复制到内核空间的 I/O 缓冲区,所以对于 I/O 密集型操作来说效率稍低。
- 垃圾回收:缓冲区的生命周期由 JVM 管理,垃圾回收器可以自动清理不再使用的缓冲区。这也意味着频繁创建和销毁堆缓冲区可能会导致更频繁的垃圾回收(GC),影响性能。
2. 直接内存分配(Direct Buffer)
通过 ByteBuffer.allocateDirect() 方法,可以分配一个直接内存缓冲区,这种方式的缓冲区直接在操作系统的内存中分配,不经过 JVM 的堆。
ByteBuffer directBuffer = ByteBuffer.allocateDirect(16);直接缓冲区的特点是:
- I/O 性能:由于数据直接分配在操作系统的内存中,在进行 I/O 操作时,不需要将数据从 JVM 堆内存复制到内核空间且不受垃圾回收影响,从而提高了 I/O 性能。
- 分配和释放成本高:因为直接内存是由操作系统分配和管理的,分配和释放的成本较高,且需要显式释放,否则可能出现内存泄漏(Java 的垃圾回收机制不能自动清理直接缓冲区)。
(四)ByteBuffer 中数据的读和写
1.写数据到 ByteBuffer
准备空间:首先,我们需要为 ByteBuffer 分配空间,比如用 ByteBuffer.allocate(size)。这就像买了一个空箱子,决定它的大小。
ByteBuffer buffer = ByteBuffer.allocate(16); 写入数据:接下来,我们可以用 put() 方法把数据放进这个缓冲区。记住,这个过程是在“写模式”下进行的,也就是说,你可以不断地将数据写入这个缓冲区,直到达到它的容量限制。
buffer.put((byte) 1); // 写入 1
buffer.put((byte) 2); // 写入 2 切换到读模式:写完数据后,我们需要调用 flip() 方法来切换到“读模式”。这个方法会设置缓冲区的读取位置,也就是告诉缓冲区:接下来我要读取你里面的数据了。
buffer.flip(); // 切换到读模式2.从 ByteBuffer 读取数据
读取数据:一旦切换到读模式,就可以使用 get() 方法来读取数据。这个方法会从缓冲区的当前位置读取数据,并自动移动读取位置。
byte firstValue = buffer.get(); // 读取第一个值
byte secondValue = buffer.get(); // 读取第二个值处理读取后的状态:在读取完数据后,缓冲区的 position 会向前移动,表示我们已经读取了这些数据。如果我们想再次写入新的数据,就需要调用 clear() 或 compact() 方法。这两个方法在前面也有提到。
- clear():这个方法会重置缓冲区,设置
position为 0,limit为容量,准备再次写入数据。但是这会清空已经读取的数据,所有内容都会被丢弃。
buffer.clear(); // 清空缓冲区,准备写入新数据- compact():这个方法会把未读取的部分(即还没被读的内容)移动到缓冲区的开始位置,然后再准备写入新数据。这种方式可以保留尚未读取的数据。
buffer.compact(); // 将未读数据压缩到前面,并准备写入新数据3.读写数据总结:
所以,ByteBuffer 的读和写过程大致可以归纳为:
- 分配空间:创建一个新的缓冲区。
- 写数据:用
put()方法向缓冲区写入数据。 - 切换模式:使用
flip()方法切换到读模式。 - 读数据:用
get()方法读取数据。 - 清理或压缩:调用
clear()或compact()方法以便再次写入数据。
通过这种方式,我们就能高效地在 ByteBuffer 中读写数据,为 NIO 的性能优化奠定基础。
4、Selector
在 NIO 中,Selector 是一个非常重要的组件,它的作用是让一个线程能够同时管理多个 Channel。Selector 可以被视作一个 大管家,管理多个 门(Channel)。当有客人(事件)到访时,管家会及时通知你,让你去接待他们。这样,你就不需要为每个客人都派一个服务员(线程),从而节省资源。
(1)Selector 的工作原理
Selector 的工作流程通常包括以下几个步骤:
- 注册 Channel:首先,你需要将要管理的 Channel 注册到 Selector 上,告诉 Selector 哪些 Channel 需要关注。
- 调用 select() 方法:然后,调用 Selector 的
select()方法。这个方法会阻塞,直到至少有一个注册的 Channel 发生读写就绪事件。也就是说,Selector 会在这里“守门”,等待事件的发生。 - 处理事件:一旦有 Channel 有事件发生(例如有数据可读或可写),
select()方法会返回这些事件,然后你可以在一个线程中处理所有的 Channel 事件。这种方式避免了因为某个 Channel 的事件而让线程被阻塞。
代码示例:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.nio.channels.SelectionKey;
import java.nio.channels.SelectableChannel;
import java.util.Iterator;public class NioSelectorExample {public static void main(String[] args) throws IOException {// 创建 SelectorSelector selector = Selector.open();// 创建 ServerSocketChannel,并设置为非阻塞模式ServerSocketChannel serverChannel = ServerSocketChannel.open();serverChannel.bind(new InetSocketAddress(8080));serverChannel.configureBlocking(false);// 将 serverChannel 注册到 Selector,监听接受连接事件serverChannel.register(selector, SelectionKey.OP_ACCEPT);System.out.println("Server is listening on port 8080...");while (true) {// 阻塞等待事件发生selector.select();// 获取所有已准备好的事件Iterator<SelectionKey> keys = selector.selectedKeys().iterator();while (keys.hasNext()) {SelectionKey key = keys.next();keys.remove();if (key.isAcceptable()) {// 接受新的连接SocketChannel clientChannel = serverChannel.accept();clientChannel.configureBlocking(false);// 注册到 Selector,监听读取事件clientChannel.register(selector, SelectionKey.OP_READ);System.out.println("Accepted new connection from " + clientChannel.getRemoteAddress());} else if (key.isReadable()) {// 读取数据SocketChannel clientChannel = (SocketChannel) key.channel();ByteBuffer buffer = ByteBuffer.allocate(256);int bytesRead = clientChannel.read(buffer);if (bytesRead == -1) {// 客户端关闭连接clientChannel.close();System.out.println("Closed connection from " + clientChannel.getRemoteAddress());} else {// 处理读取的数据String message = new String(buffer.array()).trim();System.out.println("Received: " + message);}}}}}
}在这个示例中,我们主要关注 Channel的register() 方法、Selector的selectedKeys() 方法 和 为什么被注册到 Selector 中的 Channel 需要通过 configureBlocking(false) 方法设置为非阻塞的。
(2)register() 方法详解
作用:register() 方法用于将一个 Channel 注册到 Selector。这使得 Selector 能够监视该 Channel 上的特定事件(如连接、读取或写入)。每个 Channel 在注册时可以指定一个或多个感兴趣的事件(如连接、读取或写入)。
方法签名:
public SelectionKey register(Selector sel, int ops) throws ClosedChannelException;参数:
Selector sel:需要注册的 Selector。int ops:感兴趣的操作类型,例如SelectionKey.OP_ACCEPT(接收连接)、SelectionKey.OP_READ(可读)、SelectionKey.OP_WRITE(可写)。
返回值:返回一个 SelectionKey,用于标识该 Channel 的注册状态。
(3)selectedKeys() 方法详解
作用:selectedKeys() 方法返回一个 Set<SelectionKey>,包含了上一次调用 select() 方法后,所有已准备好的事件的 SelectionKey。它可以检查哪些 Channel 上发生了感兴趣的事件,并进行相应的处理。
返回值:返回的 Set<SelectionKey> 中包含了所有已准备好处理的 Key,开发者可以通过这些 Key 获取具体的 Channel 和事件类型。
注意:处理完一个 SelectionKey 后,必须手动从集合中移除它。selectedKeys() 的集合不会自动移除已处理的 Key。如果不手动移除,下一次事件循环时,你将继续处理已完成的事件,可能导致重复处理。示例:调用remove()方法移除已处理的 SelectionKey
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectedKeys.iterator();while (iterator.hasNext()) {SelectionKey key = iterator.next();// 处理 key 的逻辑iterator.remove(); // 处理后手动移除
}(4)为什么 Channel 必须设置为非阻塞模式
在 NIO 中,注册到 Selector 的 Channel 必须设置为非阻塞模式,这里有几个原因:
(一)避免线程阻塞:如果 Channel 是阻塞的,当调用 select() 方法时,如果某个 Channel 的 I/O 操作未准备好(例如,没有数据可读),则相关的线程会被阻塞,无法继续处理其他 Channel 的事件。这就违背了使用 Selector 的初衷。
(二)提高资源利用率:通过使用非阻塞模式,线程可以在等待 I/O 事件的同时处理其他任务。这样,CPU 资源得以更有效地利用,避免了线程因等待 I/O 操作而闲置。
(三)单线程管理多个 Channel:NIO 的设计初衷是让单个线程能够高效地管理多个 Channel。非阻塞模式使得线程可以在一个事件循环中处理多个 Channel 的状态变化,而不会被单个 Channel 的状态阻塞。

推荐:
【Redis】Redis中的 AOF(Append Only File)持久化机制-CSDN博客![]() https://blog.csdn.net/m0_65277261/article/details/142661193?spm=1001.2014.3001.5502【MySQL】常见的SQL优化方式(二)-CSDN博客
https://blog.csdn.net/m0_65277261/article/details/142661193?spm=1001.2014.3001.5502【MySQL】常见的SQL优化方式(二)-CSDN博客![]() https://blog.csdn.net/m0_65277261/article/details/142610165?spm=1001.2014.3001.5502
https://blog.csdn.net/m0_65277261/article/details/142610165?spm=1001.2014.3001.5502
相关文章:
【NIO基础】NIO(非阻塞 I/O)和 IO(传统 I/O)的区别,以及 NIO 的三大组件详解
目录 1、NIO 2、NIO 和 IO 的区别 1. 阻塞 vs 非阻塞 2. 一个线程 vs 多个连接 3. 面向流 vs 面向缓冲 4. 多路复用 3、Channel & Buffer (1)Channel:双向通道 (2)Buffer:缓冲区 (3)ByteBufferÿ…...

HDLBits中文版,标准参考答案 | 3.1.3 Arithmetic Circuits | 算术电路
关注 望森FPGA 查看更多FPGA资讯 这是望森的第 10 期分享 作者 | 望森 来源 | 望森FPGA 目录 1 Half adder | 半加器 2 Full adder | 全加器 3 3-bit binary adder | 3位二进制加法器 4 Adder | 加法器 5 Signed addition overflow | 有符号数的加法溢出 6 100-bit bi…...

网络编程 websocket
1. HTTP 截至 2024 年,HTTP(HyperText Transfer Protocol)已经发展到 HTTP/3 版本。 各个版本的简介: HTTP/0.9(1991年): 最初的 HTTP 版本,非常简单,仅支持 GET 方法…...

【JDK17 | 5】Java 17 深入剖析:新的随机数生成器 API
引言 在 Java 17 中,新的随机数生成器 API 作为一个重要特性被引入,旨在提供更灵活和高效的随机数生成方案。新的 API 不仅支持多种生成算法,还改善了随机数生成的性能,适应了现代开发的需求。在本篇文章中,我们将深入…...

剪切走的照片:高效恢复与预防策略
一、剪切走的照片现象描述 在日常的数字生活中,照片作为记录生活点滴、工作成果的重要载体,其重要性不言而喻。然而,有时我们可能会遇到一种令人头疼的情况:原本打算通过剪切操作将照片移动到另一个位置,却意外地发现…...

基于XGBoost的结核分枝杆菌的耐药性预测研究【多种机器学习】
1. 绪论 目录 1. 绪论 1.1研究背景及意义 1.2国内外研究现状 1.2.1国内研究现状 1.2.2国外研究现状 1.3研究目的 2. 相关技术概念 2.1结核分枝杆菌的耐药性机制 2.2机器学习与系统发育法相结合 2.3XGBoost和随机森林算法的优势和应用 3. 模型设计 3.1数据准备与预…...

【C++差分数组】3229. 使数组等于目标数组所需的最少操作次数|2066
本文涉及知识点 C差分数组 LeetCode3229. 使数组等于目标数组所需的最少操作次数 给你两个长度相同的正整数数组 nums 和 target。 在一次操作中,你可以选择 nums 的任何子数组,并将该子数组内的每个元素的值增加或减少 1。 返回使 nums 数组变为 tar…...

浅谈PyTorch中的DP和DDP
目录 1. 引言2. PyTorch 数据并行(Data Parallel, DP)2.1 DP 的优缺点2.2 DP 实现代码示例 3. PyTorch 分布式数据并行(Distributed Data Parallel, DDP)3.1 DDP 的优缺点3.2 分布式基本概念3.3 DDP 的应用流程3.5 DDP 实现代码示…...

在Windows上利用谷歌浏览器进行视频会议和协作
随着远程工作和在线教育的普及,使用谷歌浏览器在Windows上进行视频会议和协作变得越来越常见。本文将为您提供一个详细的教程,教您如何在Windows上利用谷歌浏览器进行视频会议和协作,同时解决一些常见的问题。(本文由https://goog…...

VMware Fusion 13.6.1 发布下载,修复 4 个已知问题
VMware Fusion 13.6.1 发布下载,修复 4 个已知问题 VMware Fusion 13.6.1 for Mac - 领先的免费桌面虚拟化软件 适用于基于 Intel 处理器和搭载 Apple 芯片的 Mac 的桌面虚拟化软件 请访问原文链接:https://sysin.org/blog/vmware-fusion-13/ 查看最新…...

P9751 [CSP-J 2023] 旅游巴士
P 9751 P9751 P9751 部分分思路 题目要求时间必须是 k k k 的非负整数倍,所以想到了升维。这样就变成了一道分层图最短路的题目。用 BFS 算法可以拿到 A i 0 A_i0 Ai0 的 35 35 35 分。 满分思路 其实部分分的思路已经很接近正解了,想要拿到满…...

【Linux】man手册安装使用
目录 man(manual,手册) 手册安装: 章节区分: 指令参数: 使用场景: 手册内容列表: 手册查看快捷键: 实例: 仍致谢:Linux常用命令大全(手册) – 真正好用的Linux命令在线查询网站 提供的命令查询 在开头先提醒一下:在 man 手册中退出的方法很简单…...
)
mysql学习教程,从入门到精通,SQL处理重复数据(39)
1、SQL处理重复数据 使用GROUP BY和HAVING子句删除重复数据(以SQL Server为例)”的背景和原理的详细解释: 1.1、背景 在数据库管理中,数据重复是一个常见的问题。重复数据可能由于多种原因产生,如数据录入错误、数据…...

mapbox解决wmts请求乱码问题
贴个群号 WebGIS学习交流群461555818,欢迎大家 事故现场 如图所示,wmts请求全是乱码,看起来像是将一个完整的请求拆成一个一个的字母了,而且控制台打印map.getStyle() 查看该source发现不出异常 解决办法 此类问题就是由于更…...

《C++职场中设计模式的学习与应用:开启高效编程之旅》
在 C职场中,设计模式是提升代码质量、增强程序可维护性和可扩展性的强大武器。掌握并正确应用设计模式,不仅能让你在工作中更加得心应手,还能为你的职业发展增添有力的砝码。那么,如何在 C职场中学习和应用设计模式呢?…...

Maya动画--基础约束
005-基础约束02_哔哩哔哩_bilibili 父子约束 移动圆环,球体会跟着移动,并回到初始的相对位置 不同物体间没有层级关系 明确子物体与父物体间的关系 衣服上的纽扣 法线约束 切线约束 碰到中心时会改变方向...
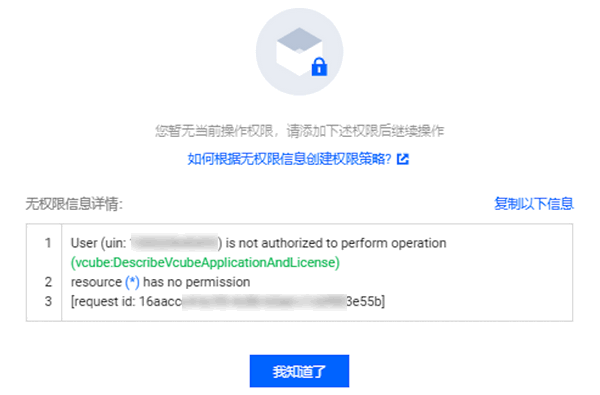
腾讯云License 相关
腾讯云视立方 License 是必须购买的吗? 若您下载的腾讯云视立方功能模块中,包含直播推流(主播开播和主播观众连麦/主播跨房 PK)、短视频(视频录制编辑/视频上传发布)、终端极速高清和腾讯特效功能模块&…...

开放式耳机什么品牌最好?十大超好用开放式耳机排名!
由于长时间使用传统入耳式耳机可能会对耳道健康带来潜在的负面影响,越来越多的用户倾向于选择开放式耳机,这种设计不侵入耳道。它有助于降低耳内湿度、减少细菌滋生,以及缓解耳道因封闭而过热的不适。但是大部分人还是不知道怎么选择开放式耳…...

基于Zynq SDIO WiFi移植二(支持2.4/5G)
1 SDIO设备识别 经过编译,将移植好的uboot、kernel、rootFS、ramdisk等烧录到Flash中,上电启动,在log中,可看到sdio设备 [ 1.747059] mmc1: queuing unknown CIS tuple 0x01 (3 bytes) [ 1.761842] mmc1: queuing unknown…...

Spring Boot敏感数据动态配置:深入实践与安全性提升
在构建Spring Boot应用的过程中,敏感数据的处理与保护是至关重要的。传统上,这些敏感数据(如数据库密码、API密钥、加密密钥等)可能被硬编码在配置文件中,这不仅增加了泄露的风险,也限制了配置的灵活性和可…...

新手避坑指南:用PEAK CAN卡和ROS快速上手大陆ARS408-21XX毫米波雷达
新手避坑指南:用PEAK CAN卡和ROS快速上手大陆ARS408-21XX毫米波雷达 毫米波雷达在自动驾驶和机器人感知领域扮演着关键角色,而大陆ARS408-21XX系列雷达因其高性价比和稳定性能,成为许多开发者的首选。然而,对于刚接触这一领域的新…...

修音翻车现场实录:用Melodyne选择工具时,这3个坑我劝你别踩
Melodyne修音避坑指南:选择工具三大致命操作误区解析 第一次用Melodyne修人声时,我对着屏幕上的波形信心满满地拖动音符,结果导出的音频听起来像电子合成器故障——音高扭曲、节奏支离破碎。后来才发现,问题都出在那个看似简单的…...

Ix开源平台:基于Kubernetes的私有云与家庭实验室一体化管理方案
1. 项目概述与核心价值最近在折腾一个叫Ix的开源项目,它来自ix-infrastructure这个组织。乍一看这个名字,你可能觉得有点抽象,但如果你对自托管、家庭实验室、私有云或者想找一个更现代、更易用的 TrueNAS 替代品感兴趣,那这个项目…...

解锁GitHub极速体验:智能加速插件深度解析
解锁GitHub极速体验:智能加速插件深度解析 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub GitHub加速插件(…...

从SD卡初始化到读写文件:一个完整嵌入式项目中的SDIO驱动避坑实践
从SD卡初始化到读写文件:嵌入式SDIO驱动实战全解析 在嵌入式系统开发中,SD卡因其高容量、低成本和便携性成为数据存储的首选方案。然而,看似简单的SD卡接口背后隐藏着复杂的初始化协议和时序要求。许多工程师在项目初期都会遇到SD卡无法识别、…...

iOS越狱终极指南:解锁iPhone隐藏功能的3个关键步骤
iOS越狱终极指南:解锁iPhone隐藏功能的3个关键步骤 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址: ht…...

使用mcp-maker快速构建AI工具调用服务器:从协议原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上更强大的“手脚”,让它能直接操作我电脑上的各种软件和工具。这听起来很酷,对吧?但实际操作起来,你会发现一个核心痛…...

为AI编程助手构建安全防线:Cursor自定义规则实战指南
1. 项目概述:为AI编程助手装上“安全护栏” 如果你和我一样,深度使用Cursor这类AI编程助手,那你一定体验过它带来的效率革命。它能帮你生成代码、重构函数、甚至解释复杂的逻辑,就像一个不知疲倦的编程伙伴。但硬币总有另一面——…...

Rekall:基于时空查询的视频内容智能检索开源框架
1. 项目概述:Rekall,一个面向视频时空查询的开源利器 如果你曾经尝试过从一段长视频里,精准地找出“那个穿红色衣服的人从画面左侧走到右侧的片段”,或者想快速定位“所有出现这只特定宠物狗的镜头”,你就会知道这有多…...

基于Panel与LLM构建智能数据可视化应用的架构与实践
1. 项目概述与核心价值最近在数据可视化与交互应用开发领域,一个名为holoviz-topics/panel-chat-examples的项目仓库引起了我的注意。乍一看,这似乎只是将聊天界面(Chat Interface)与 Panel 这个强大的 Python 交互式仪表盘库结合…...